基础开发工具
文章目录
-
- 基础开发工具
-
- [1. 软件包管理器](#1. 软件包管理器)
-
- [1.1 Linux软件安装发展过程](#1.1 Linux软件安装发展过程)
- [1.2 软件包和软件包管理器](#1.2 软件包和软件包管理器)
- [1.3 安装源](#1.3 安装源)
- [2. 编辑器vim](#2. 编辑器vim)
-
- [2.1 vim 的核心操作](#2.1 vim 的核心操作)
- [2.2 vim 命令](#2.2 vim 命令)
-
- [2.2.1 模式转换](#2.2.1 模式转换)
- [2.2.2 常见命令](#2.2.2 常见命令)
- [2.3 vim的简单配置](#2.3 vim的简单配置)
- [3. 编译器gcc /g++](#3. 编译器gcc /g++)
-
- [3.1 GCC / G++ 是什么?](#3.1 GCC / G++ 是什么?)
- [3.2 预处理 -> 编译 -> 汇编 -> 链接](#3.2 预处理 -> 编译 -> 汇编 -> 链接)
- [3.3 动态链接与静态链接](#3.3 动态链接与静态链接)
- [3.4 gcc 常用选项](#3.4 gcc 常用选项)
- [4. Makefile](#4. Makefile)
-
- [4.1 基本使用](#4.1 基本使用)
- [4.2 推导过程](#4.2 推导过程)
- [4.3 补充语法](#4.3 补充语法)
- [5. Linux第一个程序---进度条](#5. Linux第一个程序---进度条)
-
- [5.1 换行与回车](#5.1 换行与回车)
- [5.2 行缓冲区](#5.2 行缓冲区)
- [5.3 倒计时程序](#5.3 倒计时程序)
- [5.4 进度条代码](#5.4 进度条代码)
- [6. 版本控制器Git](#6. 版本控制器Git)
-
- [6.1 问题引入](#6.1 问题引入)
- [6.2 Git 登场:优雅的版本控制](#6.2 Git 登场:优雅的版本控制)
- [6.3 Git发展](#6.3 Git发展)
- [6.4 Git的使用](#6.4 Git的使用)
-
- [6.4.1 核心概念](#6.4.1 核心概念)
- [6.4.2 创建仓库](#6.4.2 创建仓库)
- [6.4.3 git 命令](#6.4.3 git 命令)
- [7. 调试器 gdb/cgdb](#7. 调试器 gdb/cgdb)
-
- [7.1 debug和release](#7.1 debug和release)
- [7.2 gdb 使用](#7.2 gdb 使用)
- [7.3 开始调试](#7.3 开始调试)
- [7.4 补充:设置条件断点(Conditional Breakpoint)](#7.4 补充:设置条件断点(Conditional Breakpoint))
1. 软件包管理器
1.1 Linux软件安装发展过程
- 最初,开源社区完全依赖手动编译源码的方式获取软件,用户需自行下载压缩包、解决依赖关系并执行编译安装,这种方式虽高度灵活却效率低下,尤其在处理复杂的依赖链时举步维艰(现在使用的
Makefile就是当时的遗留痕迹) - 随着
Linux发行版的兴起,1990年代中期诞生的静态软件包(如Debian的deb和Red Hat的rpm)首次引入元数据概念,通过预编译二进制文件和基础依赖描述简化了安装流程,但依赖冲突问题仍未彻底解决 1998年APT与2003年YUM等智能包管理器的出现,标志着依赖解析技术的突破,它们通过算法自动下载所需依赖包,并建立本地软件数据库,实现了软件安装、升级、卸载的全生命周期管理- 进入21世纪后,软件生态的复杂化催生了容器化革命,
Docker等工具通过封装应用及其完整运行环境,以镜像形式实现跨平台的标准化部署,彻底解决了"在我机器上能运行"的经典难题
1.2 软件包和软件包管理器
软件包:预编译的应用程序及其数据,包括:二进制文件、配置文件、安装/卸载脚本等。常见的软件包格式有
- Debian/Ubuntu:
.deb - RHEL/Fedora:
.rpm - Arch Linux:
.pkg
软件包管理器:类似于手机上的应用商店,具有自动处理软件包之间的依赖关系、支持多版本共存与升级回滚、验证软件包来源等功能。常见的软件包管理器有: Debian/Ubuntu:APT(Advanced Package Tool)
bash
apt update # 刷新仓库索引
apt install nginx # 安装软件包
apt remove --purge nginx # 完全卸载
apt-cache show nginx # 查看包信息RHEL/Fedora:DNF/YUM
bash
dnf makecache # 生成元数据缓存
dnf install httpd # 安装软件包
yum install httpd
yum updateArch Linux:Pacman
bash
pacman -Syu # 升级全部软件包
pacman -Qs ^linux # 正则搜索本地包
pacman -U package.pkg.tar.zst # 手动安装本地包查看软件包(lrzsz 是一个方便 Linux 服务器与本地之间进行小文件传输的工具)
bash
$ apt search lrzsz
Sorting... Done
Full Text Search... Done
cutecom/noble 0.51.0-1build2 amd64
Graphical serial terminal, like minicom
lrzsz/noble,now 0.12.21-11build1 amd64 [installed]
Tools for zmodem/xmodem/ymodem file transfer
$ 注:
yum/apt安装软件时只能一个装完再装另一个,正在yum/apt安装软件时,在尝试使用yum/apt安装另一个软件会报错
1.3 安装源
安装源(软件仓库/软件源)是操作系统获取软件包的核心渠道。不同发行版使用不同的包管理工具和配置文件,但核心逻辑类似
安装源类型
- 官方仓库:由发行版维护,稳定性高(如
Ubuntu的main、CentOS的base) - 第三方仓库:
PPA(Ubuntu):个人打包的软件集合(ppa:user/repo)、EPEL(CentOS):扩展包仓库 - 本地仓库:通过
ISO镜像或本地路径安装(适用于无网络环境) - 网络镜像:加速下载的镜像站点(如清华、中科大镜像源)
Ubuntu下的APT安装源配置文件
bash
$ cat /etc/apt/sources.list.d/ubuntu.sources
Types: deb
URIs: http://repo.huaweicloud.com/ubuntu
Suites: noble noble-updates noble-backports
Components: main restricted universe multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
Types: deb
URIs: http://repo.huaweicloud.com/ubuntu
Suites: noble-security
Components: main restricted universe multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
$ 2. 编辑器vim
Vim(Vi IMproved) 是一款高度可定制、跨平台的文本编辑器,是经典 Unix 编辑器 Vi 的增强版
Vim(Vi IMproved )是一款高度可定制、跨平台的文本编辑器,是经典 Unix 编辑器 Vi 的增强版。它以键盘操作为核心,凭借高效的工作流和强大的扩展性,成为开发者、系统管理员等技术人员的常用工具
核心特点
-
模式化编辑:
- 普通模式(Normal Mode):移动光标、执行命令(默认进入的模式)
- 插入模式(Insert Mode) :输入文本(按
i进入,Esc返回普通模式) - 可视模式(Visual Mode) :选择文本块(按
v进入) - 命令行模式(Command-line Mode) :执行保存、退出等命令(按
:进入) 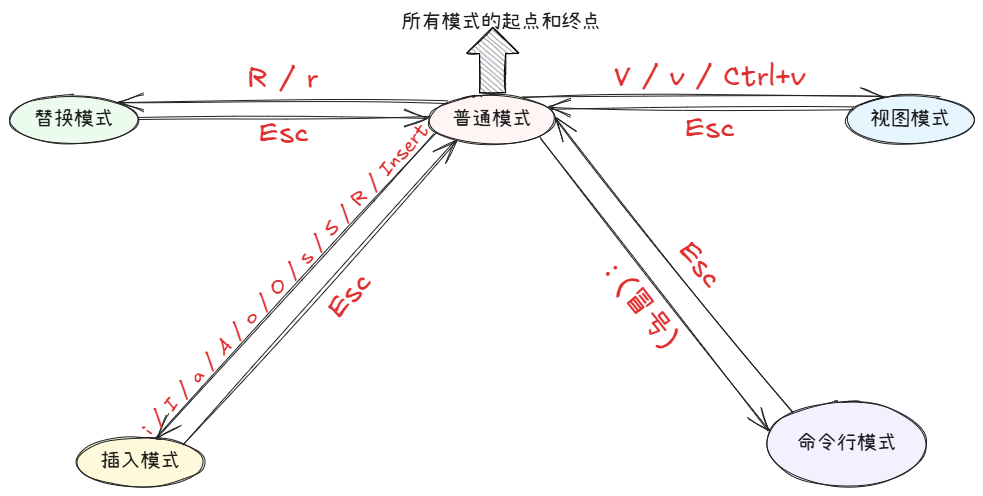
-
跨平台支持:
- 支持
Linux、macOS、Windows等主流操作系统
- 支持
-
高效操作:
- 通过组合键(如
d+w删除单词)实现快速编辑,减少鼠标依赖
- 通过组合键(如
-
可扩展性:
- 支持插件(如代码补全、语法检查)和自定义配置(通过
.vimrc文件)
- 支持插件(如代码补全、语法检查)和自定义配置(通过
2.1 vim 的核心操作
输入 vim <文件名>,就进入 vim 全屏编辑页面
vim text.txt
- 进入
vim之后,处于普通模式下,要切换到插入模式才能输入 - Esc 是万能钥匙: 在插入模式、视图模式、替换模式、命令行模式(取消输入时)下按
Esc总是回到普通模式 - 退出
vim时,输入::w保存当前文件:wq保存并退出vim:q!不保存强制退出vim
2.2 vim 命令
2.2.1 模式转换
从普通模式 -> 插入模式
i: 在光标前 插入 (insert before cursor)a: 在光标后 插入 (append after cursor)I: 在行首 插入 (Insert at beginning of line)A: 在行尾 插入 (Append at end of line)o: 在当前行下方 插入一个新行并进入插入模式 (Open a new line below)O: 在当前行上方 插入一个新行并进入插入模式 (Open a new line above)c+动作: 更改文本(删除指定范围的文本并进入插入模式)。例如cw更改一个单词,c$更改到行尾s: 删除当前字符 并进入插入模式 (substitute character)S: 删除整行 并进入插入模式 (Substitute line)C: 删除从光标到行尾 的文本并进入插入模式 (Change to end of line)
