C语言
内容提要
- 运算符
- 位运算
- 流程控制
- 算法
- 程序的三种结构
- C语句
- 数据的输入与输出
运算符
位运算
<<:左移,按位左移
说明:原操作数所有的二进制位数向左整体移动指定位。(小端模式下:高舍低补)
无符号左移
-
语法:
c操作数 << 移动位数 -
举例:
cunsigned char a = 3 << 3; // 24 将3左移3位,可以套用公式: 3 * 2 ^ 3 unsigned int b = 5 << 4; // 80 将5左移4位,可以套用公式: 5 * 2 ^ 4
有符号左移
-
语法:
c操作数 << 移动位数 -
举例:
cchar a = -3 << 3 //-24 将-3左移3位,可以套用公式: -3 * 2 ^ 3 int b = 240 << 2; //960,将240左移2位,可以套用公式: 240 * 2 ^ 2 -
注意:
- 如果符号位被覆盖或者移除高位全是1时溢出或者极端溢出时,公式不适用,其他使用都可以使用公式:a∗2na * 2 ^ na∗2n
>>:右移,按位右移
说明:原操作数所以二进制位数据整体向右移动指定位,移除的数据舍弃(高补低舍)
如果操作数时无符号数:左边用0补齐
如果操作数是有符号数:左边用什么补全,取决于计算机系统
- 逻辑右移:用0补全
- 算数右移:由符号位决定补什么,符号位是1,就用1来补全,如果符号位是0,就用0来补全
大部分情况下,系统都遵循=="算数右移"==;
无符号右移
- 语法:
c
操作数 >> 移动位数- 举例:
c
unsigned char a = 3 >> 3; //0有符号右移
- 语法:
c
操作数 >> 移动位数- 举例:
c
unsigned char a = -3 >> 3; //-1关于移位运算过程:
原数据 → 二进制原码 → 二进制反码 → 二进制补码 → 移位运算 → 二进制反码 → 二进制原码 → 特定进制数据
流程控制
算法
著名计算机科学家沃斯提出了一个公式:
c
程序 = 数据结构 + 算法- 数据结构:对数据的描述
- 算法:对操作步骤的描述
算法的定义
广义的来说,为解决一个问题而采取的方法和有限的步骤,就称为"算法"
例如:
将大象放入冰箱的算法就可以如下描述:
打开冰箱门 → 把大象装进去 → 关闭冰箱门
算法特征
- 有穷性:包含有限的操作步骤,不能无限制的执行下去。
- 可行性:算法中每一天指令必须是切实可执行的。
- **确定性:**算法中每一条指令必须有确切的含义,不能产生歧义。
算法描述-流程图
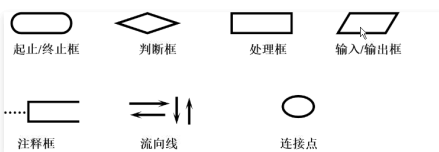
案例
-
要求:对于计算 s=1+2+3+4+5+6+7+8+9+10(累加求和)
-
用流程图表示:
程序的三种基本结构(重点)
程序的三种基本结构包括:顺序结构、分支结构(条件结构、选择结构)、循环结构(重复结构)
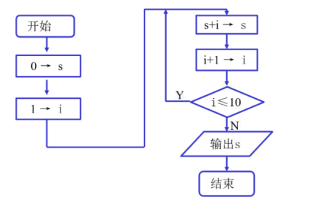
顺序结构
特点:各操作是按先后顺序执行的,是最简单的一种结构,这个结构是程序默认的。
其中A和B两个框是顺序执行的。也就是在A框所指定的操作后,必然接着执行B框所指定的操作。
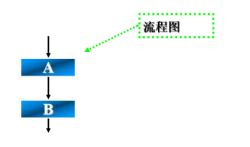
分支结构
**特点:**根据是否满足给定的条件而从一组、两组、或者多组操作中选择一种进行执行。
- 如果P条件成立,就执行A操作,否则跳过这个结构
- 无论会不会执行A操作,分支都会结束
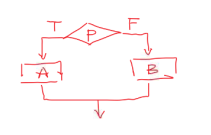
- 无论P条件是否成立,A操作或者B操作中总有一个会执行。
- 无论执行完哪一个分支,分支都会结束
分支结构又分为:
① 单分支
② 双分支
③ 多分支
循环结构
**特点:**在满足一定条件下,反复执行某一部分操作,有两种类型:
当型循环
图示:
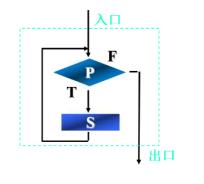
执行过程:
当给定条件P成立时,执行S操作,然后再判断P条件是否成立,如果仍然成立,再执行S操作,然后再判断...,如此反复,直到某一次P条件不成立为止,此时不再执行S,结束循环。
特点:
先判断,后执行,循环体(S)有可能一次都不执行。
代表:
while、for
直到型循环
图示:
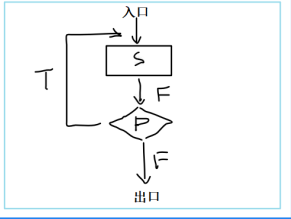
