文章目录
- 开发指南
- 开发概念
- [理解 Streamlit 的执行模型](#理解 Streamlit 的执行模型)
- [运行你的 Streamlit 应用](#运行你的 Streamlit 应用)
-
- [使用 streamlit run](#使用 streamlit run)
-
- 向脚本传递参数
- [向 streamlit run 传递 URL](#向 streamlit run 传递 URL)
- [以 Python 模块方式运行 Streamlit](#以 Python 模块方式运行 Streamlit)
- [理解 Streamlit 的客户端-服务器架构](#理解 Streamlit 的客户端-服务器架构)
-
- [Python 后端(服务器)](#Python 后端(服务器))
- 浏览器前端(客户端)
- 服务器-客户端对应用设计的影响
- 应用界面框架
- 缓存机制概述
- 为应用添加状态管理
- 使用表单
- 使用片段
- 理解小部件行为
-
- 小部件的组成结构
-
- 小部件具有会话依赖性
- 小部件返回简单的Python数据类型
- 键(Key)帮助区分组件并访问其值
-
- [Streamlit 无法识别同一页面上的两个相同组件](#Streamlit 无法识别同一页面上的两个相同组件)
- 使用键值区分其他方面相同的组件
- 操作执行顺序
- 小部件的状态保持特性
- 小部件生命周期
- 补充示例
- 多页面应用
-
-
-
-
- 多页面应用概述
- [使用 `st.Page` 和 `st.navigation` 定义多页面应用](#使用
st.Page和st.navigation定义多页面应用) - [使用 `pages/` 目录创建多页面应用](#使用
pages/目录创建多页面应用) - 多页面应用中的部件使用
-
-
-
- 多页面应用概述
-
- [`st.Page` 与 `st.navigation`](#
st.Page与st.navigation) - [`pages/` 目录](#
pages/目录) - 页面术语
- 自动页面标签与URL生成
-
- 文件名及可调用对象的组成部分
- [Streamlit 如何将文件名转换为标签和标题](#Streamlit 如何将文件名转换为标签和标题)
- [Streamlit 如何将文件名转换为 URL 路径名](#Streamlit 如何将文件名转换为 URL 路径名)
- 页面间导航
- [`st.Page` 与 `st.navigation`](#
- [使用 `st.Page` 和 `st.navigation` 定义多页面应用](#使用
st.Page和st.navigation定义多页面应用) - [使用 `pages/` 目录创建多页面应用](#使用
pages/目录创建多页面应用) - 多页面应用中的部件使用
- 应用设计理念与注意事项
- 元素动画与更新
-
- [`st.empty` 容器](#
st.empty容器) - [`.add_rows()` 方法](#
.add_rows()方法)
- [`st.empty` 容器](#
- 按钮行为与示例
-
- 概述
- [何时使用 if st.button()](#何时使用 if st.button())
- 按钮的通用逻辑
-
- 通过按钮显示临时消息
- 状态化按钮
- 切换按钮
- 用于继续或控制流程阶段的按钮
- [修改 `st.session_state` 的按钮](#修改
st.session_state的按钮) - 用于修改或重置其他控件的按钮
- 动态添加其他小部件的按钮
- 处理耗时或文件写入操作的按钮
- 反模式
- 数据框
- [Streamlit 中的多线程](#Streamlit 中的多线程)
-
- 前提条件
- 何时使用多线程
- [Streamlit 创建的线程](#Streamlit 创建的线程)
- `streamlit.errors.NoSessionContext`
- 创建自定义线程
-
- [选项一:不在自定义线程中使用 Streamlit 命令](#选项一:不在自定义线程中使用 Streamlit 命令)
- [选项2:将 `ScriptRunContext` 暴露给线程](#选项2:将
ScriptRunContext暴露给线程)
- [在 Streamlit 应用中使用自定义 Python 类](#在 Streamlit 应用中使用自定义 Python 类)
-
- 定义自定义类的模式
-
- 模式1:在单独模块中定义类
- 模式2:强制类比较内部值
-
- [示例:定义 `eq`](#示例:定义
__eq__)
- [示例:定义 `eq`](#示例:定义
- 模式3:将类存储为序列化数据
- 模式4:利用缓存保持类状态
- 理解Python如何定义和比较类
-
- 示例:当重复定义同一个类时会发生什么?
- [Streamlit 中发生了什么?](#Streamlit 中发生了什么?)
- [Streamlit 组件如何存储选项](#Streamlit 组件如何存储选项)
- [在 Streamlit 中使用 `Enum` 类](#在 Streamlit 中使用
Enum类) -
- [理解 `enumCoercion` 配置选项](#理解
enumCoercion配置选项)
- [理解 `enumCoercion` 配置选项](#理解
- 处理时区问题
-
- [Streamlit 如何处理时区问题](#Streamlit 如何处理时区问题)
-
- [**不带时区的 `datetime` 实例(原生)**](#不带时区的
datetime实例(原生)) - [**带有时区的 `datetime` 实例**](#带有时区的
datetime实例)
- [**不带时区的 `datetime` 实例(原生)**](#不带时区的
- 处理连接、密钥与用户认证
- 连接数据源
-
- 基础用法
-
- 一个简单的起点------使用本地SQLite数据库
-
- 注意
- [步骤 1:安装必备库 - SQLAlchemy](#步骤 1:安装必备库 - SQLAlchemy)
- 步骤2:在Streamlit的secrets.toml文件中设置数据库URL
- 步骤3:在应用中使用连接
- 高级主题
-
- 全局密钥管理:多应用与多数据存储场景
- [高级 SQLConnection 配置](#高级 SQLConnection 配置)
- 频繁使用或长时间运行应用中的连接注意事项
- 构建自定义连接
- 连接构建最佳实践
- 密钥管理
- 用户认证与信息
-
- [OpenID Connect](#OpenID Connect)
- [`st.login()`、`st.user` 和 `st.logout()`](#
st.login()、st.user和st.logout()) - 用户Cookie与登出机制
- 配置身份提供程序
- [在 Streamlit 中配置 OIDC 连接](#在 Streamlit 中配置 OIDC 连接)
- 简单示例
- 使用多个OIDC提供商
- 向身份提供商传递关键字
- 安全提醒
- 自定义组件
- 自定义组件入门
- 创建一个组件
- 发布组件
-
- [发布到 PyPI](#发布到 PyPI)
-
- 准备你的组件
- [构建 Python wheel 包](#构建 Python wheel 包)
- 将你的wheel包上传至PyPI
- 推广你的组件!
- 自定义组件的限制
-
- Streamlit组件与基础Streamlit包提供的功能有何不同?
- [Streamlit 组件有哪些限制?](#Streamlit 组件有哪些限制?)
- 我的组件出现闪烁/卡顿现象...如何解决?
- 配置与自定义你的应用
- 配置选项的使用方法
- [HTTPS 支持](#HTTPS 支持)
- 静态文件服务
- 主题概述
- [自定义 Streamlit 应用中的颜色与边框](#自定义 Streamlit 应用中的颜色与边框)
-
- 颜色值
- [默认的 Streamlit 颜色](#默认的 Streamlit 颜色)
- 颜色与边框配置选项
-
- `primaryColor`
- [`backgroundColor`、`secondaryBackgroundColor`、`codeBackgroundColor` 和 `dataframeHeaderBackgroundColor`](#
backgroundColor、secondaryBackgroundColor、codeBackgroundColor和dataframeHeaderBackgroundColor) - [`textColor`、`linkColor` 和 `linkUnderline`](#
textColor、linkColor和linkUnderline) - [`baseRadius` 与 `buttonRadius`](#
baseRadius与buttonRadius) - [`borderColor`、`dataframeBorderColor` 和 `showWidgetBorder`](#
borderColor、dataframeBorderColor和showWidgetBorder)
- [自定义 Streamlit 应用中的字体](#自定义 Streamlit 应用中的字体)
- [Streamlit 原生应用测试框架](#Streamlit 原生应用测试框架)
- 应用测试入门指南
-
- [使用 `pytest` 的简单测试示例](#使用
pytest的简单测试示例) -
- [`pytest` 的结构解析](#
pytest的结构解析) - 带应用测试的示例项目
- [使用 `pytest` 进行简单测试](#使用
pytest进行简单测试) - [使用 `pytest` 处理文件路径与导入](#使用
pytest处理文件路径与导入)
- [`pytest` 的结构解析](#
- 应用测试基础
- [使用 `pytest` 的简单测试示例](#使用
- 超越应用测试基础
- 使用CI自动化测试
- 应用测试示例
- 应用测试速查表
开发指南
https://docs.streamlit.io/develop
获取使用Streamlit构建美观、高性能Web应用所需的所有信息!
-
核心概念 - 通过深入指南了解Streamlit的执行模型和功能特性。
-
API参考 - 查看函数定义和示例,掌握我们的API。
-
教程 - 按照分步指导构建示例应用和实用代码片段。
-
速查表 - 快速查阅变更日志、备忘单、预发布功能和路线图等便捷信息。
欢迎访问我们的论坛,这里有丰富的实用信息和Streamlit专家答疑。
开发概念
https://docs.streamlit.io/develop/concepts
本节将介绍 Streamlit 各组件的工作原理。
Streamlit 的架构与执行模型
https://docs.streamlit.io/develop/concepts/architecture
Streamlit 的执行模型能轻松将您的脚本转化为美观的交互式网页应用。
- 了解如何运行您的应用
- 理解 Streamlit 的执行机制及客户端-服务端模型
- 掌握处理 Streamlit 重运行的核心工具
多页面应用
https://docs.streamlit.io/develop/concepts/multipage-apps
Streamlit 通过目录结构提供了一种自动化方式来构建多页面应用。
- 了解如何组织和配置您的多页面应用。
应用设计考量
https://docs.streamlit.io/develop/concepts/design
结合 Streamlit 的架构与执行模型来设计您的应用。
通过 Streamlit 命令为用户呈现动态交互内容。
- 掌握如何让应用兼具高性能与易管理性
- 学习项目结构与设计方法
连接与密钥管理
https://docs.streamlit.io/develop/concepts/connections
- 了解如何通过Streamlit内置的便捷功能来管理连接和密钥。
创建自定义组件
https://docs.streamlit.io/develop/concepts/custom-components
自定义组件扩展了 Streamlit 的功能。
- 了解如何构建自己的自定义组件。
- 了解如何安装第三方组件。
配置与主题定制
https://docs.streamlit.io/develop/concepts/configuration
Streamlit 提供了多种选项来定制和配置您的应用。
- 了解如何配置各项参数,包括服务器设置、客户端设置以及主题定制。
应用测试
https://docs.streamlit.io/develop/concepts/app-testing
Streamlit 应用测试功能让开发者能够构建并运行自动化测试。
您可以使用自己喜爱的测试自动化工具,通过简洁的语法来模拟用户输入并检查渲染输出。
理解 Streamlit 的执行模型
https://docs.streamlit.io/develop/concepts/architecture
运行你的应用
了解如何启动你的 Streamlit 应用。
https://docs.streamlit.io/develop/concepts/architecture/run-your-app
Streamlit 的架构
了解 Streamlit 的客户端-服务器架构及相关注意事项。
https://docs.streamlit.io/develop/concepts/architecture/architecture
应用界面框架
每个 Streamlit 应用在右上角都设有几个控件,这些控件既能在开发过程中为您提供帮助,也能在用户查看应用时为他们提供支持。
这一区域被称为应用界面框架。
https://docs.streamlit.io/develop/concepts/architecture/app-chrome
缓存
通过缓存结果来提升应用性能,避免每次重新运行时不必要的重复计算。
https://docs.streamlit.io/develop/concepts/architecture/caching
会话状态
使用会话状态管理应用的状态保持特性。
https://docs.streamlit.io/develop/concepts/architecture/session-state
表单
使用表单来隔离用户输入,避免应用不必要的重新运行。
https://docs.streamlit.io/develop/concepts/architecture/forms
组件行为
深入了解组件的工作原理。
https://docs.streamlit.io/develop/concepts/architecture/widget-behavior
运行你的 Streamlit 应用
https://docs.streamlit.io/develop/concepts/architecture/run-your-app
使用 Streamlit 非常简单。
首先在普通 Python 脚本中添加一些 Streamlit 命令,然后运行它。
我们会根据不同的使用场景,列出几种运行脚本的方式。
使用 streamlit run
创建好脚本文件(例如 your_script.py)后,最简单的运行方式就是使用 streamlit run 命令:
shell
streamlit run your_script.py运行上述脚本后,本地 Streamlit 服务器将立即启动,应用程序会在默认网页浏览器的新标签页中打开。
向脚本传递参数
当需要向脚本传递自定义参数时,必须在两个短横线后添加这些参数。
否则,这些参数会被当作传递给 Streamlit 本身的参数。
shell
streamlit run your_script.py [-- script args]向 streamlit run 传递 URL
你也可以向 streamlit run 传递一个 URL!当你的脚本托管在远程位置时(例如 GitHub Gist),这个功能非常有用。
例如:
shell
streamlit run https://raw.githubusercontent.com/streamlit/demo-uber-nyc-pickups/master/streamlit_app.py以 Python 模块方式运行 Streamlit
另一种运行 Streamlit 的方式是将其作为 Python 模块运行。
这在配置 PyCharm 等 IDE 以支持 Streamlit 时非常有用:
# Running
python -m streamlit run your_script.py# is equivalent to:
streamlit run your_script.py理解 Streamlit 的客户端-服务器架构
https://docs.streamlit.io/develop/concepts/architecture/architecture
Streamlit 应用采用客户端-服务器结构。
应用的 Python 后端是服务器,通过浏览器查看的前端则是客户端。
当你在本地开发应用时,你的计算机会同时运行服务器和客户端。
如果有人通过本地或全球网络查看你的应用,服务器和客户端会运行在不同的机器上。
如果你打算分享或部署应用,理解这种客户端-服务器架构对避免常见问题非常重要。
Python 后端(服务器)
当你执行命令 streamlit run your_app.py 时,你的计算机会使用 Python 启动一个 Streamlit 服务器。
这个服务器是你应用的核心,负责为所有访问应用的用户执行计算。
无论用户是通过本地网络还是互联网访问应用,Streamlit 服务器始终运行在最初执行 streamlit run 的那台机器上。
运行 Streamlit 服务器的机器也被称为主机。
浏览器前端(客户端)
当用户通过浏览器访问你的应用时,他们的设备就是一个 Streamlit 客户端。
如果你在运行或开发应用的同一台电脑上查看应用,那么服务器和客户端会恰好在同一台机器上运行。
但当用户通过本地网络或互联网访问你的应用时,客户端和服务器则运行在不同的机器上。
服务器-客户端对应用设计的影响
在构建 Streamlit 应用时,请牢记以下注意事项:
- 运行或托管 Streamlit 应用的计算机需为所有用户提供运行应用所需的计算和存储资源,必须合理配置规模以处理并发用户。
- 应用无法访问用户的文件、目录或操作系统。
应用只能通过st.file_uploader等组件处理用户上传的特定文件。 - 若应用需与外围设备(如摄像头)通信,必须使用 Streamlit 命令或自定义组件,这些组件将通过用户浏览器访问设备,并确保客户端(前端)与服务器(后端)间的正确通信。
- 若应用需启动或使用 Python 之外的程序或进程,这些操作将在服务器端运行。
例如,试图用webbrowser为用户打开浏览器时,通过网络访问应用的用户将无法看到效果------浏览器会在 Streamlit 服务器上打开。
应用界面框架
https://docs.streamlit.io/develop/concepts/architecture/app-chrome
Streamlit 应用在右上角提供了一些控件,既方便开发者调试,也能帮助用户更好地使用应用。
我们将这些元素统称为"应用界面框架"(app chrome),包含状态区、工具栏和应用菜单三部分。
应用菜单支持自定义配置。
默认情况下,当你在本地或 Streamlit Community Cloud 上以管理员身份登录时,可以通过该菜单访问开发者选项。
只需点击右上角的图标即可展开菜单。
菜单选项
菜单分为两个部分。
上半部分包含所有查看者可用的选项,下半部分则为开发者提供专属功能。
更多关于自定义此菜单的内容,请参见本页末尾说明。
重新运行
你可以通过点击应用菜单中的"重新运行 "来手动触发应用的重新运行。
这次重新运行不会重置你的会话。
存储在st.session_state中的部件状态和值将被保留。
作为快捷方式,无需打开应用菜单,你可以通过按键盘上的"R"键来重新运行应用(前提是你当前没有聚焦在输入元素上)。
设置
通过"设置 "选项,您可以控制应用运行时的显示效果。
如果在本地查看应用,您可以设置应用如何响应源代码的更改。
有关开发流程的更多信息,请参阅基本概念。
您还可以强制应用以宽屏模式显示,即使未在脚本中使用st.set_page_config进行设置。
主题设置
点击应用菜单中的"设置 "后,您可以选择应用的基础主题为"浅色 "、"深色 "或"使用系统设置 "。
点击"编辑当前主题"可以逐色修改主题配置。

打印
点击"打印 "或使用键盘快捷键(⌘+P 或 Ctrl+P)打开打印对话框。
该功能调用浏览器的内置打印转PDF功能。
如需调整打印效果,可进行以下操作:
- 打印前展开或折叠侧边栏,以决定是否将其包含在打印内容中
- 在应用中通过点击并拖拽侧边栏右边界来调整宽度
- 若使用深色模式打印,可能需在打印对话框中启用"背景图形"选项
- 可能需要通过设置关闭宽屏模式,或调整打印比例以避免内容超出页面边界
录制屏幕演示
你可以直接在应用中轻松录制屏幕!最新版本的Chrome、Edge和Firefox均支持屏幕录制功能。
请确保浏览器已更新至最新版本以获得兼容性支持。
根据当前设置,你可能需要授权浏览器录制屏幕或使用麦克风(如需录制旁白)。
-
在查看应用时,点击右上角的应用菜单。
-
选择"录制屏幕演示"。
-
如需通过麦克风录制音频,勾选"同时录制音频"。
-
点击"开始录制"(操作系统可能会提示你允许浏览器录制屏幕或使用麦克风)。
- 从列出的选项中选择要录制的标签页、窗口或显示器。
界面会因浏览器不同而有所差异。
- 点击"分享"。
- 录制过程中,应用标签页和菜单图标上会显示红色圆点。
如需取消录制,点击应用底部的"停止分享"。
- 完成录制后,按键盘"Esc "键或点击应用菜单中的"停止录制"。
- 根据浏览器提示保存录制文件。
保存的录制文件将存储在浏览器默认下载位置。
完整流程如下:
关于
您可以通过"关于 "选项便捷地查看当前运行的 Streamlit 版本。
开发者还可以使用 st.set_page_config 来自定义此处显示的信息。
开发者选项
默认情况下,开发者选项仅在本地查看应用时,或以管理员权限登录查看社区云应用时才会显示。
如需向所有用户开放这些选项,您可以自定义菜单。
清除缓存
通过以下两种方式重置应用的缓存:从应用菜单中点击"清除缓存 ",或者在未聚焦输入元素时按键盘上的"C "键。
这将清除所有通过@st.cache_data和@st.cache_resource缓存的条目。
部署此应用
如果你正在本地git仓库中运行一个应用,只需简单几步点击即可将应用部署到Streamlit Community Cloud!开始前请确保你的工作已推送至GitHub在线仓库。
为获得最佳体验,请确保你已创建Community Cloud账户并处于登录状态。
- 点击应用菜单图标(more_vert )旁的"Deploy"按钮。
- 点击"Deploy now"按钮。
- 系统将跳转至Community Cloud的"Deploy an app"页面。
你的应用仓库、分支和文件名将自动匹配当前应用!了解更多关于在Streamlit Community Cloud上部署应用的信息。
整个流程如下所示:

自定义菜单
通过应用配置中的client.toolbarMode参数,您可以让应用菜单以以下方式显示:
"developer"--- 对所有查看者显示开发者选项"viewer"--- 对所有查看者隐藏开发者选项"minimal"--- 仅显示外部设置的选项。
这些选项可以通过st.set_page_config声明,或通过Streamlit Community Cloud自动填充"auto"--- 默认模式。
当通过localhost访问时,或通过Streamlit Community Cloud登录应用管理员账户时会显示开发者选项,其他情况下不显示开发者选项
缓存机制概述
https://docs.streamlit.io/develop/concepts/architecture/caching
Streamlit 会在每次用户交互或代码变更时从头到尾重新运行你的脚本。
这种执行模式让开发变得极其简单,但也带来两大挑战:
- 耗时函数会反复执行,导致应用运行缓慢
- 对象会不断被重新创建,难以在多次运行或会话间保持持久化
不过别担心!Streamlit 通过内置缓存机制帮你解决这两个问题。
缓存会存储慢速函数的调用结果,确保它们只需执行一次。
这能显著提升应用速度,并实现对象在多次运行间的持久化。
所有应用用户都能访问缓存值。
如需保存仅限当前会话访问的结果,请改用会话状态。
最小示例
要在 Streamlit 中缓存函数,必须使用两个装饰器之一(st.cache_data 或 st.cache_resource)来装饰它:
python
@st.cache_data
def long_running_function(param1, param2):
return ...在这个示例中,用@st.cache_data装饰long_running_function会告知Streamlit:每当调用该函数时,它会检查两个要素:
- 输入参数的值(此处指
param1和param2) - 函数内部的代码
如果这是Streamlit首次遇到这些参数值和函数代码组合,它会执行函数并将返回值存入缓存。
当后续用相同参数和代码调用函数时(例如用户与应用交互时),Streamlit会跳过函数执行直接返回缓存值。
在开发过程中,缓存会随函数代码变更自动更新,确保缓存始终反映最新修改。
如前所述,Streamlit提供两种缓存装饰器:
st.cache_data是缓存数据类计算的首选方式,适用于:从CSV加载DataFrame、转换NumPy数组、查询API等返回可序列化数据对象(字符串、整型、浮点数、DataFrame、数组、列表等)的场景。
每次调用时会创建数据的新副本,从而避免数据篡改和竞态条件问题。
st.cache_data的行为符合大多数场景需求------如果不确定如何选择,建议优先尝试st.cache_data!st.cache_resource适用于缓存全局资源,如ML模型或数据库连接等不可序列化且需避免重复加载的对象。
通过它可以在应用的所有重新运行和会话间共享这些资源,无需复制副本。
需注意:对缓存返回值的任何修改都会直接影响缓存中的对象(下文详述)。
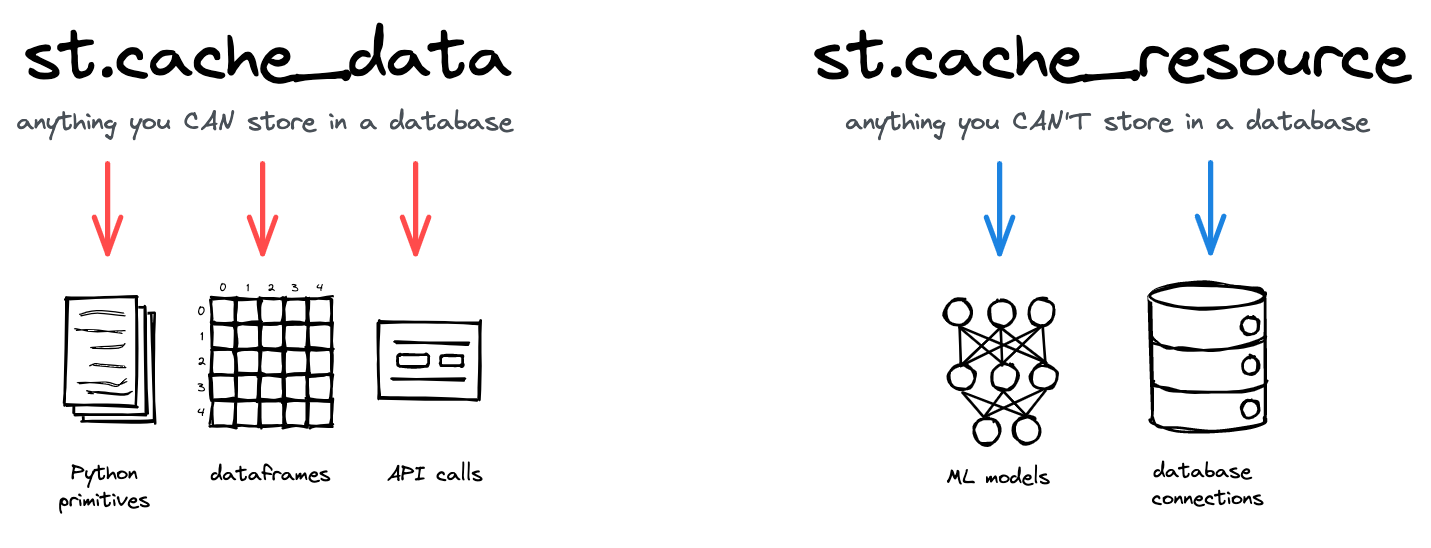 Streamlit的两种缓存装饰器及其用例。
Streamlit的两种缓存装饰器及其用例。
基本用法
st.cache_data
st.cache_data 是处理所有返回数据函数的首选命令------无论是DataFrame、NumPy数组、字符串、整数、浮点数还是其他可序列化类型。
它几乎是所有用例的理想选择!在每个用户会话中,被@st.cache_data装饰的函数会返回缓存返回值的一个副本(如果该值已被缓存)。
用法
让我们通过一个例子来了解如何使用 st.cache_data。
假设你的应用需要从网络加载 Uber 打车数据集(一个 50MB 的 CSV 文件)到 DataFrame 中:
python
def load_data(url):
df = pd.read_csv(url) # 👈 Download the data
return df
df = load_data("https://github.com/plotly/datasets/raw/master/uber-rides-data1.csv")
st.dataframe(df)
st.button("Rerun")运行 load_data 函数需要 2 到 30 秒,具体取决于您的网络连接速度。
(提示:如果网络较慢,可以使用这个 5 MB 的数据集替代)。
如果不启用缓存,每次加载应用或用户交互时都会重新下载数据。
点击我们添加的按钮亲自试试吧!体验不太理想...😕
现在让我们在 load_data 上添加 @st.cache_data 装饰器:
python
@st.cache_data # 👈 Add the caching decorator
def load_data(url):
df = pd.read_csv(url)
return df
df = load_data("https://github.com/plotly/datasets/raw/master/uber-rides-data1.csv")
st.dataframe(df)
st.button("Rerun")再次运行应用程序。
你会发现缓慢的下载仅发生在首次运行时。
之后的每次重新运行几乎都是瞬间完成的!💨
行为原理
它是如何工作的?让我们逐步解析 st.cache_data 的行为机制:
- 首次运行时 :Streamlit 检测到从未以指定参数值(CSV文件的URL)调用过
load_data函数,因此会执行该函数并下载数据。 - 缓存激活阶段 :返回的 DataFrame 通过 pickle 序列化(转换为字节),并与
url参数值一起存入缓存。 - 后续运行时 :Streamlit 检查缓存中是否存在对应特定
url的load_data条目。
若存在,则直接读取缓存对象,反序列化为 DataFrame 并返回,而无需重新执行函数和重复下载数据。
这种缓存对象的序列化与反序列化过程会创建原始 DataFrame 的副本。
虽然复制行为看似多余,但正是缓存数据对象时所需的效果------它能有效避免数据篡改和并发问题。
深入阅读下方章节「数据篡改与并发问题」可进一步理解此机制。
警告
st.cache_data 隐式使用了 pickle 模块,该模块已知存在安全隐患。
缓存函数返回的所有内容都会被序列化存储,并在读取时反序列化。
请确保你的缓存函数仅返回可信值,因为恶意构造的 pickle 数据可能在反序列化时执行任意代码。
切勿以不安全模式加载可能来自不可信源的数据,或可能被篡改的数据。
仅加载你信任的数据。
示例
DataFrame转换操作
在上面的例子中,我们已经展示了如何缓存加载DataFrame。
缓存DataFrame的转换操作(如df.filter、df.apply或df.sort_values)同样很有用。
特别是对于大型DataFrames,这些操作可能会很耗时。
python
@st.cache_data
def transform(df):
df = df.filter(items=['one', 'three'])
df = df.apply(np.sum, axis=0)
return df数组计算
同理,缓存 NumPy 数组上的计算也是有意义的:
python
@st.cache_data
def add(arr1, arr2):
return arr1 + arr2数据库查询
在使用数据库时,通常需要执行SQL查询将数据加载到应用程序中。
频繁运行这些查询会导致速度变慢、增加成本,并降低数据库性能。
我们强烈建议在应用程序中对所有数据库查询进行缓存。
如需深入了解具体示例,请参阅我们关于将Streamlit连接到不同数据库的指南。
python
connection = database.connect()
@st.cache_data
def query():
return pd.read_sql_query("SELECT * from table", connection)提示
建议设置 ttl(生存时间)参数以从数据库获取新结果。
例如,设置 st.cache_data(ttl=3600) 后,Streamlit 会在1小时(3600秒)后使缓存失效并重新执行缓存函数。
具体说明请参阅控制缓存大小与持续时间。
API调用
同样地,缓存API调用是合理的做法,这还能避免触发速率限制。
python
@st.cache_data
def api_call():
response = requests.get('https://jsonplaceholder.typicode.com/posts/1')
return response.json()运行机器学习模型(推理)
运行复杂的机器学习模型会消耗大量时间和内存。
为了避免重复执行相同的计算,建议使用缓存机制。
python
@st.cache_data
def run_model(inputs):
return model(inputs)st.cache_resource
st.cache_resource 是用于缓存"资源"的正确命令,这些资源应当全局可用,跨所有用户、会话和重新运行。
它的使用场景比 st.cache_data 更为有限,尤其适用于缓存数据库连接和机器学习模型。
在每个用户会话中,被 @st.cache_resource 装饰的函数会返回缓存后的返回值实例(如果该值已被缓存)。
因此,由 st.cache_resource 缓存的对象会表现得像单例模式,并且可以发生状态变化。
用法
以 st.cache_resource 为例,我们来看一个典型的机器学习应用场景。
第一步需要加载一个机器学习模型,这里我们使用 Hugging Face 的 transformers 库 来实现:
python
from transformers import pipeline
model = pipeline("sentiment-analysis") # 👈 Load the model如果我们直接将这段代码放入Streamlit应用中,每次重新运行或用户交互时,应用都会重新加载模型。
重复加载模型会带来两个问题:
-
加载模型耗时且会拖慢应用响应速度。
-
每个会话都需从头加载模型,这会占用大量内存。
更合理的做法是只加载一次模型,然后在所有用户和会话中复用该对象。
这正是st.cache_resource的适用场景!让我们将其添加到应用中,并处理用户输入的文本:
python
from transformers import pipeline
@st.cache_resource # 👈 Add the caching decorator
def load_model():
return pipeline("sentiment-analysis")
model = load_model()
query = st.text_input("Your query", value="I love Streamlit! 🎈")
if query:
result = model(query)[0] # 👈 Classify the query text
st.write(result)如果你运行这个应用,会发现它只在应用启动时调用一次load_model。
后续运行会复用缓存中的同一模型,从而节省时间和内存!
