目录
[1. 简单的条形图](#1. 简单的条形图)
(1)堆积图,对Improved进行堆积,注意position="stack"
(2)分组图,对Improved进行分组,注意position="dodge":
(3)填充条形图,对Improved进行填充,注意position="fill":
一、前言
ggplot2 是一个基于 R 语言的数据可视化包,提供了一种结构化的方法来描述和构建图表,因此被广泛用于制作可视化图表。其是tidyverse数据科学生态系统的一部分。
在 ggplot2 中,每一个图形都是从数据映射到美学属性(如颜色、形状和大小)、加上几何对象(如点、线和条形图)、统计变换和坐标系等元素组合而成。这种分层和模块化的方法使得用户可以灵活地创建复杂的图表,同时保持代码的可读性和易用性。通过ggplot2,你可以创建各种图表:包括但不限于散点图、线图、直方图、条形图和箱线图。此外,ggplot2 提供了广泛的自定义选项,允许用户调整几乎图表的每个细节,以适应具体的展示需求。
简而言之,ggplot2 是 R 语言中一个功能强大且灵活的数据可视化工具。因此,本文主要学习如何在R语言中通过ggplot2来绘制条形图、堆积图、饼图、直方图、核密度图、箱图、小提琴图。
二、条形图
以 vcd 包中的Arthritis数据框为例:
R
install.packages("vcd")
library(vcd)
library(grid)
data_frame <- package_name::data_frame_name
Arthritis <- vcd::Arthritis
Arthritis输出如下:
R
ID Treatment Sex Age Improved
1 57 Treated Male 27 Some
2 46 Treated Male 29 None
3 77 Treated Male 30 None
4 17 Treated Male 32 Marked
5 36 Treated Male 46 Marked
6 23 Treated Male 58 Marked
7 75 Treated Male 59 None
8 39 Treated Male 59 Marked
9 33 Treated Male 63 None
10 55 Treated Male 63 None
11 30 Treated Male 64 None
12 5 Treated Male 64 Some
13 63 Treated Male 69 None
14 83 Treated Male 70 Marked
