本篇博客内容主要参考:ZOMI酱的视频。
本篇博客主要用于记录自己学习过程,可能存在犯错。请大家在学习过程中遇到疑惑还多查证。
本文内容框架:
- MoE的前世今生
a. MoE是什么
b. MoE架构发展过程(论文概述) - MoE架构原理
MoE的前世今生
MoE是什么?
MoE(Mixture of Experts)即专家混合模型,在当今流行的大模型架构中基本上已是不可或缺的一部分,根本原因是因为MoE设计可以节省训练成本,提升训练效率。
那么MoE到底是什么?
MoE是一种让模型"在不同输入情况下调用不同子网络"的架构设计思路。MoE就像一个"专家团队",每次输入进来,系统只调用其中一部分专家来处理,从而提升效率和模型容量。每个MoE层通常由一组N个专家和一个"门控网络(Gate Network)"构成。每个专家都有各自擅长的任务,而门控网络则是负责决定将什么任务分配个哪位专家。
为什么要用MoE?
传统 Transformer 模型存在一个矛盾:
- 更大的模型 --> 更强的能力;
- 更大的模型 --> 更高的计算代价
MoE 的目标就是为了解决这个矛盾:训练时只激活部分子模型(Experts)--> 节省算力,同时保持参数量巨大 --> 表现好,效率高。
下文将更详细的对MoE架构进行介绍,如果不想看MoE相关背景研究的话,可以直接跳到MoE架构原理
MoE架构发展过程
本文对每篇论文细节不做展开,只做概述。有兴趣的话可以自行搜索查阅哈。
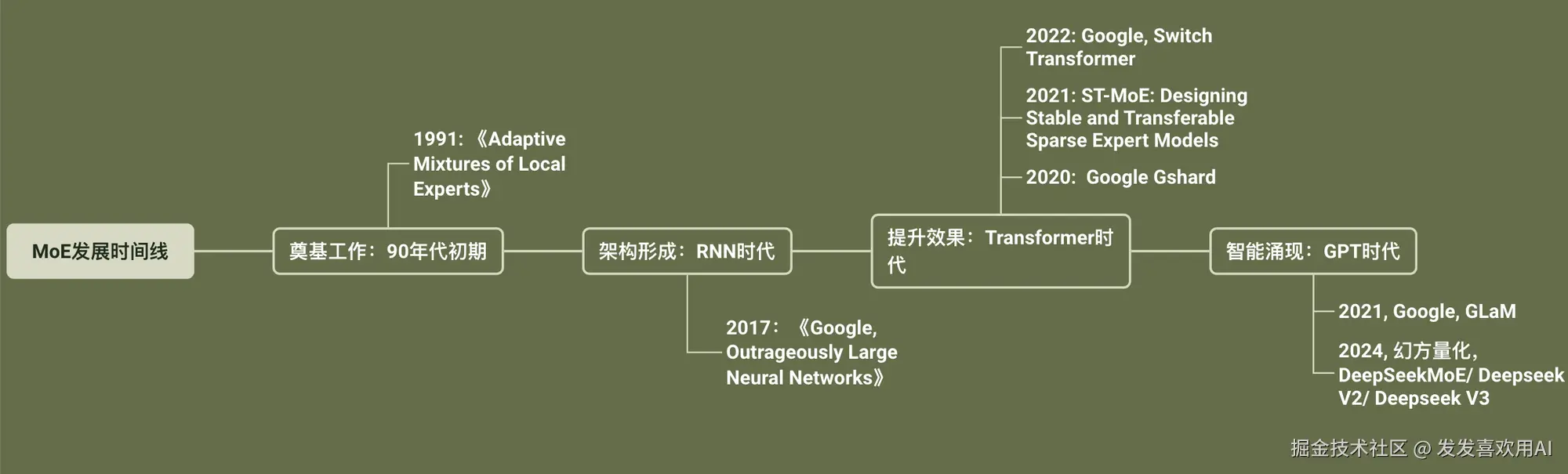
MoE发展时间线
-
奠基工作:90年代初期
《Adaptive Mixtures of Local Experts》(1991)是由去年获得图灵奖的 Geoffrey Hinton 等人提出的奠基性论文,目标是用于元音辨别任务。
多专家(Mixture of Experts)这个思想在这篇论文之前就已存在,但之前的设计倾向于让专家之间"协作"完成任务。而这篇论文则首次将专家之间的关系调整为"竞争"关系 ,通过改变损失函数(Loss) 实现专家间的竞争性选择,从而增强了模型的选择能力和泛化能力。
-
架构形成:RNN 时代的突破
《Outrageously Large Neural Networks》(2017)是 Google Brain 提出的划时代工作。它首次在实践中将 MoE 与 RNN 架构融合,构建出了真正可训练、可扩展、具备高容量稀疏激活能力的 MoE 网络结构。
-
论文中指出的主要挑战包括:
- GPU 不适合条件执行(if-else)
MoE 的稀疏激活机制对 GPU 并不友好,因为 GPU 更擅长统一的大规模并行计算而非条件分支逻辑。 - 需要 Large Batch Size
