一直在思考大模型推理优化的事情,因为最近在研究大模型的一体机。优化的方案有很多,但都比较零散,没有什么理论依据。但在网上发现很好的一张图,感觉这张图讲清楚了大致的优化方案,借用来理解一下。
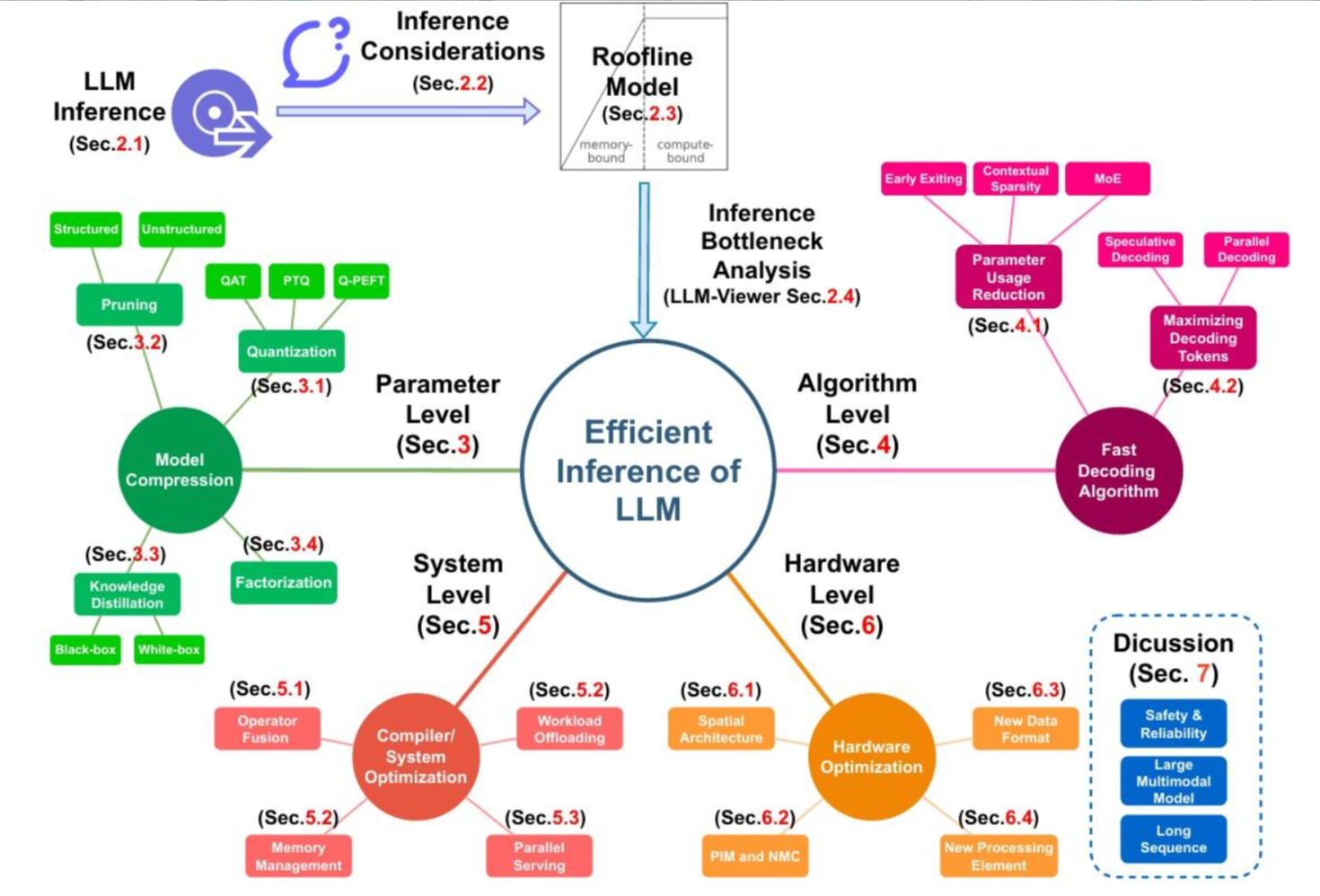
上面这张图,内容非常多,但简单总结,也就是一句话:
这是一张"高效大模型推理"综述的思维导图,从"推理流程 → 找瓶颈 → 四个层级的优化手段 → 未来讨论方向",把整个 LLM 推理优化的版图画了出来。
下面按图上的结构一点点展开来理解:
首先,提出问题:
1. 目标:Efficient Inference of LLM
中间那个大圆就是总目标:让 LLM 推理更高效(更快、更省显存、更省钱、但还能保持可接受的精度)。
下面四条彩色分支就是四个层次的优化维度:
Parameter Level ------ 模型的权重
Algorithm Level ------ 算法
System Level ------ 运行的系统支撑
Hardware Level ------ 硬件架构
2. 分析:从"LLM 推理"到"瓶颈分析"
1)LLM Inference
-
表示我们要优化的是 大语言模型的推理过程,不是训练。
-
指的就是:给定 prompt,模型做前向计算,生成 token 的整个流程。
2)Inference Considerations
在真正谈优化前,要先明确 需求 & 约束,比如:
-
想优化的是 延迟 还是 吞吐?
