前言
我在写《一文打通浏览器页面生命周期》来介绍浏览器页面生命周期的时候,就想细细讲解一下"从输入URL回车,到页面显示"的全过程,因篇幅问题,只好作罢,于是我在这里再续前文(注意!本文篇幅较长,但是值得大家细细品味)。
一、前置知识点
把进程和线程的基本概念搞懂,可以省去很多功夫,可以看一下我写的《前端提升必备知识:浏览器的进程与线程》。
二、过程概述
"从输入URL回车,到页面显示"这一全过程,我在讲述浏览器生命周期时粗略地称其为 "无状态" => ACTIVE状态,但是这不是很准确。如果将其详细解析,我觉得可以分为以下几个阶段:
- 导航阶段(从输入URL到获取资源)
- 输入URL并解析
- 查找缓存
- DNS查询
- 建立TCP连接(三次握手)
- 发送HTTP请求
- 处理服务器返回的响应报文
- 渲染阶段(渲染页面,超重要!!!)
- 解析并渲染页面
- 收尾工作
- 关闭TCP连接(四次挥手)
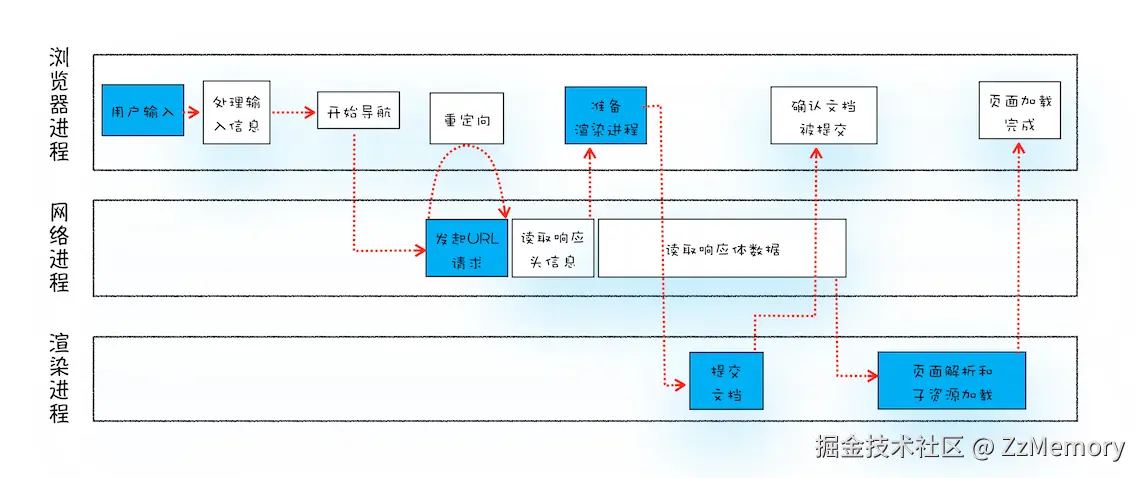
进程协作情况
上面这些工作当然不会是一个进程能做完的,而是几个进程共同完成的。它们分别是浏览器主进程、网络进程、渲染进程:
- 浏览器主进程: 负责统筹协调与资源管理,它控制应用的"Chrome"部分,包括地址栏、书签、返回和前进按钮,还处理网络浏览器的不可见特权部分,例如网络请求和文件访问。所以输入URL的地址栏归浏览器主进程管理,由它进行URL解析。
- 网络进程: 负责所有网络请求与数据获取,它专注于处理所有与网络相关的操作,从 URL 解析到数据接收的全流程均由其完成。
- 渲染进程: 负责页面解析与渲染显示,它注于将网络进程获取的 HTML、CSS、JavaScript 等资源转换为用户可见的页面。其核心作用由内部的多个线程(如渲染线程、JS 引擎线程)协同完成。 协作情况如图所示:
 (原图出自极客时间《浏览器工作原理与实践》)
(原图出自极客时间《浏览器工作原理与实践》)
三、全流程详解
(一)输入URL并解析
这部分由浏览器主进程(Browser Process)进行,因为输入URL的地址栏属于"Chrome"的部分,所以属于浏览器主进程的管辖范围。
URL规范
想要完全搞懂这部分有必要学习一下URL的规范。一般URL由以下几部分构成:
-
Scheme(协议): 规定了"如何访问资源",是
URL的访问规则,是URL必须明确的部分 。但是在浏览器的地址栏输入时,浏览器会自动帮你补全协议(默认为https://或是http://)。常见的协议有http://、https://等。 -
Userinfo(用户信息): 格式如
ftp://user:pass@ftp.example.com,用于身份验证(常见于 FTP 协议)。现代网络中几乎不用,可完全省略。 -
Host(域名/IP地址): 这是资源所在的服务器地址,我们见的最多的应该是localhost(域名),以及127.0.0.1(IP地址),这也是URL必须明确的部分。在URL中,域名和IP地址必须二者择一,否则无法找到服务器。
-
Port(端口): 格式为
:数字,端口是服务器上资源对应的服务端口,所以端口必须搭配服务器地址使用。不同协议有默认端口(如http://默认 80,https://默认 443,ftp://默认 21)。- 当我们使用默认端口时,可以省略端口,比如
http://www.baidu.com:80可简写为http://www.baidu.com - 当我们使用非默认端口,比如
Tomcat的8080端口,http://localhost:8080,这时必须写明端口。
- 当我们使用默认端口时,可以省略端口,比如
-
Path(路径): 格式为
/资源路径,路径用于定位服务器上的具体资源(如某个网页、文件),比如http://www.baidu.com/s,/s是百度搜索的核心路径,只要有它,就可以判断这是百度的搜索结果页面。 -
Query(查询参数): 格式为
?键值对,用于向服务器传递额外参数(如搜索关键词、筛选条件),比如http://www.baidu.com/s?wd=我的世界,wd是百度搜索服务的核心参数,代表"搜索关键词",?wd=我的世界就是要以"我的世界"为搜索关键词来调用搜索服务。-
注意: 有可能你搜索之后得到的页面,其URL复制过来为www.baidu.com/s?wd=%E6%88... 。很奇怪吧,
wd后接的搜索关键词为一串不知名字符串,不用感到诧异,这是"我的世界"的UTF-8格式,在URL中,特殊字符(如中文和空格)会被浏览器自动编码为UTF-8格式,服务器解码即可得到原来的明文("我的世界")。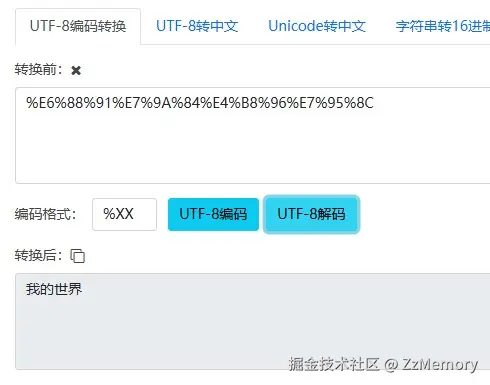
-
-
Fragment(锚点): 格式为
#锚点名称,用于定位页面内的具体位置(如网页中的某个章节),百度搜索结果页面下方的分页符代表的锚点名称为page,所以可以通过www.baidu.com/s?wd=我的世界#p... , 来定位到该搜索结果页面的分页符位置。 -
示例: 以www.baidu.com/s?wd=我的世界#p... 这个URL为例,图解说明。

用户输入后浏览器解析URL
当我们在浏览器的地址栏进行输入时,输入的内容还不能称之为"URL",充其量只是个查询关键字。当你回车之后,地址栏会对你输入的查询关键字进行判断,有以下两种判断结果:
搜索内容
你输入的内容不符合 URL 规范,地址栏会判断你输入的内容为搜索内容 ,比如输入"我的世界"。此时地址栏会直接使用浏览器默认的搜索引擎 (我使用的为"必应"),来合成新的搜索关键字的 URL 。过程为:搜索内容 => URL => 跳转URL。
-
地址栏会把你输入的"我的世界"这句话当成是你要搜索的内容,例子中最终合成的
URL为cn.bing.com/search?q=%E...,最终会跳转到这个URL以获取搜索结果。- 输入内容

- 搜索引擎将输入的搜索内容合成URL
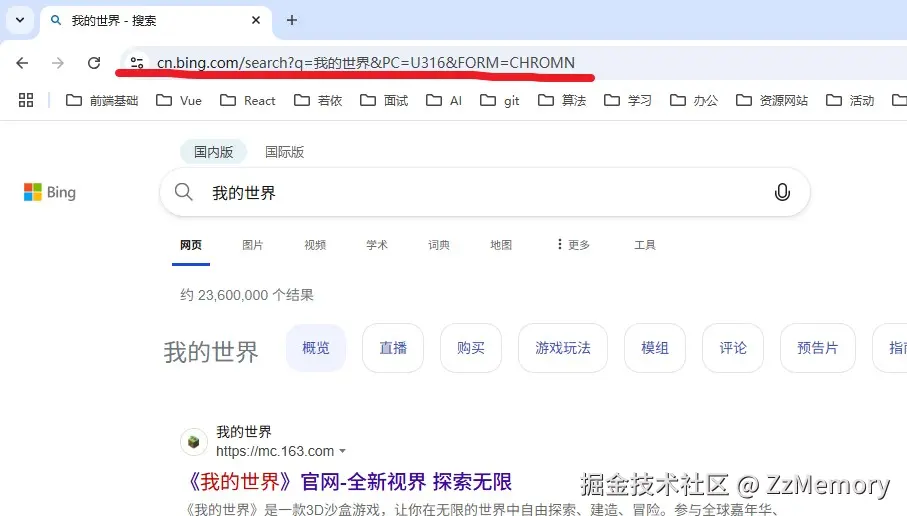
URL请求
如果你输入的内容符合 URL 规范,即为至少有主机/IP地址(浏览器会自动补全协议部分),那么地址栏就会根据 URL 规范,为输入的内容加上协议,合成为完整的 URL。
开始导航
- beforeunload事件: 在解析完成之后,导航开始之前,会先检查当前页面是否注册了
beforeunload事件。如果有,会触发该事件,目的是询问用户是否确认离开当前页面(例如当前有一个表单,离开时会提示用户 "是否保存修改")。- 只有在
beforeunload事件处理完成(用户确认离开或事件被忽略)后,浏览器才会真正卸载当前页面,加载新的 URL。 - 顺序: 输入URL并回车操作 => 浏览器解析URL(确定目标地址) => 触发beforeunload事件(当前页面即将卸载) => 卸载当前页面并加载新URL
- 只有在
- 进程间通信: 得到
URL之后,浏览器主进程将会通过进程间通信(IPC)把URL请求发送给网络进程。
(二)查找缓存
网络进程接收到浏览器主进程发送来的URL请求,会先判断当前请求的资源是否已被本地存储且有效 ,如果命中有效缓存,可直接复用资源,跳过后续的 DNS、TCP、HTTP 请求等步骤,极大减少加载时间(这就叫"前人栽树,后人乘凉")。
查找缓存顺序
优先级从高到低:Service Worker缓存 > 内存缓存 > 硬盘缓存