MoE 模型若 batch 太小会出现专家"偏食"现象。必须使用大 batch size 才能确保不同 expert 被充分调用。 - 额外的 Loss Terms 设计
训练中引入了额外的负载均衡损失(如 Load Balancing Loss),以避免某些专家被过度或完全忽略。 - 网络带宽成为瓶颈
多个 expert 分布在不同 GPU/TPU 上,通信开销大,带来分布式训练效率挑战。 - 大容量模型训练困难
虽然 MoE 的参数量很大,但稀疏激活让梯度传播路径减少,训练优化难度提升。
- GPU 不适合条件执行(if-else)
-
本文提出的经典模型架构
论文不仅提出了挑战,还构建了 MoE 的标准化实现框架,主要包括以下要点:
- MoE 计算公式
提出数学化描述的稀疏专家选择机制,为后续各种实现提供基础公式。 - Gating Network + Top-K 策略
门控网络负责根据输入内容选择最合适的 expert,具体做法是对所有专家打分后,仅保留 Top-K(如前两个专家) ,其余得分设为负无穷,从而获得稀疏性。 - 负载均衡机制
为了解决"某些专家被用太多、某些几乎不用"的问题,论文提出给门控网络的打分过程加入噪声扰动,让专家选择更加多样性,从而缓解专家偏食、提升训练稳定性。
- MoE 计算公式
-
-
提升效果:Transformer时代
- 《Gshard: Scaling Giant Models with Conditional Computation and Automatic Sharding》,这篇论文比较偏向于工程化。总而言之提出了一些提升训练效率的工程方法。
- 《ST-MoE: Designing Stable and Transferable Sparse Expert Models》:虽然现在混合专家机制通过稀疏性可以提升模型效果,但模型的训练过程并不稳定,本文提出了一些对应解决方案。
- 《Switch Transformer》,该论文主要完成的工作包括:简化了MoE路由算法、设计了一个优化之后的模型架构、减少了计算和通讯的耗时。其中论文中提出了一个很有趣的理论:在总的计算量不变前提下,当模型参数规模增大时,也能提升大模型效果。这代表着MoE架构可以把参数量给累上去,提升模型效果,且基于稀疏性的原则,这并不会增加计算成本。
-
智能涌现:GPT时代
-
Google,GLaM:...
-
幻方量化-DeepseekMoE(八股文重点) :
MoE专家可以使得模型规模在增加同时不增加算力成本,这使得MoE架构很有前途,但是MoE架构也存在着几个问题:
- 知识的混合(Knowledge Hybridity):因为有很多专家,我们该怎么让不同的专家学习不同的知识(怎么学?)
- 知识的冗余(Knowledge Redundancy):将token分配个各个专家,我们其实不知道每个专家具体学到了什么(学了什么?)
