本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
关于SQL语句的面试题中,有两个被面试官问到的频率特别高,一个是SQL优化,另外一个则是索引失效。
接下来我们就来一一进行盘点,索引失效的场景到底有哪些。
准备工作
我们先来创建一张订单表,并为该表生成100w+的数据,这样SQL语句所对应的执行计划会更加准确,表结构如下:
SQL
CREATE TABLE `tony_order` (
`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`product_id` int NOT NULL COMMENT '商品ID',
`user_id` int NOT NULL COMMENT '用户ID',
`status` tinyint NOT NULL COMMENT '状态',
`discount_amount` int NOT NULL COMMENT '总金额',
`total_amount` int NOT NULL COMMENT '打折金额',
`payable_amount` int NOT NULL COMMENT '实际支付金额',
`receiver_name` varchar(255) DEFAULT NULL COMMENT '收件人名称',
`receiver_phone` varchar(255) DEFAULT NULL COMMENT '收件人手机号',
`receiver_address` varchar(255) DEFAULT NULL COMMENT '收件人地址',
`note` varchar(255) DEFAULT NULL COMMENT '备注',
`payment_time` datetime NULL DEFAULT NULL COMMENT '支付时间',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id` DESC) USING BTREE,
INDEX `idx_product_id`(`product_id` ASC) USING BTREE,
INDEX `idx_user_id_total_amount`(`user_id` ASC, `total_amount` ASC) USING BTREE,
INDEX `idx_create_time`(`create_time` ASC) USING BTREE,
INDEX `idx_update_time`(`update_time` ASC) USING BTREE,
INDEX `idx_status`(`status` ASC) USING BTREE,
INDEX `idx_receiver_phone`(`receiver_phone` ASC) USING BTREE,
INDEX `idx_receiver_name`(`receiver_name` ASC) USING BTREE,
INDEX `idx_receiver_address`(`receiver_address` ASC) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 ROW_FORMAT = Dynamic;接下来我们来一一验证下索引失效的场景。