行为
使用 st.cache_resource 与使用 st.cache_data 非常相似,但在行为上有几个重要区别:
st.cache_resource不会 创建缓存返回值的副本,而是直接将对象本身存储在缓存中。
对函数返回值的所有修改都会直接影响缓存中的对象,因此必须确保来自多个会话的修改不会引发问题。
简而言之,返回值必须是线程安全的。
警告
在非线程安全的对象上使用 st.cache_resource 可能导致程序崩溃或数据损坏。
更多详情请参阅下方 数据变更与并发问题 章节。
- 不创建副本意味着缓存返回对象只有一个全局实例,从而节省内存(例如使用大型机器学习模型时)。
用计算机科学术语来说,我们创建了一个 单例模式。 - 函数的返回值不需要可序列化。
这一特性特别适合那些本质上不可序列化的类型,例如数据库连接、文件句柄或线程。
使用st.cache_data无法缓存这类对象。
示例
数据库连接
st.cache_resource 非常适合用于数据库连接。
通常,我们会创建一个全局复用的连接对象来执行所有查询。
如果在每次运行时都新建连接对象,不仅效率低下,还可能导致连接错误。
这正是 st.cache_resource 的用武之地,例如针对 Postgres 数据库的场景:
python
@st.cache_resource
def init_connection():
host = "hh-pgsql-public.ebi.ac.uk"
database = "pfmegrnargs"
user = "reader"
password = "NWDMCE5xdipIjRrp"
return psycopg2.connect(host=host, database=database, user=user, password=password)
conn = init_connection()当然,你也可以对其他数据库进行同样的操作。
查看我们关于如何将Streamlit连接到数据库的指南,获取详细的示例。
加载机器学习模型
你的应用应当始终缓存ML模型,这样它们就不会为每个新会话重复加载到内存中。
参考上面的示例,了解这在🤗 Hugging Face模型中的实现方式。
同样的方法也适用于PyTorch、TensorFlow等框架。
以下是一个PyTorch的示例:
python
@st.cache_resource
def load_model():
model = torchvision.models.resnet50(weights=ResNet50_Weights.DEFAULT)
model.eval()
return model
model = load_model()如何选择合适的缓存装饰器
前文展示了各个缓存装饰器的常见使用场景,但在某些边缘情况下,选择哪个装饰器可能不那么显而易见。
归根结底,关键在于区分"数据"和"资源"这两个概念:
- 数据 :指可序列化对象(可通过pickle转换为字节的对象),这类对象能轻松存储到磁盘。
典型例子包括通常存入数据库或文件系统的所有类型------基础类型如str、int和float,也包括数组、DataFrame、图像,或是这些类型的组合(列表、元组、字典等)。 - 资源 :指不可序列化的对象,通常不会存储到磁盘或数据库中。
这类对象往往更复杂且具有临时性,如数据库连接、机器学习模型、文件句柄、线程等。
从上述分类可以看出,Python中的大多数对象都属于"数据"。
这也解释了为什么st.cache_data能覆盖绝大多数使用场景。
而st.cache_resource属于更特殊的命令,仅适用于特定情况。
如果你不想费心思考,可以直接参考下表查找你的使用场景或返回类型😉:
| 使用场景 | 典型返回类型 | 缓存装饰器 |
|---|---|---|
| 用pd.read_csv读取CSV文件 | pandas.DataFrame | st.cache_data |
| 读取文本文件 | str, str列表 | st.cache_data |
| 转换pandas数据框 | pandas.DataFrame, pandas.Series | st.cache_data |
| numpy数组计算 | numpy.ndarray | st.cache_data |
| 基础类型简单计算 | str, int, float等 | st.cache_data |
| 数据库查询 | pandas.DataFrame | st.cache_data |
| API查询 | pandas.DataFrame, str, dict | st.cache_data |
| 运行ML模型(推理) | pandas.DataFrame, str, int, dict, list | st.cache_data |
| 创建/处理图像 | PIL.Image.Image, numpy.ndarray | st.cache_data |
| 创建图表 | matplotlib.figure.Figure, plotly.graph_objects.Figure, altair.Chart | st.cache_data(但某些库要求使用st.cache_resource,因为图表对象不可序列化------注意创建后不要修改图表!) |
| 延迟计算 | polars.LazyFrame | st.cache_resource(但对最终结果使用st.cache_data可能更合适) |
| 加载ML模型 | transformers.Pipeline, torch.nn.Module, tensorflow.keras.Model | st.cache_resource |
| 初始化数据库连接 | pyodbc.Connection, sqlalchemy.engine.base.Engine, psycopg2.connection, mysql.connector.MySQLConnection, sqlite3.Connection | st.cache_resource |
| 打开持久文件句柄 | _io.TextIOWrapper | st.cache_resource |
| 启动持久线程 | threading.thread | st.cache_resource |
高级用法
控制缓存大小与持续时间
如果您的应用程序长时间运行并持续缓存函数,可能会遇到两个问题:
-
由于缓存过大导致应用内存耗尽。
-
缓存中的对象变得陈旧,例如因为缓存了数据库中的旧数据。
您可以通过 ttl 和 max_entries 参数来解决这些问题,这两个参数在所有缓存装饰器中都可用。
ttl(生存时间)参数
ttl 为缓存函数设置一个生存时间。
当时间到期后再次调用该函数时,应用会丢弃所有旧的缓存值,并重新运行函数。
新计算的值随后会存入缓存。
这种行为有助于防止数据过时(问题2)和缓存无限增长(问题1)。
特别是在从数据库或API获取数据时,应始终设置 ttl 以避免使用旧数据。
例如:
python
@st.cache_data(ttl=3600) # 👈 Cache data for 1 hour (=3600 seconds)
def get_api_data():
data = api.get(...)
return data提示
你也可以使用 timedelta 来设置 ttl 值,例如 ttl=datetime.timedelta(hours=1)。
关于 max_entries 参数
max_entries 用于设置缓存中的最大条目数。
对缓存条目数量设置上限有助于限制内存使用(问题1),尤其是在缓存大型对象时。
当向已满的缓存添加新条目时,最旧的条目将被移除。
以下是一个示例:
python
@st.cache_data(max_entries=1000) # 👈 Maximum 1000 entries in the cache
def get_large_array(seed):
np.random.seed(seed)
arr = np.random.rand(100000)
return arr自定义加载指示器
默认情况下,当缓存函数运行时,Streamlit 会在应用中显示一个小的加载指示器。
你可以通过 show_spinner 参数轻松修改这一行为,该参数适用于所有缓存装饰器。
python
@st.cache_data(show_spinner=False) # 👈 Disable the spinner
def get_api_data():
data = api.get(...)
return data
@st.cache_data(show_spinner="Fetching data from API...") # 👈 Use custom text for spinner
def get_api_data():
data = api.get(...)
return data排除输入参数
在缓存函数中,所有输入参数必须是可哈希的。
让我们快速解释原因及其含义。
当函数被调用时,Streamlit会检查其参数值以确定是否之前被缓存过。
因此,它需要一种可靠的方式来比较不同函数调用间的参数值。
对于字符串或整数来说很简单------但对于任意对象则很复杂!Streamlit使用哈希来解决这个问题。
它将参数转换为一个稳定的键并存储该键。
在下次函数调用时,它会再次对参数进行哈希,并与存储的哈希键进行比较。
遗憾的是,并非所有参数都是可哈希的!例如,你可能向缓存函数传递了一个不可哈希的数据库连接或ML模型。
在这种情况下,你可以将输入参数排除在缓存之外。
只需在参数名前加上下划线(例如_param1),它就不会被用于缓存。
即使该参数发生变化,只要其他所有参数匹配,Streamlit仍会返回缓存的结果。
以下是一个示例:
python
@st.cache_data
def fetch_data(_db_connection, num_rows): # 👈 Don't hash _db_connection
data = _db_connection.fetch(num_rows)
return data
connection = init_connection()
fetch_data(connection, 10)但如果想缓存一个接收不可哈希参数的函数该怎么办?例如,你可能需要缓存一个以机器学习模型为输入并返回该模型各层名称的函数。
由于模型是唯一的输入参数,无法将其排除在缓存机制之外。
这时可以使用 hash_funcs 参数来为模型指定自定义的哈希函数。
hash_funcs 参数
如前所述,Streamlit 的缓存装饰器会对输入参数和缓存函数的签名进行哈希处理,以判断该函数是否曾经运行过且存储了返回值("缓存命中"),或者需要重新运行("缓存未命中")。
对于 Streamlit 哈希实现无法处理的不可哈希输入参数,可以通过在其名称前添加下划线来忽略它们。
但在以下两种罕见情况下,这种做法并不理想,即您希望对 Streamlit 无法哈希的参数进行哈希处理:
-
当 Streamlit 的哈希机制无法对参数进行哈希处理时,会抛出
UnhashableParamError错误。 -
当您希望覆盖 Streamlit 对某个参数的默认哈希机制时。
接下来我们将通过示例分别讨论这两种情况。
示例1:哈希自定义类
Streamlit 无法直接对自定义类进行哈希处理。
如果你将一个自定义类传递给缓存函数,Streamlit 会抛出 UnhashableParamError 错误。
例如,我们定义一个接受初始整型分数作为参数的自定义类 MyCustomClass,同时定义一个缓存函数 multiply_score,该函数会将分数乘以一个乘数:
python
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
@st.cache_data
def multiply_score(obj: MyCustomClass, multiplier: int) -> int:
return obj.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(multiply_score(score, multiplier))如果你运行这个应用,会发现 Streamlit 会抛出一个 UnhashableParamError 错误,因为它不知道如何对 MyCustomClass 进行哈希处理:
UnhashableParamError: Cannot hash argument 'obj' (of type __main__.MyCustomClass) in 'multiply_score'.为了解决这个问题,我们可以使用 hash_funcs 参数来告诉 Streamlit 如何对 MyCustomClass 进行哈希处理。
具体做法是向 hash_funcs 传递一个字典,该字典将参数名称映射到哈希函数。
哈希函数的选择由开发者决定。
在本例中,我们定义一个自定义哈希函数 hash_func,它以自定义类作为输入并返回分数。
我们希望将分数作为对象的唯一标识符,这样就可以用它来确定性哈希对象:
python
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
def hash_func(obj: MyCustomClass) -> int:
return obj.my_score # or any other value that uniquely identifies the object
@st.cache_data(hash_funcs={MyCustomClass: hash_func})
def multiply_score(obj: MyCustomClass, multiplier: int) -> int:
return obj.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(multiply_score(score, multiplier))现在运行应用时,你会发现 Streamlit 不再抛出 UnhashableParamError 错误,应用能按预期运行。
接下来我们考虑这种情况:multiply_score 是 MyCustomClass 的一个属性,而我们希望对整个对象进行哈希处理:
python
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
@st.cache_data
def multiply_score(self, multiplier: int) -> int:
return self.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(score.multiply_score(multiplier))运行此应用时,你会看到 Streamlit 抛出一个 UnhashableParamError 错误,因为它无法对 'multiply_score' 函数中的参数 'self'(类型为 main.MyCustomClass)进行哈希处理。
一个简单的解决方法是使用 Python 的 hash() 函数对该对象进行哈希处理:
python
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
@st.cache_data(hash_funcs={"__main__.MyCustomClass": lambda x: hash(x.my_score)})
def multiply_score(self, multiplier: int) -> int:
return self.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(score.multiply_score(multiplier))在上文中,哈希函数被定义为 lambda x: hash(x.my_score)。
这会基于 MyCustomClass 实例的 my_score 属性生成哈希值。
只要 my_score 保持不变,哈希值也会保持不变。
因此,无需重新计算,便可以从缓存中获取 multiply_score 的结果。
作为精明的 Python 开发者,你可能曾想使用 Python 的 id() 函数来哈希对象,如下所示:
python
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
@st.cache_data(hash_funcs={"__main__.MyCustomClass": id})
def multiply_score(self, multiplier: int) -> int:
return self.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(score.multiply_score(multiplier))如果你运行这个应用,会发现即使my_score没有变化,Streamlit每次都会重新计算multiply_score!感到困惑吗?在Python中,id()返回对象的唯一标识符,该标识符在对象生命周期内是唯一且恒定的。
这意味着即使两个MyCustomClass实例的my_score值相同,id()对这两个实例也会返回不同的值,从而导致不同的哈希值。
因此,Streamlit认为这两个不同的实例需要单独的缓存值,所以即使my_score没有变化,它每次都会重新计算multiply_score。
这就是为什么我们不建议将其用作哈希函数,而是鼓励使用返回确定性、真实哈希值的函数。
话虽如此,如果你清楚自己在做什么,也可以将id()用作哈希函数,但需要注意其后果。
例如,当你将@st.cache_resource函数的结果作为输入参数传递给另一个缓存函数时,id通常是正确 的哈希函数。
有一整类对象类型在其他情况下是不可哈希的。
示例2:对Pydantic模型进行哈希处理
让我们看另一个例子,这次我们希望对一个Pydantic模型进行哈希处理:
python
import streamlit as st
from pydantic import BaseModel
class Person(BaseModel):
name: str
@st.cache_data
def identity(person: Person):
return person
person = identity(Person(name="Lee"))
st.write(f"The person is {person.name}")上面我们使用 Pydantic 的 BaseModel 定义了一个自定义类 Person,它只有一个属性 name。
我们还定义了一个 identity 函数,该函数接受一个 Person 实例作为参数并原样返回。
这个函数旨在缓存结果,因此,如果多次使用相同的 Person 实例调用它,不会重新计算而是返回缓存的实例。
然而,如果你运行这个应用,会遇到 UnhashableParamError: Cannot hash argument 'person' (of type __main__.Person) in 'identity'. 错误。
这是因为 Streamlit 不知道如何对 Person 类进行哈希处理。
为了解决这个问题,我们可以使用 hash_funcs 参数来告诉 Streamlit 如何对 Person 进行哈希处理。
在下面的版本中,我们定义了一个自定义哈希函数 hash_func,它以 Person 实例作为输入并返回 name 属性。
我们希望 name 作为对象的唯一标识符,因此可以用它来确定性哈希对象:
python
import streamlit as st
from pydantic import BaseModel
class Person(BaseModel):
name: str
@st.cache_data(hash_funcs={Person: lambda p: p.name})
def identity(person: Person):
return person
person = identity(Person(name="Lee"))
st.write(f"The person is {person.name}")示例3:对机器学习模型进行哈希处理
在某些情况下,您可能希望将自己喜欢的机器学习模型传递给缓存函数。
例如,假设您想根据用户在应用中选择的模型,将TensorFlow模型传递给缓存函数。
您可能会尝试这样做:
python
import streamlit as st
import tensorflow as tf
@st.cache_resource
def load_base_model(option):
if option == 1:
return tf.keras.applications.ResNet50(include_top=False, weights="imagenet")
else:
return tf.keras.applications.MobileNetV2(include_top=False, weights="imagenet")
@st.cache_resource
def load_layers(base_model):
return [layer.name for layer in base_model.layers]
option = st.radio("Model 1 or 2", [1, 2])
base_model = load_base_model(option)
layers = load_layers(base_model)
st.write(layers)在上述应用中,用户可以选择两种模型之一。
根据所选模型,应用会加载对应的模型并将其传递给 load_layers 函数。
该函数随后返回模型中各层的名称。
运行应用时,你会发现 Streamlit 会抛出 UnhashableParamError 错误,因为它无法对 load_layers 函数中的参数 'base_model'(类型为 keras.engine.functional.Functional)进行哈希处理。
如果通过在参数名前添加下划线来禁用 base_model 的哈希处理,你会发现无论选择哪种基础模型,显示的层都是相同的。
这个细微的错误是由于当基础模型变更时,load_layers 函数并未重新执行。
这是因为 Streamlit 没有对 base_model 参数进行哈希处理,因此它不知道在基础模型变更时需要重新运行该函数。
为了解决这个问题,我们可以使用 hash_funcs 参数来告诉 Streamlit 如何对 base_model 参数进行哈希处理。
在下面的版本中,我们定义了一个自定义哈希函数 hash_func:Functional: lambda x: x.name。
我们选择这个哈希函数是基于对 Functional 对象或模型的 name 属性能够唯一标识它的了解。
只要 name 属性保持不变,哈希值也会保持不变。
因此,load_layers 的结果可以从缓存中获取,而无需重新计算。
python
import streamlit as st
import tensorflow as tf
from keras.engine.functional import Functional
@st.cache_resource
def load_base_model(option):
if option == 1:
return tf.keras.applications.ResNet50(include_top=False, weights="imagenet")
else:
return tf.keras.applications.MobileNetV2(include_top=False, weights="imagenet")
@st.cache_resource(hash_funcs={Functional: lambda x: x.name})
def load_layers(base_model):
return [layer.name for layer in base_model.layers]
option = st.radio("Model 1 or 2", [1, 2])
base_model = load_base_model(option)
layers = load_layers(base_model)
st.write(layers)在上述情况下,我们也可以使用 hash_funcs={Functional: id} 作为哈希函数。
这是因为当你将 @st.cache_resource 函数的结果作为输入参数传递给另一个缓存函数时,id 通常是正确的哈希函数。
示例4:覆盖Streamlit的默认哈希机制
让我们看另一个例子,我们想为pytz本地化的datetime对象覆盖Streamlit的默认哈希机制:
python
from datetime import datetime
import pytz
import streamlit as st
tz = pytz.timezone("Europe/Berlin")
@st.cache_data
def load_data(dt):
return dt
now = datetime.now()
st.text(load_data(dt=now))
now_tz = tz.localize(datetime.now())
st.text(load_data(dt=now_tz))令人惊讶的是,尽管 now 和 now_tz 同属 <class 'datetime.datetime'> 类型,Streamlit 却无法对 now_tz 进行哈希处理,并会抛出 UnhashableParamError 错误。
这种情况下,我们可以通过向 hash_funcs 参数传递自定义哈希函数,来覆盖 Streamlit 对 datetime 对象的默认哈希机制:
python
from datetime import datetime
import pytz
import streamlit as st
tz = pytz.timezone("Europe/Berlin")
@st.cache_data(hash_funcs={datetime: lambda x: x.strftime("%a %d %b %Y, %I:%M%p")})
def load_data(dt):
return dt
now = datetime.now()
st.text(load_data(dt=now))
now_tz = tz.localize(datetime.now())
st.text(load_data(dt=now_tz))现在让我们考虑一个需要覆盖 Streamlit 默认 NumPy 数组哈希机制的场景。
虽然 Streamlit 原生支持对 Pandas 和 NumPy 对象进行哈希处理,但在某些情况下,您可能需要覆盖这些对象的默认哈希机制。
例如,假设我们创建了一个带缓存装饰器的 show_data 函数,它接收一个 NumPy 数组并原样返回。
在下面的应用中,data = df["str"].unique()(这是一个 NumPy 数组)被传递给 show_data 函数。
python
import time
import numpy as np
import pandas as pd
import streamlit as st
@st.cache_data
def get_data():
df = pd.DataFrame({"num": [112, 112, 2, 3], "str": ["be", "a", "be", "c"]})
return df
@st.cache_data
def show_data(data):
time.sleep(2) # This makes the function take 2s to run
return data
df = get_data()
data = df["str"].unique()
st.dataframe(show_data(data))
st.button("Re-run")由于 data 始终相同,我们预期 show_data 函数会返回缓存值。
但当你运行应用并点击 Re-run 按钮时,会发现 show_data 函数每次都会重新执行。
可以推断这种行为是 Streamlit 对 NumPy 数组默认哈希机制的结果。
为解决这个问题,我们定义一个自定义哈希函数 hash_func,它接收 NumPy 数组作为输入并返回该数组的字符串表示:
python
import time
import numpy as np
import pandas as pd
import streamlit as st
@st.cache_data
def get_data():
df = pd.DataFrame({"num": [112, 112, 2, 3], "str": ["be", "a", "be", "c"]})
return df
@st.cache_data(hash_funcs={np.ndarray: str})
def show_data(data):
time.sleep(2) # This makes the function take 2s to run
return data
df = get_data()
data = df["str"].unique()
st.dataframe(show_data(data))
st.button("Re-run")现在如果你运行应用并点击Re-run按钮,会发现show_data函数不再每次都被重新执行。
这里需要重点说明的是,我们选择的哈希函数非常基础,未必是最佳选择。
例如,当NumPy数组很大时,将其转换为字符串形式可能开销较大。
这种情况下,开发者需要根据实际使用场景自行定义合适的哈希函数。
静态元素
从 1.16.0 版本开始,缓存函数可以包含 Streamlit 命令!例如,你可以这样做:
python
@st.cache_data
def get_api_data():
data = api.get(...)
st.success("Fetched data from API!") # 👈 Show a success message
return data众所周知,Streamlit 只会在函数未被缓存时运行它。
在首次运行时,st.success 消息会显示在应用中。
但后续运行时会发生什么?它依然会出现!Streamlit 会识别出缓存函数中存在 st. 命令,在首次运行时保存该命令,并在后续运行时重放它。
这种静态元素重放机制对两种缓存装饰器都有效。
您还可以利用这一特性来缓存整个 UI 部分:
python
@st.cache_data
def show_data():
st.header("Data analysis")
data = api.get(...)
st.success("Fetched data from API!")
st.write("Here is a plot of the data:")
st.line_chart(data)
st.write("And here is the raw data:")
st.dataframe(data)输入控件
你也可以在缓存函数中使用交互式输入控件,比如 st.slider 或 st.text_input。
目前,控件回放还是一项实验性功能。
要启用该功能,你需要设置 experimental_allow_widgets 参数:
python
@st.cache_data(experimental_allow_widgets=True) # 👈 Set the parameter
def get_data():
num_rows = st.slider("Number of rows to get") # 👈 Add a slider
data = api.get(..., num_rows)
return dataStreamlit 将滑块视为缓存函数的额外输入参数。
当你调整滑块位置时,Streamlit 会检查是否已缓存该滑块值对应的函数结果。
若存在缓存,则直接返回缓存值;若不存在,则使用新的滑块值重新运行函数。
在缓存函数中使用控件极具威力,因为这允许你缓存整个应用的部分功能。
但这也存在风险!由于 Streamlit 将控件值视为额外输入参数,极易导致内存过度消耗。
试想:若你的缓存函数包含五个滑块并返回 100 MB 的 DataFrame,那么针对这五个滑块值的每种排列组合 ,缓存都会增加 100 MB ------ 即便这些滑块根本不影响返回数据!这种累积会迅速撑爆你的缓存空间。
如果在缓存函数中使用控件,请务必注意此限制。
我们建议仅对控件直接影响缓存返回值的独立 UI 部分启用此功能。
警告
对缓存函数中 widget 的支持目前处于实验阶段。
我们可能随时更改或移除该功能,恕不另行通知。
请谨慎使用!
注意
目前缓存函数暂不支持两个组件:st.file_uploader 和 st.camera_input。
未来可能会提供支持。
如果你需要这些功能,欢迎提交 GitHub issue!
处理大规模数据
正如我们之前解释的,通常应该使用 st.cache_data 来缓存数据对象。
但对于超大规模数据(例如行数超过1亿的DataFrame或数组),这种方式可能会很慢。
这是因为 st.cache_data 的复制行为:在首次运行时,它会将返回值序列化为字节,并在后续运行时反序列化。
这两个操作都需要时间。
如果你处理的是超大规模数据,改用 st.cache_resource 可能更合适。
它不会通过序列化/反序列化创建返回值的副本,速度几乎瞬时。
但要注意:对函数返回值的任何修改(例如从DataFrame中删除列或设置数组中的值)都会直接操作缓存中的对象。
你必须确保这不会破坏数据或导致程序崩溃。
详见下文关于突变与并发问题的章节。
在对包含四列的pandas DataFrame进行 st.cache_data 基准测试时,我们发现当行数超过1亿后性能会显著下降。
下表展示了不同行数(均为四列)下两种缓存装饰器的运行时间:
| 1000万行 | 5000万行 | 1亿行 | 2亿行 | ||
|---|---|---|---|---|---|
| st.cache_data | 首次运行* | 0.4秒 | 3秒 | 14秒 | 28秒 |
| 后续运行 | 0.2秒 | 1秒 | 2秒 | 7秒 | |
| st.cache_resource | 首次运行* | 0.01秒 | 0.1秒 | 0.2秒 | 1秒 |
| 后续运行 | 0秒 | 0秒 | 0秒 | 0秒 |
| **表格中的首次运行时间仅显示使用缓存装饰器的开销时间,不包含被缓存函数本身的运行时间。 |
- |
突变与并发问题
在前面的章节中,我们详细讨论了缓存函数返回对象被修改时可能出现的问题。
这个话题相当复杂!但理解这些差异对于掌握st.cache_data和st.cache_resource的行为区别至关重要。
让我们更深入地探讨一下。
首先,我们需要明确定义什么是"突变"和"并发":
- 突变 指的是在缓存函数被调用后,对其返回值所做的任何修改。
例如类似这样的操作:
python
@st.cache_data
def create_list():
l = [1, 2, 3]
l = create_list() # 👈 Call the function
l[0] = 2 # 👈 Mutate its return value- 并发性 指的是多个会话可以同时引发这些数据变更。
Streamlit 是一个需要处理多用户和多会话连接应用的网页框架。
如果两个人同时访问一个应用,都会触发 Python 脚本重新运行,可能导致同时对缓存返回对象进行操作------即并发操作。
修改缓存返回对象可能存在风险。
这可能导致应用抛出异常,甚至损坏数据(后果比应用崩溃更严重!)。
接下来,我们将首先解释 st.cache_data 的复制行为,展示它如何避免数据变更问题。
然后,我们会演示并发变更如何导致数据损坏,以及如何预防这种情况。
复制行为
st.cache_data 在每次调用函数时都会创建缓存返回值的副本。
这避免了大多数数据变更和并发问题。
为了深入理解,让我们回顾上文 st.cache_data 章节中的 Uber 拼车示例。
我们对其做了两处修改:
-
改用
st.cache_resource而非st.cache_data。
st.cache_resource不会创建缓存对象的副本,因此我们可以观察没有复制行为时会发生什么。 -
加载数据后,我们直接操作返回的 DataFrame(原地修改!),删除了
"Lat"列。
代码如下:
python
@st.cache_resource # 👈 Turn off copying behavior
def load_data(url):
df = pd.read_csv(url)
return df
df = load_data("https://raw.githubusercontent.com/plotly/datasets/master/uber-rides-data1.csv")
st.dataframe(df)
df.drop(columns=['Lat'], inplace=True) # 👈 Mutate the dataframe inplace
st.button("Rerun")让我们运行一下看看会发生什么!第一次运行应该没问题。
但在第二次运行时,你会看到一个异常:KeyError: "['Lat'] not found in axis"。
为什么会这样呢?让我们一步步分析:
-
第一次运行时,Streamlit 执行
load_data并将生成的 DataFrame 存入缓存。由于我们使用的是
st.cache_resource,它不会创建副本,而是直接存储原始 DataFrame。 -
接着我们从 DataFrame 中删除了列
"Lat"。请注意,这里删除的是缓存中存储的原始 DataFrame 的列。
我们正在直接修改它!
-
第二次运行时,Streamlit 从缓存中返回的就是这个被修改过的 DataFrame。
它已经不再包含
"Lat"列了!因此我们的df.drop调用导致了异常。Pandas 无法删除不存在的列。
st.cache_data 的复制行为可以防止这类数据篡改错误。
修改操作只会影响特定副本,而不会波及缓存中的底层对象。
下次重新运行时,会获得自己那份未被修改的 DataFrame 副本。
你可以自己试试,只需将上面的 st.cache_resource 替换为 st.cache_data,就会发现一切正常。
由于这种复制机制,st.cache_data 是被推荐用于缓存数据转换和计算操作的方式------适用于任何返回可序列化对象的场景。
并发问题
现在让我们看看当多个用户同时修改缓存中的对象时会发生什么。
假设你有一个返回列表的函数。
我们再次使用 st.cache_resource 来缓存它,以避免创建副本:
python
@st.cache_resource
def create_list():
l = [1, 2, 3]
return l
l = create_list()
first_list_value = l[0]
l[0] = first_list_value + 1
st.write("l[0] is:", l[0])假设用户A运行该应用,他们将看到以下输出:
l[0] is: 2
Let's say another user, B, visits the app right after. In contrast to user A, they will see the following output:
`l[0] is: 3现在,用户A在用户B之后立即重新运行应用程序。
他们将看到以下输出:
l[0] is: 4
这里发生了什么?为什么所有输出都不同?
-
当用户A访问应用时,
create_list()被调用,列表[1, 2, 3]被存入缓存。随后该列表返回给用户A。
列表的第一个值
1被赋给first_list_value,同时l[0]被改为2。 -
当用户B访问应用时,
create_list()返回缓存中已被修改的列表:[2, 2, 3]。列表的第一个值
2被赋给first_list_value,同时l[0]被改为3。 -
当用户A重新运行应用时,
create_list()再次返回被修改的列表:[3, 2, 3]。列表的第一个值
3被赋给first_list_value,同时l[0]被改为4。
仔细想想,这是合理的。
用户A和B使用的是同一个列表对象(缓存中存储的那个)。
由于列表对象被修改,用户A对列表对象的更改也会反映在用户B的应用中。
这就是为什么在使用st.cache_resource缓存可变对象时必须格外小心,特别是当多个用户同时访问应用时。
如果我们改用st.cache_data而非st.cache_resource,应用会为每个用户复制列表对象,那么上述示例就会按预期工作------用户A和B都会看到:
l[0] is: 2
注意
这个简单的例子看似无害。
但数据损坏可能极其危险!想象一下,如果我们处理的是某大型银行的财务记录。
你肯定不希望一觉醒来账户里的钱变少了,仅仅因为有人用错了缓存装饰器 😉
从 st.cache 迁移
我们在 Streamlit 1.18.0 版本中引入了上述缓存命令。
在此之前,我们只有一个全能命令 st.cache。
使用它常常令人困惑,会导致奇怪的异常,并且速度较慢。
这就是为什么我们在 1.18.0 版本中用新命令替换了 st.cache(更多内容请阅读这篇博客文章)。
新命令提供了一种更直观、更高效的方式来缓存数据和资源,旨在取代所有新开发中的 st.cache。
如果你的应用仍在使用 st.cache,请不要担心!以下是迁移时的一些注意事项:
- 如果你的应用使用了
st.cache,Streamlit 会显示一个弃用警告。 - 我们不会很快移除
st.cache,所以你不需要担心两年前的应用会崩溃。
但我们鼓励你尝试使用新命令------它们会减少很多麻烦! - 在大多数情况下,将代码切换到新命令应该很容易。
要决定使用st.cache_data还是st.cache_resource,请阅读决定使用哪个缓存装饰器。
Streamlit 还会识别常见用例,并在弃用警告中直接显示提示。 st.cache中的大多数参数也存在于新命令中,但有一些例外:-
allow_output_mutation不再存在。你可以安全地删除它。
只需确保为你的用例使用正确的缓存命令。
-
suppress_st_warning不再存在。你可以安全地删除它。
缓存的函数现在可以包含 Streamlit 命令,并且会重放它们。
如果你想在缓存的函数中使用小部件,请设置
experimental_allow_widgets=True。示例请参见输入小部件。
-
如果在迁移过程中有任何问题或疑问,请在论坛上联系我们,我们将很乐意为你提供帮助。
🎈
为应用添加状态管理
https://docs.streamlit.io/develop/concepts/architecture/session-state
什么是状态?
我们将浏览器标签页中对Streamlit应用的访问定义为会话 。
每当一个浏览器标签页连接到Streamlit服务器时,就会创建一个新会话。
每次与应用交互时,Streamlit都会从头到尾重新运行你的脚本。
每次重新运行都在一个全新的环境中进行:不同运行之间不共享任何变量。
会话状态(Session State)是一种在重新运行之间共享变量的方法,针对每个用户会话。
除了存储和保持状态的能力外,Streamlit还提供了使用回调函数(Callbacks)操作状态的能力。
会话状态在多页面应用的不同页面间也能保持。
本指南将通过构建一个有状态的计数器应用,展示会话状态 和回调函数的使用方法。
有关会话状态和回调函数API的详细信息,请参阅我们的会话状态API参考指南。
此外,可以通过Streamlit开发者倡导者Marisa Smith博士的会话状态基础教程视频入门:
构建计数器
我们将脚本命名为 counter.py。
它会初始化一个 count 变量,并包含一个按钮用于增加 count 变量中存储的值:
python
import streamlit as st
st.title('Counter Example')
count = 0
increment = st.button('Increment')
if increment:
count += 1
st.write('Count = ', count)无论我们点击多少次上面应用中的 Increment 按钮,count 的值始终保持在 1。
让我们理解其中的原因:
-
每次点击 Increment 按钮时,Streamlit 都会从头到尾重新运行
counter.py,而每次运行时count都会被初始化为0。 -
随后点击 Increment 会将 0 加 1,因此无论点击多少次 Increment ,
count始终等于 1。
正如我们稍后将看到的,可以通过将 count 存储为 Session State 变量来避免这个问题。
这样做相当于告诉 Streamlit:在应用重新运行时,应该保留 Session State 变量中存储的值。
接下来让我们学习如何使用 Session State 的 API。
初始化
Session State API 采用基于字段的 API 设计,其使用方式与 Python 字典非常相似:
python
import streamlit as st
# Check if 'key' already exists in session_state
# If not, then initialize it
if 'key' not in st.session_state:
st.session_state['key'] = 'value'
# Session State also supports the attribute based syntax
if 'key' not in st.session_state:
st.session_state.key = 'value'读取与更新
通过将项目传递给 st.write 来读取 Session State 中某个项目的值:
python
import streamlit as st
if 'key' not in st.session_state:
st.session_state['key'] = 'value'
# Reads
st.write(st.session_state.key)
# Outputs: value通过为会话状态中的项目赋值来更新它:
python
import streamlit as st
if 'key' not in st.session_state:
st.session_state['key'] = 'value'
# Updates
st.session_state.key = 'value2' # Attribute API
st.session_state['key'] = 'value2' # Dictionary like API如果访问未初始化的变量,Streamlit 会抛出异常:
python
import streamlit as st
st.write(st.session_state['value'])
# Throws an exception!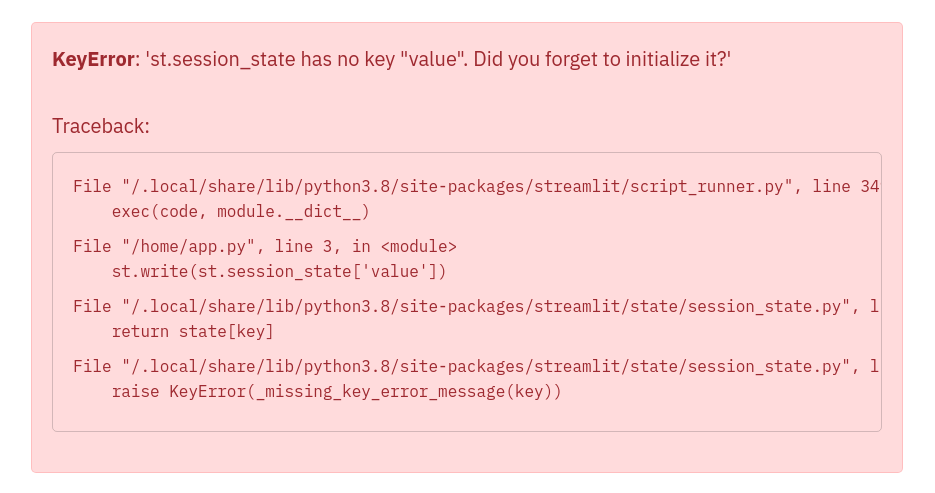
现在让我们通过几个示例,了解如何为计数器应用添加会话状态(Session State)。
示例1:添加会话状态
现在我们已经熟悉了 Session State API,接下来让我们更新计数器应用来使用会话状态:
python
import streamlit as st
st.title('Counter Example')
if 'count' not in st.session_state:
st.session_state.count = 0
increment = st.button('Increment')
if increment:
st.session_state.count += 1
st.write('Count = ', st.session_state.count)如上述示例所示,每次按下 Increment 按钮都会更新 count 值。
示例2:会话状态与回调函数
在通过会话状态构建了一个基础计数器应用后,我们接下来尝试更复杂的内容。
以下示例将结合回调函数与会话状态进行演示。
回调函数 :回调函数是一个Python函数,当输入组件发生变化时会被触发调用。
通过on_change(或on_click)、args和kwargs等参数,回调函数可与组件配合使用。
完整的回调函数API请参阅会话状态API参考指南。
python
import streamlit as st
st.title('Counter Example using Callbacks')
if 'count' not in st.session_state:
st.session_state.count = 0
def increment_counter():
st.session_state.count += 1
st.button('Increment', on_click=increment_counter)
st.write('Count = ', st.session_state.count)现在,每次点击 Increment 按钮时,都会通过调用 increment_counter() 函数来更新计数。
示例3:在回调中使用args和kwargs
回调也支持通过小部件的args参数传递参数:
python
import streamlit as st
st.title('Counter Example using Callbacks with args')
if 'count' not in st.session_state:
st.session_state.count = 0
increment_value = st.number_input('Enter a value', value=0, step=1)
def increment_counter(increment_value):
st.session_state.count += increment_value
increment = st.button('Increment', on_click=increment_counter,
args=(increment_value, ))
st.write('Count = ', st.session_state.count)此外,我们还可以在 widget 中使用 kwargs 参数向回调函数传递命名参数,如下所示:
python
import streamlit as st
st.title('Counter Example using Callbacks with kwargs')
if 'count' not in st.session_state:
st.session_state.count = 0
def increment_counter(increment_value=0):
st.session_state.count += increment_value
def decrement_counter(decrement_value=0):
st.session_state.count -= decrement_value
st.button('Increment', on_click=increment_counter,
kwargs=dict(increment_value=5))
st.button('Decrement', on_click=decrement_counter,
kwargs=dict(decrement_value=1))
st.write('Count = ', st.session_state.count)示例4:表单与回调函数
假设我们现在不仅需要递增 count,还想记录最后一次更新的时间。
我们将通过回调函数和 st.form 来实现这一功能。
python
import streamlit as st
import datetime
st.title('Counter Example')
if 'count' not in st.session_state:
st.session_state.count = 0
st.session_state.last_updated = datetime.time(0,0)
def update_counter():
st.session_state.count += st.session_state.increment_value
st.session_state.last_updated = st.session_state.update_time
with st.form(key='my_form'):
st.time_input(label='Enter the time', value=datetime.datetime.now().time(), key='update_time')
st.number_input('Enter a value', value=0, step=1, key='increment_value')
submit = st.form_submit_button(label='Update', on_click=update_counter)
st.write('Current Count = ', st.session_state.count)
st.write('Last Updated = ', st.session_state.last_updated)高级概念
会话状态与组件状态的关联
会话状态提供了在多次重新运行间存储变量的功能。
组件状态(即组件的值)同样会被存储在会话中。
为简化操作,我们已将这些信息统一 存放在一个位置------会话状态中。
这一便捷特性使得在应用代码的任何位置读写组件状态变得极其简单。
会话状态变量通过 key 参数来映射组件的值。
我们通过以下示例来说明这一点。
假设应用中有一个滑块用于表示摄氏温度。
可以通过会话状态 API 来设置 和获取温度组件的值,具体如下:
python
import streamlit as st
if "celsius" not in st.session_state:
# set the initial default value of the slider widget
st.session_state.celsius = 50.0
st.slider(
"Temperature in Celsius",
min_value=-100.0,
max_value=100.0,
key="celsius"
)
# This will get the value of the slider widget
st.write(st.session_state.celsius)使用会话状态API设置小部件值存在一个限制。
重要提示
Streamlit 不允许 通过 Session State API 为 st.button 和 st.file_uploader 设置控件值。
以下示例在尝试通过 Session State API 设置 st.button 的状态时,会引发 StreamlitAPIException 异常:
python
import streamlit as st
if 'my_button' not in st.session_state:
st.session_state.my_button = True
# Streamlit will raise an Exception on trying to set the state of button
st.button('Submit', key='my_button')
可序列化的会话状态
序列化是指将对象或数据结构转换为可持久化和共享的格式,并允许恢复数据原始结构的过程。
Python 内置的 pickle 模块能将 Python 对象序列化为字节流(称为 "pickling"),并将该流反序列化为对象(称为 "unpickling")。
默认情况下,Streamlit 的 会话状态 允许在会话期间持久化任何 Python 对象,无论该对象是否可被 pickle 序列化。
这一特性支持存储 Python 基础类型(如整数、浮点数、复数、布尔值)、数据框,甚至函数返回的 lambda 表达式。
但某些执行环境可能要求序列化会话状态中的所有数据,因此在开发阶段检测不兼容性,或预判执行环境未来可能停止支持的情况会很有帮助。
为此,Streamlit 提供了 runner.enforceSerializableSessionState 配置选项。
当设为 true 时,该选项仅允许会话状态中包含可被 pickle 序列化的对象。
启用方式包括:创建包含以下配置的全局或项目配置文件,或直接将其作为命令行标志使用:
# .streamlit/config.toml
[runner]
enforceSerializableSessionState = true所谓"可 pickle 序列化 ",是指调用 pickle.dumps(obj) 时不应引发 PicklingError 异常。
当启用该配置选项时,向会话状态添加不可序列化的数据应触发异常。
例如,
python
import streamlit as st
def unserializable_data():
return lambda x: x
#👇 results in an exception when enforceSerializableSessionState is on
st.session_state.unserializable = unserializable_data()
警告
当 runner.enforceSerializableSessionState 设置为 true 时,会话状态会隐式使用 pickle 模块,而该模块已知存在安全隐患。
请确保从会话状态保存和检索的所有数据都是可信的,因为在反序列化过程中可能构造恶意 pickle 数据来执行任意代码。
切勿以不安全模式加载可能来自不可信源的数据,或可能被篡改过的数据。
仅加载你信任的数据。
注意事项与限制
使用会话状态(Session State)时需注意以下限制:
- 会话状态仅在标签页保持打开且连接到Streamlit服务器期间存在。
一旦关闭标签页,存储在会话状态中的所有数据都将丢失。 - 会话状态不具备持久性。
如果Streamlit服务器崩溃,会话状态中存储的所有内容都会被清除 - 关于会话状态API的具体限制,请参阅API限制说明。
使用表单
https://docs.streamlit.io/develop/concepts/architecture/forms
当您不希望每次用户输入都重新运行脚本时,st.form 可以帮您解决这个问题!表单能够轻松地将用户输入批量处理为单次重新运行。
本使用指南提供了示例,并解释了用户如何与表单交互。
示例
在以下示例中,用户可以设置多个参数来更新地图。
当用户更改参数时,脚本不会重新运行,地图也不会更新。
只有当用户点击标有"更新地图"的按钮提交表单时,脚本才会重新运行并更新地图。
如果用户在任何时候点击表单外的"生成新点 "按钮,脚本将重新运行。
如果用户在表单内有任何未提交的更改,这些更改不会 随重新运行一起发送。
对表单所做的所有更改,只有在提交表单本身时才会发送到Python后端。
查看源代码
python
import streamlit as st
import pandas as pd
import numpy as np
def get_data():
df = pd.DataFrame({
"lat": np.random.randn(200) / 50 + 37.76,
"lon": np.random.randn(200) / 50 + -122.4,
"team": ['A','B']*100
})
return df
if st.button('Generate new points'):
st.session_state.df = get_data()
if 'df' not in st.session_state:
st.session_state.df = get_data()
df = st.session_state.df
with st.form("my_form"):
header = st.columns([1,2,2])
header[0].subheader('Color')
header[1].subheader('Opacity')
header[2].subheader('Size')
row1 = st.columns([1,2,2])
colorA = row1[0].color_picker('Team A', '#0000FF')
opacityA = row1[1].slider('A opacity', 20, 100, 50, label_visibility='hidden')
sizeA = row1[2].slider('A size', 50, 200, 100, step=10, label_visibility='hidden')
row2 = st.columns([1,2,2])
colorB = row2[0].color_picker('Team B', '#FF0000')
opacityB = row2[1].slider('B opacity', 20, 100, 50, label_visibility='hidden')
sizeB = row2[2].slider('B size', 50, 200, 100, step=10, label_visibility='hidden')
st.form_submit_button('Update map')
alphaA = int(opacityA*255/100)
alphaB = int(opacityB*255/100)
df['color'] = np.where(df.team=='A',colorA+f'{alphaA:02x}',colorB+f'{alphaB:02x}')
df['size'] = np.where(df.team=='A',sizeA, sizeB)
st.map(df, size='size', color='color')基于Streamlit构建 🎈全屏显示 open_in_new
用户交互
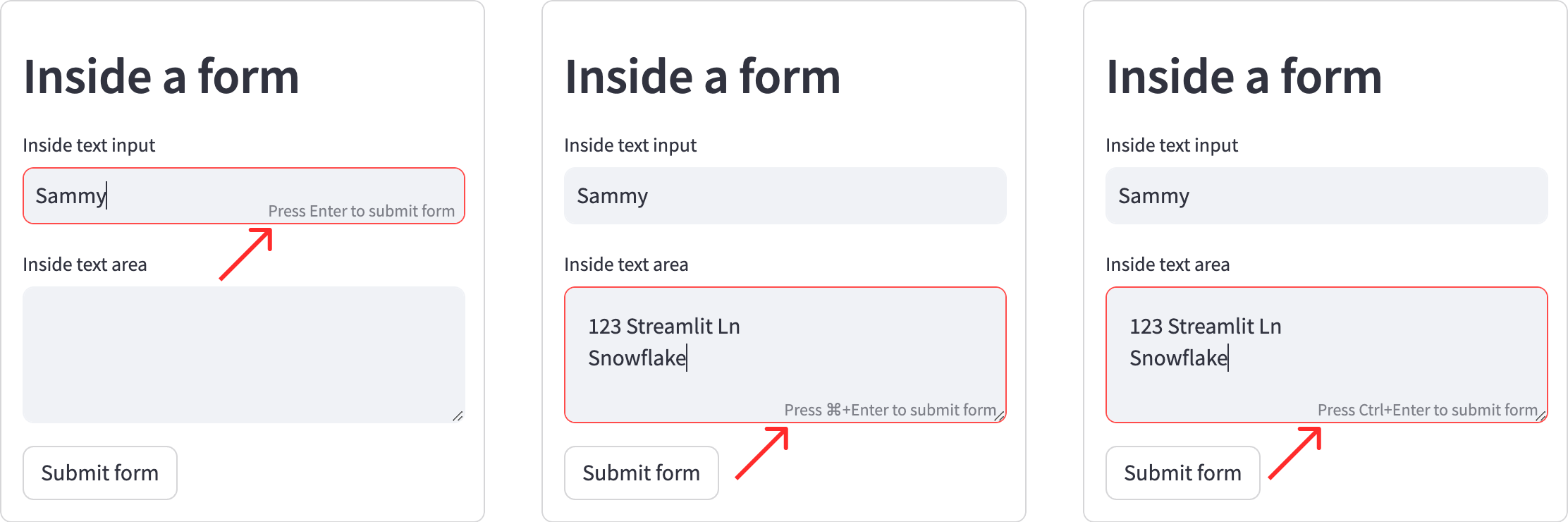
如果某个小部件不在表单内,当用户更改其值时,该小部件会触发脚本重新运行。
对于带键控输入的小部件(st.number_input、st.text_input、st.text_area),当用户点击或移出该小部件时,新值会触发重新运行。
用户还可以在光标位于小部件内时按Enter键提交更改。
另一方面,如果小部件位于表单内,当用户点击或移出该小部件时,脚本不会重新运行。
对于表单内的小部件,只有在表单提交时脚本才会重新运行,此时表单内所有小部件会将其更新后的值发送至Python后端。
用户可以通过键盘Enter 键提交表单,前提是光标位于接受键控输入的小部件中。
在st.number_input和st.text_input中,用户按Enter 提交表单;在st.text_area中,用户需按Ctrl+Enter /⌘+Enter提交表单。
控件默认值
在表单提交之前,表单内的所有控件都会拥有默认值,这与表单外的控件具有默认值的机制相同。
python
import streamlit as st
with st.form("my_form"):
st.write("Inside the form")
my_number = st.slider('Pick a number', 1, 10)
my_color = st.selectbox('Pick a color', ['red','orange','green','blue','violet'])
st.form_submit_button('Submit my picks')
# This is outside the form
st.write(my_number)
st.write(my_color)使用 Streamlit 构建 🎈全屏 open_in_new
表单是容器
当调用 st.form 时,前端会创建一个容器。
你可以像操作其他容器元素一样向该容器写入内容。
也就是说,你可以像上面示例中那样使用 Python 的 with 语句,也可以将表单容器赋值给变量并直接调用其方法。
此外,你可以在表单容器的任意位置放置 st.form_submit_button。
python
import streamlit as st
animal = st.form('my_animal')