普通模式 -> 可视化选择模式
- 字符视图模式 (Visual Mode): 按字符选择文本。按
v进入。这是最常用的视图模式 - 行视图模式 (Visual Line Mode): 按整行选择文本。按
V(大写) 进入。适合操作整行 - 块视图模式 (Visual Block Mode): 按矩形块选择文本(列选择)。按
Ctrl+v进入。非常适合在多行文本的相同位置进行编辑(例如同时注释多行代码) - 如何进入 (从普通模式):
v,V,Ctrl+v - 如何操作: 进入后,使用移动命令 (
h,j,k,l,w,b,},0,$,gg,G等)来扩展或缩小选择区域 - 如何执行命令: 选择好文本后,按一个操作命令 ,
Vim会像在普通模式下一样执行该命令,但作用范围仅限于选中的文本 。常用操作:d/x: 删除选中文本 (Cut)y: 复制选中文本 (Yank/Copy)c: 更改选中文本(删除并进入插入模式)>: 向右缩进选中文本<: 向左缩进选中文本~: 切换选中文本的大小写u: 将选中文本转为小写U: 将选中文本转为大写:: 对选中文本执行命令行命令(例如:'<,'>s/old/new/g在选中范围内替换)
普通模式 -> 命令行模式
:按:(冒号)。光标会移动到屏幕底部,出现:提示符- 文件操作:
:w(保存),:w filename(另存为),:q(退出),:q!(不保存强制退出),:wq或:x(保存并退出),:e filename(打开另一个文件) - 搜索和替换:
:/pattern(向下搜索),:?pattern(向上搜索),:%s/old/new/g(全局替换),:%s/old/new/gc(全局替换并确认) - 设置选项:
:set number(显示行号),:set nonumber(隐藏行号),:set hlsearch(高亮搜索结果),:set nohlsearch(取消高亮) - 执行外部命令:
:!command(如:!ls,:!gcc %编译当前文件) - 其他高级操作:
:split(水平分屏),:vsplit(垂直分屏),:tabnew(新建标签页),:help(查看帮助)
普通模式 -> 替换模式 (Replace Mode)
- 一种特殊的插入模式
- 作用: 覆盖 (替换) 已有的文本 ,而不是插入新文本。按一个键,会删除光标下的字符,然后插入你按的字符
R: 进入连续替换模式。之后输入的字符会逐个覆盖后面的原有字符r: 后跟一个字符 。仅替换当前光标下的一个字符 ,然后自动回到普通模式 (r本身不是模式,是一个命令)
2.2.2 常见命令
主要在普通模式下(按下就会执行)
d/x: 删除选中文本 (Cut)y: 复制选中文本 (Yank/Copy)c: 更改选中文本(删除并进入插入模式)>: 向右缩进选中文本<: 向左缩进选中文本~: 切换选中文本的大小写u: 将选中文本转为小写U: 将选中文本转为大写:: 对选中文本执行命令行命令(例如:'<,'>s/old/new/g在选中范围内替换)
移动 (Navigation):
h/←: 左移j/↓: 下移一行k/↑: 上移一行l/→: 右移w/W: 移动到下一个单词/大词 (词首)b/B: 移动到上一个单词/大词 (词首)e/E: 移动到下一个单词/大词 (词尾)0/^/$: 移动到行首 / 行首第一个非空白字符 / 行尾gg: 移动到文件第一行G: 移动到文件最后一行:[行号]+Enter: 跳转到指定行号 (e.g,:42跳到第42行)Ctrl+f/Page Down: 向下翻一页Ctrl+b/Page Up: 向上翻一页Ctrl+d/Ctrl+u: 向下/向上翻半页%: 在匹配的括号 ((),{},[]) 间跳转f[字符]/F[字符]/t[字符]/T[字符]: 在当前行查找字符并移动 (f到字符上,t到字符前, 大写表示反向)
编辑 (Editing):
i/a/o/O/I/A/s/S/c/C: 进入插入模式 (见上文)x/dl: 删除光标下的字符 (相当于Del)X/dh: 删除光标前的字符 (相当于Backspace)d[动作]: 删除 (Cut) 文本 (e.g,dw删一个单词,d$/D删到行尾,dd删整行,dG删到文件尾)y[动作]: 复制 (Yank) 文本 (e.g,yw复制一个单词,y$复制到行尾,yy/Y复制整行,yG复制到文件尾)p: 在光标后 粘贴 (小写p)P: 在光标前 粘贴 (大写P)u: 撤销 (Undo)Ctrl+r: 重做 (Redo) 撤销的操作.(点): 重复上一个编辑操作 (非常强大!)r[字符]: 替换当前光标下的一个字符 (单个字符替换命令)R: 进入替换模式 (连续替换)~: 切换当前光标下字符的大小写
搜索与替换 (Search & Replace):
/pattern: 向下搜索pattern(正则表达式)?pattern: 向上搜索patternn: 重复上一次搜索,相同方向N: 重复上一次搜索,相反方向:%s/old/new/g: 在整个文件中 (%) 将所有old替换为new(global):%s/old/new/gc: 同上,但每次替换前询问确认 (confirm):[行范围]s/old/new/g: 在指定行范围内替换 (e.g.,:10,20s/foo/bar/g在10-20行替换)
文件与窗口 (File & Window):
:w: 保存文件:w filename: 另存为filename:q: 退出Vim(如果文件未修改):q!: 不保存强制退出:wq/:x/ZZ(普通模式): 保存并退出:e filename: 编辑另一个文件filename:split/:sp [filename]: 水平分割窗口 (打开filename或当前文件):vsplit/:vsp [filename]: 垂直分割窗口Ctrl+w+方向键/h/j/k/l: 在窗口间切换Ctrl+w+c: 关闭当前窗口:tabnew [filename]: 在新标签页打开文件gt/gT: 切换到下一个 / 上一个标签页:tabn/:tabp: 同上 (命令形式)
其他实用命令:
:set number/:set nu: 显示行号:set nonumber/:set nonu: 隐藏行号:set hlsearch/:set hls: 高亮所有搜索结果:set nohlsearch/:set nohls: 关闭搜索结果高亮:nohlsearch/:noh: 临时关闭当前搜索的高亮 (直到下次搜索):help [topic]: 查看帮助 (e.g,:help w,:help :w)Ctrl+g/:f/Ctrl+g: 在底部显示当前文件名和光标位置信息#:#表示一个数字,在冒号后输入一个数字,再回车,就会跳转到对应的行数
2.3 vim的简单配置
步骤 1:创建配置文件
bash
# Linux/macOS
touch ~/.vimrc步骤 2:安装插件管理器 (vim-plug)
bash
# Linux/macOS
curl -fLo ~/.vim/autoload/plug.vim --create-dirs \
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim步骤 3:编辑配置文件
打开 ~/.vimrc (Linux/macOS),复制以下内容:
vim
" === 基础设置 ===
set number " 显示行号
set tabstop=4 " Tab宽度=4空格
set expandtab " Tab转空格
syntax on " 语法高亮
set mouse=a " 启用鼠标
" === 插件管理 ===
call plug#begin('~/.vim/plugged')
" 必备插件
Plug 'preservim/nerdtree' " 文件树
Plug 'vim-airline/vim-airline' " 状态栏
Plug 'tpope/vim-commentary' " 快速注释
Plug 'kien/ctrlp.vim' " 模糊搜索
call plug#end()
" === 插件配置 ===
" NERDTree 文件树
map <C-n> :NERDTreeToggle<CR> " Ctrl+n 开关
let NERDTreeShowHidden=1 " 显示隐藏文件
" 快速注释
nmap gcc :Commentary<CR> " gcc 注释当前行
vmap gc :Commentary<CR> " 可视化模式注释选中行
" CtrlP 模糊搜索
let g:ctrlp_map = '<c-p>' " Ctrl+p 搜索文件步骤 4:安装插件
- 打开
Vim - 执行命令:
vim
:PlugInstall等待插件安装完成(状态栏显示 "Done")
步骤 5:常用操作
| 功能 | 快捷键/命令 |
|---|---|
| 打开文件树 | Ctrl + n |
| 注释当前行 | gcc |
| 搜索文件 | Ctrl + p |
| 保存文件 | :w |
| 退出 Vim | :q |
| 重载配置 | :source ~/.vimrc |
选择主题
- 在
call plug#begin后添加:
vim
Plug 'joshdick/onedark.vim' " 主题插件- 在文件末尾添加:
vim
colorscheme onedark " 使用主题
set background=dark " 深色模式- 重载配置并安装:
vim
:source %
:PlugInstall验证配置
打开 Vim 测试:
- 按
Ctrl+n应出现文件树 - 输入文本后按
gcc应注释当前行 - 按
Ctrl+p应出现文件搜索框
遇到问题执行 :PlugStatus查看插件状态
更新插件用 :PlugUpdate
3. 编译器gcc /g++
3.1 GCC / G++ 是什么?
- GCC (GNU Compiler Collection):
- 定义:
GCC最初代表 "GNU C Compiler",但随着其支持语言的扩展,现在代表 "GNU Compiler Collection " (GNU编译器套件) - 功能: 它是一个由
GNU项目开发的、功能强大且广泛使用的编译器套件 。它支持多种编程语言,最主要的是:- C (
gcc): 编译C语言程序 - C++ (
g++): 编译C++语言程序 - 其他:
Fortran(gfortran),Ada(gnat),Go(gccgo),D(gdc),Objective-C,Objective-C++等
- C (
- 跨平台:
GCC是跨平台 的,可以在多种操作系统上运行,包括Linux、macOS(通过Xcode Command Line Tools或Homebrew等)、Windows(通过MinGW,Cygwin,WSL等) - 开源: 它是自由开源软件 (
FOSS),遵循GPL许可证 - 核心作用: 将人类可读的高级语言源代码 (如
.c,.cpp文件) 转换成计算机可执行的机器码或中间代码
- G++:
- 定义:
g++是GCC编译器套件中专门用于编译 C++ 源代码的程序 - 与
gcc的关系:gcc和g++本质上是同一个驱动程序 (driver program)。它们的主要区别在于默认行为 和默认链接的库- 当调用
gcc时:- 默认将文件视为
C源代码 - 默认在链接阶段只链接标准
C库 (libc) , 不链接C++标准库 (libstdc++)
- 默认将文件视为
- 当调用
g++时:- 默认将文件 (如
.c,.cpp,.cc,.C) 视为 C++ 源代码 (遵循特定后缀规则) - 默认在链接阶段链接
C++标准库 (libstdc++) 。这是编译C++程序所必需的
- 默认将文件 (如
3.2 预处理 -> 编译 -> 汇编 -> 链接
程序如何从文本变成可执行文件的过程可以分为:预处理 -> 编译 -> 汇编 -> 链接。我们以一个简单的 C 程序 hello.c 为例:
c
#include <stdio.h>
#define GREETING "Hello, World!"
int main() {
printf("%s\n", GREETING);
return 0;
}阶段 1:预处理 (Preprocessing)
-
工具:
cpp(C Preprocessor),通常由gcc -E或g++ -E调用 -
输入: 源代码文件 (
.c,.cpp) -
输出: 预处理后的源代码 (
.i或.ii文件,或直接输出到标准输出) -
核心任务: 处理源代码中以
#开头的预处理指令 (preprocessor directives) ,对源代码进行文本级别的替换和修改 -
主要操作:
- 头文件包含 (
#include): 将被包含的文件(如stdio.h)的内容复制并插入 到#include指令所在的位置。这通常会导致代码量显著增加 - 宏展开 (
#define): 将所有定义的宏(如GREETING)替换为其定义的值("Hello, World!") - 条件编译 (
#ifdef,#ifndef,#if,#else,#elif,#endif): 根据给定的条件(通常是宏是否定义或表达式值)决定是否包含或排除某些代码块。这在编写跨平台代码或调试时非常有用 - 删除注释: 移除所有注释 (
//,/* ... */) - 处理特殊指令: 如
#pragma,#line,#error等
- 头文件包含 (
-
目的: 产生一个"纯净"的、不含预处理指令、宏已展开、头文件已包含的源代码文件,供真正的编译器使用
-
查看预处理结果:
bashgcc -E hello.c -o hello.i # 输出到 hello.i g++ -E hello.cpp -o hello.ii # C++ 通常用 .ii打开
hello.i,你会看到#include <stdio.h>被替换成了stdio.h中大量的函数声明和宏定义,GREETING被替换成了"Hello, World!",注释也被删除了
阶段 2:编译 (Compilation)
-
工具: 真正的编译器核心 (如
cc1 for C,cc1plus for C++),通常由gcc -S或g++ -S调用 -
输入: 预处理后的源代码 (
.i或.ii文件,或直接来自上一步) -
输出: 汇编语言源代码 (
.s文件) -
核心任务: 将高级语言 (
C/C++) 翻译成低级、与特定处理器架构相关的汇编语言 (Assembly Language) -
主要操作:
- 词法分析 (Lexical Analysis): 将源代码字符流分解成有意义的词素 (
token),如关键字、标识符、常量、运算符等 - 语法分析 (Syntax Analysis / Parsing): 根据语法规则检查词素序列的结构,构建抽象语法树 (
Abstract Syntax Tree,AST)。检查语法错误 - 语义分析 (Semantic Analysis): 在 AST 上检查语义是否正确(如类型检查、变量声明检查、函数调用匹配等)。收集类型信息
- 中间代码生成 (Intermediate Code Generation): (可选但常见) 生成一种独立于具体硬件架构的中间表示 (如
GIMPLE,RTL in GCC),便于优化 - 优化 (Optimization): 在中间代码或汇编代码级别进行各种优化,以提高程序的运行效率或减小其大小(如常量传播、死代码消除、循环优化、内联函数等)。优化级别可通过
-O0(不优化),-O1,-O2,-O3,-Os(优化大小) 等选项控制 - 目标代码生成 (Code Generation): 将优化后的中间代码或直接从
AST生成特定CPU架构的汇编语言指令
- 词法分析 (Lexical Analysis): 将源代码字符流分解成有意义的词素 (
-
目的: 生成与机器指令一一对应的、人类(勉强)可读的低级表示(汇编代码)
-
查看编译结果 (生成汇编):
bashgcc -S hello.i -o hello.s # 从预处理文件编译 gcc -S hello.c -o hello.s # gcc 会自动先预处理再编译 g++ -S hello.cpp -o hello.s打开
hello.s,你会看到类似movl,call,pushq,.section,.globl main等针对特定CPU(如x86-64) 的汇编指令
阶段 3:汇编 (Assembly)
-
工具: 汇编器 (Assembler) ,如
as -
输入: 汇编语言源代码 (
.s文件) -
输出: 目标文件 (Object File) (
.o或.obj文件) -
核心任务: 将汇编语言指令 逐条翻译成对应的、处理器能够直接理解和执行的机器指令 (二进制码),并将结果打包成目标文件格式
-
主要操作:
- 指令翻译: 将汇编助记符 (如
mov,add,call) 翻译成二进制机器码 (Opcode) - 符号解析 (初步): 记录代码中定义的符号(函数名、全局变量名)及其位置(地址),以及引用的外部符号(如
printf) - 生成目标文件: 生成特定格式(如
Linux/Unix上的ELF-Executable and LinkableFormat,Windows上的PE/COFF)的目标文件。目标文件包含:- 编译后的机器代码 (
.text段) - 初始化了的全局/静态变量数据 (
.data段) - 未初始化 (或初始化为0) 的全局/静态变量数据 (
.bss段,在文件中只占位置标记,不占实际空间) - 符号表 (Symbol Table): 记录本文件中定义和引用的符号信息(名称、类型、大小、地址等)
- 重定位信息 (Relocation Information): 记录文件中哪些位置在最终链接时需要用其他目标文件或库中符号的地址来修正
- 调试信息 (可选,编译时加
-g选项)
- 编译后的机器代码 (
- 指令翻译: 将汇编助记符 (如
-
目的: 生成包含机器码和元数据的可重定位目标文件,为链接阶段做准备
-
执行汇编:
bashgcc -c hello.s -o hello.o # 从汇编文件汇编 gcc -c hello.c -o hello.o # gcc 会自动预处理->编译->汇编 g++ -c hello.cpp -o hello.o生成的
hello.o是一个二进制文件,直接用文本编辑器打开是乱码。可以使用objdump -d hello.o或nm hello.o来查看其反汇编代码或符号表
阶段 4:链接 (Linking)
-
工具: 链接器 (Linker) ,如
ld。gcc/g++驱动程序会调用ld,并负责传递正确的库路径和库名 -
输入: 一个或多个目标文件 (
.o) 和库文件 (静态库.a/.lib, 动态库.so/.dll/.dylib) -
输出: 最终的可执行文件 (Linux/Unix 无后缀或
.out, Windows.exe) 或 共享库/动态链接库 (.so,.dll,.dylib) -
核心任务: 将多个独立编译的目标文件以及所需的库文件组合 成一个单一的、完整的、可被操作系统加载执行的程序映像。解决符号引用问题
-
主要操作:
- 符号解析 (Symbol Resolution):
- 链接器扫描所有输入的目标文件和库
- 为每个目标文件中"引用 (Reference) "的符号(如
printf)在输入文件中寻找其"定义 (Definition)" - 确保每个符号引用都能找到一个且仅一个符号定义(避免未定义引用
undefined reference或多重定义multiple definition错误)
- 重定位 (Relocation):
- 合并所有输入目标文件的同类型段(如将所有
.text段合并到输出文件的.text段,所有.data段合并到.data段) - 计算每个定义的符号(函数、变量)在最终输出文件中的绝对内存地址(或相对于基址的相对地址)
- 根据计算出的新地址,修改所有引用这些符号的地方(机器指令中使用的地址或数据段中的指针),填入正确的地址值。这是利用汇编阶段生成的重定位信息来完成的
- 合并所有输入目标文件的同类型段(如将所有
- 解析库依赖:
- 链接器按顺序处理输入文件(包括命令行上指定的库)
- 如果一个目标文件引用了库中的符号,链接器会从库中提取 包含该符号定义的目标文件(模块),并将其加入链接过程。对于静态库,代码被复制 到最终可执行文件中。对于动态库,只在可执行文件中记录库的名字和所需符号,运行时由操作系统加载
- 生成可执行文件: 将合并、重定位后的代码和数据,以及必要的头部信息(如程序入口点
_start,它负责初始化环境后调用main)、段表等,按照操作系统要求的格式(如ELF,PE)打包成最终的可执行文件或共享库
- 符号解析 (Symbol Resolution):
-
目的: 解决模块间依赖(符号引用),合并代码和数据,分配最终运行时地址,生成可直接加载运行的程序
-
执行链接:
bashgcc hello.o -o hello # 链接单个目标文件 (自动链接C标准库) g++ hello.o -o hello # 链接单个目标文件 (自动链接C++和C标准库) gcc main.o utils.o -o myprog -lm # 链接多个目标文件和数学库
3.3 动态链接与静态链接
在实际开发中,不可能将所有代码放在一个源文件中,所以会出现多个源文件,而且多个源文件之间是独立的,且会存在多种依赖关系,如一个源文件可能要调用另一个源文件中定义的函数,这是最常用的场景了;但是每个源文件是独立编译的,每个 .c 文件都会形成一个 .o 文件,为了满足前面的依赖关系,则需要将这些源文件产生的目标文件进行链接,从而形成一个可以执行的从程序。这个链接的过程就是静态链接,其缺点很明显:
- 浪费空间:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,如多个程序中都调用了printf()函数,则这多个程序中都含有printf.o,所以同一个目标文件都在内存存在多个副本
- 更新比较困难:因为每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快
动态链接的出现解决了静态链接中给提到的问题,其思想是把程序按照模块拆分成各个相对独立的部分 ,在程序运行时才将它们链接到一起形成完整的可执行程序 ,而不是像静态链接一样把所有的程序模块都链接成一个单独的可执行文件
动态链接比较常用,默认情况下程序采用的都是动态链接
bash
$ ldd hello
linux-vdso.so.1 (0x00007ffc9bdb2000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x000079eb86800000)
/lib64/ld-linux-x86-64.so.2 (0x000079eb86aa1000)
$
# ldd 用于打印程序或者库文件所依赖的共享库列表在这里涉及到一个概念 库 ,
在 C 程序中,并没有定义 printf 的函数实现,而且在预编译中包含的头文件 stdio.h,也只有该函数的声明,而没有定义函数的实现
真正的实现是在库中,libc.so.6 的库文件中,系统把这些函数都实现在库文件中 。在没有指定路径的情况下,gcc 到系统默认的搜索路径下 /usr/lib 下进行查找,也就是链接到 Libc.so.6 库中,这样就能实现函数 printf 了,刚好这就是链接的作用
3.4 gcc 常用选项
基础控制选项
| 选项 | 功能 | 示例 |
|---|---|---|
-E |
仅执行预处理 | gcc -E main.c -o main.i |
-S |
仅编译到汇编 | gcc -S main.c → 生成 main.s |
-c |
编译+汇编(不链接) | gcc -c main.c → 生成 main.o |
-o <file> |
指定输出文件名 | gcc main.c -o myapp |
-x <语言> |
强制指定语言类型 | gcc -x c++ foo.txt |
-v |
显示详细编译过程 | gcc -v main.c |
-### |
显示命令但不执行 | gcc -### main.c |
目录与路径选项
| 选项 | 功能 | 示例 |
|---|---|---|
-I<dir> |
添加头文件搜索路径 | gcc -Iinclude/ main.c |
-L<dir> |
添加库文件搜索路径 | gcc -Llib/ main.o -lmylib |
-l<库名> |
链接指定库 | gcc main.c -lm(链接数学库) |
-nostdinc |
禁止搜索标准头文件目录 | gcc -nostdinc -Icustom_include/ |
预处理选项
| 选项 | 功能 | 示例 |
|---|---|---|
-D<宏>[=值] |
定义宏 | gcc -DDEBUG main.c |
-U<宏> |
取消宏定义 | gcc -UDEBUG main.c |
-include <文件> |
强制包含头文件 | gcc -include defs.h main.c |
-M / -MM |
生成依赖关系(用于Makefile) | gcc -MM main.c → 输出依赖规则 |
警告控制选项
| 选项 | 功能 | 说明 |
|---|---|---|
-Wall |
启用所有常见警告 | 包含未使用变量、函数未声明等 |
-Wextra |
启用额外警告 | 比 -Wall 更严格(如空循环体) |
-Werror |
将警告视为错误 | 编译失败 |
-Wno-<警告名> |
禁用特定警告 | gcc -Wno-unused-variable |
-pedantic |
严格遵循 ISO 标准 |
拒绝非标准扩展 |
优化选项
| 选项 | 优化级别 | 特点 |
|---|---|---|
-O0 |
无优化 | 编译快,调试友好(默认) |
-O1 |
基础优化 | 平衡性能与编译速度 |
-O2 |
推荐优化 | 激进优化(不增加代码大小) |
-O3 |
最高优化 | 可能增加代码大小(循环展开等) |
-Os |
优化代码大小 | 适用于嵌入式设备 |
-Ofast |
激进优化 | 可能违反标准(如浮点精度) |
调试选项
| 选项 | 功能 | 说明 |
|---|---|---|
-g |
生成调试信息 | 支持 GDB 调试 |
-ggdb |
生成GDB专用调试信息 | 比 -g 更详细 |
-g3 |
包含宏定义信息 | 调试时可展开宏 |
-s |
移除所有符号表 | 减小可执行文件大小 |
-p / -pg |
生成性能分析数据 | 用于 gprof 分析 |
七、链接选项
| 选项 | 功能 | 示例 |
|---|---|---|
-static |
静态链接 | gcc -static main.c |
-shared |
生成动态库 | gcc -shared -fPIC -o libfoo.so foo.c |
-fPIC |
生成位置无关代码 | 编译动态库必备 |
-pthread |
支持多线程 | 定义宏并链接线程库 |
-Wl,<选项> |
传递选项给链接器 | gcc -Wl,-rpath=/lib main.c |
语言标准选项
| 选项 | 标准 | 说明 |
|---|---|---|
-std=c89 / -ansi |
C89 标准 |
传统 C 语言 |
-std=c99 |
C99 标准 |
支持 // 注释、long long |
-std=c11 |
C11 标准 |
现代 C 语言(推荐) |
-std=c++11 |
C++11 标准 |
智能指针、Lambda |
-std=c++17 |
C++17 标准 |
结构化绑定、std::optional |
4. Makefile
Makefile 是一个用于自动化软件构建过程的脚本文件,由 make 工具解析执行。它定义了项目中的依赖关系、构建规则和操作指令,主要用于编译源代码、链接目标文件和管理项目构建流程
- 一个工程中的源文件不计其数,其类型、功能、模块分别放在若干个目录中,
makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,甚至是更复杂的操作 makefile带来的好处就是---自动化编译,一旦写好,只需要一个make命令,整个工程就能按照定义的规则自动编译,极大地提高了软件开发的效率make是一个工具,具体来说是解释makefile中指令的命令工具。一般,大部分的IDE都有这个命令,如Delphi的make,Visual C++中的namke,Linux下的GNU的makemake是一条命令,makefile是一个文件,两个搭配使用,完成项目的自动化构建
核心概念
- 目标(Target)
需要生成的文件(如可执行文件、目标文件)或伪目标(如clean) - 依赖(Prerequisites)
目标所依赖的文件或其他目标 - 命令(Recipe)
构建目标时执行的Shell命令(必须用 Tab 缩进)
4.1 基本使用
c
#include<stdio.h>
int main()
{
printf("Hello makefile!\n");
return 0;
}以单个简单的源文件作为示例
makefile
Hello:Hello.c
gcc -o Hello Hello.c
.PHONY: clean
clean:
rm -f Hello上面的 makefile 中,大部分其实都是用我们正常使用 gcc/g++ 时的语法,只是放在 makefile 中了而已,执行的时候只需输入 make 即可自动完成 makefile 中的命令
依赖关系
上面的文件 Hello.c,生成可执行程序Hello(Hello 依赖于 Hello.c)
依赖方法
gcc -o Hello Hello.c,就是上面的依赖关系
项目清理
- 工程是需要清理的
clean,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,可以通过显示make执行,也就是make clean,以此来清除所有的目标文件,以重新编译- 一般将
clean这种目标文件,设置为伪目标(不生成实际文件的目标),用.PHONY修饰,伪目标的特性是:总是被执行
总是被执行:
bash
$ stat ***
File: ***
Size: ** Blocks: * IO Block: * regular file
Device: 253,1 Inode: 810719 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ wyf) Gid: ( 1000/ wyf)
Access: 2024-06-05 15:33:54.461535234 +0800
Modify: 2024-06-05 15:33:42.343412262 +0800
Change: 2024-06-05 15:33:42.343412262 +0800
Birth: 2024-06-05 15:33:42.342412252 +0800 - 文件 = 内容 + 属性
Modify: 内容变更,时间更新Change:属性变更,时间更新Access:常指的是文件最近一次被访问的时间。在Linux的早期版本中,每当文件被访问时,其atime都会更新。但这种机制会导致大量的IO操作。具体更新原则,此处不做深究
.PHONY :让 make 忽略源文件和可执行目标文件的 M 时间对比
4.2 推导过程
makefile
Hello:Hello.o
gcc Hello.o -o Hello
Hello.o:Hello.s
gcc -c Hello.s -o Hello.o
Hello.s:Hello.i
gcc -S Hello.i -o Hello.s
Hello.i:Hello.c
gcc -E Hello.c -o Hello.i
.PHONY:clean
clean:
rm -f *.i *.s *.o Hello编译
bash
$ make
gcc -E Hello.c -o Hello.i
gcc -S Hello.i -o Hello.s
gcc -c Hello.s -o Hello.o
gcc Hello.o -o Hello
$ ./Hello
Hello makefile!
