嗨,各位前端圈的朋友们!
当我们谈论现代 Web 应用时,"丝滑的用户体验"是一个绕不开的话题。我们早已习惯了在应用内无缝跳转,URL 在变,内容在更新,唯独浏览器顶部的刷新按钮静如处子。这种媲美原生应用的体验,正是单页应用(SPA)的魅力所在。
而支撑起这份魅力的核心技术,就是前端路由。它究竟是如何工作的?今天,就让我们一起,从底层到框架,彻底把它搞明白。
核心摘要 (TL;DR)
时间紧张?没关系,三句话带你了解全文核心:
- 前端路由 是单页应用(SPA)的基石,它允许我们在不刷新页面的情况下,根据 URL 变化来动态更新页面内容。
- 它主要通过两种浏览器原生机制实现:一是利用 URL
#的hash模式 ;二是利用history.pushState()API 的history模式,后者 URL 更美观,但需要服务器配置支持。 - 现代框架(如
React Router)将这些底层 API 封装成声明式组件(如<Link>,<Route>),极大地简化了开发,让我们能更专注于业务逻辑。
一、一个时代的跃迁:从多页(MPA)到单页(SPA)
在前端路由出现之前,我们生活在一个由**多页应用(Multi-Page Application)**主导的世界。每一次点击链接,都是一次完整的页面刷新,不仅有白屏等待,页面状态也会丢失,体验较为割裂。
为了解决这些痛点,单页应用(Single-Page Application)应运而生。它的核心思想是应用即页面,路由即状态。我们只加载一个"应用外壳",之后的所有导航,都只是通过 JavaScript 动态地改变视图,而 URL 的变化则成为了一种"状态"的表征。
二、两大支柱:hash 与 history 模式
JS 是如何做到在不刷新页面的前提下,既能修改 URL,又能监听其变化呢?答案就藏在浏览器提供的两大机制中。
1. hash 模式:URL 上的"便利贴"
这是最简单直接的方式。它的原理是:
- URL 的
#(hash) 片段 的改变,不会触发浏览器向服务器发送请求。 - 浏览器提供了
onhashchange事件,可以监听到 hash 值的变化。
因此,开发者可以通过修改 location.hash 来更新 URL,并通过监听事件来渲染对应视图。这种方式兼容性极佳,且无需服务端配置。但缺点也很明显------URL 中始终带着一个 #,不够美观。
2. history 模式:URL 的"隐形魔术"
为了实现更优雅的 URL,HTML5 对 window.history 对象进行了史诗级增强,带来了 pushState 和 replaceState 两个关键 API。
让我们通过一个原生 JS 模拟器来一探究竟:
html5/router/4.html
html
<body>
<h2>SPA路由模拟</h2>
<button onclick="navigate('/home')">首页</button>
<button onclick="navigate('/about')">关于</button>
<div id="view">当前视图</div>
<script>
function render(path) { /* ... */ }
function navigate(path) {
// 核心!pushState 仅改变 URL 并创建历史记录,但不会刷新页面。
history.pushState({path}, '', path);
// 手动调用 render 更新视图