执行过程:
执行S操作,然后判断条件P是否成立,如果成立,再执行S操作,然后再判断,......,如此反复,直到某一次P条件不成立不再执行S,结束循环。
特点:先执行,后判断,循环体(S)最少执行一次。
代表:
do...while
C语句
定义
- C程序是以函数为基础单位的
- C语句必须依赖于函数存在
- 一个函数的执行部分是由若干条语句构成的。
- C语句都是用来完成一定的操作任务。
C程序结构
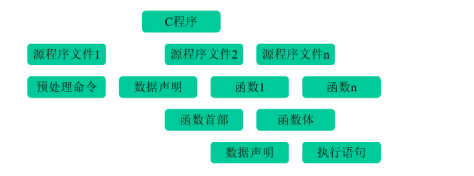
C语句分类
1、控制语句
作用:用来完成一定的控制功能
举例:
if...else...、for...、while...、do...while、continue、break、switch、return、goto
2、函数调用语句
由一个函数调用+分号组成,例如:
c
printf("这是一个函数调用语句");
test();3、表达式语句
由一个表达式+分号组成,最典型的表达式语句就是赋值语句,例如:
c
a = 3 // 表达式
score >= 90 // 表达式
score = 90; // 表达式语句4、空语句
只有一个分号,什么都不做,例如:
c
;
for(;;)5、复合语句
用{...}括起来的若干个语句,例如:
c
{
z = z +y;
t = z / 100;
printf("%f\n",t);
// 超过1条语句就是复合语句
}数据的输入与输出
数据的输入与输出是相对而言,其中:
- 从计算机向外部设备输送数据为输出(output) 。通常的输出设备包括:显示器、打印机等。
- 从外部设备项计算机输送数据为输入(input) 。通常的输入设备包括:键盘、鼠标、扫描仪等。
在C 语言中,输入与输出需要使用标准的输入输出库(stdio.h)中的输入函数(scanf())、输出函数(printf())实现,后期可以扩展其他输入输出函数。我们将这种跟硬件打交道的输入输出操作称作外设IO。
库函数已经被编译成了目标文件内置于编译系统,在链接时与编译源程序得到的目标文件相链接,生成可执行程序。
注意:在使用系统库函数的时候,需要用预处理指令 #include 将有关的头文件包含到用户资源文件中(一般放在程序的开头位置)头文件中包含了调用函数时需要的有关信息,具体的函数实现在编译的时候再去链接对应的系统库。
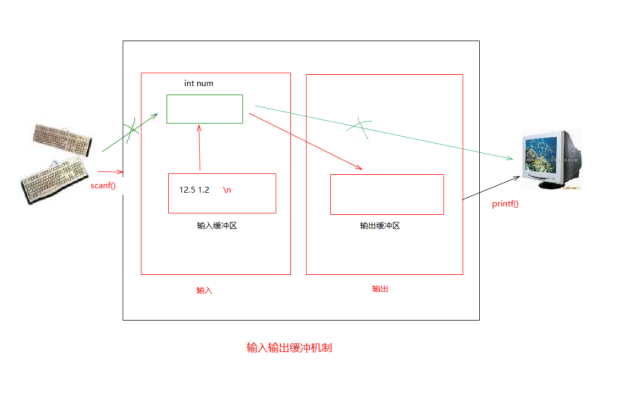
输入输出缓冲机制
缓冲区的概念
- 缓冲区(缓存)是内存空间的一部分,用于暂存输入或输出的数据。
- 在进行输入操作时,系统从外部设备(如键盘)读取数据,先放入缓冲区,程序再从缓冲区中读取数据。
输入时数据流向:外部设备 → 输入缓冲区 → 程序
- 在进行输出操作时,系统先将数据放入缓冲区,然后在特定条件下(如缓冲区满、遇到特定字符、手动刷新等)再将缓冲区中的数据输出到外部设备(如屏幕)
输出时数据流向:程序 → 输出缓冲区 → 外部设备
缓冲区的类型
C语言的缓冲区有三种类型:
**全缓冲:**当缓冲区填满后,才进行实际的输入输出操作。例如:对磁盘文件的读写。--- window全缓冲区大小是4096字节, Linux全缓冲区大小是1024字节。
行缓冲 :当在输入和输出中遇到换行符(\n或者回车)时,执行实际的输入输出操作。例如:标准输入(stdin)和标准输出(stdout)。
**无缓冲:**不进行缓冲,直接进行输入输出操作。例如:标准错误流(stderr)
缓冲区的刷新条件
缓冲区的刷新(如将缓冲区中的数据实际输出到外部设备)通常发生在以下情况:
-
**缓冲区满:**当缓冲区写满时,会自动刷新。
-
**遇到特定字符:**如换行符(\n)等。
-
**手动刷新:**使用fflush(stdout)函数手动刷新输出缓冲区。
-
**程序关闭时:**当程序结束时,缓冲区中的数据会被刷新。
缓冲区的实际应用
-
**提高效率:**通过缓冲区,可以减少与外部设备的交互次数,提高数据传输的效率
-
**处理输入输出:**例如:使用scanf和printf函数时,数据先被放入缓冲区,然后按照特定的规则从缓冲区读取或输出。
原理实现
简单的输入与输出
用printf函数输出数据
基础用法
语法:
c
printf("格式控制",输出列表);引入文件:
c
#include <stdio.h>举例:
c
