目录
一.获取网页资源
1.获取渲染后的网页代码
使用 driver.page_source 获取浏览器渲染后的网页源代码(含动态加载内容图片音频等)。
优势:自动渲染,避免被反爬机制检测(模拟真实浏览器行为)。
python
import requests
import re
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/search?keyword=c++&jc=")
print(driver.page_source)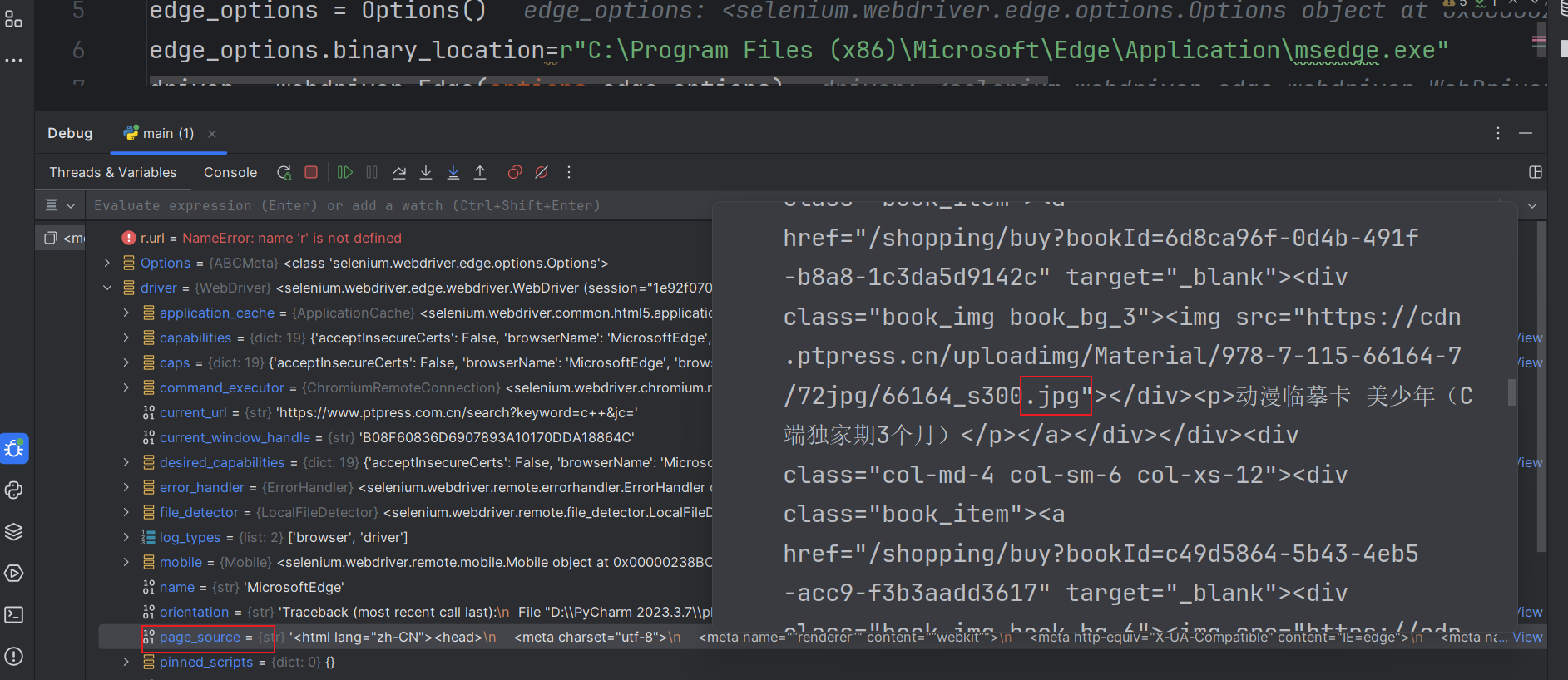
2.获取网页中的指定元素
我们可以使用正则表达式的方法进行过滤来获取我们想要的元素,而WebDriver对象中也提供了大量用于获取指定网页元素的方法
python
driver.find_element(self, by=By. , value=" ")返回的元素不止一个则用**find_elements()**方法,参数不变
我们可以在By.后面填写如下的属性ID,NAME等,value中则填写在需要爬取的网页中的对应属性的信息
python
class By(object):
"""
Set of supported locator strategies.