15 66 Treated Female 23 None
16 40 Treated Female 32 None
17 6 Treated Female 37 Some
18 7 Treated Female 41 None
19 72 Treated Female 41 Marked
20 37 Treated Female 48 None
21 82 Treated Female 48 Marked
22 53 Treated Female 55 Marked
23 79 Treated Female 55 Marked
24 26 Treated Female 56 Marked
25 28 Treated Female 57 Marked
26 60 Treated Female 57 Marked
27 22 Treated Female 57 Marked
28 27 Treated Female 58 None
29 2 Treated Female 59 Marked
30 59 Treated Female 59 Marked
31 62 Treated Female 60 Marked
32 84 Treated Female 61 Marked
33 64 Treated Female 62 Some
34 34 Treated Female 62 Marked
35 58 Treated Female 66 Marked
36 13 Treated Female 67 Marked
37 61 Treated Female 68 Some
38 65 Treated Female 68 Marked
39 11 Treated Female 69 None
40 56 Treated Female 69 Some
41 43 Treated Female 70 Some
42 9 Placebo Male 37 None
43 14 Placebo Male 44 None
44 73 Placebo Male 50 None
45 74 Placebo Male 51 None
46 25 Placebo Male 52 None
47 18 Placebo Male 53 None
48 21 Placebo Male 59 None
49 52 Placebo Male 59 None
50 45 Placebo Male 62 None
51 41 Placebo Male 62 None
52 8 Placebo Male 63 Marked
53 80 Placebo Female 23 None
