一、物理内存管理架构
物理内存通过Node -> Zone -> Page三级结构管理
1. Node (pglist_data)
关键字段:
c
// include/linux/mmzone.h
typedef struct pglist_data {
int node_id; // NUMA节点ID
struct page *node_mem_map; // 该节点所有page结构数组
unsigned long node_start_pfn; // 起始页帧号
unsigned long node_present_pages; // 实际可用物理页数
unsigned long node_spanned_pages; // 包含内存空洞的总页数
// 内存区域管理
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
// 内存回收机制
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd; // 内存回收守护进程
int kswapd_order; // kswapd回收的页块大小
enum zone_type kswapd_highest_zoneidx; // 最高回收区域索引
// 统计信息
unsigned long totalreserve_pages;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;2. struct zone (内存域)
解决硬件限制,不是所有物理内存对所有内核组件都"平等可用"。关键成员
c
struct zone {
/* 基本属性 */
const char *name; // 区域名称 ("DMA", "Normal"等)
unsigned long zone_start_pfn; // 区域起始页帧号
atomic_long_t managed_pages; // 被伙伴系统管理的页面数
/* 水线管理 */
unsigned long watermark_boost; // 水线提升值
unsigned long watermark[NR_WMARK]; // MIN, LOW, HIGH水线值
/* 空闲内存管理 */
struct free_area free_area[MAX_ORDER]; // 伙伴系统核心结构
unsigned long percpu_drift_mark; // per-CPU缓存水位
/* 内存保留 */
long lowmem_reserve[MAX_NR_ZONES]; // 为高优先级区域保留的内存
/* 统计信息 */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
/* 回收相关 */
unsigned long compact_cached_free_pfn;
unsigned long compact_cached_migrate_pfn[ASYNC_AND_SYNC];
};主要域 (ZONE):
c
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA, // 0-16MB。传统ISA设备DMA只能访问此范围。
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32, // (64位系统): 0-4GB。用于32位PCI设备DMA。
#endif
ZONE_NORMAL, // 直接映射到内核虚拟地址空间的部分。内核大部分动态分配和内核栈在此。驱动开发最常打交道的区域!
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM, // (32位系统): 物理内存超过内核直接映射范围的部分。需动态映射(kmap/kunmap)才能访问。
#endif
ZONE_MOVABLE, // 可移动页的集合,用于反碎片和内存热插拔。
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};3. struct page(页描述符)
内核为每个物理页帧维护一个struct page实例(存储在mem_map数组中),包含页的状态(空闲、使用中、脏、写回等)、引用计数、所属的zone、指向伙伴系统的链表指针、映射信息(谁在使用此页)等。 关键成员:
c
// include/linux/mm_types.h
struct page {
unsigned long flags; // 页状态标志
atomic_t _refcount; // 引用计数
union {
struct { // 页缓存和匿名页使用
union {
struct list_head lru; // LRU链表
struct dev_pagemap *pgmap; // 设备内存映射
};
struct address_space *mapping; // 文件映射
pgoff_t index; // 文件内偏移
};
struct { // SLAB分配器使用
struct kmem_cache *slab_cache;
void *freelist;
};
};
union {
unsigned long private; // 文件系统私有数据
spinlock_t *ptl; // 页表锁
};
void *virtual; // 内核虚拟地址