# This is writing directly to the main body. Since the form container is
# defined above, this will appear below everything written in the form.
sound = st.selectbox('Sounds like', ['meow','woof','squeak','tweet'])
# These methods called on the form container, so they appear inside the form.
submit = animal.form_submit_button(f'Say it with {sound}!')
sentence = animal.text_input('Your sentence:', 'Where\'s the tuna?')
say_it = sentence.rstrip('.,!?') + f', {sound}!'
if submit:
animal.subheader(say_it)
else:
animal.subheader(' ')表单提交处理
表单的作用是覆盖 Streamlit 的默认行为(即用户一旦做出更改就重新运行脚本)。
对于表单外的控件,其逻辑流程如下:
-
用户在前端修改控件的值。
-
控件在
st.session_state和 Python 后端(服务器)中的值被更新。 -
脚本开始重新运行。
-
如果控件有回调函数,该函数会作为页面重新运行的前缀执行。
-
在重新运行期间执行更新后的控件函数时,会输出新值。
对于表单内的控件,用户所做的任何更改(步骤1)在表单提交前都不会传递到 Python 后端(步骤2)。
此外,表单内唯一可以拥有回调函数的控件是 st.form_submit_button。
如果需要使用新提交的值执行流程,主要有以下三种模式可供选择。
表单提交后执行流程
若需在表单提交时执行一次性流程,可将该流程与st.form_submit_button进行条件绑定,在表单提交后触发执行。
如需将流程结果显示在表单上方,可通过容器组件控制表单与输出内容的相对位置。
python
import streamlit as st
col1,col2 = st.columns([1,2])
col1.title('Sum:')
with st.form('addition'):
a = st.number_input('a')
b = st.number_input('b')
submit = st.form_submit_button('add')
if submit:
col2.title(f'{a+b:.2f}')使用 Streamlit 构建 🎈全屏 open_in_new
使用带会话状态的回调
你可以通过回调函数在脚本重新运行前执行预处理操作。
重要提示
在回调函数中处理新更新的值时,不要直接通过args或kwargs参数将这些值传递给回调。
您需要为回调中使用的任何小部件分配一个键。
如果在回调函数体内从st.session_state查找该小部件的值,您将能够访问新提交的值。
请参考以下示例。
python
import streamlit as st
if 'sum' not in st.session_state:
st.session_state.sum = ''
def sum():
result = st.session_state.a + st.session_state.b
st.session_state.sum = result
col1,col2 = st.columns(2)
col1.title('Sum:')
if isinstance(st.session_state.sum, float):
col2.title(f'{st.session_state.sum:.2f}')
with st.form('addition'):
st.number_input('a', key = 'a')
st.number_input('b', key = 'b')
st.form_submit_button('add', on_click=sum)使用 Streamlit 构建 🎈全屏显示 open_in_new
使用 st.rerun
如果您的流程会影响表单上方的内容,另一种选择是额外使用重新运行功能。
不过这种方式可能资源效率较低,相比上述选项可能不太理想。
python
import streamlit as st
if 'sum' not in st.session_state:
st.session_state.sum = ''
col1,col2 = st.columns(2)
col1.title('Sum:')
if isinstance(st.session_state.sum, float):
col2.title(f'{st.session_state.sum:.2f}')
with st.form('addition'):
a = st.number_input('a')
b = st.number_input('b')
submit = st.form_submit_button('add')
# The value of st.session_state.sum is updated at the end of the script rerun,
# so the displayed value at the top in col2 does not show the new sum. Trigger
# a second rerun when the form is submitted to update the value above.
st.session_state.sum = a + b
if submit:
st.rerun()使用 Streamlit 构建 🎈全屏 open_in_new
限制条件
- 每个表单必须包含一个
st.form_submit_button。 - 表单内不能添加
st.button和st.download_button。 st.form不能嵌套在另一个st.form内部。- 回调函数只能分配给表单内的
st.form_submit_button;表单中的其他组件不能设置回调。 - 表单内相互依赖的组件可能不太实用。
如果在表单内将widget1的值传递给widget2,那么widget2只会在表单提交时更新。
使用片段
https://docs.streamlit.io/develop/concepts/architecture/fragments
重运行是每个Streamlit应用的核心机制。
当用户与组件交互时,你的脚本会从头到尾重新执行,应用前端随之更新。
Streamlit提供了多种特性来帮助开发者适应这种执行模式。
Streamlit 1.37.0版本引入了片段功能,允许仅重新运行部分代码而非整个脚本。
随着应用规模扩大和复杂度增加,片段重运行能有效提升应用性能和效率。
片段机制为你提供了更精细、更易理解的执行流程控制。
在阅读片段功能前,建议先掌握缓存、会话状态和表单的基础知识。
片段的使用场景
片段功能灵活多样,适用于多种情况。
以下是几个常见的使用场景:
- 当应用包含多个可视化组件,每个组件加载耗时较长,但只需通过筛选输入更新其中一个时
- 当存在动态表单且无需立即更新应用其他部分(直到表单完成提交时)
- 当需要自动更新单个组件或组件组以实现数据流传输时
定义和调用片段函数
Streamlit 提供了一个装饰器 st.fragment,可以将任意函数转换为片段函数。
当你调用包含控件函数的片段函数时,用户与该片段控件交互会触发片段重运行 而非完整重运行。
在片段重运行期间,仅该片段函数会被重新执行。
片段主体内的任何内容都会在前端更新,而应用的其他部分保持不变。
我们稍后会介绍跨多个容器编写的片段。
以下是定义和调用片段函数的基础示例。
与缓存机制类似,请记得在定义后调用你的函数。
python
import streamlit as st
@st.fragment
def fragment_function():
if st.button("Hi!"):
st.write("Hi back!")
fragment_function()如果您希望片段的主体内容显示在侧边栏或其他容器中,请在上下文管理器内调用片段函数。
python
with st.sidebar:
fragment_function()片段执行流程
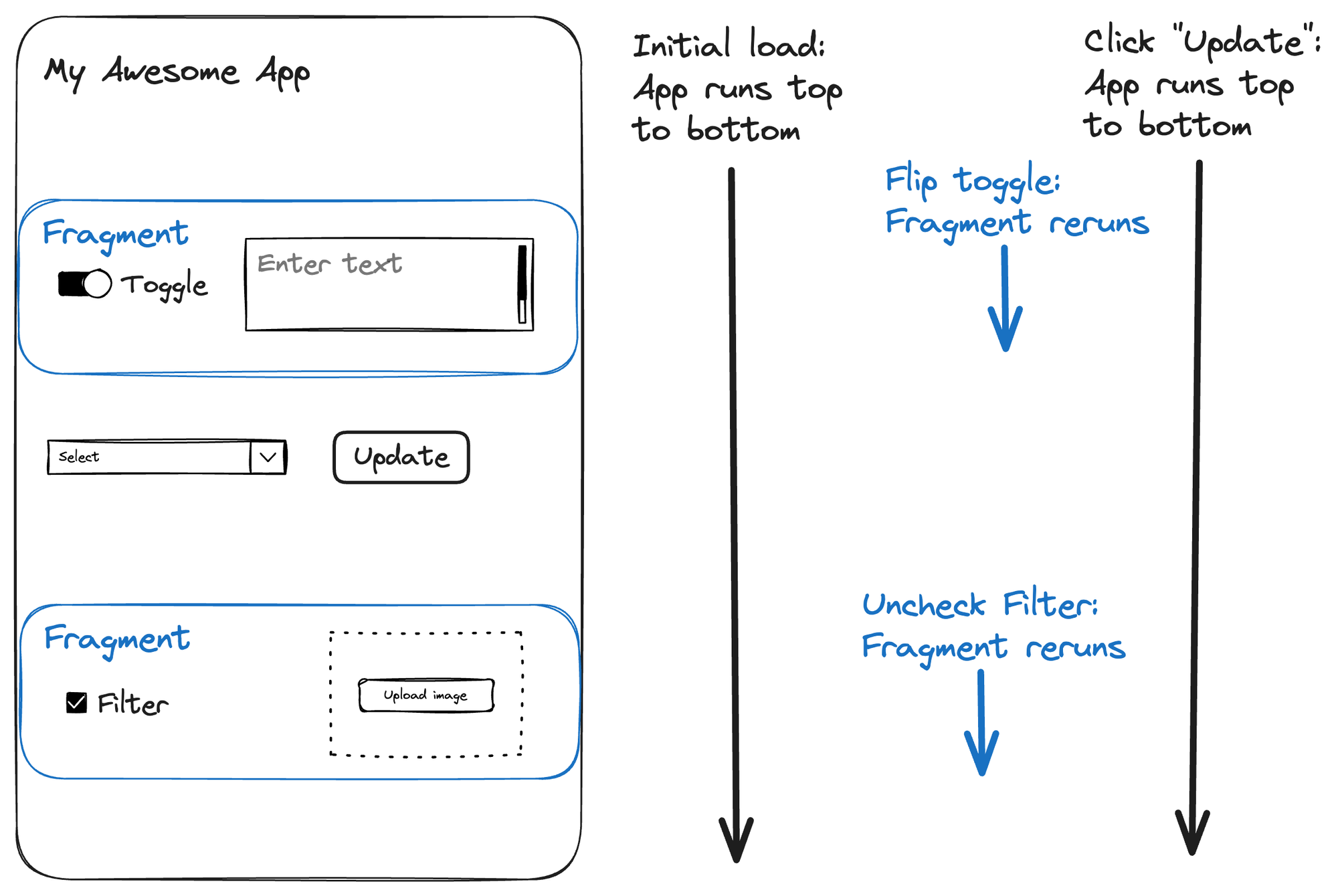
请参考以下代码及随附的解释和示意图。
python
import streamlit as st
st.title("My Awesome App")
@st.fragment()
def toggle_and_text():
cols = st.columns(2)
cols[0].toggle("Toggle")
cols[1].text_area("Enter text")
@st.fragment()
def filter_and_file():
cols = st.columns(2)
cols[0].checkbox("Filter")
cols[1].file_uploader("Upload image")
toggle_and_text()
cols = st.columns(2)
cols[0].selectbox("Select", [1,2,3], None)
cols[1].button("Update")
filter_and_file()当用户与片段内的输入组件交互时,仅该片段会重新执行,而非整个脚本。
而当用户与片段外的输入组件交互时,整个脚本会如常重新运行。
运行上述代码时,应用初始加载会从上至下完整执行整个脚本。
如果在运行应用中切换开关按钮,第一个片段(toggle_and_text())将重新执行,重绘开关和文本框区域,同时保持其他所有内容不变。
若点击复选框,第二个片段(filter_and_file())会重新执行,从而重绘复选框和文件上传器,其余部分保持不变。
最后,点击更新按钮时,整个脚本将重新执行,Streamlit会重绘所有内容。
片段返回值与应用程序其他部分的交互
在片段重新运行时,Streamlit 会忽略片段的返回值,因此不建议为片段函数定义返回值。
相反,如果片段需要与应用程序的其他部分共享数据,请使用会话状态(Session State)。
片段只是脚本中的函数,因此它们可以访问会话状态、导入的模块以及其他 Streamlit 元素(如容器)。
如果片段向自身外部创建的容器写入内容,请注意以下行为差异:
- 片段主体中绘制的元素会在片段重新运行时被清除并原地重绘。
重复的片段重新运行不会导致额外的元素出现。 - 绘制到片段主体外部容器中的元素不会在每次片段重新运行时被清除。
相反,Streamlit 会以叠加方式绘制这些元素,这些元素会累积,直到下一次完整脚本重新运行。 - 片段不能在主体外部的容器中绘制控件(widgets)。
控件只能放置在片段的主体中。
为了防止元素在外部容器中累积,可以使用 st.empty 容器。
相关教程请参阅跨多个容器创建片段。
如果需要从片段内部触发完整脚本的重新运行,可以调用 st.rerun。
相关教程请参阅从片段内部触发完整脚本重新运行。
自动化片段重运行
st.fragment 提供了一个便捷的 run_every 参数,可以让片段按指定的时间间隔自动重新运行。
这些自动重运行会叠加在用户触发的任何重运行(片段或完整脚本)之上。
即使用户没有与应用交互,自动片段重运行仍会持续执行。
这是展示实时数据流或后台任务状态的绝佳方式,能够高效更新渲染数据------且仅更新渲染数据。
python
@st.fragment(run_every="10s")
def auto_function():
# This will update every 10 seconds!
df = get_latest_updates()
st.line_chart(df)
auto_function()相关教程请参阅启动和停止流式片段。
片段与其他Streamlit功能的对比
片段与表单对比
以下是片段(Fragments)和表单(Forms)的对比:
- 表单 允许用户与组件交互而无需重新运行整个应用。
在表单提交之前,Streamlit不会将表单内的用户操作发送到应用的Python后端。
表单内的组件无法实时动态更新其他组件(无论是否在表单内)。 - 片段 独立于其他代码运行。
当用户与片段内的组件交互时,其操作会立即被应用的Python后端处理,并重新运行片段代码。
片段内的组件可以实时动态更新同一片段内的其他组件。
表单会批量收集用户输入,但组件之间没有交互;片段会立即处理用户输入,但限制了重新运行的范围。
片段与回调对比
以下是片段(Fragments)和回调(Callbacks)的对比:
- 回调 允许你在脚本重新运行时开头执行一个函数。
回调是脚本重新运行的单一前缀。 - 片段 允许你重新运行脚本的一部分。
片段是脚本的可重复后缀 ,每次用户与片段控件交互时都会运行,或者当设置了run_every时自动按顺序运行。
当回调向页面渲染元素时,这些元素会在页面其他元素之前渲染。
而当片段向页面渲染元素时,它们会随着每次片段重新运行而更新(除非这些元素被写入片段之外的容器中,这种情况下它们会在容器中累积)。
片段与自定义组件的对比
以下是片段和自定义组件之间的比较:
- 组件 是自定义的前端代码,可以与 Streamlit 应用中的 Python 代码、原生元素和小部件交互。
自定义组件扩展了 Streamlit 的功能范围,它们遵循 Streamlit 的正常执行流程。 - 片段 是应用中可以独立于整个应用重新运行的部分。
片段可以由多个 Streamlit 元素、小部件或任何 Python 代码组成。
一个片段可以包含一个或多个自定义组件,但自定义组件很难直接包含片段!
片段与缓存的对比
以下是片段和缓存之间的比较:
- 缓存: 允许跳过函数并返回之前计算的值。
使用缓存时,除了已缓存的函数(如果之前运行过)外,其他所有内容都会执行。 - 片段: 允许冻结应用的大部分内容,仅执行片段部分。
使用片段时,只会执行片段本身(当触发片段重新运行时)。
缓存可以避免在运行其他部分时重复执行应用中不必要的部分。
而片段则可以在只需运行某一部分时,避免运行整个应用。
限制与不支持的行为
- 片段无法检测输入值的变化。
对于片段函数的动态输入和输出,建议使用会话状态(Session State)。 - 同一函数上同时使用缓存和片段功能是不支持的。
- 片段无法在外部创建的容器中渲染组件;组件只能位于片段的主体部分内。
理解小部件行为
https://docs.streamlit.io/develop/concepts/architecture/widget-behavior
小部件(如 st.button、st.selectbox 和 st.text_input)是 Streamlit 应用的核心。
它们是 Streamlit 的交互元素,将用户的信息传递到 Python 代码中。
小部件非常神奇,通常能按预期工作,但在某些情况下可能会表现出意外的行为。
理解小部件的不同部分以及事件发生的精确顺序,有助于实现预期的效果。
本指南涵盖了关于小部件的高级概念。
通常,它会从简单的概念开始,逐步增加复杂性。
对于大多数初学者来说,这些细节可能不需要立即了解。
但当你想动态更改小部件或在页面之间保留小部件信息时,这些概念就非常重要了。
建议在阅读本指南之前,先对 Session State 有基本的了解。
🎈 快速总结 展开更多
1、一个用户的操作不会影响其他用户的小部件。
2、小部件函数调用返回小部件的当前值,这是一个简单的 Python 类型(例如 st.button 返回布尔值)。
3、在用户首次与小部件交互之前,小部件会返回其默认值。
4、小部件的身份取决于传递给小部件函数的参数。
更改小部件的标签、最小值或最大值、默认值、占位文本、帮助文本或键会导致其重置。
5、如果在脚本运行期间未调用小部件函数,Streamlit 将删除该小部件的信息------包括其在 Session State 中的键值对 。
如果稍后调用相同的小部件函数,Streamlit 会将其视为一个新小部件。
最后两点(小部件身份和小部件删除)在动态更改小部件或处理多页应用时最为相关。
本指南后续会详细讨论:小部件的状态性 和 小部件的生命周期。
小部件的组成结构
使用小部件时需要牢记四个部分:
1、用户看到的前端组件。
2、通过st.session_state访问的后端值或实际值。
3、用于通过st.session_state获取其值的小部件键名。
4、小部件函数返回的值。
小部件具有会话依赖性
小部件的状态依赖于特定会话(浏览器连接)。
一个用户的操作不会影响其他用户的任何小部件。
此外,如果用户打开多个标签页访问同一个应用,每个标签页都将被视为独立的会话。
在一个标签页中修改小部件不会影响另一个标签页中的相同小部件。
小部件返回简单的Python数据类型
通过st.session_state查看或由小部件函数返回的值都是简单的Python类型。
例如,st.button返回一个布尔值,如果使用了key参数,该布尔值也会保存在st.session_state中。
首次调用小部件函数时(在用户与之交互前),它将返回默认值(例如st.selectbox默认返回第一个选项)。
除st.button和st.file_uploader等少数特殊例外,所有小部件的默认值均可配置。
键(Key)帮助区分组件并访问其值
组件键(Key)主要有两个作用:
- 区分两个原本完全相同的组件
- 通过
st.session_state创建访问和操作组件值的途径
Streamlit会尽可能在前端增量更新组件,而不是在每次重新运行时重建它们。
这意味着Streamlit会根据传递给组件函数的参数为每个组件分配一个ID。
组件的ID基于以下参数:标签(label)、最小值或最大值(min/max)、默认值(default)、占位文本(placeholder)、帮助文本(help)以及键(key)。
组件所在页面也会影响其ID的生成。
如果在同一页面上存在两个类型相同且参数完全相同的组件,就会出现DuplicateWidgetID错误。
这种情况下,需要为这两个组件分配不同的键(key)来确保唯一性。
Streamlit 无法识别同一页面上的两个相同组件
# This will cause a DuplicateWidgetID error.
st.button("OK")
st.button("OK")使用键值区分其他方面相同的组件
python
st.button("OK", key="privacy")
st.button("OK", key="terms")操作执行顺序
当用户与组件交互时,逻辑执行顺序如下:
- 组件在
st.session_state中的值会被更新 - 执行回调函数(如果存在)
- 页面重新运行,此时组件函数将返回新值
如果回调函数向屏幕输出内容,这些内容会显示在页面其他部分的上方。
回调函数会作为脚本重新运行的前置操作执行。
因此,这意味着通过回调函数输出的任何内容都会在用户执行下一个操作时立即消失。
通常不应在回调函数内创建其他组件。
注意
如果回调函数接收了任何 args 或 kwargs 参数,这些参数将在组件渲染时确定。
特别需要注意的是,若要在组件自身的回调函数中使用该组件的新值,不能通过 args 参数将该值传递给回调函数;您必须为组件分配一个键(key),并在回调函数内部通过调用 st.session_state 来获取其新值。
在表单中使用回调函数
在表单中使用回调函数时,需要注意以下操作顺序。
python
import streamlit as st
if "attendance" not in st.session_state:
st.session_state.attendance = set()
def take_attendance():
if st.session_state.name in st.session_state.attendance:
st.info(f"{st.session_state.name} has already been counted.")
