🧩 带哨兵位的双向循环链表详解(含 C 代码)+ LeetCode138 深度解析 + 顺序表 vs 链表缓存机制对比(图解 CPU 层级)
🚀 本文是我个人 Gitee 数据结构项目的一部分学习笔记,结合了:
① 带哨兵的双向循环链表实现
② LeetCode 高频题:复制带随机指针的链表
③ 顺序表 vs 链表的缓存命中率分析
④ CPU / Cache / 内存层次结构图讲解(与数据结构性能结合)适合正在学习链表、指针、动态内存管理、性能优化的同学作为深度参考。
📑 目录
- 一、什么是带哨兵位的双向循环链表?
- 二、完整 C 语言实现:带哨兵节点的双向循环链表
- 三、LeetCode138:复制带随机指针的链表(代码 + 逐行解析)
- 四、顺序表 vs 链表:真正的差异并不只是"是否连续"
- 五、缓存机制:为什么链表天生比数组慢?
- 六、CPU 与内存层级结构图(图解 + 程序性能)
- 七、全文总结
- 八、参考与扩展阅读(含你的代码仓库)
🧵 一、带哨兵位的双向循环链表(概念讲解)
双向循环链表大家都见过,但加上哨兵位(dummy / sentinel)之后,链表结构会变得 极其优雅 :
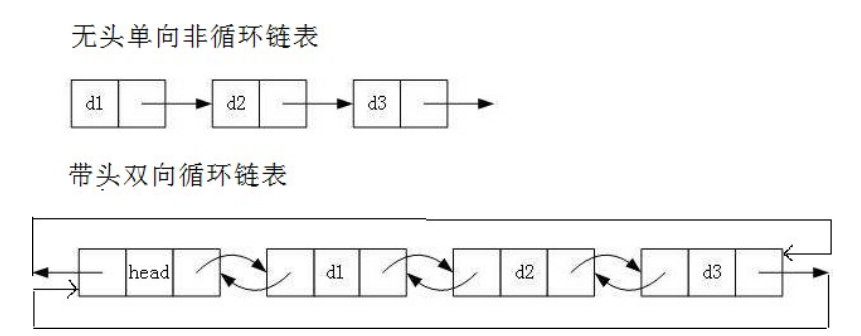
✔ 为什么要用哨兵位?
- 不用处理 "空链表" 特殊情况
- 插入删除不需判断 "头/尾节点"
- 所有操作逻辑统一
- 更适合在工程里维护(比如模拟 STL list)
🔧 链表示意图:
[head] <-> node1 <-> node2 <-> ... <-> nodeN <-> [head]这个 head 节点:
- 不存放数据
- 只是链表的"标志位"
- 永远存在,避免大量 if 判断
🧰 二、完整 C 语言实现:带哨兵节点双向循环链表
以下是一个可直接运行、包含常用功能的链表模板。
链接如下:
带哨兵位的双向循环链表
⭐ 写法亮点
- 插入、删除不需要 if 判断
- 逻辑统一,不容易写出越界 Bug
- 是工程里真正推荐的链表写法
🔍 三、LeetCode138:复制带随机指针的链表(代码逐行解析)
这是 LeetCode 高频题,题目如下:
- 每个节点不仅有
next,还有一个random - 要深拷贝链表(包括
random指向的任意节点) - 不能用额外哈希表的做法(需要 O(1) 空间)
你提供的 C 代码如下,我会完整解释:
c
struct Node* copyRandomList(struct Node* head) {
// 1. 将拷贝节点插入到原节点后面
struct Node* cur = head;
while (cur) {
struct Node* copy = malloc(sizeof(struct Node));
copy->val = cur->val;
struct Node* next = cur->next;
cur->next = copy;
copy->next = next;
cur = next;
}
// 2. 设置 copy 的 random
cur = head;
while(cur){
struct Node* copy = cur->next;
if(cur->random == NULL)
copy->random = NULL;
else
copy->random = cur->random->next;
cur = cur->next->next;
}
// 3. 拆出拷贝链表,恢复原链表
struct Node* copyhead = NULL, *copyTail = NULL;
cur = head;
while(cur){
struct Node* copy = cur->next;
struct Node* next = copy->next;
// 拷贝链表的构建
if(copyhead == NULL){
copyhead = copyTail = copy;
} else {
copyTail->next = copy;
copyTail = copyTail->next;
}
// 恢复原链表
cur->next = next;
cur = next;
}
return copyhead;
}🧠 三步法总结(必须掌握)
1)插入拷贝节点
让 A → A' → B → B' → C → C'
复制节点紧跟在原节点后面。
2)设置 random
因为 copy 紧跟在原节点后面,所以:
copy->random = cur->random->next3)把链表拆分成两个
同时恢复原链表结构。
✔ 时间复杂度:O(n)
✔ 空间复杂度:O(1)
经典、优雅、值得背下来的写法。
四、顺序表 vs 链表:真正的差异不只是"连续 vs 不连续"
教材常说:
| 特性 | 数组(顺序表) | 链表 |
|---|---|---|
| 存储 | 连续 | 不连续 |
| 随机访问 | O(1) | 不支持 |
| 插入删除 | 代价大 | O(1) |
但这只是"表面差异"。
真正的性能差异来自 CPU 缓存命中率。
⚡ 五、缓存机制:为什么链表比数组慢几十倍?