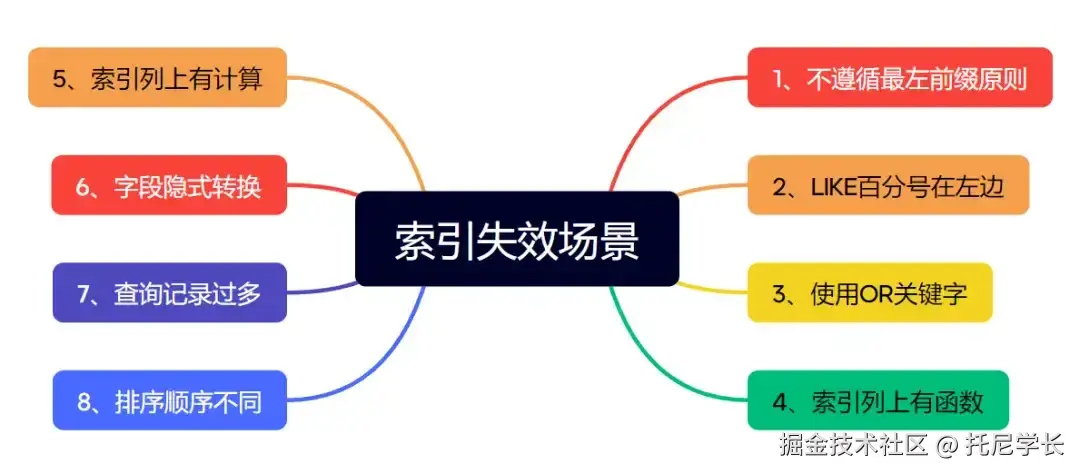
索引失效场景
1、不遵循最左前缀原则
SQL
SELECT * FROM tony_order WHERE total_amount = 100;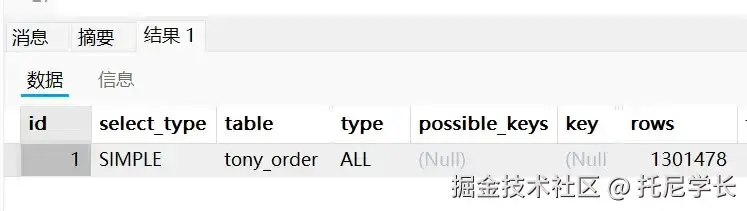
我们从执行计划中可以看到,这条SQL语句走的是全表扫描,即使创建了索引idx_user_id_total_amount也没有生效。
但由于其total_amount字段没有在联合索引的最左边,不符合最左前缀原则。
SQL
SELECT * FROM tony_order WHERE user_id = 4323 AND total_amount = 101;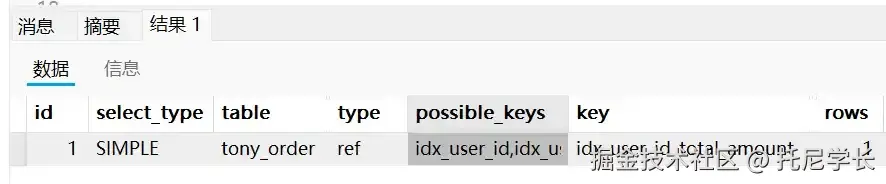
当我们把user_id这个字段补上之后,果然就可以用上索引了。
在MySQL 8.0 版本以后,联合索引的最左前缀原则不再那么绝对了,其引入了Skip Scan Range Access Method机制,可对区分度较低的字段进行优化。
感兴趣的同学可以去看下,本文中就不过多展开描述了。
2、LIKE百分号在左边
SQL
SELECT * FROM tony_order WHERE receiver_address LIKE '%北京市朝阳区望京SOHO';
SELECT * FROM tony_order WHERE receiver_address LIKE '%北京市朝阳区望京SOHO%'; 执行上面这两条SQL语句,结果都是一样的,走了全表扫描。
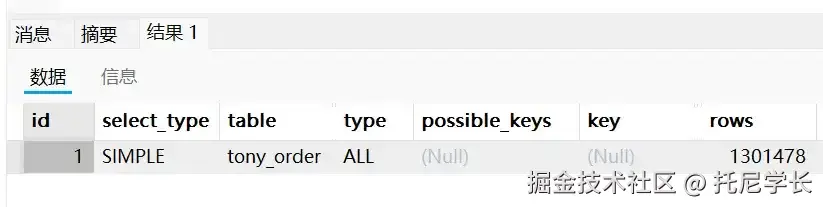
接下来我们将SQL语句改为%在右边,再执行一次看看。
SQL
SELECT * FROM tony_order WHERE receiver_address LIKE '北京市朝阳区望京SOHO%'; 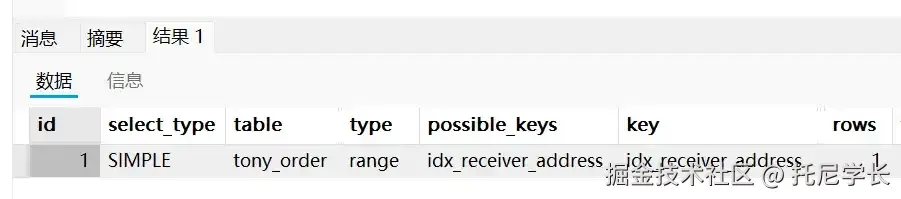
这个原理很好理解,联合索引需要遵循最左前缀原则,而单个索引LIKE的情况下,也需要最左边能够匹配上才行,否则就会导致索引失效。
3、使用OR关键字
有一种说法,只要使用OR关键字就会导致索引失效,我们来试试。
SQL
SELECT * FROM tony_order WHERE receiver_name = 'Tony学长' OR user_id = 41323;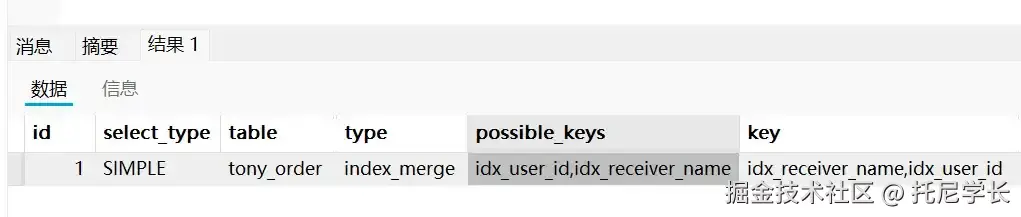
从结果中我们可以看到,索引并没有失效,聪明的查询优化器将receiver_name和user_id两个字段上的索引进行了合并。
接下来我们再换个SQL试试。
SQL
SELECT * FROM tony_order WHERE receiver_phone = '13436669764' OR user_id = 4323;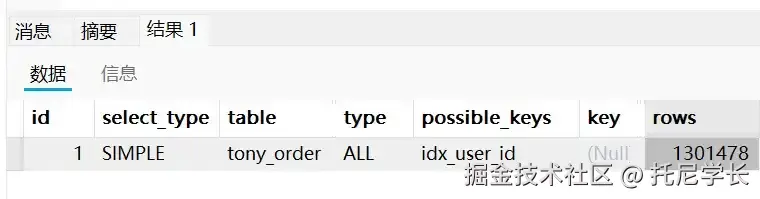
这次确实索引失效了,由于receiver_phone这个字段上并没有创建索引,所以无法使用索引合并操作了,只能走全表扫描。
有的同学会问,那为什么user_id上的索引也失效了呢?
