概述
之前做了一个公式识别软件 FreeTex,但遗留了一些问题。
因此,本次将软件从v0.3.0更新到v1.0.0,具体包含以下内容:
- 1.新增多模态大模型识别识别
- 2.优化不同屏幕分辨率下的显示
- 3.对深色背景图像进行反色处理
- 4.增加软件更新检查提示
视频演示:www.bilibili.com/video/BV1zK...
更新方式
此轮更新,对 mac 的版本也进行了同步升级,可通过以下地址下载。
windows系统:
- Github:github.com/zstar1003/F...
- 百度网盘:pan.baidu.com/s/1aPhwaSme... 提取码: 8888
mac系统:
- Github:github.com/zstar1003/F...
- 百度网盘:pan.baidu.com/s/1Rc7gKEY5... 提取码: 8888
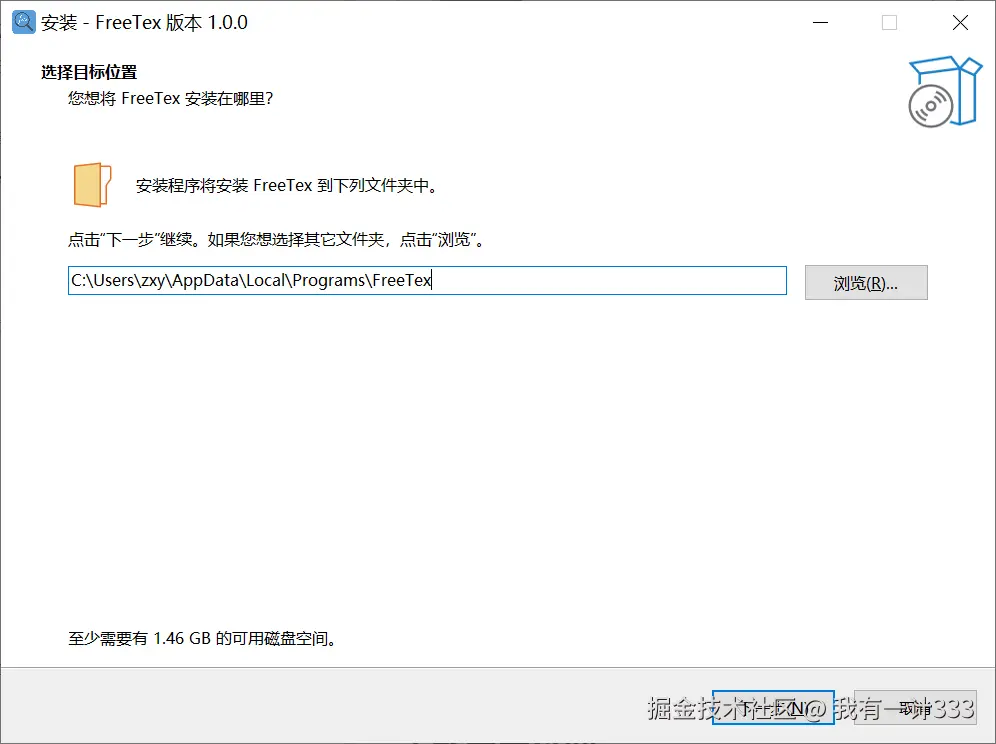
注:受到部分依赖的影响,windows版本若安装在含中文的路径下,会造成启动无反应的问题,下图中为默认的安装路径,如果用户名是中文,那么需要安装到其它盘的非中文路径中。
算法比较
1. 理论数值比较
之前有读者留言,本软件使用的 UniMERNet 算法在复杂公式(比如大括号、多行长公式)情况下识别效果不佳。
于是思考,是否有更好的算法模型。
正好看到百度的 PP-FormulaNet 文档中,对 MFR 的主流算法性能进行了对比,结果如下:
| 模型 | En-BLEU(%) | Zh-BLEU(%) | GPU推理耗时(ms)常规模式 / 高性能模式 | CPU推理耗时(ms)常规模式 / 高性能模式 | 模型存储大小(MB) |
|---|---|---|---|---|---|
| UniMERNet | 85.91 | 43.50 | 1311.84 / 1311.84 | - / 8288.07 | 1530 |
| PP-FormulaNet-S | 87.00 | 45.71 | 182.25 / 182.25 | - / 254.39 | 224 |
| PP-FormulaNet-L | 90.36 | 45.78 | 1482.03 / 1482.03 | - / 3131.54 | 695 |
| PP-FormulaNet_plus-S | 88.71 | 53.32 | 179.20 / 179.20 | - / 260.99 | 248 |
| PP-FormulaNet_plus-M | 91.45 | 89.76 | 1040.27 / 1040.27 | - / 1615.80 | 592 |
| PP-FormulaNet_plus-L | 92.22 | 90.64 | 1476.07 / 1476.07 | - / 3125.58 | 698 |
| LaTeX_OCR_rec | 74.55 | 39.96 | 1088.89 / 1088.89 | - / - | 99 |
数据来源:paddlepaddle.github.io/PaddleOCR/l...
