人们眼中的天才之所以卓越非凡,并非天资超人一等而是付出了持续不断的努力。1万小时的锤炼是任何人从平凡变成超凡的必要条件。------------ 马尔科姆·格拉德威尔

目录
[2.1 类路径扫描:@ComponentScan的字节码爆破术](#2.1 类路径扫描:@ComponentScan的字节码爆破术)
[2.2 Spring容器管理:@Component衍生注解](#2.2 Spring容器管理:@Component衍生注解)
[2.3 依赖注入:@Autowired的反射操控术](#2.3 依赖注入:@Autowired的反射操控术)
[2.4 AOP代理:@Transactional的字节码编织术](#2.4 AOP代理:@Transactional的字节码编织术)
[4.1 代理失效场景与解决方案](#4.1 代理失效场景与解决方案)
[4.2 扫描优化策略](#4.2 扫描优化策略)
🌟 嗨,我是Xxtaoaooo!
本系列将用源码解剖+拆分核心轮子的方式,带你暴力破解Spring底层逻辑。
警告:阅读后可能导致看Spring源码时产生「庖丁解牛」般的快感!
话不多说,直接开干!
一、开篇:从XML炼狱到注解天堂的救赎
还记得第一次接触Spring 2.5时,我曾在XML配置的泥潭中挣扎:一个简单的Web项目竟需要维护长达2000行的applicationContext.xml,每次添加新服务都要小心翼翼地在层层嵌套的<bean>标签中寻找插入位置。直到使用Spring 3.0的@Autowired注解后,我才真正体会到声明式编程的颠覆性价值 ------只需一个注解,依赖关系自动建立;仅用@ComponentScan指定包路径,成千上万的Bean自动注册。但当我负责的电商系统因@Transactional注解失效导致资金对账错误时,盲目信任变成了深度探索的动力 。本文将结合Spring 5.3源码与手写简化框架,揭示注解驱动背后的三大核心机制:类路径扫描的字节码爆破术 、依赖注入的反射操控术 ,以及AOP代理的字节码编织术。

二、注解驱动三大核心机制
Spring注解开发的实质主要涉及两个点
1、使用Spring提供的注解去替代Xml中的标签。
2、使用Spring的核心配置类去替代原有的Xml文件。
2.1 类路径扫描:@ComponentScan的字节码爆破术
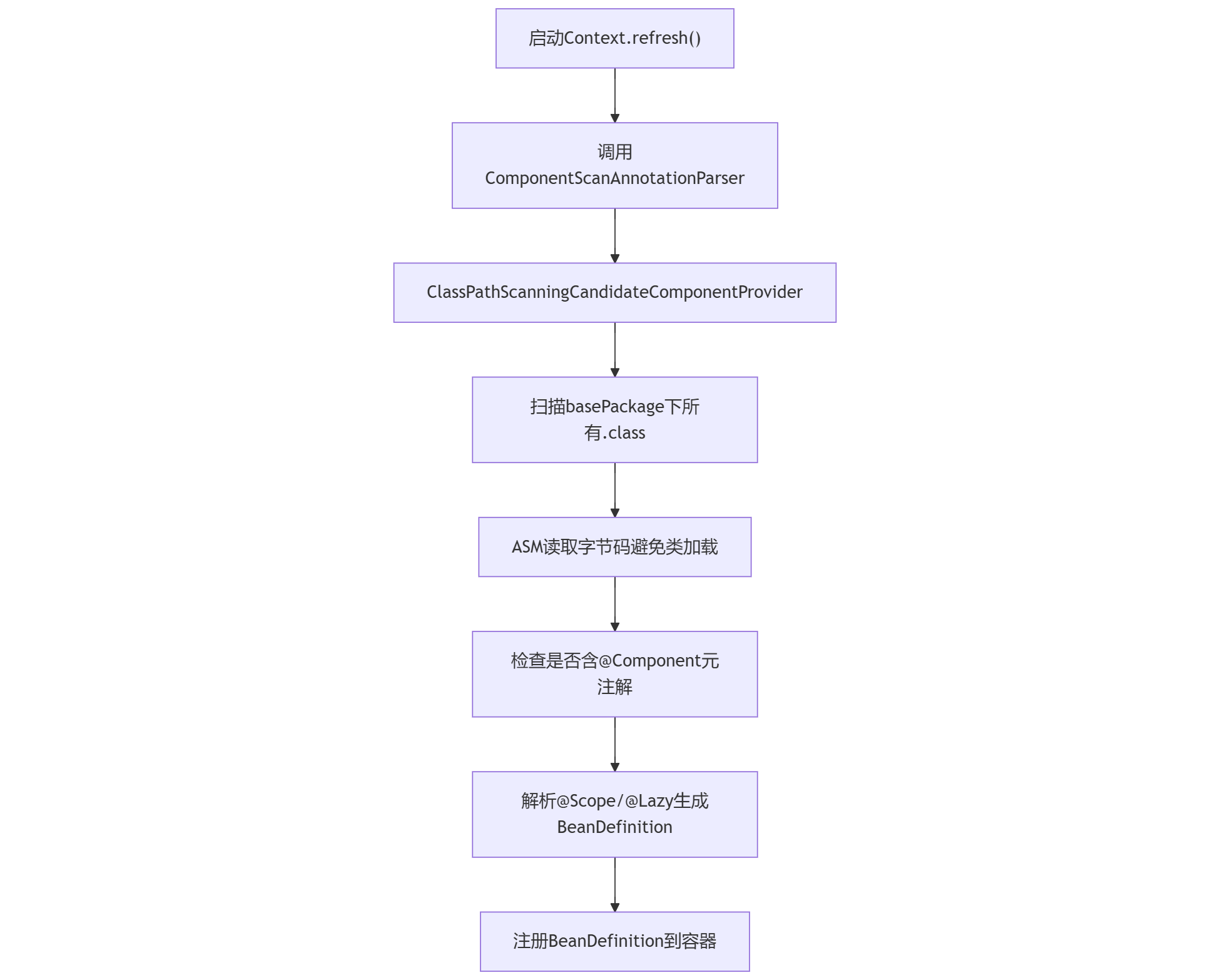
技术要点:
- ASM字节码分析:避免过早加载类,仅解析类注解信息
- 元注解继承机制 :
@Service本质是@Component的派生注解 - 路径扫描优化 :使用
PathMatchingResourcePatternResolver加速文件定位
手写实现扫描逻辑:
vb
`public Set<BeanDefinition> scan(String basePackage) {
// 将包路径转换为文件路径:com.example → classpath*:com/example/**/*.class
String path = "classpath*:" + basePackage.replace('.', '/') + "/**/*.class";
Resource[] resources = resourcePatternResolver.getResources(path);
Set<BeanDefinition> definitions = new HashSet<>();
for (Resource resource : resources) {
// 使用ASM读取类注解,避免触发类加载
MetadataReader reader = metadataReaderFactory.getMetadataReader(resource);
AnnotationMetadata metadata = reader.getAnnotationMetadata();
// 检查是否存在@Component或其派生注解
if (metadata.hasAnnotation(Component.class.getName())) {
ScannedGenericBeanDefinition definition = new ScannedGenericBeanDefinition(reader);