54 12 Placebo Female 30 None
55 29 Placebo Female 30 None
56 50 Placebo Female 31 Some
57 38 Placebo Female 32 None
58 35 Placebo Female 33 Marked
59 51 Placebo Female 37 None
60 54 Placebo Female 44 None
61 76 Placebo Female 45 None
62 16 Placebo Female 46 None
63 69 Placebo Female 48 None
64 31 Placebo Female 49 None
65 20 Placebo Female 51 None
66 68 Placebo Female 53 None
67 81 Placebo Female 54 None
68 4 Placebo Female 54 None
69 78 Placebo Female 54 Marked
70 70 Placebo Female 55 Marked
71 49 Placebo Female 57 None
72 10 Placebo Female 57 Some
73 47 Placebo Female 58 Some
74 44 Placebo Female 59 Some
75 24 Placebo Female 59 Marked
76 48 Placebo Female 61 None
77 19 Placebo Female 63 Some
78 3 Placebo Female 64 None
79 67 Placebo Female 65 Marked
80 32 Placebo Female 66 None
81 42 Placebo Female 66 None
82 15 Placebo Female 66 Some
83 71 Placebo Female 68 Some
84 1 Placebo Female 74 Marked1.简单的条形图
在该数据框中,变量improved记录了对每位接受了安慰剂或药物的病人的治疗效果:
R
table(Arthritis$Improved)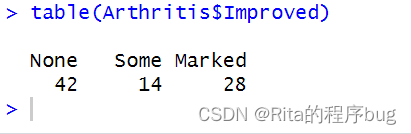
**table()**函数用于创建频数表(频率表)或列联表,它可以统计向量中每个元素的出现次数。
对Improved变量作简单的条形图:
R
library(ggplot2)
ggplot(Arthritis,aes(x=Improved))+geom_bar()+