从表中可以看到 PP-FormulaNet_plus 的指标性能远高于 UniMERNet,那么它的实战水准如何呢?下面来做具体测试。
2. PP-FormulaNet-PLUS-S 算法测试
PP-FormulaNet-PLUS 有多种型号,考虑到较大的模型会更消耗资源,因此下面采用 S 型号进行测试。
参考官方文档,测试代码如下:
ini
from paddleocr import FormulaRecognition
model = FormulaRecognition(model_name="PP-FormulaNet_plus-S", model_dir = "PP-FormulaNet_plus-S_infer")
output = model.predict(input="0000015.png", batch_size=1)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")运行代码后,会在 output/res.json 文件中生成结果。
先测试一张 UniMERNet-S 表现比较好的图像。
原始图像:
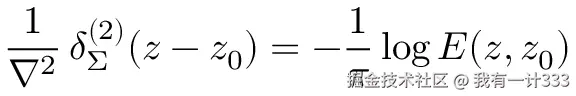
识别对比结果:

可以看到,PP-FormulaNet-Plus-S 虽然识别出了结果,但log的符号加了过多的装饰,整体效果不如 UniMERNet-S。
再测一张黑色背景的图片,UniMERNet-S 对深色背景的图片识别效果不好。
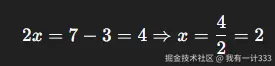
PP-FormulaNet-Plus-S 识别的结果如下,说明它也没有在深色背景的图像上训练过,效果很差。
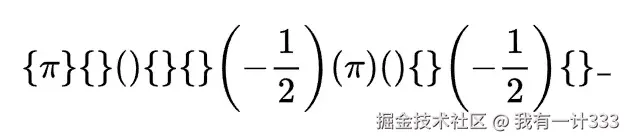
最后测一张读者反馈的多行复杂公式,UniMERNet-S 的效果不行,识别后无法正常渲染。
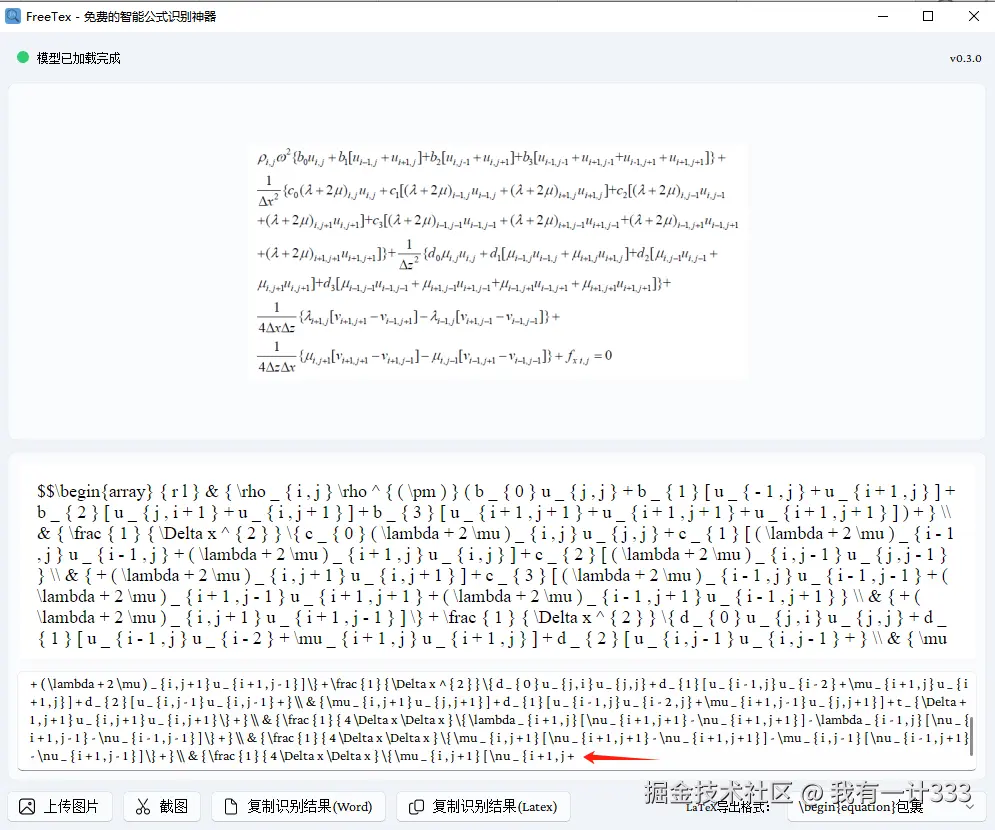
读者提供的识别截图
下面用 PP-FormulaNet-Plus-S 测试下,效果仍然不行,同样无法渲染出来,识别的原始结果如下:
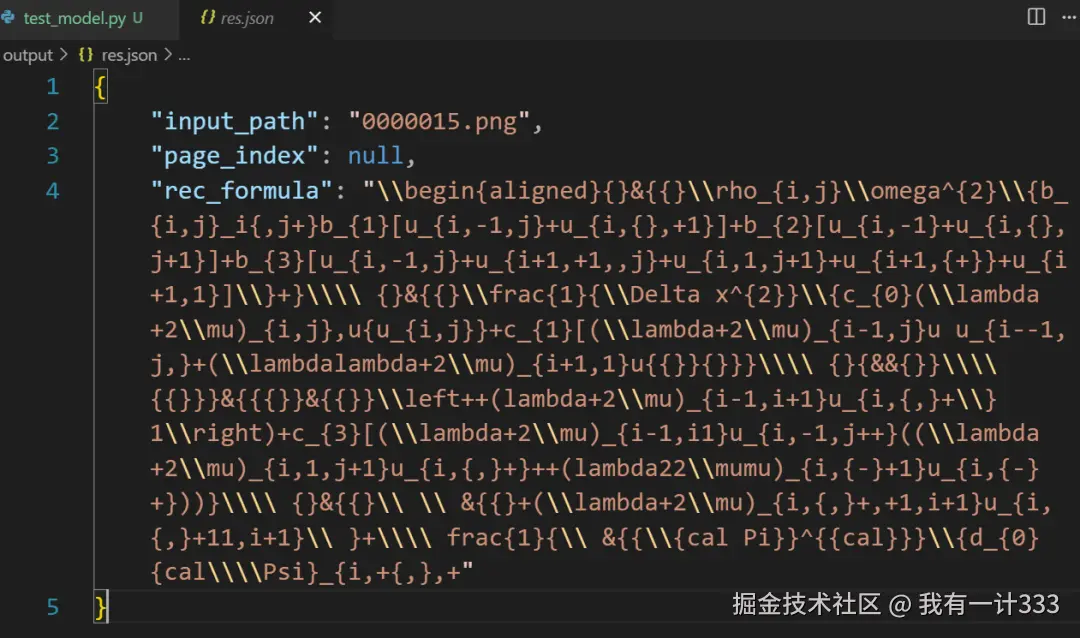
而且测试发现,PP-FormulaNet-Plus-S 总是倾向于输出多余的转义符``,可能和训练数据集的标签有关系。
综上所述,小模型的瓶颈已经基本显现,无论指标数值吹得天花乱坠,拿到真实图像上遛一遛,结果都差不多。
3. 多模态大模型算法测试
那么,如何突破算法瓶颈呢?
如今的版本答案就是直接上多模态大模型,大力出奇迹!
