Spring是如何解析XML的呢?
好了,我们接着方法doLoadBeanDefinitions继续分析:
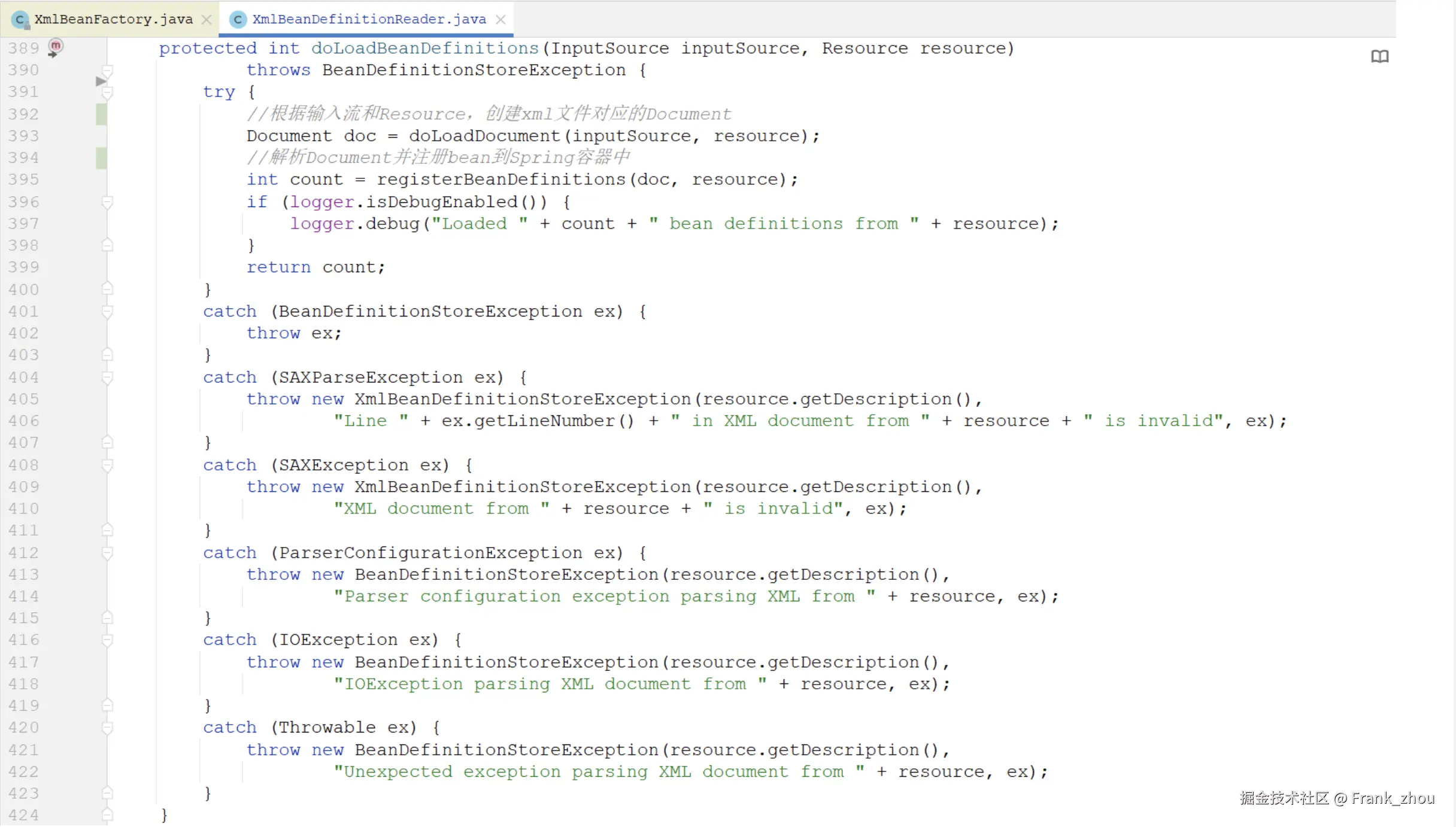 我们可以看到,在方法doLoadBeanDefinitions中,首先将封装好的inputSource及资源resource传递进了doLoadDocument方法中,通过方法的名称应该是把resource资源加载成一个Document对象,确实我们也看到了它返回了一个Document对象。
我们可以看到,在方法doLoadBeanDefinitions中,首先将封装好的inputSource及资源resource传递进了doLoadDocument方法中,通过方法的名称应该是把resource资源加载成一个Document对象,确实我们也看到了它返回了一个Document对象。
到这个方法看下:
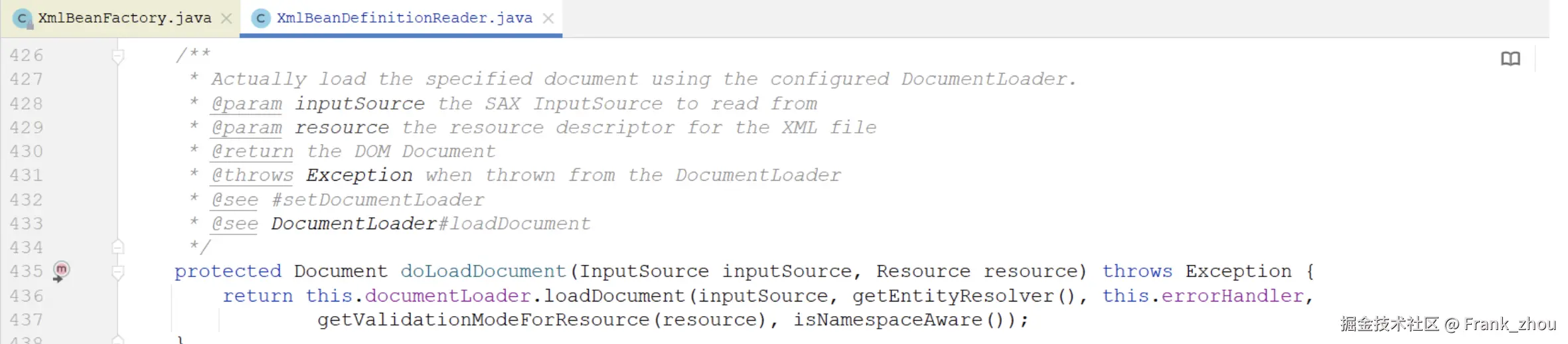
可以看到,XmlBeanDefinitionReader又将加载资源resource的任务,委托给了成员变量documentLoader来完成。那documentLoader又是什么呢?我们可以来看下这个成员变量:

可以看到,成员变量documentLoader的类型为DefaultDocumentLoader,通过类的名称,我们初步可以推测出它就是用来加载Document的一个组件。