struct mem_cgroup *memcg_data; // CGroup内存控制
};页标志位
c
// page-flags.h
enum pageflags {
PG_locked, // 页面被锁定
PG_error, // I/O错误发生
PG_referenced, // 页面被访问
PG_uptodate, // 页面数据有效
PG_dirty, // 页面被修改
PG_lru, // 在LRU链表中
PG_active, // 在活跃LRU链表中
PG_slab, // SLAB分配器页面
PG_writeback, // 页面正在回写
// ...超过30种标志
};二、物理内存分配流程
内核中常用的分配物理内存页面的接口函数是 alloc_pages(),用于分配一个或多个连续的物理页面,分配的页面个数只能是2的整数次幂。诸如 vmalloc、 get_user_pages、以及缺页中断中分配页面,都是通过该接口分配的物理页面。
c
// include/linux/gfp.h
struct page *alloc_pages(gfp_t gfp_mask, unsigned int order);
核心参数:
gfp_mask:分配标志(Get Free Pages mask)
order:分配页数的对数(实际分配页数 = 2^order)
返回值:
成功:指向第一个page结构的指针
失败:NULL1. GFP掩码详解
c
// include/linux/gfp.h
// 1. 内存区域修饰符
__GFP_DMA (0x01u): 分配的内存页必须位于低 16MB 的内存中,通常用于旧的 ISA 设备。
__GFP_HIGHMEM (0x02u): 允许分配高内存(highmem)。高内存是指物理内存中超出内核直接映射范围的部分。
__GFP_DMA32 (0x04u): 分配的内存页必须位于低 4GB 的内存中,适用于一些只能访问 32 位地址空间的设备。
__GFP_MOVABLE (0x08u): 分配的内存页可以被移动(用于内存压缩等操作)。
// 2. 行为修饰符
__GFP_RECLAIMABLE (0x10u): 分配的内存页在需要时可以被回收。
__GFP_HIGH (0x20u): 允许分配高优先级的内存。
__GFP_IO (0x40u): 允许在分配过程中进行 I/O 操作。
__GFP_FS (0x80u): 允许在分配过程中调用文件系统操作。
__GFP_ZERO (0x100u): 分配后将内存页清零。
__GFP_ATOMIC (0x200u): 原子上下文分配,不允许睡眠。
__GFP_DIRECT_RECLAIM (0x400u): 允许直接回收内存。
__GFP_KSWAPD_RECLAIM (0x800u): 允许 kswapd(内核交换守护进程)回收内存。
__GFP_WRITE (0x1000u): 分配的内存页将用于写操作。
__GFP_NOWARN (0x2000u): 如果分配失败,不发出警告。
__GFP_RETRY_MAYFAIL (0x4000u): 如果分配失败,允许重试。
__GFP_NOFAIL (0x8000u): 不允许分配失败(可能会导致系统崩溃)。
__GFP_NORETRY (0x10000u): 如果分配失败,不重试。
__GFP_MEMALLOC (0x20000u): 允许分配内存用于内存分配(如 OOM 情况)。
__GFP_COMP (0x40000u): 分配的内存页将用于压缩。
__GFP_NOMEMALLOC (0x80000u): 不允许分配内存用于内存分配(与 __GFP_MEMALLOC 相反)。
__GFP_HARDWALL (0x100000u): 严格限制内存分配在当前节点。
__GFP_THISNODE (0x200000u): 仅在当前节点分配内存。
__GFP_ACCOUNT (0x400000u): 将分配的内存页计入内存使用统计。
__GFP_ZEROTAGS (0x800000u): 分配的内存页将清零所有标签。
__GFP_SKIP_KASAN_POISON (0x1000000u): 跳过 KASAN(Kernel Address Sanitizer)的内存毒化操作。
__GFP_CMA (0x2000000u): 分配的内存页将用于 CMA(Contiguous Memory Allocator)。
__GFP_NOLOCKDEP (0x4000000u): 禁用锁依赖检查。内核常用预定义组合
c
#define GFP_ATOMIC (__GFP_HIGH | __GFP_ATOMIC | __GFP_KSWAPD_RECLAIM) // 用于原子上下文,不允许睡眠,允许 kswapd 回收内存
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS) // 用于普通内核上下文,允许直接回收内存、I/O 操作和文件系统调用
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT) // 与 GFP_KERNEL 类似,但分配的内存页计入内存使用统计
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM) // 与 GFP_KERNEL 类似,但不允许直接回收内存,仅允许 kswapd 回收
#define GFP_NOIO (__GFP_RECLAIM) // 与 GFP_KERNEL 类似,但不允许在分配过程中进行 I/O 操作