$ make clean
rm -f *.i *.s *.o Hellomake 的核心机制是 基于文件依赖关系和时间戳 来决定是否需要重建目标。如果依赖文件不存在,且没有规则能创建它,make 会拒绝工作
make 是如何工作的?在只输入 make 命令时:
-
make会在当前目录下找名字叫makefile或makefile的文件 -
如果找到,它会找文件中的第一个目标文件(
target),在上面的示例中,会找到Hello,并将其作为最终的目标文件 -
如果
Hello文件不存在。或是Hello所依赖的后面的Hello.o文件的修改时间要比Hello这个文件新(可以用touch测试),那么,它就会执行后面所定义的命令来生成这个文件 -
如果
Hello所依赖的Hello.o文件不存在,那么make会在当前文件中找目标为Hello.o文件的依赖性,如果找到则再根据对应的规则生成Hello.o文件(类似于堆栈的过程)
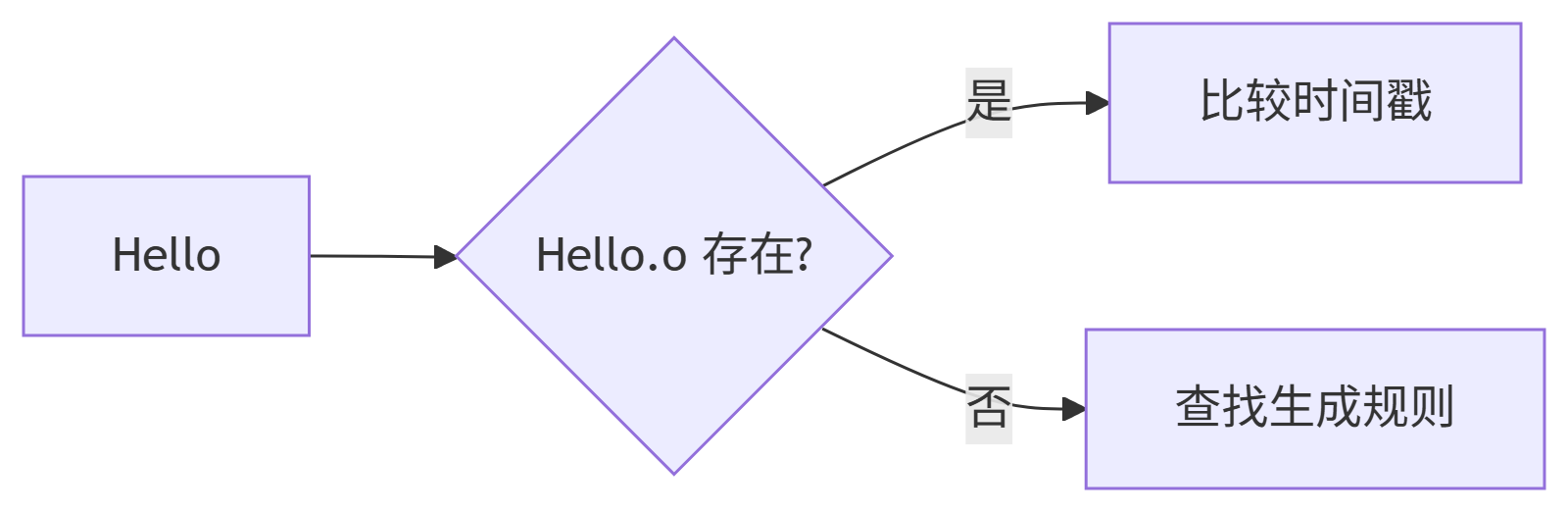
-
C文件和H文件是存在的,于是make就会生成Hello.o文件,然后再调用Hello.o文件声明的终极任务,也就是生成执行文件Hello -
这就是
make的依赖性,make会一层一层的找文件的依赖关系,直到最终编译出目标文件 -
在寻找的过程中,如果出现错误,比如依赖的文件找不到,那么
make就会直接退出,并报错,而对于所定义命令的错误,或是编译不成功,make不会处理(自己定义的规则出了问题由你承担) -
make只负责文件的依赖性,也就是说:如果找到了依赖关系后,冒号后的文件还是不存在,那么make不会工作
4.3 补充语法
-
变量定义
BIN = main最终生成的可执行文件名SRC = $(wildcard *.c)获取所有源文件(推荐使用wildcard)OBJ = $(SRC:.c=.o)将.c文件列表转为.o文件列表CC = gccC编译器(C++使用g++)
-
特殊函数
SRC=$(shell ls *.c采用shell命令的方式获取当前所有的.c文件SRC=$(wildcard *.c)采用wildcard函数,获取当前所有.c文件
-
编译选项
LDFLAGS=-o链接选项CLAGS=-c编译选项RM=rm -rf引入删除命令
-
自动变量
$@代表目标文件名$^代表依赖文件列表$<对展开的依赖.c文件,一个一个的交给指定的编译工具
-
模式规则
%.o:%.c为每个.c文件生成对应的.o文件
-
特殊符号
$@不回显命令
完整 makefile
makefile
BIN = Hello
SRC = $(wildcard *.c)
OBJ = $(SRC:.c=.o)
CC = gcc
CFLAGS = -c
LDFLAGES = -o
RM = rm -f
$(BIN):$(OBJ)
@$(CC) $(LDFLAGES) $@ $^
@echo "Linking......$^ to $@"
%.o : %.c
@$(CC) $(CFLAGS) $<
@echo "Comling......$< to $@"
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN)
.PHONY:run
run:
@./$(BIN)使用👇
bash
$ make
Comling......Hello.c to Hello.o
Linking......Hello.o to Hello
$ make run
Hello makefile!
$ make clean
rm -f Hello.o Hello5. Linux第一个程序---进度条
5.1 换行与回车
换行(Line Feed,LF,\n)和回车(Carriage Return,CR,\r)的区别源于计算机历史,在系统中的表现主要取决于操作系统
核心区别
-
回车 (CR,
\r)- 起源 :机械打字机时代,表示将打印头移回行首(
Carriage Return) - 作用:光标回到当前行的开头,不换行
- ASCII 码 :
0x0D(十进制13)
- 起源 :机械打字机时代,表示将打印头移回行首(
-
换行 (LF,
\n)- 起源 :机械打字机中,表示滚筒下移一行(
Line Feed) - 作用:光标垂直移动到下一行,但水平位置不变
- ASCII 码 :
0x0A(十进制10)
- 起源 :机械打字机中,表示滚筒下移一行(
操作系统中的实现差异
| 系统 | 换行符表示 | 行为说明 |
|---|---|---|
| Linux/Unix/macOS(现代) | \n (LF) |
仅需一个字符表示换行: 1. 移动到下一行 2. 回到行首(隐含回车动作) |
| Windows | \r\n (CR+LF) |
需两个字符: 1. \r 回到行首 2. \n 移动到下一行 |
📌 关键点 :Linux 的
\n等价于 Windows 的\r\n,它同时完成了"回车+换行"两个动作
为什么在 Linux 中单独拎出来说
-
文件格式问题
- 若
Windows文件(含\r\n)在Linux中打开,多余的\r会显示为^M(如cat -A file可见),可能导致脚本错误 - 示例
:Shell脚本包含\r时,会报错bash: $'\r': command not found
- 若
-
工具兼容性
Linux工具(如grep,sed)默认按\n识别行尾。若文件含\r\n,可能影响文本处理
-
跨平台协作
Git等工具在Windows/Linux间同步代码时,可能自动转换换行符(通过core.autocrlf配置)
5.2 行缓冲区
在 C 语言中,标准输出流(stdout)默认使用行缓冲模式。也就是说输出内容会先存储在内存缓冲区中,直到满足特定条件才实际写入终端,下面具体分析:
换行符触发刷新(\n)
c
int main()
{
printf("Hello world!\n"); // 包含换行符
sleep(3);
return 0;
}- 结果 :立即输出 "Hello world!",然后等待
3秒 - 原理 :
\n符合行缓冲的刷新条件,触发缓冲区立即刷新
无刷新导致延迟输出
c
int main()
{
printf("Hello world!"); // 无换行符
sleep(3);
return 0;
}- 结果 :先等待
3秒,程序结束时才输出 "Hello world!" - 原理:
- 输出内容暂存缓冲区(未达到刷新条件)
sleep(3)期间缓冲区保持未刷新状态- 程序结束时自动刷新所有缓冲区
手动强制刷新缓冲区(fflush)
c
int main()
{
printf("Hello world!");
fflush(stdout); // 强制刷新
sleep(3);
return 0;
}- 结果 :立即输出 "Hello world!",然后等待
3秒 - 原理 :
fflush(stdout)强制清空缓冲区
缓冲区核心作用
-
减少系统调用
每次实际输出(如终端显示)需切换到内核态,频繁操作效率低下。缓冲区积累数据后批量写入,显著提升性能
-
优化I/O效率
示例中若每秒输出
1字符:- 无缓冲:触发
100次系统调用(效率极低) - 有缓冲:单次系统调用写入全部内容
- 无缓冲:触发
-
刷新触发条件
条件 示例 遇到换行符 \nprintf("text\n")缓冲区满 默认大小约4KB 手动刷新 fflush(stdout)程序正常终止 return 0/exit()
缓冲区工作流程
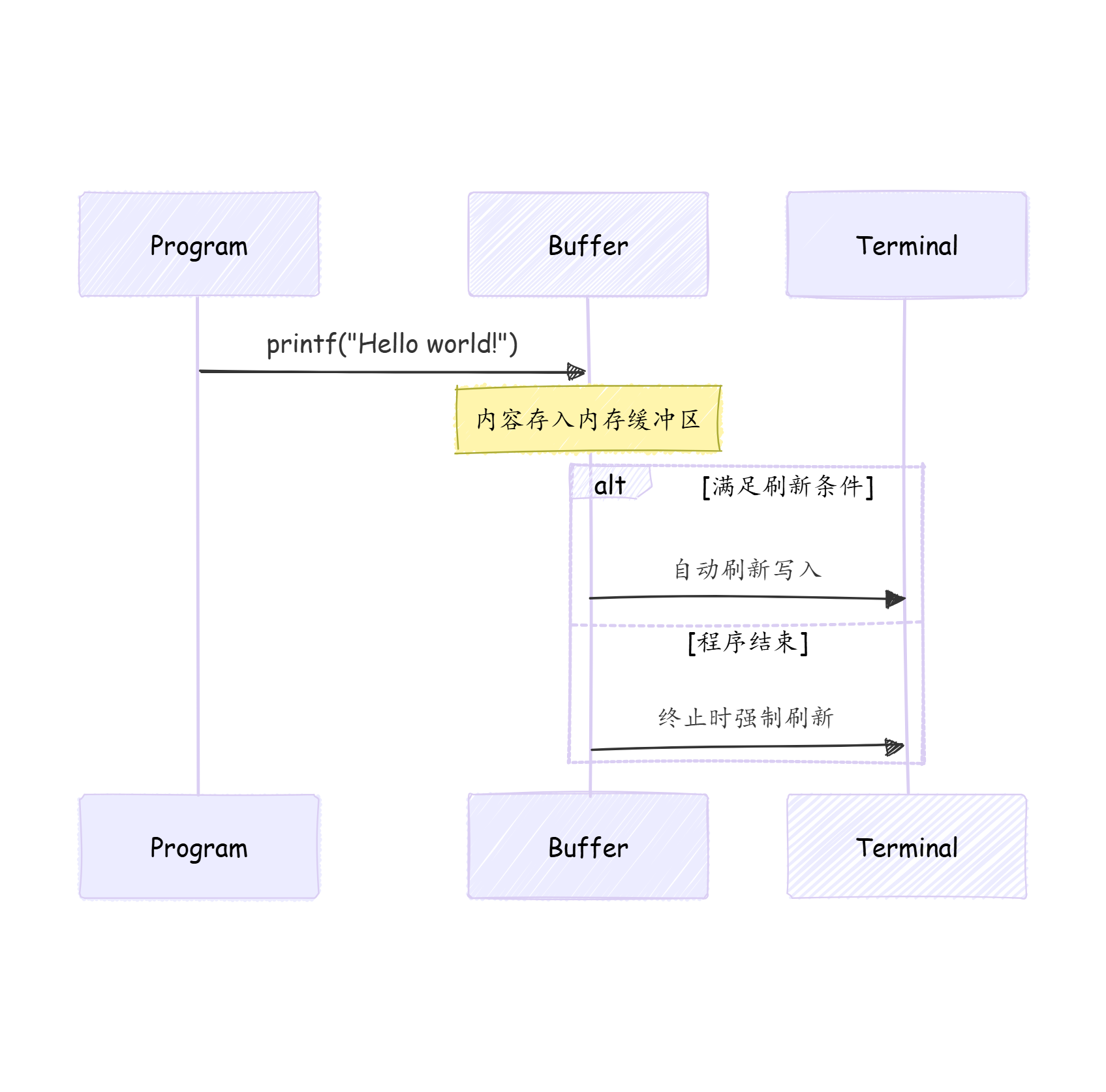
5.3 倒计时程序
下面基于上面所介绍的内容,实现一个简易的倒计时程序
c
// countdown.c
#include<stdio.h>
#include<unistd.h>
int main()
{
int count = 10;
printf("倒计时开始\n");
while(count)
{
printf("\r[ %2d ]", count);
fflush(stdout);
sleep(1);
count--;
}
printf("\n倒计时结束!\n");
return 0;
}结果
bash
$ ./countdown
倒计时开始
[ 1 ]
倒计时结束!
$ 5.4 进度条代码
c
// progress_bar.h
