大家好,我是java1234_小锋老师,最近写了一套【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts)视频教程,持续更新中,计划月底更新完,感谢支持。今天讲解 基于jieba实现词频统计
视频在线地址:
2026版【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts+爬虫) 视频教程 (火爆连载更新中..)_哔哩哔哩_bilibili
课程简介:
本课程采用主流的Python技术栈实现,Mysql8数据库,Flask后端,Pandas数据分析,前端可视化图表采用echarts,以及requests库,snowNLP进行情感分析,词频统计,包括大量的数据统计及分析技巧。
实现了,用户登录,注册,爬取微博帖子和评论信息,进行了热词统计以及舆情分析,以及基于echarts实现了数据可视化,包括微博文章分析,微博IP分析,微博评论分析,微博舆情分析。最后也基于wordcloud库实现了词云图,包括微博内容词云图,微博评论词云图,微博评论用户词云图等功能。
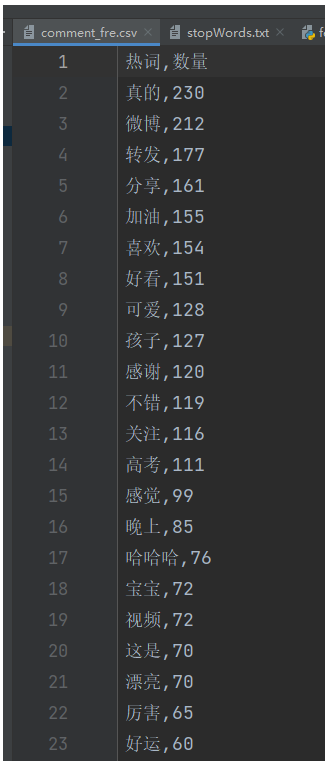
基于jieba实现词频统计
我们来实现下微博舆情热词分析,对微博评论信息进行词频统计。
首先第一步,从数据库获取所有微博评论信息,然后遍历每条评论信息,进行分词,过滤掉停用词,最后统计出每个词出现的次数,排个序,就能找到热词。
第一步,数据库查询所有评论信息。
通过Pymsql实现,先定义一个dbUtil.py数据库工具类
"""
数据库连接工具
作者 : 小锋老师
官网 : www.python222.com
"""
from pymysql import Connection
def getCon():
"""
获取数据连接
:return: 数据库连接
"""
con = Connection(
host="localhost", # 主机名
port=3308, # 端口
user="root", # 账户
password="123456", # 密码
database="db_weibo", # 数据库
autocommit=True # 设置自动提交
)
return con
def closeCon(con: Connection):
"""
关闭数据库连接
:param con: 数据库连接
:return:
"""
if con:
con.close()再新建commentDao.py,操作评论信息的数据访问对象,实现查询所有评论信息的方法
"""
用户评论信息 数据访问对象
"""
from util import dbUtil
def getAllComment():
"""
获取所有评论信息
:return:
"""
con = None
try:
con = dbUtil.getCon()
cursor = con.cursor()
sql = "SELECT * from t_comment where text!=''"
cursor.execute(sql)
return cursor.fetchall()
except Exception as e:
print(e)
con.rollback()
return None
finally:
dbUtil.closeCon(con)jieba分词后,我们还需要进行过滤过滤数据,单个字以及停顿词。
词频统计实现代码:
"""
微博评论信息分词 词频统计
"""
import re
import jieba
import pandas as pd
from dao import commentDao
def outCommentFreToCsv(sorted_wfc_list):
"""
词频统计后,写入到csv
:param sorted_wfc_list:
:return:
"""
df = pd.DataFrame(sorted_wfc_list, columns=['热词', '数量'])
df.to_csv('comment_fre.csv', index=False)
def getStopWordsList():
"""
获取停顿词
:return:
"""
return [line.strip() for line in open('stopWords.txt', encoding='UTF-8').readlines()]
def cut_comment():
"""
分词
:return:
"""
allCommentStr = " ".join([comment[1].strip() for comment in commentDao.getAllComment()])
seg_list = jieba.cut(allCommentStr) # 精准模式分词
return seg_list
def word_fre_count():
"""
词频统计 过滤数据,单个字以及停顿词
:return:
"""
seg_list = cut_comment()
stopWord_list = getStopWordsList()
# 正则去掉数字,单个字以及停顿词
new_seg_list = []
for s in seg_list:
number = re.search('\d+', s)
if not number and s not in stopWord_list and len(s) > 1:
new_seg_list.append(s)
# 词频统计
wfc = {}
for w in set(new_seg_list):
wfc[w] = new_seg_list.count(w)
# 排序
sorted_wfc_list = sorted(wfc.items(), key=lambda x: x[1], reverse=True)
return sorted_wfc_list
if __name__ == '__main__':
# print("/".join(cut_comment()))
# print(getStopWordsList())
outCommentFreToCsv(word_fre_count())运行后,写入到csv文件。