- Service Worker 缓存(前提是页面注册了Service Worker): 由开发者通过代码控制的 "可编程缓存",独立于浏览器默认缓存机制,属于前端可控的缓存策略。
- 应用场景: PWA(渐进式 Web 应用)中常用,可实现离线访问。例如,开发者可以指定某些资源强制缓存,即使网络断开也能加载。
- 查找逻辑: 如果页面注册了 Service Worker,浏览器会先询问 Service Worker 是否缓存了该资源,由 Service Worker 的代码决定是否返回缓存或发起网络请求。
- 内存缓存(Memory Cache): 存储在浏览器内存中,访问速度最快(微秒级),但容量有限,且关闭标签页后会被释放。
- 应用场景: 临时高频使用的资源,比如刚加载的 CSS、JS、小型图片(如 icon)等。
- 查找逻辑: 输入
URL后,浏览器会先检查内存中是否有该资源的缓存。例如,你刷新当前页面时,很多资源会直接从内存缓存中读取,因为它们刚刚被使用过。
- 磁盘缓存(Disk Cache): 存储在硬盘中,速度比内存缓存慢(毫秒级),但容量大、持久化(关闭浏览器后仍保留)。
- 应用场景: 不常变动的大型资源,比如图片(jpg/png)、视频、字体文件,以及长期复用的 CSS/JS(如第三方库)等。
- 查找逻辑:如果内存缓存未命中,浏览器会检查磁盘缓存。例如,你关闭浏览器后重新打开同一页面,很多资源会从磁盘缓存中加载。
何为"命中有效缓存"
命中:先确认 "有没有"
- "命中" 的前提是本地缓存中存在与当前请求完全匹配的资源 。这里的 "匹配" 不仅指 URL 一致,还包括请求方法(如 GET)、请求头(如
Accept、Cookie等)是否一致。 - 假设浏览器先后处理两个请求:
*- 请求
https://www.taobao.com/static/main.css(请求头中无 Cookie);
-
- 请求
https://www.taobao.com/static/main.css(请求头中带 Cookie ,比如Cookie: userId=12345; sessionId=abcdef)。
- 请求
- 这两个请求的 URL 完全相同(都是
https://www.taobao.com/static/main.css),但浏览器会将它们视为两个不同的请求,缓存无法复用。
- 请求
- 这一机制的核心目的是保证缓存资源的准确性------ 避免因请求上下文(如用户状态)不同,导致复用错误的资源。
有效:后判断 "能不能用"
- 找到匹配资源后,需通过 HTTP 缓存规则判断其是否 "有效",核心是判断资源是否 "过期" 或 "是否被修改",具体分两种情况:
- (1)强缓存: 直接本地判断,无需问服务器。通过响应头中的
Cache-Control(优先级更高)或Expires,判断资源是否在 "有效期内"。Cache-Control: max-age=3600:表示资源从被缓存时刻起,3600 秒(1 小时)内有效。浏览器会记录缓存时间,当前时间 - 缓存时间 < 3600 秒 → 有效。Expires: Wed, 15 Jul 2025 12:00:00 GMT:表示资源在该时间点前有效(基于服务器时间)。若当前时间早于该时间 → 有效。- 若强缓存有效:直接复用缓存资源,完全跳过网络请求(DNS、TCP、HTTP 都不触发),性能最优。
- (2)协商缓存: 需问服务器 "是否能用"。若强缓存已过期(如
max-age超时、Expires已过),浏览器会进入 "协商缓存" 阶段,通过服务器判断资源是否被修改:- 用
Last-Modified和If-Modified-Since:- 服务器返回资源时会带
Last-Modified: Wed, 10 Jul 2025 10:00:00 GMT(资源最后修改时间)。 - 缓存过期后,浏览器发起请求时会带
If-Modified-Since: Wed, 10 Jul 2025 10:00:00 GMT,问服务器:"这个时间后资源没改吧?" - 服务器对比后,若没改 → 返回
304 Not Modified(无响应体),表示缓存可用;若改了 → 返回200 OK和新资源。
- 服务器返回资源时会带
- 用
Etag和If-None-Match:- 服务器返回资源时会带
Etag: "abc123"(资源唯一标识,内容变则 Etag 变)。 - 缓存过期后,浏览器发起请求时带
If-None-Match: "abc123",问服务器:"Etag 还是这个吗?" - 服务器对比后,Etag 不变 → 返回
304(缓存可用);Etag 变了 → 返回新资源。
- 服务器返回资源时会带
- 若协商缓存有效(服务器返回 304) :复用本地缓存资源,但会发起一次 "轻量网络请求"(仅验证,无资源传输)。
- 用
- 特殊情况:
Service Worker的"有效性"判断为自定义逻辑 ,即为由开发者通过代码完全控制 ,不强制遵循 HTTP 缓存规则。- 可以忽略
max-age,强制返回缓存资源(离线可用); - 可以自定义过期逻辑(如 "缓存 7 天后必须重新请求");
- 甚至可以故意返回过期缓存,同时后台悄悄更新缓存(提升用户体验)。
- 可以忽略
未命中缓存/命中无效的结果
若所有缓存位置都没找到匹配资源(未命中),或找到但强缓存过期且协商缓存失败(服务器返回新资源),则必须发起完整网络请求(DNS → TCP → HTTP)获取资源,并按规则将新资源存入缓存(供下次使用)。
(三)DNS查询
在查询缓存失败之后,网络进程则必须向 DNS 服务器(DNS服务器有自己的IP地址)发送域名查询请求。
DNS 是什么?
DNS(Domain Names System,域名系统),提供的是⼀种主机名到 IP 地址的转换服务,它是⼀个由分层的 DNS 服务器组成的分布式数据库,是定义了主机如何查询 这个分布式数据库的⽅式的应用层协议。它能够使人更方便地访问互联网,⽽不用去记住能够被机器直接读取的IP数串。
-
域名: 一串用
.分隔的字符串组成的Internet上的某一台计算机或计算机组的名称,用于在数据传输时对计算机的定位标识,比如www.baidu.com。 -
IP地址: 一长串能够唯一地 标记网络上的计算机的数字,比如上面域名转换的IP地址
180.101.50.242 -
DNS本质: 域名人类看得懂,但是计算机看不懂;反之,IP地址计算机看得懂,人类看不懂,这时候DNS就出来充当翻译官 ,为他们进行翻译。所以其本质是将人类易记的域名(如
www.baidu.com)解析为计算机可识别的 IP 地址(如180.101.50.242) ,因为网络中设备间的通信依赖 IP 地址而非域名,为后续的TCP 连接、HTTP 请求铺路。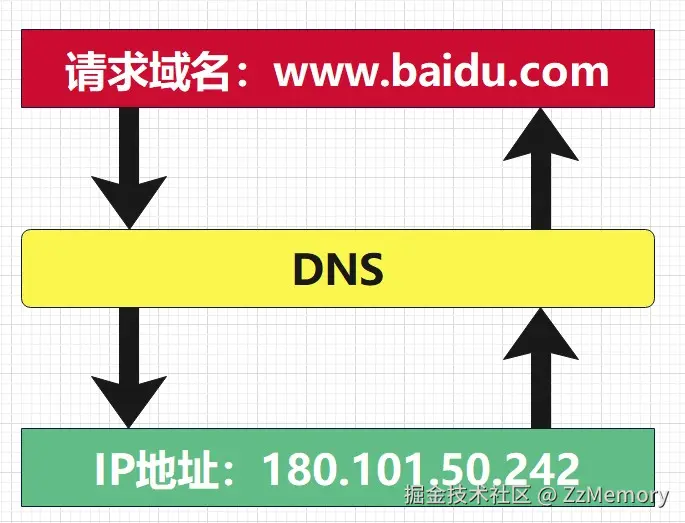
DNS查询方式
DNS 的查询和URL请求一样,都是会先查找缓存,以求避免重复的网络查询,提高效率;在没有查找到缓存的情况下,再使用DNS服务器发起查询。
查询缓存(顺序由上至下)
- 浏览器缓存: 浏览器缓存的近期解析过的域名,缓存时间由域名的 DNS 记录中的
TTL字段决定,通常为几分钟到几小时。 - 本地DNS(操作系统)缓存: 若浏览器缓存未命中,浏览器会向操作系统(OS)发起查询,检查操作系统的 DNS 缓存。操作系统的缓存来源包括:
- 近期系统内所有应用(如浏览器、客户端软件)的 DNS 查询结果;
- 本地