#pragma once
#include<stdio.h>
#include<unistd.h>
#include<time.h>
#include<stdlib.h>
#include<string.h>
void progress_bar();
c
// progress_bar.c
#include <stdio.h>
#include <unistd.h>
#include "progress_bar.h"
#define SIZE 100
#define TYPE "="
void progress_bar()
{
static const char labble[4] = {'|', '/', '-', '\\'};
char buffer[SIZE + 1];
memset(buffer, 0, sizeof(buffer));
for (int percent = 0; percent <= SIZE; percent++)
{
if (percent < SIZE)
buffer[percent] = TYPE[0];
printf("[%-*s][%3d%%][%c]\r", SIZE, buffer, percent, labble[percent % 4]);
fflush(stdout);
usleep(30000);
}
printf("\n");
}
c
// main.c
#include"progress_bar.h"
int main()
{
progress_bar();
return 0;
}效果
bash
$ ./progress_bar
[====================================================================================================][100%][|]
$ 扩展功能
c
#include "progress_bar.h"
typedef void(Cal)(double total, double current, char *name);
const double speed[] = {1.23, 0.28, 1.5, 1.1, 0.1, 2.5};
// 模拟因各种原因导致不同的下载速度
int len_speed = sizeof(speed) / sizeof(speed[0]);
// 模拟任务
void upload(double total, Cal cal)
{
double current = 0;
while (current < total)
{
usleep(20000);
current += speed[rand() % len_speed];
if (current > total)
{
current = total;
}
cal(total, current, "uploading");
if (current >= total)
{
current = total;
break;
}
}
printf("\n");
}
void download(double total, Cal cal)
{
double current = 0;
while (current < total)
{
usleep(10000);
current += speed[rand() % len_speed];
if (current > total)
{
current = total;
}
cal(total, current, "downloading");
if (current >= total)
{
break;
}
}
printf("\n");
}
int main()
{
srand(time(NULL));
upload(1024, progress_bar_extend);
download(4545,progress_bar_extend);
return 0;
}
c
//progress_bar.c
#include <stdio.h>
#include <unistd.h>
#include "progress_bar.h"
#define SIZE 100
#define TYPE "="
void progress_bar_extend(double total, double current, char *name)
{
static const char label[4] = {'|', '/', '-', '\\'};
static int len_label = sizeof(label) / sizeof(label[0]);
static int index_label = 0;
char buffer[SIZE + 1];
memset(buffer, 0, sizeof(buffer));
double percent = (current / total) * 100;
percent = percent < 0 ? 0 : (percent > 100 ? 100 : percent);
int pos = (int)(percent);
if (pos > 0)
memset(buffer, TYPE[0], pos);
printf("[%-*s][%3.1f%%][%c][%s...]\r", SIZE, buffer, percent, label[index_label % len_label], name);
index_label++;
fflush(stdout);
}
c
//progress_bar.h
#pragma once
#include<stdio.h>
#include<unistd.h>
#include<time.h>
#include<stdlib.h>
#include<string.h>
void progress_bar_extend(double total, double current, char *name);效果演示
bash
$ ./progress_bar
[====================================================================================================][100.0%][|][uploading...]
[====================================================================================================][100.0%][-][downloading...]
$ 6. 版本控制器Git
6.1 问题引入
想象一下你和同事 小王 正在合作撰写一份重要的项目报告(report.docx)。你们需要反复修改和完善这份文档
- 第一天: 你完成了初稿,保存为
report_v1.docx,然后通过邮件发给小王 - 第二天: 小王修改了你的版本,添加了新内容,保存为
report_v2_wang.docx,并邮件发回给你 - 第三天: 你收到小王的版本,发现他修改了某个你很重要的部分,同时你也有新的想法要加入。于是你:
- 基于
report_v1.docx修改了你认为重要的部分,保存为report_v1_final_me.docx。 - 又基于
report_v2_wang.docx添加了你的新想法,保存为report_v2_me_added.docx。
- 基于
- 第四天: 小王又发来一个文件
report_v3_wang_fixed.docx,说在v2的基础上修正了一些错误... - 问题爆发:
- 文件夹里堆满了
report_v1.docx,report_v1_final_me.docx,report_v2_wang.docx,report_v2_me_added.docx,report_v3_wang_fixed.docx... 哪个是最新的?哪个包含了你俩都认可的所有修改?哪次修改引入了那个关键错误? - 不小心覆盖了文件怎么办?误删了某个"版本"怎么办?
- 如何把你基于
v1的修改和小王在v2上的修改合并成一个包含所有内容的新版本?手动复制粘贴? - 某段文字被删了,是谁删的?什么时候删的?为什么删?
- 文件夹里堆满了
这就是"版本控制"要解决的核心问题!