-
场景里对 在线响应时间、并发数、成本、精度 的要求分别是什么?
-
这些会直接影响后面采取哪种技术路线。
3)Roofline Model
-
用一个 Roofline 模型 来定位:当前推理是 算力受限(compute-bound) 还是 带宽受限(memory-bound)。
-
横轴一般是算术强度(FLOPs/byte),纵轴是性能(如 GFLOPs)。
-
左侧:受内存带宽限制;
-
右侧:受算力峰值限制。
-
-
对 LLM 来说,这一步是用来 定性地看到"算还是搬数据更卡",为后面选优化方向。
4)Inference Bottleneck Analysis(Sec.2.4,LLM-Viewer)
-
基于前面的 Roofline,再做更细节的 瓶颈分析工具(例如论文里叫 LLM-Viewer),看:
-
哪些层/算子最耗时?
-
是 GEMM、Attention、KV cache 读写,还是别的?
-
-
这一步的意思:不要盲目优化,先用工具找真正的热点。
3. 优化1------参数级(权重):Parameter Level
目标:从"参数"本身下手,让模型更小、更轻,属于"Model Compression"范畴。
3.1 Quantization
-
把 FP16/FP32 权重 & 激活量化到 低比特(INT8/INT4/甚至更低) 。
实际上,一体机一般也会有 Int4版本,主要就是通过量化来提升大模型的性能,当然,会牺牲精度。
-
图里写了几种代表性方式:
-
QAT:Quantization Aware Training(带量化感知的再训练),这个是有一定的难度的,需要考虑重新训练,边训练边量化。效果可能会更好,但难度更大。
-
PTQ:Post-Training Quantization(训练完再量化),这是比较常见的做法,我们之前在量化YOLO这种普通的神经网络时,也会简单采用PTQ,效果也还不错。
-
Q-PEFT:跟参数高效微调(LoRA/PEFT)结合的量化方案。这个用得比较少。
-
-
作用:减少存储 + 提高吞吐,到一定程度牺牲一点精度。
3.2 Pruning
-
剪枝:把不重要的参数/通道/注意力头删掉。
-
可包括非结构化剪枝(稀疏)和结构化剪枝(整通道/整块)。
3.3 Knowledge Distillation
-
知识蒸馏:大模型做 teacher,小模型做 student。
-
图里区分:
-
Black-box:只用 teacher 的输入输出(看不见内部);
-
White-box:还能访问中间层特征等。
-
-
目标是:**训练一个更小的 student 模型,但性能尽量接近大模型。**在DeepSeek中,就有不少的蒸馏模型,经验证,效果是不错的。
3.4 Factorization(Sec.3.4)
-
各种 矩阵/张量分解 技术,比如低秩分解,减少参数和计算量。
-
例如把一个大矩阵 W 分解成 A·B 两个小矩阵,整体 FLOPs 和存储都下降。
总的来说,这一支就是:把模型本身变小 / 变稀疏 → 推理更省。
4. 优化2------算法级:Algorithm Level
目标:在不(或少)改模型参数的前提下,改变推理过程本身,尤其是解码阶段。
4.1 Parameter Usage Reduction
怎么理解"参数使用减少"?不是把参数删掉,而是 在一次推理中少用一部分参数/层。
包含几类:
-
Early Exiting:
- 在中间层插"出口":某个 token 提前判断已经稳定,就不再走后面所有层,直接输出。
-
Contextual Sparsity:
- 对当前上下文只激活一部分通道/头/专家,比如注意力稀疏化。
-
MoE(Mixture of Experts):
-
模型里有很多"专家",每次只激活很少几位专家参与计算,其余都不算,节省计算。
-
这个在大模型中非常常见,比如:deepseek就是典型的MoE优化模型。
-
4.2 Maximizing Decoding Tokens
一次解码尽量多生成 / 利用更多 token,减少轮次:
-
Speculative Decoding:
- 用一个小模型先"猜"一串 token,大模型一次性校验/纠正,大模型不用一步一步生成。
-
Parallel Decoding:
- 让未来的多个位置并行预测(打破传统自回归的严格顺序),通过一些修正策略保证合理性。
这种方式,会比较少,没有看到好的例子。
这条支线的核心:不是压缩模型,而是让解码过程更聪明、更并行。
5. 优化3 ------系统级:System Level
目标:在不改模型数学表达式的前提下,从 编译器 / 运行时 / 调度 角度挖潜。
统称为 Compiler / System Optimization。
典型手段:
5.1 Operator Fusion(算子融合)
-
把若干连续算子(如 GEMM + Bias + GELU + LayerNorm)
合并为一个或更少的 kernel 调用,减少:
-
内存读写;
-
kernel launch 开销。
-
这要看具体的算力芯片,算子融合的方法有所不同。
5.2 Memory Management & Workload Offloading
-
Memory Management:
-
KV cache 管理、激活 checkpointing、显存/主存之间的分页和复用;
-
多卡/多机场景下减少数据搬运。
-
-
Workload Offloading:
-
把部分工作卸载到别的设备:比如 CPU 负责 sampling / post-processing,GPU 专注矩阵乘;
-
或者 KV cache 放到 CPU/内存,计算放在 GPU。
-
这是常见的方法,经常会有将GPU卸载到CPU,或者卸载到 FPGA。当然,目的会不一样。
-
5.3 Parallel Serving
-
从"服务层面"优化:
-
多用户并发调度(batching / dynamic batching);
-
pipeline 并行 / 张量并行 / expert 并行等布局;
-
保证 QPS(吞吐)最大化,同时控制 tail latency。
-
这一块更接近"工程/系统调优",不动模型结构,但把 算力用得更满。
6. 优化4------硬件级:Hardware Level
目标:从芯片和体系结构层面专门为 LLM/矩阵计算做优化。
统称为 Hardware Optimization,包括:
6.1 Spatial Architecture
-
一般指 空间架构 / 加速器 Topology:
-
FPGA/ASIC 的 systolic array 布局;
-
on-chip NoC、核心间通信结构;
-
适合 LLM 的片上层次结构(SRAM/缓存多级布局)。
-
6.2 PIM and NMC(Processing In Memory / Near Memory Computing)
-
把部分计算"搬到存储边上/里面做",减轻内存带宽瓶颈:
-
例如存算一体的 DRAM、RRAM;
-
接近内存的算子引擎,减少数据来回搬。
-
6.3 New Data Format
-
为硬件设计 更适合的数字格式:
-
bfloat16、FP8 等;
-
针对 LLM 的对数量化格式等;
-
-
让硬件的 ALU / Tensor Core 可以更高吞吐、配合低比特量化。
6.4 New Processing Element
-
设计专门的 PE(Processing Element):
-
针对矩阵乘、注意力、Softmax 等算子做硬件级优化;
-
比如专用的 Attention 单元、KV cache 引擎等。
-
这一层就是你很熟悉的:NPU/GPU/FPGA/ASIC 架构层的优化。
7. 不确定项
这是作者认为 未来还需要重点讨论 / 仍然难搞 的几个方向:
-
Safety & Reliability:高效推理不能牺牲安全性、鲁棒性(例如量化/剪枝后行为是否更难预测);
-
Large Multimodal Model:多模态大模型(图文、音视频)推理的高效问题;
-
Long Sequence:长上下文(几十万 token)场景下的高效 attention、KV cache、内存管理等。
最后总结:
做"大模型高效推理"这件事,不是单点小优化,而是一整套从"参数---算法---系统---硬件"四个层级协同的工程 :
先通过 Roofline / 工具找到瓶颈,然后在各层级选择合适的策略(压模型、改解码、调系统、做硬件),最后还得兼顾安全、多模态、长上下文这些新需求。
具体如何做,需要根据方案的特点,去找最合适的方案。