hosts文件(如 Windows 的C:\Windows\System32\drivers\etc\hosts)中的静态映射(若域名在hosts中已配置 IP,则直接返回该 IP,跳过后续网络查询)。
- 路由器缓存: 若操作系统缓存未命中,查询请求会被发送到本地路由器。路由器作为家庭 / 局域网的网关,通常会缓存其覆盖设备的 DNS 查询结果,供局域网内所有设备复用,进一步减少外部网络请求。
- ISP DNS服务器(本地DNS服务器)缓存: 若前三级缓存均未命中,查询会进入 "网络查询" 阶段(不过现在还是在找缓存 ),首先向用户的ISP(互联网服务提供商)的 DNS 服务器 (也称为 "本地 DNS 服务器",如电信、联通的 DNS 服务器)发起查询。
- ISP DNS 服务器是用户接入互联网的 "第一道外部 DNS 节点",通常缓存了大量常用域名的 IP(如百度、淘宝等),若命中则直接返回结果。
DNS服务器架构
若 ISP DNS 服务器也未缓存目标域名的 IP,则会启动 "递归查询"(Recursive Query)------ 即由 ISP DNS 服务器代替用户,向更上层的 DNS 服务器逐级查询(自最高层向下),直至获取结果。
- DNS服务器架构: 看到 递归 这么经典的查询方式,我们就要想到树结构 啊!!!DNS 的服务器架构就是树形结构的。如下图所示:
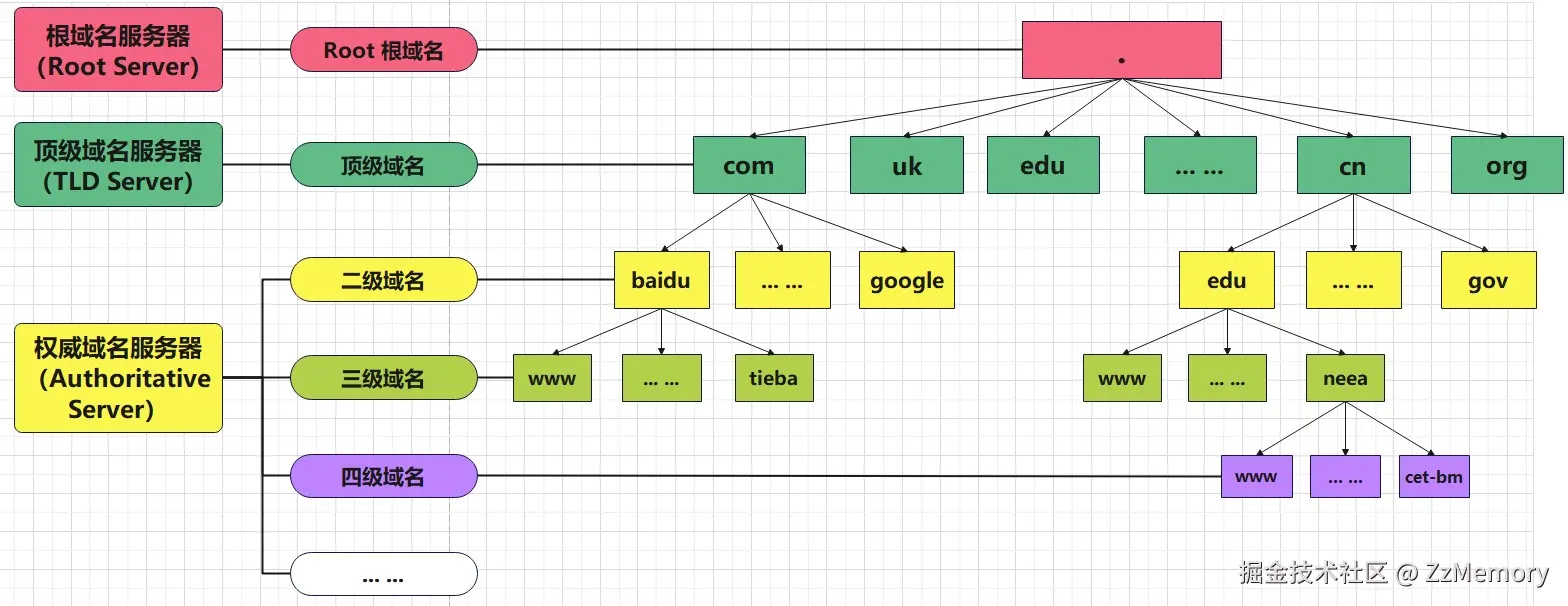 每个域名都有与之对应的服务器。
每个域名都有与之对应的服务器。
- 根域名服务器: 根域名服务器是 DNS 系统的 "顶层",全球共 13 组(由字母 A 到 M 标识),负责管理所有顶级域名 (如
.com、.cn、.org)的服务器地址。其使用.来在URL中表示,所以www.baidu.com 其实是https://www.baidu.com.,但是现在几乎所有用户都不会输入尾部的点 ,所以浏览器会自动帮你加上末尾的.,你要是手动加上,反而有可能会出错 ,比如你打不开www.baidu.com.这个网址。 - 顶级域名服务器: 顶级域名服务器(如
.com服务器)管理该顶级域下的所有二级域名 (如baidu.com)。 - 权威域名服务器: 权威域名服务器是管理某个具体域名 (如
baidu.com)的最终服务器,由域名持有者(如企业、个人)配置(通常通过域名注册商设置,如阿里云、腾讯云的 DNS 解析服务)。 - 权责是否重叠?: 看了上面的说明,你可能有点迷糊,顶级域名服务器不是管理了该顶级域下的所有二级域名(比如
baidu.com)吗,怎么权威域名管理器又来管理baidu.com了?这不是职责重叠了吗?其实这里的职责并没有重叠 。- TLD "去哪查": TLD 只负责二级域的权威服务器定位 ,不碰具体域名的 IP 记录(比如
.com服务器不知道baidu.com的 IP,只知道baidu.com的权威服务器在哪)。 - 权威服务器 "查什么": 权威服务器 只负责自己域名下的子域解析 ,不关心其他顶级域或二级域(比如
baidu.com的权威服务器不管google.com的解析,也不管.com顶级域的其他二级域)。
- TLD "去哪查": TLD 只负责二级域的权威服务器定位 ,不碰具体域名的 IP 记录(比如
查询方式:递归 + 迭代
上面说的递归查询不完全对,对于我们使用的客户端来说,确实是递归查询 (客户端只需发起一次递归查询,使用体验良好),但是对于DNS服务器来说,其实是迭代查询 ,所以实际上的DNS查询方式是 递归 + 迭代。
| 维度 | 递归查询(Recursive Query) | 迭代查询(Iterative Query) |
|---|---|---|
| 发起方 | 客户端 → 本地 DNS 服务器(如 ISP 的 DNS) | 本地 DNS 服务器 → 上层 DNS 服务器(根、顶级、权威) |
| 核心逻辑 | 客户端要求 本地 DNS 必须返回最终 IP 结果(要么找到,要么报错),本地 DNS 负责全程处理。 | 上层 DNS 服务器只需告诉 "下一步该找谁查询" (返回下一级服务器地址),不负责完成整个查询。 |
| 责任方 | 本地 DNS 服务器承担全部查询工作 | 本地 DNS 服务器自行串联多轮查询 |
-
原因: 我们都知道递归虽然看着简洁,但其实是一个时间和空间复杂度都比较高的行为 ,效率低下,如果 DNS服务器查询域名的时候全部使用递归查询 ,那么结果就是根、顶级服务器会被海量请求压垮 。而通过迭代查询,它们只需返回 "指引",把具体查询工作交给本地 DNS 服务器,分散压力。
-
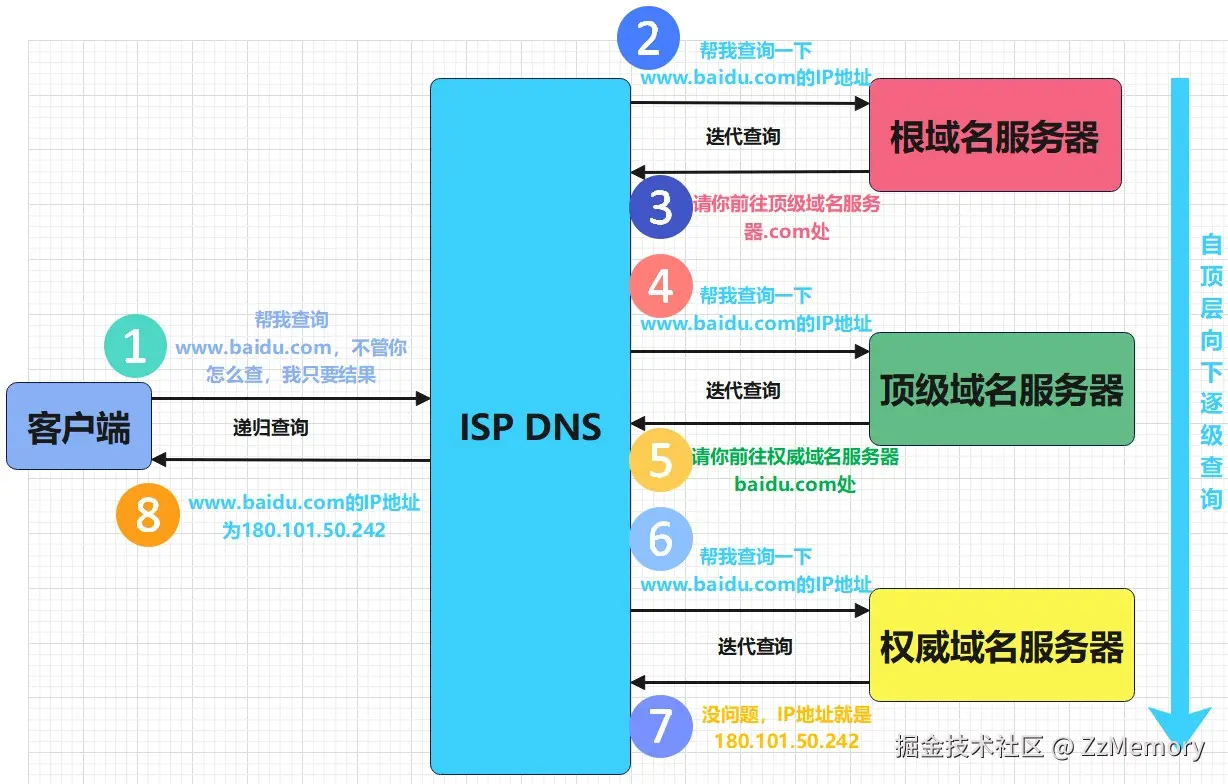
示例: 以解析
www.baidu.com为例,我将向你讲述DNS查询的全流程。- 发起递归查询: 客户端 → 本地 DNS 服务器。
- 浏览器先查本地缓存、
hosts文件(如没结果),向 本地 DNS 服务器 发请求: "帮我查www.baidu.com的 IP,不管你怎么查,必须给我最终结果!"* - 本地 DNS 服务器收到的是 递归查询,因此会启动后续流程,直到拿到 IP 再返回给客户端。
- 浏览器先查本地缓存、
- 迭代查询: 本地 DNS 服务器 → 上层服务器
-
如果本地 DNS 缓存也没结果,它会向 根服务器、顶级服务器、权威服务器 依次发起 迭代查询(每一步只拿 "下一步该找谁" 的指引):
-
- 本地 DNS → 根服务器(迭代):
- "请问 www.baidu.com 的 IP 是多少?"
- 根服务器:"我不知道 IP,但
.com顶级服务器的IP地址是x.x.x.x(代指),你去问它。"
-
- 本地 DNS → 顶级服务器(
.com,迭代):
- "请问 www.baidu.com 的 IP 是多少?"
- 顶级服务器:"我不知道 IP,但
baidu.com的权威服务器的IP地址是x.x.x.x(代指),你去问它。"
- 本地 DNS → 顶级服务器(
-
- 本地 DNS → 权威服务器(
baidu.com,迭代):
- "请问 www.baidu.com 的 IP 是多少?"
- 权威服务器:"完全没问题,是
180.101.50.242。" - 这时我们就找到了IP地址,接下来需要将它返回。
- 本地 DNS → 权威服务器(
-
- 返回结果(递归响应):
- 本地 DNS 拿到 IP 后,将结果返回给客户端,完成 递归查询的响应。至此,本次DNS查询结束。
- 发起递归查询: 客户端 → 本地 DNS 服务器。
-
流程图:
(四)发起TCP请求(三次握手)
拿到IP地址之后,我们就可以前往该IP地址获取资源,但在这之前,我们还需要建立TCP连接。
- TCP协议特点: TCP,即为Transmission Control Protocol(传输控制协议),其特点如下:
- 面向连接: 传送数据之前必须先建立连接,数据传送结束之后要释放连接。
- 点对点(一对一): 每一条TCP连接只能有两个端点,所以每一条TCP连接只能是点对点的(一对一)。
- 可靠交付: TCP提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复,并且按序到达。
- 全双工通信: TCP允许通信双方 的应用进程在任何时候都能发送数据。
- 面向字节流: 虽然应用程序和TCP的交互是一次一个数据块(大小不等),但是TCP把应用程序交下来的数据仅仅看成是一连串的无结构字节流。
为什么要先建立TCP连接?