labs(title = "Simple Bar chart",x="Improved",y="Frequency")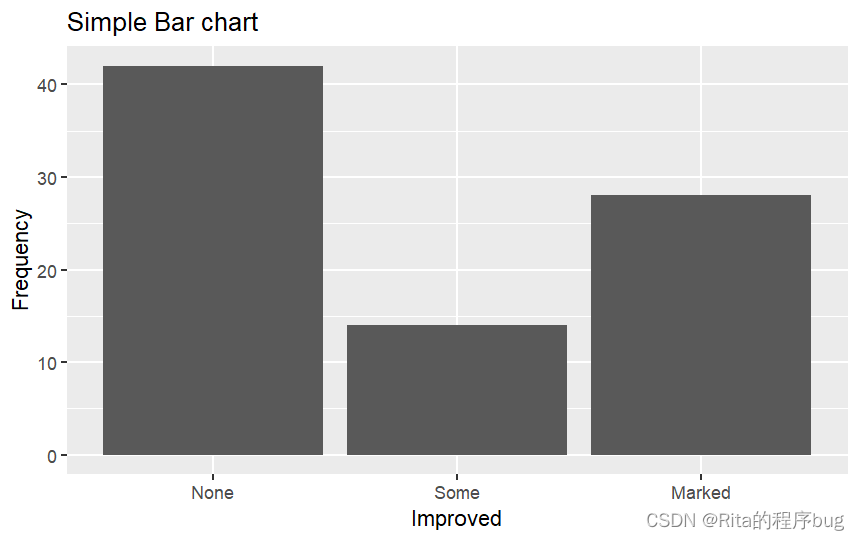
将上面的变量图修改为横着的,利用函数**coord_flip()**可以在绘制图形时交换x轴和y轴的方向,从而实现图形的翻转(全称coordinate Flip就是坐标翻转的意思):
R
library(ggplot2)
ggplot(Arthritis,aes(x=Improved))+geom_bar()+
labs(title = "Horizontal Bar chart",x="Improved",y="Frequency")+
coord_flip()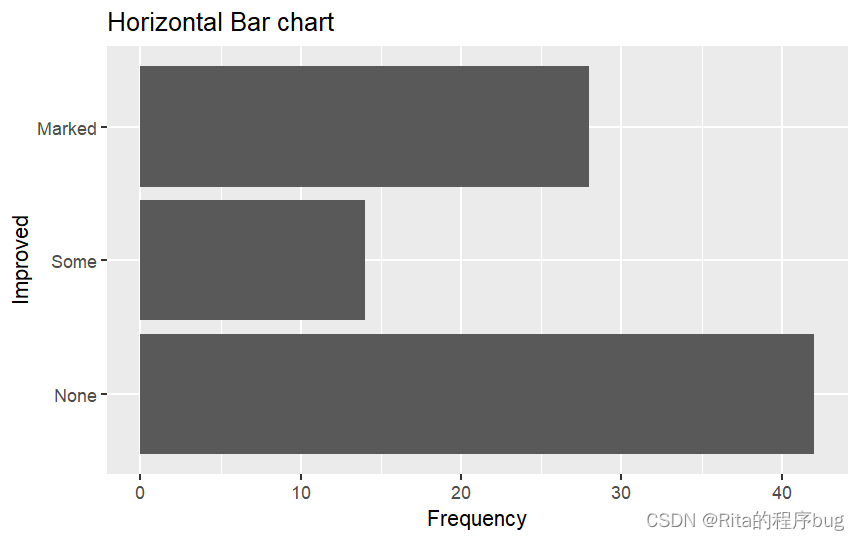
2.堆积、分组和填充条形图(柱状图)
例子:比较分别接受了安慰剂(Placebo)或药物(Treated)的病人的治疗效果

(1)堆积图,对Improved进行堆积,注意position="stack"
R
library(ggplot2)
ggplot(Arthritis,aes(x=Treatment,fill=Improved))+
geom_bar(position = "stack")+
labs(title="Stacked Bar chart",
x="Treament",y="Frequency")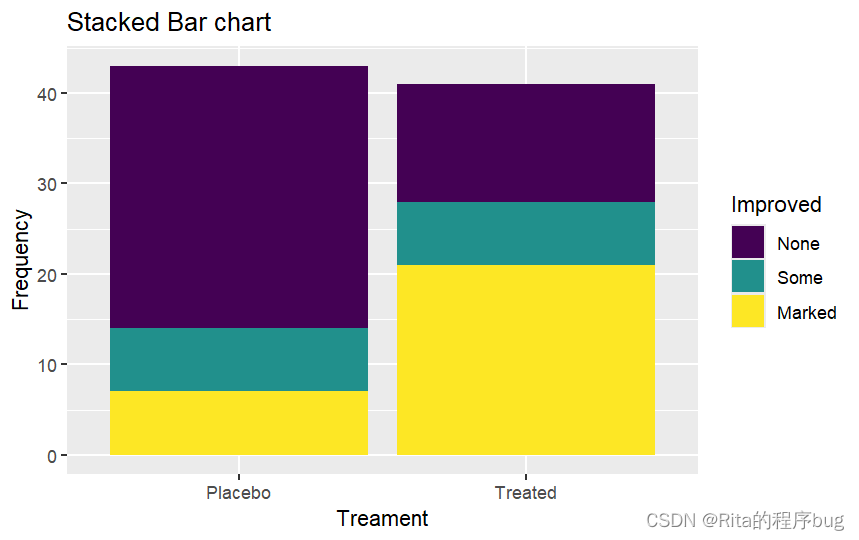
(2)分组图,对Improved进行分组,注意position="dodge":
R
library(ggplot2)
ggplot(Arthritis,aes(x=Treatment,fill=Improved))+
geom_bar(position = "dodge")+
labs(title="Grouped Bar chart",
x="Treament",y="Frequency")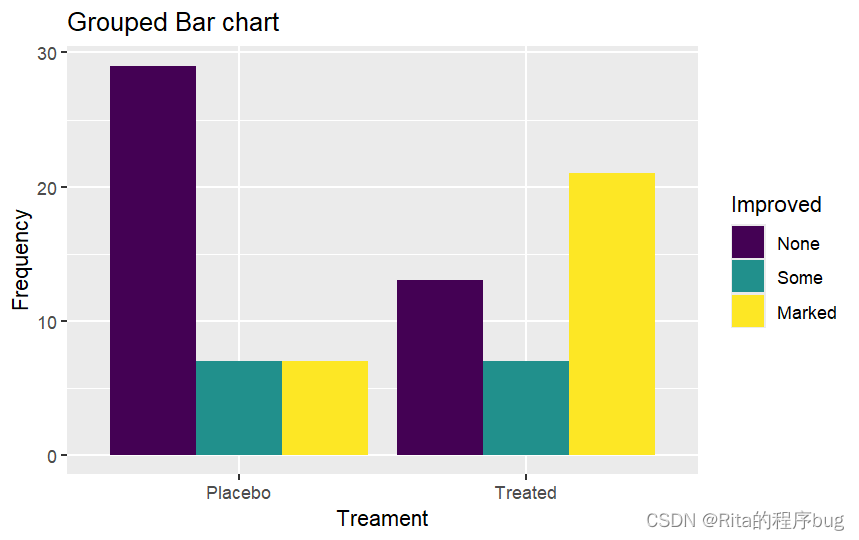
(3)填充条形图,对Improved进行填充,注意position="fill":
R
library(ggplot2)
ggplot(Arthritis,aes(x=Treatment,fill=Improved))+
geom_bar(position = "fill")+
labs(title="Filled Bar chart",
x="Treament",y="Frequency")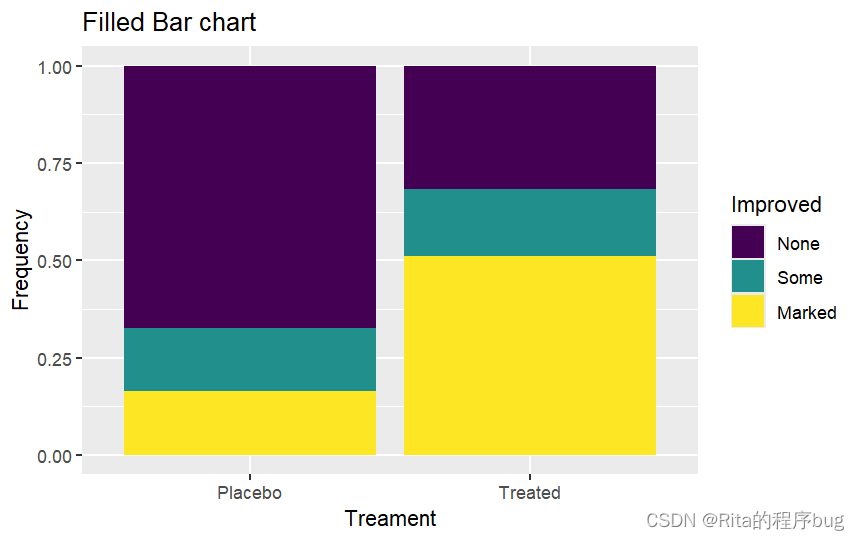