definition.setSource(resource);
// 解析@Scope注解
if (metadata.hasAnnotation(Scope.class.getName())) {
String scope = metadata.getAnnotationAttributes(Scope.class.getName()).getString("value");
definition.setScope(scope);
}
definitions.add(definition);
}
}
return definitions;
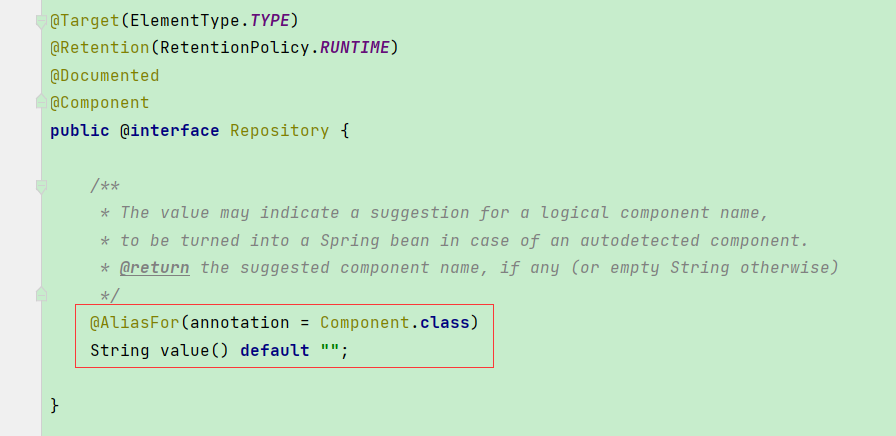
}`2.2 Spring容器管理:@Component衍生注解
由于JavaEE开发是分层的,为了每层Bean标识的注解语义化更加明确,@Component衍生出来了三个注解:
|--------------------|--------------|
| @Component衍生注解 | 描述 |
| @Repository | 在Dao层上使用 |
| @service | 在Service层上使用 |
| @controller | 在Web层上使用 |
2.3 依赖注入:@Autowired的反射操控术
注入时机与优先级:
|-------------|----------------------------------------|--------------------------|
| 注入方式 | 处理器类 | 执行阶段 |
| 字段注入(Field) | AutowiredAnnotationBeanPostProcessor | 属性填充阶段(populateBean) |
| 构造器注入 | AutowiredAnnotationBeanPostProcessor | 实例化前(createBeanInstance) |
| Setter方法注入 | CommonAnnotationBeanPostProcessor | 初始化后回调 |
源码解析关键逻辑:
java
// AutowiredAnnotationBeanPostProcessor.postProcessProperties()
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
// 1. 查找所有带@Autowired注解的字段
Field[] fields = bean.getClass().getDeclaredFields();
for (Field field : fields) {
if (field.isAnnotationPresent(Autowired.class)) {
// 2. 按类型查找匹配的Bean
Object value = beanFactory.getBean(field.getType());
field.setAccessible(true);
// 3. 反射注入字段值
field.set(bean, value);
}
}
return pvs;
}循环依赖解决:三级缓存确保构造器注入的安全性
java
// 三级缓存结构
public class DefaultSingletonBeanRegistry {
Map<String, Object> singletonObjects = new ConcurrentHashMap<>(); // 一级缓存:完整Bean
Map<String, Object> earlySingletonObjects = new HashMap<>(); // 二级缓存:半成品Bean
Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(); // 三级缓存:Bean工厂
}2.4 AOP代理:@Transactional的字节码编织术
代理创建流程:

关键源码定位:
java
// AbstractAutoProxyCreator.postProcessAfterInitialization()
