引言
在软件开发中,并发编程是提升程序性能和响应能力的关键。然而,传统基于线程和锁的并发模型往往伴随着高昂的资源开销和复杂的同步问题,如死锁、竞态条件等,这给开发者带来了巨大的心智负担。
Go 语言在设计之初就将并发视为一等公民,并提出了一套独特且高效的并发模型。它并非依赖传统的线程,而是通过 Goroutine 和 Channel ,遵循"通过通信来共享内存"的哲学,为并发编程提供了一种更简单、更安全的范式。本文将系统性地介绍 Go 并发的核心概念,并深入探讨如何通过 Worker Pool(工作池)模式进行实战。
一、轻量级并发体:Goroutine
Goroutine 是 Go 并发模型的基石。我们可以将其理解为一个由 Go 运行时(runtime)管理的、极其轻量级的线程。
- 开销小:每个 Goroutine 的初始栈空间仅为几 KB,远小于传统线程(通常为 MB 级别)。这使得我们可以在一个进程中轻松创建成千上万个 Goroutine,而无需担心系统资源耗尽。
- 调度高效:Goroutine 的调度由 Go 运行时负责,而非操作系统内核。这避免了昂贵的内核态与用户态之间的切换,使得并发执行的切换成本非常低。
启动一个 Goroutine 的语法非常简洁,只需在函数调用前使用 go 关键字。
go
package main
import (
"fmt"
"time"
)
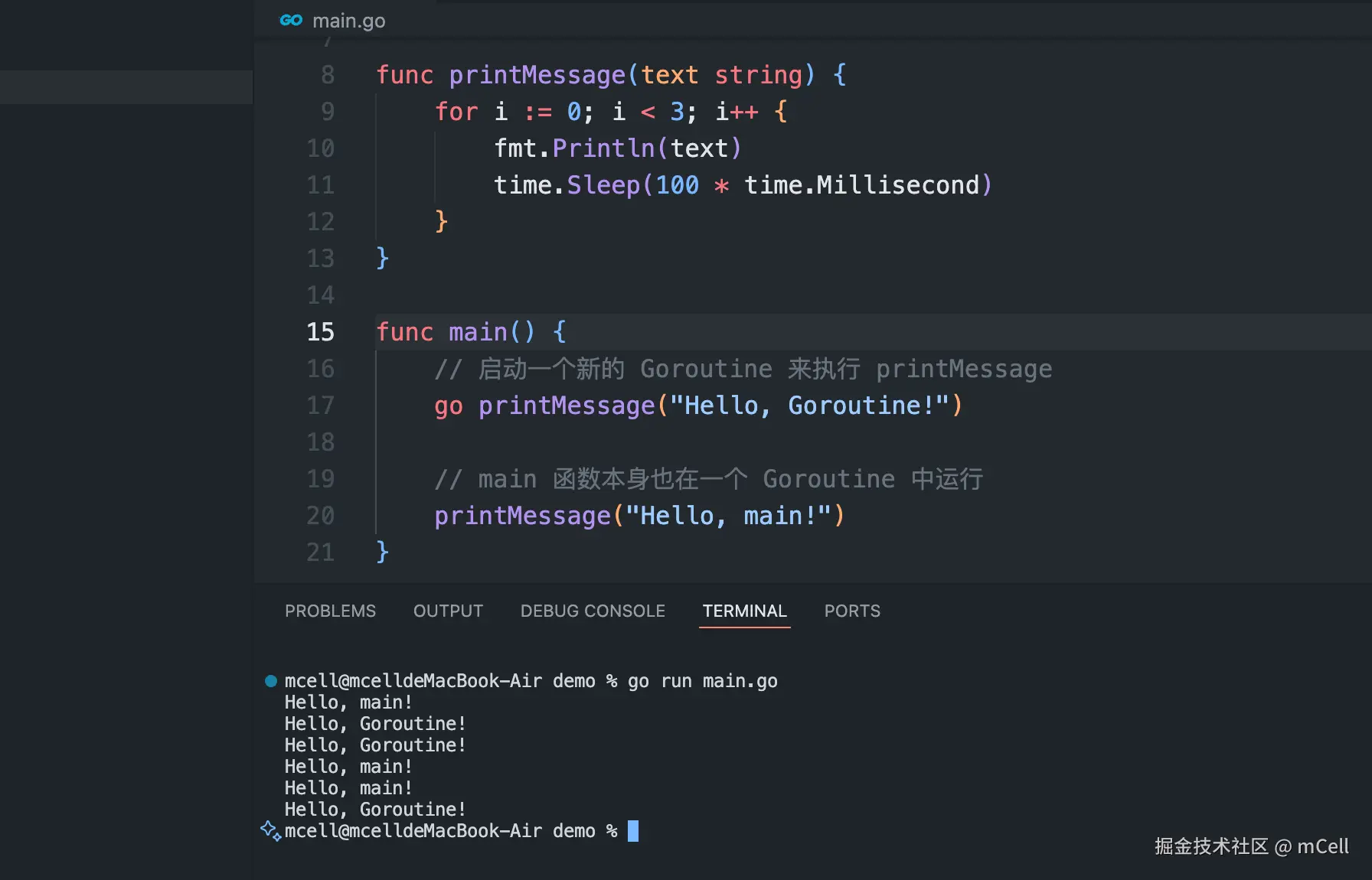
func printMessage(text string) {
for i := 0; i < 3; i++ {
fmt.Println(text)
time.Sleep(100 * time.Millisecond)
}
}
func main() {
// 启动一个新的 Goroutine 来执行 printMessage
go printMessage("Hello, Goroutine!")