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO) // 与 GFP_KERNEL 类似,但不允许调用文件系统操作
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL) // 用于用户空间内存分配,严格限制在当前节点
#define GFP_DMA __GFP_DMA // 分配位于低 16MB 内存中的页,适用于旧的 ISA 设备
#define GFP_DMA32 __GFP_DMA32 // 分配位于低 4GB 内存中的页,适用于只能访问 32 位地址空间的设备
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM) // 与 GFP_USER 类似,但允许分配高内存
#define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE | __GFP_SKIP_KASAN_POISON) // 与 GFP_HIGHUSER 类似,但分配的内存页可以被移动,并跳过 KASAN 的内存毒化操作
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | __GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM) // 用于透明大页分配,轻量级版本,不允许直接回收内存
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM) // 用于透明大页分配,完整版本,允许直接回收内存
/* Convert GFP flags to their corresponding migrate type */
#define GFP_MOVABLE_MASK (__GFP_RECLAIMABLE | __GFP_MOVABLE) // 用于提取与内存迁移相关的标志2. 物理内存分配流程(以alloc_pages为例)
2.1 代码调用流程
c
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
static inline struct page *__alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
static inline struct page *__alloc_pages(gfp_t gfp_mask, unsigned int order, int preferred_nid)
struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask)
static struct page *get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac)
static inline struct page *__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,struct alloc_context *ac)
static inline struct page *rmqueue(struct zone *preferred_zone, struct zone *zone, unsigned int order, gfp_t gfp_flags, unsigned int alloc_flags, int migratetype)2.2 快速路径分配 (get_page_from_freelist)
c
// mm/page_alloc.c
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx, ac->nodemask) {
// 1. 检查水线
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
continue;
// 2. 尝试分配
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
// 3. 页面初始化
prep_new_page(page, order, gfp_mask, alloc_flags);
return page;
}
}
return NULL;
}2.3 慢速路径分配 (__alloc_pages_slowpath)
c
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
retry:
// 1. 唤醒kswapd
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
// 2. 直接内存回收
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac, &did_reclaim);
if (page)
goto got_pg;
// 3. 内存压缩
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
// 4. OOM终结进程
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
// 5. 最终重试