- 专家同质化与负载失衡:部分专家承担了过多计算任务,而其他专家利用率低。
针对上述问题,Deepseek给出了如下解决方案:
- 细颗粒度的专家划分(Fine-Grained Expert Segmentation) :在保持参数量不变的前提下,将每个专家的参数量减少,但是让专家的总数变多,从而细化每个专家所学习的知识;
- 独立共享专家(Shared Expert Islolation) : 设置独立的共享专家 - 即该专家知道的都是一些common knowledge, 并让它参与到其他细化专家的计算过程。如此便可以让其他专家的领域知识更加细化,也同时减少了知识的冗余。
- 动态专业化路由(Dynamic Specialization Routing/DSR) :DSR通过门控网络动态选择最相关专家,确保每个输入仅激活少量专家,从而降低计算成本。DSR还通过负载均衡机制,避免某些专家过载或限制,确保专家利用率均衡。
-
MoE架构原理
MoE核心原理可视化
- MoE基本原理
-
- 两个重要概念:
-
- 门控网络(Gating Network):~决定了当一个新的token(词元)进入到模型时,对应激活哪个专家对其进行计算。
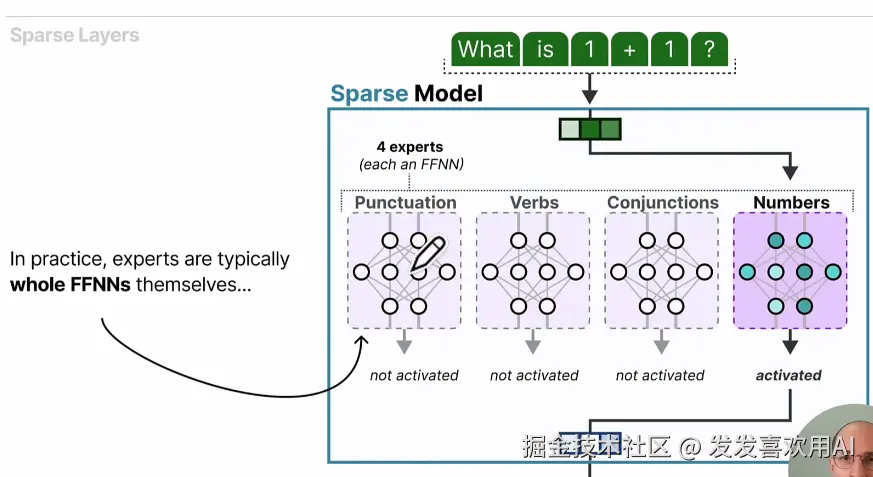
- 专家(Expert):~是一个抽象概念,每个专家其实是一个FFNN(前馈神经网络)
- 注意⚠️:所谓专家并不代表着它们精通不同领域的知识,这里的专家是按照句法信息(syntactic information)进行划分的,例如:动词、介词、名词等。
从Decoder Only到稀疏模型
首先,让我们来从上到下对Decoder Only模型架构进行拆解,这能帮助我们更好地了解MoE原理。
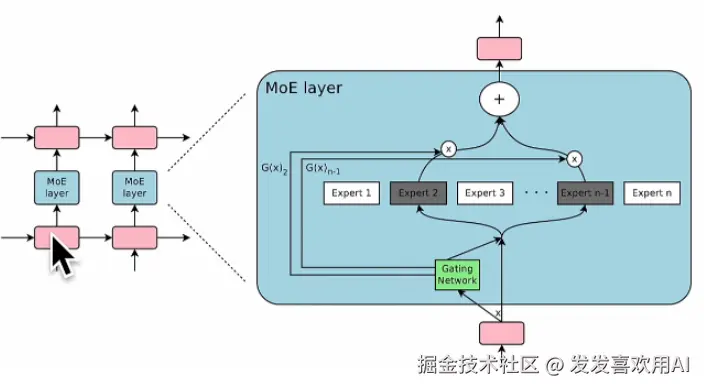
Decoder-Only架构由多个Decoder Block堆叠而成。每个 Decoder Block 通常包含两层 LayerNorm,分别用于Masked Self-Attention 和 FFNN 的输入,外加对应的残差连接。Masked Self-Attention 用于建模序列的前向依赖,FFNN 则由两层全连接层和中间的激活函数组成。而 MoE 架构之所以能在扩增模型参数量的同时节省算力其实就是在 FFNN 部分做的文章。
MoE 模型在 FFNN 部分引入稀疏激活(每次只激活部分)的多个专家模块,每个专家模块都是一个单独的,小体量的 FFNN层!所以 MoE 的架构长得如下图所示,图中标注的 FFNN 块是当前输入中被选中的专家,而其他专家不参与计算。
那么问题来了:我们怎么知道每次计算对应选择哪个专家呢?