// main 函数本身也在一个 Goroutine 中运行
printMessage("Hello, main!")
}在上述代码中,go printMessage(...) 创建了一个新的 Goroutine。程序会并发执行两个 printMessage 函数,因此你会看到两条消息交替输出。
二、Goroutine 间的通信桥梁:Channel
实现了任务的并发执行后,下一步就是解决 Goroutine 之间的协作问题。Go 语言不推荐使用共享内存加锁的方式进行通信,而是引入了 Channel(通道) 。
Channel 可以被视为一个类型化的、线程安全的消息队列。一个 Goroutine 可以向 Channel 发送数据,另一个 Goroutine 则可以从中接收数据,保证了数据流转的同步和安全。
- 发送操作 :
ch <- value - 接收操作 :
value := <-ch
操作符 <- 的方向指明了数据的流向。默认情况下,发送和接收操作都是阻塞 的------直到另一方准备好,操作才会完成。这使得 Channel 不仅是通信工具,也是一种强大的同步原语。我们使用内置的 make 函数来创建 Channel。
go
ch := make(chan int) // 创建一个用于传输 int 类型的 Channel关于 make 函数的说明
在 Go 语言中,make 是一个非常重要的内置函数,专门用于 初始化并分配 Slice(切片)、Map(映射)和 Channel(通道)这三种引用类型。
- 为什么需要
make? 对于 Slice、Map 和 Channel,它们的零值(zero value)是nil。一个nil的 Channel 是无法发送或接收数据的,同样,你也不能向一个nil的 Map 存入键值对。make的作用就是创建这些类型的实例,并为其分配好底层的、可用的数据结构,使其处于"就绪"状态。 makevsnew:初学者可能会混淆make和new。new(T)函数用于分配内存,它会返回一个指向类型T的零值的指针 (*T)。而make(T, ...)返回的是一个已初始化的、类型T的实例,而不是指针。对于我们的 Channel 来说,我们需要的是一个可用的 Channel 实例,而不是一个指向nilChannel 的指针,因此make是正确的选择。
现在,我们继续看 Channel 的完整示例:
go
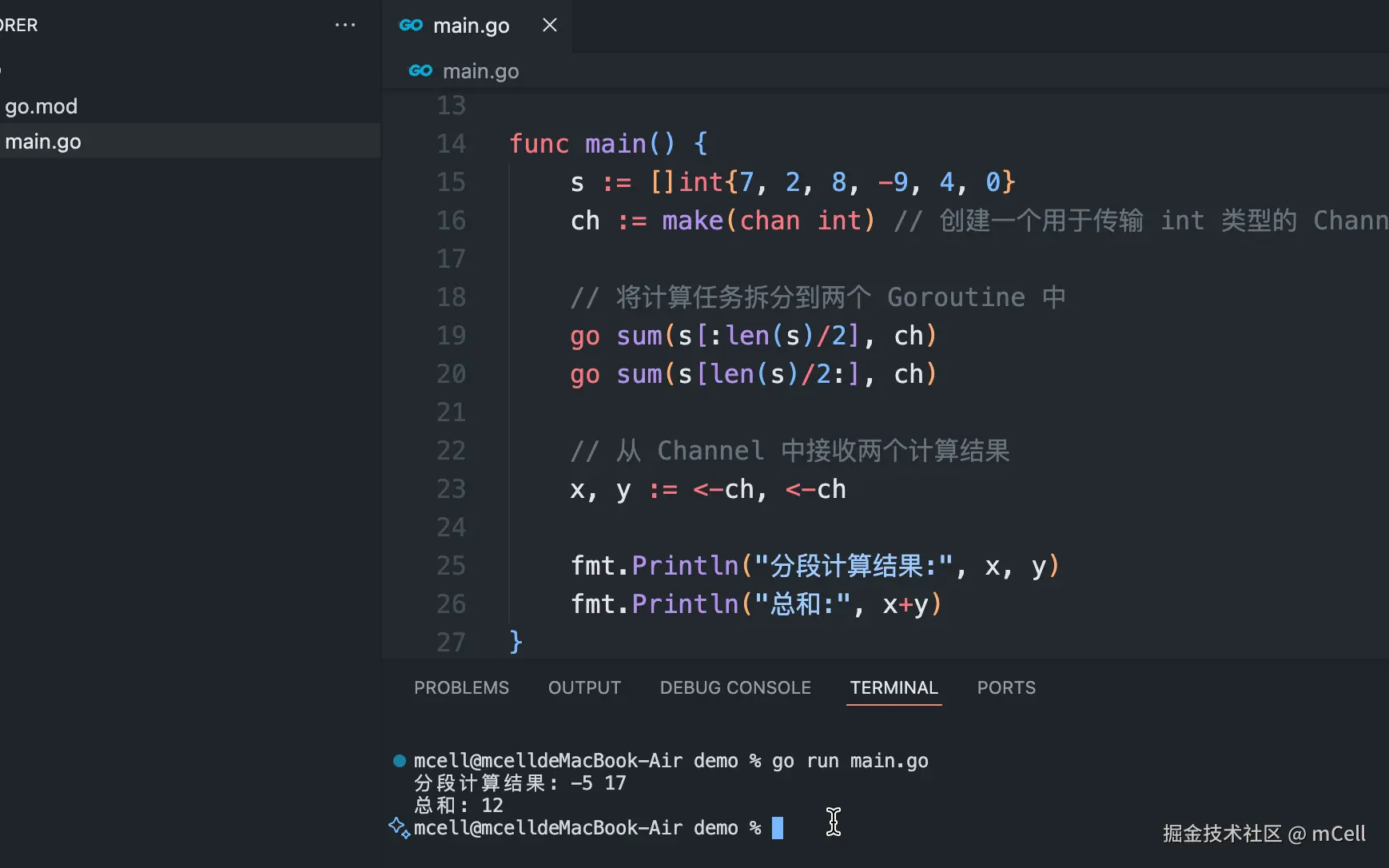
package main
import "fmt"
// 该函数计算切片的和,并将结果发送到 Channel
func sum(s []int, ch chan int) {
total := 0
for _, v := range s {
total += v
}
ch <- total // 将计算结果发送到通道 c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
ch := make(chan int) // 使用 make 创建 Channel
// 将计算任务拆分到两个 Goroutine 中
go sum(s[:len(s)/2], ch)
go sum(s[len(s)/2:], ch)
// 从 Channel 中接收两个计算结果
x, y := <-ch, <-ch
fmt.Println("分段计算结果:", x, y)
fmt.Println("总和:", x+y)
}在这个例子中,main Goroutine 在尝试从 Channel ch 接收数据时会阻塞,直到两个 sum Goroutine 完成计算并将结果送入 Channel。