printf("i=%d,x=%d,y=%d\n",i,34,i+1);注意:格式控制中的格式化符号(%d)要和输出的数据一一对应。
参数:
- ==格式控制:==用一对英文双引号括起来,包括两种信息:
- 格式说明:
- 由
%和特定字符组成,如:%d,%f,%c等,这是格式说明符,用于说明输出项目所采用的格式。 - 普通字符:作为说明性文字、符号等,按照输入原样输出。
- ==输出列表:==输出列表中的各项目指出了所要输出的内容。可以是常量(字面量、符号常量、const修饰的变量)、变量、表达式。输出列表的个数,由格式控制中的格式化符号来决定。
基本的格式化符
%d 按有符号十进制整型(int)数据的实际长度输出。(十进制(0)、八进制
(00)、十六进制(0x00))
%u 按无符号十进制整型(int)数据的实际长度输出。
%c 仅输出一个字符(char)
%s 输出结果是字符串,举例:printf("%s\n","CHINA");,输出结果:CHINA
%f 以小数形式输出 float 类型实数;
%lf 以小数形式输出 double 类型(双精度)实数
%e 也可以写作%E,以指数形式输出一个实数(涵单双精度)。小数点前1位非0数字,并输出6位小数。
%hd 短整型(short int/short)
%hhd 字符型的ASCII码,char数据对应的ASCII码的值,举例:char a 'A';printf("%hhd\n",a);,输出结果:65
%ld 长整型(long int/long)
%lld 长长整型(long long int/long long)
%x 十六进制,但是十六进制的前缀0x不会打印出来,举例printf("%x\n",198);,输出结果:c6
%#x 十六进制,并且十六进制的前缀0x也会打印出来,举例printf("%#x\n",198);,输出结果:0xc6
%o 八进制,前缀0不会打印出来,举例:5
%#o 八进制,并且八进制的前缀0也会打印出来,举例:05
%p 打印内存的地址
%% 输出%本身
案例:
c
/*************************************************************************
> File Name: demo01.c
> Author: 朱旭博
> Description:
> Created Time: 2025年07月11日 星期五 15时28分40秒
************************************************************************/
#include <stdio.h>
int main(int argc,char *argv[])
{
printf("%x,%#x\n",255,255);//输出16进制整数
printf("%o,%#o\n",255,255);//输出8进制
printf("%d,%u,%c\n",5,5,'%');//正常输出
printf("%%\n");//输出%
printf("%f,%lf,%e\n",99.12345,99.12345,99.12345);//输出小数
return 0;
}运行结果:

用scanf输入数据
基础用法
语法:
c
scanf("格式控制", 地址列表);注意:地址列表不能传变量、常量、表达式。只能传与之对应的内存地址(首地址),如果是普通变量,通过& + b变量名获取变量地址。
举例:
c
int a = 10; // 定义了一个变量a
scanf("%d",&a);// &在这里称作 取地址符,&a的意思是获取变量a对应的内存地址
(首地址)作用:
将从键盘输入的数据存入内存中所占的存储单元里,存储单元有地址标识。
参数:
- 格式控制:含义等同于printf函数的格式控制,说明输入的数据应该使用的格式。
- 地址列表:
- :是由若干个地址组成,可以是变量的地址或者字符串的地址。&是取地址符号,用于取出变量的地址。与格式化输出一样,在格式控制中,用于说明数据格式的格式说明符以%开头,后面紧跟具体的格式。
案例:
- 需求:从键盘输入整数给变量a,b,c赋值
- 代码:
c
/*************************************************************************
> File Name: demo02.c
> Author: 朱旭博