因为 CPU 和内存的速度差距巨大:
- CPU:1ns
- DRAM:100ns(慢 100 倍)
- SSD:0.1ms
- HDD:10ms
所以 CPU 必须依赖 L1/L2/L3 Cache 才能跑快。
✔ 数组:连续 → 缓存命中率极高
- CPU 会一次加载一个缓存行(64B)
- 连续的元素会被一并读入
- CPU 可以预取(Prefetching)
遍历数组几乎是"满速运行",稳定高性能。
✔ 链表:离散 → 容易 cache miss
由于每个节点是 malloc 的:
- 节点分布在堆内存的任意位置
- 每次访问
next都是跳到未知地址 - CPU 无法预测
- 缓存失效率高 → 内存延迟巨大 → 性能暴跌
所以链表慢不是结构复杂,而是缓存友好性太差。
面试官很喜欢问。
🧠 六、CPU 与内存层级结构图
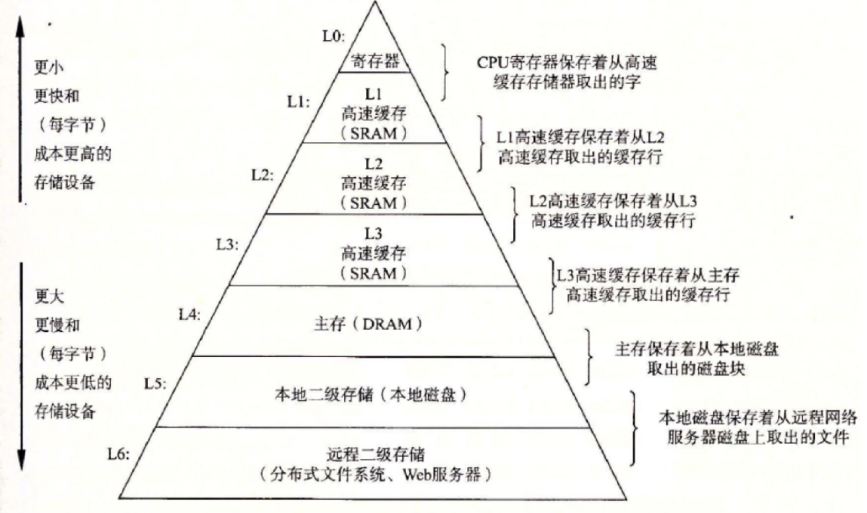
业界经典的存储金字塔:
CPU Register(最快)
L1 Cache
L2 Cache
L3 Cache
主存 DRAM
本地磁盘 SSD / HDD
远程存储越往上:
- 更小
- 更贵
- 更快
越往下:
- 更大
- 更慢
- 更便宜
这就是为什么:
💡 数据结构并不只看时间复杂度,还要看"局部性原理"。
链表违反了缓存友好性 → 性能差
数组满足缓存友好性 → 性能爆炸
📝 七、总结(非常重要)
本文用"结构 + 工程实践 + 性能理解"三条线讲解链表,让你真正理解链表在系统中的表现。
✔ 1. 链表结构
带哨兵位的双向循环链表 ------ 写法最优雅、最稳定。
✔ 2. 算法实践
LeetCode138 ------ 经典"三步法" + 原地复制技巧。
✔ 3. 系统性能
顺序表和链表最大差异不是 "是否连续",而是:
- 缓存命中率
- 预取机制
- 指令流水线友好度
- CPU/Memory 性能鸿沟
这是数据结构真正与体系结构结合的部分,也是进阶程序员必学内容。
🔗 八、参考与扩展阅读
📌 代码仓库(Gitee)
📚 进阶推荐
- 《深入理解计算机系统》
- 酷壳(陈皓):https://coolshell.cn/articles/20793.htm