三、实践模式:构建 Worker Pool(工作池)
尽管 Goroutine 开销很小,但在处理海量任务时,无限制地创建 Goroutine 仍然可能导致调度压力过大或资源耗尽。Worker Pool 是一种经典的并发设计模式,用于控制并发执行的任务数量,达到复用 Goroutine、平滑系统负载的目的。
其核心思想是:
- 创建一组(固定数量的)
workerGoroutine。 - 创建一个
jobsChannel 用于分发任务。 worker从jobsChannel 中获取任务并执行。- (可选)创建一个
resultsChannel 用于收集任务结果。
go
package main
import (
"fmt"
"time"
)
// worker 定义了工作单元的行为
// jobs 是一个只读 channel,results 是一个只写 channel
func worker(id int, jobs <-chan int, results chan<- int) {
for j := range jobs {
fmt.Printf("worker %d 开始处理 job %d\n", id, j)
time.Sleep(time.Second) // 模拟耗时任务
results <- j * 2
fmt.Printf("worker %d 完成处理 job %d\n", id, j)
}
}
func main() {
const numJobs = 5
const numWorkers = 3
// 使用 make 创建带缓冲的 channel
jobs := make(chan int, numJobs)
results := make(chan int, numJobs)
// 启动 3 个 worker
for w := 1; w <= numWorkers; w++ {
go worker(w, jobs, results)
}
// 发送 5 个任务到 jobs channel
for j := 1; j <= numJobs; j++ {
jobs <- j
}
close(jobs) // **关键步骤**: 关闭 jobs channel,通知所有 worker 任务已全部分发完毕。
// 收集所有任务的结果
for a := 1; a <= numJobs; a++ {
<-results
}
fmt.Println("所有任务已处理完成。")
}
代码要点解析:
close(jobs):这是该模式中的关键一步。当所有任务都发送到jobsChannel 后,我们必须关闭它。for j := range jobs循环在感知到 Channel 关闭且其中的值已取空后,会自动结束,从而使workerGoroutine 能够优雅地退出,避免了 Goroutine 泄漏。- 缓冲通道 :
make(chan int, numJobs)创建了一个带缓冲的 Channel。这意味着主 Goroutine 可以一次性将所有任务发送到jobsChannel,而无需等待worker立即接收,从而避免了阻塞。
总结
Go 语言通过 Goroutine 和 Channel 提供了一套强大而简洁的并发工具。理解并掌握其核心思想,能帮助我们构建出高性能、高健壮性的应用程序。
- 使用 Goroutine 作为并发执行的基本单位。
- 通过内置函数
make来创建和初始化 Channel。 - 利用 Channel 实现 Goroutine 间的类型安全通信和同步。
- 在需要控制并发粒度和资源消耗的场景下,应用 Worker Pool 模式。