render(path);
}
// 监听浏览器前进/后退事件
window.addEventListener('popstate', (event) => {
// 当用户点击浏览器导航按钮时,popstate 被触发
render(event.state?.path || location.pathname);
})
</script>
</body>这段代码精妙地展示了 history 模式的运作流程:
history.pushState(): 这是导航的关键。它以"静默"模式修改 URL 并推入历史记录栈,但不会触发页面刷新。popstate事件: 当用户点击浏览器的前进/后退按钮时,该事件被触发,我们可以从中获取当初存入的状态,渲染正确的视图。
注意 :history 模式虽然 URL 干净,但需要服务器配置支持 。因为当用户在 mysite.com/about 这样的地址上刷新时,浏览器会真实地请求该路径。服务器必须配置一个"回退路由",将所有这类请求都重定向到你的主 index.html。
三、优雅的抽象:React Router 的实践
理解了底层原理后,我们再来看 React Router 这样的库,就会发现它所做的一切都是那么的顺理成章------将底层的命令式 API 封装成了优雅的声明式组件。
一张图看懂 React Router 工作流
当你在使用 React Router 的应用中点击一个链接时,内部发生了什么?下面这张图一目了然:
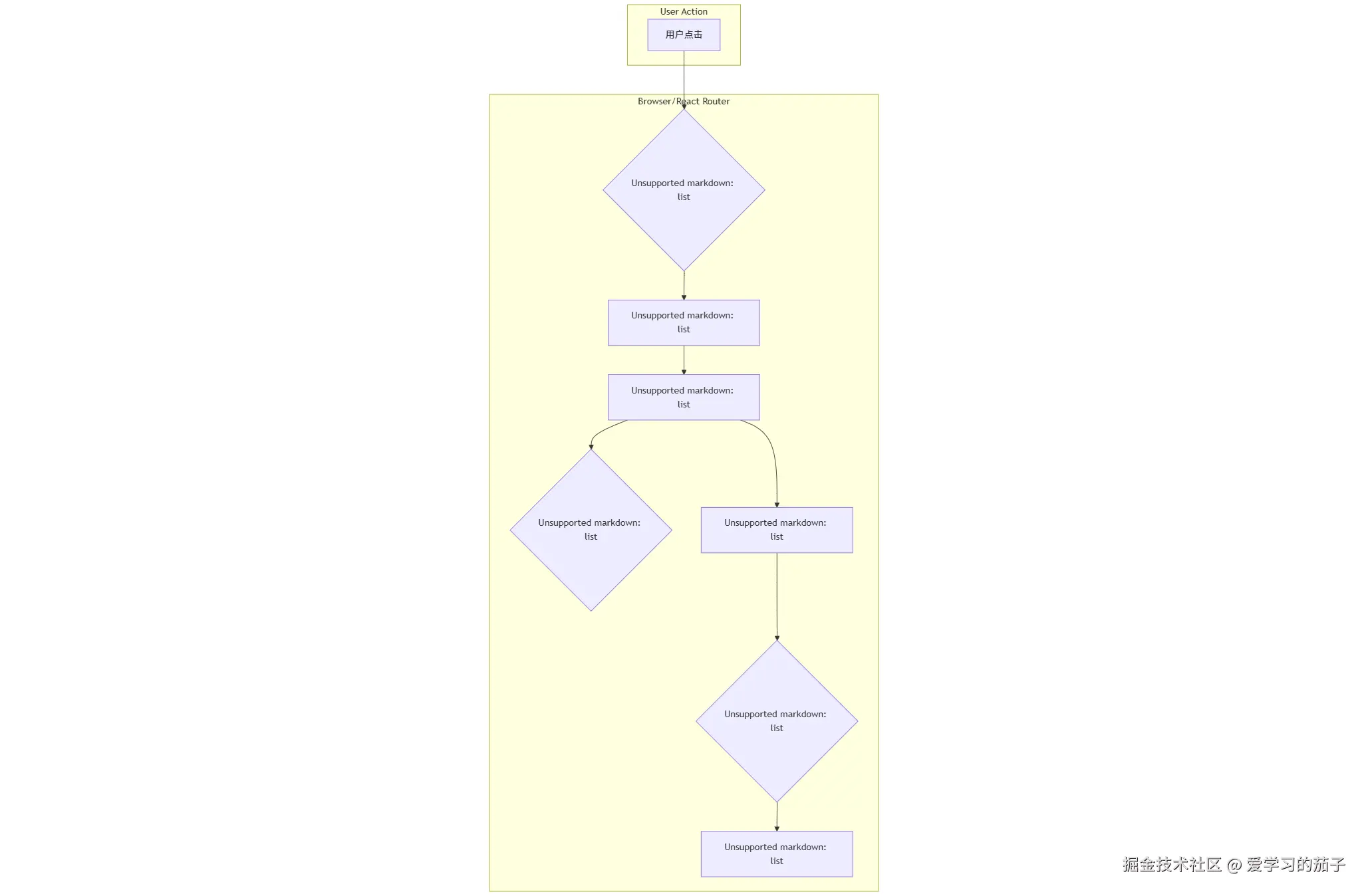
核心组件解析
hash-history-router/src/App.jsx
jsx
import { BrowserRouter as Router, Routes, Route, Link } from 'react-router-dom';
import Home from './pages/Home';
import About from './pages/About';
function App() {
return (
// 1. <Router>:提供路由上下文环境
<Router>
<nav>
{/* 2. <Link>:声明式导航,底层调用 history.pushState */}
<Link to="/">Home</Link>
<Link to="/about">About</Link>
</nav>
<main>
{/* 3. <Routes>:监听URL变化,匹配并渲染对应<Route> */}
<Routes>
<Route path="/" element={<Home />} />
<Route path="/about" element={<About />} />
</Routes>
</main>
</Router>
)
}这套组合拳将我们从繁琐的底层操作中解放出来,只需关心**"哪个路径对应哪个组件"**,实现了真正的高内聚、低耦合。
写在最后
前端路由技术是 Web 应用进化的关键一步。通过今天的探索,我们:
- 理解了 SPA 相对于 MPA 的核心优势。
- 剖析了
hash和history两种模式的底层原理。 - 掌握了
React Router如何将底层能力抽象成优雅的声明式组件。
掌握了这些,你不仅能自如地运用各种路由库,更能在遇到疑难杂症时,拥有直抵问题根源的洞察力。前端的世界日新月异,但这些根植于浏览器内核的原理,将是你技术道路上最坚实的基石。