else:
st.session_state.attendance.add(st.session_state.name)
with st.form(key="my_form"):
st.text_input("Name", key="name")
st.form_submit_button("I'm here!", on_click=take_attendance)使用 Streamlit 构建 🎈全屏显示 open_in_new
小部件的状态保持特性
只要小部件的定义参数保持不变,并且该小部件在前端持续渲染,它就会保持状态并记住用户输入。
修改组件参数将导致其重置
如果组件的任何定义参数发生变化,Streamlit会将其视为新组件并重置它。
在这种情况下,手动分配键和默认值的使用尤为重要。
*请注意,回调函数、回调参数及关键字参数、标签可见性以及禁用组件不会影响组件的身份。
*
在这个示例中,我们有一个滑块,其最小值和最大值会被修改。
尝试与每个滑块交互以更改其值,然后调整最小或最大设置,观察会发生什么。
python
import streamlit as st
cols = st.columns([2, 1, 2])
minimum = cols[0].number_input("Minimum", 1, 5)
maximum = cols[2].number_input("Maximum", 6, 10, 10)
st.slider("No default, no key", minimum, maximum)
st.slider("No default, with key", minimum, maximum, key="a")
st.slider("With default, no key", minimum, maximum, value=5)
st.slider("With default, with key", minimum, maximum, value=5, key="b")基于 Streamlit 🎈 构建全屏显示 open_in_new
更新无默认值的滑块控件
对于前文提到的两个滑块控件,一旦最小值或最大值发生改变,滑块就会重置为最小值。
从Streamlit的角度来看,修改最小值或最大值会使它们成为"全新"的控件组件,因此当应用带着变更后的参数重新运行时,这些控件会从头开始重建。
由于没有定义默认值,每个控件都会重置为其最小值。
无论是否设置key属性都会出现这种情况,因为系统始终将其视为新控件。
关于已存在key与控件绑定的微妙机制,我们将在控件生命周期章节深入说明。
为滑块设置默认值更新
对于上述最后两个滑块,修改最小值或最大值会导致组件被视为"新"组件,从而像之前一样重新创建。
由于定义了默认值5,每当最小值或最大值改变时,每个组件都会重置为5。
无论是否使用key属性,这种现象都会发生。
关于在改变组件参数时保持状态的解决方案将在后续部分提供。
小部件在不持续渲染时不会持久化
如果在脚本运行期间未调用小部件的函数,那么它的所有部分都不会被保留,包括其在 st.session_state 中的值。
如果一个小部件有键(key),并且你导航离开了该小部件,其在 st.session_state 中的键和关联值将被删除。
即使是暂时隐藏小部件,当其重新出现时也会导致重置;Streamlit 会将其视为一个新部件。
你可以中断小部件清理流程(在本页末尾描述),或者将值保存到另一个键中。
在会话状态中保存小组件值以实现跨页面保留
若需在导航离开小组件后返回时仍保留其值,可在st.session_state中使用独立键来保存信息(与小组件解耦)。
本示例采用带下划线前缀的临时键:使用"_my_key"作为小组件键,同时将数据复制到"my_key"以实现跨页面持久化。
python
import streamlit as st
def store_value():
# Copy the value to the permanent key
st.session_state["my_key"] = st.session_state["_my_key"]
# Copy the saved value to the temporary key
st.session_state["_my_key"] = st.session_state["my_key"]
st.number_input("Number of filters", key="_my_key", on_change=store_value)如果将其功能化以支持多个小部件,可能会是这样的:
python
import streamlit as st
def store_value(key):
st.session_state[key] = st.session_state["_"+key]
def load_value(key):
st.session_state["_"+key] = st.session_state[key]
load_value("my_key")
st.number_input("Number of filters", key="_my_key", on_change=store_value, args=["my_key"])小部件生命周期
当调用小部件函数时,Streamlit会检查是否已存在具有相同参数的小部件。
如果Streamlit认为该小部件已存在,则会重新连接。
否则,将创建一个新的小部件。
如前所述,Streamlit根据标签、最小值或最大值、默认值、占位文本、帮助文本和key等参数确定小部件的ID。
页面名称也会影响小部件的ID。
另一方面,回调函数、回调参数及关键字参数、标签可见性以及禁用小部件不会影响小部件的身份。
当小部件不存在时调用其函数
如果你的脚本重新运行时调用了参数已更改的小部件函数,或调用了上次脚本运行中未使用的小部件函数:
-
Streamlit 将使用默认值构建该小部件的前端和后端部分。
-
如果该小部件已分配了键(key),Streamlit 会检查该键是否已存在于会话状态(Session State)中:
a. 若存在且当前未关联到其他小部件,Streamlit 会将该键的值赋给此小部件。
b. 否则,会将默认值赋给
st.session_state中的键(创建新键值对或覆盖现有键值)。 -
若存在回调函数的 args 或 kwargs,它们会在此阶段被计算并保存。
-
最后,函数返回该小部件的值。
步骤 2 可能较为复杂。
例如,如果你有一个小部件:
python
st.number_input("Alpha",key="A")并且在页面重新运行时将其更改为:
python
st.number_input("Beta",key="A")由于标签变更,Streamlit 会将其视为一个新组件。
键 "A" 会被视为属于标签为 "Alpha" 的组件,而不会原样附加到新标签为 "Beta" 的组件上。
Streamlit 会销毁 st.session_state.A 并用默认值重新创建它。
如果组件在创建时附加到预先存在的键,并且还手动分配了默认值,当两者不一致时会出现警告。
若要通过 st.session_state 控制组件的值,应通过 st.session_state 初始化组件的值,并避免使用默认值参数以防止冲突。
当部件已存在时调用部件函数
当重新运行脚本而不更改部件参数时:
-
Streamlit 会连接到现有的前端和后端部分。
-
如果部件的键已从
st.session_state中删除,Streamlit 将使用当前前端值重新创建该键。(例如,删除键不会将部件恢复为默认值。
)
-
它将返回部件的当前值。
组件清理流程
当 Streamlit 执行到脚本运行结束时,它会清除内存中所有未在屏幕上渲染的组件数据。
最关键的是,这意味着 Streamlit 将删除 st.session_state 中与当前不在屏幕上的组件相关联的所有键值对。
补充示例
如之前所述,我们将介绍如何在切换页面或修改参数时保持小部件的状态。
有两种方法可以实现:
-
使用虚拟键在
st.session_state中复制小部件值,防止数据随小部件一起被删除。 -
中断小部件的清理过程。
第一种方法已在将小部件值保存在会话状态中以在页面间保留中展示。
中断小部件清理流程
要为 key="my_key" 的小部件保留信息,只需在每个页面顶部添加以下内容:
python
st.session_state.my_key = st.session_state.my_key当你手动将数据保存到 st.session_state 的某个键时,在清理过程中该键将与所有小部件解除关联。
如果你离开某个使用 "my_key" 的小部件,并在新页面中向 st.session_state.my_key 保存数据,就会中断小部件的清理流程------当存在另一个使用相同键的小部件时,该键值对将不会被删除或覆盖。
在更改部件参数时保持状态
这是我们之前关于更改滑块最小值和最大值示例的解决方案。
该方案会中断上述描述的清理过程。
python
import streamlit as st
# Set default value
if "a" not in st.session_state:
st.session_state.a = 5
cols = st.columns(2)
minimum = cols[0].number_input("Min", 1, 5, key="min")
maximum = cols[1].number_input("Max", 6, 10, 10, key="max")
def update_value():
# Helper function to ensure consistency between widget parameters and value
st.session_state.a = min(st.session_state.a, maximum)
st.session_state.a = max(st.session_state.a, minimum)
# Validate the slider value before rendering
update_value()
st.slider("A", minimum, maximum, key="a")使用 Streamlit 构建 🎈全屏 open_in_new
update_value() 这个辅助函数实际上承担着双重职责。
表面上看,它确保参数值不会出现描述中的不一致变更。
更重要的是,它还中断了小组件的清理流程。
当小组件的最小值或最大值发生变化时,Streamlit 会将其视为重新运行时的新组件。
如果不将值保存到 st.session_state.a,该值就会被丢弃并被"新"组件的默认值取代。
多页面应用
https://docs.streamlit.io/develop/concepts/multipage-apps
多页面应用概述
Streamlit 提供了多种定义多页面应用的方式。
了解相关术语及各方法之间的基本对比。
https://docs.streamlit.io/develop/concepts/multipage-apps/overview
使用 st.Page 和 st.navigation 定义多页面应用
了解定义多页面应用的首选方法。
st.Page 和 st.navigation 让你可以灵活地组织项目目录,并自由地为页面命名。
使用 pages/ 目录创建多页面应用
通过目录结构定义多页面应用。
将额外的 Python 文件放在入口文件旁的 pages/ 目录中,页面会自动显示在应用侧边栏的导航组件中。
https://docs.streamlit.io/develop/concepts/multipage-apps/pages-directory
多页面应用中的部件使用
了解部件标识如何与页面绑定。
学习如何通过策略实现所需的部件行为。
https://docs.streamlit.io/develop/concepts/multipage-apps/widgets
多页面应用概述
Streamlit 提供了两种内置机制来创建多页面应用。
最简单的方法是使用 pages/ 目录。
不过,更推荐且可定制性更强的方法是使用 st.navigation。
st.Page 与 st.navigation
若想获得定义多页面应用的最大灵活性,我们推荐使用 st.Page 和 st.navigation。
通过 st.Page,你可以将任何 Python 文件或 Callable 声明为应用中的页面。
此外,你可以在入口文件(即传递给 streamlit run 的文件)中为所有页面定义公共元素。
采用这些方法后,入口文件就如同一个被所有页面共享的画框。
必须在入口文件中包含 st.navigation 来配置应用的导航菜单。
这也是入口文件充当页面间路由器的关键方式。
pages/ 目录
如果你需要一个快速简单的解决方案,只需在入口文件旁边放置一个 pages/ 目录。
对于 pages/ 目录中的每个 Python 文件,Streamlit 都会为你的应用创建一个附加页面。
Streamlit 会根据文件名自动确定页面标签和 URL,并在应用侧边栏顶部生成导航菜单。
your_working_directory/
├── pages/
│ ├── a_page.py
│ └── another_page.py
└── your_homepage.pyStreamlit 根据文件名决定导航中的页面顺序。
您可以在文件名中使用数字前缀来调整页面顺序。
更多信息请参阅侧边栏中的页面排序方式。
若想通过此选项自定义导航菜单,您可以通过配置 (client.showSidebarNavigation = false) 禁用默认导航。
随后,您可以使用 st.page_link 手动构建自定义导航菜单。
通过 st.page_link,您可以更改导航菜单中的页面标签和图标,但无法修改页面的 URL。
页面术语
一个页面包含以下四个标识部分:
- 页面源码:这是包含页面源代码的 Python 文件或可调用函数。
- 页面标签 :这是页面在导航菜单中的显示标识。
参见 looks_one。 - 页面标题 :这是 HTML
<title>元素的内容,也是页面在浏览器标签页中的显示标识。
参见 looks_two。 - 页面 URL 路径名 :这是页面相对于应用根 URL 的相对路径。
参见 looks_3。
此外,一个页面还可以包含以下两个图标:
- 页面 favicon :这是显示在浏览器标签页中页面标题旁边的图标。
参见 looks_4。 - 页面图标 :这是显示在导航菜单中页面标签旁边的图标。
参见 looks_5。
通常情况下,页面图标和 favicon 是相同的,但也可以将它们设置为不同。
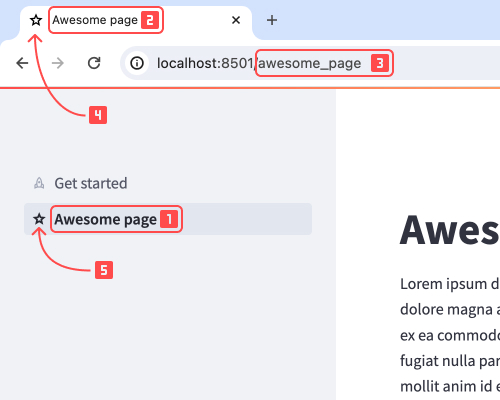 1. 页面标签, 2. 页面标题, 3. 页面 URL 路径名, 4. 页面 favicon, 5. 页面图标
1. 页面标签, 2. 页面标题, 3. 页面 URL 路径名, 4. 页面 favicon, 5. 页面图标
自动页面标签与URL生成
当使用st.Page而未声明页面标题或URL路径时,Streamlit会采用与pages/目录配合默认导航菜单时相同的自动命名机制,自动确定页面标签、标题和URL路径名。
本节将阐述这两种多页面应用实现方式所共享的命名规范。
文件名及可调用对象的组成部分
文件名由以下四个不同部分按顺序组成:
1、number:一个非负整数。
2、separator:任意下划线("_")、短横线("-")和空格(" ")的组合。
3、identifier:直到但不包括 ".py" 的所有内容。
4、".py"
对于可调用对象,函数名即为 identifier,包括任何前导或后置的下划线。
Streamlit 如何将文件名转换为标签和标题
在导航菜单中,Streamlit 会按照以下规则显示页面标签和标题:
-
如果页面有
identifier,Streamlit 会显示该identifier。页面
identifier中的下划线会被视为空格。因此,开头和结尾的下划线不会显示,连续的下划线会显示为单个空格。
-
如果页面没有
identifier但有number,Streamlit 会直接显示number(不做修改)。如果存在前导零,也会一并显示。
-
如果页面只有
separator,既没有number也没有identifier,Streamlit 不会在侧边栏导航中显示该页面。
以下文件名和可调用对象在侧边栏导航中都会显示为 "Awesome page":
"Awesome page.py""Awesome_page.py""02Awesome_page.py""--Awesome_page.py""1_Awesome_page.py""33 - Awesome page.py"Awesome_page()_Awesome_page()__Awesome_page__()
Streamlit 如何将文件名转换为 URL 路径名
您应用的主页与应用的根 URL 相关联。
对于所有其他页面,它们的 identifier 或 number 会按照以下方式成为其 URL 路径名:
- 如果您的页面有一个来自文件名的
identifier,Streamlit 会使用该identifier,但会做一处修改:Streamlit 会将连续的多个空格(" ")和下划线("_")压缩为单个下划线。 - 如果您的页面有一个来自可调用对象名称的
identifier,Streamlit 会直接使用未修改的identifier。 - 如果您的页面有一个
number但没有identifier,Streamlit 会使用该number。
如果存在前导零,则会保留。
对于上述列表中的每个文件名,URL 路径名将是相对于应用根 URL 的 "Awesome_page"。
例如,如果您的应用运行在 localhost 的 8501 端口上,完整的 URL 将是 localhost:8501/awesome_page。
然而,对于最后两个可调用对象,路径名会包含前导和尾随的下划线,以完全匹配可调用对象的名称。
页面间导航
用户在不同页面间导航的主要方式是通过导航组件。
定义多页面应用的两种方法都包含一个默认的导航菜单,该菜单显示在侧边栏中。
当用户点击此导航组件时,应用会重新运行并加载所选页面。
您也可以选择隐藏默认导航界面,使用 st.page_link 构建自定义导航菜单。
更多信息请参阅 使用 st.page_link 构建自定义导航菜单。
如果需要以编程方式切换页面,请使用 st.switch_page。
如上所述,用户还可以通过 URL 在页面间导航。
当多个文件具有相同的 URL 路径时,Streamlit 会根据导航菜单中的顺序选择第一个文件。
用户可以通过访问页面的 URL 来查看特定页面。
重要提示
通过URL在页面间跳转会创建新的浏览器会话。
特别需要注意的是,点击指向其他页面的Markdown链接会重置st.session_state。
若需保留st.session_state中的值,请使用Streamlit的导航命令和组件进行页面切换,例如st.navigation、st.switch_page、st.page_link以及内置的导航菜单。
如果用户尝试访问不存在的页面URL,将会看到如下提示模态框,显示"页面未找到"。
使用 st.Page 和 st.navigation 定义多页面应用
https://docs.streamlit.io/develop/concepts/multipage-apps/page-and-navigation
st.Page 和 st.navigation 是定义多页面应用的首选命令。
通过这些命令,您可以灵活地组织项目文件并自定义导航菜单。
只需使用 st.Page 初始化 StreamlitPage 对象,然后将这些 StreamlitPage 对象传递给入口文件(即传递给 streamlit run 的文件)中的 st.navigation。
本页面假设您已理解概述中介绍的页面术语。
应用结构
当使用 st.navigation 时,你的入口文件相当于一个页面路由器。
每个页面都是从入口文件执行的脚本。
你可以通过 Python 文件或函数来定义页面。
如果在入口文件中包含元素或组件,这些会成为各页面间的共享元素。
这种情况下,可以把入口文件想象成包裹每个页面的画框。
每个应用运行期间只能调用一次 st.navigation,且必须从入口文件调用。
当用户在导航中选择页面(或通过类似 st.switch_page 的命令跳转)时,st.navigation 会返回选中的页面。
你需要手动通过 .run() 方法执行该页面。
以下示例展示了一个双页面应用,其中每个页面都由一个 Python 文件定义。
目录结构:
shell
your-repository/
├── page_1.py
├── page_2.py
└── streamlit_app.pystreamlit_app.py:
python
import streamlit as st
pg = st.navigation([st.Page("page_1.py"), st.Page("page_2.py")])
pg.run()定义页面
st.Page 允许您定义一个页面。
第一个也是唯一必需的参数用于指定页面来源,可以是 Python 文件或函数。
使用 Python 文件时,页面可以位于子目录(或上级目录)中。
页面文件的路径必须始终相对于入口文件。
创建页面对象后,将它们传递给 st.navigation 以在应用中注册为页面。
如果不定义页面标题或 URL 路径名,Streamlit 会按照多页面应用概述中的说明,从文件或函数名自动推断。
但 st.Page 允许您手动配置这些属性。
在 st.Page 内部,Streamlit 使用 title 设置页面标签和标题,使用 icon 设置页面图标和网站图标。
若需要不同的页面标题与标签,或不同的页面图标与网站图标,可通过 st.set_page_config 进行修改。
只需在入口文件或页面脚本中调用 st.set_page_config 即可。
您可以多次调用该函数以叠加配置页面属性:在入口文件中声明默认配置,在页面脚本中调用以覆盖默认值。
以下示例使用 st.set_page_config 在所有页面上统一设置标题和网站图标。
每个页面在导航菜单中会有独立的标签和图标,但浏览器标签页会显示统一的标题和网站图标。
目录结构:
shell
your-repository/
├── create.py
├── delete.py
└── streamlit_app.pystreamlit_app.py:
python
import streamlit as st
create_page = st.Page("create.py", title="Create entry", icon=":material/add_circle:")
delete_page = st.Page("delete.py", title="Delete entry", icon=":material/delete:")
pg = st.navigation([create_page, delete_page])
st.set_page_config(page_title="Data manager", page_icon=":material/edit:")
pg.run()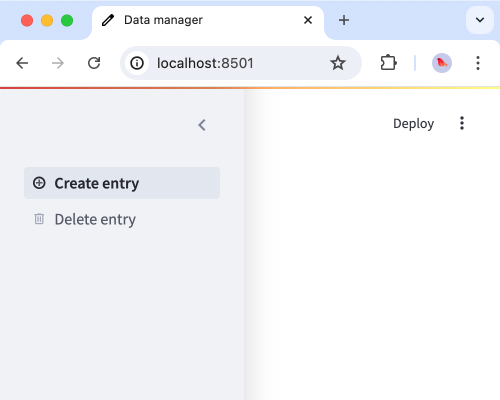
自定义导航
您可以通过st.navigation中的position参数,选择在应用侧边栏或顶部显示导航菜单。
如需将页面分组,st.navigation支持在侧边栏导航中添加标题,或在顶部导航中创建下拉分组。
您也可以禁用默认导航组件,使用st.page_link构建自定义导航菜单。
此外,您可以动态调整传递给st.navigation的页面列表。
但需注意,只有通过st.navigation返回的页面才能调用.run()方法。
如果用户首次访问时输入的URL路径名未关联到st.navigation中的任何页面,Streamlit会抛出"页面未找到"错误并重定向至默认页面。
添加章节标题
自定义导航菜单的最简单方法是在 st.navigation 中组织页面。
您可以对页面进行排序或分组,也可以移除不希望用户访问的任何页面。
这是处理用户权限的一种便捷方式。
但请注意,您无法在导航中隐藏某个页面同时仍允许通过直接 URL 访问它。
如果需要隐藏页面但保持可访问性,您需要隐藏默认导航菜单,并使用 st.page_link 等命令构建自定义导航菜单。
以下示例创建了两种菜单状态。
当用户开始新会话时,他们处于未登录状态,此时唯一可用的页面是登录页。
如果用户尝试通过 URL 访问其他页面,这将创建一个新会话,而 Streamlit 无法识别该页面,用户将被重定向到登录页。
然而,当用户登录后,他们将看到包含三个分区的导航菜单,并被引导至仪表盘作为应用的默认页面(即主页)。
目录结构:
shell
your-repository/
├── reports
│ ├── alerts.py
│ ├── bugs.py
│ └── dashboard.py
├── tools
│ ├── history.py
│ └── search.py
└── streamlit_app.pystreamlit_app.py:
python
import streamlit as st
if "logged_in" not in st.session_state:
st.session_state.logged_in = False
def login():
if st.button("Log in"):
st.session_state.logged_in = True
st.rerun()
def logout():
if st.button("Log out"):
st.session_state.logged_in = False
st.rerun()
login_page = st.Page(login, title="Log in", icon=":material/login:")
logout_page = st.Page(logout, title="Log out", icon=":material/logout:")
dashboard = st.Page(
"reports/dashboard.py", title="Dashboard", icon=":material/dashboard:", default=True
)
bugs = st.Page("reports/bugs.py", title="Bug reports", icon=":material/bug_report:")
alerts = st.Page(
"reports/alerts.py", title="System alerts", icon=":material/notification_important:"
)
search = st.Page("tools/search.py", title="Search", icon=":material/search:")
history = st.Page("tools/history.py", title="History", icon=":material/history:")
if st.session_state.logged_in:
pg = st.navigation(
{
"Account": [logout_page],
"Reports": [dashboard, bugs, alerts],
"Tools": [search, history],
}
)
else:
pg = st.navigation([login_page])
pg.run()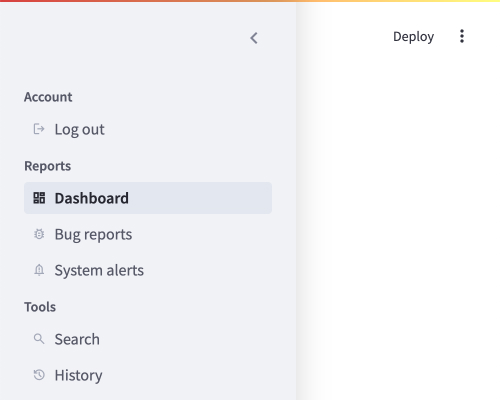
动态更改可用页面
通过更新 st.navigation 中的页面列表,您可以动态调整用户可访问的页面。
这种方式非常适合实现基于角色或用户的页面访问控制。
如需了解更多详情,请参阅我们的教程:创建动态导航菜单。
构建自定义导航菜单
如需对导航菜单进行更多控制,您可以隐藏默认导航并构建自己的菜单。
通过在 st.navigation 命令中包含 position="hidden" 即可隐藏默认导航。
若希望某个页面对用户可用但不在导航菜单中显示,必须使用此方法。
如果页面未包含在 st.navigation 中,用户将无法通过URL导航或 st.switch_page、st.page_link 等命令访问该页面。
使用 pages/ 目录创建多页面应用
https://docs.streamlit.io/develop/concepts/multipage-apps/pages-directory
声明多页面应用最灵活的方式是使用页面与导航。
不过,Streamlit 还提供了一种更简便的方法,能够自动识别页面并在应用侧边栏的导航组件中显示。
这种方法就是使用 pages/ 目录。
在阅读本页内容前,请确保您已理解概述中介绍的页面术语。
应用结构
当使用 pages/ 目录时,Streamlit 会通过目录结构和文件名来识别多页面应用中的各个页面。
入口文件(即传递给 streamlit run 的文件)就是应用的主页。
如果在入口文件同级目录下存在 pages/ 目录,Streamlit 会将该目录内的每个 Python 文件识别为一个独立页面。
以下示例展示了包含三个页面的结构:your_homepage.py 是入口文件兼主页。
shell
your_working_directory/
├── pages/
│ ├── a_page.py
│ └── another_page.py
└── your_homepage.py像运行单页应用一样运行你的多页应用。
将入口文件传递给 streamlit run 即可。
shell
streamlit run your_homepage.py只有 pages/ 目录下的 .py 文件会被识别为页面文件。
Streamlit 会忽略 pages/ 目录及其子目录中的所有其他文件。
同时,Streamlit 也会忽略 pages/ 子目录中的 Python 文件。
重要提示
如果在应用中的任何会话调用了 st.navigation,Streamlit 将切换至新版的多页面导航结构。
此时,所有会话中的 pages/ 目录将被忽略。
除非重启应用,否则无法恢复使用 pages/ 目录。
侧边栏页面排序规则
请参阅概述文档,了解 Streamlit 如何根据构成文件名的数字、分隔符、标识符和".py"扩展名自动分配页面标签和URL。
入口文件始终显示在首位。
其余页面按以下规则排序:
- 含有
数字的文件排在无数字文件之前 - 文件首先按
数字(如有)排序,其次按标签(如有)排序 - 排序时,Streamlit 将
数字视为实际数值而非字符串。
因此03与3被视为相同
下表展示了文件名示例及其对应的渲染标签,按它们在侧边栏中的出现顺序排列。
示例:
| 文件名 | 渲染标签 |
|---|---|
1 - first page.py |
first page |
12 monkeys.py |
monkeys |
123.py |
123 |
123_hello_dear_world.py |
hello dear world |
_12 monkeys.py |
12 monkeys |
小贴士
使用表情符号可以让你的页面名称更有趣!例如,将文件命名为🏠_Home.py会在侧边栏中创建一个标题为"🏠 Home"的页面。
在文件名中添加表情符号时,最佳实践是包含数字前缀,这样可以使终端中的自动补全更容易。
终端自动补全功能可能会被Unicode(表情符号的表示方式)搞混。
注意事项与限制
-
页面支持保存时自动重新运行。
-
当应用运行时更新页面,会导致当前正在查看该页面的用户触发重新运行。
-
当应用运行时更新页面,不会自动为当前正在查看其他页面的用户触发重新运行。
-
-
应用运行时,添加或删除页面会立即更新侧边栏导航。
-
st.set_page_config在页面级别生效。-
使用
st.set_page_config设置title或favicon时,仅对当前页面有效。 -
使用
st.set_page_config设置layout时,该设置会在会话期间保持有效,直到通过另一次st.set_page_config调用更改。如果使用
st.set_page_config设置layout,建议在所有页面上调用它。
-
-
页面间全局共享相同的 Python 模块:
page1.py
import foo
foo.hello = 123page2.py
import foo
st.write(foo.hello) # If page1 already executed, this writes 123
页面共享相同的 st.session_state:
# page1.py
import streamlit as st
if "shared" not in st.session_state:
st.session_state["shared"] = True
# page2.py
import streamlit as st
st.write(st.session_state["shared"]) # If page1 already executed, this writes True现在你已经对多页面应用有了扎实的理解。
你学会了如何构建应用、定义页面以及在用户界面中实现页面间的导航。
是时候创建你的第一个多页面应用了!🥳
多页面应用中的部件使用
https://docs.streamlit.io/develop/concepts/multipage-apps/widgets
在Streamlit应用中创建部件时,Streamlit会生成一个部件ID,并利用该ID使部件具备状态保持能力。
当应用因用户交互而重新运行时,Streamlit通过将部件值与ID关联来跟踪其状态。
特别需要注意的是,部件的ID取决于它被创建的页面。
如果在两个不同页面上定义完全相同的部件,切换页面时该部件会重置为默认值。
本指南介绍了三种策略来处理这种情况,如果您希望部件在所有页面间保持状态:
- 若您不希望部件出现在所有页面,但希望在离开其所在页面(再返回)时保持状态,可采用方案2或方案3
- 关于这些策略的详细信息,请参阅理解部件行为
(注:原文末尾的星号分隔符***已转换为中文文档常用的空行分隔)
选项1(推荐):在入口文件中执行小部件命令
当你使用 st.Page 和 st.navigation 定义多页面应用时,入口文件会成为包裹各页面的公共元素框架。
如果在入口文件中执行小部件命令,Streamlit 会将该小部件关联到入口文件而非特定页面。
由于入口文件会在每次应用重新运行时执行,其中的小部件状态将在用户切换页面时得以保留。
注意:若通过 pages/ 目录结构定义应用,此方法无效。
以下示例在侧边栏放置了选择框和滑块组件,这些部件会在所有页面上渲染并保持状态。
每个小部件都分配了唯一键,以便通过会话状态在页面内访问其值。
目录结构:
shell
your-repository/
├── page_1.py
├── page_2.py
└── streamlit_app.pystreamlit_app.py:
python
import streamlit as st
pg = st.navigation([st.Page("page_1.py"), st.Page("page_2.py")])
st.sidebar.selectbox("Group", ["A","B","C"], key="group")
st.sidebar.slider("Size", 1, 5, key="size")
pg.run()选项2:将小组件值保存到会话状态的虚拟键中
如果您希望在离开小组件后返回时保留其值,或者想在多个页面上使用同一个小组件,可以在st.session_state中使用单独的键来独立保存该值。
本示例展示了如何配合小组件使用临时键。
临时键采用下划线前缀命名,例如使用"_my_key"作为小组件键,但实际数据会被复制到"my_key"中,从而实现跨页面数据持久化。
python
import streamlit as st
def store_value():
# Copy the value to the permanent key
st.session_state["my_key"] = st.session_state["_my_key"]
# Copy the saved value to the temporary key
st.session_state["_my_key"] = st.session_state["my_key"]
st.number_input("Number of filters", key="_my_key", on_change=store_value)如果将其功能化以支持多个小部件,可能会是这样的:
python
import streamlit as st
def store_value(key):
st.session_state[key] = st.session_state["_"+key]
def load_value(key):
st.session_state["_"+key] = st.session_state[key]
load_value("my_key")
st.number_input("Number of filters", key="_my_key", on_change=store_value, args=["my_key"])选项3:中断小部件的清理过程
当Streamlit运行到应用程序末尾时,它会删除所有未被渲染的小部件数据。
这包括与当前页面无关的任何小部件数据。
但是,如果在某次应用运行中重新保存了一个键值对,Streamlit不会将该键值对关联到任何小部件,除非你再次使用该键执行小部件命令。
因此,如果在每个页面顶部都放置以下代码,那么无论"my_key"键对应的小部件是否被渲染(或未被渲染),它都会保留其值。
另外,如果你使用st.navigation和st.Page,可以在入口文件中执行页面之前包含此代码一次。
python
if "my_key" in st.session_state:
st.session_state.my_key = st.session_state.my_key应用设计理念与注意事项
https://docs.streamlit.io/develop/concepts/design
动画与元素更新
了解如何在不重新运行应用的情况下创建动态动画内容或更新元素。
https://docs.streamlit.io/develop/concepts/design/animate
按钮行为与示例
通过解释和示例了解按钮的工作原理,避免常见错误。
https://docs.streamlit.io/develop/concepts/design/buttons
数据框
数据框是以表格形式展示和编辑数据的绝佳方式。
了解 Streamlit 中可用的用户界面及选项。
https://docs.streamlit.io/develop/concepts/design/dataframes
在Streamlit应用中使用自定义Python类
了解在Streamlit的重新运行模型中定义自定义Python类的影响。
https://docs.streamlit.io/develop/concepts/design/custom-classes
多线程
了解如何在 Streamlit 应用中使用多线程。
https://docs.streamlit.io/develop/concepts/design/multithreading
处理时区问题
了解如何为用户本地化显示时间。
https://docs.streamlit.io/develop/concepts/design/timezone-handling
元素动画与更新
https://docs.streamlit.io/develop/concepts/design/animate
有时您会显示图表或数据框,并希望在应用运行时动态修改它们(例如在循环中)。
某些元素内置了方法,允许您就地更新而无需重新运行应用。
可更新的元素包括:
st.empty容器可以按顺序写入内容,始终显示最后写入的内容。
也可以通过调用.empty()方法来清除内容。st.dataframe、st.table和许多图表元素可以使用.add_rows()方法追加数据来更新。st.progress元素可以通过额外的.progress()调用来更新。
也可以通过调用.empty()方法清除。st.status容器具有.update()方法,可以更改其标签、展开状态和状态。st.toast消息可以通过额外的.toast()调用来就地更新。
st.empty 容器
st.empty 可以容纳单个元素。
当你向 st.empty 容器写入任何元素时,Streamlit 会丢弃其先前的内容并显示新元素。
你也可以通过调用 .empty() 方法清空容器。
如果想更新一组元素,可以在 st.empty 内部使用普通容器(st.container()),并将内容写入该普通容器。
通过反复重写普通容器及其内容,可以按需更新应用的显示界面。
.add_rows() 方法
st.dataframe、st.table 以及所有图表函数都可以通过对其输出使用 .add_rows() 方法进行动态更新。
在下面的示例中,我们使用 my_data_element = st.line_chart(df)。
你可以尝试将 st.line_chart 替换为 st.table、st.dataframe 或大多数其他简单图表来体验该功能。
需要注意的是,st.dataframe 默认仅显示前十行数据,并通过滚动条查看额外行数,因此添加行数的视觉效果不如 st.table 或图表元素那样直观。
python
import streamlit as st
import pandas as pd
import numpy as np
import time
df = pd.DataFrame(np.random.randn(15, 3), columns=(["A", "B", "C"]))
my_data_element = st.line_chart(df)
for tick in range(10):
time.sleep(.5)
add_df = pd.DataFrame(np.random.randn(1, 3), columns=(["A", "B", "C"]))
my_data_element.add_rows(add_df)
st.button("Regenerate")按钮行为与示例
https://docs.streamlit.io/develop/concepts/design/buttons
概述
使用 st.button 创建的按钮不会保持状态。
当用户点击按钮导致脚本重新运行时,按钮会返回 True,但在下一次脚本重新运行时立即恢复为 False。
如果某个显示元素嵌套在 if st.button('点击我'): 语句中,该元素会在按钮被点击时显示,并在用户执行下一个操作时消失。
这是因为脚本重新运行后,按钮的返回值变为 False。
在本指南中,我们将演示按钮的使用方法,并解释常见的误解。
继续阅读,您将看到一系列基于 st.button 并结合 st.session_state 的扩展示例。
最后还包含了一些反模式的说明。
建议您打开喜欢的代码编辑器,边阅读边通过 streamlit run 运行这些示例。
如果您尚未运行过自己的 Streamlit 脚本,可以参考 Streamlit 的基本概念文档。
何时使用 if st.button()
当代码根据按钮的值进行条件判断时,它会在按钮被点击时执行一次,之后不会再次执行(直到按钮再次被点击)。
适合嵌套在按钮中的情况:
- 立即消失的临时消息
- 每次点击执行一次的过程,例如将数据保存到会话状态、文件或数据库
不适合嵌套在按钮中的情况:
- 需要持续显示的内容(当用户继续操作时仍应保留)
- 会导致脚本重新运行的其他小部件
- 既不修改会话状态也不写入文件/数据库的过程*
- 当需要一次性结果时,这种方式可能是合适的。
例如"验证"按钮可以直接基于按钮条件触发验证过程,用于生成显示"有效"或"无效"的提示,而无需保留该信息。
(注:原文中的代码块标记和术语如st.button()、'Valid'/'Invalid'等均按核心翻译原则保持原样)
按钮的通用逻辑
通过按钮显示临时消息
如果想为用户提供一个快速按钮来检查某个条目是否有效,但又不希望这个检查结果在用户继续操作时一直显示。
在这个示例中,用户可以通过点击按钮来检查他们的animal字符串是否存在于animal_shelter列表中。
当用户点击"检查可用性 "时,他们会看到"我们有这种动物!"或"我们没有这种动物。
"的提示。
如果用户在st.text_input中修改了动物名称,脚本会重新运行,消息将消失,直到用户再次点击"检查可用性"按钮。
python
import streamlit as st
animal_shelter = ['cat', 'dog', 'rabbit', 'bird']
animal = st.text_input('Type an animal')
if st.button('Check availability'):
have_it = animal.lower() in animal_shelter
'We have that animal!' if have_it else 'We don\'t have that animal.'注意:上述示例使用了magic在前端渲染消息。
状态化按钮
如果你希望点击后的按钮保持True状态,可以在st.session_state中创建一个值,并通过回调函数让按钮将该值设为True。
python
import streamlit as st
if 'clicked' not in st.session_state:
st.session_state.clicked = False
def click_button():
st.session_state.clicked = True
st.button('Click me', on_click=click_button)
if st.session_state.clicked:
# The message and nested widget will remain on the page
st.write('Button clicked!')
st.slider('Select a value')切换按钮
如果你想要一个像开关一样工作的按钮,可以考虑使用 st.checkbox。
否则,你可以通过带有回调函数的按钮来反转保存在 st.session_state 中的布尔值。
在这个示例中,我们使用 st.button 来切换另一个小部件的开关状态。
通过在 st.session_state 中的某个值上条件式地显示 st.slider,用户可以与滑块交互而不会使其消失。
python
import streamlit as st
if 'button' not in st.session_state:
st.session_state.button = False
def click_button():
st.session_state.button = not st.session_state.button
st.button('Click me', on_click=click_button)
if st.session_state.button:
# The message and nested widget will remain on the page
st.write('Button is on!')
st.slider('Select a value')
else:
st.write('Button is off!')或者,您可以在滑块的 disabled 参数中使用 st.session_state 中的值。
python
import streamlit as st
if 'button' not in st.session_state:
st.session_state.button = False
def click_button():
st.session_state.button = not st.session_state.button
st.button('Click me', on_click=click_button)
st.slider('Select a value', disabled=st.session_state.button)用于继续或控制流程阶段的按钮
另一种替代在按钮内嵌套内容的方法是使用st.session_state中的值来指定流程的"步骤"或"阶段"。
在这个示例中,我们的脚本包含四个阶段:
0、用户开始前
1、用户输入姓名
2、用户选择颜色
3、用户收到感谢消息
初始按钮将阶段从0推进到1,结束按钮将阶段从3重置为0。
阶段1和2中使用的其他小部件通过回调函数来设置阶段。
如果你的流程包含依赖步骤并希望保持先前阶段可见,这种回调机制会强制用户在更改早期小部件时重新经历后续阶段。
python
import streamlit as st
if 'stage' not in st.session_state:
st.session_state.stage = 0
def set_state(i):
st.session_state.stage = i
if st.session_state.stage == 0:
st.button('Begin', on_click=set_state, args=[1])
if st.session_state.stage >= 1:
name = st.text_input('Name', on_change=set_state, args=[2])
if st.session_state.stage >= 2:
st.write(f'Hello {name}!')
color = st.selectbox(
'Pick a Color',
[None, 'red', 'orange', 'green', 'blue', 'violet'],
on_change=set_state, args=[3]
)
if color is None:
set_state(2)
if st.session_state.stage >= 3:
st.write(f':{color}[Thank you!]')
st.button('Start Over', on_click=set_state, args=[0])修改 st.session_state 的按钮
如果在按钮内部修改 st.session_state,必须注意该按钮在脚本中的位置。
一个小问题
在这个示例中,我们在修改按钮前后都访问了 st.session_state.name。
当点击按钮("Jane " 或 "John ")时,脚本会重新运行。
按钮前显示的信息会滞后于按钮后写入的信息。
按钮前的 st.session_state 数据不会更新。
当脚本执行按钮函数时,正是更新 st.session_state 的条件代码触发了变更。
因此,这一变更会在按钮后体现出来。
python
import streamlit as st
import pandas as pd
if 'name' not in st.session_state:
st.session_state['name'] = 'John Doe'
st.header(st.session_state['name'])
if st.button('Jane'):
st.session_state['name'] = 'Jane Doe'
if st.button('John'):
st.session_state['name'] = 'John Doe'
st.header(st.session_state['name'])回调函数中的逻辑运用
回调函数是修改 st.session_state 的一种简洁方式。
回调函数会在脚本重新运行前作为前置操作执行,因此按钮位置与数据访问的相对顺序并不重要。
python
import streamlit as st
import pandas as pd
if 'name' not in st.session_state:
st.session_state['name'] = 'John Doe'
def change_name(name):
st.session_state['name'] = name
st.header(st.session_state['name'])
st.button('Jane', on_click=change_name, args=['Jane Doe'])
st.button('John', on_click=change_name, args=['John Doe'])
st.header(st.session_state['name'])带有重新运行逻辑的嵌套按钮
虽然通常推荐使用回调来避免额外的重新运行,但我们可以通过添加 st.rerun 来修改最初的 'John Doe'/'Jane Doe' 示例。
如果你需要在修改数据的按钮之前访问 st.session_state 中的数据,可以包含 st.rerun 以便在更改提交后重新运行脚本。
这意味着点击按钮时脚本会运行两次。
python
import streamlit as st
import pandas as pd
if 'name' not in st.session_state:
st.session_state['name'] = 'John Doe'
st.header(st.session_state['name'])
if st.button('Jane'):
st.session_state['name'] = 'Jane Doe'
st.rerun()
if st.button('John'):
st.session_state['name'] = 'John Doe'
st.rerun()
st.header(st.session_state['name'])用于修改或重置其他控件的按钮
当使用按钮来修改或重置另一个控件时,其原理与上述修改 st.session_state 的示例相同。
但需特别注意:如果当前脚本运行期间页面上已经渲染了具有该键的控件,则无法修改 st.session_state 中对应的键值对。
重要
不要这样做!