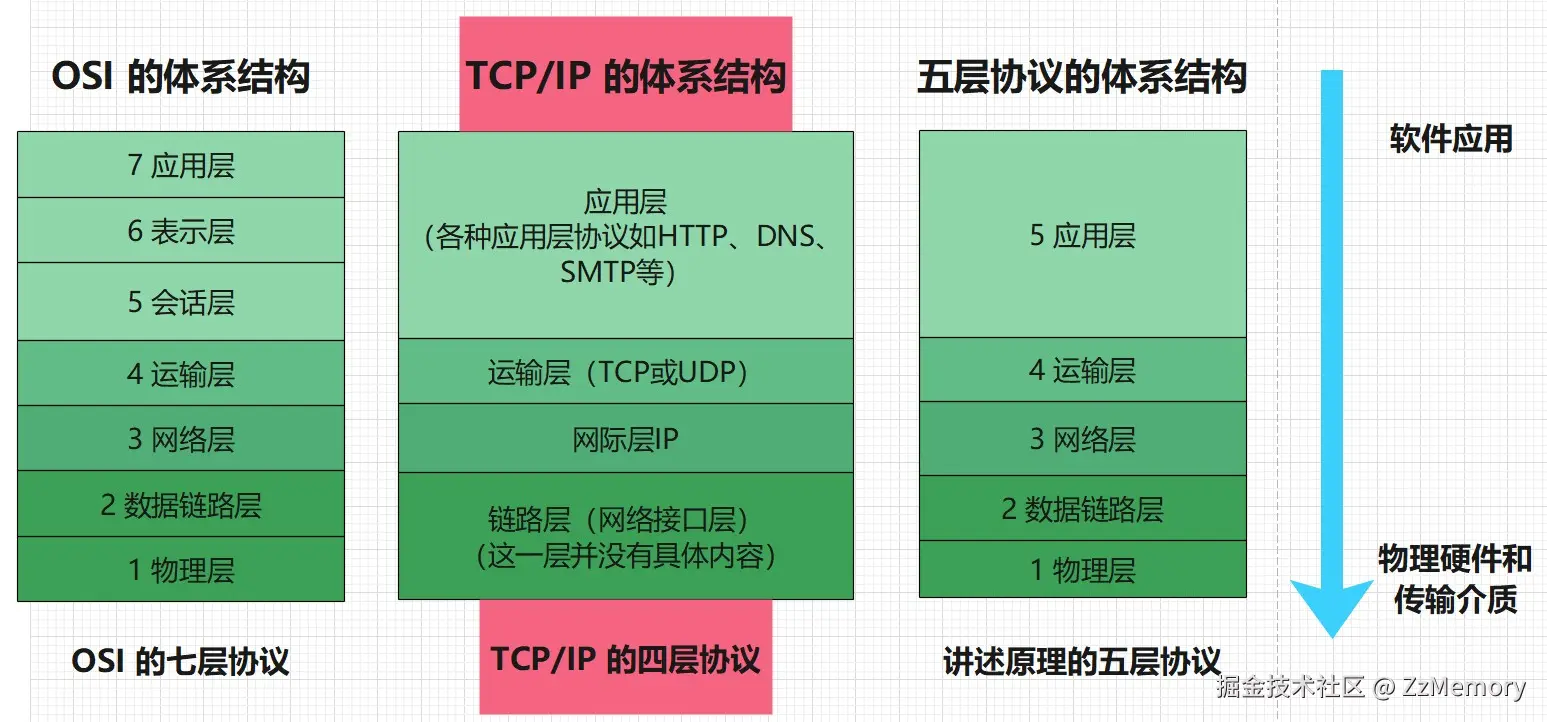
这与计算机网络体系结构有关,我们现在主要有OSI体系结构、TCP/IP体系结构、五层协议体系结构。
- OSI体系结构: 最全面,理论最完整,但它既复杂又不实用,现在应用很少。
- TCP/IP体系结构(重点): 最实战,现在应用最广泛的体系结构。
- 五层协议体系结构: 最适合讲述计网原理,教科书一般采用该体系结构讲述计网。
- 示图:
-
计算机网络体系结构如下图所示:
-
本节我们要重点讲解的就是TCP/IP,如下图所示:
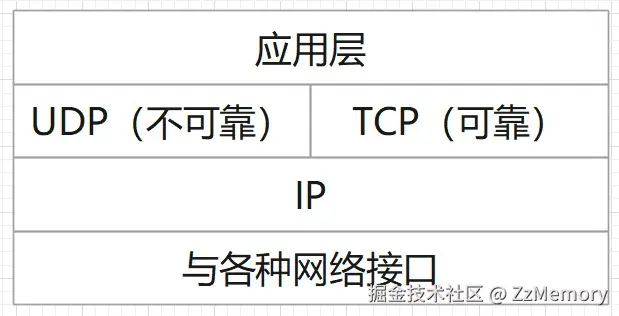
- 可以从图中看到,应用层 (最接近用户应用的层次,负责承载具体的应用级协议和业务逻辑)想要通过IP地址 ,从各种网络接口 中拿到资源,其中间必须通过运输层(TCP),建立TCP连接。
-
- 示例: 当我们用浏览器访问网页时,以HTTP为例。
*- 应用层(HTTP) :组装网页请求(如
GET /index.html),交给运输层。
-
- 运输层(TCP) :建立连接,把 HTTP 数据封装成 TCP 报文段,交给网际层。
-
- 网际层(IP) :给 TCP 报文段加 IP 头(源 / 目的 IP),交给网络接口层。
-
- 网络接口层:最终通过网卡、网线等硬件发送数据。
- 应用层(HTTP) :组装网页请求(如
三次握手
-
三次握手定义: TCP连接建立过程中,客户端和服务器端总共要进行三次交流,双方在此期间交换三个TCP报文段,所以我们形象地称为这段过程为 "三次握手",三次握手均成功,通信双方才有了信任,建立了TCP连接。
-
TCP报文核心字段解释: TCP结构全讲解的话太复杂,而且和三次握手关联不大,我们就讲一下核心字段。
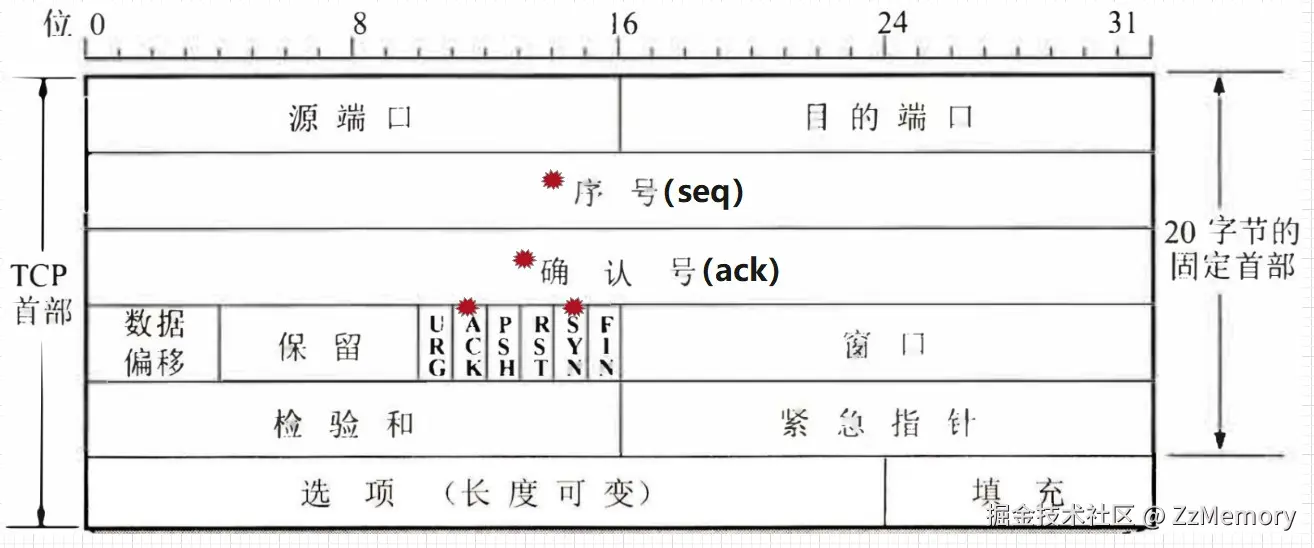
- SYN(Synchronize,同步位): TCP 报头的标志位。
SYN=1表示 "同步请求",用于发起连接(第一次握手和第二次握手的 SYN 用于协商初始序列号)。
- seq(Sequence Number,序号): 发送方为数据段分配的唯一序号 ,保证数据有序传输。
- 三次握手中,
seq是初始序列号 (随机生成,如客户端的x、服务器的y),后续数据传输时,seq会随数据长度递增。
- 三次握手中,
- ACK(Acknowledgment,确认位): 同样也是 TCP 报头的标志位。
ACK=1表示 "确认有效",此时 ack 字段必须携带确认号,用于确认已收到对方数据。
- ack(Acknowledgment Number,确认号): 期望收到的下一个序列号 。
- "下一个"即为
ack = 对方的 seq + 1(表示已收到对方seq及之前的所有数据,期待下一个序号)。
- "下一个"即为
- SYN(Synchronize,同步位): TCP 报头的标志位。
-
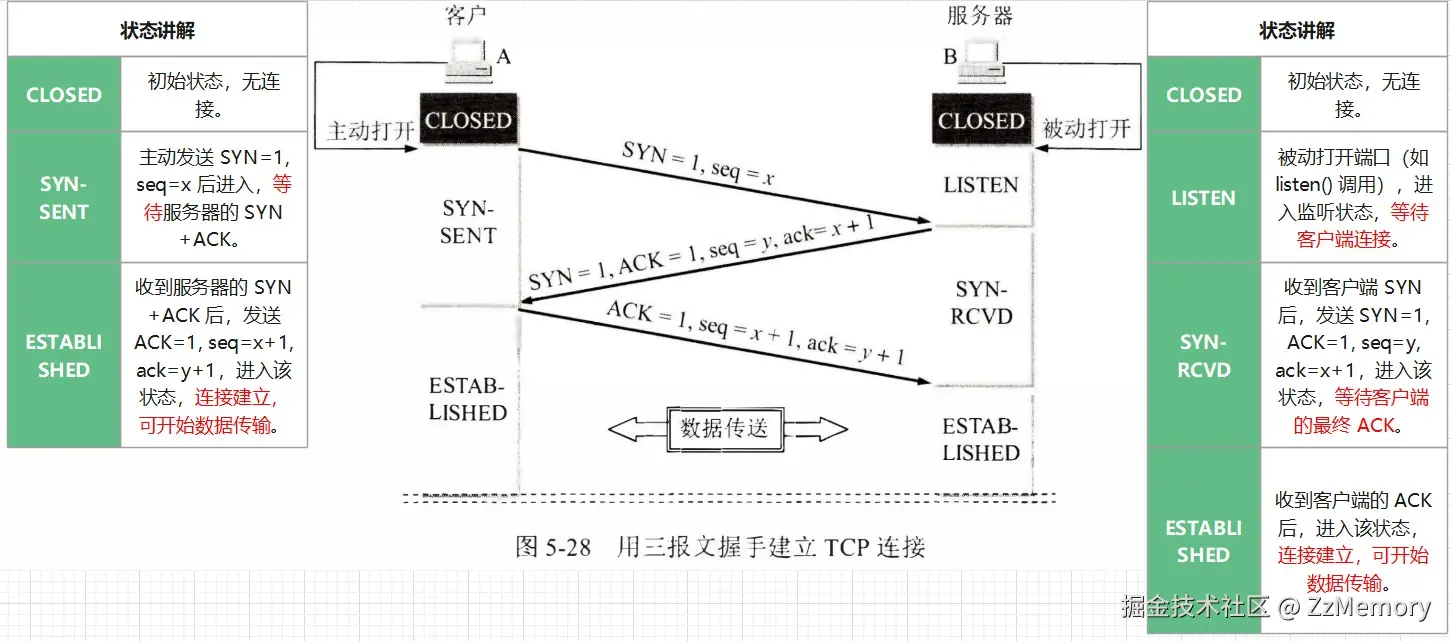
三次握手流程详情:
- 第一次握手(客户端→服务器):
- 客户端:
CLOSED → SYN-SENT,发送SYN=1, seq=x(无 ACK,因为还未确认任何数据)。 - 服务器:
LISTEN → SYN-RCVD(收到 SYN 后触发)。
- 客户端:
- 第二次握手(服务器→客户端):
- 服务器回复
SYN=1, ACK=1, seq=y, ack=x+1(SYN发起自身同步,ACK确认客户端的 SYN,ack=x+1表示期待客户端下一个序号是x+1)。 - 客户端:收到后,确认服务器的 SYN(准备发送 ACK)。
- 服务器回复
- 第三次握手(客户端→服务器):
- 客户端发送
ACK=1, seq=x+1, ack=y+1(ACK确认服务器的 SYN,seq=x+1是自身下一个序号,ack=y+1期待服务器下一个序号是y+1)。 - 服务器:
SYN-RCVD → ESTABLISHED(收到 ACK 后,连接正式建立)。
- 客户端发送
- 第一次握手(客户端→服务器):
-
示图:
为什么是三次握手?
