今天我们来学习这一题大模型开发的面试真题!
字节面试官:「谈一谈你对 RAG 的理解?** 」
简要回答
我理解RAG本质上是为了解决大模型"知识时效性差"和"容易幻觉"这两个核心痛点而提出的技术方案。
它的核心思路就是不让模型完全依赖训练时学到的参数化知识,而是在回答问题之前先去外部知识库里检索相关的文档片段,然后把这些实时检索到的内容作为上下文喂给模型,让模型基于真实资料来生成答案。
这样既能让模型回答最新的信息,又能大幅降低胡编乱造的概率,特别适合企业内部知识问答、文档分析这类对准确性要求很高的场景。
详细回答
我先说说为什么会有RAG这个技术出现。咱们都知道大模型虽然很强大,但它的知识其实是"冻结"在训练那个时间点的,比如GPT-4的训练数据截止到2023年某个时间,那它就不可能知道之后发生的事情。
而且模型有时候会很自信地给出一些看似合理但完全错误的答案,这就是我们常说的"幻觉问题"。对于企业应用来说,这两点是致命的,因为客户问的往往是最新的产品信息、内部的业务流程,模型如果瞎编一通,那后果不堪设想。
RAG就是专门来解决这个问题的。它的全称是Retrieval-Augmented Generation,直译过来就是"检索增强生成"。
核心逻辑其实挺直观的,就是在模型生成答案之前,先让它去"查资料"。
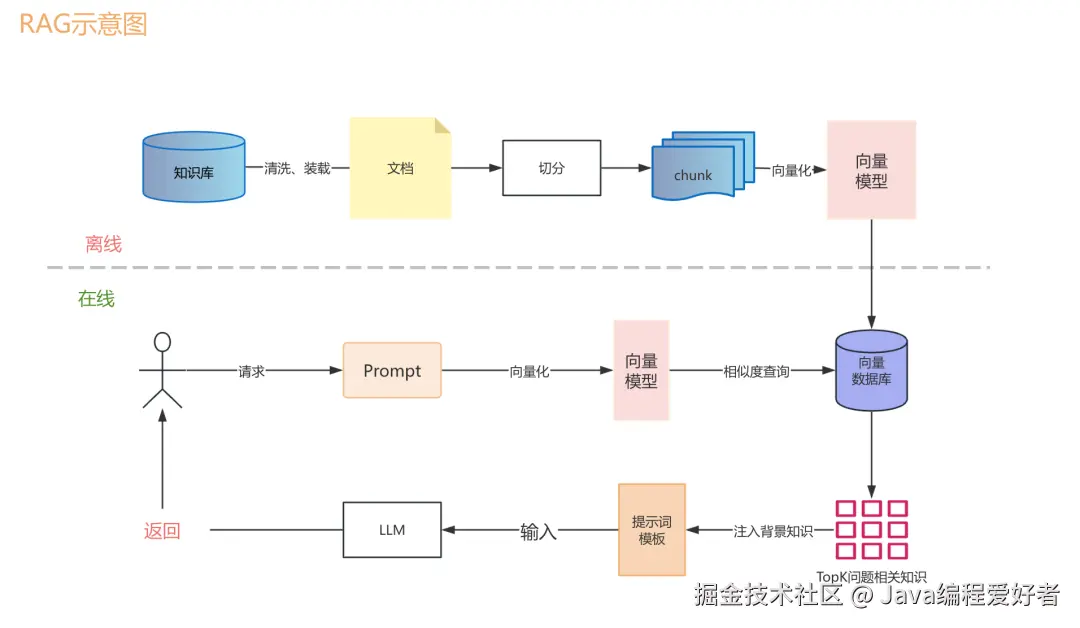
具体的工作流程是这样的:首先,用户提出一个问题,比如"公司今年Q3的销售额是多少";然后系统会把这个问题转成向量,去事先建好的向量数据库**里做相似度搜索,找出最相关的几段文档内容;接着把这些检索到的文档片段和用户的原始问题一起拼接成一个完整的Prompt,喂给大模型;最后模型基于这些真实的参考资料来生成回答。
我举个实际项目中的例子来说明一下。假设我们在做一个企业内部的智能客服系统,后台有大量的产品文档、FAQ、操作手册等资料。首先我们要做的是文档预处理,把这些资料切成合适大小的片段,然后用Embedding模型**把每个片段转成向量存到向量数据库里,这个过程我们叫做"离线索引构建"。
代码实现起来大概是这样:
ini
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 文档切片
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)
# 向量化并存储
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings
)这样离线的索引就建好了。当用户真正来提问时,我们会把问题也转成向量,然后去向量库里做相似度检索,找出最相关的Top K个文档片段。检索这一步代码很简洁:
ini
# 用户提问
query = "如何重置账户密码?"
# 检索相关文档
relevant_docs = vectorstore.similarity_search(query, k=3)
# 构建完整的Prompt
context = "\n".join([doc.page_content for doc in relevant_docs])
prompt = f"根据以下参考资料回答问题:\n{context}\n\n问题:{query}"
# 调用大模型生成答案
response = llm.generate(prompt)这里有个关键点需要解释一下,就是为什么要用向量检索而不是传统的关键词搜索?
因为向量检索能够理解语义,比如用户问"怎么改密码"和文档里写的"密码重置流程",虽然字面上不完全匹配,但在向量空间里它们是非常接近的,所以能够准确召回。这就是Embedding模型的价值所在。
当然,RAG也不是银弹,它也有自己的挑战。
- 第一个是召回质量问题,如果检索出来的文档根本不相关或者漏掉了关键信息,那后面模型再厉害也是巧妇难为无米之炊。
- 第二个是上下文长度限制,如果检索回来的文档太多太长,可能会超出模型的Token限制,这时候就需要做Rerank或者进一步的精简。
- 第三个是实时性和成本的平衡,因为每次问答都要做一次向量检索,对向量数据库的性能要求还是挺高的。
我在实际项目中的经验是,RAG特别适合那种知识密集型、对准确性要求高、且知识会频繁更新的场景。比如我之前做过的法律咨询助手、企业内部知识库问答、医疗文献检索这些项目,RAG的效果都非常好。
因为它既保留了大模型强大的语言理解和生成能力,又通过外挂知识库的方式补上了知识时效性和准确性的短板,可以说是当前AI应用落地最成熟、最实用的技术路线之一。