下面的测试脚本通过硅基流动的API,调用Qwen/Qwen2.5-VL-72B-Instruct多模态大模型。
python
import base64
from typing import List, Union
from openai import OpenAI
from PIL import Image
class FormulaRecognizer:
def __init__(self, api_key: str, model: str = "Qwen/Qwen2.5-VL-72B-Instruct"):
"""
初始化硅基流动API客户端
:param api_key: 从硅基流动平台获取的API Key
:param model: 模型名称,默认为Qwen/Qwen2.5-VL-72B-Instruct
"""
self.client = OpenAI(
api_key=api_key,
base_url="https://api.siliconflow.cn/v1" # 硅基流动API端点
)
self.model = model
def _encode_image(self, image_path: str) -> str:
"""将本地图像编码为base64格式"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def recognize(
self,
image_paths: Union[str, List[str]],
prompt: str = None,
max_tokens: int = 1024
) -> List[str]:
"""
识别图像中的数学公式并返回LaTeX代码
:param image_paths: 单张图像路径或图像路径列表
:param prompt: 自定义提示词,默认为专业公式识别指令
:param max_tokens: 最大输出token数
:return: LaTeX公式列表(单行格式)
"""
if isinstance(image_paths, str):
image_paths = [image_paths]
# 修改后的系统指令(禁止多行环境)
system_prompt = """你是一个专业的数学公式识别系统,请严格按照以下要求操作:
1. 专注识别图像中的数学公式、符号、希腊字母、运算符等
2. 输出标准LaTeX代码,确保可被编译器解析
3. 所有公式必须转换为单行格式(禁止使用\begin{{align}}等多行环境)
4. 多行公式用空格分隔或合并为单行
5. 不添加解释性文字,直接输出纯净的LaTeX代码"""
user_prompt = prompt or "请将图中的数学公式转换为精确的单行LaTeX代码,禁止使用多行环境,不要添加任何额外描述。"
results = []
for img_path in image_paths:
try:
Image.open(img_path).verify()
except Exception as e:
raise ValueError(f"无效图像文件: {img_path}, 错误: {str(e)}")