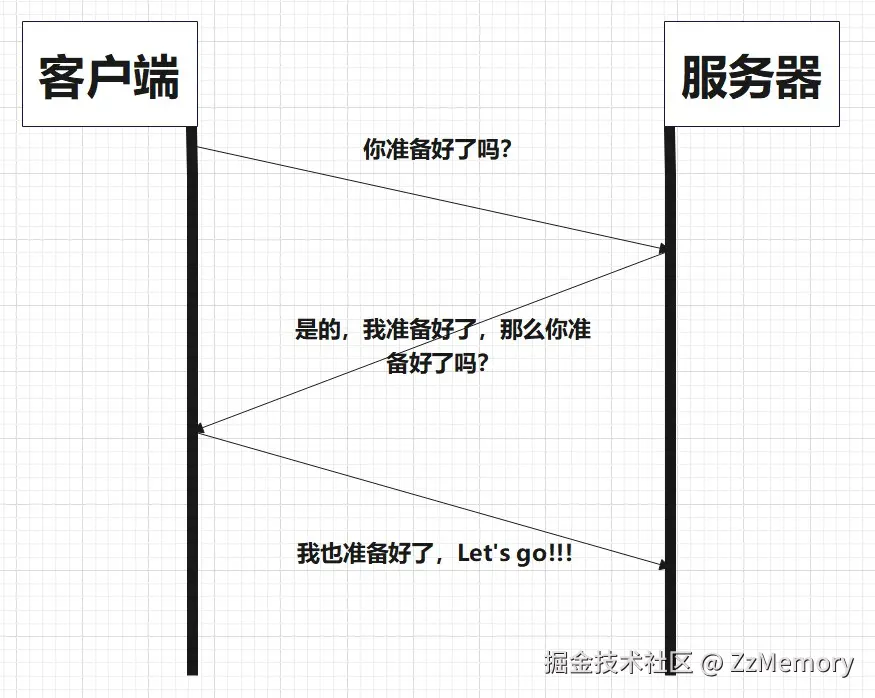
看到示图,我们可以发现,似乎经历了前两次握手的一问一答之后,客户端就已经建立起了可以传输数据的连接(客户端状态为ESTABLISHED),那么为什么要设计似乎多此一举的第三次握手呢?
-
答案:保证TCP的全双工通信
- 还记得我们上面说过TCP协议的特点是全双工通信(双方可同时收发消息) 吗?你再仔细看看示图,如果只是实现了前两次握手,只能验证单向通信,是无法验证全双工通信是否建立的。
- 假设两次握手即建立连接:
- 第一次握手:客户端 -> 服务器,验证 "客户端能发,服务器能收"。
- 第二次握手:服务器 -> 客户端,验证 "服务器能发,客户端能收"。
- 之后就会出现问题,两次握手后,服务器会直接进入
ESTABLISHED状态,认为连接已建立,但是它并不知道客户端有没有收到第二次握手的回复。客户端可能出现如"网络丢包"的情况,没有收到服务器发来的请求,这时客户端会认为连接失败了。 - 造成一个局面:服务器已分配资源(如连接表、缓存),但客户端并未真正准备好,导致服务器空等,浪费资源。
-
三次握手就不会造成一方准备好了,而另一方处于连接失败的情况,经过第三次握手,服务器端接收到了来自客户端的消息,知道客户端已经准备好了,才会进入
ESTABLISHED状态。 -
三次握手流程简化图:
(五)发送HTTP请求
当TCP连接建立之后,浏览器和服务器就可以在这基础之上进行通信,浏览器会构建 HTTP 请求,然后向服务器发送构建的 HTTP 请求信息。
- HTTP 协议: 如果是HTTP协议,则可以在建立TCP连接之后,直接发送HTTP请求。
- HTTPS(HTTP over TLS) 协议: 如果是HTTPS协议,则需要在建立TCP连接之后,进行TLS连接建立 ,对传输的数据进行加密,之后才能发送 HTTP请求。
- 注意: HTTPS 协议 发送的也是HTTP请求,二者之间的差异仅在于传输方式 ,HTTPS 本质上是 安全传输的HTTP。普通 HTTP 的请求 / 响应是明文在 TCP 上传输,而 HTTPS 的请求 / 响应会被 TLS 加密后再通过 TCP 传输,避免了数据被窃听、篡改或伪造。
HTTP 请求构成
HTTP请求由请求行、请求头、请求体构成,请求头和请求体之间还有一个空行,用以分隔二者。如下图所示:
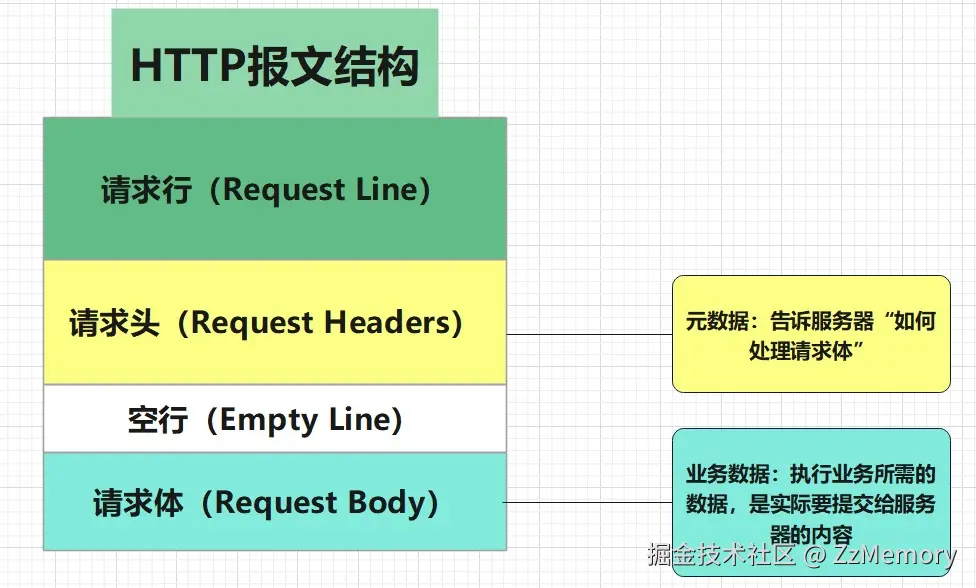
- 1. 请求行(Request Line): 是 HTTP 请求的第一行 ,明确请求的核心动作 与基本信息 。
- 格式 :
[请求方法] [请求路径/URI] [HTTP 协议版本] - 示例 :
GET /api/user HTTP/1.1
- 格式 :
- 2. 请求头(Request Headers): 通过键值对(Key-Value) 传递 元数据 ,让服务器理解请求的上下文、约束或附加信息 。
- 常见字段:
User-Agent:客户端标识(浏览器 / APP 类型、版本等,用于服务器 "识别" 请求来源)。Content-Type:请求体的数据格式(如application/json表示请求体是 JSON ,application/x-www-form-urlencoded表示表单)。Cookie:传递客户端会话信息(用于身份验证、状态保持)。Accept:客户端可接受的响应数据格式(如application/json, text/html)。
- 常见字段:
- 3. 空行(Empty Line): 是请求头与请求体的 "分隔符" ,通过
\r\n(换行 + 回车)的空行,告诉服务器: "请求头已结束,接下来是请求体(如果有)" 。- 为什么需要空行? HTTP 协议通过这种 "空行约定" 明确报文结构,让服务器能精准解析头和体的边界(否则无法区分哪里是请求头的结束 、请求体的开始)。
- 4. 请求体(Request Body): 传递实际的 "业务数据" ,非所有请求都有,需结合请求方法判断。
POST/PUT等方法常用(需向服务器提交数据,如表单、文件、JSON )。GET请求一般无请求体 (数据通过 URL 传递,如?name=xxx&age=20)。
完整的HTTP请求示例
由于我们输入URL输入打开的页面几乎都是GET形式的请求(GET形式没有请求体),不能全面说明HTTP请求报文的构成,于是我将使用 Trae 生成一段示例程序为你全面讲解HTTP报文。
- 示例程序展示:
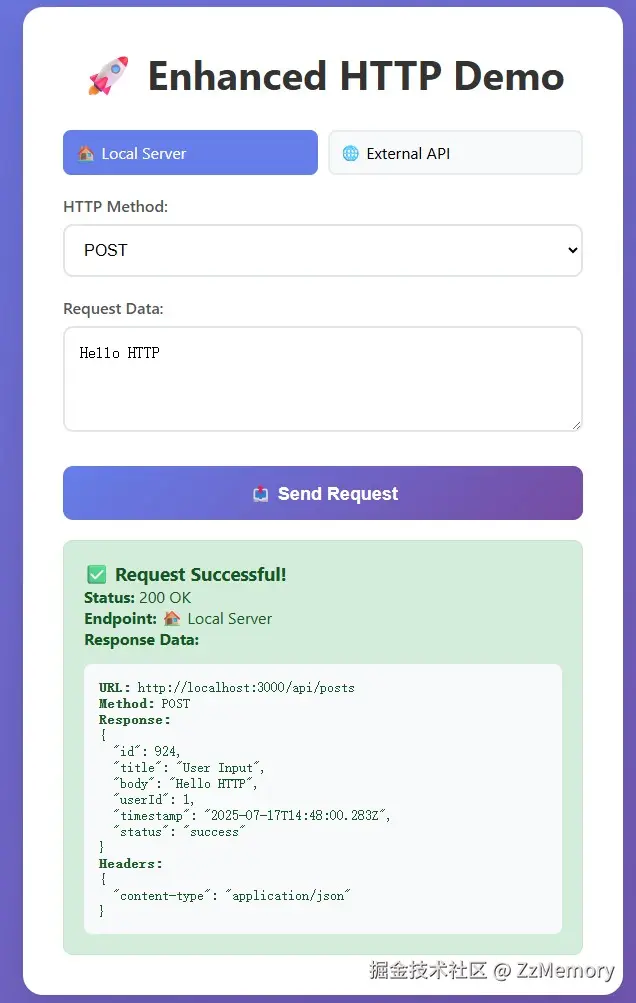
- 浏览器控制台查看报文:
-
注意: 在浏览器控制台看到的报文并不是合并在一起的,还记得上面的 HTTP 报文结构吗?