python
import streamlit as st
st.text_input('Name', key='name')
# These buttons will error because their nested code changes
# a widget's state after that widget within the script.
if st.button('Clear name'):
st.session_state.name = ''
if st.button('Streamlit!'):
st.session_state.name = ('Streamlit')选项1:为按钮设置键值并将逻辑置于组件之前
如果为按钮分配一个键值,您可以通过在st.session_state中使用该键值来编写基于按钮状态的逻辑代码。
这意味着依赖于按钮的逻辑可以放在脚本中该按钮之前的位置。
在以下示例中,我们对st.session_state使用.get()方法,因为当脚本首次运行时,按钮的键值尚不存在。
.get()方法在找不到键时会返回False,否则将返回该键对应的值。
python
import streamlit as st
# Use the get method since the keys won't be in session_state
# on the first script run
if st.session_state.get('clear'):
st.session_state['name'] = ''
if st.session_state.get('streamlit'):
st.session_state['name'] = 'Streamlit'
st.text_input('Name', key='name')
st.button('Clear name', key='clear')
st.button('Streamlit!', key='streamlit')选项2:使用回调函数
python
import streamlit as st
st.text_input('Name', key='name')
def set_name(name):
st.session_state.name = name
st.button('Clear name', on_click=set_name, args=[''])
st.button('Streamlit!', on_click=set_name, args=['Streamlit'])选项3:使用容器
通过使用 st.container,您可以让控件在脚本和前端视图(网页)中以不同的顺序显示。
python
import streamlit as st
begin = st.container()
if st.button('Clear name'):
st.session_state.name = ''
if st.button('Streamlit!'):
st.session_state.name = ('Streamlit')
# The widget is second in logic, but first in display
begin.text_input('Name', key='name')动态添加其他小部件的按钮
在动态向页面添加小部件时,请确保使用索引来保持键的唯一性,避免出现 DuplicateWidgetID 错误。
本示例中,我们定义了一个函数 display_input_row 来渲染一行小部件。
该函数接受一个 index 作为参数。
由 display_input_row 渲染的小部件在其键中使用 index,这样 display_input_row 就可以在单次脚本重新运行时多次执行,而不会重复任何小部件键。
python
import streamlit as st
def display_input_row(index):
left, middle, right = st.columns(3)
left.text_input('First', key=f'first_{index}')
middle.text_input('Middle', key=f'middle_{index}')
right.text_input('Last', key=f'last_{index}')
if 'rows' not in st.session_state:
st.session_state['rows'] = 0
def increase_rows():
st.session_state['rows'] += 1
st.button('Add person', on_click=increase_rows)
for i in range(st.session_state['rows']):
display_input_row(i)
# Show the results
st.subheader('People')
for i in range(st.session_state['rows']):
st.write(
f'Person {i+1}:',
st.session_state[f'first_{i}'],
st.session_state[f'middle_{i}'],
st.session_state[f'last_{i}']
)处理耗时或文件写入操作的按钮
当涉及耗时较长的操作时,建议将其设置为点击按钮后触发运行,并将结果保存到 st.session_state 中。
这样可以在不重复执行的情况下持续访问操作结果,尤其适用于需要写入磁盘或数据库的操作。
本例中,我们定义了一个依赖两个参数 option 和 add 的 expensive_process 函数。
从功能上看,add 会改变输出结果,而 option 仅作为参数存在------其值不会影响输出。
python
import streamlit as st
import pandas as pd
import time
def expensive_process(option, add):
with st.spinner('Processing...'):
time.sleep(5)
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C':[7, 8, 9]}) + add
return (df, add)
cols = st.columns(2)
option = cols[0].selectbox('Select a number', options=['1', '2', '3'])
add = cols[1].number_input('Add a number', min_value=0, max_value=10)
if 'processed' not in st.session_state:
st.session_state.processed = {}
# Process and save results
if st.button('Process'):
result = expensive_process(option, add)
st.session_state.processed[option] = result
st.write(f'Option {option} processed with add {add}')
result[0]敏锐的观察者可能会认为:"这有点像缓存。
"我们目前只保存与单个参数相关的结果,但这种模式可以轻松扩展为保存与两个参数相关的结果。
从这个角度看,确实与缓存有相似之处,但也存在重要差异。
当你在st.session_state中保存结果时,这些结果仅对当前用户的当前会话可见。
如果改用st.cache_data,则所有用户的所有会话都能访问这些结果。
此外,若想更新已保存的结果,必须清除该函数的所有缓存结果才能实现。
反模式
以下是按钮设计出错的几个简化示例。
请注意避免这些常见错误。
按钮内嵌套按钮
python
import streamlit as st
if st.button('Button 1'):
st.write('Button 1 was clicked')
if st.button('Button 2'):
# This will never be executed.
st.write('Button 2 was clicked')按钮内嵌套的其他小部件
python
import streamlit as st
if st.button('Sign up'):
name = st.text_input('Name')
if name:
# This will never be executed.
st.success(f'Welcome {name}')在按钮内嵌套流程而不保存到会话状态
python
import streamlit as st
import pandas as pd
file = st.file_uploader("Upload a file", type="csv")
if st.button('Get data'):
df = pd.read_csv(file)
# This display will go away with the user's next action.
st.write(df)
if st.button('Save'):
# This will always error.
df.to_csv('data.csv')数据框
https://docs.streamlit.io/develop/concepts/design/dataframes
数据框是以表格形式展示和编辑数据的绝佳方式。
在数据科学工作流中,处理Pandas DataFrame和其他表格数据结构是关键环节。
如果开发者和数据科学家希望在Streamlit中展示这类数据,他们有多种选择:st.dataframe 和 st.data_editor。
若只需在类似表格的界面中展示数据,st.dataframe 是最佳选择;如需交互式编辑数据,则应使用 st.data_editor。
我们将在后续章节探讨每种选项的使用场景和优势。
使用 st.dataframe 展示数据框
Streamlit 能够通过 st.dataframe 以表格形式的用户界面展示数据框:
python
import streamlit as st
import pandas as pd
df = pd.DataFrame(
[
{"command": "st.selectbox", "rating": 4, "is_widget": True},
{"command": "st.balloons", "rating": 5, "is_widget": False},
{"command": "st.time_input", "rating": 3, "is_widget": True},
]
)
st.dataframe(df, use_container_width=True)基于Streamlit构建 🎈全屏查看 open_in_new
st.dataframe 用户界面功能
st.dataframe 底层使用了 glide-data-grid,提供以下增强功能:
- 列排序 :点击列标题或通过标题菜单(more_vert )选择"升序排序 "或"降序排序"进行排序。
- 列宽调整 :拖拽列标题边框,或通过标题菜单选择"自动调整"来改变列宽。
- 列隐藏 :通过标题菜单选择"隐藏列"可隐藏指定列。
- 列重排与固定 :拖拽列标题可调整顺序,或通过标题菜单选择"固定列"将列固定在左侧。
- 数字、日期和时间格式化 :在标题菜单的"格式"选项下可修改数值列的显示格式。
- 数据框缩放:拖拽右下角可调整数据框尺寸。
- 全屏模式 :点击工具栏全屏图标(fullscreen)可全屏查看数据。
- 搜索功能 :点击工具栏搜索图标(search )或使用快捷键(
⌘+F或Ctrl+F)进行数据检索。 - 下载数据 :点击工具栏下载图标(download)可将数据导出为CSV文件。
- 复制到剪贴板 :选中单元格后使用快捷键(
⌘+C或Ctrl+C)即可将数据粘贴至其他表格软件。
您可以通过上一节的嵌入式应用体验所有功能。
除Pandas DataFrame外,st.dataframe 还支持列表、字典、numpy数组等Python数据类型,同时兼容 Snowpark 和 PySpark DataFrame,支持从数据库延迟加载数据,这对处理大型数据集特别有用。
使用 st.data_editor 编辑数据
Streamlit 通过 st.data_editor 命令支持可编辑的数据框。
查看其 API 文档:st.data_editor。
它会以表格形式展示数据框,类似于 st.dataframe。
但与 st.dataframe 不同的是,这个表格不是静态的!用户可以点击单元格进行编辑,修改后的数据会返回给 Python 端。
以下是一个示例:
python
df = pd.DataFrame(
[
{"command": "st.selectbox", "rating": 4, "is_widget": True},
{"command": "st.balloons", "rating": 5, "is_widget": False},
{"command": "st.time_input", "rating": 3, "is_widget": True},
]
)
edited_df = st.data_editor(df) # 👈 An editable dataframe
favorite_command = edited_df.loc[edited_df["rating"].idxmax()]["command"]
st.markdown(f"Your favorite command is **{favorite_command}** 🎈")由Streamlit构建 🎈全屏打开 open_in_new
双击任意单元格即可试用。
你会发现可以编辑所有单元格的值。
试着修改评分列中的数值,观察底部文本输出如何变化:
st.data_editor 的 UI 功能
st.data_editor 还支持以下附加功能:
- 添加和删除行:在调用
st.data_editor时设置num_rows= "dynamic"即可实现。
这将允许用户根据需要添加和删除行。 - 复制粘贴支持:支持在
st.data_editor与 Google Sheets、Excel 等电子表格软件之间进行复制粘贴。 - 访问编辑后的数据:通过 Session State 仅访问单个编辑内容,而非整个编辑后的数据结构。
- 批量编辑:类似于 Excel,只需拖动手柄即可编辑相邻单元格。
- 自动输入验证:列配置提供了强大的数据类型支持和其他可配置选项。
例如,无法在数字单元格中输入字母。
数字单元格可以设置最小值和最大值。 - 编辑常见数据结构:
st.data_editor支持列表、字典、NumPy ndarray 等多种数据结构!
添加与删除行
通过 st.data_editor,用户可以直接在表格界面中添加或删除行。
只需将 num_rows 参数设置为 "dynamic" 即可启用此功能:
python
edited_df = st.data_editor(df, num_rows="dynamic")-
要添加新行,点击工具栏中的加号图标(添加 )。
或者,点击表格底部最后一行的阴影单元格内部。
-
要删除行,使用左侧的复选框选中一行或多行。
点击删除图标(删除 )或按键盘上的
delete键。
由 Streamlit 🎈 构建全屏显示 open_in_new
复制粘贴支持
数据编辑器支持从 Google Sheets、Excel、Notion 等类似工具粘贴表格数据。
您还可以在多个 st.data_editor 实例之间进行数据复制粘贴。
该功能基于 Clipboard API 实现,能为跨平台处理数据的用户节省大量时间。
使用方法如下:
- 从 此 Google Sheets 文档 复制数据到剪贴板
- 点击上方应用中
name列的任意单元格,使用快捷键(⌘+V或Ctrl+V)粘贴数据
注意
粘贴数据的每个单元格都会单独评估,只有当数据与列类型兼容时才会插入到单元格中。
例如,将非数值文本数据粘贴到数字列中会被忽略。
提示
如果通过 iframe 嵌入应用,且需要使用复制粘贴功能,则需要允许 iframe 访问剪贴板。
为此,请为 iframe 添加 clipboard-write 和 clipboard-read 权限。
例如:
<iframe allow="clipboard-write;clipboard-read;" ... src="https://your-app-url"></iframe>作为开发者,在使用 TLS 时请确保应用提供的是有效且受信任的证书。
如果用户遇到复制粘贴数据的问题,请引导他们检查浏览器是否已为 Streamlit 应用激活剪贴板访问权限------无论是通过提示还是通过浏览器的网站设置进行授权。
访问编辑后的数据
有时,了解哪些单元格被修改比获取整个编辑后的数据框更为方便。
Streamlit 通过使用会话状态简化了这一过程。
如果设置了key参数,Streamlit会将数据框的所有变更存储在会话状态中。
以下代码片段展示了如何通过会话状态访问变更的数据:
python
st.data_editor(df, key="my_key", num_rows="dynamic") # 👈 Set a key
st.write("Here's the value in Session State:")
st.write(st.session_state["my_key"]) # 👈 Show the value in Session State在这段代码中,key参数被设置为"my_key"。
创建数据编辑器后,Session State中与"my_key"关联的值会通过st.write显示在应用中。
这展示了用户所做的添加、编辑和删除操作。
当处理大型数据框时,此功能尤为实用------您只需了解哪些单元格被修改过,而无需访问整个编辑后的数据框。
由Streamlit构建 🎈全屏查看 open_in_new
请运用目前学到的所有知识,在上方嵌入的应用中进行实践。
尝试编辑单元格、新增行和删除行。
注意表格的编辑如何实时反映在Session State中。
任何编辑操作都会触发重新运行,将更改传至后端。
该组件的状态是一个包含三个属性的JSON对象:edited_rows (已编辑行)、added_rows (新增行)和deleted rows(删除行)。
警告
从 1.23.0 版本开始,当从 st.experimental_data_editor 迁移到 st.data_editor 时,数据编辑器在 st.session_state 中的表示方式发生了变化。
edited_cells 字典现在更名为 edited_rows,并采用了不同的格式(使用 {0: {"列名": "编辑后的值"}} 替代原先的 {"0:1": "编辑后的值"})。
如果您的应用同时使用 st.experimental_data_editor 和 st.session_state,可能需要调整代码逻辑。
edited_rows是一个包含所有编辑操作的字典。
键为从零开始的行索引,值为映射列名到编辑内容的字典(例如{0: {"col1": ..., "col2": ...}})。added_rows是一个存储新增行的列表。
每个元素的格式与上述相同(例如[{"col1": ..., "col2": ...}])。deleted_rows是一个记录被删除行号的列表(例如[0, 2])。
st.data_editor 不支持行重新排序功能,因此新增的行总是会附加到数据框末尾,所有编辑和删除操作仅适用于原始行。
批量编辑
数据编辑器提供了一项支持批量编辑单元格的功能。
与 Excel 类似,您可以通过拖拽选区手柄来批量修改单元格值。
您甚至可以使用电子表格软件中常见的键盘快捷键。
当您需要对多个单元格进行相同修改时,这一功能非常实用,无需逐个编辑单元格。
编辑常见数据结构
编辑功能不仅适用于 Pandas DataFrames!您还可以编辑列表、元组、集合、字典、NumPy 数组或 Snowpark 和 PySpark DataFrames。
大多数数据类型会以原始格式返回,但某些类型(如 Snowpark 和 PySpark)会被转换为 Pandas DataFrames。
要了解所有支持的类型,请阅读 st.data_editor API 文档。
例如,您可以轻松让用户向列表中添加项:
python
edited_list = st.data_editor(["red", "green", "blue"], num_rows= "dynamic")
st.write("Here are all the colors you entered:")
st.write(edited_list)或者 numpy 数组:
python
import numpy as np
st.data_editor(np.array([
["st.text_area", "widget", 4.92],
["st.markdown", "element", 47.22]
]))或者记录列表:
python
st.data_editor([
{"name": "st.text_area", "type": "widget"},
{"name": "st.markdown", "type": "element"},
])或者字典以及更多类型!
python
st.data_editor({
"st.text_area": "widget",
"st.markdown": "element"
})自动输入验证
数据编辑器内置了自动输入验证功能,可在编辑单元格时帮助防止错误。
例如,若某列包含数值型数据,输入字段将自动限制用户只能输入数值。
这能有效避免用户意外输入非数值内容导致的错误。
您可以通过列配置API配置更多输入验证规则。
下文将概述列配置选项(包括验证功能)的使用方法。
配置列
您可以通过列配置API来配置st.dataframe和st.data_editor中列的显示与编辑行为。
我们开发这个API的目的是让您能在数据框和数据编辑器列中添加图片、图表和可点击的URL链接。
此外,您还可以将单个列设为可编辑状态,将列指定为分类类型并定义其可选值,隐藏数据框的索引等等。
列配置支持以下列类型:文本(Text)、数字(Number)、复选框(Checkbox)、选择框(Selectbox)、日期(Date)、时间(Time)、日期时间(Datetime)、列表(List)、链接(Link)、图片(Image)、折线图(Line chart)、柱状图(Bar chart)和进度条(Progress)。
同时还提供通用列(Column)选项。
您可以通过下方嵌入的应用查看这些不同的列类型。
每种列类型的具体效果预览详见列配置API文档。
由Streamlit构建 🎈全屏查看 open_in_new
格式化数值
在文本列、日期列、时间列和日期时间列的列配置中,可以使用format参数。
图表类列也支持格式化。
折线图列和柱状图列具有y_min和y_max参数来设置垂直边界。
对于进度条列,可以通过min_value和max_value声明水平边界。
验证输入
在指定列配置时,不仅可以声明列的数据类型,还可以设置值限制。
所有列配置元素都允许通过关键字参数required=True将列设为必填项。
对于文本(Text)和链接(Link)列,可以通过max_chars指定最大字符数,或使用正则表达式通过validate验证输入内容。
数值类列(包括数字(Number)、日期(Date)、时间(Time)和日期时间(Datetime))具有min_value和max_value参数。
选择框(Selectbox)列可配置options列表。
数字(Number)列的数据类型默认为float。
若向min_value、max_value、step或default任一参数传递int类型的值,将把该列类型设为int。
配置空数据框
您可以使用 st.data_editor 从用户处收集表格输入。
当从空数据框开始时,默认列类型为文本。
通过列配置来指定您希望从用户收集的数据类型。
python
import streamlit as st
import pandas as pd
df = pd.DataFrame(columns=['name','age','color'])
colors = ['red', 'orange', 'yellow', 'green', 'blue', 'indigo', 'violet']
config = {
'name' : st.column_config.TextColumn('Full Name (required)', width='large', required=True),
'age' : st.column_config.NumberColumn('Age (years)', min_value=0, max_value=122),
'color' : st.column_config.SelectboxColumn('Favorite Color', options=colors)
}
result = st.data_editor(df, column_config = config, num_rows='dynamic')
if st.button('Get results'):
st.write(result)使用 Streamlit 构建 🎈全屏显示 open_in_new
额外格式化选项
除了列配置外,st.dataframe 和 st.data_editor 还提供了一些参数来自定义数据框的显示方式:
hide_index:设置为True可隐藏数据框的索引列。column_order:传入列标签列表以指定显示顺序。disabled:传入列标签列表以禁用这些列的编辑功能,避免逐个单独禁用。
处理大型数据集
得益于采用高性能的 glide-data-grid 库和 HTML Canvas 实现,st.dataframe 和 st.data_editor 理论上能够处理数百万行的表格。
但实际应用中,一个程序能处理的最大数据量还取决于以下因素:
-
WebSocket 消息大小限制 :通过
server.maxMessageSize配置选项 可调整 Streamlit 的 WebSocket 消息大小上限,这会限制单次通过 WebSocket 连接传输的数据量。 -
服务器内存 :程序能处理的数据量受服务器可用内存影响。
若超出内存容量,程序可能变慢或无响应。
-
用户浏览器内存 :由于所有数据都需传输至用户浏览器进行渲染,用户设备的可用内存也会影响程序性能。
若超出浏览器内存限制,可能导致崩溃或无响应。
除上述因素外,网络连接速度过慢也会显著拖慢处理大型数据集的程序性能。
当处理超过 15 万行的数据时,Streamlit 会自动启用额外优化措施(例如禁用列排序功能),以此减少单次需处理的数据量,从而提升程序性能。
限制说明
- Streamlit 在内部将所有列名转换为字符串,因此
st.data_editor返回的 DataFrame 中所有列名均为字符串类型。 - 当前数据表格工具栏不支持自定义配置。
- 虽然 Streamlit 的数据编辑功能提供了丰富的特性,但仅支持对有限列类型进行编辑(包括 TextColumn、NumberColumn、LinkColumn、CheckboxColumn、SelectboxColumn、DateColumn、TimeColumn 和 DatetimeColumn)。
我们正在积极扩展对其他列类型的编辑支持,例如图像、列表和图表等。 - 索引编辑支持几乎所有可编辑数据类型,但不支持编辑
pandas.CategoricalIndex和pandas.MultiIndex类型。 - 当
num_rows="dynamic"时,st.data_editor不支持排序功能。 - 对于超过 150,000 行的大型数据集,排序功能会被自动禁用以优化性能。
我们持续改进 Streamlit 对 DataFrame 的处理能力,并不断增强数据编辑功能,请密切关注更新动态。
Streamlit 中的多线程
https://docs.streamlit.io/develop/concepts/design/multithreading
多线程是一种并发技术,能提升计算机程序的运行效率。
它让处理器实现多任务处理。
Streamlit 在其架构内部使用了线程机制,这可能导致应用开发者难以集成自己的多线程流程。
虽然 Streamlit 官方不支持在应用代码中使用多线程,但本指南将介绍如何实现这一功能。
前提条件
- 您需要对 Streamlit 的架构有基本了解。
何时使用多线程
多线程只是并发的一种形式。
多进程和协程是其他类型的并发方式。
你需要分析代码的性能瓶颈,才能选择合适的并发方案。
多进程天生具有并行性,意味着资源被分割后可以同时执行多个任务。
因此,多进程适合计算密集型操作。
相比之下,多线程和协程本身不具备并行性,而是通过资源切换实现的并发。
这使得它们特别适合代码因等待 某些操作(如IO操作)而阻塞的场景。
对于非常缓慢的IO操作,使用协程的AsyncIO可能是更好的选择;而对于较快的IO操作,多线程可能更合适。
关于如何在Streamlit中使用AsyncIO,可以参考Sehmi-Conscious Thoughts在Medium上的文章。
别忘了Streamlit还提供片段和缓存功能!通过缓存可以避免重复执行不必要的计算或IO操作。
使用片段可以将需要独立更新的代码部分与应用其他部分隔离,并可以设置定时重新运行片段,从而实现图表或表格的实时流式更新。
(注:所有技术术语、代码片段、链接均按核心翻译原则保留原格式)
Streamlit 创建的线程
Streamlit 在 Python 中会创建两种类型的线程:
- 服务器线程:运行 Tornado web(HTTP + WebSocket)服务器。
- 脚本线程:运行页面代码------每个会话中运行的脚本都会对应一个线程。
当用户连接到你的应用时,会创建一个新会话并启动一个脚本线程来为该用户初始化应用。
脚本线程运行时会渲染用户浏览器标签页中的元素,并将状态报告回服务器。
当用户与应用交互时,另一个脚本线程会运行,重新渲染浏览器标签页中的元素并更新服务器上的状态。
以下是一个简化示意图,展示 Streamlit 的工作原理:
)
streamlit.errors.NoSessionContext
许多 Streamlit 命令(包括 st.session_state)预期在脚本线程中被调用。
当 Streamlit 正常运行时,这些命令会使用附加到脚本线程的 ScriptRunContext,以确保它们在预期的会话中工作,并更新正确的用户视图。
当这些 Streamlit 命令无法找到任何 ScriptRunContext 时,它们会抛出 streamlit.errors.NoSessionContext 异常。
根据日志设置,你可能还会在控制台看到一条消息,通过线程名称标识并警告:"缺少 ScriptRunContext!"
创建自定义线程
在处理远程查询或数据加载等IO密集型操作时,你可能需要缓解延迟问题。
通用的编程策略是创建线程并让它们并发工作。
然而,如果在Streamlit应用中这样做,这些自定义线程可能会难以与Streamlit服务器进行交互。
本节介绍两种模式,让你可以在Streamlit应用中创建自定义线程。
这些模式仅作为起点提供,而非完整的解决方案。
选项一:不在自定义线程中使用 Streamlit 命令
如果不在自定义线程中调用 Streamlit 命令,就可以完全避免这个问题。
幸运的是,Python 的线程机制提供了从其他线程启动线程并收集其结果的解决方案。
在下面的示例中,脚本线程创建了五个自定义线程。
当这些线程运行结束后,它们的结果会在应用中显示。
python
import streamlit as st
import time
from threading import Thread
class WorkerThread(Thread):
def __init__(self, delay):
super().__init__()
self.delay = delay
self.return_value = None
def run(self):
start_time = time.time()
time.sleep(self.delay)
end_time = time.time()
self.return_value = f"start: {start_time}, end: {end_time}"
delays = [5, 4, 3, 2, 1]
threads = [WorkerThread(delay) for delay in delays]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
for i, thread in enumerate(threads):
st.header(f"Thread {i}")
st.write(thread.return_value)
st.button("Rerun")使用 Streamlit 构建 🎈全屏打开 open_in_new
若要在应用中显示多个自定义线程运行完成后的结果,可使用容器组件。
以下示例创建了五个自定义线程,其方式与前例类似。
但在运行这些线程之前,我们先初始化了五个容器,并通过while循环实时显示各线程的可用结果。
由于 Streamlit 的write命令是在自定义线程外部调用的,因此不会引发异常。
python
import streamlit as st
import time
from threading import Thread
class WorkerThread(Thread):
def __init__(self, delay):
super().__init__()
self.delay = delay
self.return_value = None
def run(self):
start_time = time.time()
time.sleep(self.delay)
end_time = time.time()
self.return_value = f"start: {start_time}, end: {end_time}"
delays = [5, 4, 3, 2, 1]
result_containers = []
for i, delay in enumerate(delays):
st.header(f"Thread {i}")
result_containers.append(st.container())
threads = [WorkerThread(delay) for delay in delays]
for thread in threads:
thread.start()
thread_lives = [True] * len(threads)
while any(thread_lives):
for i, thread in enumerate(threads):
if thread_lives[i] and not thread.is_alive():
result_containers[i].write(thread.return_value)
thread_lives[i] = False
time.sleep(0.5)
for thread in threads:
thread.join()
st.button("Rerun")基于 Streamlit 构建 🎈全屏显示 open_in_new
选项2:将 ScriptRunContext 暴露给线程
如果需要在自定义线程中调用 Streamlit 命令,必须为该线程附加正确的 ScriptRunContext。
警告
- 此功能未获官方支持,可能在Streamlit的未来版本中发生变更。
- 并非所有Streamlit命令都能兼容此功能。
- 请确保自定义线程不会比持有
ScriptRunContext的脚本线程存活更久。
若ScriptRunContext发生泄漏,可能导致安全漏洞、致命错误或意外行为。
在以下示例中,附加了ScriptRunContext的自定义线程可以无警告地调用st.write。
python
import streamlit as st
from streamlit.runtime.scriptrunner import add_script_run_ctx, get_script_run_ctx
import time
from threading import Thread
class WorkerThread(Thread):
def __init__(self, delay, target):
super().__init__()
self.delay = delay
self.target = target
def run(self):
# runs in custom thread, but can call Streamlit APIs
start_time = time.time()
time.sleep(self.delay)
end_time = time.time()
self.target.write(f"start: {start_time}, end: {end_time}")
delays = [5, 4, 3, 2, 1]
result_containers = []
for i, delay in enumerate(delays):
st.header(f"Thread {i}")
result_containers.append(st.container())
threads = [
WorkerThread(delay, container)
for delay, container in zip(delays, result_containers)
]
for thread in threads:
add_script_run_ctx(thread, get_script_run_ctx())
thread.start()
for thread in threads:
thread.join()
st.button("Rerun")由Streamlit构建 🎈全屏显示 open_in_new
在 Streamlit 应用中使用自定义 Python 类
https://docs.streamlit.io/develop/concepts/design/custom-classes
当您构建复杂的 Streamlit 应用或处理现有代码时,可能会在脚本中定义自定义 Python 类。
常见示例如下:
- 使用
@dataclass在应用中存储关联数据 - 定义
Enum类来表示固定的选项或值集合 - 为
st.connection未涵盖的外部服务或数据库创建自定义接口
由于 Streamlit 会在每次用户交互后重新运行脚本,自定义类可能在同一个 Streamlit 会话中被多次重新定义。
这可能导致意外效果,特别是在类和实例比较时。
继续阅读以了解这个常见陷阱及其规避方法。
我们将首先介绍适用于不同类型自定义类的通用模式,随后解释相关技术细节说明其重要性。
最后,我们会专门深入探讨使用 Enum 类的情况,并介绍一个使其更便捷的配置选项。
定义自定义类的模式
模式1:在单独模块中定义类
这是推荐且通用的解决方案。
如果可能,请将类定义移至独立的模块文件中,并在应用脚本中导入它们。
只要你不编辑定义应用的源文件,Streamlit 就不会在每次重新运行时重复导入这些类。
因此,若类定义在外部文件中并被导入脚本,除非你正在主动修改应用,否则该类在会话期间不会被重复定义。
示例:移动类定义的位置
尝试运行以下 Streamlit 应用,其中 MyClass 被定义在页面脚本内。
首次运行脚本时 isinstance() 会返回 True,但之后每次重新运行时都会返回 False。
python
# app.py
import streamlit as st
# MyClass gets redefined every time app.py reruns
class MyClass:
def __init__(self, var1, var2):
self.var1 = var1
self.var2 = var2
if "my_instance" not in st.session_state:
st.session_state.my_instance = MyClass("foo", "bar")
# Displays True on the first run then False on every rerun
st.write(isinstance(st.session_state.my_instance, MyClass))
st.button("Rerun")如果将类定义从 app.py 移到另一个文件中,可以让 isinstance() 始终返回 True。
参考以下文件结构:
shell
myproject/
├── my_class.py
└── app.py# my_class.py
class MyClass:
def __init__(self, var1, var2):
self.var1 = var1
self.var2 = var2
python
# app.py
import streamlit as st
from my_class import MyClass # MyClass doesn't get redefined with each rerun
if "my_instance" not in st.session_state:
st.session_state.my_instance = MyClass("foo", "bar")
# Displays True on every rerun
st.write(isinstance(st.session_state.my_instance, MyClass))
st.button("Rerun")Streamlit 仅在检测到代码变更时才会重新加载导入模块中的代码。
因此,如果您正在积极编辑应用代码,可能需要启动新会话或重启 Streamlit 服务器,以避免出现意外的类重定义问题。
模式2:强制类比较内部值
对于存储数据的类(如数据类),你可能更关注比较内部存储的值而非类本身。
通过定义自定义的__eq__方法,可以强制在内部存储值之间进行比较。
示例:定义 __eq__
尝试运行以下 Streamlit 应用,观察比较结果在首次运行时为 True,而在之后的每次重新运行时变为 False。
python
import streamlit as st
from dataclasses import dataclass
@dataclass
class MyDataclass:
var1: int
var2: float
if "my_dataclass" not in st.session_state:
st.session_state.my_dataclass = MyDataclass(1, 5.5)
# Displays True on the first run the False on every rerun
st.session_state.my_dataclass == MyDataclass(1, 5.5)
st.button("Rerun")由于每次重新运行都会重新定义MyDataclass,存储在Session State中的实例将不等于后续脚本运行中定义的任何实例。
您可以通过强制比较内部值来解决此问题,方法如下:
python
import streamlit as st
from dataclasses import dataclass
@dataclass
class MyDataclass:
var1: int
var2: float
def __eq__(self, other):
# An instance of MyDataclass is equal to another object if the object
# contains the same fields with the same values
return (self.var1, self.var2) == (other.var1, other.var2)
if "my_dataclass" not in st.session_state:
st.session_state.my_dataclass = MyDataclass(1, 5.5)
# Displays True on every rerun
st.session_state.my_dataclass == MyDataclass(1, 5.5)
st.button("Rerun")常规类或@dataclass的默认Python __eq__实现依赖于类或类实例的内存ID。
为避免Streamlit中的问题,自定义的__eq__方法不应依赖于self和other的type()。
模式3:将类存储为序列化数据
对于存储数据的类,另一种选择是定义序列化和反序列化方法,如to_str和from_str。
通过这些方法,你可以将类实例数据存储在st.session_state中,而不是直接存储类实例本身。
与模式2类似,这是一种强制比较内部数据并绕过内存ID变化的方式。
示例:将类实例保存为字符串
沿用模式2中的相同示例,可按如下方式实现:
python
import streamlit as st
from dataclasses import dataclass
@dataclass
class MyDataclass:
var1: int
var2: float
def to_str(self):
return f"{self.var1},{self.var2}"
@classmethod
def from_str(cls, serial_str):
values = serial_str.split(",")
var1 = int(values[0])
var2 = float(values[1])
return cls(var1, var2)
if "my_dataclass" not in st.session_state:
st.session_state.my_dataclass = MyDataclass(1, 5.5).to_str()
# Displays True on every rerun
MyDataclass.from_str(st.session_state.my_dataclass) == MyDataclass(1, 5.5)
st.button("Rerun")模式4:利用缓存保持类状态
对于作为资源使用的类(如数据库连接、状态管理器、API接口),建议采用缓存单例模式。
通过@st.cache_resource装饰器修饰类的@staticmethod方法,即可生成一个被缓存的类单例。
例如:
python
import streamlit as st
class MyResource:
def __init__(self, api_url: str):
self._url = api_url
@st.cache_resource(ttl=300)
@staticmethod
def get_resource_manager(api_url: str):
return MyResource(api_url)
# This is cached until Session State is cleared or 5 minutes has elapsed.
resource_manager = MyResource.get_resource_manager("http://example.com/api/")当你对函数使用 Streamlit 的缓存装饰器时,Streamlit 不会通过函数对象来查找缓存值。
相反,Streamlit 的缓存装饰器会使用函数的限定名称和模块来索引返回值。
因此,尽管每次运行脚本时 Streamlit 都会重新定义 MyResource,但这不会影响 st.cache_resource。
每次重新运行时,get_resource_manager() 都会返回其缓存值,直到该值过期为止。
理解Python如何定义和比较类
那么这里到底发生了什么?我们将通过一个简单的例子来说明为什么这是一个陷阱。
如果你不想深入细节,可以跳过本节,直接学习如何使用Enum类。
示例:当重复定义同一个类时会发生什么?
暂时抛开 Streamlit,思考下面这个简单的 Python 脚本:
python
from dataclasses import dataclass
@dataclass
class Student:
student_id: int
name: str
Marshall_A = Student(1, "Marshall")
Marshall_B = Student(1, "Marshall")
# This is True (because a dataclass will compare two of its instances by value)
Marshall_A == Marshall_B
# Redefine the class
@dataclass
class Student:
student_id: int
name: str
Marshall_C = Student(1, "Marshall")
# This is False
Marshall_A == Marshall_C在这个示例中,Student数据类被定义了两次。
三个Marshall实例都拥有相同的内部值。
如果你比较Marshall_A和Marshall_B,它们会是相等的,因为两者都是基于第一个Student定义创建的。
然而,比较Marshall_A和Marshall_C时则会不相等,因为Marshall_C是基于第二个 Student定义创建的。
尽管两个Student数据类的定义完全一致,但它们在内存中的ID不同,因此被视为不同的实例。
Streamlit 中发生了什么?
在 Streamlit 中,你可能不会在页面脚本中重复编写相同的类。
然而,Streamlit 的重新运行逻辑会产生相同的效果。
让我们用上面的例子来类比。
如果你在一次脚本运行中定义了一个类,并将实例保存在 Session State 中,那么后续的重新运行会重新定义该类,最终可能导致你将重新运行中的 Mashall_C 与 Session State 中的 Marshall_A 进行比较。
由于组件底层依赖于 Session State,这里就容易产生混淆。
Streamlit 组件如何存储选项
多个 Streamlit UI 元素(如 st.selectbox 或 st.radio)通过 options 参数接收多项选择选项。
应用程序用户通常可以选择其中一个或多个选项。
选中的值会由组件函数返回。
例如:
python
number = st.selectbox("Pick a number, any number", options=[1, 2, 3])
# number == whatever value the user has selected from the UI.当你调用类似 st.selectbox 的函数并向 options 传递一个 Iterable 时,该 Iterable 和当前选择会被保存到 Session State 的一个隐藏部分,称为 Widget Metadata。
当应用程序用户与 st.selectbox 小部件交互时,浏览器会将其选择的索引发送到 Streamlit 服务器。
该索引用于确定从原始 options 列表中返回哪些值到你的应用程序,这些值 保存在前一次页面执行时的 Widget Metadata 中。
关键细节在于,st.selectbox(或类似的小部件函数)返回的值来自 前一次 页面执行时保存在 Session State 中的 Iterable,而不是 当前 执行时传递给 options 的值。
Streamlit 这样设计有许多架构上的原因,这里不展开讨论。
然而,正是 这种方式导致了我们认为在比较同一类的实例时,实际上却在比较不同类的实例。
一个极端案例
上面的解释可能有些令人困惑,因此这里用一个极端案例来说明这个概念。
python
import streamlit as st
from dataclasses import dataclass
@dataclass
class Student:
student_id: int
name: str
Marshall_A = Student(1, "Marshall")
if "B" not in st.session_state:
st.session_state.B = Student(1, "Marshall")
Marshall_B = st.session_state.B
options = [Marshall_A,Marshall_B]
selected = st.selectbox("Pick", options)
# This comparison does not return expected results:
selected == Marshall_A
# This comparison evaluates as expected:
selected == Marshall_B最后需要说明的是,我们在本节示例中使用了 @dataclass 来阐述观点,但实际上这些相同的问题也可能出现在普通类中。
任何在比较运算符(如 __eq__ 或 __gt__)内部检查类身份的类都可能表现出这些问题。
在 Streamlit 中使用 Enum 类
Python 标准库中的 Enum 类是一种强大的方式,可用于定义自定义符号名称,这些名称可以作为选项用于 st.multiselect 或 st.selectbox,以替代 str 值。
例如,您可以在 Streamlit 页面中添加以下内容:
python
from enum import Enum
import streamlit as st
# class syntax
class Color(Enum):
RED = 1
GREEN = 2
BLUE = 3
selected_colors = set(st.multiselect("Pick colors", options=Color))
if selected_colors == {Color.RED, Color.GREEN}:
st.write("Hooray, you found the color YELLOW!")如果您使用的是最新版本的 Streamlit,这个 Streamlit 页面会如预期般工作。
当用户同时选择 Color.RED 和 Color.GREEN 时,他们将看到特殊消息。
不过,如果您仔细阅读了本页其他内容,可能会发现一个微妙的问题。
具体来说,每次运行此脚本时,Enum 类 Color 都会被重新定义。
在 Python 中,即使两个 Enum 类具有相同的类名、成员和值,它们及其成员仍被视为彼此独立的对象。
这理论上 会导致上述 if 条件始终判定为 False ------ 因为在脚本重新运行时,st.multiselect 返回的 Color 值将与当前脚本运行中定义的 Color 属于不同的类。
如果您在 Streamlit 1.28.0 或更早版本中运行上述代码片段,将无法看到特殊消息。
值得庆幸的是,从 1.29.0 版本开始,Streamlit 引入了一个配置选项来大幅简化此问题,这就是默认启用的 enumCoercion 配置选项。
理解 enumCoercion 配置选项
当启用 enumCoercion 时,Streamlit 会尝试识别你是否在使用像 st.multiselect 或 st.selectbox 这样的元素,并将一组 Enum 成员作为选项。
如果 Streamlit 检测到这种情况,它会将小部件返回的值转换为最新脚本运行中定义的 Enum 类的成员。
我们称之为自动 Enum 强制转换。
此行为可以通过 Streamlit config.toml 文件中的 enumCoercion 设置进行配置。
默认情况下是启用的,也可以禁用或设置为更严格的匹配条件。
如果你发现启用 enumCoercion 后仍然遇到问题,可以考虑使用上述的自定义类模式,例如将 Enum 类定义移动到单独的模块文件中。
处理时区问题
https://docs.streamlit.io/develop/concepts/design/timezone-handling
通常来说,处理时区可能会很棘手。
您的Streamlit应用用户所处的时区,与运行应用的服务器时区未必相同。
对于公开应用尤其如此------全球任何时区的用户都可能访问您的应用。
因此,理解Streamlit如何处理时区至关重要,这样在显示datetime信息时才能避免意外行为。
Streamlit 如何处理时区问题
Streamlit 始终在前端显示与后端对应的 datetime 实例相同的时间信息。
也就是说,日期或时间信息不会自动适应用户的时区。
我们区分以下两种情况:
不带时区的 datetime 实例(原生)
当你提供一个未指定时区 的 datetime 实例时,前端会显示不带时区信息的 datetime 实例。
例如(这也适用于其他小部件,如 st.dataframe):
python
import streamlit as st
from datetime import datetime
st.write(datetime(2020, 1, 10, 10, 30))
# Outputs: 2020-01-10 10:30:00上述应用程序的用户始终看到输出为 2020-01-10 10:30:00。
带有时区的 datetime 实例
当你提供一个 datetime 实例并指定时区 时,前端会在同一时区显示该 datetime 实例。
例如(这也适用于其他组件如 st.dataframe):
python
import streamlit as st
from datetime import datetime
import pytz
st.write(datetime(2020, 1, 10, 10, 30, tzinfo=pytz.timezone("EST")))
# Outputs: 2020-01-10 10:30:00-05:00上述应用程序的用户始终看到输出为 2020-01-10 10:30:00-05:00。
在这两种情况下,前端既不会自动调整日期信息,也不会自动调整时间信息以适应用户的时区。
用户看到的内容与后端对应的 datetime 实例完全一致。
目前无法自动将日期或时间信息调整为查看应用程序的用户所在时区。
注意
旧版 st.dataframe 存在时区处理问题。
我们不再计划为旧版数据框提供额外的修复或功能增强。
如需稳定的时区支持,建议通过修改配置设置切换至箭头序列化模式:config.dataFrameSerialization = "arrow"。
处理连接、密钥与用户认证
连接数据
将您的应用连接到远程数据或第三方 API。
https://docs.streamlit.io/develop/concepts/connections/connecting-to-data
密钥管理
配置您的开发环境并设计应用程序以安全地处理密钥。
https://docs.streamlit.io/develop/concepts/connections/secrets-management
认证与用户信息
通过 OpenID Connect 提供商进行用户认证,为您的应用实现个性化功能。
安全提醒
查看以下注意事项,遵循最佳实践并避免安全错误。
https://docs.streamlit.io/develop/concepts/connections/security-reminders
连接数据源
大多数Streamlit应用都需要访问某种数据或API才能发挥作用------无论是检索数据供查看,还是保存用户操作的结果。
这些数据或API通常来自远程服务、数据库或其他数据源。
凡是能用Python实现的功能(包括数据连接)通常都能在Streamlit中运行 。
Streamlit的教程是了解多种数据源的绝佳起点。
但需要注意:
- 在Python应用中连接数据往往繁琐且令人困扰
- 从Streamlit应用连接数据时需特别注意缓存和密钥管理等事项
Streamlit提供了st.connection()功能,只需几行代码就能轻松将应用连接到数据和API 。
本页首先展示该功能的基础用法示例,然后重点介绍高级用法。
要全面了解此功能,请观看Streamlit开发者体验产品经理Joshua Carroll的视频教程。
通过实际案例,您将学习如何在应用中创建和管理数据连接。
基础用法
关于基础启动和使用示例,请参阅相关的数据源教程。
Streamlit 内置支持 SQL 方言和 Snowflake 的连接。
我们还维护了可安装的连接组件,用于云文件存储和Google Sheets。
如果你是初学者,最佳学习方式是选择一个可访问的数据源,并通过上述页面👆中的最小示例开始实践。
这里我们将提供一个使用 SQLite 数据库的超简示例。
之后,本页将重点介绍高级用法。
一个简单的起点------使用本地SQLite数据库
本地SQLite数据库可以用于应用程序的半持久化数据存储。
注意
社区云应用不保证本地文件存储的持久性,因此平台可能随时删除使用此技术存储的数据。
要查看下方示例的实时运行效果,请查看以下交互式演示:
步骤 1:安装必备库 - SQLAlchemy
Streamlit 中的所有 SQLConnections 都使用 SQLAlchemy。
对于大多数其他 SQL 方言,您还需要安装驱动程序。
但 SQLite 驱动已随 python3 内置,因此无需额外安装。
pip install SQLAlchemy==1.4.0
步骤2:在Streamlit的secrets.toml文件中设置数据库URL
在运行应用的同一目录下创建.streamlit/secrets.toml目录和文件。
将以下内容添加到该文件中。
# .streamlit/secrets.toml
[connections.pets_db]