> Description:
> Created Time: 2025年07月11日 星期五 15时48分53秒
************************************************************************/
#include <stdio.h>
int main(int argc,char *argv[])
{
//定义三个变量a,b,c,用来接收控制台的输入
int a,b,c;//因为我们需要通过接收控制台输入进行赋值,所以无需初始化
//每次在使用键盘录入前加上提示信息
printf("请输入3个整数:\n");
scanf("%d%d%d",&a,&b,&c);
//测试输出
printf("a=%d,b=%d,c=%d\n",a,b,c);
return 0;
}运行结果:
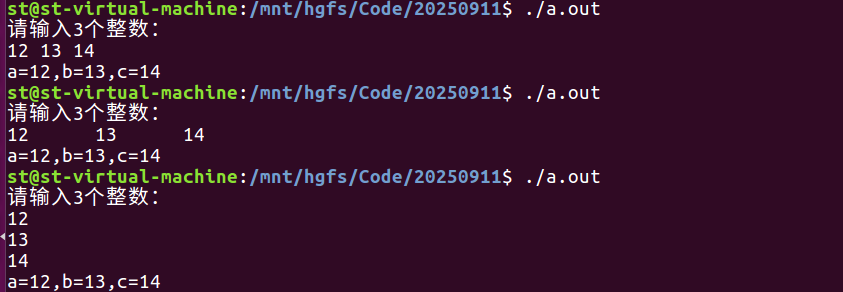
总结:输入多个数据的时候可以用空格、 Tab键、回车键中的任意一种。
说明:
- scanf函数中的"格式控制"后面应当是变量的地址,由取地址符&和变量名共同组成,举例:
c
scanf("%f%d", &a, &b);- 如果"格式控制"中除了格式说明以外还有其他字符,则在输入数据时必须在对应位置输入与之相同的字符,举例:
c
scanf("%d,%d",&a, &b);从键盘录入数据的时候,使用格式控制中的逗号分隔: 3,4
c
scanf("%d-%d-%d",&year, &month, &day);从键盘录入数据的时候,使用格式控制中的短横线分隔: 2025-7-11
c
scanf("%d年%d月%d日",&year, &month, &day);从键盘录入数据的时候,使用格式控制中的年月日分隔: 2025年7月11日
- 用
%c格式输入字符时,转义符(如:\n , \t等)都作为有效字符输入,应注意:
c
scanf("%c%c%c", &a, &b, &c);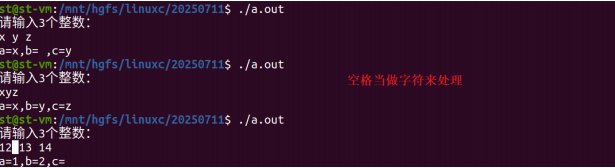
注意:其实Tab 键、空格键、回车键的响应都是当做字符处理。
- 在输入数值型数据(整型+浮点型)时,遇到空格、回车、Tab键或遇到非法输入(A,?..),则认为该输入结束;
c
scanf("%d%d%d",&a, &b, &c);- 对于
unsigned型变量所需的数据,建议用%u格式输入;若用%d(signed int),需确保输入值在int范围内(否则可能溢出)
复杂的输入与输出
按指定格式输出数据的宽度、小数位数、上下行数据按小数点对齐、用八进制、十六进制输出等。
输出格式控制
整型格式说明符
- 十进制形式(0~9)
| 说明符 | 说明 | 数据类型 |
|---|---|---|
| %d和%md | 用于基本整型 | int |
| %ld和%mld | 用于长整型 | long |
| %u和%mu | 用于无符号基本整型 | unsigned int |
| %lu和%mlu | 用于无符号长整型 | unsigned long |
- 八进制形式(0~7)
| 说明符 | 说明 | 数据类型 |
|---|---|---|
| %o和%mo | 用于基本整型 | int |
| %lo和%mlo | 用于长整型 | long |
- 十六进制形式(0~F)
| 说明符 | 说明 | 数据类型 |
|---|---|---|
| %x和%mx | 用于基本整型 | int |
| %lx和%mlx | 用于长整型 | long |
说明:
m 表示输出整型数据所占的总宽度(列数,1个字符占1列),其中:
① 当实际数据的位数不到m位时,数据前面将用空格填满, 举例:原数据( "12" ),列宽为m(4)的数据(" 12")
② 若实际数据的位数大于等于m位时,则以数据的实际位数为标准进行输出,列宽无效,举例:
原数据( "12345" ),列宽m(4)的数据( "12345" )
总结:
如果实际 数据列宽 < m,使用空格补齐m。
如果实际 数据列宽 >=m,输出实际数据,m失效。
一个int型整数也可以用%u输出,反之一个unsigned型整数也可以用%d、%o、%x格式输出。按相互赋值的规则处理
举例:
c
#include <stdio.h>
int main(int argc,char *argv[])
{