- 路由(Router)原理
-
- 一个概念上的区分:
-
- 门控网络:~ 指用于计算不同Expert 激活权重的具体神经网络模块;
- 路由:~ 指根据门控网络输出的权重来选择激活哪些Expert的过程。
路由机制决定了每次输入调用哪些专家。门控网络是由一个FFNN和Softmax所组成的。门控网络的FFNN对当前token输入进行投影,计算各Expert的分数,确定哪些Expert被激活以参与后续计算。而Softmax层将所计算的打分转化为"概率分布",方便分析。
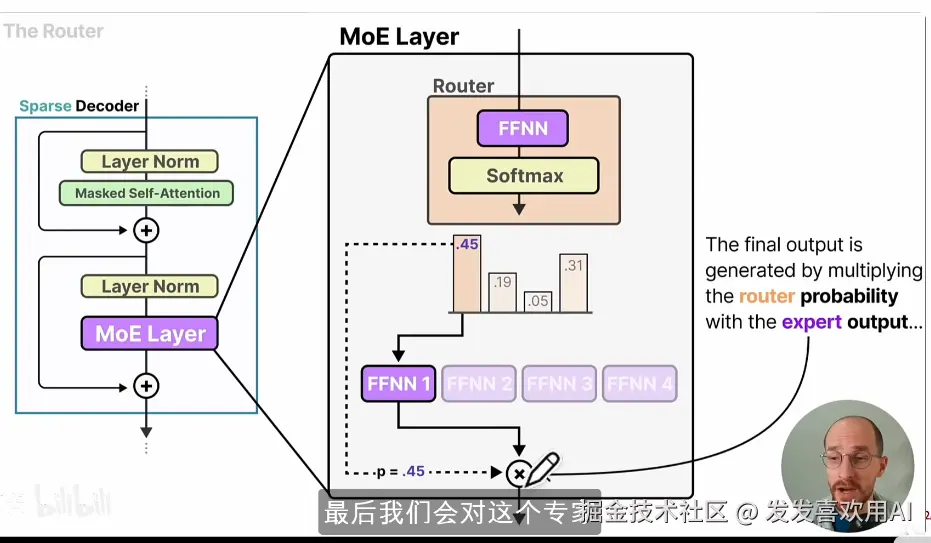
路由/门控网络组成
- 专家选择(Keep Top-K)
在路由过程中,当我们根据输入token计算得到了各Expert的分数之后,我们通常只会选择Top-K个专家来进行计算,K值通常设置为 1 或 2。
- 负载均衡(Load Balancing)
不同Expert在训练过程中被选中参与计算的频率可能会出现不均的情况。例如:某些专家被过度使用,而另一些专家则被打入冷宫,学不到东西。这会影响模型容量利用率和泛化能力,这个现象被称为****负载失衡(Load Imbalance)** **。
为了解决少数Expert被频繁选中导致负载失衡的问题,会在训练中引入一个 **辅助损失(Auxiliary Loss) **,即负载均衡Loss ,用于惩罚不同Expert被选中的概率差异,鼓励门控网络平衡地选择各Expert,从而达到负载均衡。
- 辅助损失(Auxiliary Loss)
为了计算辅助损失,我们首先会计算每个专家在当前batch中被选中的总概率和总次数,这个值被称为 Importance(重要性系数)。
Importance 的具体含义是:
对于一个给定的 Expert,它在当前 batch 中被分配到多少 token(或者说被分配了多大的概率和权重)。可以理解成衡量每个专家重要性的一个指标,这是一个相对局部指标。
在实现时:对于每个Expert,我们会累加当前 batch 内所有 token 被分配给该 Expert 的概率。如果一个 Expert 被频繁选中, 它的 Importance 就会较大;如果一个 Expert 很少被选中,它的 Importance 就会较小。
举个例子:
假设当前有 4 个 Expert, 门控网络对 8 个 token 的分配概率如下:
-
- Expert 1: 3.2
- Expert 2: 2.5
- Expert 3: 1.8
- Expert 4: 0.5
此时,Expert 1的 Importance 最大,说明它在当前 batch 中被使用得最大,而 Expert 4被使用得最少。
为了量化 Importance 分布的均衡程度,我们计算其 Coefficient of Variation (CV) ,这是一个相对全局指标,衡量全部专家的重要性分布均衡程度,它定义为:
当 CV 值越高,说明部分 Expert 被选中过度使用,而部分 Expert 很少被选中,负载失衡严重;当 CV 值越低,说明所有 Expert 被均匀使用。
在训练过程中,我们将:
作为辅助损失(Auxiliary Loss)的核心,乘以一个常数权重后加入总损失,用于惩罚负载失衡。
通过最小化 Auxiliary Loss,模型会通过反向传播自动调整门控网络参数,使得未来各 Expert 被选中的概率更加均匀,从而实现负载均衡(Load Balancing),充分利用 MoE 架构的模型容量,避免部分 Expert 长期闲置影响泛化能力。
- 专家容量(Expert Capacity)
每个 Expert 在一次前向传播中最多能够接受和处理的 token 数(或样本数)的上限。
为什么需要"专家容量"?