- HTTP 请求的结构是 "元数据(请求头) + 业务数据(请求体)" 的分层模型。
- 这种分层的核心目的是 "让不同层级的信息承担不同职责" ,类似快递包裹的 "面单(元数据)" 和 "内部物品(业务数据)":
-
请求行和请求头: 在
F12打开的浏览器控制台中,NetWork(网络) ->Headers,其中有Request Headers,可以查看请求行和请求头;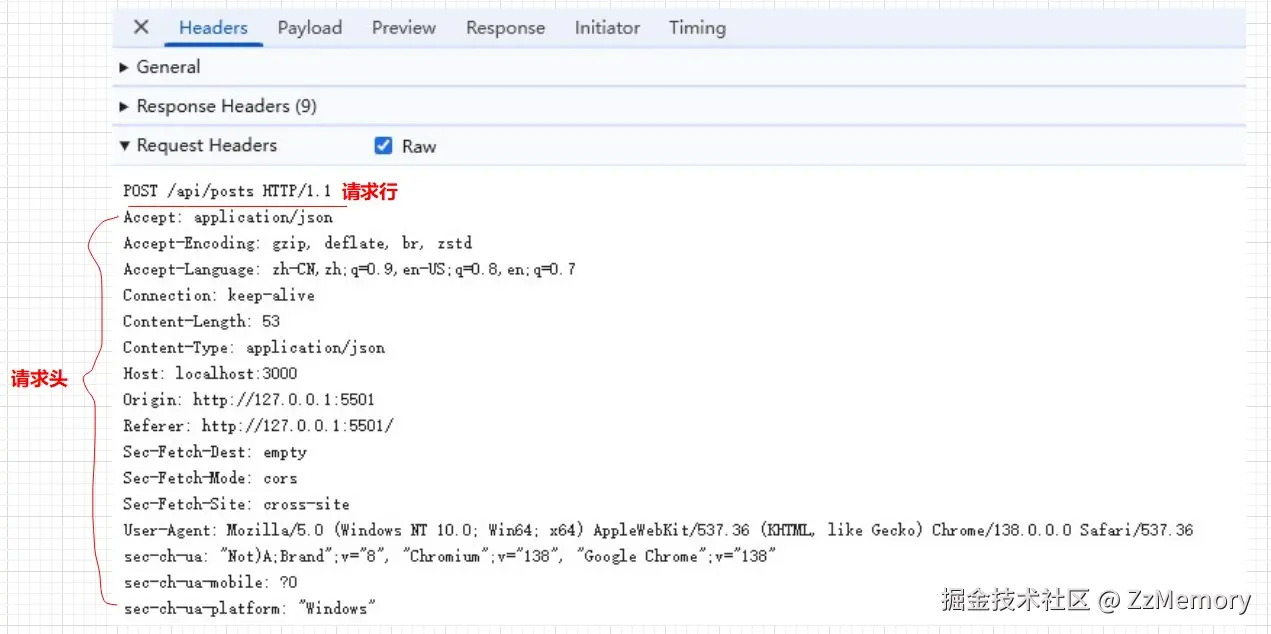
-
请求体: 因为我们选择的示例是
POST方式的HTTP报文,所以还能在Payload中查看请求体。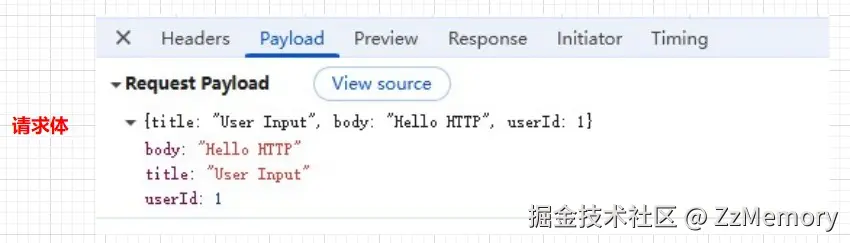
-
完整报文解析: 将报文合并分析。

-
(六)处理服务器返回的响应报文
既然浏览器发送了HTTP请求,那么服务器收到浏览器的请求之后,就要对其响应,执行一系列逻辑操作之后,服务器会返回一个 HTTP 响应报文。
响应报文构成
响应报文也是 HTTP 报文,所以它们结构类似,由四部分组成:状态行、响应头、空行、响应体。
状态行(Status Line)
状态行是响应报文的第一行 ,明确 "响应的基本结果",格式为HTTP/<协议版本> <状态码> <原因短语>
-
示例:
HTTP/1.1 200 OKHTTP/1.1:使用的 HTTP 协议版本。200:状态码 (三位数字,标识请求处理结果,如200成功、404资源不存在、500服务器错误 )。OK:原因短语 (状态码的 "可读说明",帮助理解结果,协议允许自定义,但常用短语固定,如Not Found对应404)。
-
常用的状态码与原因短语:
状态码范围 含义 核心作用 经典示例及详细说明 1xx 信息性响应(临时状态) 表示请求正在处理中,需要客户端继续操作 100 Continue:服务器允许客户端继续发送请求体(如POST大文件前的确认,避免浪费带宽)2xx 成功响应 服务器已成功处理请求 200 OK:通用成功(返回响应体,如网页、JSON 数据等);201 Created:资源创建成功(如新建用户、文章后返回新资源 URL);204 No Content:成功处理但无响应体(如删除资源、OPTIONS预检请求)3xx 重定向响应 需要客户端重新定位资源(换 URL 请求) 301 Moved Permanently:资源永久迁移(客户端应更新本地记录,后续用新 URL 请求,如域名更换);302 Found:资源临时迁移(仅本次跳转新 URL,后续仍用原 URL 请求,如临时维护页);304 Not Modified:资源未修改(客户端直接复用本地缓存,无需重复传输,减少带宽)4xx 客户端错误 客户端请求有问题(如资源不存在、权限不足) 400 Bad Request:请求语法错误(服务器无法解析,如 JSON 格式错误、URL 混乱);401 Unauthorized:需身份验证(未登录或令牌无效,如访问个人中心未登录);403 Forbidden:服务器拒绝请求(身份验证通过但无权限,如普通用户访问管理员后台);404 Not Found:请求的资源不存在(如访问未定义的 URL);422 Unprocessable Entity:请求格式正确但语义错误(如表单必填项缺失、手机号格式错误)5xx 服务器错误 服务器处理请求时出错(代码崩溃、配置问题等) 500 Internal Server Error:服务器内部未知错误(如代码抛出未捕获异常、配置错误);502 Bad Gateway:网关错误(服务器作为代理时,收到上游服务器无效响应,如 Nginx 连接不上 Tomcat)
响应头(Response Headers)
位于状态行之后,通过键值对(Header-Name: value)的形式,传递与响应相关的附加信息(如内容类型、服务器信息、缓存规则等),帮助客户端正确处理响应体。
- 常见响应头及作用 :
-
Server:服务器软件信息(如Server: Nginx/1.21.0表示服务器用 Nginx)。 -
Content-Type:响应体的类型和编码(核心头字段),如:Content-Type: text/html; charset=UTF-8(响应体是 HTML 文本,编码为 UTF-8)Content-Type: application/json(响应体是 JSON 数据)
-
Content-Length:响应体的字节数(如Content-Length: 1024表示响应体大小为 1024 字节),帮助客户端确认是否接收完整。 -
Cache-Control:缓存规则(如Cache-Control: max-age=3600表示客户端可缓存该响应 1 小时)。 -
Location:配合 3xx 重定向状态码使用,指定新的资源 URL(如Location: https://new-domain.com表示跳转到该地址)。 -
Set-Cookie:服务器向客户端设置 Cookie(如Set-Cookie: sessionId=abc123; Path=/)。
-
空行(Empty Line)
严格分隔 "响应头" 和 "响应体" 的标志,是 HTTP 协议规定的语法边界。
格式 :由一个 "回车符(CR)+ 换行符(LF)" 组成(即 \r\n),且必须单独占一行(不能有其他字符)。
响应体(Response Body)
服务器返回的 "实际数据",是客户端请求的核心内容(如网页 HTML、API 返回的 JSON、图片二进制数据等)。
- 特点:
- 内容格式由
Content-Type头字段指定(客户端据此解析,如浏览器遇到text/html会渲染为网页,遇到image/jpeg会显示图片)。 - 长度由
Content-Length头字段指定(或通过分块传输编码Transfer-Encoding: chunked动态传输,适用于大文件)。 - 并非所有响应都有响应体:
204 No Content(成功但无内容)、304 Not Modified(缓存未修改)等状态码的响应体为空;404 Not Found可能返回一个 "找不到页面" 的 HTML 作为响应体。
- 内容格式由
响应报文示例图

接收并处理响应报文流程
服务器返回响应报文之后,浏览器会通过与服务器建立的 TCP 连接,接收服务器返回的 HTTP 响应报文,并按固定流程解析、处理,最终完成页面渲染或请求结果反馈。
- 1. 接收响应数据: 服务器通过 TCP 连接将响应报文以字节流形式发送,浏览器基于 TCP 的 "可靠传输" 特性(如校验和、重传机制)确保数据完整接收。
- 若响应体较大(如大文件、长 HTML),可能采用分块传输 (
Transfer-Encoding: chunked),浏览器会按分块标识(如每个分块的长度 + 数据)逐步拼接完整响应体。
- 若响应体较大(如大文件、长 HTML),可能采用分块传输 (
- 2. 解析报文结构 浏览器按 HTTP 协议规范解析字节流,拆分出四部分,就是我们上面介绍的响应报文结构了。
- 这里状态行 (如 302 重定向、401 需登录) 和 响应头 (如
Location跳转地址、Content-Type解析方式、Cache-Control缓存规则),决定了浏览器接下来要干什么。 - 响应体 决定了浏览器拿到了什么资源(诸如 HTML、JSON、图片等)。
- 这里状态行 (如 302 重定向、401 需登录) 和 响应头 (如
- 3. 根据状态码与响应头处理结果 浏览器会根据解析响应报文后拿到的状态码和响应头的信息,执行对应的针对性操作:
- 2xx 成功响应 : 最常见的就是
200 OK。- 若
Content-Type为text/html,将响应体(HTML 代码)传递给渲染引擎,开始解析 DOM、CSSOM 并渲染页面; - 若为
application/json,将响应体(JSON 字符串)解析为 JavaScript 对象,供前端脚本处理(如 AJAX 请求的回调逻辑); - 若为
image/jpeg等媒体类型,调用对应解码器处理二进制数据,显示图片或播放视频。
- 若
- 3xx 重定向响应 :
读取Location头中的 新URL,自动发起新的 HTTP 请求(跳转类型由状态码决定:301会更新本地缓存的 URL,302则临时跳转)。 - 4xx/5xx 错误响应 :
浏览器根据状态码显示预设错误页面(如404页面提示 "资源未找到",500提示 "服务器错误"),部分响应体可能包含自定义错误信息(如开发者返回的错误 HTML),浏览器会渲染该内容。 - 特殊状态码 :
