1、什么是SFT?
SFT,全称是 Supervised Fine-tuning(有监督微调),在大语言模型中通常指"指令微调"。
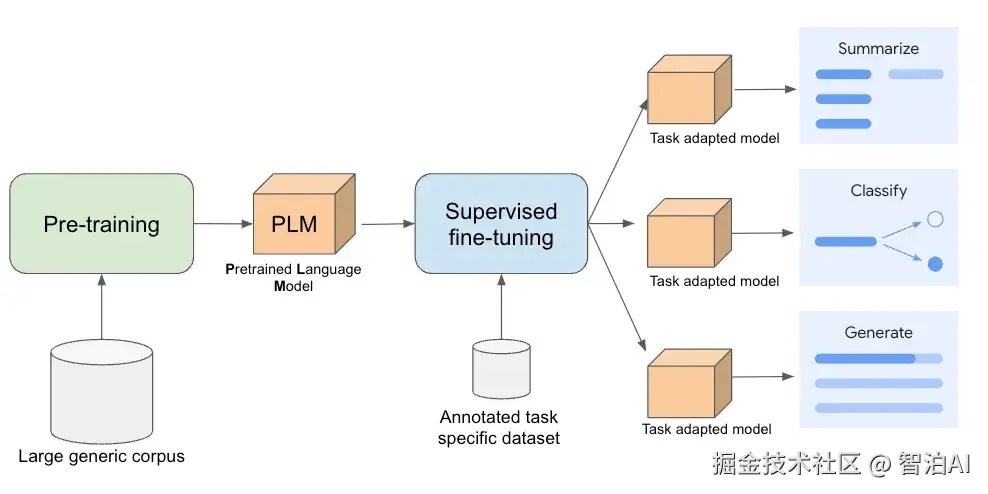
它是在大模型经过预训练、具备通用语言能力后,通过进一步微调让它学会理解人类意图,生成有用回答。
SFT 的目标是通过一批高质量的"指令-回复"对,让大模型学会:
什么是"有用"的回答
如何有逻辑地、结构地回应用户指令
如何按照不同任务的需求(总结、翻译、写代码等)采用合适的表达方式
简单说: 预训练是"学语言",SFT是"学听话"
2、SFT的流程是怎样的?
整个过程可分为四个主要步骤:
准备数据(指令-回答对)
数据来源可能包括:
真实用户提问 +人工精心撰写的优质回答
专门设计的任务指令及对应回复
高质量开源数据集(如 Alpaca、ShareGPT等)
每个样本的形式通常是:
输入:一个用户指令
输出:一个理想回复
构造训练格式(加特殊 Token)
为了让模型区分"指令"和"回答",通常会加上一些特殊的标记(token),比如:
请介绍一下绍兴
<|assistant|>绍兴是浙江省的历史文化名城......
这些标记帮助模型判断哪一部分是提问,哪一部分是它需要生成的回复。
训练前会通过 tokenizer 把文本切成 token 序列,如:"请介绍一下绍兴"→1432,2101,847,1067
训练方法
和预训练阶段的自监督学习不同,SFT使用的是标准的监督学习:在给定指令的基础上,学习如何生成与目标回答一致的内容。
损失函数通常还是交叉熵(Cross Entropy Loss),用来衡量模型生成的 token 和理想答案之间的差距。
训练过程
训练过程主要包括:
将用户输入(指令)和目标回复拼接成一个完整的 token序列
并行预测每个 token 的下一个 token
只在<|assistant|>之后的部分计算损失
反向传播,更新参数
重点: 用户输入部分不计算损失,目的是避免模型记忆、复述、或篡改用户问题,而是专注于生成有用回答。
此外,训练中也可加入:多轮对话上下文,帮助模型理解语境。
3、SFT的作用和局限
预训练: 教模型学语言,理解语法、常识、表达方式但这阶段的模型不能准确遵循指令生成内容,只是机械地补全文本。
SFT(指令微调) : 教模型听懂人话,按照指令-完成任务,比如写诗、总结、答题。它让模型从"语言模型"变成了"初步的对话助手"。
但 SFT 无法处理以下问题:
模型更偏好哪种回答风格?哪个更符合人类喜好?
如何避免输出攻击性内容、虚假信息、立场偏差?
这些问题,靠模仿人类回答还不够,还需要下一阶段:RLHF(基于人类反馈的强化学习),让模型"更合人意"。