在没有版本控制系统(如 Git)的情况下,协作修改文件(尤其是代码、配置、设计稿等文本类文件)会变得极其混乱、低效且充满风险
6.2 Git 登场:优雅的版本控制
为了方便我们管理不同的文件,便有了版本控制器,其能让你了解到一个文件的历史,以及它的发展此过程的系统。通俗的讲就是一个可以记录工程的每一次改动和版本迭代的一个管理系统,同时也方便多人协同作业
Git 几乎能管理任何文件格式: 但是,"可以管理"不等于"适合管理"或"管理得好"。 文件格式对 Git 的效率和实用性有着巨大影响
-
文本文件 (Text Files):Git 的"主战场"
- 优势:
- 差异比较 (Diff):
Git的核心功能之一是展示文件内容的变化(git diff)。对于文本文件(如.txt,.py,.java,.c,.html,.css,.js,.json,.xml,.md等),Git 可以清晰地逐行显示添加、删除或修改了哪些内容 - 高效存储:
Git使用差异算法(基于快照,但存储时复用相同内容)和压缩技术。当文本文件只有小部分修改时,Git只需要存储变化的部分,非常节省空间 - 合并 (Merge):
Git最强大的功能之一是自动合并不同分支上的修改。对于文本文件,只要修改发生在不同行,Git通常能完美地自动合并这些更改。如果修改了同一行(冲突),Git会明确标记出来让你手动解决 - 版本历史可读性: 查看文本文件的历史版本 (
git show) 或比较不同版本 (git diff commit1 commit2 -- file) 非常直观和有价值
- 差异比较 (Diff):
- 优势:
-
二进制文件 (Binary Files):Git 的"痛点"
- 劣势:
- 无法有效 Diff: 二进制文件(如图片
.jpg,.png, 视频.mp4, 音频.mp3, 压缩包.zip, 可执行文件.exe,.dll, Word 文档.docx,Excel表格.xlsx, PDF.pdf等)内部结构复杂。Git无法理解其内容,只能将其视为一大块不透明的二进制数据。运行git diff时,你只会看到类似Binary files a/file.jpg and b/file.jpg differ的信息,完全不知道具体哪里变了 - 低效存储:
Git对二进制文件的处理非常"笨拙"。即使二进制文件只改动了一个像素或一个字节,Git 通常也会存储整个文件的新副本 。这会导致仓库体积急剧膨胀 ,克隆、拉取、推送操作变得非常缓慢 - 无法自动合并: 如果两个分支都修改了同一个二进制文件,
Git无法自动合并它们。它只能报告冲突,并让你选择保留其中一个版本(通常是最后修改的那个),或者手动用外部工具合并(对于图片、设计稿等,这通常很困难甚至不可能) - 版本历史价值低: 查看历史版本的二进制文件需要完整检出该版本的文件并用专用软件打开,无法像文本文件那样快速浏览差异
- 无法有效 Diff: 二进制文件(如图片
- 劣势:
Git 是一个分布式版本控制系统 。它的核心思想是:记录文件的变化历史,而非保存多个完整的副本
引入 Git 后的优势总结:
- 完整历史记录: 每个文件如何一步步变成现在的样子,清晰可查
- 版本回溯: 轻松切换到任何一个历史版本(就像游戏读档),不怕改错代码或误删文件
- 高效协作: 多人并行工作,自动合并修改,大幅提升团队效率
- 分支管理:
Git允许创建独立的分支,用于开发新功能、修复Bug或做实验,而不会影响主线(main/master分支)。功能完成后可以合并回主线。这解决了"基于v1改还是基于v2改"的困境 - 责任追溯: 明确知道每行代码是谁、在什么时候、为什么修改
- 代码备份: 本地仓库和远程仓库(如
GitHub)共同构成了天然的备份机制
6.3 Git发展
Git 的发展史充满了传奇色彩,与 Linux 内核的开发密不可分
-
背景:Linux 内核的困境 (2005年之前)
Linux内核是一个庞大且由全球开发者协作的开源项目。- 在
2002年到2005年期间,Linux开发团队使用一个名为 BitKeeper的专有分布式版本控制系统。BitKeeper的创始人Larry McVoy免费授权Linux团队使用,条件是不能开发竞争工具 BitKeeper满足了Linux大规模分布式协作的需求,效果不错
-
导火索:BitKeeper 的终结 (2005年4月)
2005年,Linux内核社区和BitKeeper公司之间的关系破裂。具体原因涉及对BitKeeper使用协议条款的争议以及社区中有人尝试对BitKeeper协议进行逆向工程Larry McVoy收回了Linux团队的免费使用授权- 后果:
Linux开发团队瞬间失去了他们赖以协作的核心工具,面临巨大危机。当时的其他主流版本控制系统(如CVS,SVN)都是集中式的,无法满足Linux分布式、高性能、大规模协作的需求
-
林纳斯的"十日奇迹" (2005年4月)
Linux的创造者Linus Torvalds对当时的替代方案(如Monotone)都不满意,认为它们太慢、太复杂- 2005年4月3日:
Linus Torvalds决定自己动手开发一个新的版本控制系统 - 核心目标:
- 速度: 极快的操作(提交、分支切换、合并)
- 简单设计: 核心概念清晰、直接
- 强大的非线性分支支持: 鼓励频繁分支与合并(对内核开发至关重要)
- 完全分布式: 每个开发者都有完整的仓库历史,不依赖中央服务器
- 高效处理大型项目: 能轻松应对
Linux内核这样超大规模的项目 - 强数据完整性: 使用
SHA-1哈希(后来是 SHA-256)保证内容不被篡改
- 2005年4月7日:
Git实现了自托管(用Git来管理Git自身的开发) - 2005年4月18日: 合并多个外部贡献者的分支到
Git主线 - 2005年4月20日:
Linux内核2.6.12版本发布说明中提到了Git - 2005年7月:
Git已经足够成熟,可以接管Linux内核的版本控制工作
-
核心设计
- 快照,而非差异:
Git把每次提交看作项目文件在某个时间点的完整快照(虽然内部存储会复用未修改的文件,实现高效)。这与许多以文件差异为中心的系统不同。 - 本地操作: 几乎所有操作(查看历史、提交、分支、合并)都在本地完成,速度极快
- 数据完整性: 所有数据对象(文件内容、提交、树结构)都用其内容的
SHA-1哈希值命名。任何微小的改动都会改变哈希值,保证历史不可篡改 - "通常只添加数据": 绝大多数
Git操作只是向数据库添加数据,很难真正丢失数据(直到垃圾回收运行)
- 快照,而非差异:
-
成长与普及 (2005年至今)
- 2005年底:
Junio Hamano接手成为Git的核心维护者,并持续至今,对Git的稳定性和功能扩展贡献巨大。 - GitHub 的诞生 (2008年):
GitHub提供了一个基于Git的代码托管平台,极大地简化了协作流程(Pull Request,Issue Tracking,Web UI),将Git的强大功能包装成用户友好的界面,引爆了Git的普及。GitHub成为了开源世界的中心 - 竞争对手的出现:
GitLab(2011),Bitbucket(支持Git后) 等平台也提供了强大的Git托管服务 - 工具链完善: 围绕
Git开发了大量图形化客户端(如GitKraken,Sourcetree,Tower)、IDE集成插件(VS Code,IntelliJ等都有极佳的Git支持)和命令行辅助工具(如tig),降低了学习曲线 - 超越代码:
Git的核心思想被应用于管理配置文件、文档、书籍、甚至法律合同、设计稿(虽然对二进制文件支持不如文本好)等领域
- 2005年底:
-
现状
- 事实标准:
Git已成为全球软件开发领域绝对主导 的版本控制系统。几乎所有大型科技公司、开源项目和个人开发者都在使用Git - 持续活跃:
Git本身仍在积极开发和维护,不断引入新功能和性能优化(如部分克隆、稀疏检出、新的哈希算法支持SHA-256) - 生态系统庞大: 围绕
Git的托管服务、工具、工作流(Gitflow,GitHub Flow,GitLab Flow)形成了极其庞大的生态系统
- 事实标准:
6.4 Git的使用
6.4.1 核心概念
- 仓库 (Repository): 项目的版本控制数据库,包含所有文件的历史记录和元数据。本地仓库在项目目录下的
.git文件夹中;远程仓库托管在GitHub、GitLab等平台 - 工作区 (Working Directory): 我们实际看到和编辑的项目文件目录
- 暂存区 (Staging Area / Index): 一个中间区域,用于准备下一次提交的内容。用
git add将工作区的修改放入这里 - 提交 (Commit): 一个永久的、带描述的项目状态快照,保存在仓库历史中。由
git commit创建 - 分支 (Branch): 指向某个提交的可移动指针。默认分支通常是
main或master。允许我们在独立于主线的情况下开发新功能或修复 Bug - 远程 (Remote): 指向托管在网络上(如
GitHub)的仓库副本的引用(通常命名为origin)。用于与他人协作和备份
6.4.2 创建仓库
创建一个自己的仓库很简单,步骤如下:
- 登录 GitHub :打开 github.com 并登录你的账户
- 找到"新建仓库"按钮 :
- 在页面右上角,点击
+下拉菜单 - 选择
New repository
- 在页面右上角,点击
- 填写仓库信息 :
- Repository name:输入你的仓库名称(必填)
- Description:添加一个简短的描述(可选,但推荐)
- Public/Private:选择仓库是公开(所有人可见)还是私有(仅你授权的人可见)
- 初始化选项 (可选但推荐):
- 勾选
Add a README file:创建一个初始README文件(非常重要,用于介绍项目) - 勾选
.gitignore:选择模板(如Python、Node等)忽略不需要跟踪的文件 - 勾选
Choose a license:为你的项目选择一个开源许可证(不清楚许可证的可以不用选)
- 勾选
- 创建仓库 :点击页面底部的绿色按钮
Create repository
完成! 你已成功创建了一个新的 GitHub 仓库,可以开始上传代码、协作和管理项目了
创建完成之后,会看到 HTTPS 的链接,这个就是仓库的链接,后面的 git 操作会用到
6.4.3 git 命令
1. git clone
-
作用:将远程仓库复制到本地
-
命令 :
bashgit clone <远程仓库URL> # 默认克隆到同名目录 git clone <URL> <自定义目录名> # 克隆到指定目录 -
关键点 :
- 自动创建远程跟踪分支(如
origin/main) - 默认检出
main或master分支
- 自动创建远程跟踪分支(如
2. git pull
-
作用 :拉取远程分支最新内容并合并到当前分支(
= git fetch + git merge) -
命令 :
bashgit pull origin <分支名> # 拉取指定分支 git pull # 若已设置上游分支(upstream),可省略参数 -
冲突处理 :
- 若拉取时发生冲突,需手动解决冲突后提交
- 使用
git status查看冲突文件
3. git commit
-
作用 :将暂存区(
Staging Area)的修改保存到本地仓库 -
流程 :
-
添加修改到暂存区:
bashgit add <文件名> # 添加单个文件 git add . # 添加所有修改 -
提交到本地仓库:
bashgit commit -m "提交描述" # 必须填写清晰的描述
-
-
修正提交 :
-
修改最后一次提交:
bashgit commit --amend # 可修改描述或追加新更改
-
4. git push
-
作用:将本地提交推送到远程仓库
-
命令 :
bashgit push origin <分支名> # 推送到指定分支 git push -u origin <分支名> # 首次推送时设置上游分支(后续可简写为 `git push`)
5. 分支管理
-
创建分支 :
bashgit branch <新分支名> # 创建分支 git checkout -b <新分支名> # 创建并切换到该分支 -
切换分支 :
bashgit checkout <分支名> git switch <分支名> # Git 2.23+ 推荐方式 -
合并分支 :
bashgit merge <分支名> # 将指定分支合并到当前分支
6. 撤销操作
-
撤销工作区修改 :
bashgit restore <文件名> # 丢弃未暂存的修改(Git 2.23+) -
撤销暂存区文件 :
bashgit restore --staged <文件名> # 将文件移出暂存区 -
回退提交 :
bashgit reset --soft HEAD~1 # 撤销提交但保留修改 git reset --hard HEAD~1 # 彻底丢弃最近一次提交(谨慎使用!)
