RDB 是 SPL 的 Native 数据源,SPL 通过 JDBC 与数据库交互,可以动态生成 / 拼接 SQL,也可以为 SQL 传递参数,原来在 Java 等语言与 SQL 结合的场景都可以使用 SPL 来完成。
导入 MySQL 数据。
配置数据库连接
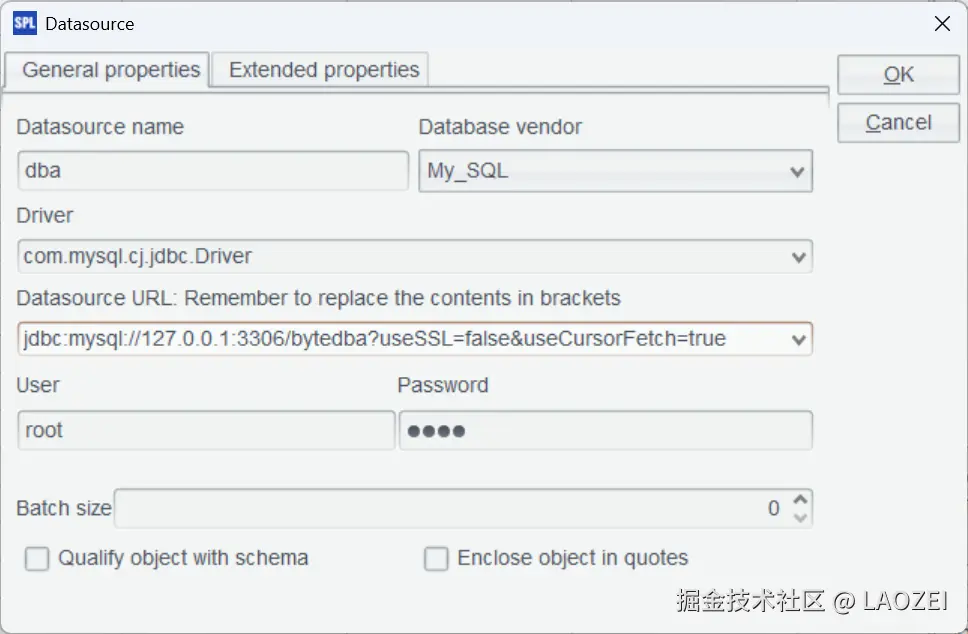
连接串:jdbc:mysql://127.0.0.1:3306/bytedba?useSSL=false&useCursorFetch=true
计算用例
查询目标
2024 年各类订单状态的订单金额
设置脚本参数
为脚本设置年份参数用于数据过滤。

编写脚本
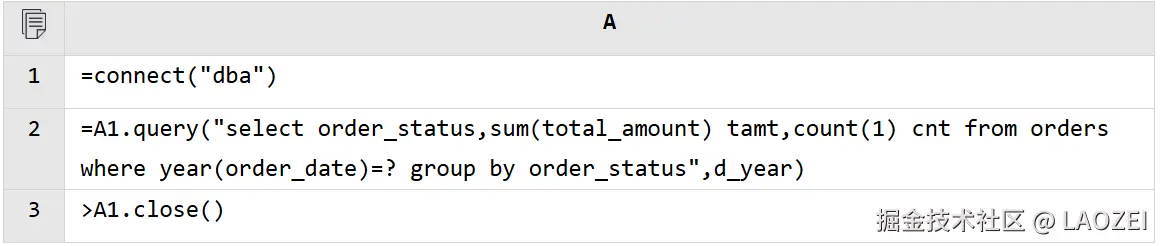
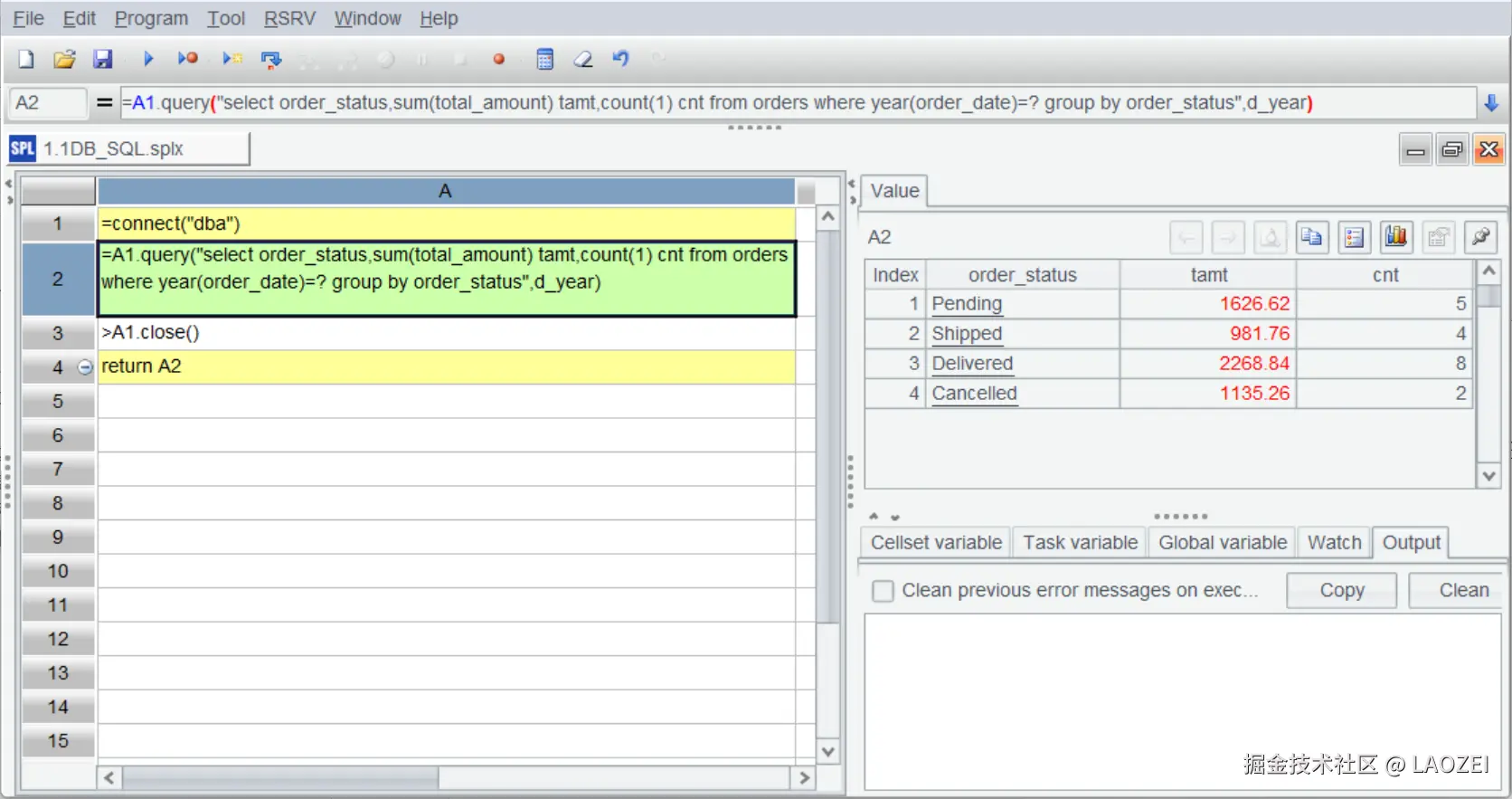
A1:连接数据库
A2:执行 SQL 查询,其中 d_year 为脚本参数
A3:关闭数据库连接
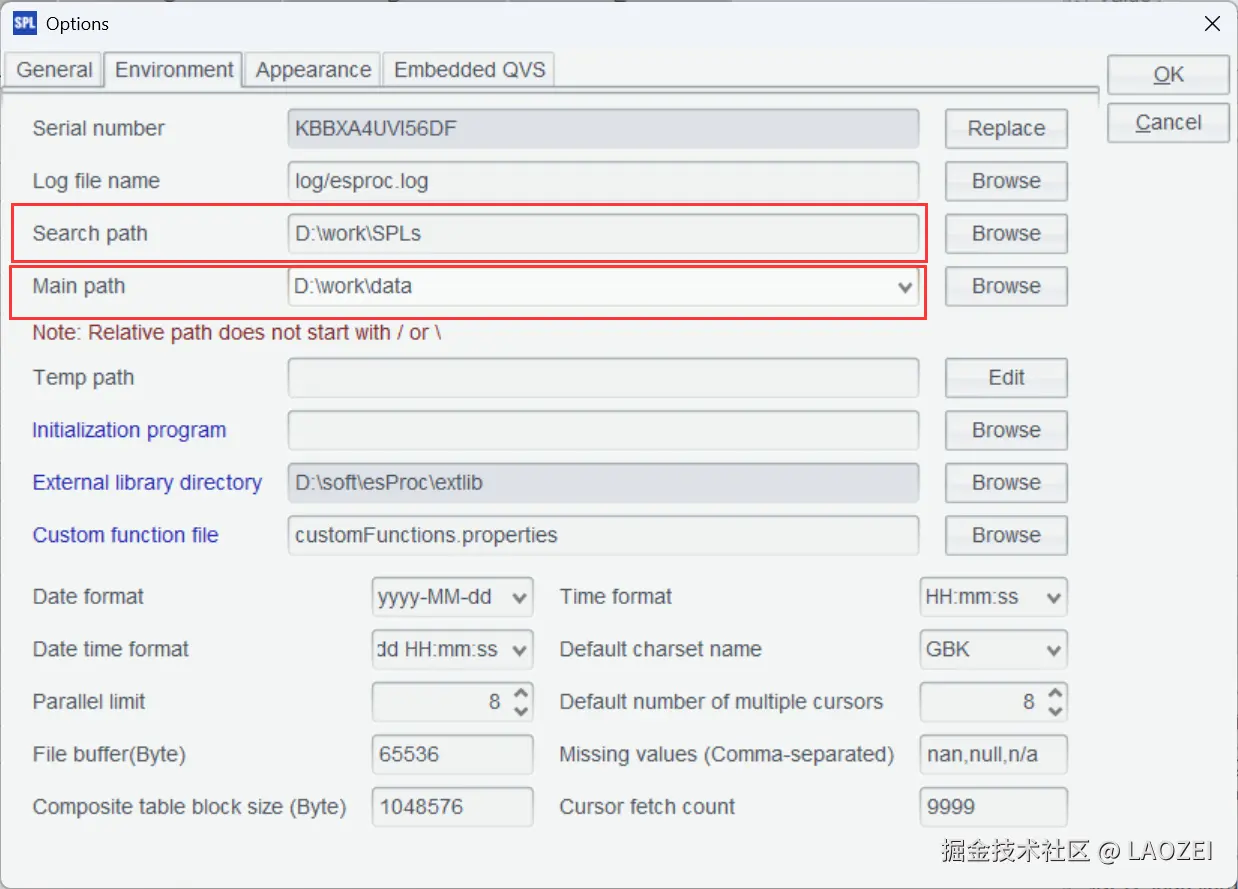