url = "sqlite:///pets.db"步骤3:在应用中使用连接
以下应用会创建一个数据库连接,利用该连接创建表并插入数据,然后查询数据并以数据框形式展示结果。
python
# streamlit_app.py
import streamlit as st
# Create the SQL connection to pets_db as specified in your secrets file.
conn = st.connection('pets_db', type='sql')
# Insert some data with conn.session.
with conn.session as s:
s.execute('CREATE TABLE IF NOT EXISTS pet_owners (person TEXT, pet TEXT);')
s.execute('DELETE FROM pet_owners;')
pet_owners = {'jerry': 'fish', 'barbara': 'cat', 'alex': 'puppy'}
for k in pet_owners:
s.execute(
'INSERT INTO pet_owners (person, pet) VALUES (:owner, :pet);',
params=dict(owner=k, pet=pet_owners[k])
)
s.commit()
# Query and display the data you inserted
pet_owners = conn.query('select * from pet_owners')
st.dataframe(pet_owners)在这个示例中,我们没有在调用 conn.query() 时设置 ttl= 值,这意味着只要应用服务器运行,Streamlit 就会无限期缓存结果。
现在,让我们进入更高级的主题!🚀
高级主题
全局密钥管理:多应用与多数据存储场景
Streamlit 支持通过全局密钥文件管理配置,该文件通常位于用户主目录下(例如~/.streamlit/secrets.toml)。
如果您需要构建或管理多个应用,我们建议在本地开发时使用全局凭证或密钥文件。
这种方法只需在一处设置和管理凭证,将新应用连接到现有数据源仅需一行代码即可实现。
同时,由于凭证无需存放在项目仓库中,也降低了意外提交至Git的风险。
当本地开发中需要连接多个相似数据源时(例如本地环境与预发布环境的数据库),您可以在密钥或凭证文件中为不同环境定义独立的连接配置区块,并在运行时动态选择。
st.connection通过*name=env:<MY_NAME_VARIABLE>*语法支持此功能。
例如,假设我需要交替连接本地MySQL数据库和预发布环境数据库,可以创建如下全局密钥文件:
# ~/.streamlit/secrets.toml
[connections.local]
url = "mysql://me:****@localhost:3306/local_db"
[connections.staging]
url = "mysql://jdoe:******@staging.acmecorp.com:3306/staging_db"然后我可以配置应用连接,使其名称从指定的环境变量中获取
python
# streamlit_app.py
import streamlit as st
conn = st.connection("env:DB_CONN", "sql")
df = conn.query("select * from mytable")
# ...现在,我可以通过设置 DB_CONN 环境变量来指定在运行时连接到本地还是预发布环境。
# connect to local
DB_CONN=local streamlit run streamlit_app.py
# connect to staging
DB_CONN=staging streamlit run streamlit_app.py高级 SQLConnection 配置
SQLConnection 配置使用 SQLAlchemy 的 create_engine() 函数。
该函数可接受单个 URL 参数,或尝试通过 SQLAlchemy.engine.URL.create() 从多个部分(如用户名、数据库、主机等)构建 URL。
除了 URL 外,许多流行的 SQLAlchemy 方言(如 Snowflake 和 Google BigQuery)可通过向 create_engine() 传递额外参数进行配置。
这些参数可直接作为 **kwargs 传递给 st.connection 调用,或在名为 create_engine_kwargs 的额外 secrets 部分中指定。
例如,snowflake-sqlalchemy 接受一个额外的 connect_args 字典参数,用于配置 URL 不支持的选项。
具体配置方式如下:
# .streamlit/secrets.toml
[connections.snowflake]
url = "snowflake://<user_login_name>@<account_identifier>/"
[connections.snowflake.create_engine_kwargs.connect_args]
authenticator = "externalbrowser"
warehouse = "xxx"
role = "xxx"
python
# streamlit_app.py
import streamlit as st
# url and connect_args from secrets.toml above are picked up and used here
conn = st.connection("snowflake", "sql")
# ...或者,这也可以完全在 **kwargs 中指定。
python
# streamlit_app.py
import streamlit as st
# secrets.toml is not needed
conn = st.connection(
"snowflake",
"sql",
url = "snowflake://<user_login_name>@<account_identifier>/",
connect_args = dict(
authenticator = "externalbrowser",
warehouse = "xxx",
role = "xxx",
)
)
# ...您还可以同时提供 kwargs 和 secrets.toml 值,它们将被合并(通常 kwargs 具有更高优先级)。
频繁使用或长时间运行应用中的连接注意事项
默认情况下,连接对象会通过 st.cache_resource 进行无过期时间的缓存。
这在大多数情况下是符合预期的。
如果你希望连接对象在一段时间后过期,可以使用 st.connection('myconn', type=MyConnection, ttl=<N>) 来设置。
许多连接类型设计为长期运行或完全无状态的,因此不需要设置过期时间。
假设某个连接变得陈旧(例如缓存的令牌过期或服务器端连接被关闭),每个连接都提供了一个 reset() 方法,该方法会使缓存的版本失效,并导致 Streamlit 在下次获取连接时重新创建它。
像 query() 和 read() 这样的便捷方法通常会默认使用 st.cache_data 缓存结果,且不设置过期时间。
当应用执行大量不同的读取操作并产生较大结果时,可能会导致内存使用量随时间增加,并且在长时间运行的应用中结果变得陈旧,这与 st.cache_data 的其他使用情况类似。
对于生产环境,我们建议在这些读取操作上设置适当的 ttl,例如 conn.read('path/to/file', ttl="1d")。
更多信息请参考缓存。
对于可能面临高并发使用的应用,请确保你理解连接的任何线程安全影响,尤其是在使用第三方构建的连接时。
由 Streamlit 构建的连接默认应提供线程安全的操作。
构建自定义连接
在大多数情况下,使用现有驱动或SDK实现基础连接功能相当简单。
通过进一步开发,您还可以添加更复杂的功能。
这种自定义实现是扩展对新数据源支持的绝佳方式,同时能为Streamlit生态系统贡献力量。
对于频繁使用特定访问模式和数据源的组织而言,维护一个定制化的内部Connection实现能显著提升开发效率。
请查看下方st.experimental_connection演示应用中的构建自定义连接页面,获取快速教程和可运行示例。
该演示基于DuckDB构建了一个最小化但功能完备的Connection实现。
由Streamlit构建 🎈全屏打开 open_in_new
典型实现步骤如下:
- 声明Connection类,通过类型参数绑定底层连接对象来扩展
ExperimentalBaseConnection:
python
from streamlit.connections import ExperimentalBaseConnection
import duckdb
class DuckDBConnection(ExperimentalBaseConnection[duckdb.DuckDBPyConnection])2、实现 _connect 方法,该方法读取所有 kwargs 参数、外部配置/凭证位置以及 Streamlit 密钥,用于初始化底层连接:
python
def _connect(self, **kwargs) -> duckdb.DuckDBPyConnection:
if 'database' in kwargs:
db = kwargs.pop('database')
else:
db = self._secrets['database']
return duckdb.connect(database=db, **kwargs)3、添加对连接有意义的实用辅助方法(在需要缓存的地方用st.cache_data包装它们)
连接构建最佳实践
我们建议遵循以下最佳实践,以确保您的 Connection 与 Streamlit 内置及更广泛生态中的 Connections 保持一致。
这些实践对于计划公开分发的 Connections 尤为重要。
1、扩展现有驱动或 SDK,并采用符合其现有用户习惯的默认语义
构建 Connection 时,很少需要从头实现复杂的数据访问逻辑。
尽可能使用现有的流行 Python 驱动和客户端。
这样做能使您的 Connection 更易维护、更安全,并让用户获得最新功能。
例如:SQLConnection 扩展自 SQLAlchemy,FileConnection 扩展自 fsspec,GsheetsConnection 扩展自 gspread 等。
建议采用与底层包一致的访问模式、方法/参数命名及返回值,这些应被该包的现有用户所熟悉。
2、直观易用的读取方法
st.connection 的核心优势在于提供直观易用的读取方法,帮助应用开发者快速上手。
大多数 Connection 应至少暴露一个具备以下特性的读取方法:
- 使用简单动词命名,如
read()、query()或get() - 默认由
st.cache_data包装,至少支持ttl=参数 - 若结果为表格形式,返回 pandas DataFrame
- 提供常用关键字参数(如分页或格式化)并设置合理默认值------理想情况下,常见场景只需 1-2 个参数
3、_connect 方法中的配置、密钥与优先级
每个 Connection 都应支持通过 Streamlit secrets 和关键字参数提供的常用连接参数,其名称应与初始化或配置底层包时使用的名称一致。
此外,在适用情况下,Connection 应支持通过现有标准环境变量或配置文件/凭证文件进行数据源特定配置。
多数情况下,底层包已提供可轻松处理此事的构造函数或工厂函数。
当同一连接参数可通过多种方式指定时,建议尽可能遵循以下优先级顺序(从高到低):
* 代码中指定的关键字参数
* Streamlit secrets
* 数据源特定配置(如适用)4、处理线程安全与陈旧连接
Connection 应在可行时(大多数情况下)提供线程安全操作,并明确记录相关注意事项。
大多数底层驱动或 SDK 应提供线程安全对象或方法------尽可能使用这些。
如果底层驱动或 SDK 存在状态化连接对象变陈旧或失效的风险,考虑在访问方法中内置低开销的健康检查或重置/重试机制。
Streamlit 内置的 SQLConnection 通过 tenacity 和内置的 Connection.reset() 方法提供了良好范例。
另一种方法是建议开发者在 st.connection() 调用上设置适当的 TTL,以确保定期重新初始化连接对象。
密钥管理
将未加密的密钥存储在git仓库中是一种不良实践。
对于需要访问敏感凭证的应用程序,推荐解决方案是将这些凭证存储在仓库之外------例如使用未提交到仓库的凭证文件,或通过环境变量传递它们。
Streamlit 提供了基于文件的原生密钥管理功能,可以轻松存储并安全地访问 Streamlit 应用中的密钥。
注意
现有的密钥管理工具(如 dotenv 文件、AWS 凭证文件、Google Cloud Secret Manager 或 Hashicorp Vault)在 Streamlit 中均可正常使用。
我们仅针对特定场景提供了原生的密钥管理功能以增强便利性。
如何使用密钥管理
本地开发与密钥配置
Streamlit 提供了两种使用 TOML 格式在本地设置密钥的方式:
1、通过 全局密钥文件:
-
macOS/Linux 系统路径为
~/.streamlit/secrets.toml -
Windows 系统路径为
%userprofile%/.streamlit/secrets.tomlEverything in this section will be available as an environment variable
db_username = "Jane"
db_password = "mypassword"You can also add other sections if you like.
The contents of sections as shown below will not become environment variables,
but they'll be easily accessible from within Streamlit anyway as we show
later in this doc.
[my_other_secrets]
things_i_like = ["Streamlit", "Python"]
如果使用全局密钥文件,当多个Streamlit应用共享相同密钥时,无需在各个项目级文件中重复配置密钥。
2、在项目级密钥文件$CWD/.streamlit/secrets.toml中($CWD表示运行Streamlit的目录)。
若全局密钥文件与项目级密钥文件同时存在,项目级文件中的密钥会覆盖全局文件中定义的密钥。
重要提示
将此文件添加到你的 .gitignore 中,以免提交你的敏感信息!
在应用中使用密钥
通过查询 st.secrets 字典或环境变量来访问你的密钥。
例如,如果你输入了上一节中的密钥,以下代码展示了如何在 Streamlit 应用中访问它们。
python
import streamlit as st
# Everything is accessible via the st.secrets dict:
st.write("DB username:", st.secrets["db_username"])
st.write("DB password:", st.secrets["db_password"])
# And the root-level secrets are also accessible as environment variables:
import os
st.write(
"Has environment variables been set:",
os.environ["db_username"] == st.secrets["db_username"],
)提示
除了使用键值表示法(如 st.secrets["key"])外,你还可以通过属性表示法(如 st.secrets.key)访问 st.secrets ------ 类似于 st.session_state 的使用方式。
你甚至可以利用 TOML 区块简洁地将多个密钥作为单个属性传递。
参考以下密钥配置:
yaml
[db_credentials]
username = "my_username"
password = "my_password"相比将每个密钥作为函数属性传递,您可以通过更简洁的方式传递整个部分来实现相同效果。
请参考以下概念性代码示例,它使用了上述密钥:
# Verbose version
my_db.connect(username=st.secrets.db_credentials.username, password=st.secrets.db_credentials.password)
# Far more compact version!
my_db.connect(**st.secrets.db_credentials)错误处理
以下是使用密钥管理时可能遇到的常见错误:
- 如果在应用运行时创建了
.streamlit/secrets.toml文件,需要重启服务器才能使更改在应用中生效。 - 当尝试访问密钥但不存在
secrets.toml文件时,Streamlit会抛出FileNotFoundError异常:

- 当尝试访问不存在的密钥时,Streamlit会抛出
KeyError异常:
python
import streamlit as st
st.write(st.secrets["nonexistent_key"])
在 Streamlit Community Cloud 上使用密钥
当你将应用部署到 Streamlit Community Cloud 时,可以使用与本地相同的密钥管理工作流。
不过,你还需要在 Community Cloud 的密钥管理控制台中设置密钥。
具体操作方法请参阅云服务专属的 密钥管理 文档。
用户认证与信息
https://docs.streamlit.io/develop/concepts/connections/authentication
为用户个性化定制应用是提升应用吸引力的有效方式。
用户认证与个性化功能为开发者开启了众多应用场景,包括管理员控制面板、个性化股票行情展示,或是能保存会话间聊天记录的聊天机器人应用。
在阅读本指南前,您应当已掌握密钥管理的基础知识。
OpenID Connect
Streamlit 支持通过 OpenID Connect (OIDC) 进行用户身份验证,这是一种基于 OAuth 2.0 构建的认证协议。
OIDC 仅支持身份验证(authentication),而不支持授权(authorization):也就是说,OIDC 连接会告诉你用户是谁 (身份验证),但不会授予你模拟 他们的权限(授权)。
如果需要连接通用的 OAuth 2.0 提供商,或让应用代表用户执行操作,可以考虑使用或创建自定义组件。
一些流行的 OIDC 提供商包括:
st.login()、st.user 和 st.logout()
用户认证涉及三个命令:
st.login()将用户重定向至身份提供方。
登录后,Streamlit 会存储身份验证 cookie,并在新会话中将用户重定向回应用首页。st.user是一个类字典对象,用于访问用户信息。
它包含持久性属性.is_logged_in,可检查用户登录状态。
用户登录后,根据身份提供方的配置,还可访问其他属性。st.logout()会从用户浏览器中移除身份验证 cookie,并在新会话中将用户重定向至应用首页。
用户Cookie与登出机制
Streamlit会在每个新会话开始时检查身份验证Cookie。
如果用户在一个标签页中登录您的应用,然后打开新标签页,他们将在新标签页中自动保持登录状态。
当您在用户会话中调用st.logout()时,Streamlit会移除身份验证Cookie并启动新会话,这将使当前会话的用户登出。
但若用户已在其他会话中登录,那些会话仍将保持登录状态。
st.user中的信息会在会话开始时更新(这就是为什么st.login()和st.logout()在保存或删除身份验证Cookie后都会启动新会话)。
如果用户未主动登出就关闭应用,身份验证Cookie将在30天后过期。
该过期时间不可配置,且与用户身份令牌可能返回的过期时间无关。
如需禁用应用的持久化身份验证功能,请检查st.user中身份提供商返回的过期信息,并在必要时手动调用st.logout()。
Streamlit不会修改或删除由身份提供商直接保存的任何Cookie。
例如:若使用Google作为身份提供商,当用户通过st.logout()从您的应用登出后,其Google账户仍将保持登录状态。
配置身份提供程序
要使用身份提供程序,首先需要通过管理员账户配置您的身份提供程序。
这通常涉及在身份提供程序系统中设置一个客户端或应用程序。
请遵循您所用身份提供程序的文档进行操作。
一般而言,身份提供程序客户端通常具备以下功能:
- 管理您的用户列表
- (可选)允许用户自行加入您的用户列表
- 声明从每个用户账户传递给客户端(随后传递给您的Streamlit应用)的属性集合
- 仅允许来自您的Streamlit应用的身份验证请求
- 在用户完成身份验证后将其重定向回您的Streamlit应用
配置应用时,您需要准备以下信息:
- 应用URL
例如,本地开发时通常使用http://localhost:8501 - 重定向URL,即应用URL加上路径名
oauth2callback
例如,本地开发时通常使用http://localhost:8501/oauth2callback - Cookie密钥,应为一个高强度随机生成的字符串
使用这些信息完成身份提供程序客户端配置后,您将从身份提供程序处获得以下凭证:
- 客户端ID
- 客户端密钥
- 服务器元数据URL
常见OIDC提供程序的配置示例可在st.login()的API参考文档中查阅。
在 Streamlit 中配置 OIDC 连接
完成身份提供者客户端的配置后,您还需要配置 Streamlit 应用。
st.login() 会使用应用的 secrets.toml 文件来配置连接,其工作方式与 st.connection() 类似。
无论您使用单个还是多个 OIDC 提供者,都必须在 secrets.toml 中设置 [auth] 字典。
该字典必须声明 redirect_uri 和 cookie_secret 这两个值,它们会在应用的所有 OIDC 提供者之间共享。
如果仅使用一个 OIDC 提供者,您可以将剩余的三个属性(client_id、client_secret 和 server_metadata_url)直接放在 [auth] 中。
但如果使用多个提供者,则需要为每个连接指定唯一名称,以便在各自的字典中声明这些唯一值。
例如,若将连接命名为 "connection_1" 和 "connection_2",则需将它们的剩余属性分别放入 [auth.connection_1] 和 [auth.connection_2] 字典中。
简单示例
如果您使用 Google Identity 作为身份提供商,本地开发的基础配置将如下方 TOML 文件所示:
.streamlit/secrets.toml:
yaml
[auth]
redirect_uri = "http://localhost:8501/oauth2callback"
cookie_secret = "xxx"
client_id = "xxx"
client_secret = "xxx"
server_metadata_url = "https://accounts.google.com/.well-known/openid-configuration"请确保 redirect_uri 中的端口号与您实际使用的端口一致。
cookie_secret 应当是一个高强度随机生成的密钥。
redirect_uri 和 cookie_secret 这两个参数都需要预先配置到 Google Cloud 的客户端设置中。
创建客户端后,您必须从 Google Cloud 复制 client_id 和 client_secret。
某些身份提供商可能会为每个客户端分配专属的 server_metadata_url,但在 Google Cloud 中,所有 OIDC 客户端共享同一个元数据 URL。
在您的应用中,需要实现一个简易登录流程:
python
import streamlit as st
if not st.user.is_logged_in:
if st.button("Log in with Google"):
st.login()
st.stop()
if st.button("Log out"):
st.logout()
st.markdown(f"Welcome! {st.user.name}")当你使用 st.stop() 时,脚本会在登录按钮显示后立即终止运行。
这样可以避免将整个页面嵌套在条件块中。
此外,你还可以通过回调函数进一步简化代码:
python
import streamlit as st
if not st.user.is_logged_in:
st.button("Log in with Google", on_click=st.login)
st.stop()
st.button("Log out", on_click=st.logout)
st.markdown(f"Welcome! {st.user.name}")使用多个OIDC提供商
当您需要使用多个OIDC提供商时,必须为每个提供商声明唯一的名称。
例如,若想在同一应用中使用Google Identity和Microsoft Entra ID作为两个提供商,本地开发环境的配置将如下方TOML文件所示:
.streamlit/secrets.toml:
yaml
[auth]
redirect_uri = "http://localhost:8501/oauth2callback"
cookie_secret = "xxx"
[auth.google]
client_id = "xxx"
client_secret = "xxx"
server_metadata_url = "https://accounts.google.com/.well-known/openid-configuration"
[auth.microsoft]
client_id = "xxx"
client_secret = "xxx"
server_metadata_url = "https://login.microsoftonline.com/{tenant}/v2.0/.well-known/openid-configuration"Microsoft 的服务器元数据 URL 会根据客户端的作用域略有不同。
将 {tenant} 替换为 Microsoft 文档中 OpenID 配置 描述的适当值。
您的应用代码:
python
import streamlit as st
if not st.user.is_logged_in:
if st.button("Log in with Google"):
st.login("google")
if st.button("Log in with Microsoft"):
st.login("microsoft")
st.stop()
if st.button("Log out"):
st.logout()
st.markdown(f"Welcome! {st.user.name}")使用回调函数时,代码示例如下:
python
import streamlit as st
if not st.user.is_logged_in:
st.button("Log in with Google", on_click=st.login, args=["google"])
st.button("Log in with Microsoft", on_click=st.login, args=["microsoft"])
st.stop()
st.button("Log out", on_click=st.logout)
st.markdown(f"Welcome! {st.user.name}")向身份提供商传递关键字
如需自定义身份提供商的行为,您可能需要声明额外的关键字。
有关完整的OIDC参数列表,请参阅OpenID Connect Core及您的提供商文档。
默认情况下,Streamlit会设置scope="openid profile email"和prompt="select_account"。
您可以通过向client_kwargs传递设置字典来修改这些及其他OIDC参数。
出于安全考虑使用的state和nonce会自动处理,无需特别指定。
例如,如果您使用Auth0并需要强制用户每次登录,请按照Auth0文档自定义注册和登录提示中的说明使用prompt="login"。
您的配置将如下所示:
yaml
[auth]
redirect_uri = "http://localhost:8501/oauth2callback"
cookie_secret = "xxx"
[auth.auth0]
client_id = "xxx"
client_secret = "xxx"
server_metadata_url = "https://{account}.{region}.auth0.com/.well-known/openid-configuration"
client_kwargs = { "prompt" = "login" }注意
托管代码环境(如 GitHub Codespaces)设有额外的安全控制措施,这会阻止登录重定向的正常处理。
安全提醒
https://docs.streamlit.io/develop/concepts/connections/security-reminders
保护你的机密信息
切勿将用户名、密码或安全密钥直接保存在代码中或提交到代码仓库。
使用环境变量
通过环境变量来避免在代码中直接存储敏感信息。
建议查看 st.secrets 文档。
在使用任何平台时,请研究其安全最佳实践并遵循。
如果使用 Streamlit Community Cloud,Secrets 管理功能 可帮助你将环境变量和密钥安全存储在代码之外。
保持 .gitignore 文件更新
在开发过程中如果使用任何敏感或私有信息,请确保将这些信息保存在与代码分离的独立文件中。
同时,正确配置 .gitignore 文件,防止将私有信息提交到代码仓库中。
Pickle 安全警告
Streamlit 的 st.cache_data 和 st.session_state 隐式使用了 pickle 模块,而该模块已知存在安全隐患。
恶意构造的 pickle 数据可能在反序列化时执行任意代码。
切勿以不安全模式加载可能来自不可信源的数据,或可能被篡改的数据。
仅加载你信任的数据。
- 使用
st.cache_data时,函数返回的所有内容都会被 pickle 序列化存储,并在检索时反序列化。
请确保缓存函数返回的是可信值。
此警告同样适用于已弃用的st.cache。 - 当 配置选项(https://docs.streamlit.io/(/develop/concepts/configuration#runner)
runner.enforceSerializableSessionState设为true时,请确保所有存入及从 Session State 读取的数据都是可信的。
自定义组件
https://docs.streamlit.io/develop/concepts/custom-components
组件是第三方Python模块,用于扩展Streamlit的功能。
如何使用组件
组件使用起来非常简单:
1、首先找到你想使用的组件。
以下两个资源非常有用:
* [组件库](https://streamlit.io/components)
* 论坛用户Fanilo A.维护的[社区组件追踪帖](https://discuss.streamlit.io/t/streamlit-components-community-tracker/4634)2、使用你喜欢的Python包管理器安装组件。
这个步骤及后续操作都会在组件的说明文档中详细描述。
例如,要使用强大的AgGrid组件,首先通过以下命令安装:
pip install streamlit-aggrid3、在你的Python代码中,按照组件说明导入该组件。
以AgGrid为例,此步骤为:
python
from st_aggrid import AgGrid4、...现在你可以开始使用了!对于AgGrid来说,操作如下:
AgGrid(my_dataframe)创建自定义组件
如果你想开发自己的组件,可以参考以下资源:
如果你更喜欢通过视频学习,我们的工程师Tim Conkling制作了一些非常棒的教程:
视频教程,第一部分
视频教程,第二部分
自定义组件入门
https://docs.streamlit.io/develop/concepts/custom-components/intro
开发Streamlit组件的第一步是决定创建静态组件(即仅渲染一次,由Python控制)还是创建双向组件(可在Python和JavaScript之间双向通信)。
创建静态组件
如果你的目标是仅为了显示HTML代码或渲染Python可视化库中的图表而创建Streamlit组件,Streamlit提供了两个能极大简化流程的方法:components.html() 和 components.iframe()。
如果不确定是否需要双向通信,请先从这里开始!
渲染HTML字符串
虽然 st.text、st.markdown 和 st.write 可以轻松地将文本写入Streamlit应用,但有时你可能希望实现自定义的HTML片段。
同样,尽管Streamlit原生支持多种图表库,但你可能需要为新的图表库实现特定的HTML/JavaScript模板。
components.html 的功能是允许你在Streamlit应用中嵌入一个iframe,其中包含你想要的输出内容。
示例
python
import streamlit as st
import streamlit.components.v1 as components
# bootstrap 4 collapse example
components.html(
"""
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/css/bootstrap.min.css" integrity="sha384-Gn5384xqQ1aoWXA+058RXPxPg6fy4IWvTNh0E263XmFcJlSAwiGgFAW/dAiS6JXm" crossorigin="anonymous">
<script src="https://code.jquery.com/jquery-3.2.1.slim.min.js" integrity="sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN" crossorigin="anonymous"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/js/bootstrap.min.js" integrity="sha384-JZR6Spejh4U02d8jOt6vLEHfe/JQGiRRSQQxSfFWpi1MquVdAyjUar5+76PVCmYl" crossorigin="anonymous"></script>
<div id="accordion">
<div class="card">
<div class="card-header" id="headingOne">
<h5 class="mb-0">
<button class="btn btn-link" data-toggle="collapse" data-target="#collapseOne" aria-expanded="true" aria-controls="collapseOne">
Collapsible Group Item #1
</button>
</h5>
</div>
<div id="collapseOne" class="collapse show" aria-labelledby="headingOne" data-parent="#accordion">
<div class="card-body">
Collapsible Group Item #1 content
</div>
</div>
</div>
<div class="card">
<div class="card-header" id="headingTwo">
<h5 class="mb-0">
<button class="btn btn-link collapsed" data-toggle="collapse" data-target="#collapseTwo" aria-expanded="false" aria-controls="collapseTwo">
Collapsible Group Item #2
</button>
</h5>
</div>
<div id="collapseTwo" class="collapse" aria-labelledby="headingTwo" data-parent="#accordion">
<div class="card-body">
Collapsible Group Item #2 content
</div>
</div>
</div>
</div>
""",
height=600,
)渲染 iframe URL
components.iframe 的功能与 components.html 类似,不同之处在于 components.iframe 接收一个 URL 作为输入。
这适用于你想在 Streamlit 应用中嵌入整个页面的场景。
示例
python
import streamlit as st
import streamlit.components.v1 as components
# embed streamlit docs in a streamlit app
components.iframe("https://example.com", height=500)创建双向组件
一个双向 Streamlit 组件包含两部分:
1、前端部分:由 HTML 和任意你喜欢的 Web 技术(如 JavaScript、React、Vue 等)构建,通过 iframe 标签在 Streamlit 应用中渲染。
2、Python API:Streamlit 应用通过该接口实例化组件并与前端通信。
为了简化双向 Streamlit 组件的开发流程,我们在 Streamlit 组件模板 GitHub 仓库 中提供了 React 模板和纯 TypeScript 模板。
同一仓库中还包含一些 组件示例。
开发环境配置
要构建一个 Streamlit 组件,你的开发环境需要安装以下工具:
克隆 component-template GitHub 仓库,然后选择你想使用的模板:React.js 版本("template")或纯 TypeScript 版本("template-reactless")。
- 在终端中初始化并构建组件模板的前端:
shell
# React template
template/my_component/frontend
npm install # Initialize the project and install npm dependencies
npm run start # Start the Vite dev server
# or
# TypeScript-only template
template-reactless/my_component/frontend
npm install # Initialize the project and install npm dependencies
npm run start # Start the Vite dev server2、从另一个终端,运行声明并使用该组件的 Streamlit 应用(Python):
shell
# React template
cd template
. venv/bin/activate # or similar to activate the venv/conda environment where Streamlit is installed
pip install -e . # install template as editable package
streamlit run my_component/example.py # run the example
# or
# TypeScript-only template
cd template-reactless
. venv/bin/activate # or similar to activate the venv/conda environment where Streamlit is installed
pip install -e . # install template as editable package
streamlit run my_component/example.py # run the example完成上述步骤后,你将在浏览器中看到一个如下所示的Streamlit应用:
该模板示例应用展示了双向通信的实现方式。
Streamlit组件显示了一个按钮(Python → JavaScript),终端用户可以点击该按钮。
每次点击时,JavaScript前端会递增计数器值并传回Python(JavaScript → Python),随后由Streamlit显示该值(Python → JavaScript)。
前端
由于每个 Streamlit 组件本质上是一个渲染在 iframe 中的独立网页,因此您可以使用任何喜欢的网页技术来构建该页面。
我们在 Streamlit 的 Components-template GitHub 仓库 中提供了两个入门模板:其中一个模板基于 React,另一个则不依赖 React。
注意
即使您还不熟悉 React,您可能仍想看看基于 React 的模板。
它处理了大部分与 Streamlit 之间发送和接收数据所需的样板代码,您可以边学边掌握所需的 React 知识。
如果您不想使用 React,也请务必阅读本节内容!它解释了 Streamlit 与组件通信的基本原理。
React
基于 React 的模板位于 template/my_component/frontend/src/MyComponent.tsx。
-
当组件需要重新渲染时,会自动调用
MyComponent.render()(与任何 React 应用中的行为一致) -
从 Python 脚本传递的参数可通过
this.props.args字典获取:Send arguments in Python:
result = my_component(greeting="Hello", name="Streamlit")
// Receive arguments in frontend:
let greeting = this.props.args["greeting"]; // greeting = "Hello"
let name = this.props.args["name"]; // name = "Streamlit"`
- Use `Streamlit.setComponentValue()` to return data from the component to the Python script:在前端设置值:
javascript
Streamlit.setComponentValue(3.14);# Access value in Python:
result = my_component(greeting="Hello", name="Streamlit")
st.write("result = ", result) # result = 3.14当你调用 Streamlit.setComponentValue(new_value) 时,新值会被发送到 Streamlit,随后 Streamlit 会从上到下重新执行整个 Python 脚本 。
当脚本重新执行时,my_component(...) 的调用将返回这个新值。
从代码流程 的角度看,这像是与前端同步传输数据:Python 将参数发送给 JavaScript,而 JavaScript 又将值返回给 Python,整个过程似乎发生在一个函数调用中!但实际上,这一切都是异步进行的,正是 Python 脚本的重新执行实现了这种看似同步的魔法效果。
-
使用
Streamlit.setFrameHeight()可以控制组件的高度。默认情况下,React 模板会自动调用此方法(参见
StreamlitComponentBase.componentDidUpdate())。如果需要更精细的控制,可以覆盖此行为。
-
文件最后一行有个小魔法:
export default withStreamlitConnection(MyComponent)------ 它会与 Streamlit 进行一些握手操作,并建立双向数据通信的机制。
仅限 TypeScript
纯 TypeScript 模板位于 template-reactless/my_component/frontend/src/MyComponent.tsx。
该模板比对应的 React 版本包含更多代码,因为所有握手机制、事件监听器设置以及组件框架高度调整都需要手动实现。
而 React 版本的模板会自动处理大部分这些细节。
-
在源文件底部,模板会调用
Streamlit.setComponentReady()通知 Streamlit 组件已准备就绪,可以开始接收数据。
(通常建议在创建并加载完组件依赖的所有资源后再执行此操作。
) -
它会订阅
Streamlit.RENDER_EVENT事件来接收重绘通知。
(只有调用setComponentReady后才会触发此事件) -
在
onRender事件处理函数中,通过event.detail.args访问 Python 脚本传入的参数 -
其数据回传 Python 脚本的方式与 React 模板一致------点击"Click Me!"按钮会触发
Streamlit.setComponentValue()- It informs Streamlit when its height may have changed via `Streamlit.setFrameHeight()
主题应用指南
注意
自定义组件主题支持需要 streamlit-component-lib 1.2.0 或更高版本。
除了向组件发送 args 对象外,Streamlit 还会发送一个 theme 对象,其中定义了当前主题,以便组件能以兼容的方式调整其样式。
该对象与 args 在同一消息中发送,因此可通过 this.props.theme(使用 React 模板时)或 event.detail.theme(使用纯 TypeScript 模板时)访问。
theme 对象的结构如下:
json
{
"base": "lightORdark",
"primaryColor": "someColor1",
"backgroundColor": "someColor2",
"secondaryBackgroundColor": "someColor3",
"textColor": "someColor4",
"font": "someFont"
}base 选项允许您指定一个预设的 Streamlit 主题作为自定义主题的继承基础。
任何未在主题设置中定义的配置选项,其值都将沿用基础主题的设置。
base 的有效取值为 "light" 和 "dark"。
请注意,主题对象的字段名称和语义与 streamlit config show 命令输出的配置选项中 "theme" 部分的参数完全一致。
当使用 React 模板时,以下 CSS 变量也会被自动设置。
shell
--base
--primary-color
--background-color
--secondary-background-color
--text-color
--font如果你不熟悉 CSS variables,简单来说,你可以这样使用它们:
js
.mySelector {
color: var(--text-color);
}这些变量与上方 theme 对象中定义的字段相匹配。
在组件中使用 CSS 变量还是主题对象,取决于个人偏好。
其他前端细节
- 由于你通过开发服务器(使用
npm run start)托管组件,保存时所做的任何更改都会自动反映在 Streamlit 应用中。 - 如需为组件添加更多包,请在组件的
frontend/目录下运行npm add命令进行添加。
shell
npm add baseui- 要构建组件的静态版本,请运行
npm run export。
更多信息请参阅准备你的组件
Python API
只需使用 components.declare_component() 即可为你的组件创建 Python API:
python
import streamlit.components.v1 as components
my_component = components.declare_component(
"my_component",
url="http://localhost:3001"
)然后,你可以使用返回的 my_component 函数与前端代码进行数据收发:
# Send data to the frontend using named arguments.
return_value = my_component(name="Blackbeard", ship="Queen Anne's Revenge")
# `my_component`'s return value is the data returned from the frontend.
st.write("Value = ", return_value)虽然从Python端定义上述内容就足以创建一个可用的组件,但我们建议创建一个带有命名参数、默认值、输入验证等功能的"包装器"函数。
这将使最终用户更容易理解你的函数接受哪些数据值,并允许定义有用的文档字符串。
请参考Components模板中的这个示例,了解如何创建包装器函数。
数据序列化
Python → 前端
通过将关键字参数传递给组件的调用函数(即从declare_component返回的函数),可以将数据从Python发送到前端。
支持从Python向前端发送以下类型的数据:
- 任何可JSON序列化的数据
numpy.arraypandas.DataFrame
可JSON序列化的数据会被序列化为JSON字符串,并在JavaScript端反序列化为等效对象。
numpy.array和pandas.DataFrame则通过Apache Arrow进行序列化,反序列化为ArrowTable实例------这是一个封装Arrow结构的自定义类型,提供了便捷的API接口。
关于ArrowTable的具体用法,可参考示例代码:CustomDataframe和SelectableDataTable。
前端 → Python
你可以通过 Streamlit.setComponentValue() API(这是模板代码的一部分)将数据从前端发送到 Python。
与从 Python → 前端传递参数不同,该 API 只接受单个值 。
如果需要返回多个值,你必须将它们包装在 Array 或 Object 中。
自定义组件可以从前端向 Python 发送 JSON 可序列化的数据,也可以使用 Apache Arrow 的 ArrowTable 来表示数据框。
创建一个组件
https://docs.streamlit.io/develop/concepts/custom-components/create
注意
如果你只对使用 Streamlit 组件 感兴趣,可以直接跳过本节,前往 Streamlit 组件库 查找并安装社区创建的组件!