7. 查看状态与历史
-
状态检查 :
bashgit status # 查看工作区和暂存区状态 -
提交历史 :
bashgit log --oneline # 简洁版提交历史 git log -p # 显示详细修改内容
8. 冲突解决
- 触发场景 :
git pull或git merge时发生文件冲突 - 解决步骤 :
-
打开冲突文件(搜索
<<<<<<<标记) -
手动修改文件,保留所需内容
-
标记冲突已解决:
bashgit add <冲突文件名> git commit -m "解决冲突"
-
7. 调试器 gdb/cgdb
GDB
- 定位: 命令行调试器,功能极其强大,是
Linux/Unix环境下C/C++等程序调试的核心引擎 - 工作模式: 纯命令行交互。你输入命令,
GDB输出结果
CGDB (Curses GDB)
- 定位:
GDB的终端可视化前端 。它不是一个独立的调试器,而是一个封装了GDB的用户界面 - 核心思想: 将终端窗口分成两个主要窗格:
- 上部窗格: 显示当前正在调试的源代码(类似于
list命令的输出,但持续可见) - 下部窗格: 显示
GDB的命令行界面和输出(就是你直接使用GDB时看到的那个界面)
- 上部窗格: 显示当前正在调试的源代码(类似于
- 核心能力:
CGDB完全继承GDB的所有调试能力 ,因为它只是在GDB外面套了一个更友好的UI。你在CGDB的下部窗格中输入的命令,就是原汁原味的GDB命令
7.1 debug和release
- 程序的发布方式有两种,
debug和release模式,Linux下gcc/g++编译出来的二进制程序默认是release模式 - 要使用
gdb调试,必须 要源代码生成二进制程序的时候,加上-g(Generate debugging information) 选项,如果没有添加,不能用gdb调试
以下面的代码作为使用示例
c
#include <stdio.h>
int Sum(int start, int end)
{
int ret = 0;
for (int i = start; i <= end; i++)
{
ret += i;
}
return ret;
}
int main()
{
int s = 0;
int e = 100;
printf("Start Calculating\n");
int sum = Sum(s,e);
printf("From %d to %d.Sum is %d\n",s,e,sum);
return 0;
}debug vs release
bash
$ gcc sum.c -o s1
$ file s1
s1: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=41ec5e3b6e67c06874ac326252d2400c845df920, for GNU/Linux 3.2.0, not stripped
$ gcc -g sum.c -o s2
$ file s2
s2: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=8a2666fe3c73713f8232033ece4dc99edd172dcb, for GNU/Linux 3.2.0, with debug_info, not stripped
$ 在带了 -g 选项的二进制文件中,是明显带有 debug_info 的
7.2 gdb 使用
| 命令 | 简写 | 功能说明 |
|---|---|---|
list [file:]line/func |
l |
显示源代码。可指定文件、行号或函数名 |
break [file:]line/func |
b |
设置断点。可指定文件、行号、函数名或地址 |
info breakpoints |
i b |
列出所有断点信息 |
delete [breakpoints] [n] |
d |
删除所有断点或指定编号 n 的断点 |
run [arg1 arg2 ...] |
r |
从头开始运行程序(可带命令行参数) |
continue |
c |
从当前停止点继续运行程序。 |
next |
n |
单步执行(不进入函数)。执行下一行代码,如果遇到函数调用,将其视为一个整体执行 |
step |
s |
单步执行(进入函数)。执行下一行代码,如果该行是函数调用,则进入该函数内部 |
finish |
fin |
执行完当前函数,并停在函数返回后的位置 |
print expression |
p |
计算并打印表达式的值(变量、表达式、函数调用结果等) |
display expression |
disp |
每次程序停止时自动打印表达式的值 |
info locals |
i lo |
显示当前栈帧(函数)的局部变量 |
backtrace |
bt |
显示函数调用栈(栈回溯) |
frame [n] |
f |
选择栈帧 n(bt 输出中的编号)。f 0 通常是当前正在执行的函数 |
watch expression |
设置观察点,当表达式的值被改变时暂停程序 | |
set var [variable]=[value] |
set var | 运行时修改变量值 (例:set var x=10 或 set var ptr=0x7fffffffd) |
disable breakpoints [n] |
dis b [n] |
禁用断点 禁用指定编号的断点(如 dis b 2),若省略编号则禁用所有断点 |
enable breakpoints [n] |
ena b [n] |
启用断点 启用指定编号的断点(如 ena b 1-3),若省略编号则启用所有断点 |
info breakpoints |
i b |
扩展说明:列出断点详情 显示所有断点的编号、位置、启用状态、命中次数 (例:Num Type Disp Enb Address What) |
quit |
q |
退出 GDB |
7.3 开始调试
bash
$ gdb s2
GNU gdb (Ubuntu 15.0.50.20240403-0ubuntu1) 15.0.50.20240403-git
Copyright (C) 2024 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from s2...
(gdb) l # 查看源代码
1 #include <stdio.h>
2
3 int Sum(int start, int end)
4 {
5 int ret = 0;
6 for (int i = start; i <= end; i++)
7 {
8 ret += i;
9 }
10 return ret;
(gdb) # 在gdb中,上一次的命令可以直接通过回车的方式继续使用,而不需要再次输入
11 }
12
13 int main()
14 {
15 int s = 0;
16 int e = 100;
17 printf("Start Calculating\n");
18 int sum = Sum(s,e);
19 printf("From %d to %d.Sum is %d\n",s,e,sum);
20 return 0;
(gdb)
21 }
(gdb) b 16 # 创建断点,删除的时候通过断点的编号进行删除
Breakpoint 1 at 0x11b0: file sum.c, line 16.
(gdb) r
Starting program: /home/wyf/s2
This GDB supports auto-downloading debuginfo from the following URLs:
<https://debuginfod.ubuntu.com>
Enable debuginfod for this session? (y or [n]) y
Debuginfod has been enabled.
To make this setting permanent, add 'set debuginfod enabled on' to .gdbinit.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Breakpoint 1, main () at sum.c:16
16 int e = 100;
(gdb) i lo # 显示当前函数内的变量
s = 0
e = -8616
sum = 32767
(gdb) n
17 printf("Start Calculating\n");
(gdb)
Start Calculating
18 int sum = Sum(s,e);
(gdb) s # 进入函数内部
Sum (start=0, end=100) at sum.c:5
5 int ret = 0;
(gdb) watch ret # 监视ret的值,每次变换的时候都会停止
Hardware watchpoint 2: ret
(gdb) n
Hardware watchpoint 2: ret
Old value = -134230016
New value = 0
Sum (start=0, end=100) at sum.c:6
6 for (int i = start; i <= end; i++)
(gdb) n
8 ret += i;
(gdb)
6 for (int i = start; i <= end; i++)
(gdb)
8 ret += i;
(gdb)
Hardware watchpoint 2: ret
Old value = 0
New value = 1
Sum (start=0, end=100) at sum.c:6
6 for (int i = start; i <= end; i++)
(gdb)
8 ret += i;
(gdb)
Hardware watchpoint 2: ret
Old value = 1
New value = 3
Sum (start=0, end=100) at sum.c:6
6 for (int i = start; i <= end; i++)
(gdb)
Hardware watchpoint 2: ret
Old value = 3
New value = 6
Sum (start=0, end=100) at sum.c:6
6 for (int i = start; i <= end; i++)
(gdb) disable 2 # 移除当前观察点
(gdb) fin # 跳出当前函数
Run till exit from #0 Sum (start=0, end=100) at sum.c:6
0x00005555555551d5 in main () at sum.c:18
18 int sum = Sum(s,e);
Value returned is $1 = 5050
(gdb) n
Watchpoint 2 deleted because the program has left the block
in which its expression is valid.
19 printf("From %d to %d.Sum is %d\n",s,e,sum);
(gdb) i lo
s = 0
e = 100
sum = 5050
(gdb) n
From 0 to 100.Sum is 5050
20 return 0;
(gdb)
21 }
(gdb)
Download failed: Invalid argument. Continuing without source file ./csu/../sysdeps/nptl/libc_start_call_main.h.
__libc_start_call_main (main=main@entry=0x55555555519d <main>, argc=argc@entry=1, argv=argv@entry=0x7fffffffde58)
at ../sysdeps/nptl/libc_start_call_main.h:74
warning: 74 ../sysdeps/nptl/libc_start_call_main.h: No such file or directory
(gdb)
[Inferior 1 (process 1588250) exited normally]
(gdb) q
$7.4 补充:设置条件断点(Conditional Breakpoint)
设置条件断点
gdb
break [位置] if [条件]或给已存在的断点添加条件
gdb
condition [断点编号] [条件]具体使用方式
| 场景 | 命令示例 | 说明 |
|---|---|---|
| 新建条件断点 | break main if argc > 1 |
在 main 函数入口设置断点,仅当命令行参数> 1 时触发 |
break 18 if s == 0 |
在源代码 18 行设置断点,仅当变量 s 等于 0 时触发 |
|
break Sum if end > 50 |
在 Sum 函数入口设置断点,仅当 end 参数 > 50 时触发 |
|
| 修改现有断点 | condition 1 i == 50 |
为 1 号断点添加条件:仅当变量 i 等于 50 时触发 |
condition 2 ret % 5 == 0 |
为 2 号断点添加条件:仅当ret是5的倍数时触发 |
|
| 删除条件 | condition 3 |
删除 3 号断点的条件(变为普通断点) |
小技巧:使用 ignore 断点编号 次数 可以忽略断点前N次触发,如 ignore 1 100会跳过1号断点的前100次触发