printf("%d\n",12); // "12" 输出后,实际列宽是2
printf("%6d\n",12); // " 12" 输出后,实际列宽是6,右对齐,左边使用空格填充
printf("%-6d\n",12); // "12 " 输出后,实际列宽是6,左对齐,右边使用空格填充
printf("%6d\n",1234567); // "1234567" 输出后,实际列宽是7,一旦实际列宽超过指定列宽,就按实际列宽输出
printf("%06d\n",12); // "000012" 输出后,实际列宽是6,右对齐,左边使用0填充
printf("%+d,%+d\n",12,-12); // "+12,-12" 输出后,显示正负号
printf("%#06x,%#06o\n",12,12);// "0x000c,000014" 输出后,实际列宽是6
return 0;
}
字符型格式说明符
- 字符型
| 说明符 | 说明 | 举例 |
|---|---|---|
| %c或者%mc | 输出的字符占m列 | printf("%3c\n",'a'); |
用法和整型的用法一致。
- 字符串型
在C语言中,支持字符串常量,不支持字符串变量。
| 说明符 | 说明 |
|---|---|
| %ms | 输出的字符串占m列。若串长>=m,全部输出;反之在串前补空格(m为正往前补空格) 举例:printf("%6s\n","hello"); " hello" |
| %-ms | 输出的字符串占m列。若串长>=m,全部输出;反之在串后补空格(m为负往后补空格) 举例: printf("%-6s\n","hello"); "hello" |
| %m.ns | 输出的字符串占m列,取字符串前 n 个字符,再按 m 列补空格。 举例: printf("%6.2s\n","hello"); " he"(先截取,在补全) |
| %- | 输出的字符串占m列。只取字符串前n个字符,不足部分串后补空格。举例: printf("%-6.2s\n","hello"); "he " |
案例:
- 需求:字符串输出
- 代码:
c
#include <stdio.h>
int main(int argc,char *argv[])
{
printf("%3s\n%7.2s\n%-5.3s\n%.4s\n","CHINA","CHINA","CHINA","CHINA");
// %3s: "CHINA" 超出指定列宽,按实际列宽输出
// %7.2s: " CH" 截取CH,实际列宽补足到7,右对齐
// %-5.3s: "CHI " 截取 CHI,实际列宽补足到5,左对齐
// %.4s: "CHIN" 截取CHIN,实际列宽就是默认列宽4
return 0;
}- 运行结果:

浮点型格式说明符
浮点型格式分为三种形式:
| 序号 | 名称 | 说明 |
|---|---|---|
| 1 | 十进制形式 | %m.nf或者%-m.nf,m是列宽,n是保留的小数位 |
| 2 | 指数形式 | %m.ne或者%-m.ne,m是列宽,n是保留的尾数位 |
| 3 | %g或者%G | 根据数值的大小,自动选择%f或者%e中宽度较短的一种格式,不输出无意义的0 |
解释:
在输出浮点型数据时,格式说明符中的m表示整个数据所占的列宽,n表示小数点后面所占的位数(保留的小数位)
如果在小数点后取n位后,所规定的数据宽度m不够输出数据前面的整数部分(包括小数点),则按实际的位数进行输出。
案例:
- 需求:输出浮点型数时,指定小数位。
- 案例:
c
#include <stdio.h>
int main(int argc,char *argv[])
{
float f = 123.456f; // f是标识,不计入列宽的,实际列宽是7
printf("%8.2f\n%-8.2f\n%8.6f\n%9.2e\n%g\n%G\n",f,f,f,f,f,f);
// %8.2f: " 123.46" 小数位保存采取"四舍五入" 小数保留2位,实际列宽补足到8,右对齐
// %-8.2f: "123.46 " 左对齐
// %8.6f: "123.456001" 实际列宽超过指定列宽,以实际列宽为准
// %9.2e: " 1.23e+02" 首先,小数转换为指数;接着,处理尾数,这里的.2是尾数位;最后补足列宽。
return 0;
}- 运行结果:

注意:这里的小数位的保留采用四舍五入