204 No Content:无响应体,浏览器仅确认请求成功(如删除操作完成,不刷新页面);304 Not Modified:无响应体,浏览器直接复用本地缓存的资源(减少重复加载)。
- 2xx 成功响应 : 最常见的就是
- 补充:附加处理
- 缓存存储 :根据
Cache-Control、Expires等响应头,将响应体(如静态资源、API 数据)存入浏览器缓存(内存缓存、磁盘缓存),后续相同请求可直接复用。 - Cookie 设置 :解析
Set-Cookie头,将键值对(如会话 ID、用户信息)存入本地 Cookie,后续请求会自动携带(用于身份验证、状态保持)。 - 连接管理 :若响应头为
Connection: keep-alive(HTTP/1.1 默认),TCP 连接会被保留供后续请求复用;若为Connection: close,则在处理完响应后关闭连接(四次挥手)。
- 缓存存储 :根据
(七)解析并渲染页面(重点)
浏览器的渲染流程是一个重点,前面的步骤都只能算是为它的登场做铺垫,它才是这篇文章的重点。
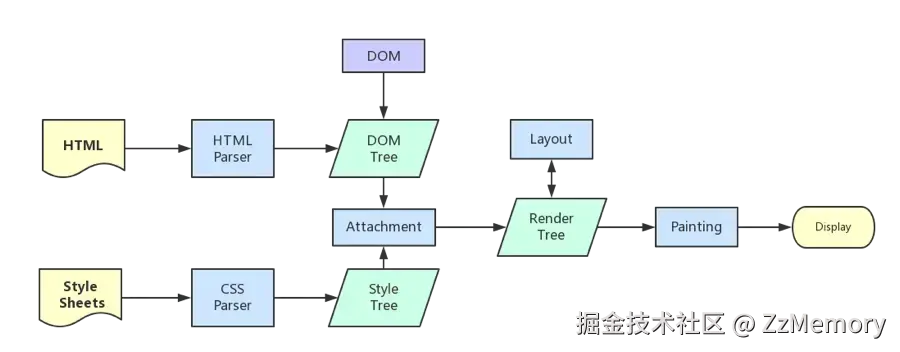
解析并渲染页面流程
由于浏览器渲染页面所需的资源(即为响应体部分),在第六步中已经被浏览器拆解出来了,所以浏览器现在可以直接对其进行解析,然后对页面进行渲染。步骤如下:
-
- 解析 HTML 生成 DOM树
-
- 解析 CSS 生成 CSSOM树
-
- 将DOM树与CSSOM树合并,生成Render树
-
- 布局Render树(Layout / Reflow)
-
- 绘制Render树(Paint / Repaint)
-
- 合成与显示(Compositing & Display)
 (本图为网图)
(本图为网图)
1. 解析 HTML 生成 DOM树
- 流程: 解压得到字节流 -> 编码转换 -> 词法分析 -> 语法分析 -> 组装DOM树
- 详情: 因为得到的数据是
gzip形式的(可在请求头的content-encoding:gzip验证),所以要先解压得到 HTML 字节流,随后通过编码转换 (如 UTF-8)将字节转为字符,再通过词法分析 将字符拆分为标签(如<div>)、属性(如class="box")、文本等 "令牌(Token)" ,最后通过语法分析 将Token转化为 节点(Node),按照嵌套关系组装成 DOM 树。 - DOM树示图:
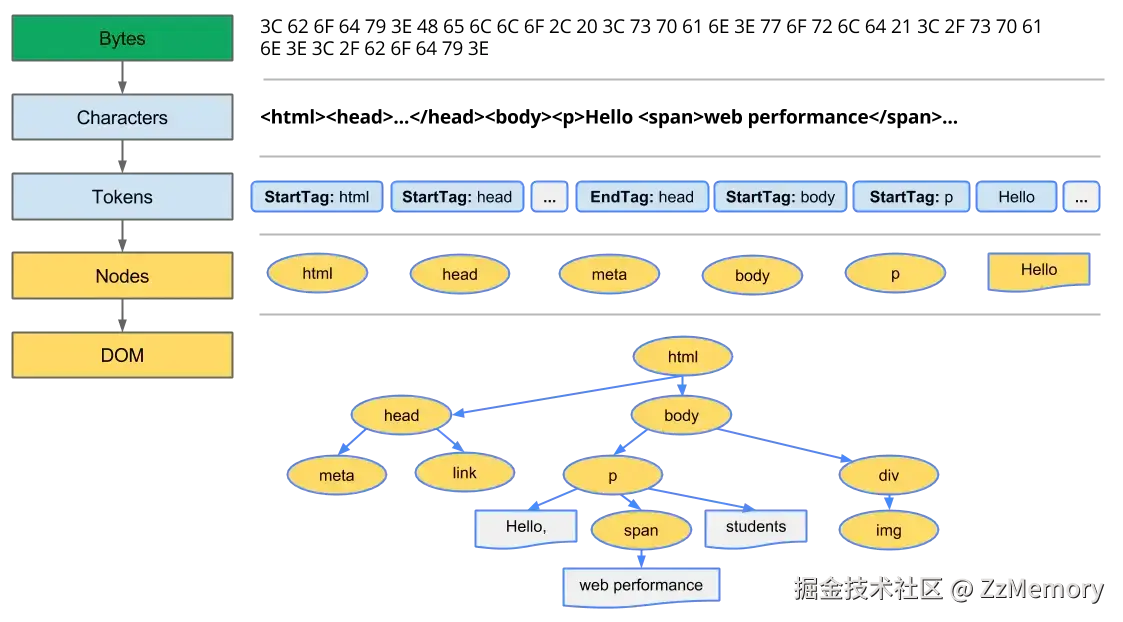 (本图为网图)
(本图为网图)
- 补充特性:
- 增量解析:HTML 解析是 "边加载边解析" 的,无需等待整个 HTML 加载完成(因为 HTML 通常是流式传输)。
- 阻塞问题 :遇到
<script>标签时,HTML 解析会暂停 (默认行为),原因是 JS 可能通过document.write()等 API 修改 DOM 结构,浏览器需等待 JS 执行完再继续解析。- 若 JS 通过
async或defer加载,解析不会被阻塞(async加载完立即执行,defer等待 HTML 解析完再执行)。 - 遇到
<link rel="stylesheet">(加载 CSS)时,HTML 解析不会暂停,但 CSSOM 未构建完会阻塞后续渲染(见步骤 2)。
- 若 JS 通过
2. 解析 CSS 生成 CSSOM树
同时,浏览器会解析 CSS 资源(包括<style>标签内的样式、<link>引入的外部 CSS、元素的style属性),构建CSSOM 树------ 这是页面样式的 "规则集",用于描述如何为 DOM 节点应用样式。
- 流程: 流程类似于 HTML解析,CSS 会先被转换为令牌,再组装成包含所有样式规则的树形结构。CSSOM 的节点与 DOM 节点对应,但包含层级化的样式信息(如子元素继承父元素样式)。
- 特性:
- 样式优先级 :CSSOM 会处理样式冲突(如
id选择器优先级高于class),计算每个节点的 "最终样式"。 - 阻塞渲染 :CSSOM 必须完全构建后,才能进入下一步(构建渲染树),因为渲染树需要依赖 DOM 的结构和 CSSOM 的样式。因此,未加载完成的 CSS 会阻塞页面渲染(但不阻塞 HTML 解析)。
- 样式优先级 :CSSOM 会处理样式冲突(如
3. 将DOM树与CSSOM树合并,生成Render树
渲染树是 DOM 树和 CSSOM 树的 "结合体",但并非简单叠加,而是筛选出需要显示的节点(不可见元素直接被排除) 并关联其样式,用于后续计算布局和绘制(见步骤 4)。
- 不可见: 这里需要重点区分
display: none和visibility: hiddendisplay: none: 元素会被完全从渲染流程中移除,不会出现在渲染树中。这意味着它既不会参与布局计算(不占据任何空间),也不会被绘制到屏幕上,相当于在视觉层面 "不存在"。visibility: hidden: 元素仍然会被保留在渲染树中(因为它并未被标记为 "无需渲染"),会参与布局计算(占据原有空间) ,但在绘制阶段会被隐藏(视觉上不可见)。
- 流程:
*- 遍历 DOM 树,忽略无需渲染的节点(如
<head>标签、display: none的元素)。
-
- 为每个保留的 DOM 节点匹配 CSSOM 中的样式规则,计算其 "最终应用样式"(如继承、优先级合并后的样式)。
-
- 生成渲染树节点(Render Object),每个节点包含:DOM 节点的结构信息 + 最终样式信息。
- 遍历 DOM 树,忽略无需渲染的节点(如
- 示例: 若 DOM 中有一个
<p style="display: none">,则它不会出现在渲染树中;若有一个<span class="text">,则渲染树节点会包含span的结构(DOM节点)和class="text"对应的样式(CSSOM样式规则)。
4. 布局(Layout / Reflow 回流,也叫重排)
Render树仅包含"what to render"(渲染什么),布局阶段则解决 "where to render"(在哪里渲染)------ 计算每个渲染树节点的几何信息(宽高、位置、尺寸等)。
- Layout 与 Reflow: 首次布局称为 "Layout" ,后续布局调整称为 "Reflow" 。
- 计算方法: 使用递归算法,从Render树的根节点开始,递归计算每个节点的布局。
- 根节点的位置通常是视口(viewport)的左上角,坐标(0,0),宽高默认等于视口宽高。
- 子节点的位置和尺寸依赖父节点(如
position: relative的子元素基于父元素定位),同时受盒模型(margin、padding、border)、布局模式(flex、grid、float等)影响。
- 补充特性:
- 递归: 因为使用的是递归,所以父节点的布局变化会触发子节点的重新计算(如父元素宽高改变,子元素的
width: 50%会重新计算)。 - 回流/重排的触发条件: 当窗口大小变化、DOM 节点增删、元素尺寸 / 位置 / 布局模式修改(如
width、left、display变化)等,都会触发 回流/重排。 - 回流导致的性能成本: 还是和递归有关系,渲染树是层级结构 ,一个节点的布局变化可能 "连锁反应" 影响父节点、子节点甚至兄弟节点。
- 例如:修改一个父元素的
width,其所有子元素若依赖%百分比宽度,都会被重新计算。 - 这种牵一发而动全身的情况会带来惊人的计算量,如果频繁触发,会导致页面卡顿,造成很不好的用户体验。
- 例如:修改一个父元素的
- 递归: 因为使用的是递归,所以父节点的布局变化会触发子节点的重新计算(如父元素宽高改变,子元素的
5. 绘制(Paint / Repaint 重绘)
布局完成后,浏览器需要将渲染树节点的 "几何信息 + 样式信息" 转换为像素点 (如颜色、阴影、背景图等视觉属性),这个过程称为绘制。、
- 流程: 浏览器会根据渲染树和布局结果,按层绘制 元素的视觉部分。
- 先绘制背景色,再绘制边框,然后是文本、阴影等(遵循 CSS 层叠规则)。
- 现代浏览器会将渲染树拆分为多个 "绘制层"(如
z-index不同的元素、opacity < 1的元素),每层独立绘制,避免整个页面重绘。
- 补充特性:
- 重绘触发条件: 元素的视觉样式变化(如颜色从
red改为blue),但几何信息不变时,会触发重绘(不触发回流)。 - 不依赖几何信息: 绘制仅处理视觉样式(如