messages = [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{self._encode_image(img_path)}"
}
},
{"type": "text", "text": user_prompt}
]
}
]
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
max_tokens=max_tokens,
temperature=0.2
)
# 后处理:确保没有漏网的多行标记
latex_code = response.choices[0].message.content
latex_code = latex_code.replace("\begin{align}", "").replace("\end{align}", "")
latex_code = latex_code.replace("\begin{aligned}", "").replace("\end{aligned}", "")
latex_code = " ".join(latex_code.split()) # 合并多余空格
results.append(latex_code)
return results
# 使用示例
if __name__ == "__main__":
API_KEY = "your_api_key_here"
recognizer = FormulaRecognizer(api_key=API_KEY)
# 示例识别
latex_result = recognizer.recognize("formula.png")
print("识别结果:", latex_result[0])运行时,API_KEY 需要替换成自己的。如果未进行注册,可在硅基流动网站上进行注册。
网站地址:cloud.siliconflow.cn/i/bjDoFhPf
拿上面最难的第三张图片进行测试:
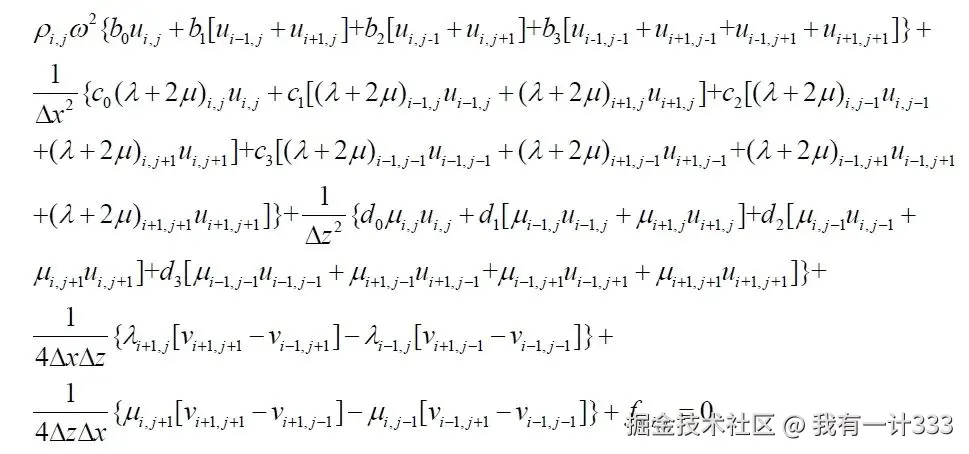
原始图像
识别效果很好,完美将多行公式识别组合成一行。
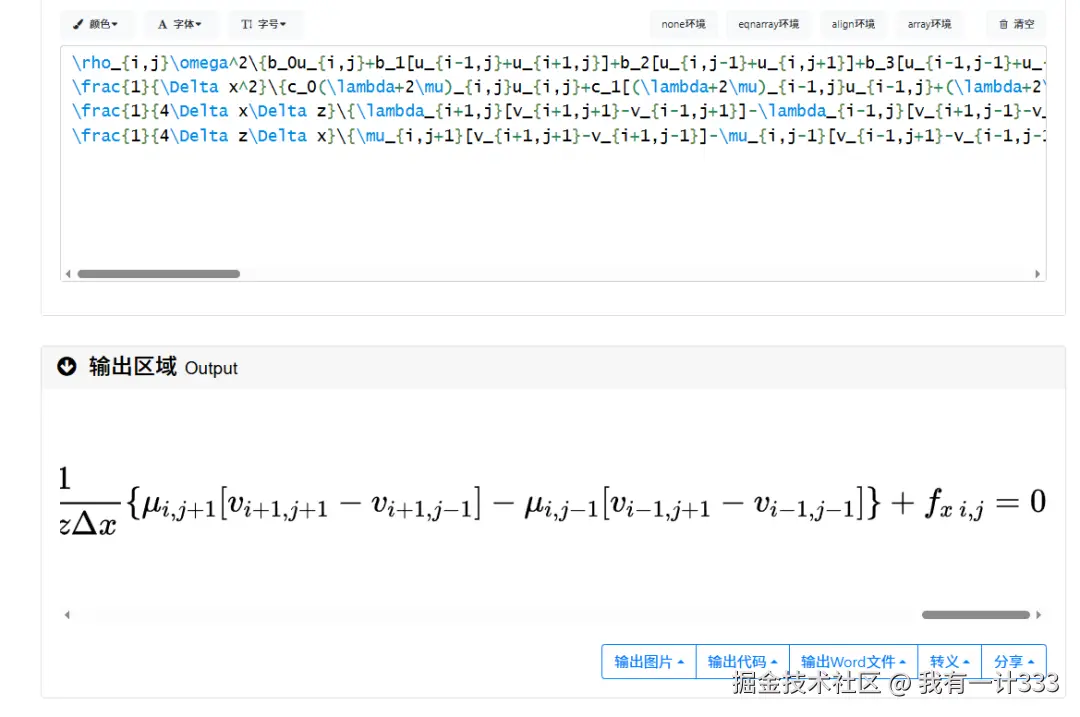
latexlive的可视化结果
代价是什么呢?当然是需要付费,毕竟多模态模型的成本较纯语言模型较高。
实测发现,根据公式长短,API的价格会有所不同,一般短公式0.001元/条;长公式价格在0.007元/条。
以平均价格0.005元/条计算,新用户的免费额度可以识别2800条公式,约等于免费。
更新内容详解
上面写这么多,实际上就是在解释为什么要引入多模态大模型。
这一节将对更新的内容进行具体阐述,并介绍如何操作。
1. 多模态大模型设置
在软件中,新增了多模态设置的按钮,点击后进入具体的设置界面。
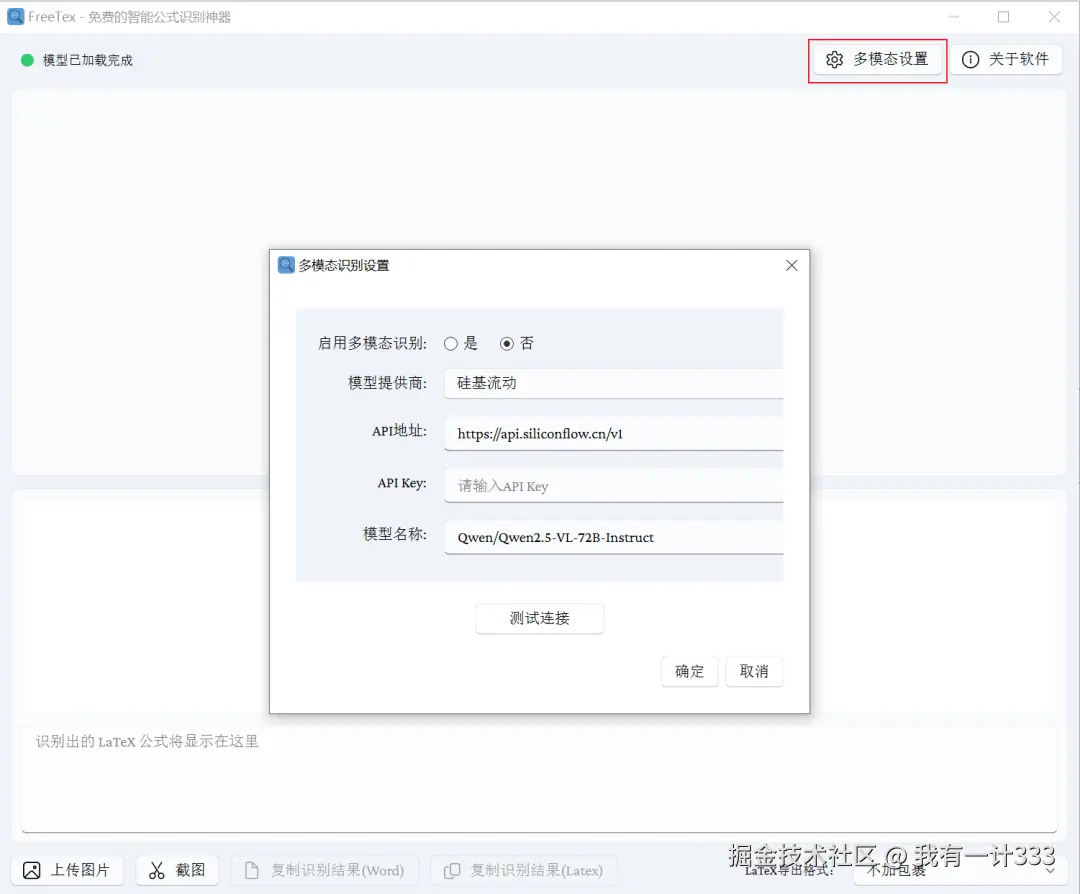
默认不启用,如需启用,可选择是选项。
模型提供商支持硅基流动和自定义,自定义模式兼容openai规范的模型提供商。