loadDocument方法看一下。
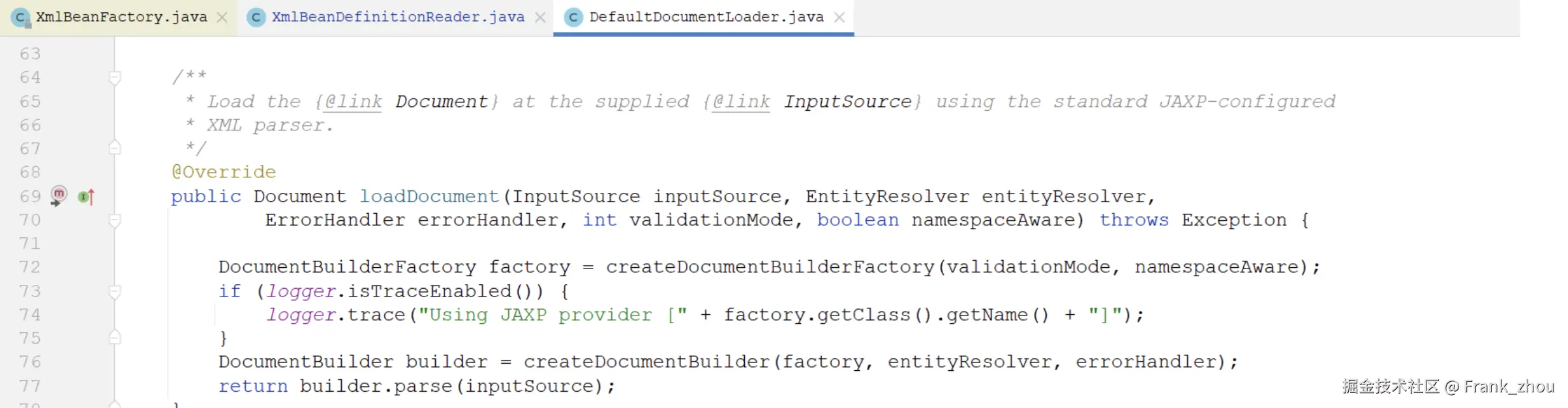
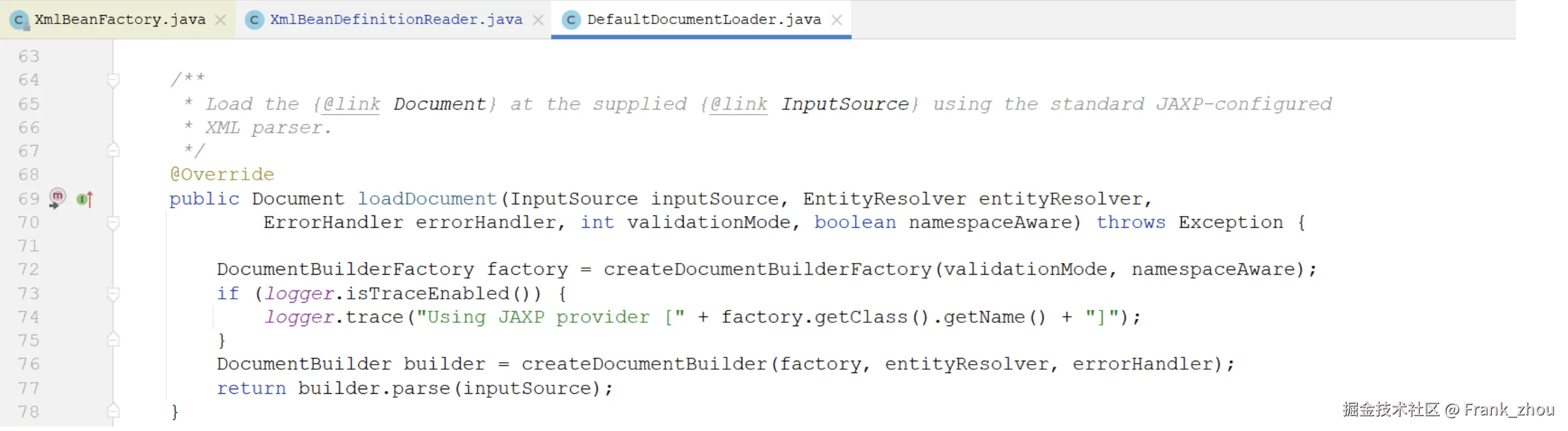
看到这里几乎就真相大白了,Spring其实就是通过DOM来解析xml文件的
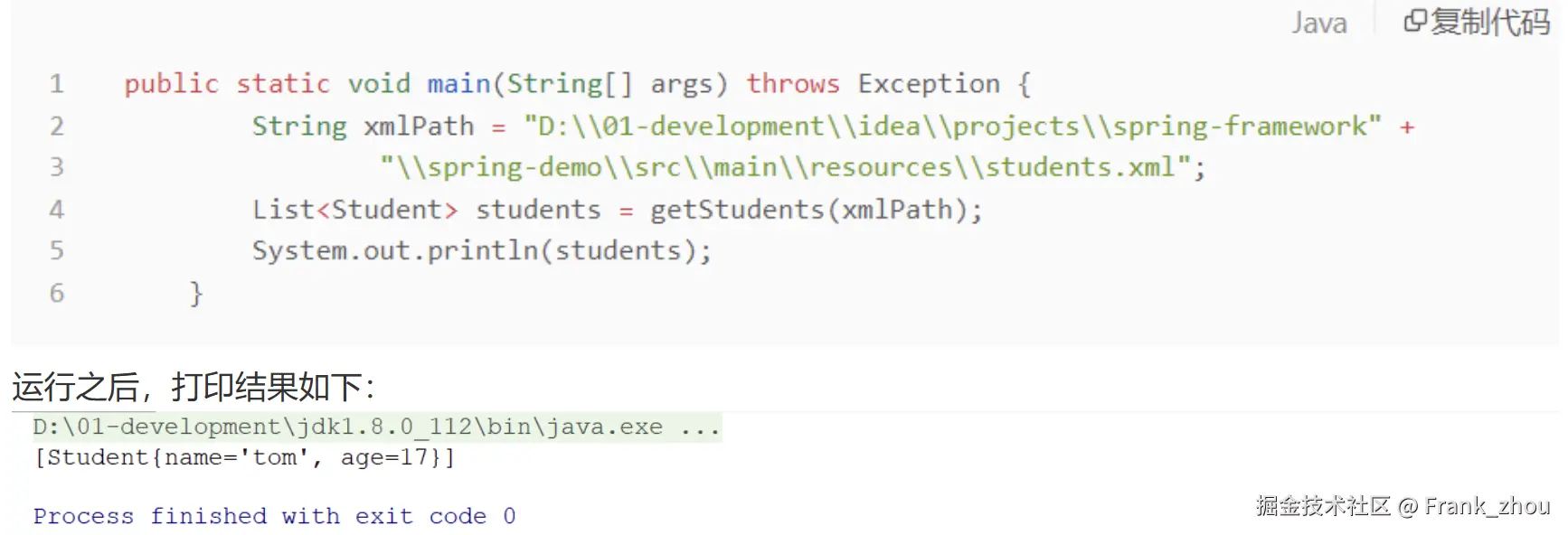
XML解析的示例:DOM解析
简单的实体
package com.ruyuan.container;
public class Student {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
student.xml
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student>
<name>tom</name>
<age>17</age>
</student>
</students>
获取Document
public static Document getDocument(String xmlPath) throws Exception {
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
return db.parse(xmlPath);
} catch (Exception e) {