(4)关于position的设置可以分为以下4种:
1)position="stack"(默认值):将柱子堆叠在一起,形成堆叠柱状图。
2)position="fill":将每个柱子的高度归一化为1,使得每个柱子的面积代表相对比例。这样可以更好地比较不同类别之间的相对频率或比例。
3)position="dodge":将柱子并排显示,以显示不同类别之间的直接比较。每个类别的柱子宽度保持不变。
4)position="identity"(用的少):不对柱子进行任何位置调整,直接使用数据中的数值作为柱子的位置。这通常用于自定义柱状图的位置布局。
3.均值条形图
(1)举例
用R自带数据集state.x77来绘制1970年美国各地区的平均文盲率,数据集state.region具有每个州所属的地区名,看一下state.x77和state.region数据集:
R
head(state.x77)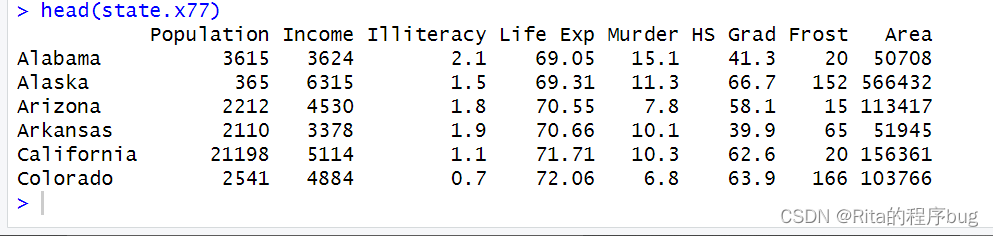
R
state.region
(2)计算不同地区的平均文盲率:
R
states <- data.frame(state.region,state.x77)
library(dplyr)
plotdata <- states %>%
group_by(state.region)%>%
summarize(mean=mean(Illiteracy))
plotdata
(3)作图
R
library(ggplot2)
ggplot(plotdata,aes(x=reorder(state.region,mean),y=mean))+
geom_bar(stat = "identity")+
labs(x="region",
y="mean",
title = "Mean Illiteracy Rate")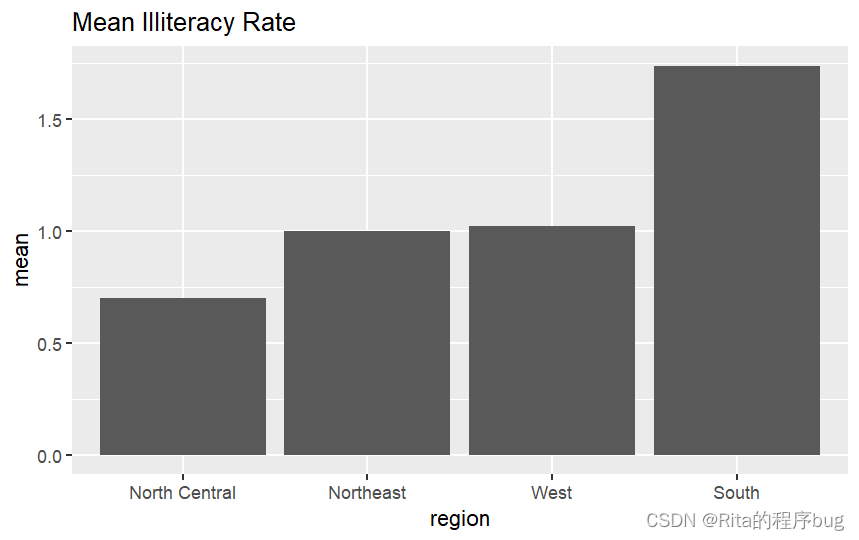
注意:
1)reorder()函数用于对因子(factor)变量进行重新排序,以便根据另一个变量的值对其进行排序。它通常与aes()函数结合使用,用于设置绘图的变量映射:
reorder(variable, by_variable, FUN = NULL)variable:是要重新排序的因子变量。被排序者
by_variable是用于排序的参考变量,可以是任何数值型变量或表达式。按什么排序
FUN是一个可选的函数,用于对by_variable进行聚合。默认情况下,它不进行聚合,而是直接使用by_variable的值进行排序。