color、background、box-shadow),不涉及位置和尺寸,因此重绘成本低于回流。
- 重绘触发条件: 元素的视觉样式变化(如颜色从
6. 合成与显示(Compositing & Display)
最后,浏览器将所有绘制好的 "图层" 按照顺序(靠z-index),合并为一个完整的页面,并发送到 GPU 渲染到屏幕上,这个过程为 合成 -> 显示。
- 过程:
*- 浏览器将绘制层按
z-index顺序排序(处理层叠关系)。
-
- GPU 将多层像素合并为单个图像,显示在视口中。
- 浏览器将绘制层按
- 补充特性:
- GPU 加速:合成阶段由 GPU 处理,效率极高(尤其适合动画)。
- 零回流 / 重绘 :若仅修改
transform(如平移、缩放)或opacity,浏览器可直接在合成阶段处理(无需布局和绘制),这也是这类属性性能更优的原因。 - 图层优化 :合理拆分图层(如通过
will-change: transform提示浏览器)可减少合成成本,避免图层过多导致的内存占用过高。
补充:回流、重绘、合成的关系
回流是渲染流程中的 "上游阶段" ,上游的变化会影响下游 (重绘、合成),但是下游很难影响上游。
- 回流必然导致重绘: 因为元素的位置 / 尺寸变了,其视觉表现(颜色、阴影等)即使没变,也需要重新绘制到新的位置。
- 回流可能触发合成: 重绘后的图层需要重新合并,因此 回流 -> 重绘 -> 合成 是连贯的流程。
- 下游很难影响上游: 重绘不一定触发回流 (如仅修改
color),合成也不一定依赖回流 / 重绘 (如用transform: translate()移动元素,仅触发合成,无回流 / 重绘)。 - 优化:
*- 优先规避回流: 能用合成属性(
transform/opacity)就不用几何属性,批量处理 DOM 操作。
-
- 缩小重绘范围: 用
contain限制影响,合并样式修改,减少高成本属性。
- 缩小重绘范围: 用
-
- 合理管理合成层: 不滥用图层提升,控制数量和尺寸,避免图层爆炸。
- 优先规避回流: 能用合成属性(
(八)关闭TCP连接(四次挥手)
关闭时机
TCP 连接会根据 HTTP 协议的配置(如是否启用 keep-alive)来决定是否关闭。
- 持久连接: 上面关于处理响应报文的内容有提到,HTTP/1.1默认
Connection: keep-alive,这是持久连接 ,持久连接不会在单个请求后关闭 ,而是复用连接加载页面所有资源(图片、脚本等)。- 关闭时机: 在持久连接的情况下,关闭只有三种可能。
- 标签页被用户关闭,浏览器会主动终止所有与该页面相关的网络活动,TCP连接自然也在其中。
- 当所有资源加载完毕且页面渲染完成后,浏览器确认不再需要该连接时,才会触发TCP关闭(四次挥手,步骤 8 符合这个情况)。
- 空闲超时 (由服务器/浏览器设定,如Nginx默认
keepalive_timeout 60s)。
- 关闭时机: 在持久连接的情况下,关闭只有三种可能。
- 非持久连接(罕见): HTTP/1.0 的默认
Connection: close,这使得服务器可能在响应后立即关闭连接 。不过现代浏览器基本上不使用这种方法,都是使用Connection: keep-alive,所以这种情况很罕见。
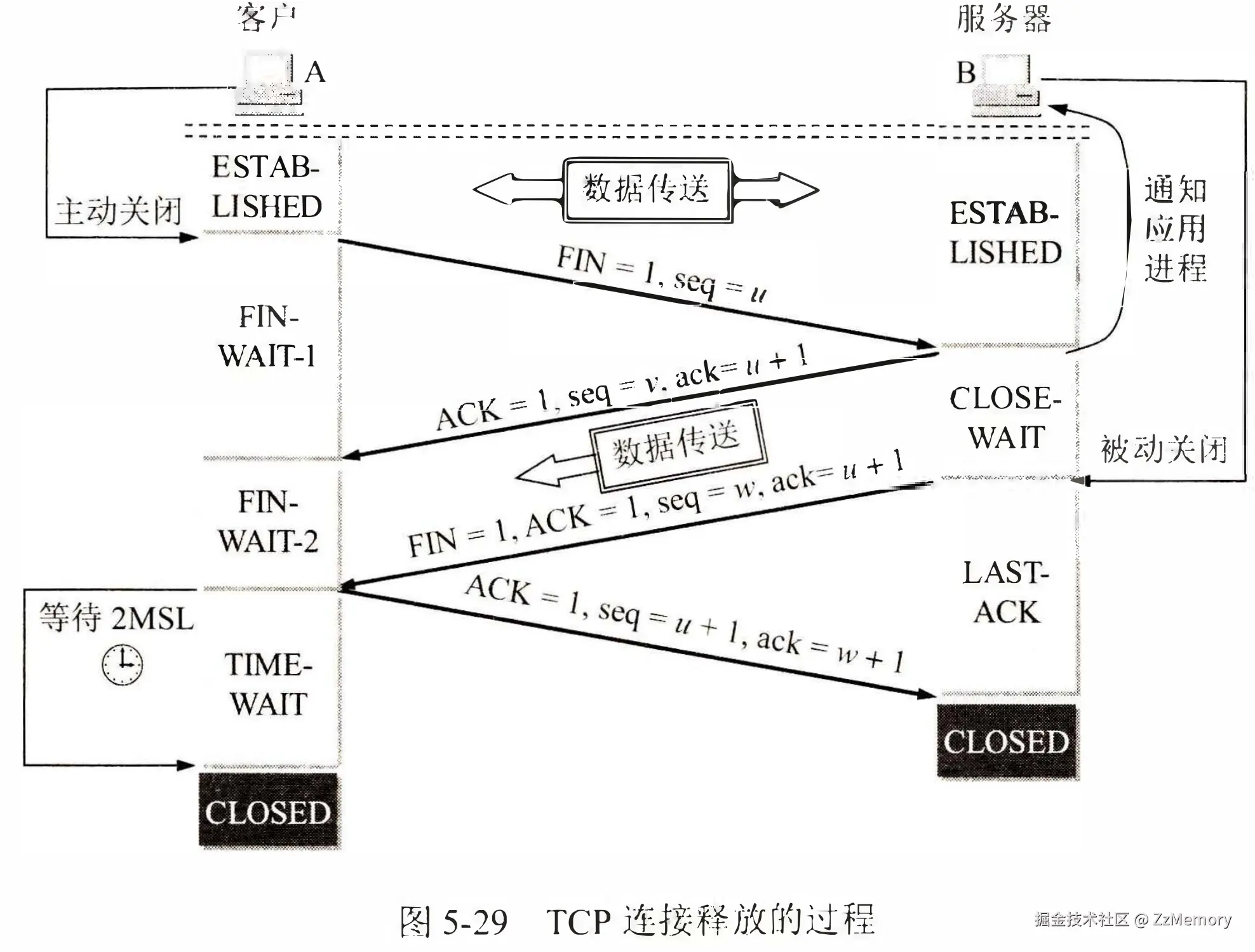
四次挥手流程详解
前面我们通过三次握手了解了通信双方如何建立连接,而四次挥手恰恰相反,是用来让通信双方关闭连接而不丢失数据。
- 核心字段: 前面介绍过其他四个,这里我加一个
FIN。- FIN(Finish,结束位): TCP 报头的标志位 (Flags 字段中的 1 个二进制位)。
FIN=1表示 "单向结束请求" ,用于告知对方: "本端已无应用数据需要发送,请求关闭 当前方向的数据流" (注意是单向关闭,不影响反向数据传输)。
- FIN(Finish,结束位): TCP 报头的标志位 (Flags 字段中的 1 个二进制位)。
流程
-
第一次挥手 (FIN from Client): B,我没有数据要发送给你了,我想关闭我这边的连接通道。(但 A 仍能接收 B 发来的数据)。
-
主动方: 客户端 (A) 决定要关闭连接。
-
状态: A 从
ESTABLISHED状态进入FIN_WAIT_1状态。 -
动作: A 向服务器 (B) 发送一个 TCP 报文段。
FIN = 1:表示 A 请求关闭连接。seq = u:这个报文段的序列号是u。u通常是 A 之前发送的最后一个数据字节的序列号加 1。
-
-
第二次挥手 (ACK from Server): A,我收到你的关闭请求了(FIN)。我确认(ACK)了。
-
主动方: 服务器 (B) 对 A 的 FIN 进行确认。
-
状态: B 保持在
CLOSE_WAIT状态。A 从FIN_WAIT_1进入FIN_WAIT_2状态。 -
动作: B 向 A 发送一个 TCP 报文段。
ACK = 1:表示这是一个确认报文。seq = v:这个报文段的序列号是v(B 自己的序列号)。ack = u + 1:确认收到了 A 的 FIN 报文 (seq=u)。期望 A 下次从 u+1 开始发送(虽然 A 不会再发数据了,这是 TCP 确认的固定机制)。
-
-
第三次挥手 (FIN from Server): A,我这边也没有数据要发送了,我也要关闭连接了(FIN)。之前你的 FIN 我已经确认过了(ACK=u+1)。
-
主动方: 服务器 (B) 也决定关闭连接(发送完所有数据后)。
-
状态: B 从
CLOSE_WAIT状态进入LAST_ACK状态(图中未明确标出此状态名)。A 保持在FIN_WAIT_2状态。 -
动作: B 向 A 发送一个 TCP 报文段。
FIN = 1:表示 B 也请求关闭连接。ACK = 1:通常同时设置 ACK 标志(虽然图中显示在第三次挥手,但第二次挥手已经确认了A的FIN,这次FIN通常也隐含对之前数据的确认)。seq = w:这个报文段的序列号是w。w可能等于v(如果 B 在发送 ACK 后没有发送任何数据)或v + 数据长度(如果 B 在 CLOSE_WAIT 期间发送了数据)。ack = u + 1:再次确认 A 的初始 FIN 报文(seq=u),期望值仍然是 u+1(因为 A 在 FIN_WAIT_2 状态不会再发数据)。
-
-
第四次挥手 (Final ACK from Client): B,我收到你的关闭请求(FIN)了,我确认(ACK)了。
-
主动方: 客户端 (A) 对 B 的 FIN 进行最终确认。
-
状态: A 从
FIN_WAIT_2状态进入TIME_WAIT状态。B 收到 ACK 后进入CLOSED状态。 -
动作: A 向 B 发送一个 TCP 报文段。
ACK = 1:表示这是一个确认报文。seq = u + 1:序列号是 u+1(因为 A 的 FIN 报文 seq=u 已被确认,下一个序列号就是 u+1)。ack = w + 1:确认收到了 B 的 FIN 报文 (seq=w)。期望 B 下次从 w+1 开始发送(虽然 B 不会再发数据了)。
-
-
示图:
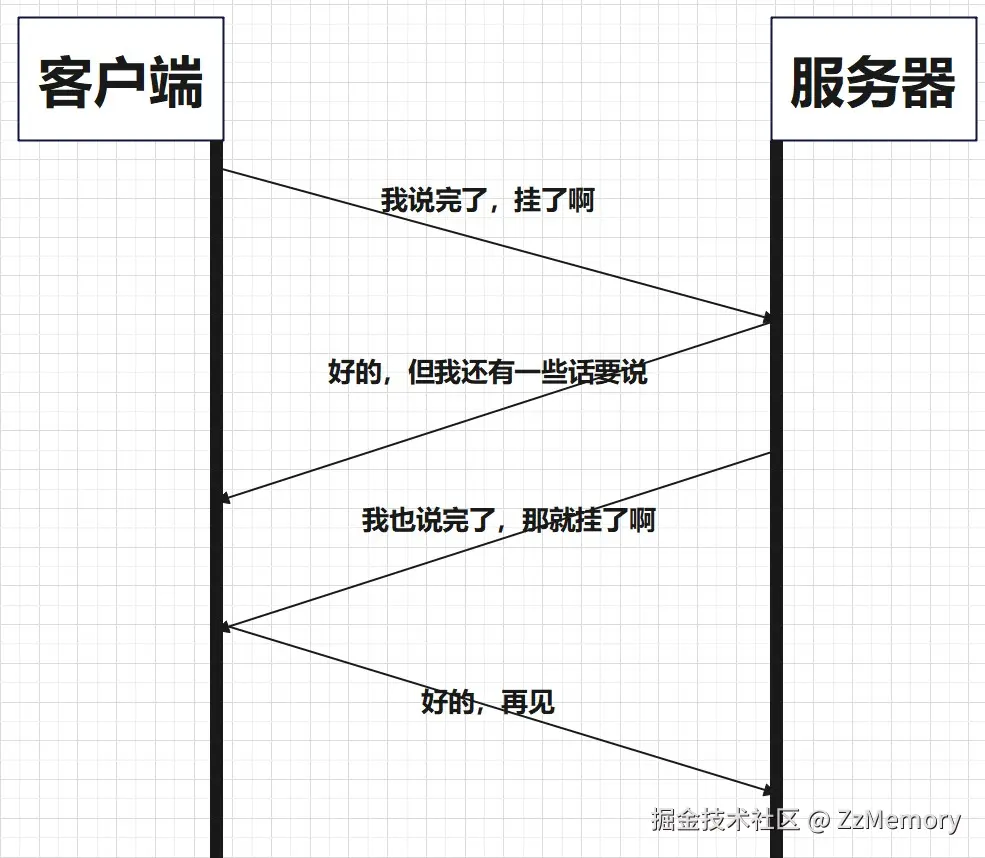
- 简化流程图: 以打电话为例。
为什么是四次挥手
四次挥手会不会太繁琐呢?我们能不能对它进行压缩呢?比如第二次和第三次挥手,又或是省去第四次挥手?
- 第二次挥手(ACK)和第三次挥手(FIN)无法强制合并:
- 当B收到A的
FIN时,B的应用程序可能还有数据要发送(如处理结果的响应)。 - B必须先发送
ACK(第二次挥手)表示"收到你的关闭请求",再继续发送剩余数据,最后才发送自己的FIN(第三次挥手)。 - 此时ACK和FIN之间可能存在延迟(数据发送耗时),无法合并为一个报文。
- 当B收到A的
- 第四次挥手必须独立存在:
- TCP要求每个
FIN必须被确认(防止报文丢失导致连接僵死)。 - B的
FIN(第三次挥手)必须由A的ACK(第四次挥手)确认,且A不能再携带其他数据(连接已半关闭)。 - 所以第四次挥手必须独立存在,绝不能省去或是被压缩。
- TCP要求每个
结语
"路漫漫其修远兮,吾将上下而求索",如果你能把这么长一篇文章看下来,那么你真的很棒,给你点赞哦👍。相信看完之后,你对计网相关的知识有了新的认识。如果帮到了你,那么我不胜荣幸。
如果文章有错误,请在评论区指正,谢谢🙏。