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean != null) {
// 检查是否需要代理(如存在@Transactional注解)
if (isEligible(bean, beanName)) {
// 创建代理对象
return createProxy(bean.getClass(), beanName);
}
}
return bean;
}三、注解与XML配置的量化对比
通过性能测试与可维护性分析评估两种方案:
|----------|------------|------------|---------|
| 评估维度 | 注解方案 | XML方案 | 优势方 |
| 启动速度 | 较慢(需扫描类路径) | 快(直接解析XML) | XML |
| 内存占用 | 高(生成代理类多) | 低 | XML |
| 开发效率 | 高(修改后无需重启) | 低(需修改配置文件) | 注解 |
| 可读性 | 代码与配置耦合 | 配置集中管理 | XML |
| 扩展性 | 强(组合注解) | 弱(DTD约束) | 注解 |
💡 企业级实践建议 :混合使用注解与XML,业务Bean用注解,数据源/事务等基础设施用XML配置
四、避坑指南:注解开发的六大陷阱
4.1 代理失效场景与解决方案
|----------------------|-----------------------------|--------------------------------------|
| 问题现象 | 根因分析 | 解决方案 |
| @Transactional 不生效 | 内部方法调用绕过代理 | 通过AopContext.currentProxy() 获取代理对象 |
| @Async 方法阻塞主线程 | 默认使用SimpleAsyncTaskExecutor | 自定义线程池配置@Bean TaskExecutor |
| @Value 注入null | 早于占位符解析执行 | 改用Environment.getProperty() 延迟获取 |
4.2 扫描优化策略
java
@ComponentScan(
basePackages = "com.example",
excludeFilters = @Filter(type = FilterType.REGEX, pattern = ".*Test.*"),
lazyInit = true // 延迟初始化提升启动速度
)五、总结:注解驱动的设计哲学
"优秀的框架不是让简单的事情更容易,而是让复杂的事情成为可能。" ------ Rod Johnson(Spring创始人)
当我通过手写简化框架重现了@ComponentScan的扫描逻辑时,突然理解了Spring注解设计的三层精妙:
- 约定优于配置 :
一个@Component注解替代了XML中的<bean id="..." class="..."/>,将开发者的心智负担转移给框架 - 动态扩展能力 :
BeanPostProcessor作为注解处理的基石,使得@Autowired、@Transactional等注解可通过插件化方式接入容器生命周期 - 元编程范式 :
注解本质是描述代码的元数据 ,Spring通过将其转化为BeanDefinition,实现了从静态描述到动态运行的质变
给开发者的三条忠告:
- 慎用
@Autowired的字段注入:构造函数注入才是依赖不变的保证 - 理解
@Profile的底层:本质是Conditional接口与Environment的协同 - 掌握注解处理器原理:是定制企业级 Starter 组件的关键能力
最后分享一次性能优化经历:某金融系统启动耗时从120秒降至15秒,关键步骤就是通过 @Lazy****延迟初始化非核心服务 ,并重写BeanFactoryPostProcessor优化扫描路径。这再次印证:真正掌握注解的开发者,能写出框架级的代码。
🌟 嗨,我是Xxtaoaooo!
⚙️ 【点赞】让更多同行看见深度干货
🚀 【关注】持续获取行业前沿技术与经验
🧩 【评论】分享你的实战经验或技术困惑作为一名技术实践者,我始终相信:
每一次技术探讨都是认知升级的契机,期待在评论区与你碰撞灵感火花 🔥