因为一个字段走索引,另一个字段走全表扫描是没有意义的,反而不如走一次全表扫描查找两个字段更有效率。
所以,有时候索引失效未必是坏事,而是查询优化器做出的最优解。
4、索引列上有函数
SQL
SELECT * FROM tony_order WHERE ABS (user_id) = 4323; 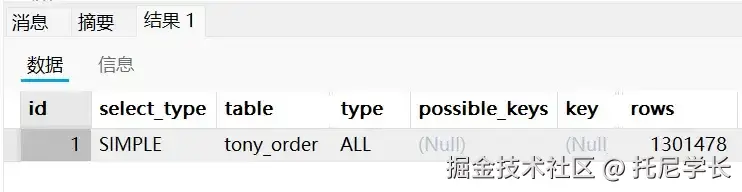
SQL
SELECT * FROM tony_order WHERE LEFT (receiver_address, 3) 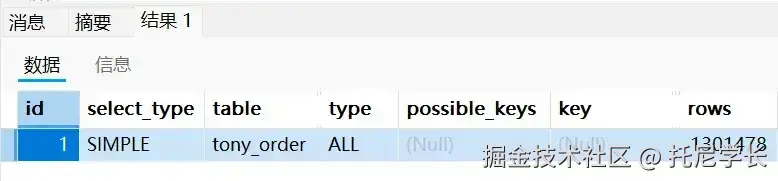
这个不用过多解释了,就是MySQL的一种规范,违反就会导致索引失效。
5、索引列上有计算
SQL
SELECT * FROM tony_order WHERE user_id + 1 = 4324; 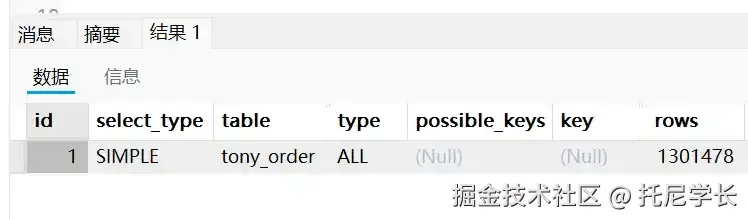
这个也不用过多解释了,还是MySQL的一种规范,违反就会导致索引失效。
6、字段隐式转换
SQL
SELECT * FROM tony_order WHERE receiver_phone = 13454566332;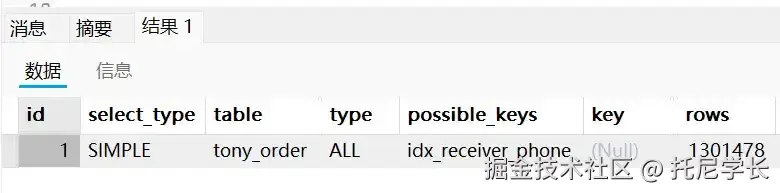
手机号字段明明是字符类型,却在SQL中不慎写成了数值类型而导致隐式转换,最终导致receiver_phone字段上的索引失效。
SQL
SELECT * FROM tony_order WHERE receiver_phone = '13454566332';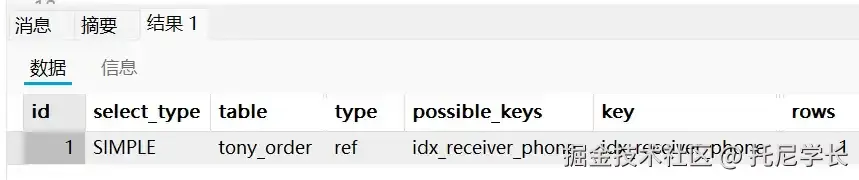
当我们把手机号加上单引号之后,receiver_phone字段的索引就生效了,整个天空都放晴了。
SQL
SELECT * FROM tony_order WHERE product_id = '12345';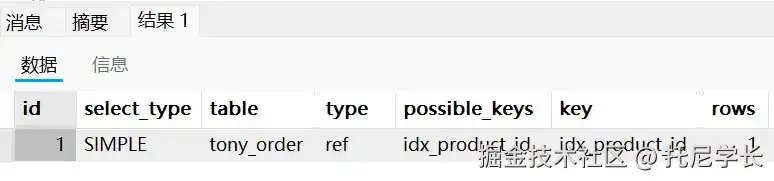
我们接着尝试,把明明是数值型的字段写成了字符型,结果是正常走的索引。
由此得知,当发生隐式转换时,把数值类型的字段写成字符串类型没有影响,反之,但是把字符类型的字段写成数值类型,则会导致索引失效。
7、查询记录过多