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
fail:
return NULL;
}2.4 伙伴系统核心操作 (rmqueue)
c
static struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
// 尝试从指定迁移类型分配
page = __rmqueue(zone, order, migratetype, alloc_flags);
if (!page) {
// 尝试回退迁移类型
page = __rmqueue_fallback(zone, order, migratetype);
}
return page;
}3. 物理内存分配流程图
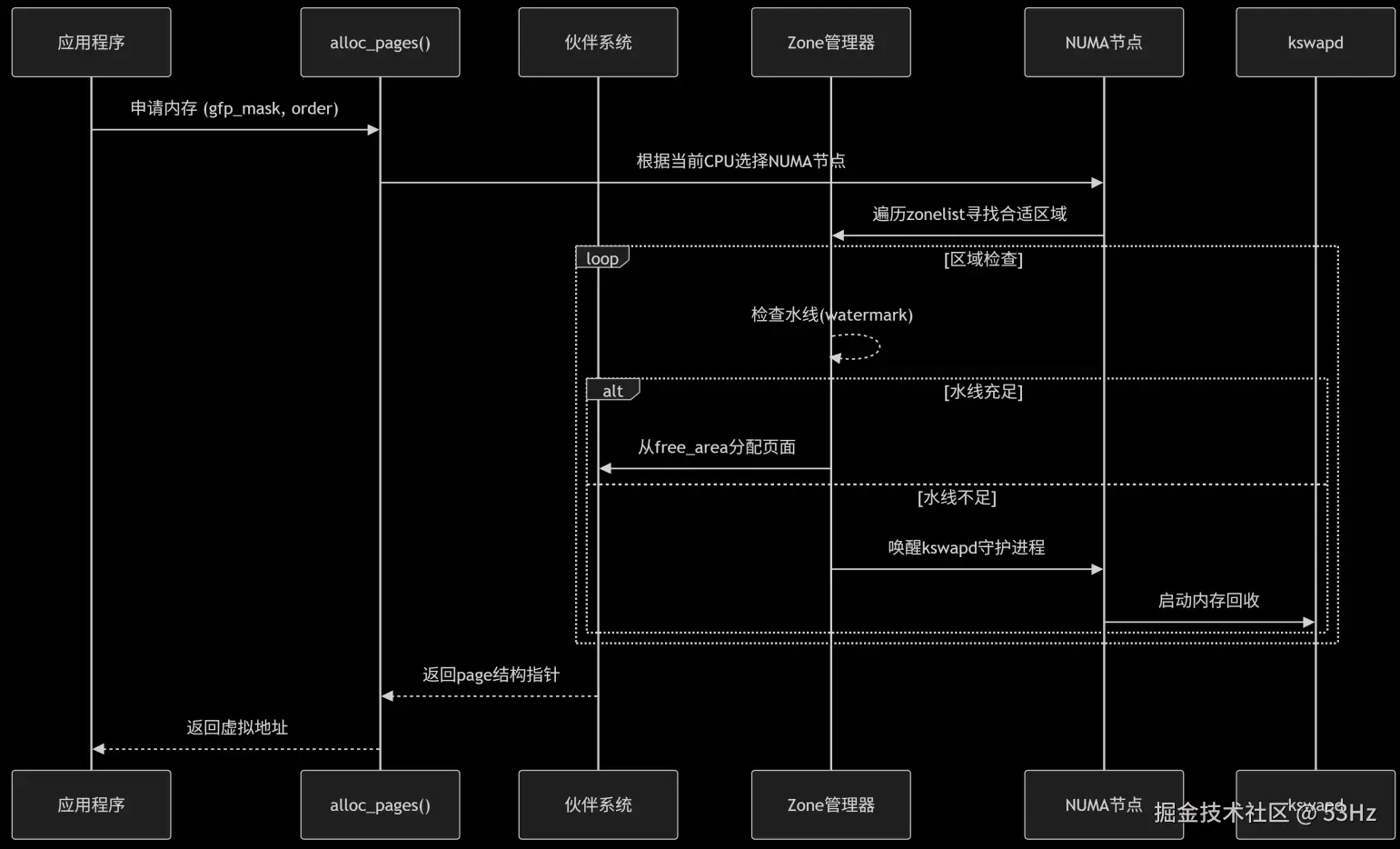
三、开发技巧
1. 上下文与GFP标志选择
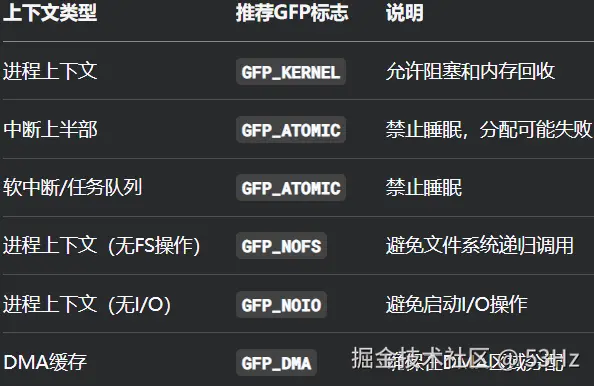 中断处理函数中的安全分配
中断处理函数中的安全分配
c
irqreturn_t interrupt_handler(int irq, void *dev_id)
{
struct page *page = alloc_pages(GFP_ATOMIC, 0);
if (!page) {
// 使用预分配缓冲
page = this_cpu_read(emergency_page);
}
...
}从连续内存区域分配
c
struct page *cma_alloc(struct cma *cma, size_t count, unsigned int align)
{
// 1. 尝试直接分配
page = alloc_contig_range(pfn, pfn + count, MIGRATE_CMA);
// 2. 失败时迁移页面
if (!page) {
ret = migrate_pages(&cma->migrate_pages, alloc_contig_range,
NULL, 0, MIGRATE_SYNC);
page = alloc_contig_range(pfn, pfn + count, MIGRATE_CMA);
}
return page;
}2. 大页分配
分配2MB大页 (order=9)
c
#define HPAGE_ORDER 9
struct page *hpage = alloc_pages(GFP_TRANSHUGE, HPAGE_ORDER); //GFP_TRANSHUGE:用于透明大页分配,完整版本,允许直接回收内存
if (!hpage) {
// 回退方案:尝试分配多个小页
hpage = alloc_pages(GFP_KERNEL, 0);
// ... 组合多个小页
}3. 错误处理
c
struct page *alloc_buffer_pages(int order)
{
struct page *page;
int retries = 0;
retry:
page = alloc_pages(GFP_KERNEL, order);
if (unlikely(!page)) {
if (order > 0) {
// 尝试降低分配阶
order--;
goto retry;
}
// 尝试紧急保留内存
page = alloc_pages(GFP_HIGHUSER | __GFP_NOFAIL, order);
}
if (!page && retries++ < 3) {
// 主动回收内存后重试
sync_filesystems(0);
try_to_free_pages(&zone, order, GFP_KERNEL);
goto retry;
}
return page;
}四、调试技巧
1. /proc接口分析
查看伙伴系统状态
c
cat /proc/buddyinfo
Node 0, zone DMA 1 1 1 0 2 1 1 0 1 1 3
Node 0, zone DMA32 314 273 452 240 187 124 77 55 35 20 16
解释:每列表示不同order(0-10)的空闲块数量
order0: 1个4KB块, order1: 1个8KB块, ... order10: 3个4MB块查看区域统计
c
cat /proc/zoneinfo
cat /proc/zoneinfo | grep -A10 "Node 0, zone DMA"
Node 0, zone DMA
per-node stats
nr_inactive_anon 76226
nr_active_anon 244
nr_inactive_file 67980
nr_active_file 18533
nr_unevictable 8171
nr_slab_reclaimable 15033
nr_slab_unreclaimable 14169
nr_isolated_anon 0
nr_isolated_file 02. 动态追踪
跟踪alloc_pages调用
c
echo 'p:alloc alloc_pages order=%dx gfp_flags=+0(%di):x32' > /sys/kernel/debug/tracing/kprobe_events触发跟踪
c
echo 1 > /sys/kernel/debug/tracing/events/kprobes/alloc/enable查看结果
c
cat /sys/kernel/debug/tracing/trace