2)stat = "identity"表示不进行任何统计变换,直接使用原始数据进行绘图。stat还可以设置为:
stat="count":默认选项,根据每个类别的频数(计数)创建柱状图。这是geom_bar的默认统计变换,它会自动对数据进行计数,并使用计数值作为柱子的高度。
stat="bin":将连续变量进行离散化分组,并显示每个分组的频数。这通常用于创建直方图,将连续变量分成多个离散的区间,并显示每个区间中观测值的频数。
stat="density":根据密度估计函数,计算每个类别的密度曲线。这适用于连续变量的柱状图,其中柱子的高度表示密度而不是频数。
stat="summary":根据指定的摘要函数,计算每个类别的摘要统计量,例如均值、中位数等。这对于创建带有摘要统计信息的柱状图很有用。
stat="bin2d":用于创建二维直方图,将两个连续变量分成多个二维的离散区间,并显示每个区间中观测值的频数。
(4)带误差线的条形图
求SEM=SD/sqrt(n) ,这里用**n=n()**来计算每组组内观测值的数量:
R
states <- data.frame(state.region,state.x77)
library(dplyr)
plotdata1<- states %>%
group_by(state.region)%>%
summarize(n=n(),
mean=mean(Illiteracy),
SEM=sd(Illiteracy)/sqrt(n))
plotdata1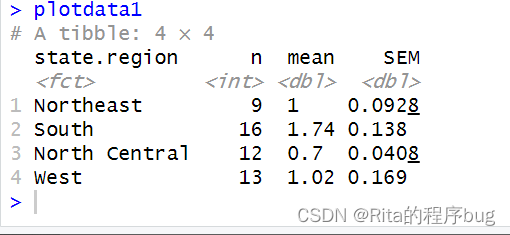
作图(带误差线)用函数geom_errorbar(),并用ymin和ymax设置误差线的上下限:
R
library(ggplot2)
ggplot(plotdata1,aes(x=reorder(state.region,mean),y=mean))+
geom_bar(stat = "identity",fill="skyblue")+
geom_errorbar(aes(ymin=mean-SEM,ymax=mean+SEM),width=0.2)+
labs(x="region",
y="mean",
title = "Mean Illiteracy Rate",
subtitle = "with standard error bars")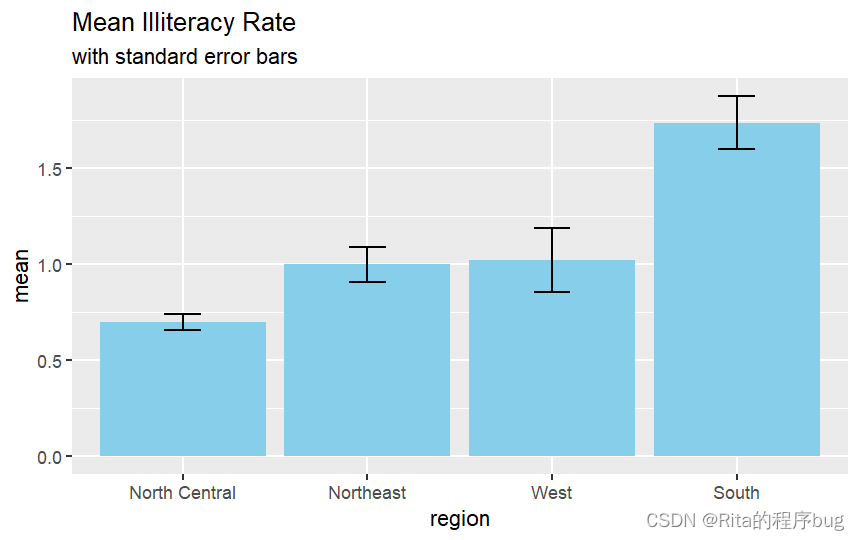
4.条形图的微调
(1)颜色
在geom_bar中,fill="color"指定区域颜色,color="color"指定边框颜色。