开发者可以编写能在 Streamlit 应用中渲染的 JavaScript 和 HTML "组件"。
Streamlit 组件既能从 Streamlit Python 脚本接收数据,也能向其发送数据。
Streamlit 组件让你能够扩展基础 Streamlit 包提供的功能。
通过它,你可以为特定用例创建所需功能,然后将其封装为 Python 包并与更广泛的 Streamlit 社区分享!
通过 Streamlit 组件,你可以通过以下方式为应用添加新功能:
- 创建自定义组件来替代现有的 Streamlit 元素和控件
- 通过封装现有的 React.js、Vue.js 或其他 JavaScript 控件工具包,创建全新的 Streamlit 元素和控件
- 通过构建 HTML 表示并设置样式以匹配应用主题,来渲染 Python 对象
- 创建便捷函数来嵌入常用网页功能,例如 GitHub gists 和 Pastebin
观看 Streamlit 工程师 Tim Conkling 的这些 Streamlit 组件教程视频开始学习:
第一部分:设置与架构
第二部分:制作滑块组件
发布组件
https://docs.streamlit.io/develop/concepts/custom-components/publish
发布到 PyPI
将您的 Streamlit 组件发布到 PyPI,可以让全球的 Python 用户轻松获取和使用。
此步骤完全是可选的,如果您不打算公开发布您的组件,可以跳过本节!
注意
对于静态 Streamlit 组件,发布 Python 包到 PyPI 的步骤与PyPI 核心打包指南相同。
静态组件通常只包含 Python 代码,因此只要正确配置 setup.py 文件并生成分发文件,就可以上传至 PyPI。
双向 Streamlit 组件至少包含 Python 和 JavaScript 代码,因此在发布到 PyPI 前需要更多准备工作。
本页剩余部分将重点介绍双向组件的发布流程。
准备你的组件
双向Streamlit组件与纯Python库略有不同,因为它必须包含预编译的前端代码。
这也是基础Streamlit的工作原理;当你执行pip install streamlit时,实际上获取的是一个Python库,其中包含的HTML和前端代码已被编译成静态资源。
component-template GitHub仓库提供了发布到PyPI所需的文件夹结构。
但在发布之前,你需要进行一些准备工作:
-
为组件命名(如果尚未完成)
- 将
template/my_component/文件夹重命名为template/<组件名称>/ - 将组件名称作为第一个参数传递给
declare_component()
- 将
-
编辑
MANIFEST.in文件将递归包含路径从
package/frontend/build *修改为<组件名称>/frontend/build * -
编辑
setup.py文件添加组件名称及其他相关信息
-
创建前端代码的发布版本
这将生成一个新目录
frontend/build/,其中包含编译后的前端代码
shell
cd frontend
npm run build将构建文件夹的路径作为 path 参数传递给 declare_component。
(如果使用模板 Python 文件,可以在文件顶部设置 _RELEASE = True)
python
import streamlit.components.v1 as components
# Change this:
# component = components.declare_component("my_component", url="http://localhost:3001")
# To this:
parent_dir = os.path.dirname(os.path.abspath(__file__))
build_dir = os.path.join(parent_dir, "frontend/build")
component = components.declare_component("new_component_name", path=build_dir)构建 Python wheel 包
当你完成以下操作后:修改默认的 my_component 引用、编译 HTML 和 JavaScript 代码,并在 components.declare_component() 中设置新组件名称,就可以开始构建 Python wheel 包了:
-
确保已安装最新版的 setuptools、wheel 和 twine
-
从源代码创建 wheel 包:
Run this from your component's top-level directory; that is,
the directory that contains
setup.pypython setup.py sdist bdist_wheel
将你的wheel包上传至PyPI
完成wheel包的构建后,最后一步就是将其上传到PyPI。
以下指南重点介绍如何上传至Test PyPI,这样你可以熟悉整个流程而无需担心影响正式环境。
上传至正式PyPI的基本步骤与此相同。
1、若尚未注册,请先在Test PyPI创建账户
- 访问https://test.pypi.org/account/register/并完成注册步骤
- 前往https://test.pypi.org/manage/account/#api-tokens创建新的API令牌。
由于你正在创建新项目,请不要将令牌范围限定到特定项目。
关闭页面前请复制令牌内容,之后将无法再次查看该信息。
2、使用twine将wheel包上传至Test PyPI。
系统会提示输入用户名和密码:用户名填写**token **,密码使用上一步获取的令牌值(需包含pypi-前缀)。
shell
python -m twine upload --repository testpypi dist/*3、将新上传的包安装到一个新的Python项目中,确保其正常运行:
shell
python -m pip install --index-url https://test.pypi.org/simple/ --no-deps example-pkg-YOUR-USERNAME-HERE如果一切顺利,按照 https://packaging.python.org/tutorials/packaging-projects/#next-steps 上的说明,你就可以将库上传到 PyPI 了。
恭喜,你已经创建了一个公开可用的 Streamlit 组件!
推广你的组件!
我们非常乐意帮助你与Streamlit社区分享你的组件!以下是分享方法:
1、如果你的代码托管在GitHub上,请添加streamlit-component标签,这样它就会出现在GitHub的streamlit-component主题列表中:
2、在Streamlit论坛的Show the Community!板块发帖。
使用类似"新组件:<你的组件名称>,实现X功能的新方法"的标题。
3、将你的组件添加到社区组件追踪器。
4、在Twitter上@streamlit提及我们,我们会帮你转发公告。
我们的组件画廊大约每月更新一次。
遵循以上建议可以最大化你的组件被收录的机会。
文档中展示的社区组件是人工精选的,更新频率较低。
拥有大量星标和良好文档的热门组件更有可能被选中。
自定义组件的限制
https://docs.streamlit.io/develop/concepts/custom-components/limitations
Streamlit组件与基础Streamlit包提供的功能有何不同?
- Streamlit组件被封装在iframe中,这使您能够使用任何喜欢的Web技术(在iframe内)自由实现功能。
Streamlit 组件有哪些限制?
由于每个 Streamlit 组件都运行在独立的沙盒 iframe 中,这导致组件存在以下限制:
- 无法与其他组件通信:组件不能包含(或与其他组件通信),因此无法用组件构建类似网格布局的功能。
- 无法修改 CSS:组件不能修改 Streamlit 应用其他部分的 CSS,例如无法通过组件实现暗黑模式切换。
- 无法添加/删除元素:组件不能添加或删除 Streamlit 应用的其他元素,例如无法通过组件移除应用菜单。
我的组件出现闪烁/卡顿现象...如何解决?
目前,Streamlit 内部不会自动对组件更新进行防抖处理。
组件开发者可以自行决定是否对传回 Streamlit 的更新进行速率限制。
https://streamlit.io/components
配置与自定义你的应用
https://docs.streamlit.io/develop/concepts/configuration
配置选项
了解通过 Streamlit 配置可用的各类选项。
HTTPS 支持
了解如何为您的 Streamlit 应用配置 SSL 和 TLS。
https://docs.streamlit.io/develop/concepts/configuration/https-support
静态文件托管
了解如何在应用旁托管文件,使其可通过URL访问。
如需使用原始HTML直接引用文件,可采用此方式。
https://docs.streamlit.io/develop/concepts/configuration/serving-static-files
主题化
主题定制
了解如何利用主题配置选项来自定义应用的外观。
https://docs.streamlit.io/develop/concepts/configuration/theming
自定义颜色与边框
了解如何通过配置选项来自定义应用的颜色方案。
https://docs.streamlit.io/develop/concepts/configuration/theming-customize-colors-and-borders
自定义字体
了解如何通过配置选项来自定义应用程序的字体。
https://docs.streamlit.io/develop/concepts/configuration/theming-customize-fonts
配置选项的使用方法
https://docs.streamlit.io/develop/concepts/configuration/options
Streamlit 提供了四种不同的方式来设置配置选项。
以下列表按优先级从低到高排序,即当多次提供相同的配置选项时,命令行标志的优先级高于环境变量。
注意
如果在应用运行时修改 .streamlit/config.toml 中的主题设置 ,这些更改会立即生效。
如果在应用运行时修改 .streamlit/config.toml 中的非主题设置,则需要重启服务器才能使更改在应用中生效。
- 全局配置文件 路径:
- macOS/Linux 系统:
~/.streamlit/config.toml - Windows 系统:
%userprofile%/.streamlit/config.toml
- macOS/Linux 系统:
yaml
[server]
port = 802、在位于 $CWD/.streamlit/config.toml 的项目级配置文件 中配置,其中
$CWD 表示运行 Streamlit 的当前工作目录。
3、通过 STREAMLIT_* 环境变量进行配置,例如:
shell
export STREAMLIT_SERVER_PORT=80
export STREAMLIT_SERVER_COOKIE_SECRET=dontforgottochangeme4、作为运行 streamlit run 时的命令行参数:
shell
streamlit run your_script.py --server.port 80可用选项
所有可用的配置选项都记录在 config.toml 文件中。
这些选项可以通过 TOML 文件、环境变量或命令行参数来声明。
当使用环境变量覆盖 config.toml 配置时,需要将变量名(包括其所属的节标题)转换为大写蛇形命名法,并添加 STREAMLIT_ 前缀。
例如,STREAMLIT_CLIENT_SHOW_ERROR_DETAILS 对应以下 TOML 配置:
yaml
[client]
showErrorDetails = true当使用命令行选项覆盖 config.toml 和环境变量时,需保持与 TOML 文件中相同的大小写格式,并以点号分隔的方式包含节头作为前缀。
例如,命令行选项 --server.enableStaticServing true 等效于以下配置:
yaml
[server]
enableStaticServing = true遥测
正如安装过程中提到的,Streamlit 会收集使用统计信息。
您可以通过阅读我们的隐私声明了解更多详情,但简要概括是:虽然我们会收集遥测数据,但我们无法查看也不会存储 Streamlit 应用中的具体内容。
如果您希望禁用使用统计功能,请在配置文件中添加以下内容:
yaml
[browser]
gatherUsageStats = false主题定制
您可以通过配置系统中的 [theme] 部分来更改应用的基础颜色。
了解更多信息,请参阅主题定制。
查看所有配置选项
如命令行选项文档所述,您可以通过以下命令查看所有可用的配置选项:
shell
streamlit config showHTTPS 支持
https://docs.streamlit.io/develop/concepts/configuration/https-support
许多应用需要通过 SSL/TLS 协议或 https:// 进行访问。
对于自托管和生产环境的使用场景,我们建议在反向代理或负载均衡器中执行 SSL 终止,而不是直接在应用中处理。
Streamlit Community Cloud 采用这种方式,所有主流云平台和应用托管平台都应支持此配置,并提供详尽的文档说明。
您可以在我们的部署教程中找到部分相关平台。
若要在 Streamlit 应用中终止 SSL,您需要配置 server.sslCertFile 和 server.sslKeyFile。
了解如何设置配置选项,请参阅配置指南。
使用详情
- 配置值应为指向证书文件和密钥文件的本地文件路径。
这些文件必须在应用启动时可用。 - 必须同时指定
server.sslCertFile和server.sslKeyFile。
如果仅指定其中一个,应用将报错退出。 - 此功能在社区云中不可用。
社区云已默认通过 TLS 为您的应用提供服务。
警告
在生产环境中,我们建议通过负载均衡器或反向代理来执行SSL终止,而不是使用此选项。
Streamlit中的此选项尚未经过全面的安全审计或性能测试。
示例用法
yaml
# .streamlit/config.toml
[server]
sslCertFile = '/path/to/certchain.pem'
sslKeyFile = '/path/to/private.key'静态文件服务
https://docs.streamlit.io/develop/concepts/configuration/serving-static-files
Streamlit 应用可以托管并提供小型静态媒体文件,以支持常规媒体元素无法实现的媒体嵌入用例。
要启用此功能,请在配置文件的 [server] 部分下设置 enableStaticServing = true,或设置环境变量 STREAMLIT_SERVER_ENABLE_STATIC_SERVING=true。
存储在运行应用文件相对路径 ./static/ 文件夹中的媒体文件,将通过路径 app/static/[文件名] 提供服务,例如 http://localhost:8501/app/static/cat.png。
使用详情
-
以下扩展名的文件将正常提供服务:
- 常见图片类型:
.jpg、.jpeg、.png、.gif - 常见字体类型:
.otf、.ttf、.woff、.woff2 - 其他类型:
.pdf、.xml、.json
其他类型的文件会以Content-Type:text/plain头信息发送,导致浏览器以纯文本形式渲染。
出于安全考虑,需要渲染的其他文件类型应在应用外部托管。
- 常见图片类型:
-
Streamlit还会为静态目录渲染的所有文件设置
X-Content-Type-Options:nosniff头信息。 -
对于运行在Streamlit Community Cloud上的应用:
-
Github仓库中的文件始终可用。
应用运行时生成的文件(如基于用户交互生成的文件上传等)无法保证在用户会话间持久保存。
-
存储并提供大量文件或大文件的应用可能会触及资源限制并被关闭。
-
示例用法
-
将图片
cat.png放入文件夹./static/中 -
在
.streamlit/config.toml文件的[server]部分下添加enableStaticServing = true -
./static/文件夹中的任何媒体文件都会通过相对 URL 提供服务,例如app/static/cat.png.streamlit/config.toml
[server]
enableStaticServing = true`
# app.py
import streamlit as st
with st.echo():
st.title("CAT")
st.markdown("[](https://streamlit.io)")其他资源:
使用Streamlit构建 🎈全屏打开 open_in_new
主题概述
https://docs.streamlit.io/develop/concepts/configuration/theming
本指南概述了 Streamlit 应用的主题和视觉自定义功能。
Streamlit 主题通过配置选项定义,这些选项通常存储在 .streamlit/config.toml 文件中。
有关设置配置选项的更多信息,请参阅使用配置选项。
完整的配置选项列表和定义,请参考 config.toml 的 API 文档。
以下选项可在 config.toml 的 [theme] 表中设置,但不能在 [theme.sidebar] 表中单独设置:
- 基础配色方案:设置自定义主题继承 Streamlit 的浅色或深色主题。
- 基础字体:设置基础字体的粗细和大小(标题和代码字体可单独配置)。
- 图表颜色:为 Plotly、Altair 和 Vega-Lite 图表设置系列颜色。
- 侧边栏边框:设置侧边栏边框的可见性。
以下选项可分别针对应用主体和侧边栏进行配置:
- 字体家族:设置正文、标题和代码的字体家族。
- 字体样式:设置标题和代码字体的粗细及大小,并设置链接下划线的可见性。
- 文本颜色:设置正文和链接的文本颜色。
- 主色调:设置交互元素和高亮的颜色。
- 背景色:设置应用、组件、代码块和数据框标题的背景颜色。
- 边框圆角:设置元素和组件的圆角程度。
- 边框颜色:设置元素、组件、侧边栏和数据框边框的颜色及可见性。
主题示例
以下浅色主题灵感来源于 Anthropic。
由 Streamlit 构建 🎈全屏查看 open_in_new
以下深色主题灵感来源于 Spotify。
由 Streamlit 构建 🎈全屏查看 open_in_new
开发过程中的主题配置
大多数主题配置选项可以在应用运行时动态更新,这使得自定义主题的迭代变得非常便捷。
例如,当你修改应用的主色调并保存config.toml文件后,只需重新运行应用即可立即看到新颜色生效。
但需注意,部分配置选项(如[[theme.fontFace]])需要重启Streamlit服务才能应用更改。
若不确定具体操作,建议在更新配置后,先在终端停止Streamlit服务,再通过streamlit run命令重新启动应用。
自定义 Streamlit 应用中的颜色与边框
https://docs.streamlit.io/develop/concepts/configuration/theming-customize-colors-and-borders
颜色值
对于所有接受颜色值的配置选项,您可以通过以下字符串格式之一来指定颜色值:
- CSS
<named-color>命名颜色,例如"darkBlue"或"maroon"。 - HEX 十六进制字符串,例如
"#483d8b"或"#6A5ACD"。 - RGB 字符串,例如
"rgb(106, 90, 205)"或"RGB(70, 130, 180)"。 - HSL 字符串,例如
"hsl(248, 53%, 58%)"或"HSL(147, 50%, 47%)"。
提示
虽然可以为颜色指定透明度(alpha值),但不建议这样做。
Streamlit会自动调整颜色的透明度值,以确保背景与前景之间的明暗对比符合上下文需求。
默认的 Streamlit 颜色
Streamlit 提供了两种预配置的主题:浅色和深色。
如果不指定任何主题配置选项,Streamlit 会尝试使用与用户浏览器设置最匹配的预配置主题。
颜色与边框配置选项
大多数主题配置选项可全局应用于整个应用,但部分选项可在侧边栏中单独设置不同值。
例如,应用的主色调 (primaryColor) 用于高亮交互元素和显示焦点状态。
若设置 theme.primaryColor 将全局改变主色调,而设置 theme.sidebar.primaryColor 则会覆盖侧边栏的主色调,从而实现双主色调效果。
以下两个配置选项仅支持全局设置:
theme.base设置应用主题的默认配色方案,可选 Streamlit 的两个内置主题 ("light"或"dark")。
若未设置该选项但使用了其他主题配置,Streamlit 将默认采用"light"主题。theme.showSidebarBorder控制侧边栏与主内容区域之间边框的可见性。theme.chartCategoricalColors和theme.chartSequentialColors为 Plotly、Altair 和 Vega-Lite 图表设置系列颜色。
以下配置选项可通过在 config.toml 中使用 [theme.sidebar] 表(而非 [theme] 表)来单独设置侧边栏样式:
theme.primaryColortheme.backgroundColortheme.secondaryBackgroundColortheme.textColortheme.linkColortheme.linkUnderlinetheme.codeBackgroundColortheme.baseRadiustheme.buttonRadiustheme.borderColortheme.dataframeBorderColortheme.dataframeHeaderBackgroundColortheme.showWidgetBorder
为简洁起见,本页后续内容将省略 theme. 和 theme.sidebar. 前缀。
primaryColor
primaryColor 定义了在 Streamlit 应用中频繁使用的强调色。
以下功能和效果会使用该主色:
- 按钮悬停效果
- 聚焦状态的元素
- 被选中的元素
提示
当您的主色调被用作背景色时,Streamlit 会自动将文字颜色切换为白色。
例如,这种情况会出现在 type="primary" 按钮以及 st.multiselect 中被选中的选项上。
为了确保可读性,请始终选择足够深的主色调,使其与白色文字形成良好的对比效果。
示例1:主色调
以下配置示例中,主色调设置为"forestGreen"。
在侧边栏中,配置将主色调覆盖为"darkGoldenrod"。
当您点击某个小组件使其获得焦点时,Streamlit会在该组件周围显示主色调边框。
此外,当鼠标悬停在次级和三级按钮上时,悬停颜色会与主色调保持一致。
yaml
[theme]
base="dark"
primaryColor="forestGreen"
[theme.sidebar]
primaryColor="darkGoldrod"使用 Streamlit 构建 🎈全屏查看 open_in_new
backgroundColor、secondaryBackgroundColor、codeBackgroundColor 和 dataframeHeaderBackgroundColor
-
backgroundColor定义应用程序的背景颜色。 -
secondaryBackgroundColor用于以下场景的对比色设置:- 小部件的输入或选择区域背景
st.help和st.dataframe等元素内的标题背景(若未设置dataframeHeaderBackgroundColor)- 代码块和内联代码的背景(若未设置
codeBackgroundColor)
-
codeBackgroundColor设置代码块和内联代码的背景色。若未设置此参数,Streamlit 会默认使用
secondaryBackgroundColor。 -
dataframeHeaderBackgroundColor设置数据框标题的背景色(包括行选择和添加操作的单元格背景,如果存在)。
注意
如果未为侧边栏定义背景颜色,Streamlit 会在侧边栏中交换 backgroundColor 和 secondaryBackgroundColor 的使用:
- 如果未定义
theme.sidebar.backgroundColor,Streamlit 会使用theme.secondaryBackgroundColor。 - 如果未定义
theme.sidebar.secondaryBackgroundColor,Streamlit 会使用theme.backgroundColor。
示例2:背景颜色配置
以下配置示例展示了主界面采用"white"白色背景,侧边栏使用带有薰衣草色调的"ghostWhite"幽灵白背景。
整个应用的辅助色设置为"lavender"薰衣草色,代码区块背景色为"powderBlue"粉蓝色。
代码背景色只需在[theme]主题配置中定义一次,即可被侧边栏继承。
但由于Streamlit在侧边栏继承背景色时会进行颜色交换,因此辅助背景色需要在[theme]和[theme.sidebar]中同时设置。
要查看悬停效果使用的辅助色,可将鼠标悬停在数据表格单元格上或打开多选下拉菜单。
yaml
[theme]
base="light"
backgroundColor="white"
secondaryBackgroundColor="lavender"
codeBackgroundColor="powderBlue"
[theme.sidebar]
backgroundColor="ghostWhite"
secondaryBackgroundColor="lavender"基于 Streamlit 构建 🎈全屏显示 open_in_new
textColor、linkColor 和 linkUnderline
您可以配置正文文本和链接的颜色。
textColor 用于设置应用中除代码块内的语言高亮、行内代码和链接外所有文本的默认颜色。
linkColor 则设置应用中所有 Markdown 链接的默认字体颜色。
若 linkUnderline 设为 true(默认值),链接下划线颜色将与 linkColor 保持一致。
以下元素会受到 textColor 的影响:
- Markdown 文本(链接除外)
- 代码块中未被语言高亮着色的文本
- 应用界面和侧边栏菜单图标
- 组件标签、图标、选项文本及占位文本
- 数据框和表格文本
- 非 Markdown 链接(如
st.page_link、st.link_button及导航菜单)
如前所述,当文本显示在主题色背景上时,Streamlit 会自动将文本颜色切换为白色。
示例3:文本颜色
以下配置示例在"dark"底色上使用"darkGoldenrod"文本和"darkOrchid"链接。
按钮(包括st.link_button)采用"darkGoldenrod"文本颜色。
在多选组件中,占位文本、下拉菜单和工具提示都使用"darkGoldenrod"文本。
当悬停在侧边栏时,滚动条和折叠图标(chevron_left )会显示为"darkGoldenrod"。
yaml
[theme]
base="dark"
textColor="darkGoldenrod"
linkColor="darkOrchid"使用 Streamlit 构建 🎈全屏显示 open_in_new
baseRadius 与 buttonRadius
baseRadius 用于定义以下元素的边框和背景圆角半径:
- 小组件上的按钮和输入区域
- 选中项,包括
st.multiselect中的选项和导航菜单项 - 代码块和内联代码
- 数据框(外边框)
- 徽标和 Markdown 文本背景
- 带边框的容器,包括扩展器、表单、对话框、弹出框和提示框
- 工具提示(包括图表内的工具提示)
- 状态和异常消息块
- 图像(包括显示为静态图像的
st.graphviz和st.pyplot)
buttonRadius 会覆盖按钮和 st.segmented_control 的 baseRadius 设置。
需注意,部分元素不会完全受 baseRadius 影响。
由于底层 HTML 结构更复杂,交互式图表和视频始终会保持直角边框,包括 st.video、st.map 和 st.pydeck_chart。
而 st.chat_input 和 st.audio_input 则始终会完全圆角化。
子元素(如工具提示)仍会遵循 baseRadius 的设置。
示例4:边框圆角
在以下配置示例中,应用主体采用"full"(1rem)的基础圆角值,而侧边栏则使用"none"(0rem)。
为了更突出这一差异,示例中搭配了对比鲜明的主色和背景色。
yaml
[theme]
base="light"
primaryColor="slateBlue"
backgroundColor="mintCream"
secondaryBackgroundColor="darkSeaGreen"
baseRadius="full"
[theme.sidebar]
backgroundColor="aliceBlue"
secondaryBackgroundColor="skyBlue"
baseRadius="none"基于 Streamlit 构建 🎈全屏显示 open_in_new
borderColor、dataframeBorderColor 和 showWidgetBorder
默认情况下,Streamlit 不会为未聚焦的组件显示边框(按钮除外)。
当用户聚焦某个组件时,Streamlit 会在输入区域周围显示一个边框,颜色取自 primaryColor。
当用户取消聚焦时,Streamlit 会隐藏该边框。
如果将 showWidgetBorder 设为 true,Streamlit 会在组件未聚焦时显示边框。
对于这些组件,边框颜色由 borderColor 设定。
如果未设置 borderColor,Streamlit 会通过为 textColor 添加透明度来自动推断颜色。
以下元素的边框支持自定义修改:
- 带边框的容器,包括扩展器、表单、对话框、弹出框和提示框
- 侧边栏,包括右侧边缘和导航菜单下方的边界
- 数据框和表格
st.tabs(底部边框)- 按钮,包括
st.button、st.pills和st.segmented_control - 输入区域的边框
对于数据框和表格,dataframeBorderColor 会覆盖 borderColor 的设置。
示例5:边框颜色与可见性
以下配置示例在整个应用中使用"mediumSlateBlue"作为边框颜色。
侧边栏中的组件会显示边框,而应用主体区域的组件边框则被隐藏。
多选框、文本输入区和聊天输入区在非聚焦状态下不显示边框,但聚焦时会显现。
其他元素如按钮和数据框则始终保持边框可见。
yaml
[theme]
base="dark"
borderColor="mediumSlateBlue"
showWidgetBorder=false
[theme.sidebar]
showWidgetBorder=true使用 Streamlit 构建 🎈全屏 open_in_new
自定义 Streamlit 应用中的字体
https://docs.streamlit.io/develop/concepts/configuration/theming-customize-fonts
Streamlit 允许你更改并自定义应用中的字体。
你可以从公共 URL 加载字体文件,或通过静态文件服务将字体与应用一同托管。
Streamlit 默认字体
Streamlit 内置了 Source Sans、Source Serif 和 Source Code 字体。
这些字体文件已包含在 Streamlit 库中,客户端无需从第三方下载。
默认情况下,Streamlit 对所有文本使用 Source Sans 字体,但行内代码和代码块会改用 Source Code 字体。
要使用这些默认字体,您可以在 config.toml 中将以下配置选项分别设为:
"sans-serif"(对应 Source Sans)"serif"(对应 Source Serif)"monospace"(对应 Source Code)
yaml
[theme]
font = "sans-serif"
headingFont = "sans-serif"
codeFont = "monospace"
[theme.sidebar]
font = "sans-serif"
headingFont = "sans-serif"
codeFont = "monospace"你可以在 config.toml 文件的 [theme] 表中设置基础字体粗细和大小。
这些设置在侧边栏中无法单独配置。
theme.baseFontSize设置应用的根字体大小。theme.baseFontWeight设置应用的根字体粗细。
以下配置选项可以通过在 config.toml 中使用 [theme.sidebar] 表(而非 [theme] 表)来为侧边栏单独设置:
theme.font设置应用中所有文本(内联代码和代码块除外)的默认字体,默认为"sans-serif"(Source Sans)。theme.headingFont设置应用中所有标题的默认字体。
如果未设置,Streamlit 会使用theme.font。theme.headingFontSizes设置<h1>-<h6>标题的字体大小。theme.headingFontWeights设置<h1>-<h6>标题的字体粗细。theme.codeFont设置所有内联代码和代码块的默认字体,默认为"monospace"(Source Code)。theme.codeFontSize设置代码块、st.json和st.help中代码文本的大小(不包括内联代码)。theme.codeFontWeight设置代码块、st.json和st.help中代码文本的粗细(不包括内联代码)。
如果 [theme.sidebar] 中未声明字体,Streamlit 会优先从 [theme] 继承每个选项,再回退到更通用的选项。
例如,如果未设置 theme.sidebar.headingFont,Streamlit 会按优先级顺序使用 theme.headingFont、theme.sidebar.font 或 theme.font。
在下面的 config.toml 示例中,Streamlit 在应用主体中使用 Source Serif 字体,在侧边栏中使用 Source Sans 字体。
yaml
[theme]
font = "serif"
[theme.sidebar]
font = "sans-serif"加载替代字体
要在应用中使用替代字体,您必须在 config.toml 文件的 [[theme.fontFaces]] 部分声明该字体。
如需使用多个替代字体,请在配置文件中声明多个 [[theme.fontFaces]] 表。
您可以通过 Streamlit 静态文件服务自托管字体,也可以指向公开托管的字体文件。
重要提示
Streamlit 支持自托管 OTF、TTF、WOFF 和 WOFF2 字体文件格式。
其他字体文件格式必须通过外部托管。
字体在 [[theme.fontFaces]] 表中通过以下属性定义:
family:这是字体的名称,用于标识该字体以供其他配置选项使用。url:这是字体文件的位置。
如果与应用一起自托管字体文件,其值类似于"app/static/font_file.woff"。weight(可选):声明字体文件中字体的粗细(例如400、"200 800"或"bold")。
更多信息,请参阅font-weightCSS@font-face描述符。style(可选):声明字体文件中字体的样式(例如"normal"、"italic"或"oblique")。
更多信息,请参阅font-styleCSS@font-face描述符。unicodeRange(可选):声明字体文件中特定的字符范围(例如"U+0025-00FF, U+4??")。
更多信息,请参阅unicode-rangeCSS@font-face描述符。
注意
字体文件可分为静态字体和可变字体。
静态字体文件仅包含单一字重和样式的字体。
若使用静态字体文件,通常需要加载多个文件才能完整支持不同字重(常规、加粗)和样式(常规、斜体)的字体变体。
而可变字体文件通过参数化控制一个或多个字体属性,这意味着单个字体文件即可支持多种字重和样式。
示例1:使用可变字体文件定义替代字体
以下示例通过静态文件托管服务加载Google的Noto Sans和Noto Sans Mono字体,并配置应用使用这些字体。
这两种字体都采用包含参数化字重的可变字体文件定义。
但由于字体样式未被参数化,Noto Sans需要两个文件分别定义常规体和斜体样式,而Noto Sans Mono则没有为其斜体样式提供单独文件。
根据CSS规则,若未显式提供斜体样式,浏览器将通过倾斜常规体字体进行模拟渲染。
该示例的逐行解析可参阅教程。
.streamlit/config.toml:
yaml
[server]
enableStaticServing = true
[[theme.fontFaces]]
family="noto-sans"
url="app/static/NotoSans-Italic-VariableFont_wdth,wght.ttf"
style="italic"
[[theme.fontFaces]]
family="noto-sans"
url="app/static/NotoSans-VariableFont_wdth,wght.ttf"
style="normal"
[[theme.fontFaces]]
family="noto-mono"
url="app/static/NotoSansMono-VariableFont_wdth,wght.ttf"
[theme]
font="noto-sans"
codeFont="noto-mono"目录结构:
shell
project_directory/
├── .streamlit/
│ └── config.toml
├── static/
│ ├── NotoSans-Italic-VariableFont_wdth,wght.ttf
│ ├── NotoSans-VariableFont_wdth,wght.ttf
│ └── NotoSansMono-VariableFont_wdth,wght.ttf
└── streamlit_app.py示例2:使用静态字体文件定义替代字体
在此配置示例中,我们通过多个静态字体文件声明了一种替代字体。
每种字体包含四个静态文件,分别定义以下字重-样式组合:
- 常规体-正常字重
- 常规体-加粗字重
- 斜体-正常字重
- 斜体-加粗字重
如果应用程序使用的字体没有匹配的字重-样式定义,用户浏览器将自动选用最接近的可用字体。
请注意,<h2>至<h6>标题的默认字重为半粗体(600)。
为确保完整性,建议包含额外的字体文件以覆盖半粗体字重及应用程序中使用的所有字重级别。
以下示例使用了Tuffy字体,该字体通过四个静态文件覆盖了上述四种字重-样式组合。
如需逐行解读此示例,可参阅教程。
.streamlit/config.toml:
yaml
[server]
enableStaticServing = true
[[theme.fontFaces]]
family="tuffy"
url="app/static/Tuffy-Regular.ttf"
style="normal"
weight=400
[[theme.fontFaces]]
family="tuffy"
url="app/static/Tuffy-Bold.ttf"
style="normal"
weight=700
[[theme.fontFaces]]
family="tuffy"
url="app/static/Tuffy-Italic.ttf"
style="italic"
weight=400
[[theme.fontFaces]]
family="tuffy"
url="app/static/Tuffy-BoldItalic.ttf"
style="italic"
weight=700
[theme]
font="tuffy"目录结构:
shell
project_directory/
├── .streamlit/
│ └── config.toml
├── static/
│ ├── Tuffy-Bold.ttf
│ ├── Tuffy-BoldItalic.ttf
│ ├── Tuffy-Italic.ttf
│ └── Tuffy-Regular.ttf
└── streamlit_app.py示例3:定义带备用字体的替代字体方案
如果不想下载字体文件并与应用一同托管,可以指向外部托管的字体文件。
当字体文件未与应用一同托管时,建议声明备用字体。
重要提示
如果您的应用配置中包含任何第三方集成(包括外部托管的字体),应用可能会将用户数据(例如IP地址)传输至外部服务器。
作为应用开发者,您有责任向用户告知这些第三方集成、提供相关隐私政策的访问途径,并确保遵守所有适用的数据保护法律法规。
在配置文件中声明默认字体时,您可以使用逗号分隔的字体列表。
建议始终将Streamlit的默认字体之一作为最终备用选项。
- 若要在示例1中指定备用字体,请在
.streamlit/config.toml文件中将[theme]表修改为以下内容:
yaml
[theme]
font="noto-sans, sans-serif"
codeFont="noto-mono, monospace"此配置与示例1相同,区别在于将Source Sans和Source Mono声明为后备字体。
您可以定义多个后备字体。
当声明默认字体时,该字体(或以逗号分隔的字体列表)会被传递给CSS的font-family属性。
提示
如果您的字体家族名称中包含空格,并且需要声明回退序列,请在名称周围使用内层引号。
例如,如果将字体命名为"Noto Sans",则应使用font="'Noto Sans', sans-serif"而非不加引号的写法。
字体大小
您可以为应用设置以像素为单位的基准字体大小。
必须将基准字体大小指定为整数。
以下配置等同于默认的16像素基准字体大小:
yaml
[theme]
baseFontSize=16此外,您还可以设置代码块的字体大小。
字体大小可以用像素(px)或rem单位来声明。
以下配置等同于默认的代码字体大小0.875rem。
yaml
[theme]
codeFontSize="0.875rem"注意
Markdown中的行内代码不受theme.codeFontSize影响。
行内代码的字体大小固定为0.75em。
字体颜色
字体颜色选项的配置方法详见自定义 Streamlit 应用的颜色和边框文档。
设计建议
在 Streamlit 应用中使用替代字体时,请牢记良好的设计实践。
字体的可读性很大程度上受其大小、与背景的对比度以及形状影响。
Streamlit 允许您为标题设置与正文不同的字体。
如果采用更复杂的字体,建议仅用于标题。
由于 theme.font 和 theme.sidebar.font 用于设置小部件标签、工具提示、列标题和数据框单元格中的字体,这些字体应始终保持高度可读性。
如需灵感,请参考 Fonts in Use。
Streamlit 原生应用测试框架
https://docs.streamlit.io/develop/concepts/app-testing
Streamlit 应用测试使开发者能够构建和运行自动化测试。
您可以使用自己喜爱的测试自动化软件,并通过简洁的语法来模拟用户输入和检查渲染输出。
提供的 AppTest 类模拟了一个运行中的应用,并通过 API 而非浏览器界面提供设置、操作和检查应用内容的方法。
AppTest 提供了类似于 Selenium 或 Playwright 等浏览器自动化工具的功能,但编写和执行测试的开销更小。
您可以将我们的测试框架与 pytest 等工具结合使用来执行或自动化测试。
常见的做法是为应用构建一套测试用例,以确保应用在演进过程中功能保持一致。
这些测试可以在本地和/或 GitHub Actions 等 CI 环境中运行。
入门指南 介绍了应用测试框架以及如何使用 pytest 执行测试。
学习如何初始化和运行模拟应用,包括如何检索、操作和检查应用元素。
进阶内容 解释了如何在应用测试中使用密钥和会话状态,包括如何测试多页面应用。
自动化测试 通过持续集成 (CI) 来验证应用随时间的变化。