填入自己的API-Key,设置好模型后,点击测试连接,可以快速测试是否能连通。
如能连通,点击确定,相关信息就会保存到软件的配置文件config.json中。
设置完之后,再进行截图检测,就会切换使用多模态大模型进行识别。
2. 多分辨率UI显示优化
之前版本,没有适配不同分辨率的屏幕,导致软件在1080P分辨率的屏幕上显示正常,在2K及以上更高分辨率的屏幕上,按钮显示很小。
之前并不是没有考虑过解决该问题,只是因为如果适配高分辨率屏幕,截图逻辑会出现异常,看似简单的截图,一旦考虑到不同DPI,不同缩放,多屏幕拓展等各种情况后,就变得复杂起来。
有没有更好的解决方案呢?最简单的方法,就是不要重复造轮子,直接调用系统的截图方法。比如,windows默认可以通过快捷键win+shift+s触发系统截图。
这样修改,多分辨率适配和截图逻辑就能完美共存。
3. 深色背景图像识别优化
之前版本,对于深色背景图像识别效果不理想,因为训练集多是浅色背景。
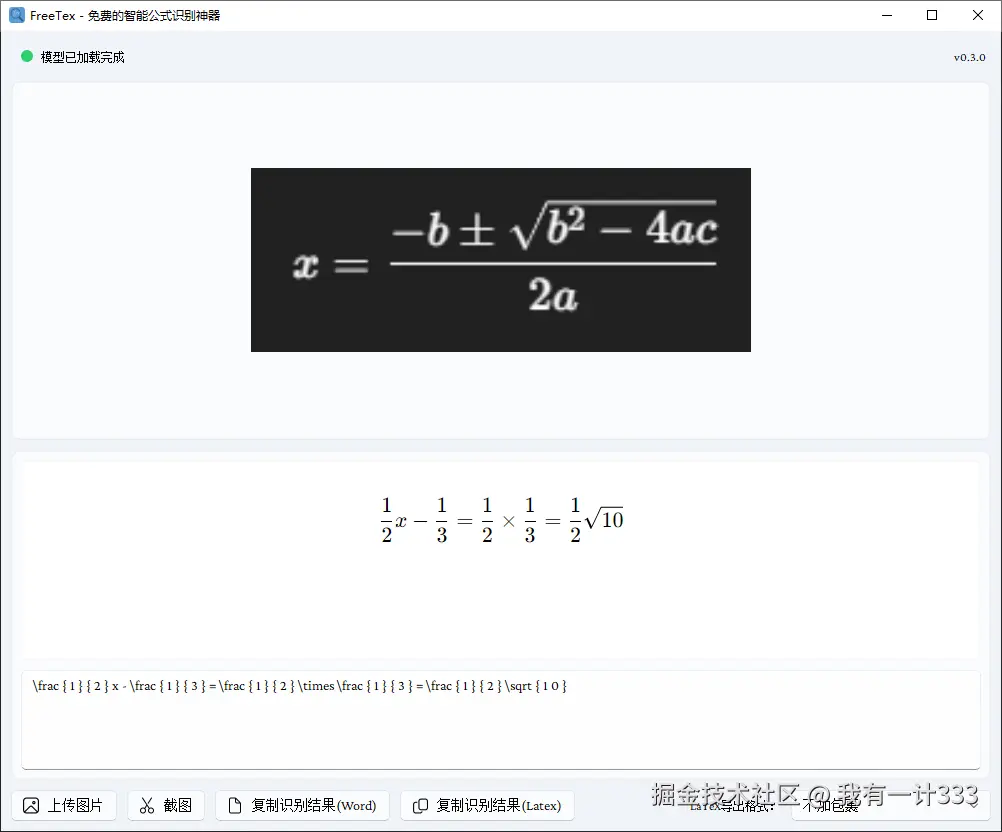
v0.3.0版本识别结果
在此版本中,对深色背景图像自动进行反色,可有效解决该问题。
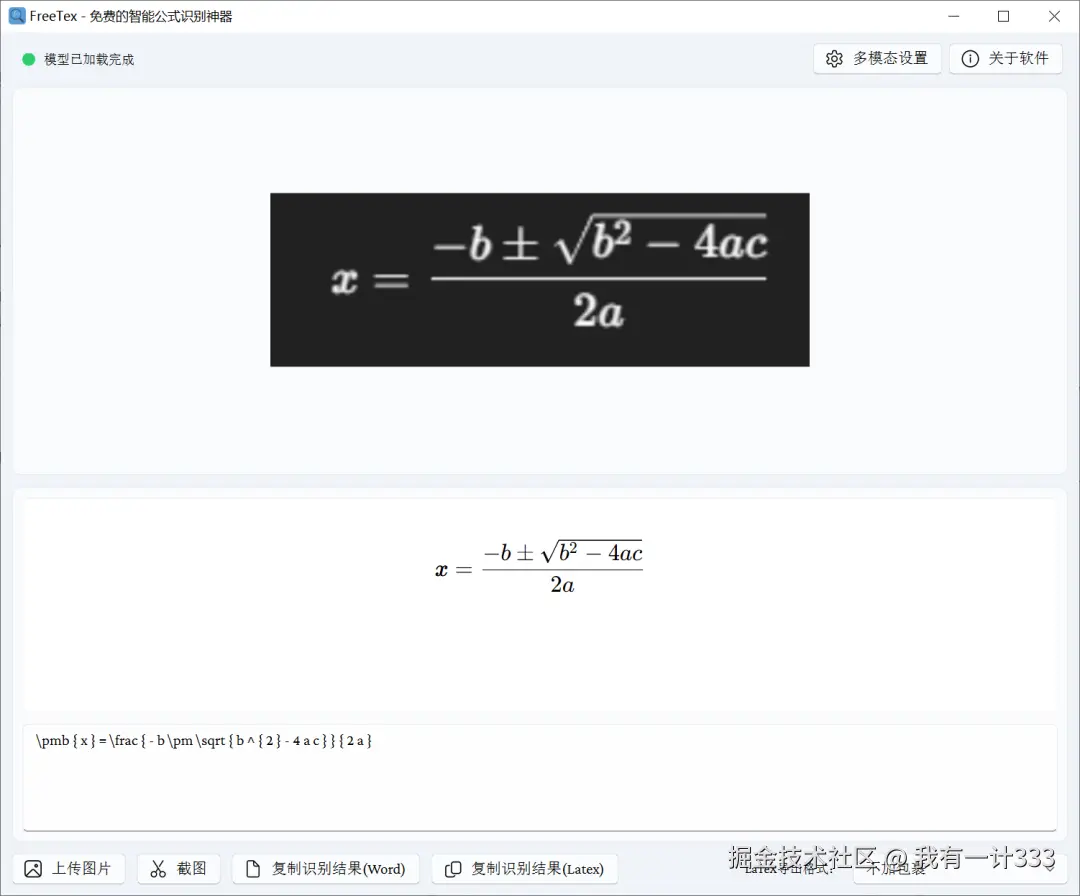
v1.0.0版本识别结果
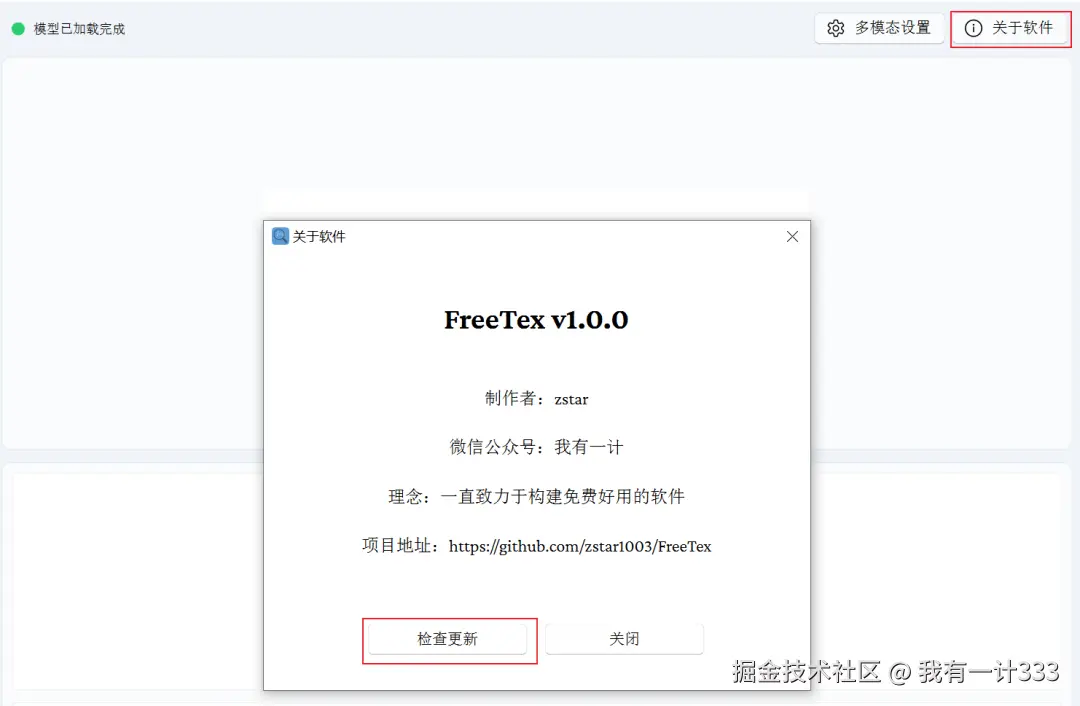
4. 软件更新检查
点击关于软件按钮,会出现软件信息弹窗,可点击检查更新,自动去 github 上查询最新版本,方便更新下载。