将脚本保存成 1.1DB_SQL.splx,并放置到 寻址路径(Search path)下。
执行脚本
SPL 脚本可以在 IDE 内执行(编辑调试 / 桌面分析),也可以集成到 Java 应用后调用。
IDE
IDE 内执行脚本可以直接按 ctrl+F9,或者点击工具栏的执行按钮

Java 调用
从 esProc 安装目录\esProc\lib 目录下找到 esProc JDBC 相关的 jar 包:esproc-bin-xxxx.jar、icu4j_60.3.jar。
将这两个 jar 包部署到 Java 开发环境的类路径下,同时将 数据库(如果用到)驱动包也放到应用中。再从目录 esProc 安装目录\esProc\config 下找到 esProc 配置文件 raqsoftConfig.xml,同样部署到 Java 开发环境的类路径下。
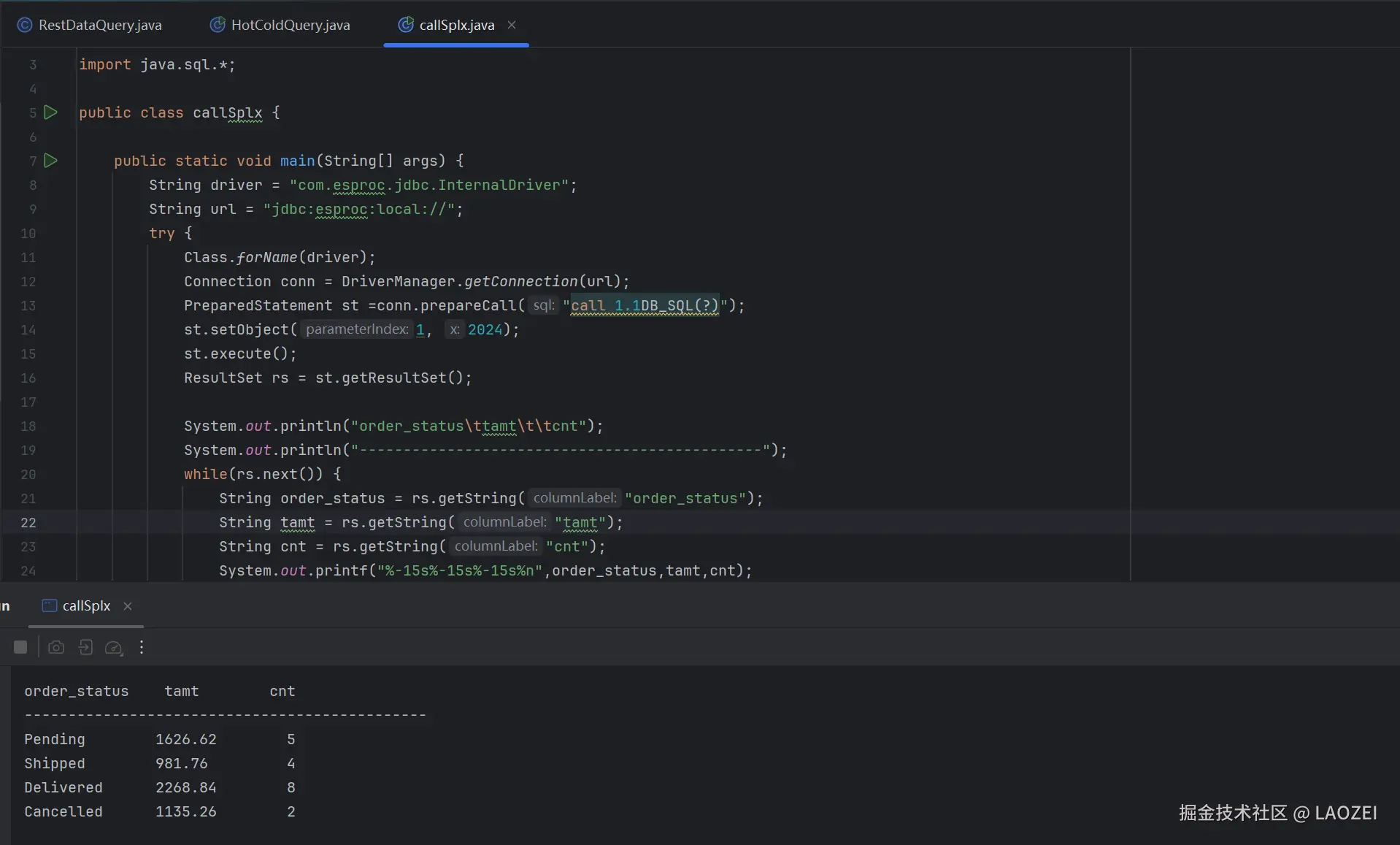
在 Java 里调用:
ini
public class callSplx {
public static void main(String[] args) {