示例 综合了上述概念。
查看一个包含多个测试的应用实例。
速查表 是一份简洁的参考,总结了可用的语法。
应用测试入门指南
https://docs.streamlit.io/develop/concepts/app-testing/get-started
本指南将通过一个简单示例展示如何在项目中组织测试结构,以及如何使用pytest执行测试。
了解整体框架后,您可以继续阅读应用测试基础:
- 初始化并运行模拟应用
- 获取页面元素
- 操作交互控件
- 检查运行结果
Streamlit的应用测试框架不限定特定测试工具,但本指南示例将使用Python主流测试框架pytest。
在开始前,请确保已在Streamlit开发环境中安装pytest:
shell
pip install pytest使用 pytest 的简单测试示例
本节将介绍如何用 pytest 构建并运行一个简单测试。
如需全面了解 pytest,请参阅 Real Python 的指南使用 pytest 进行高效 Python 测试。
pytest 的结构解析
pytest 通过特定的文件和函数命名约定来便捷地执行测试。
测试脚本需命名为 test_<名称>.py 或 <名称>_test.py 的形式。
例如,可使用 test_myapp.py 或 myapp_test.py。
在测试脚本中,每个测试需编写为函数形式,且函数名需以 test 开头或结尾。
本指南中的示例将统一采用 test_ 作为测试脚本和测试函数的前缀。
单个测试脚本内可包含任意数量的测试函数。
当在目录中运行 pytest 命令时,该目录下所有 test_<名称>.py 文件(包括子目录中的文件)都会被用于测试。
这些文件中的每个 test_<某名称> 函数都会作为独立测试执行。
测试文件可放置在项目目录的任何位置,但通常建议集中存放到专用的 tests/ 目录。
如需了解其他测试组织与执行方式,请参阅 pytest 文档中的如何调用 pytest。
带应用测试的示例项目
考虑以下项目:
shell
myproject/
├── app.py
└── tests/
└── test_app.py主应用文件:
python
"""app.py"""
import streamlit as st
# Initialize st.session_state.beans
st.session_state.beans = st.session_state.get("beans", 0)
st.title("Bean counter :paw_prints:")
addend = st.number_input("Beans to add", 0, 10)
if st.button("Add"):
st.session_state.beans += addend
st.markdown(f"Beans counted: {st.session_state.beans}")测试文件:
python
"""test_app.py"""
from streamlit.testing.v1 import AppTest
def test_increment_and_add():
"""A user increments the number input, then clicks Add"""
at = AppTest.from_file("app.py").run()
at.number_input[0].increment().run()
at.button[0].click().run()
assert at.markdown[0].value == "Beans counted: 1"在运行应用之前,我们先快速浏览一下这个应用的内容和测试。
主应用文件 (app.py) 渲染时包含四个元素:st.title、st.number_input、st.button 和 st.markdown。
测试脚本 (test_app.py) 包含一个测试(名为 test_increment_and_add 的函数)。
我们将在本指南的后半部分详细介绍测试语法,但这里先简要说明这个测试的功能:
- 初始化模拟应用并执行首次脚本运行。
python
at = AppTest.from_file("app.py").run()2、模拟用户点击加号图标(添加)以增加数字输入(并触发脚本重新运行)。
python
at.number_input[0].increment().run()3、模拟用户点击"添加"按钮(以及由此触发的脚本重新运行)。
python
at.button[0].click().run()4、检查最后是否显示正确的消息。
python
assert at.markdown[0].value == "Beans counted: 1"断言是测试的核心。
当断言为真时,测试通过;当断言为假时,测试失败。
一个测试可以包含多个断言,但保持测试高度聚焦是良好的实践。
当测试专注于单一行为时,更容易理解和应对失败情况。
使用 pytest 进行简单测试
- 将上述文件复制到新建的 "myproject" 目录中
- 打开终端并切换到项目目录
shell
cd myproject3、执行 pytest 命令
shell
pytest测试应成功执行。
您的终端应显示类似以下内容:
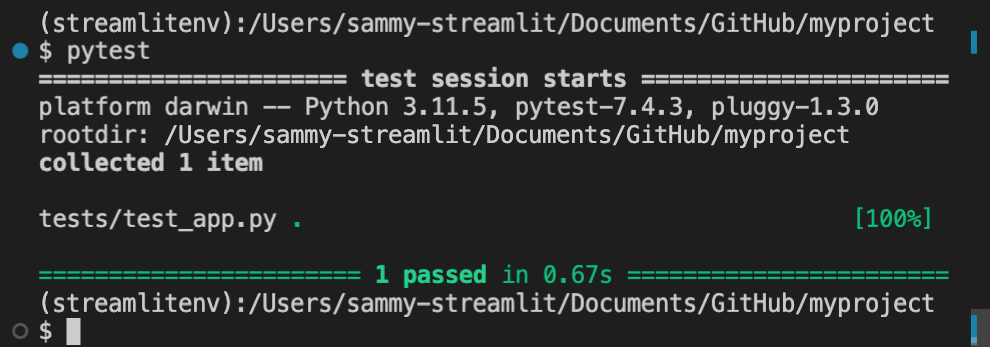
通过在项目根目录执行pytest命令,所有以test前缀(test_<名称>.py)命名的Python文件将被扫描以查找测试函数。
在每个测试文件中,所有以test前缀命名的函数都将作为测试执行。
pytest随后会统计成功案例并详细列出失败项。
您还可以指定pytest仅扫描测试目录。
例如,在项目根目录下执行:
shell
pytest tests/使用 pytest 处理文件路径与导入
测试脚本中的导入和路径应相对于调用 pytest 的目录。
这就是为什么测试函数使用路径 app.py 而非 ../app.py,即使应用文件位于测试脚本的上一级目录。
通常,你会从包含主应用文件的目录调用 pytest。
这通常是项目目录的根目录。
此外,如果在调用 pytest 的目录中存在 .streamlit/ 文件夹,其中任何 config.toml 和 secrets.toml 文件都可被模拟应用访问。
例如,在此常见配置中,你的模拟应用将能访问这些文件:
项目结构:
shell
myproject/
├── .streamlit/
│ ├── config.toml
│ └── secrets.toml
├── app.py
└── tests/
└── test_app.pytest_app.py 中的初始化:
python
# Path to app file is relative to myproject/
at = AppTest.from_file("app.py").run()执行测试的命令:
shell
cd myproject
pytest tests/应用测试基础
现在您已经掌握了pytest的基本用法,接下来让我们深入了解如何使用Streamlit的应用测试框架。
每个测试都从初始化并运行模拟应用开始,随后通过其他命令来获取、操作和检查页面元素。
在下一页中,我们将探索进阶用法,涵盖更复杂的场景,例如处理密钥、会话状态或多页面应用。
如何初始化和运行模拟应用
要测试一个 Streamlit 应用,首先需要用应用单页面的代码初始化一个 AppTest 实例。
初始化模拟应用有三种方法,它们都是 AppTest 的类方法。
我们将重点介绍 AppTest.from_file(),该方法允许你提供应用页面的路径。
这是在应用开发过程中构建自动化测试最常见的场景。
AppTest.from_string() 和 AppTest.from_function() 可能对某些简单或实验性场景有所帮助。
让我们继续使用上面的示例。
回顾测试文件:
python
"""test_app.py"""
from streamlit.testing.v1 import AppTest
def test_increment_and_add():
"""A user increments the number input, then clicks Add"""
at = AppTest.from_file("app.py").run()
at.number_input[0].increment().run()
at.button[0].click().run()
assert at.markdown[0].value == "Beans counted: 1"查看测试函数中的第一行:
at = AppTest.from_file("app.py").run()这相当于同时完成两件事:
# Initialize the app.
at = AppTest.from_file("app.py")
# Run the app.
at.run()AppTest.from_file() 返回一个 AppTest 实例,该实例使用 app.py 的内容进行初始化。
.run() 方法用于首次运行该应用。
观察测试时,请注意 .run() 方法会手动执行每个脚本运行。
每次测试都必须显式运行应用。
这既适用于应用的首次运行,也适用于由模拟用户输入触发的任何重新运行。
如何获取元素
AppTest类的属性返回元素序列。
这些元素按照在渲染应用中的显示顺序进行排序。
可以通过索引获取特定元素。
此外,带有键的部件可以通过键值来获取。
通过索引获取元素
AppTest 的每个属性都会返回对应元素类型的序列。
可以通过索引获取特定元素。
在上面的示例中,at.number_input 返回应用中所有 st.number_input 元素的序列。
因此,at.number_input[0] 表示应用中的第一个此类元素。
类似地,at.markdown 返回所有 st.markdown 元素的集合,其中 at.markdown[0] 是第一个此类元素。
查看 AppTest 类的"Attributes"部分或应用测试速查表以了解当前支持的元素列表。
你也可以使用 .get() 方法并传入属性名称。
at.get("number_input") 和 at.get("markdown") 分别等同于 at.number_input 和 at.markdown。
返回的元素序列按页面上的出现顺序排列。
如果使用容器以不同顺序插入元素,这些序列可能与代码中的顺序不一致。
考虑以下示例,其中使用容器交换了页面上两个按钮的顺序:
python
import streamlit as st
first = st.container()
second = st.container()
second.button("A")
first.button("B")如果测试上述应用,第一个按钮(at.button[0])会显示为"B",而第二个按钮(at.button[1])会显示为"A"。
作为正确的断言,这些结果应为:
assert at.button[0].label == "B"
assert at.button[1].label == "A"通过键值获取小组件
您可以通过小组件的键值而非其在页面上的顺序来获取它们。
小组件的键值可以作为参数(arg)或关键字参数(kwarg)传递。
例如,请看以下应用及其对应的(正确)断言:
python
import streamlit as st
st.button("Next", key="submit")
st.button("Back", key="cancel")
python
assert at.button(key="submit").label == "Next"
assert at.button("cancel").label == "Back"检索容器
您还可以通过检索特定容器来缩小元素序列的范围。
每个检索到的容器都具有与 AppTest 相同的属性。
例如,at.sidebar.checkbox 返回侧边栏中所有复选框的序列,而 at.main.selectbox 则返回应用主体部分(非侧边栏)中所有选择框的序列。
对于 AppTest.columns 和 AppTest.tabs,返回的是容器序列。
因此,at.columns[0].button 表示应用中第一个列内所有按钮的序列。
如何操作控件部件
所有控件部件都拥有通用的.set_value()方法。
此外,许多控件还提供了针对其值的特定操作方法。
测试元素类的名称与AppTest属性高度对应。
例如,通过查看AppTest.button的返回类型,就能找到对应的Button类。
除了使用.set_value()设置按钮值外,还可以调用.click()方法。
具体操作方法请查阅各测试元素类的专属方法说明。
如何检查元素
所有元素(包括小部件)都有一个通用的 .value 属性。
该属性返回元素的内容。
对于小部件来说,这与返回值或 Session State 中的值相同。
对于非输入元素,这将返回主要内容参数的值。
例如,.value 会返回 st.markdown 或 st.error 的 body 值,而对于 st.dataframe 或 st.table,则返回 data 的值。
此外,你还可以检查小部件的许多其他细节,如标签或禁用状态。
许多参数可供检查,但并非全部。
请使用 linting 工具查看当前支持的功能。
以下是一个示例:
python
import streamlit as st
st.selectbox("A", [1,2,3], None, help="Pick a number", placeholder="Pick me")assert at.selectbox[0].value == None
assert at.selectbox[0].label == "A"
assert at.selectbox[0].options == ["1","2","3"]
assert at.selectbox[0].index == None
assert at.selectbox[0].help == "Pick a number"
assert at.selectbox[0].placeholder == "Pick me"
assert at.selectbox[0].disabled == False提示
请注意,st.selectbox的options参数虽然声明为整数类型,但实际上会被断言为字符串类型。
正如st.selectbox文档中所述,选项在内部会被强制转换为字符串。
如果您遇到预期之外的结果,请仔细查阅文档中关于内部类型转换的说明。
超越应用测试基础
https://docs.streamlit.io/develop/concepts/app-testing/beyond-the-basics
现在您已经熟悉如何为Streamlit应用执行基础测试,让我们深入了解AppTest的可变属性:
AppTest.secretsAppTest.session_stateAppTest.query_params
这三个属性都支持通过字典式语法进行值的读取和更新。
对于.secrets和.query_params,您可以使用键标记法但不支持属性标记法。
例如,AppTest的.secrets属性接受at.secrets["my_key"]的写法,但不允许at.secrets.my_key。
这与主库中相关命令的使用方式有所不同。
另一方面,.session_state同时支持键标记法和属性标记法。
使用这些属性时,通常的模式是在首次运行应用前声明所有值。
测试过程中可以随时检查这些值。
对于secrets和Session State还有一些额外注意事项,我们接下来会具体说明。
在应用测试中使用密钥
注意不要直接在测试中包含密钥。
来看一个简单的项目示例,该项目在根目录下执行pytest:
shell
myproject/
├── .streamlit/
│ ├── config.toml
│ └── secrets.toml
├── app.py
└── tests/
└── test_app.py
shell
cd myproject
pytest tests/在上述场景中,您的模拟应用将能够访问 secrets.toml 文件。
但由于您不希望将密钥提交到代码仓库,可能需要编写测试用例来安全地将密钥加载到内存中,或使用模拟密钥进行测试。
示例:在测试中声明密钥
在测试过程中,初始化 AppTest 实例后、首次运行前需要声明每个密钥。
(缺少密钥可能导致应用无法运行!)例如,以下是一个密钥文件及对应的测试初始化代码,用于手动分配相同的密钥:
密钥文件:
yaml
db_username = "Jane"
db_password = "mypassword"
[my_other_secrets]
things_i_like = ["Streamlit", "Python"]测试包含等效密钥的文件:
yaml
# Initialize an AppTest instance.
at = AppTest.from_file("app.py")
# Declare the secrets.
at.secrets["db_username"] = "Jane"
at.secrets["db_password"] = "mypassword"
at.secrets["my_other_secrets.things_i_like"] = ["Streamlit", "Python"]
# Run the app.
at.run()通常,应避免在测试中直接输入密钥。
如果测试不需要真实的密钥,可以像上面的示例那样声明虚拟密钥。
如果应用使用密钥连接外部服务(如数据库或API),建议在应用测试中模拟该服务。
若必须使用真实密钥并实际连接,则应通过API安全且匿名地传递它们。
如果使用GitHub Actions自动化测试,请参阅其安全指南。
python
at.secrets["my_key"] = <value provided through API>在应用测试中使用会话状态
AppTest的.session_state属性允许你通过键值表示法(at.session_state["my_key"])和属性表示法(at.session_state.my_key)来读取和更新会话状态值。
通过手动声明会话状态中的值,你可以直接跳转到特定状态,而无需模拟多个步骤来达到该状态。
此外,测试框架本身不支持多页面应用。
一个AppTest实例只能测试一个页面。
你必须手动声明会话状态值来模拟用户从其他页面携带数据的情况。
示例:测试多页面应用
考虑一个简单的多页面应用,其中第一个页面可以修改会话状态中的某个值。
为了测试第二个页面,需要手动设置会话状态并在测试中运行模拟应用:
项目结构:
shell
myproject/
├── pages/
│ └── second.py
├── first.py
└── tests/
└── test_second.py应用首页:
python
"""first.py"""
import streamlit as st
st.session_state.magic_word = st.session_state.get("magic_word", "Streamlit")
new_word = st.text_input("Magic word:")
if st.button("Set the magic word"):
st.session_state.magic_word = new_word第二应用页面:
python
"""second.py"""
import streamlit as st
st.session_state.magic_word = st.session_state.get("magic_word", "Streamlit")
if st.session_state.magic_word == "Balloons":
st.markdown(":balloon:")测试文件:
python
"""test_second.py"""
from streamlit.testing.v1 import AppTest
def test_balloons():
at = AppTest.from_file("pages/second.py")
at.session_state["magic_word"] = "Balloons"
at.run()
assert at.markdown[0].value == ":balloon:"通过在测试中设置 at.session_state["magic_word"] = "Balloons",可以模拟用户在 first.py 页面输入并保存 "Balloons" 后导航到 second.py 的场景。
使用CI自动化测试
https://docs.streamlit.io/develop/concepts/app-testing/automate-tests
应用测试的一个关键优势是可以通过持续集成(CI)实现测试自动化。
通过在开发过程中自动运行测试,您可以验证对应用的修改不会破坏现有功能。
您可以在提交代码时验证应用逻辑,及早发现错误,并在部署前预防意外故障。
目前有许多流行的CI工具,包括GitHub Actions、Jenkins、GitLab CI、Azure DevOps和Circle CI。
Streamlit应用测试可以像其他Python测试一样轻松与这些工具集成。
GitHub Actions
由于许多Streamlit应用(以及所有Community Cloud应用)都在GitHub上构建,本文档使用GitHub Actions的示例进行说明。
如需了解更多关于GitHub Actions的信息,请参阅:
Streamlit 应用操作
Streamlit App Action 提供了一种简单的方式,为你在 GitHub 上的应用仓库添加自动化测试。
它还包括对应用每个页面的基本冒烟测试,而无需你编写任何测试代码。
要安装 Streamlit App Action,请在你的仓库的 .github/workflows/ 文件夹中添加一个工作流 .yml 文件。
例如:
yaml
# .github/workflows/streamlit-app.yml
name: Streamlit app
on:
push:
branches: ["main"]
pull_request:
branches: ["main"]
permissions:
contents: read
jobs:
streamlit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
- uses: streamlit/streamlit-app-action@v0.0.3
with:
app-path: streamlit_app.py让我们更详细地看看这个操作工作流在做什么。
触发工作流程
yaml
on:
push:
branches: ["main"]
pull_request:
branches: ["main"]该工作流会在针对 main 分支的拉取请求时触发并执行测试,同时也会在向 main 分支推送新提交时运行。
需要注意的是,它还会对所有已开启的拉取请求的后续提交执行测试。
更多信息和示例请参阅 GitHub Actions: 触发工作流。
设置测试环境
yaml
jobs:
streamlit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"工作流包含一个执行一系列步骤的streamlit任务。
该任务运行在使用ubuntu-latest镜像的Docker容器上。
-
actions/checkout@v4从GitHub检出当前仓库代码,并将代码复制到任务环境中。 -
actions/setup-python@v5安装Python 3.11版本。
运行应用测试
yaml
- uses: streamlit/streamlit-app-action@v0.0.3
with:
app-path: streamlit_app.pyStreamlit App Action 执行以下操作:
-
安装
pytest并安装requirements.txt中指定的所有依赖项。 -
运行内置的应用冒烟测试。
-
运行仓库中找到的其他 Python 测试。
提示
如果你的应用仓库根目录下没有包含 requirements.txt 文件,你需要在运行 Streamlit App Action 之前,添加一个步骤来使用你选择的包管理器安装依赖项。
内置的冒烟测试具有以下行为:
- 将
app-path指定的应用作为 AppTest 运行。 - 验证它是否成功完成且未导致未捕获的异常。
- 对
app-path相关的任何额外pages/执行相同的操作。
如果你想在不进行冒烟测试的情况下运行 Streamlit App Action,可以设置 skip-smoke: true。
代码检查
代码检查是指通过自动化工具(也称为 linter)对源代码进行编程和风格错误的检测。
这一过程能有效减少错误并提升代码整体质量,尤其适用于多人协作或公开的代码仓库。
你可以通过向 Streamlit App Action 传递 ruff: true 参数,集成 Ruff 工具来实现自动化代码检查。
yaml
- uses: streamlit/streamlit-app-action@v0.0.3
with:
app-path: streamlit_app.py
ruff: true提示
建议在本地开发环境中添加类似 ruff-pre-commit 的预提交钩子,以便在代码进入 CI 前自动修复格式问题。
查看测试结果
如果测试失败,CI 工作流将终止运行,你可以在 GitHub 上查看结果。
点击进入工作流运行详情页即可查看控制台日志,具体操作见此文档。
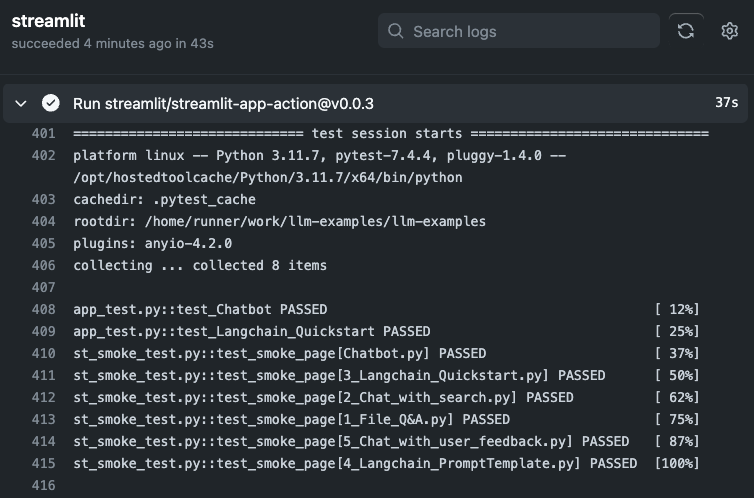
如需查看更高级的测试结果,可以使用 pytest-results-action。
你可以按以下方式将其与 Streamlit App Action 结合使用:
shell
# ... setup as above ...
- uses: streamlit/streamlit-app-action@v0.0.3
with:
app-path: streamlit_app.py
# Add pytest-args to output junit xml
pytest-args: -v --junit-xml=test-results.xml
- if: always()
uses: pmeier/pytest-results-action@v0.6.0
with:
path: test-results.xml
summary: true
display-options: fEX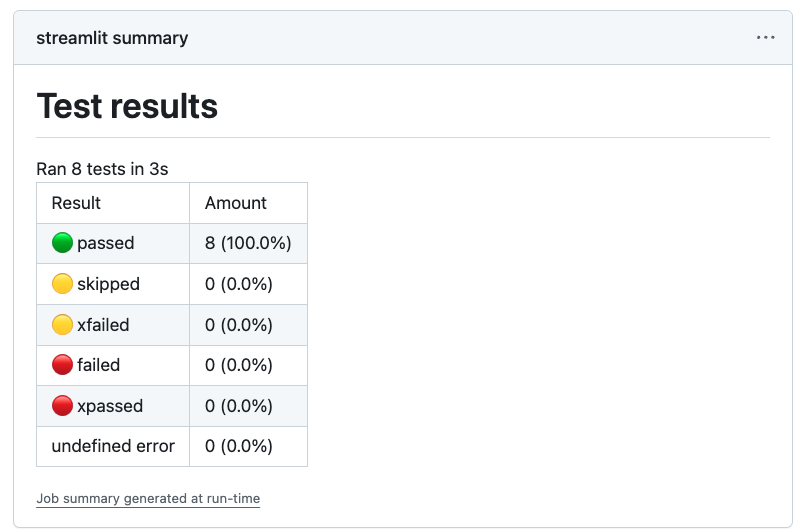
编写自定义操作
以上内容仅作为示例提供。
Streamlit App Action 是一个快速入门的方式。
一旦掌握了所选 CI 工具的基础知识,就能轻松构建和定制自己的自动化工作流。
这是提升开发者整体工作效率和应用质量的绝佳途径。
实际示例
作为最后一个实际示例,请查看我们在 streamlit/llm-examples Actions 中的实现,其定义位于这个工作流文件中。
应用测试示例
https://docs.streamlit.io/develop/concepts/app-testing/examples
测试登录页面
我们以登录页面为例。
在这个示例中,secrets.toml 文件并不存在。
我们将直接在测试中手动声明模拟的密钥。
为了避免时序攻击,登录脚本采用 hmac 来比对用户密码和密钥值,这是推荐的安全实践。
项目概述
登录页面行为
在深入应用程序代码之前,让我们先思考这个页面应该实现哪些功能。
无论您采用测试驱动开发还是编写代码后再写单元测试,预先规划需要测试的功能都是个好主意。
登录页面应具备以下行为:
-
用户与应用交互前:
-
其状态为"未验证"。
-
显示密码输入框。
-
-
当用户输入错误密码时:
-
其状态变为"错误"。
-
显示错误提示信息。
-
清空输入框中的密码尝试。
-
-
当用户输入正确密码时:
-
其状态变为"已验证"。
-
显示确认信息。
-
显示登出按钮(不再显示登录提示)。
-
-
当已登录用户点击登出 按钮时:
-
其状态恢复为"未验证"。
-
重新显示密码输入框。
-
登录页面项目结构
shell
myproject/
├── app.py
└── tests/
└── test_app.py登录页面 Python 文件
页面规范中提到的用户状态存储在 st.session_state.status 中。
该值在脚本开始时初始化为 "unverified",当密码输入框接收到新输入时,会通过回调函数更新此状态值。
python
"""app.py"""
import streamlit as st
import hmac
st.session_state.status = st.session_state.get("status", "unverified")
st.title("My login page")
def check_password():
if hmac.compare_digest(st.session_state.password, st.secrets.password):
st.session_state.status = "verified"
else:
st.session_state.status = "incorrect"
st.session_state.password = ""
def login_prompt():
st.text_input("Enter password:", key="password", on_change=check_password)
if st.session_state.status == "incorrect":
st.warning("Incorrect password. Please try again.")
def logout():
st.session_state.status = "unverified"
def welcome():
st.success("Login successful.")
st.button("Log out", on_click=logout)
if st.session_state.status != "verified":
login_prompt()
st.stop()
welcome()登录页面测试文件
这些测试严格遵循上述应用程序的规范。
在每个测试中,都会先设置一个虚拟密钥,然后运行应用程序并进行后续的模拟和检查。
python
from streamlit.testing.v1 import AppTest
def test_no_interaction():
at = AppTest.from_file("app.py")
at.secrets["password"] = "streamlit"
at.run()
assert at.session_state["status"] == "unverified"
assert len(at.text_input) == 1
assert len(at.warning) == 0
assert len(at.success) == 0
assert len(at.button) == 0
assert at.text_input[0].value == ""
def test_incorrect_password():
at = AppTest.from_file("app.py")
at.secrets["password"] = "streamlit"
at.run()
at.text_input[0].input("balloon").run()
assert at.session_state["status"] == "incorrect"
assert len(at.text_input) == 1
assert len(at.warning) == 1
assert len(at.success) == 0
assert len(at.button) == 0
assert at.text_input[0].value == ""
assert "Incorrect password" in at.warning[0].value
def test_correct_password():
at = AppTest.from_file("app.py")
at.secrets["password"] = "streamlit"
at.run()
at.text_input[0].input("streamlit").run()
assert at.session_state["status"] == "verified"
assert len(at.text_input) == 0
assert len(at.warning) == 0
assert len(at.success) == 1
assert len(at.button) == 1
assert "Login successful" in at.success[0].value
assert at.button[0].label == "Log out"
def test_log_out():
at = AppTest.from_file("app.py")
at.secrets["password"] = "streamlit"
at.session_state["status"] = "verified"
at.run()
at.button[0].click().run()
assert at.session_state["status"] == "unverified"
assert len(at.text_input) == 1
assert len(at.warning) == 0
assert len(at.success) == 0
assert len(at.button) == 0
assert at.text_input[0].value == ""注意到上次测试中会话状态是如何被修改的吗?测试没有完全模拟用户登录过程,而是通过设置at.session_state["status"] = "verified"直接跳转到已登录状态。
运行应用后,测试继续模拟用户注销过程。
自动化测试
如果将 myproject/ 作为代码库推送到 GitHub,你可以通过 Streamlit App Action 添加 GitHub Actions 测试自动化功能。
只需在 myproject/.github/workflows/ 目录下添加一个工作流文件即可实现。
yaml
# .github/workflows/streamlit-app.yml
name: Streamlit app
on:
push:
branches: ["main"]
pull_request:
branches: ["main"]
permissions:
contents: read
jobs:
streamlit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
- uses: streamlit/streamlit-app-action@v0.0.3
with:
app-path: app.py应用测试速查表
https://docs.streamlit.io/develop/concepts/app-testing/cheat-sheet
文本元素
python
from streamlit.testing.v1 import AppTest
at = AppTest.from_file("cheatsheet_app.py")
# Headers
assert "My app" in at.title[0].value
assert "New topic" in at.header[0].value
assert "Interesting sub-topic" in at.subheader[0].value
assert len(at.divider) == 2
# Body / code
assert "Hello, world!" in at.markdown[0].value
assert "import streamlit as st" in at.code[0].value
assert "A cool diagram" in at.caption[0].value
assert "Hello again, world!" in at.text[0].value
assert "\int a x^2 \,dx" in at.latex[0].value输入控件
python
from streamlit.testing.v1 import AppTest
at = AppTest.from_file("cheatsheet_app.py")
# button
assert at.button[0].value == False
at.button[0].click().run()
assert at.button[0].value == True
# checkbox
assert at.checkbox[0].value == False
at.checkbox[0].check().run() # uncheck() is also supported
assert at.checkbox[0].value == True
# color_picker
assert at.color_picker[0].value == "#FFFFFF"
at.color_picker[0].pick("#000000").run()
# date_input
assert at.date_input[0].value == datetime.date(2019, 7, 6)
at.date_input[0].set_value(datetime.date(2022, 12, 21)).run()
# form_submit_button - shows up just like a button
assert at.button[0].value == False
at.button[0].click().run()
assert at.button[0].value == True
# multiselect
assert at.multiselect[0].value == ["foo", "bar"]
at.multiselect[0].select("baz").unselect("foo").run()
# number_input
assert at.number_input[0].value == 5
at.number_input[0].increment().run()
# radio
assert at.radio[0].value == "Bar"
assert at.radio[0].index == 3
at.radio[0].set_value("Foo").run()
# selectbox
assert at.selectbox[0].value == "Bar"
assert at.selectbox[0].index == 3
at.selectbox[0].set_value("Foo").run()
# select_slider
assert at.select_slider[0].value == "Feb"
at.select_slider[0].set_value("Mar").run()
at.select_slider[0].set_range("Apr", "Jun").run()
# slider
assert at.slider[0].value == 2
at.slider[0].set_value(3).run()
at.slider[0].set_range(4, 6).run()
# text_area
assert at.text_area[0].value == "Hello, world!"
at.text_area[0].set_value("Hello, yourself!").run()
# text_input
assert at.text_input[0].value == "Hello, world!")
at.text_input[0].set_value("Hello, yourself!").run()
# time_input
assert at.time_input[0].value == datetime.time(8, 45)
at.time_input[0].set_value(datetime.time(12, 30))
# toggle
assert at.toggle[0].value == False
assert at.toggle[0].label == "Debug mode"
at.toggle[0].set_value(True).run()
assert at.toggle[0].value == True数据元素
python
from streamlit.testing.v1 import AppTest
at = AppTest.from_file("cheatsheet_app.py")
# dataframe
expected_df = pd.DataFrame([1, 2, 3])
assert at.dataframe[0].value.equals(expected_df)
# metric
assert at.metric[0].value == "9500"
assert at.metric[0].delta == "1000"
# json
assert at.json[0].value == '["hi", {"foo": "bar"}]'
# table
table_df = pd.DataFrame([1, 2, 3])
assert at.table[0].value.equals(table_df)布局与容器
python
from streamlit.testing.v1 import AppTest
at = AppTest.from_file("cheatsheet_app.py")
# sidebar
at.sidebar.text_input[0].set_value("Jane Doe")
# columns
at.columns[1].markdown[0].value == "Hello, world!"
# tabs
at.tabs[2].markdown[0].value == "Hello, yourself!"聊天元素
python
from streamlit.testing.v1 import AppTest
at = AppTest.from_file("cheatsheet_app.py")
# chat_input
at.chat_input[0].set_value("Do you know any jokes?").run()
# Note: chat_input value clears after every re-run (like in a real app)
# chat_message
assert at.chat_message[0].markdown[0].value == "Do you know any jokes?"
assert at.chat_message[0].avatar == "user"状态元素
python
from streamlit.testing.v1 import AppTest
at = AppTest.from_file("cheatsheet_app.py")
# exception
assert len(at.exception) == 1
assert "TypeError" in at.exception[0].value
# Other in-line alerts: success, info, warning, error
assert at.success[0].value == "Great job!"
assert at.info[0].value == "Please enter an API key to continue"
assert at.warning[0].value == "Sorry, the passwords didn't match"
assert at.error[0].value == "Something went wrong :("
# toast
assert at.toast[0].value == "That was lit!" and at.toast[0].icon == "🔥"限制说明
截至 Streamlit 1.28 版本,AppTest 尚未原生支持以下 Streamlit 功能。
但通过使用 AppTest.get() 直接检查底层 proto 数据,许多功能可以找到变通方案。
我们计划持续添加对缺失元素的支持,直至覆盖所有功能。
- 图表元素(
st.bar_chart、st.line_chart等) - 媒体元素(
st.image、st.video、st.audio) st.file_uploaderst.data_editorst.expanderst.statusst.camera_inputst.download_buttonst.link_button