"""
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"如下演示找到百度识图中的上传图片对应的元素
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get(r"https://graph.baidu.com/pcpage/index?tpl_from=pc")
t_element = driver.find_element(by=By.NAME,value='file')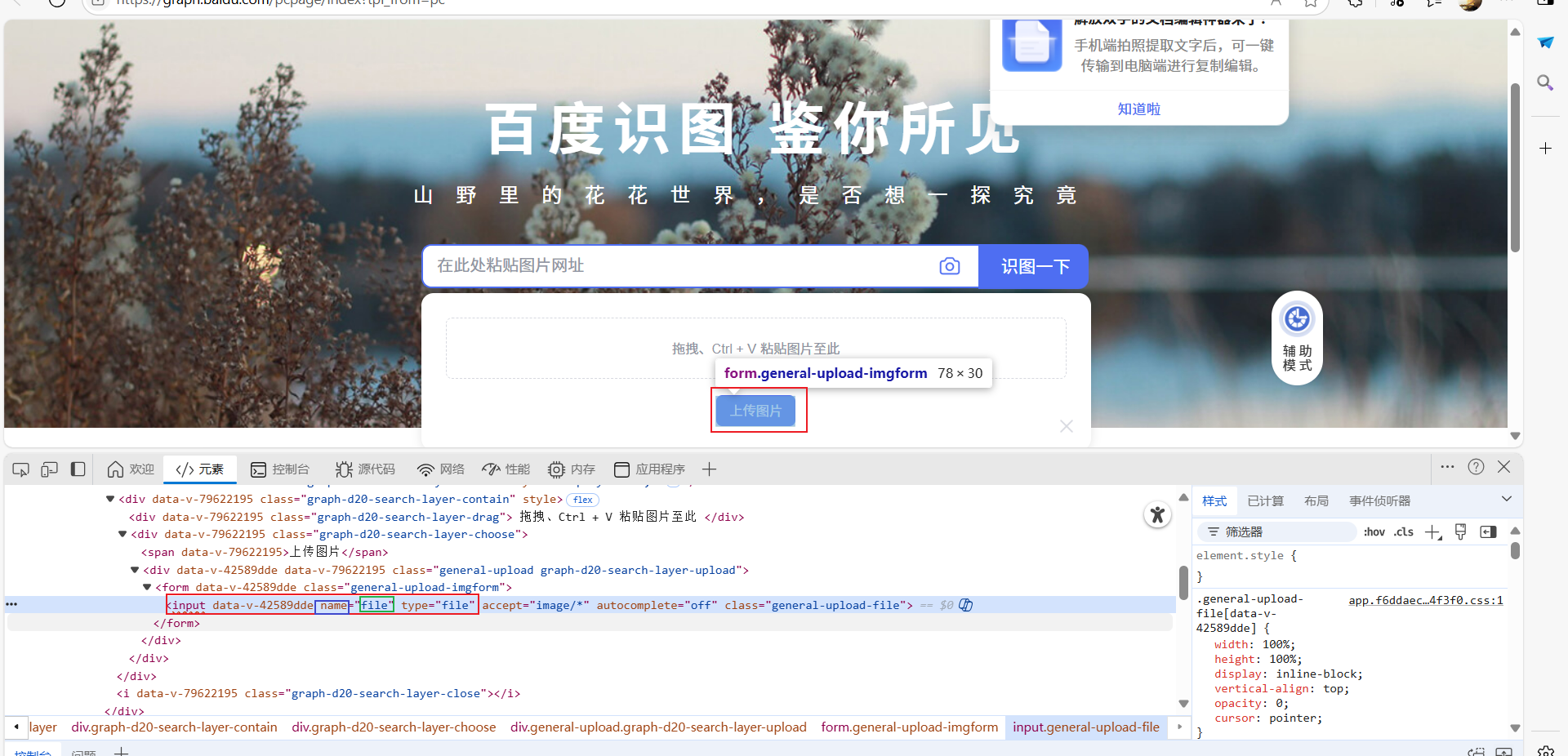
3.在元素中输入信息
python
driver.find_element(...).send_keys(输入的字符串信息)我们用send_keys()方法实现在元素中传递信息
例如在搜索框输入信息python,浏览器会自动输入不用我们手动输入
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/")