SQL
SELECT * FROM tony_order WHERE product_id NOT IN (12345,12346);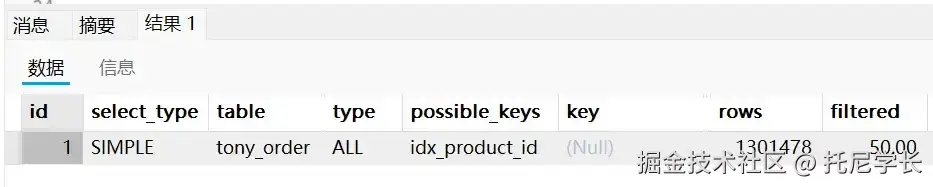
那么由此得知,使用NOT IN关键字一定会导致索引失效?先别着急下结论。
SQL
SELECT * FROM tony_order WHERE status NOT IN (0,1);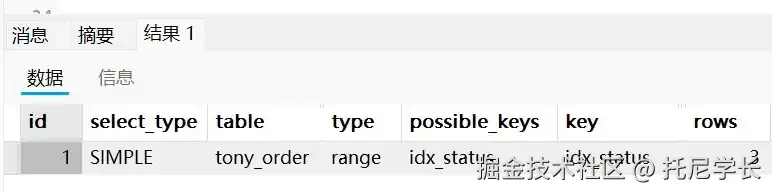
从执行计划中可以看到,status字段上的索引生效了,为什么同样使用了NOT IN关键字,结果却不一样呢?
因为查询优化器会对SQL语句的查询记录数量进行评估,如果表中有100w行数据,这个SQL语句要查出来90w行数据,那当然走全表扫描更快一些,毕竟少了回表查询这个步骤。
反之,如果表中有100w行数据,这个SQL语句只需要查出来10行数据,那当然应该走索引扫描。
SQL
SELECT * FROM tony_order WHERE status IN (0,1);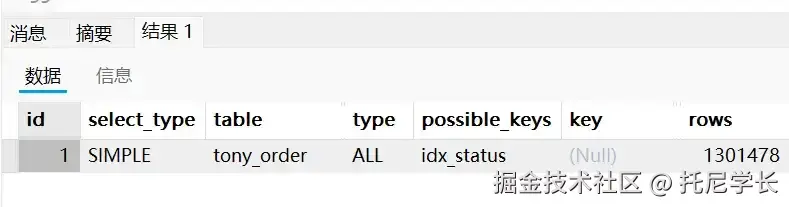
同样使用IN关键字进行查询,只要查询出来的记录数过于庞大,都会通过全表扫描来代替索引扫描。
SQL
SELECT * FROM tony_order WHERE status = 0;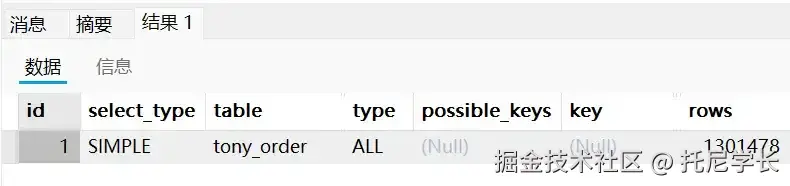
甚至我们不使用IN、NOT IN、EXISTS、NOT EXISTS这些关键字,只使用等号进行条件筛选同样会走全表扫描,这时不走索引才是最优解。
8、排序顺序不同
SQL
SELECT * FROM tony_order ORDER BY user_id DESC,total_amount ASC 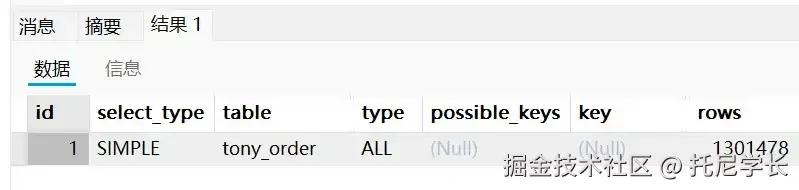
我们可以看下,这条SQL语句中的user_id用了降序,而total_amount用了升序,所以导致索引失效。
SQL
SELECT * FROM tony_order ORDERBY user_id ASC,total_amount ASC
而下面这两条SQL语句中,无论使用升序还是降序,只要顺序一致就可以使用索引扫描。