在MoE架构中,每个输入 token 会通过门控网络选择 Top-1 / Top-2 Expert 进行处理。如果不限制,每个 Expert 可能在单次前向中被分配过多 token,导致:显存溢出,加载失衡,训练效率低下等问题。
- 模型架构(Architecture)- MoE层计算过程
上面我们逐一过了MoE架构中的各个组成部分与重要设计,现在让我们整体的来梳理一遍 MoE 层的整个计算过程。
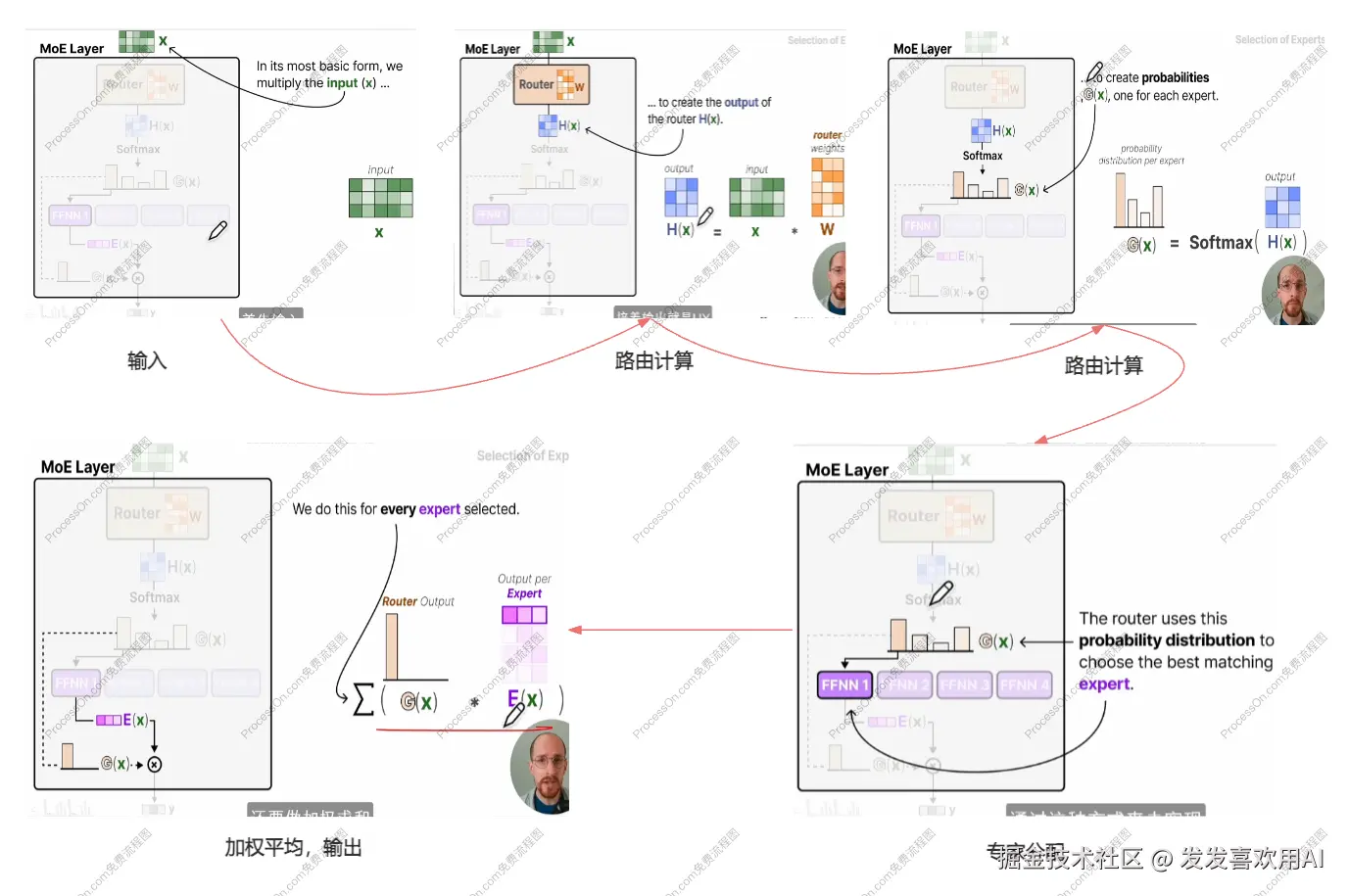
MoE层计算过程
如上图所示,在 MoE 层中首先我们输入当前需要被处理的 token。将 token 与门控网络内部FFNN进行矩阵乘法,从而得到每个专家的打分,再利用 Softmax 将打分进行映射得到概率分布。根据 Softmax 的概率值以及Keep Top-k 规则来激活对应的专家进行计算。如果选择了多个专家的话,需要对结果进行加权求和,即可得到最终输出。