driver.find_element(By.TAG_NAME,value='input').send_keys("python")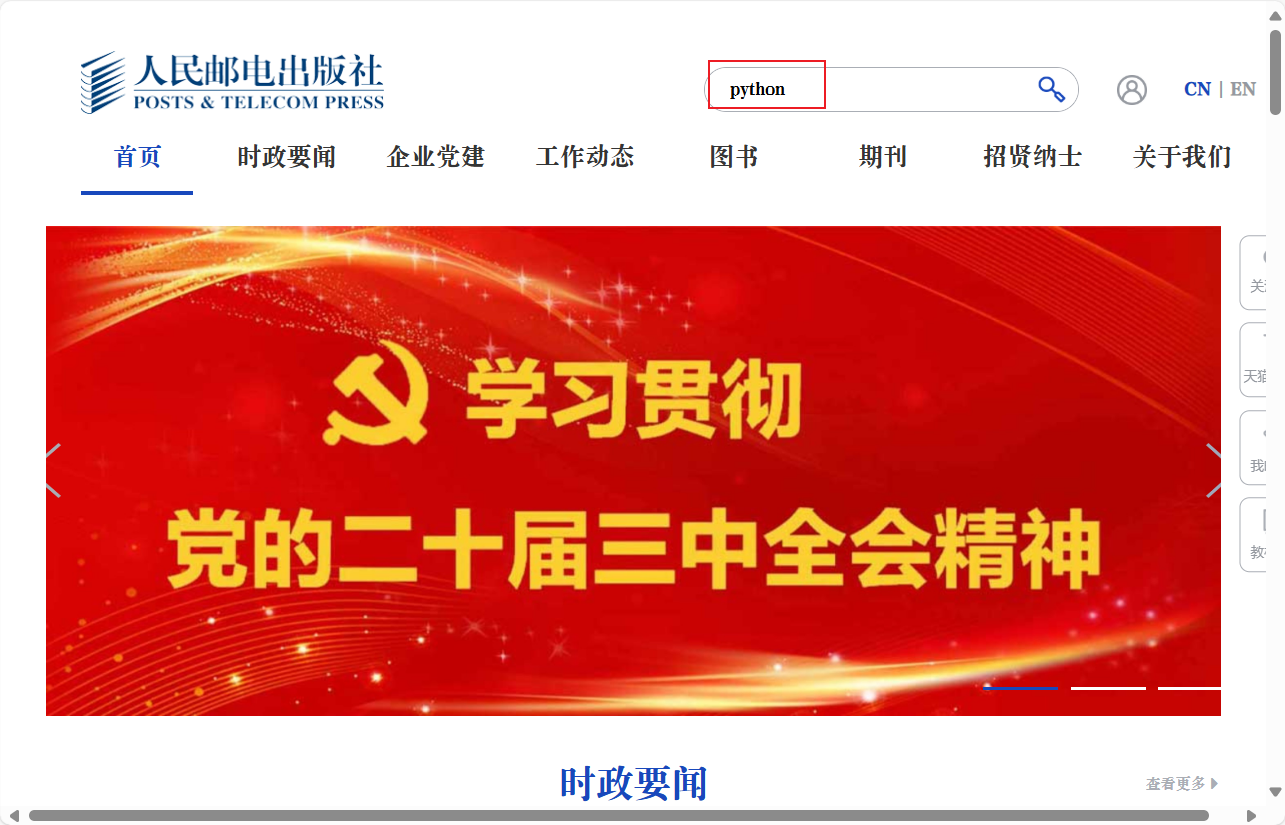
补充:如果我们将最后一个方法参数添加Keys.RETURN即send_keys("python"+Keys.RETURN)则表示输入信息后按下enter键
二.更多操作
①模拟点击
获取网页元素后可以使用click()方法实现点击该元素
python
driver.find_element(...).click()②WebDriver对象中的方法
back() :返回到上一个页面
forward():前进到下一个页面
refresh():刷新当前页面
quit():关闭当前浏览器
close():关闭当前标签页
三.不启动浏览器获取网页资源
在驱动浏览器时,可以设置无窗口模式,即驱动浏览器后并不会打开浏览器窗口,而是将网页代码在内存中处理,类Options中的add_argument()方法即可实现不启动浏览器的情况下获取网页资源
写下参数--headless即表明不启动浏览器窗口
python
Options().add_argument('--headless')