前面对所有组添加的是同样的颜色,也可以利用scale_fill_manual(values=c("color1","color2","color3",...))来手动设定不同组为不同的颜色,例如:
R
library(ggplot2)
ggplot(Arthritis,aes(x=Treatment,fill=Improved))+
geom_bar(position = "stack",color="black")+
scale_fill_manual(values = c("blue","red","skyblue"))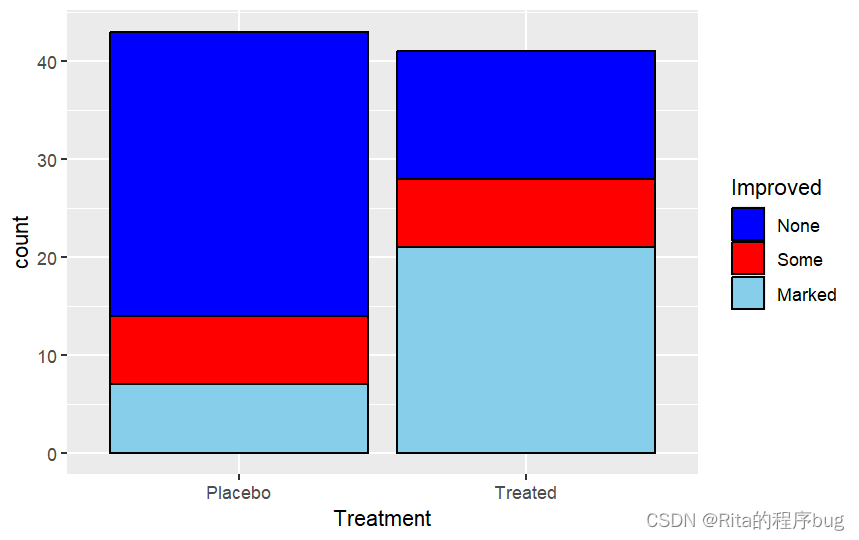
R
labs(title="Stacked Bar chart",
x="Treament",y="Frequency")
(2)条形图的标签
直接来看例子:
R
ggplot(mpg,aes(x=model))+
geom_bar()+
labs(title = "Car",y="Frequency",x="")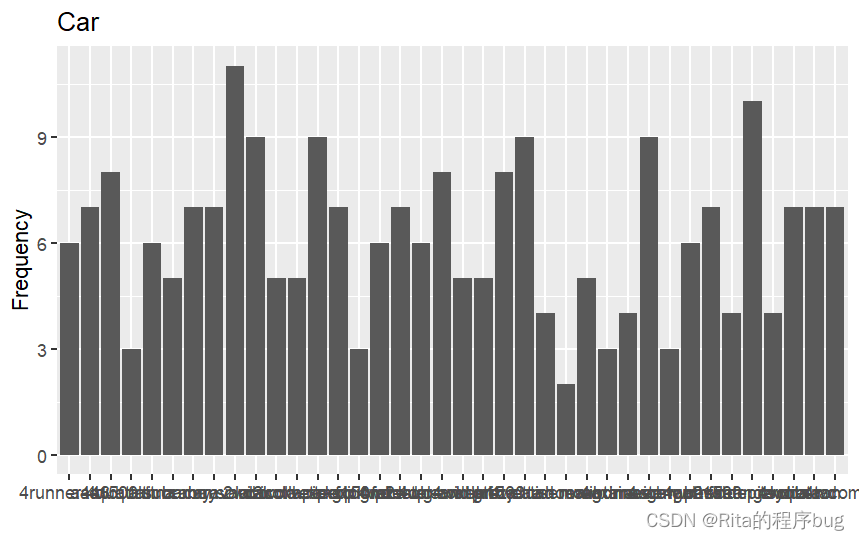
很显然,x轴的标签全部挤在一起,根本没法看,可以选择转换横纵坐标或者缩小x轴标签的字号并对其旋转一定角度。
1)旋转
ggplot(mpg,aes(x=model))+
geom_bar()+
labs(title = "Car",y="Frequency",x="")+
coord_flip()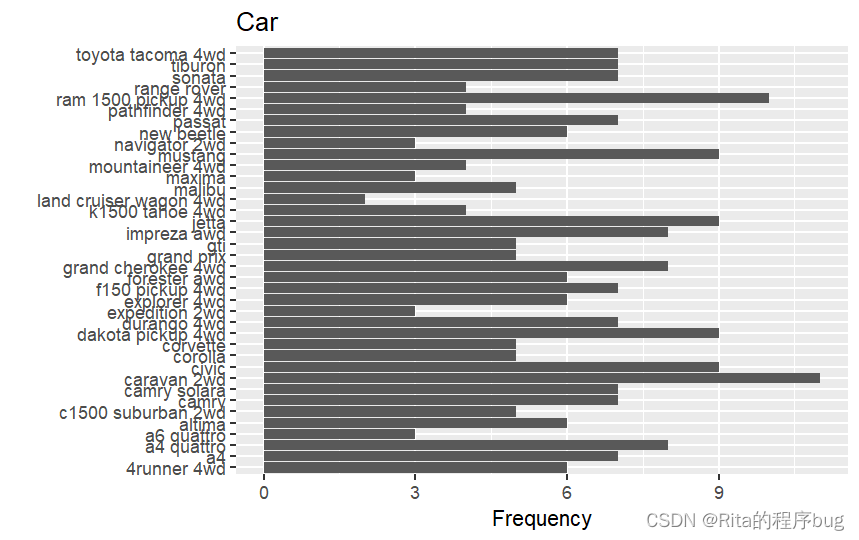
2)修改坐标轴的字体字号和旋转角度
R
ggplot(mpg,aes(x=model))+
geom_bar()+
labs(title = "Car",y="Frequency",x="")+
theme(axis.text.x = element_text(angle = 45,hjust = 1,size = 8))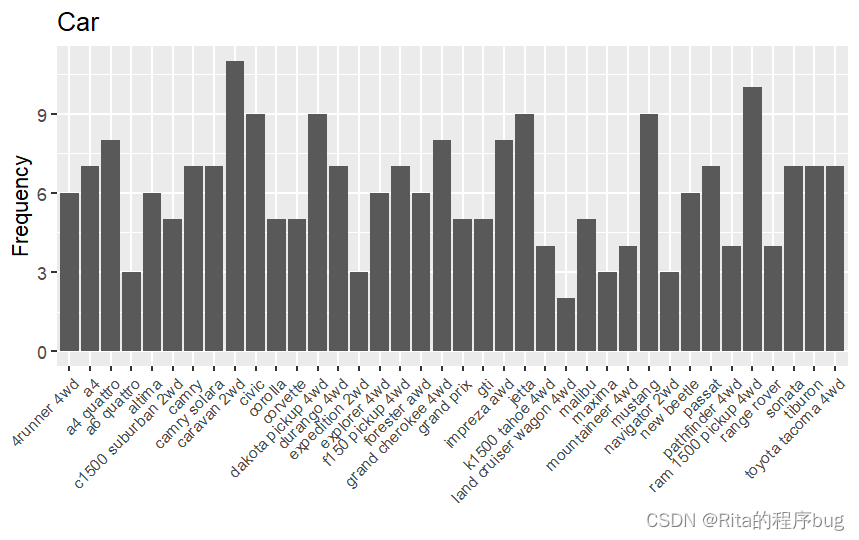
这里的theme()函数:
axis.text.x: 这指定我们正在自定义绘图中的x轴文本。
element_text(): 这是用于自定义绘图中文本元素(如轴标签、标题和图例)的函数。
angle = 45: 这个参数将x轴文本标签的角度设定为45度。这意味着标签将以顺时针45度的角度旋转。
hjust = 1: horizontal justification的缩写,意为水平对齐方式。0:左对齐;0.5:居中对齐;1:右对齐。
size = 8: 这个参数将x轴文本标签的大小设定为8点。它决定了标签的字体大小。