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
PreparedStatement st =conn.prepareCall("call 1.1DB_SQL(?)");
st.setObject(1, 2024);
st.execute();
ResultSet rs = st.getResultSet();
System.out.println("order_status\ttamt\t\tcnt");
System.out.println("----------------------------------------------");
while(rs.next()) {
String order_status = rs.getString("order_status");
String tamt = rs.getString("tamt");
String cnt = rs.getString("cnt");
System.out.printf("%-15s%-15s%-15s%n",order_status,tamt,cnt);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}其中的 call 1.1DB_SQL(?) 就是调用前面保存的 1.1DB_SQL.splx 脚本。
SQL 与 SPL 混合使用
有些复杂计算用 SQL 直接来写比较困难,这时就可以借助 SPL 语法再加工数据。还是以上面的计算为例,我们用 SPL 完成取数后的分组汇总计算。
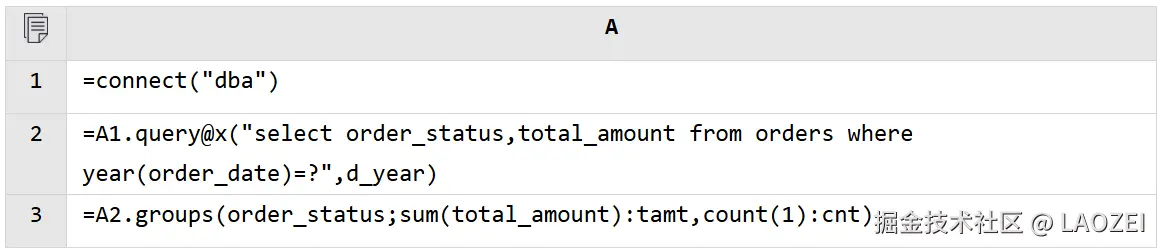
A2:执行 SQL 查询符合条件的明细数据,@x 选项代表查询完成后关闭数据库连接,这样就需要 db.close() 显示关闭连接了。
A3:用 SPL 语法进行分组汇总。
这里 A2 的 SQL 返回的是过滤后的数据,在实际应用时,应该尽量减少数据传输以避免 IO 瓶颈,所以对于数据密集型任务使用 SQL 查询数据时最好先执行一些基本运算(如过滤 / 分组)将数据量降下来。
了解了 SPL 的基本使用,以及如何基于 RDB 查询数据以后,再读取其他数据源就比较容易了。