llama-factory快速开始
文章目录
前言
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md这是GitHub中文介绍文档,里面的教程更加详细,本人记录是方便本人看,对于我已经熟练的部分,教程中可能不会细说甚至跳过。
不同的是,我用的模型是qwen3-4B
一、环境配置
1.1 训练顺利运行需要包含4个必备条件
1.机器本身的硬件和驱动支持(包含显卡驱动,网络环境等)
2.本项目及相关依赖的python库的正确安装(包含CUDA, Pytorch等)
3.目标训练模型文件的正确下载
4.训练数据集的正确构造和配置
1.2 llama-factory下载
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e '.[torch,metrics]'上述的安装命令完成了如下几件事
1.新建一个LLaMA-Factory 使用的python环境(可选) 安装LLaMA-Factory
2.所需要的第三方基础库(requirements.txt包含的库) 安装评估指标所需要的库,包含nltk, jieba,
- rouge-chinese 安装LLaMA-Factory本身,然后在系统中生成一个命令 llamafactory-cli(具体用法见下方教程)
1.3 环境下载
安装对应版本工具
1.cuda
2.pytorch等核心工具
测试torch版本:
import torch
print(torch.cuda.current_device())
print(torch.cuda.get_device_name(0))
print(torch.__version__)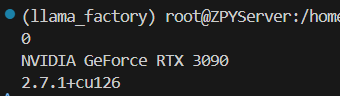
如果识别不到可用的GPU,则说明环境准备还有问题,需要先进行处理,才能往后进行。
1.4 硬件环境校验
nvidia-smi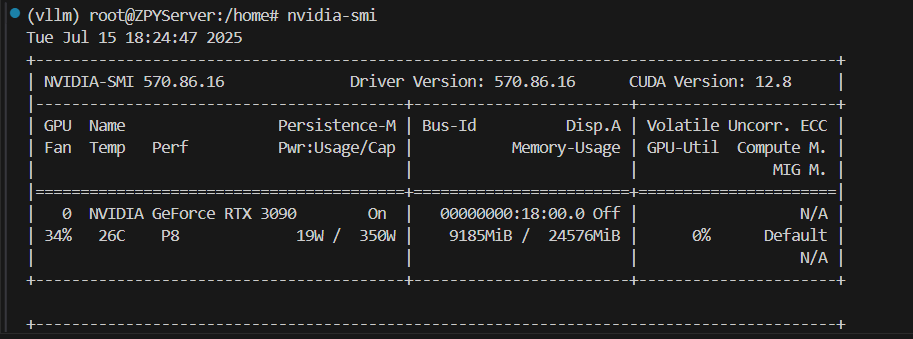
同时对本库的基础安装做一下校验,输入以下命令获取训练相关的参数指导, 否则说明库还没有安装成功
llamafactory-cli train -h
3.3 模型下载与可用性校验
参考链接:
下面文章的2.2部分
https://blog.csdn.net/2401_85252837/article/details/149342446?spm=1001.2014.3001.5502或者
1.项目支持通过模型名称直接从huggingface 和modelscope下载模型,但这样不容易对模型文件进行统一管理,所以这里笔者建议使用手动下载,然后后续使用时使用绝对路径来控制使用哪个模型。
以Meta-Llama-3-8B-Instruct为例,通过huggingface 下载(可能需要先提交申请通过)
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
2.modelscope 下载(适合中国大陆网络环境)
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
或者
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct')
由于网络环境等原因,文件下载后往往会存在文件不完整的很多情况,下载后需要先做一下校验,校验分为两部分,第一先检查一下文件大小和文件数量是否正确,和原始的huggingface显示的做一下肉眼对比二、启动
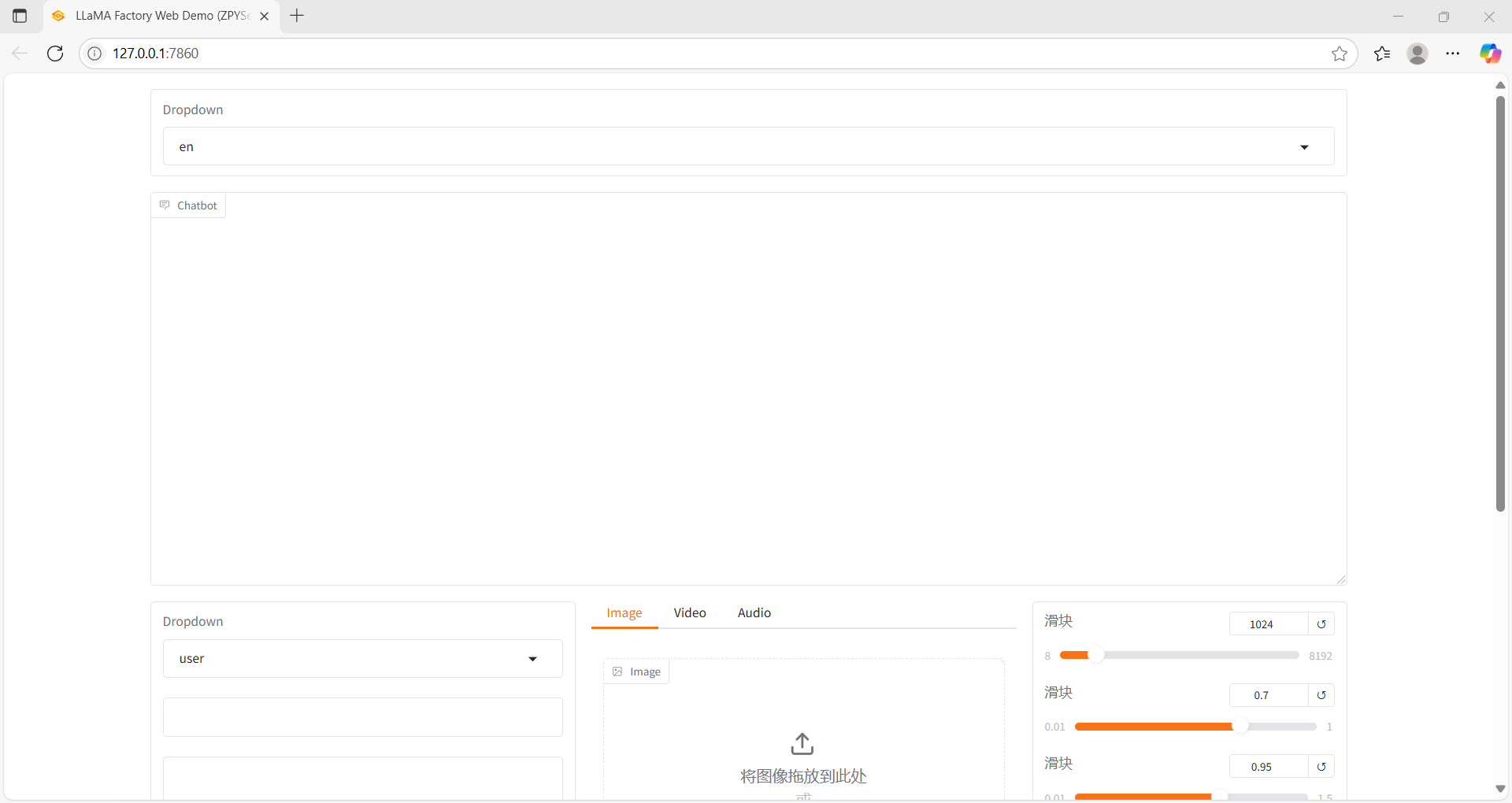
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path //home/models/Qwen3-4B \
--template qwen \