throw new RuntimeException("文档解析失败...");
}
}首先,将xml文件的绝对路径,也就是xml文件在磁盘的位置,作为方法getDocument参数传递进去,然后通过DocumentBuilderFactory的newInstance方法,创建出一个DocumentBuilderFactory,再通过newDocumentBuilder方法得到DocumentBuilder对象。
可以看到,通过DocumentBuilder的parse方法解析xml文件,可以得到xml文件对应的Document对象,Document对象中就包含了student.xml中配置的所有信息。
方法getDocument暂时只是将指定路径下的xml文件加载成了Document对象,那具体如何解析Document对象,获取xml中配置的信息呢?我们再通过另外一个方法来解析下Document:
ini
public static List<Student> getStudents(String xmlPath) throws Exception {
// 1. 获取Document对象
Document document = getDocument(xmlPath);
// 2. 获取所有student节点
List<Student> students = new ArrayList<>();
NodeList studentNodes = document.getElementsByTagName("student");
// 3. 遍历节点并解析数据
for (int i = 0; i < studentNodes.getLength(); i++) {
Element studentEle = (Element) studentNodes.item(i);
Student student = new Student();
student.setName(studentEle.getElementsByTagName("name")
.item(0).getTextContent());
student.setAge(Integer.parseInt(studentEle.getElementsByTagName("age")
.item(0).getTextContent()));
students.add(student);
}
// 4. 返回结果
return students;
}可以看到,在getStudents方法中,我们调用刚才的getDocument方法先获取student.xml对应的Document对象,然后获取配置文件中的所有student标签依次来遍历它们,通过对student标签的解析获取标签中name标签和age标签中的数据,并封装到Student对象中返回。最后,我们再测试下刚才写的这些方法: