网络层
- [IPv4 分组(数据报)](#IPv4 分组(数据报))
- IP地址(分类编址,最初阶段)
- 子网划分和子网掩码(重难点)
- 无分类编制(CIDR)
- NAT
- ARP协议
- DHCP协议
- ICMP协议
前言
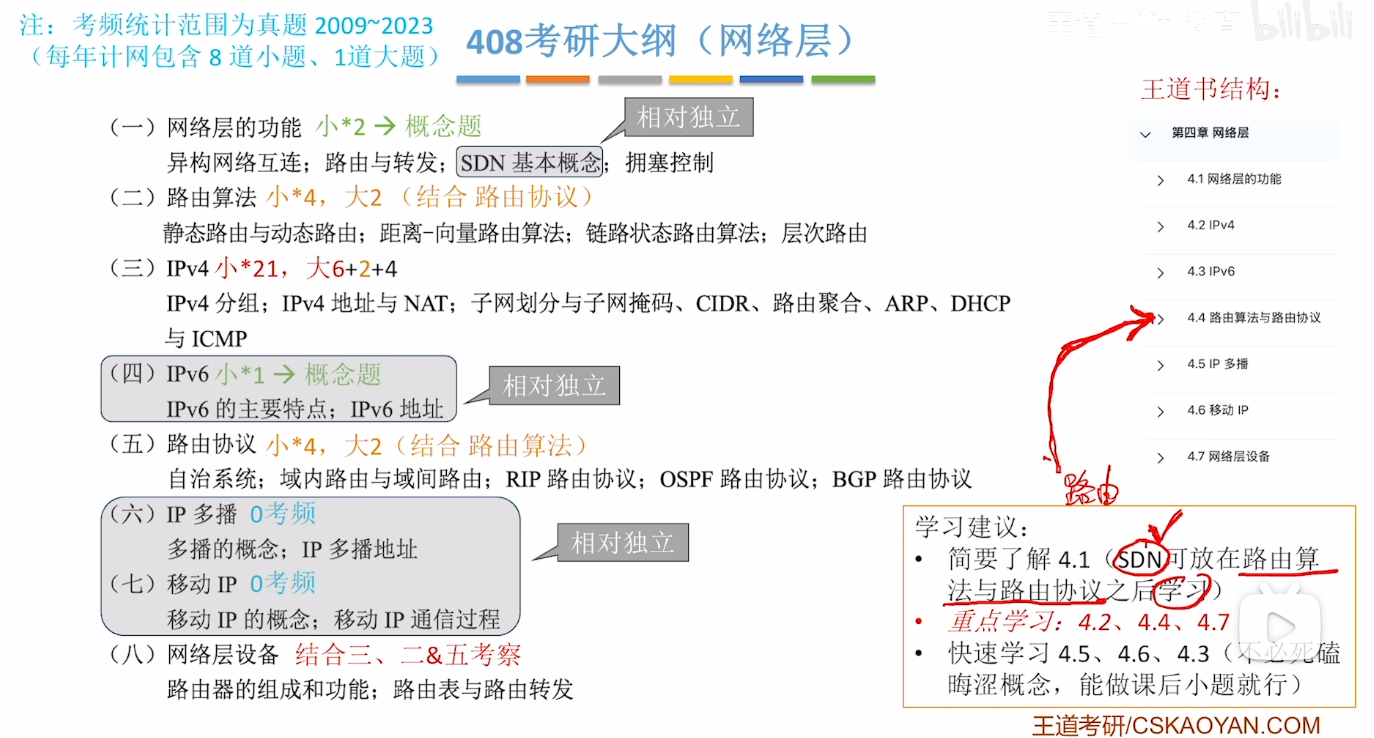
- 对于网络层这一章里面 最重要的就是IPv4 是最高频的考点 同时也是比较难以理解的知识点 常常在真题里面结合答题进行考察
- 学习顺序:
- IP分组------最初的IP地址------子网划分与子网掩码------CIDR(无分类编址)------NAT(网络地址转换)(符合时代的发展顺序)
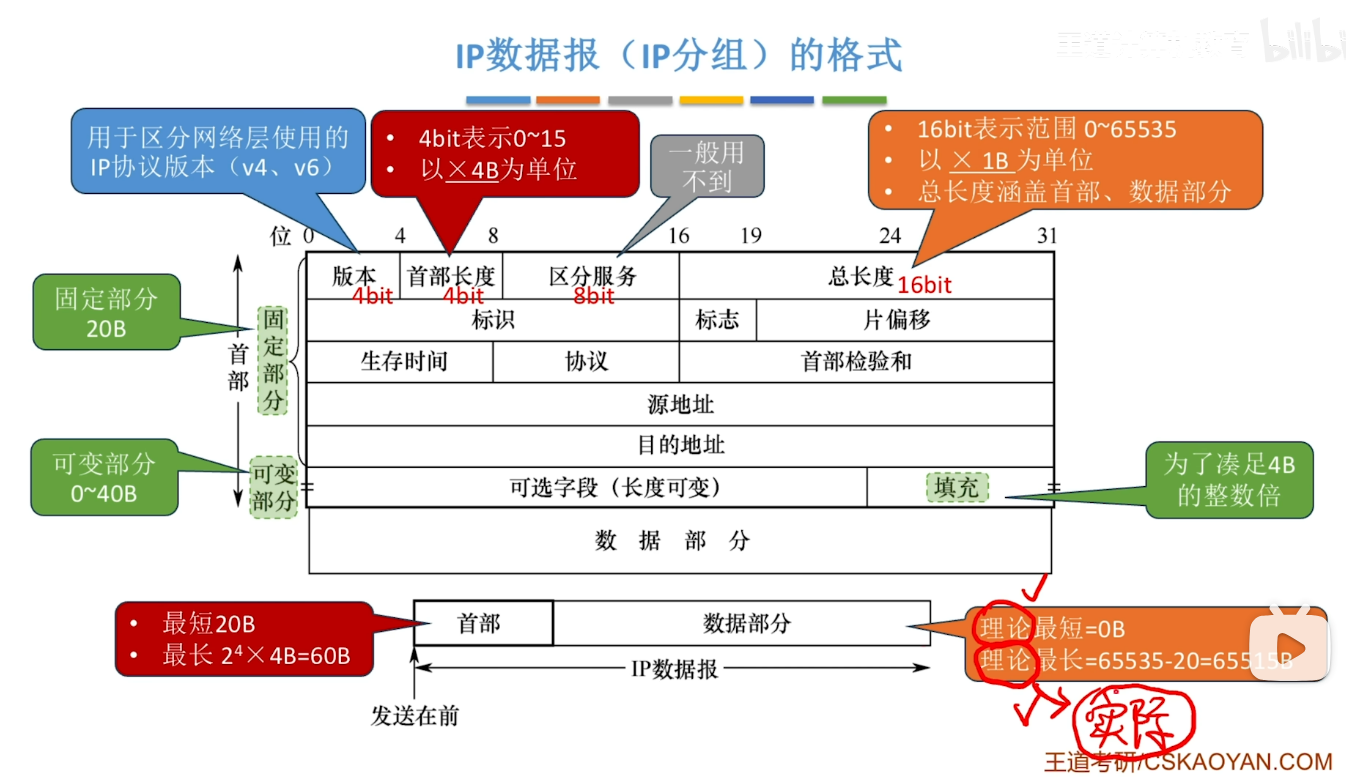
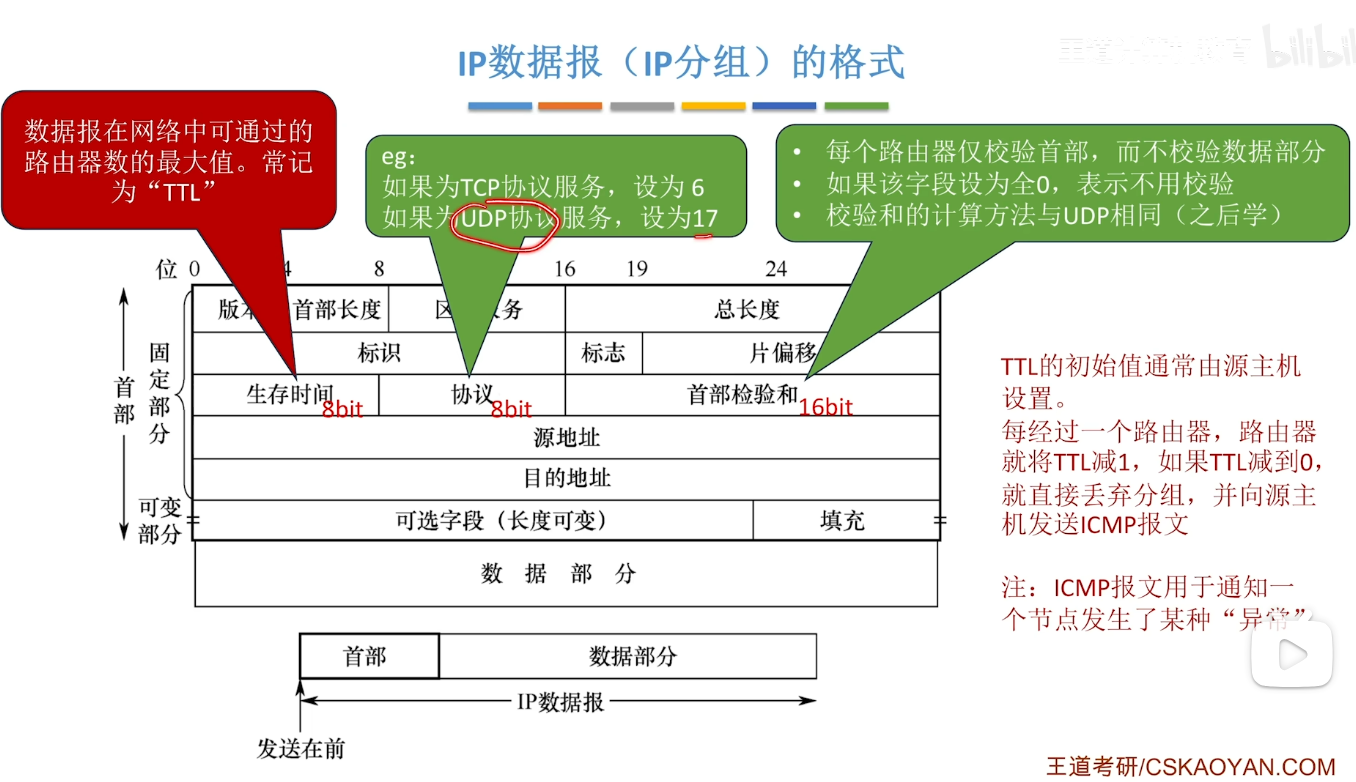
IPv4 分组(数据报)
- 首先我们需要知道的是IPv4 到底是什么东西 我们要有一个认知
- 它其实是需要拆成 IP 与 v4两部分来理解的
- IP指的是IP协议 v4指的是这个协议的版本号
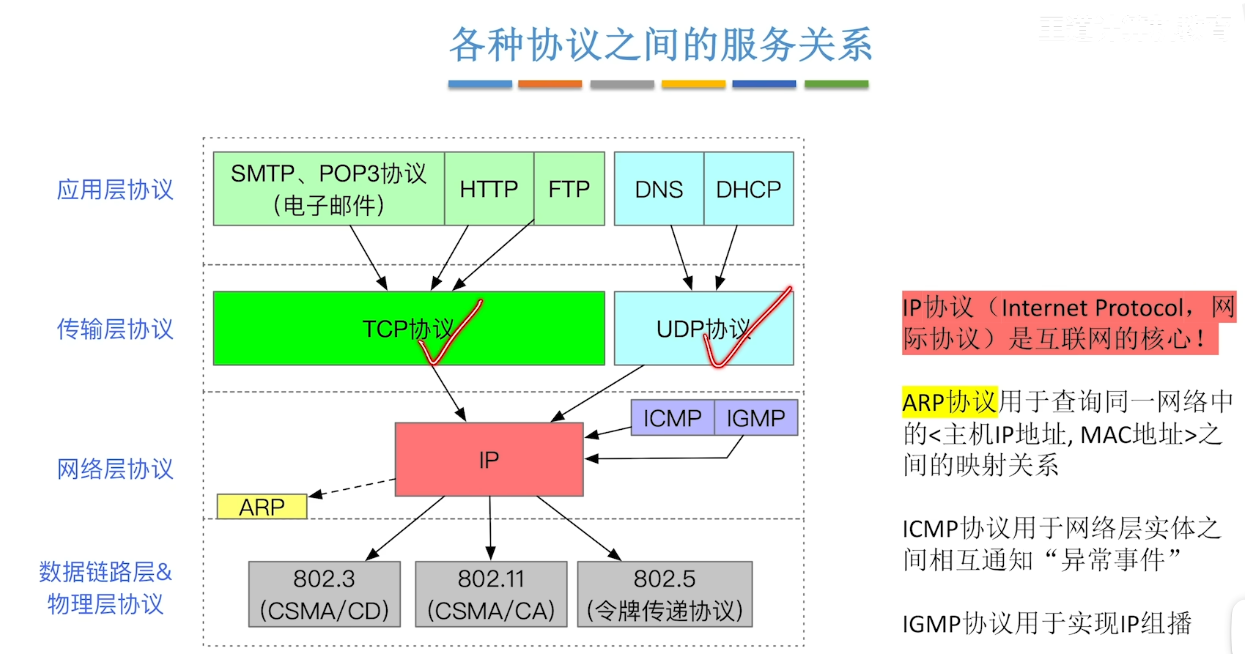
- 这里如果你已经学完了网络层的知识 在回过头来看下面这张图片的时候就不那么难绷了
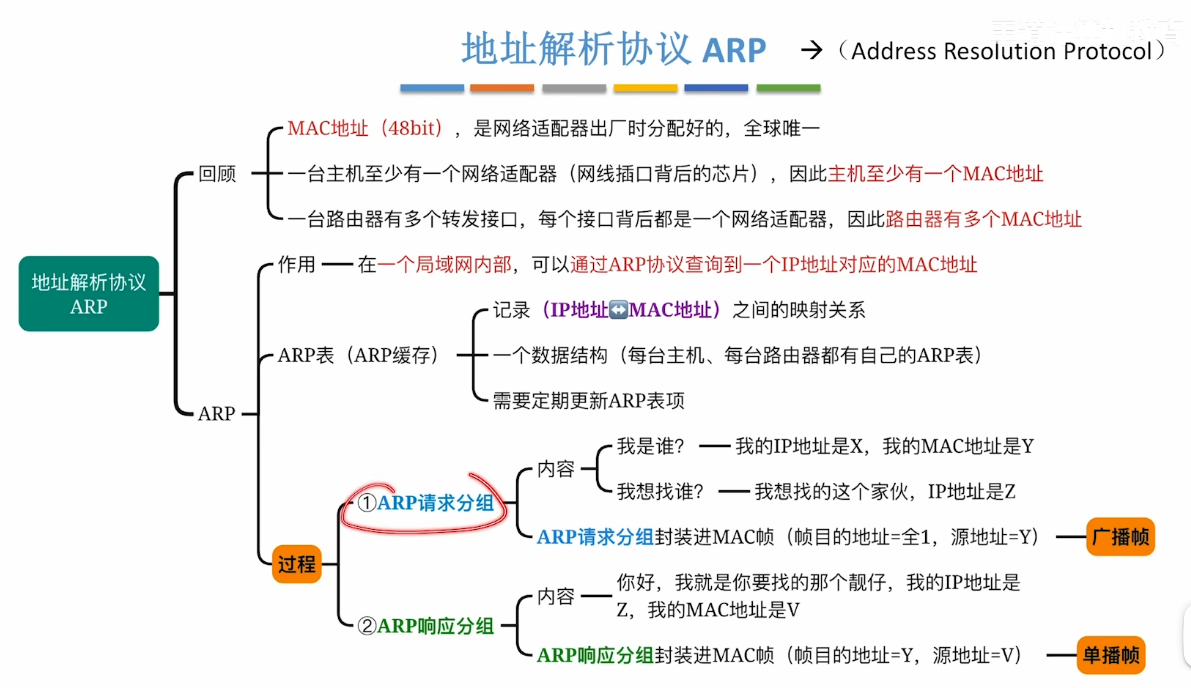
- 对于我们一直说的ARP协议 就是建立一个主机IP地址与MAC地址的映射(类似于Map)
- 举个例子 我们如果传输了一个无效的IP数据报时(比如当一个大的数据报需要分片 但是DF=1的时候) 路由器就会将这个IP数据报丢弃 同时需要给源主机发送ICMP报文 通知异常情况
格式
-
第一层
-
第二层
-
第三层
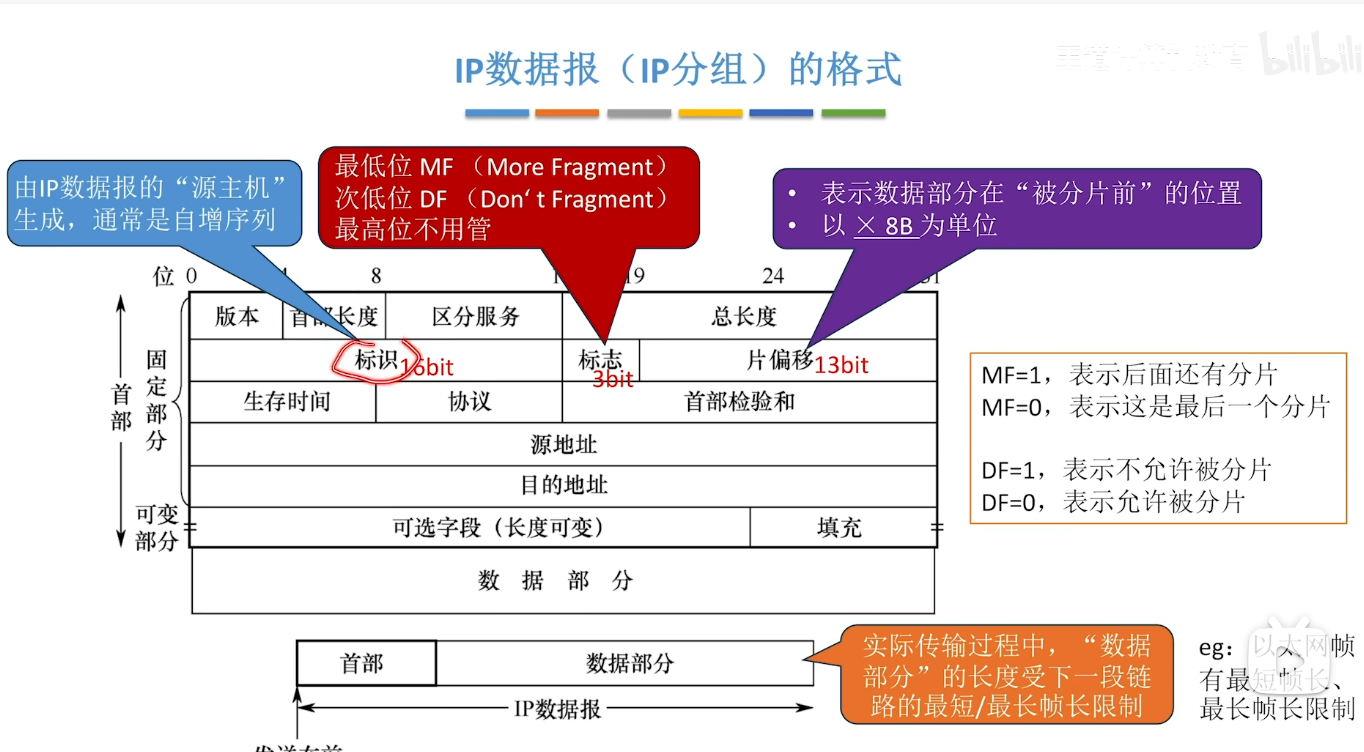
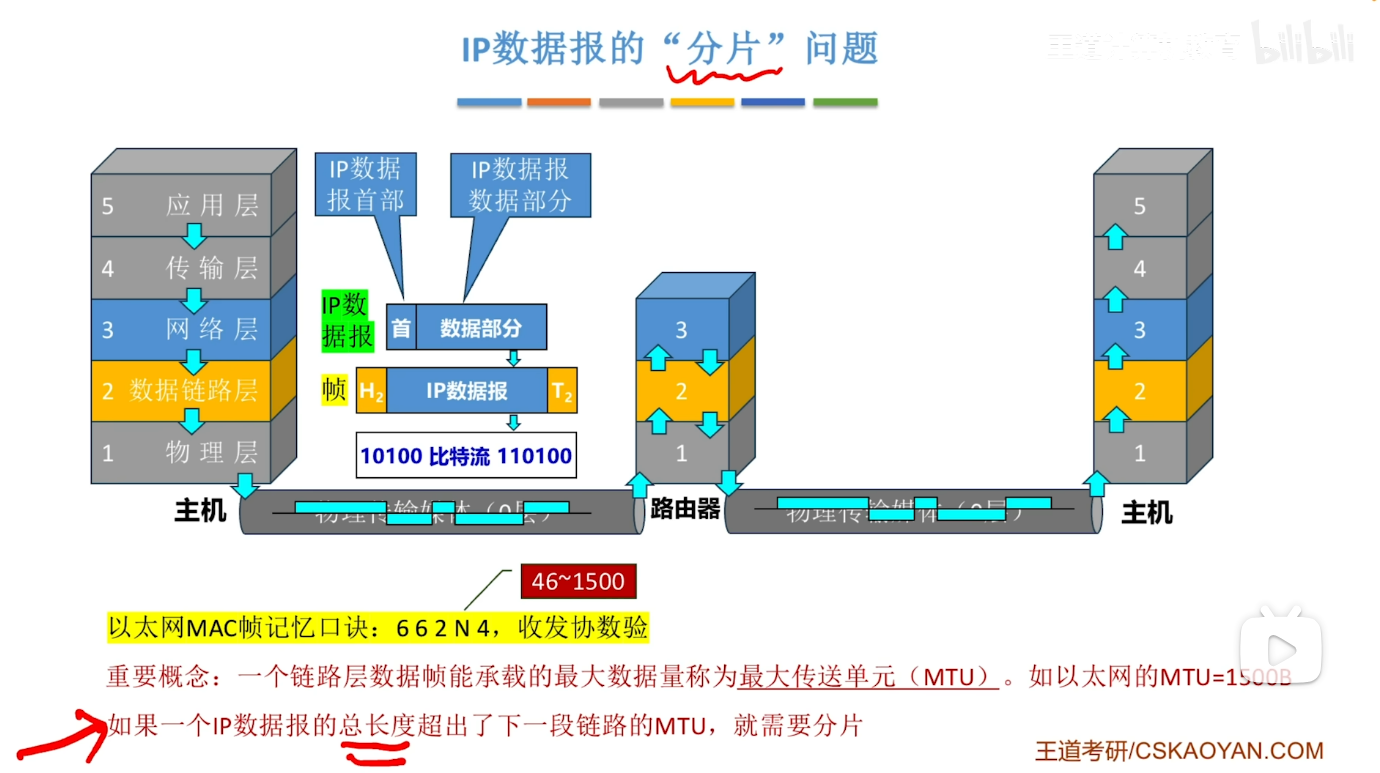
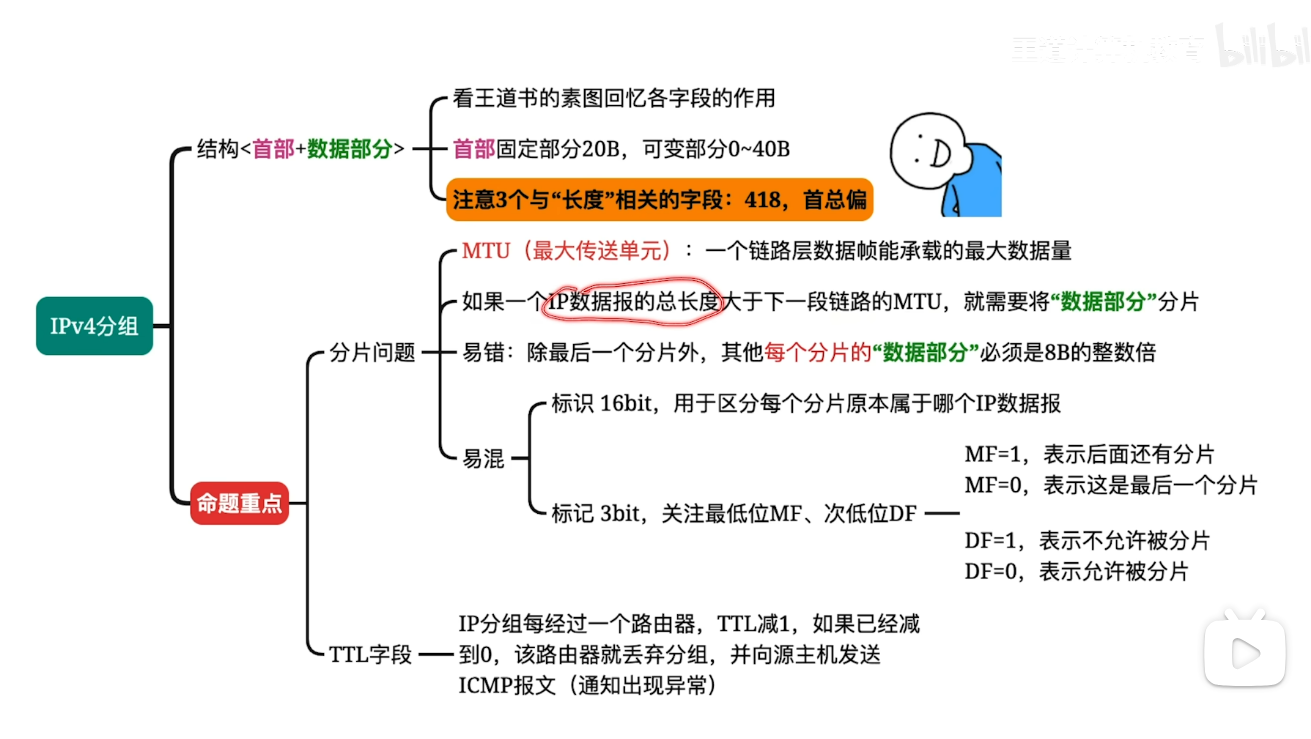
IP数据报的"分片"问题
分片大小与片偏移问题
- 案例
- 对于分片大小:
- 如下图所示 我们在链路二上传输的时候 发现MTU 仅仅为1500(我一般记忆为max transmit unit)
- 此时我们就需要对IP数据报进行分片 这里的每一个分片都是一个新的IP数据报 其同样遵循我们前面所提到的IP数据报的格式 也就是首部+数据部分
- 我们就假设首部为最小的20B 则实际上我们前两个1500B大小的数据报里面只有1480B的数据 所以最后一个IP数据报的数据部分大小自然而然的就是(3980-1480-1480=1020B)
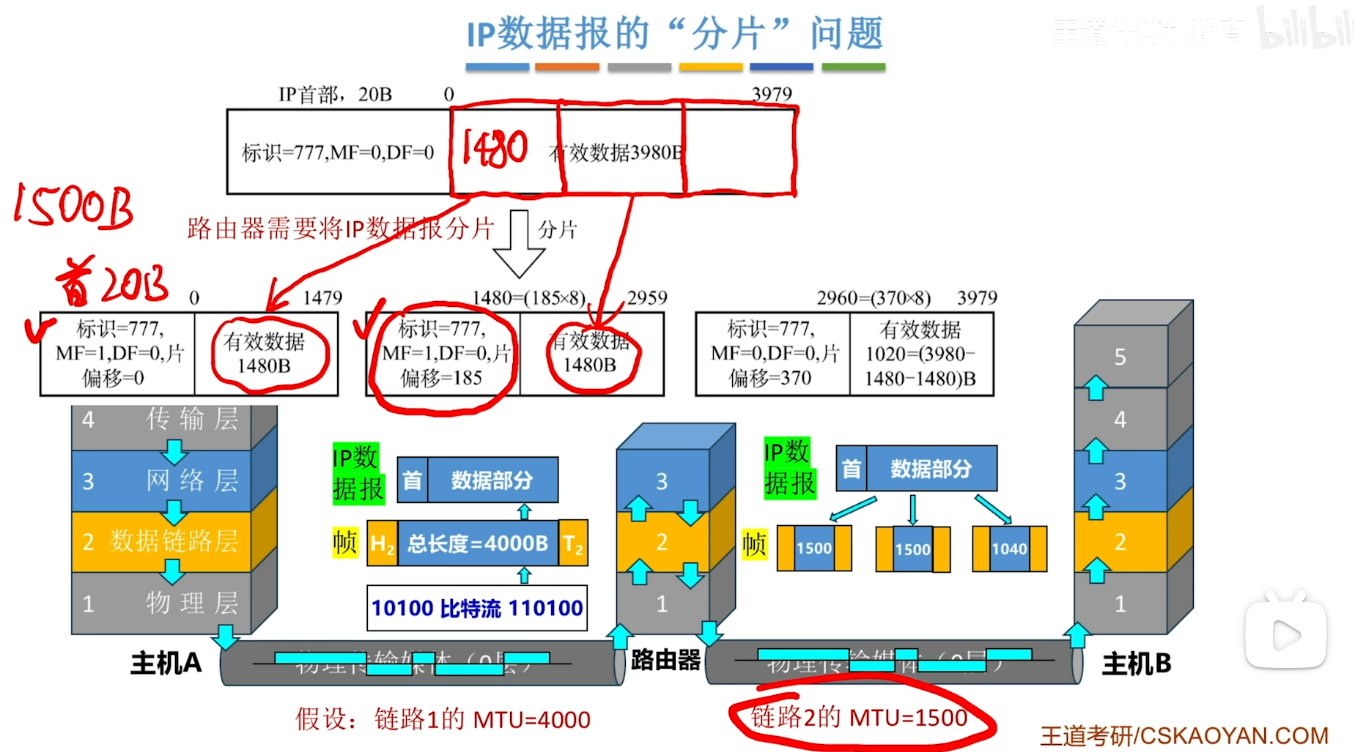
- 对于片偏移的问题:
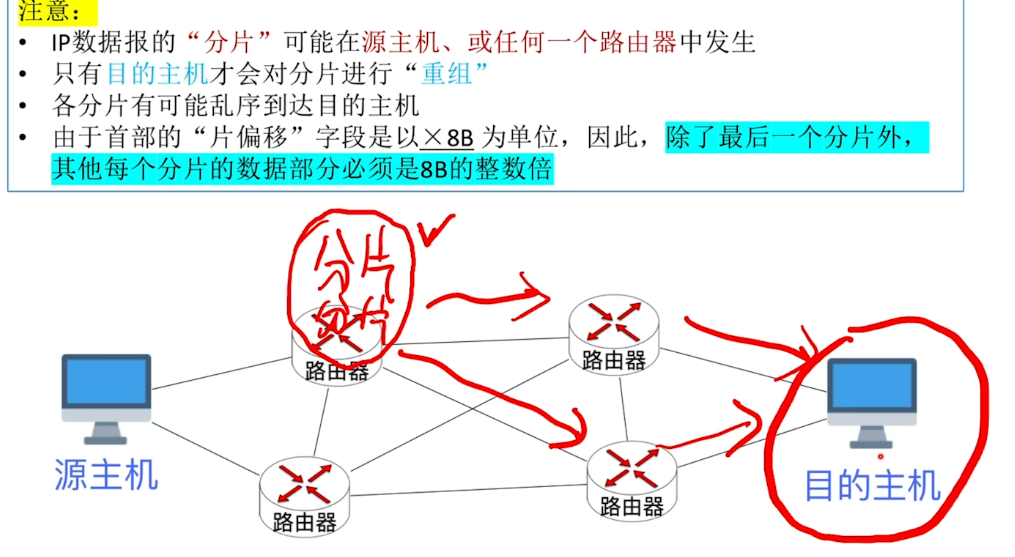
-
引入片偏移字段本质上就是帮助我们的目的主机能够按顺序 对于这些乱序到达的分片进行重组
-
再次观察分片问题的图 我们发现 第一个分片的片偏移量=0 这个不难理解 但是第二个就变成了185
-
这个是怎么来的呢?
-
这是由于第一个数据部分的大小是1480B 也就说明了 我们的第二个分片的数据部分在原始的数据报中是从1480开始存储的 而片偏移的单位是8B 所以1480/8 =185 第三个同理
-
小节
IP地址(分类编址,最初阶段)
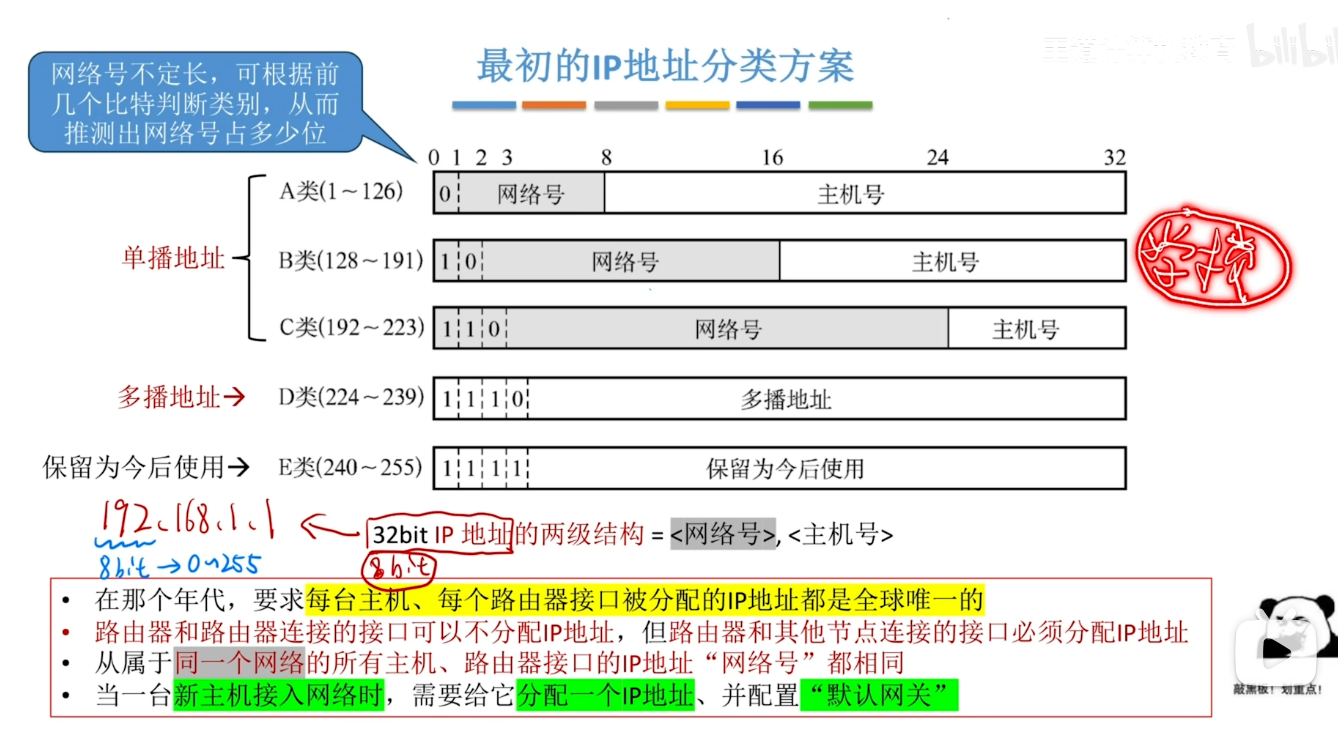
- 这里的默认网关可以理解为一个路由器 表示这个主机需要向互联网上发送IP数据报的时候 他就会知道应该先发给默认网关 然后这个路由器会帮他继续转发到互联网上
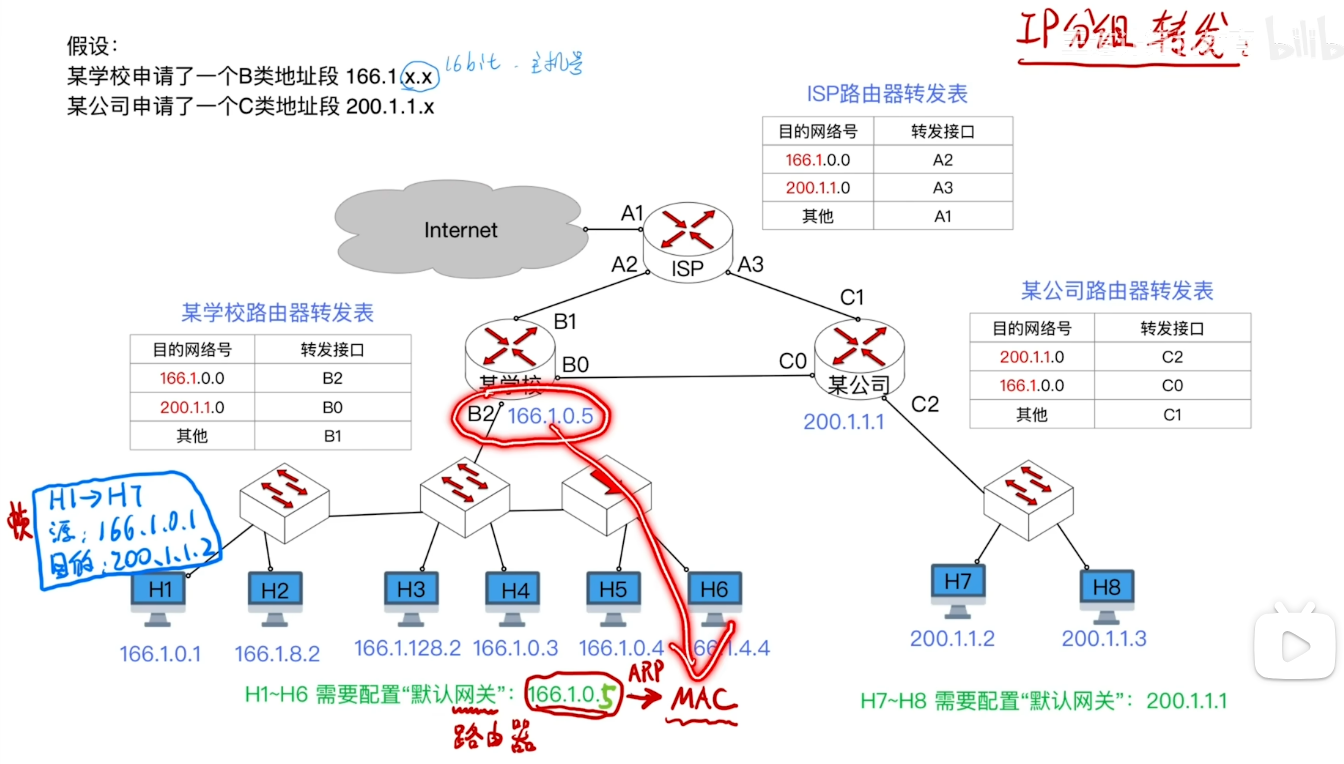
分析传输过程(非常重要)
- 在这之前我们需要知道一个很重要的事情:
- 我们要知道交换机实现的是物理层和数据链路层的功能 所以 我们的主机和我们的交换机的传输都是以帧为单位的 也就是我们对于每个IP数据报 都需要将它封装成帧来进行传输
- 例如 此时H1需要向H7发送一个数据报
- 我们来分析一整个完整的流程:
- 由于发现H1与H7并不属于一个网络 此时H1就需要将这个数据报封装成帧发送给默认网关(因为他知道是需要先由这个路由器来帮忙转发出去) 而这个路由器的IP地址是我们一开始就配置好的
- 我们依据ARP协议得到它的MAC地址 H1将这个数据报封装成帧的时候 可以将这个帧的目的MAC地址设置为B2接口所对应的MAC地址 经过交换机逐层转发到达路由器的B2接口
- 学校的路由器就会去根据IP数据报的目的地址 查询转发表 发现应该从B0接口 转发出去 同时将MAC帧的目的MAC地址修改为C0
- 到达公司路由器 它同样去查表 发现应该从C2转发出去 同时将目的MAC地址修改为H7 这样就顺利的经过交换机成功抵达H7 传输成功
- 为什么公司的路由器知道H7的MAC地址呢?
- 类似的 还是根据ARP协议 这个协议可以使得同一个网络内的主机路由器之间能够根据彼此的IP地址查询到对应的MAC地址
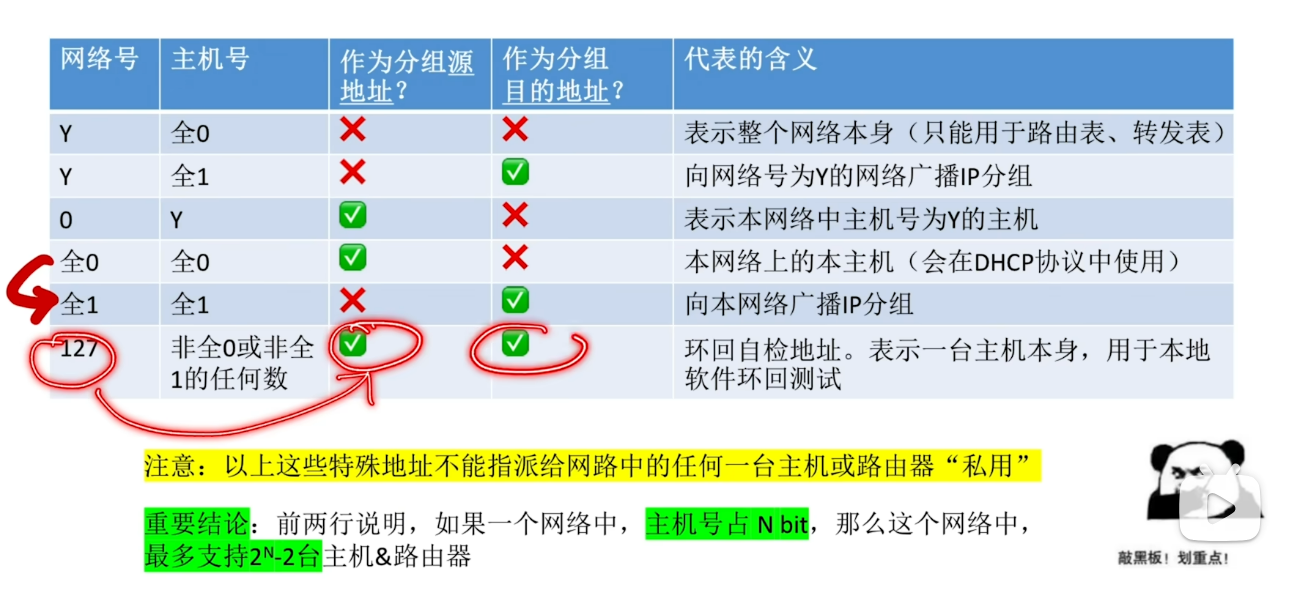
一些特殊用途的IP地址
这个结论需要重点记忆 后面在学习更复杂的知识时需要用到
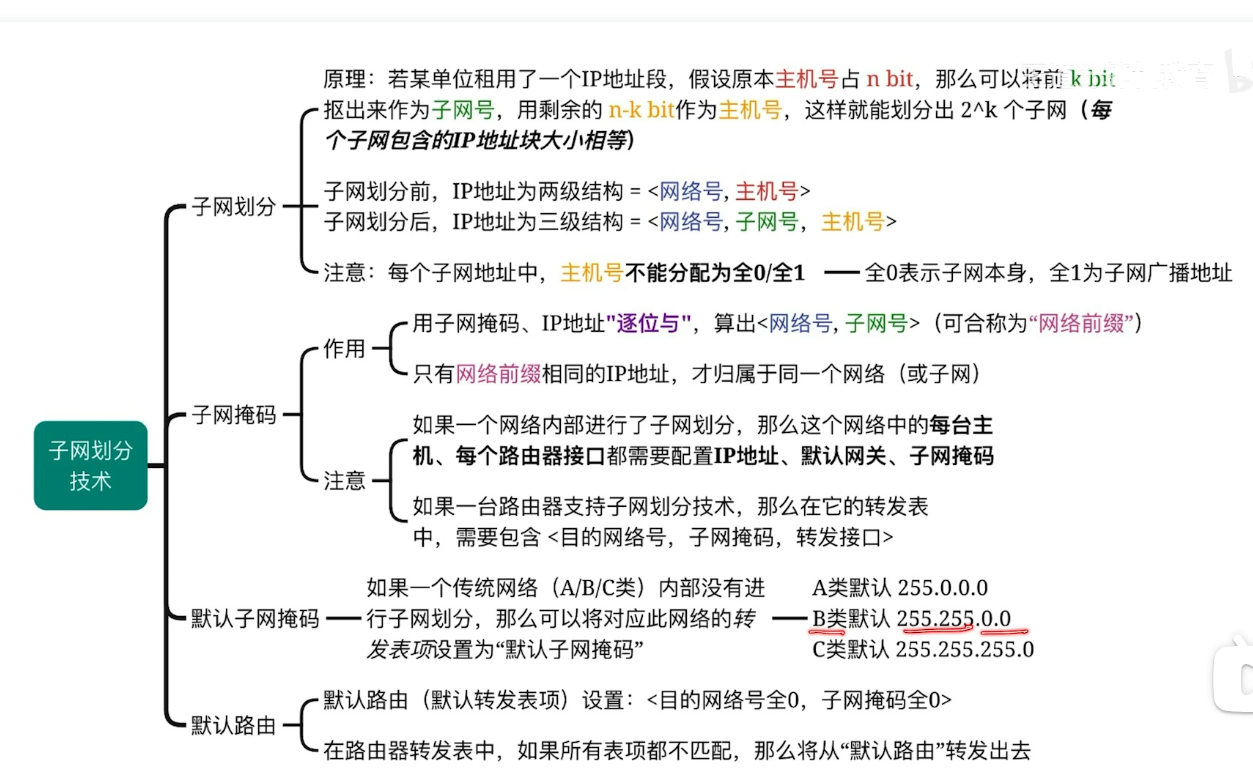
子网划分和子网掩码(重难点)
子网划分
- 引入
- 对于16bit的主机号所能表示的主机数量为2^16-2(除去全0和全1的特殊情况)但是现实情况却用不了这么多IP地址
- 假如学校有四个校区就可以在剩余16比特里面扣出2比特作为子网号
- 根据子网划分技术 给每个校区分配一个独立的子网 从而提高了IP地址利用率
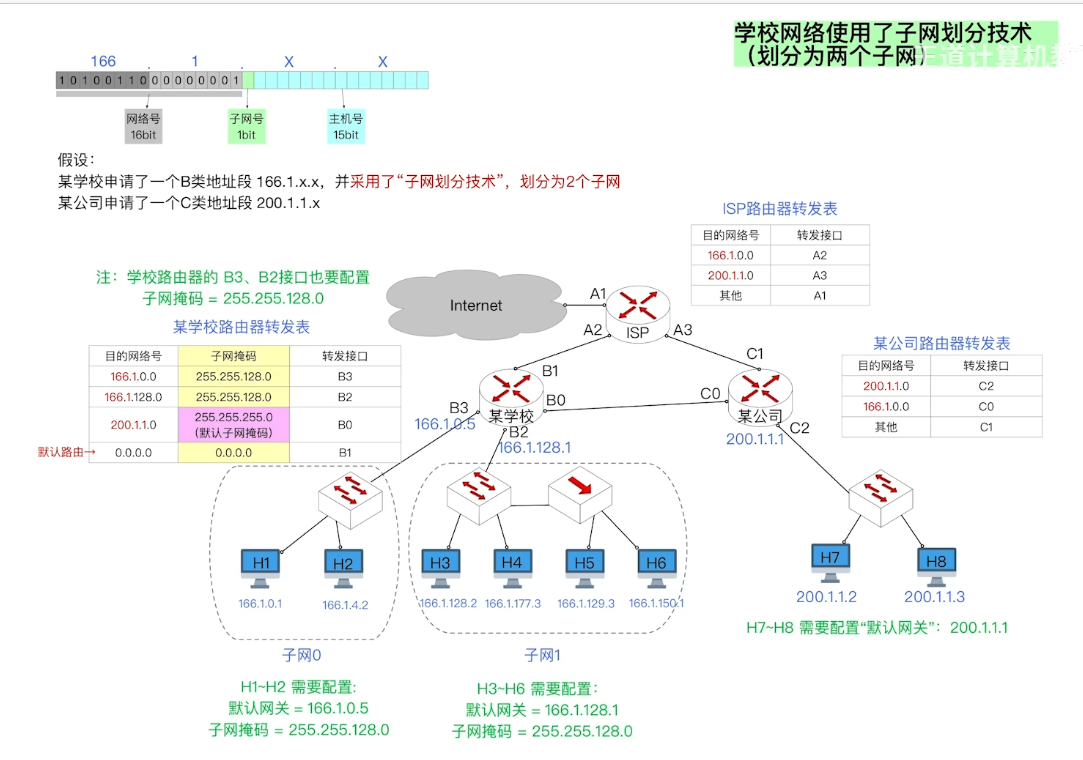
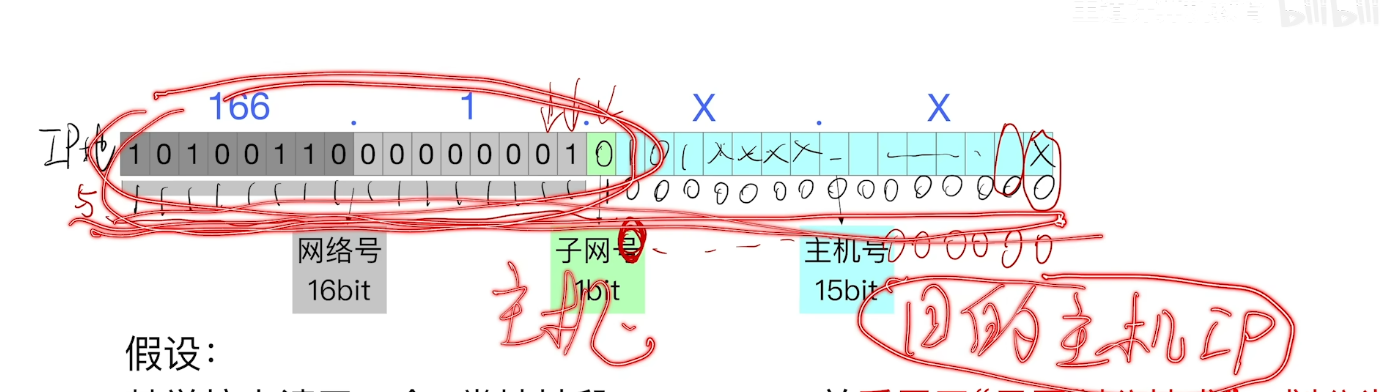
子网掩码
-
为什么需要引入子网掩码?
-
在思考这个问题之前不妨先想一下 在一台主机传输IP数据报之前 首先需要干嘛
-
是不是需要先判断我们的目的IP和我们的当前主机的IP地址是否从属于一个网络
-
如果不是 我们就交给路由器帮助我们转发
-
对于传统的IP地址 我们只需要根据类型(A,B,C)来对比前8,16,24 bit是否一致就行
-
但是现在划分子网之后 我们只有网络号+子网号都一致 才能说明从属于一个网络
-
以两个子网为例(也就是子网号占1bit 表示0/1 ) 此时网络号+子网号=16+1=17bit
-
好了现在回答最开始的问题
-
子网掩码就是帮助我们判断是否从属于一个网络
-
我们将子网掩码的前17位全部设置为1 后面15位(因为我们不关心 主机号)所以设置为0
-
转换成10进制 8个bit一组 也就是255.255.128.0 这是我们熟悉的格式
-
我们现在的逻辑是这样的 :
-
就是对于我们的目的IP地址和源IP地址在一开始都与子网掩码进行一次与操作 取得各自的高17位进行对比 如果一样则说明从属于一个网络 这样的话 我们就可以借助ARP协议得到目的地址对于的MAC地址 封装成帧 成功送达目的主机
-
这里需要补充一个点 我记得是在计组里面学过------与运算 简单回忆一下运算规则就行------任何数 与上0 都是0 任何数 与上1 都是他本身 这也解答了我们为什么上面这样设置子网掩码
默认路由
- 其实默认路由本质上就是保证我们的转发不会因为找不到目的网络号导致转发失败
- 具体的逻辑是这样的:
- 默认路由的子网掩码和目的网络号都设置为0.0.0.0表示32个bit 0 同时给他分配一个转发接口
- 为什么要设置成4组0呢?
- 还是由于与运算的特性 因为我们与运算的规则就是任何数字与上0都是0 所以即便跟前面几项都没有匹配上的时候 我们的默认路由是可以为我们兜底的
- 当我们的目的IP地址 与上 我们默认路由的子网掩码的时候 就肯定也是0.0.0.0 正好与我们默认路由的记录的目的网络号匹配上了
- 这样我们的数据报就从B1接口转发出去了
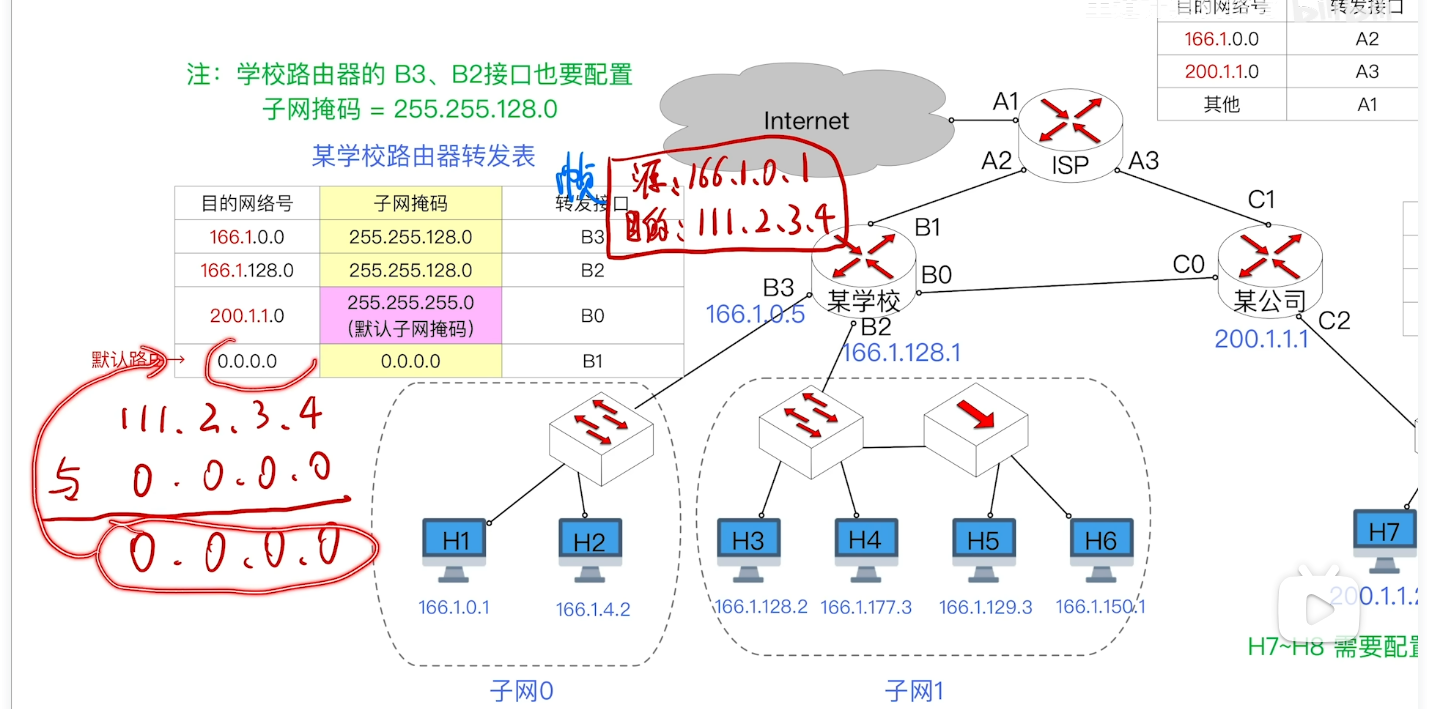
小节
无分类编制(CIDR)
- 其实说白了就是取消了传统的分类(A,B,C)这样使得我们的网络前缀是可变长的

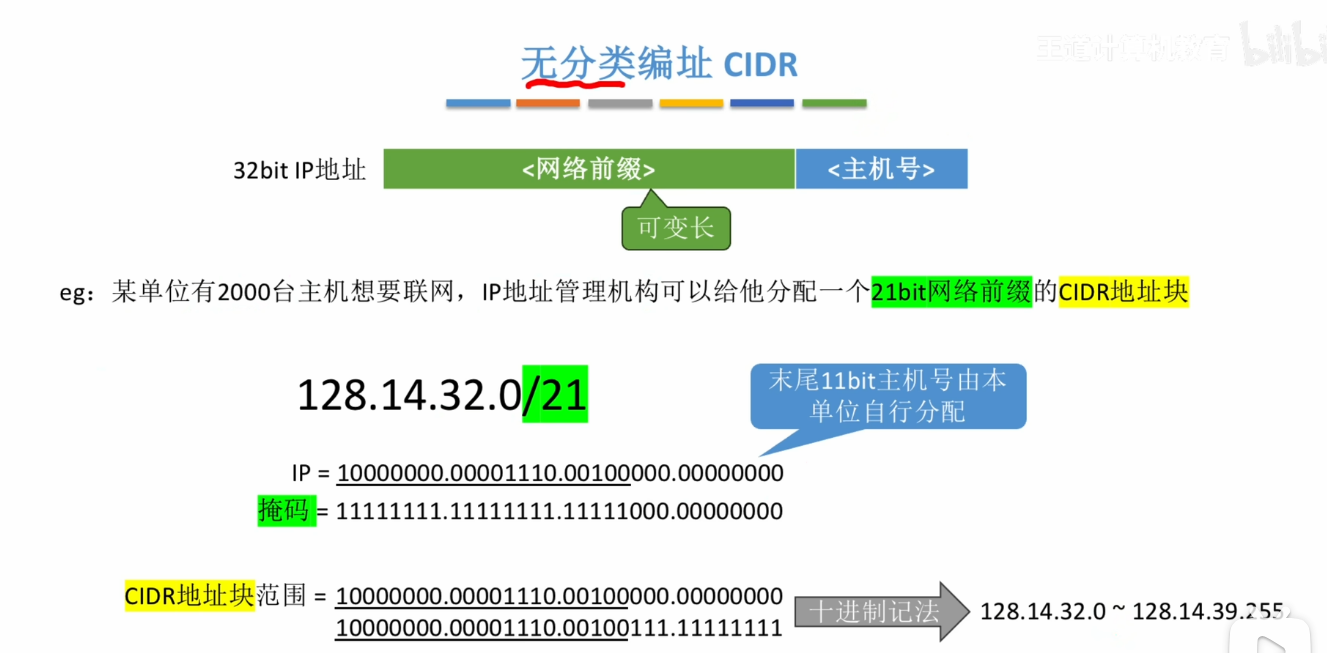
定长子网
与传统子网的划分方式一样 他会从主机号中扣出几个bit出来 用于子网号 如果抠出来Kbit 那么就可以有2^K这么多个大小相同的子网
缺陷
- 例如某一个学校分为4个校区 一校区人比较多 那么对应的 它的主机就会比较多 四校区人比较少 那么主机就少但是却拥有的是跟一校区相同数量的IP资源
- 如果采用定长子网划分的方式 就会导致人少的校区IP资源利用率很低
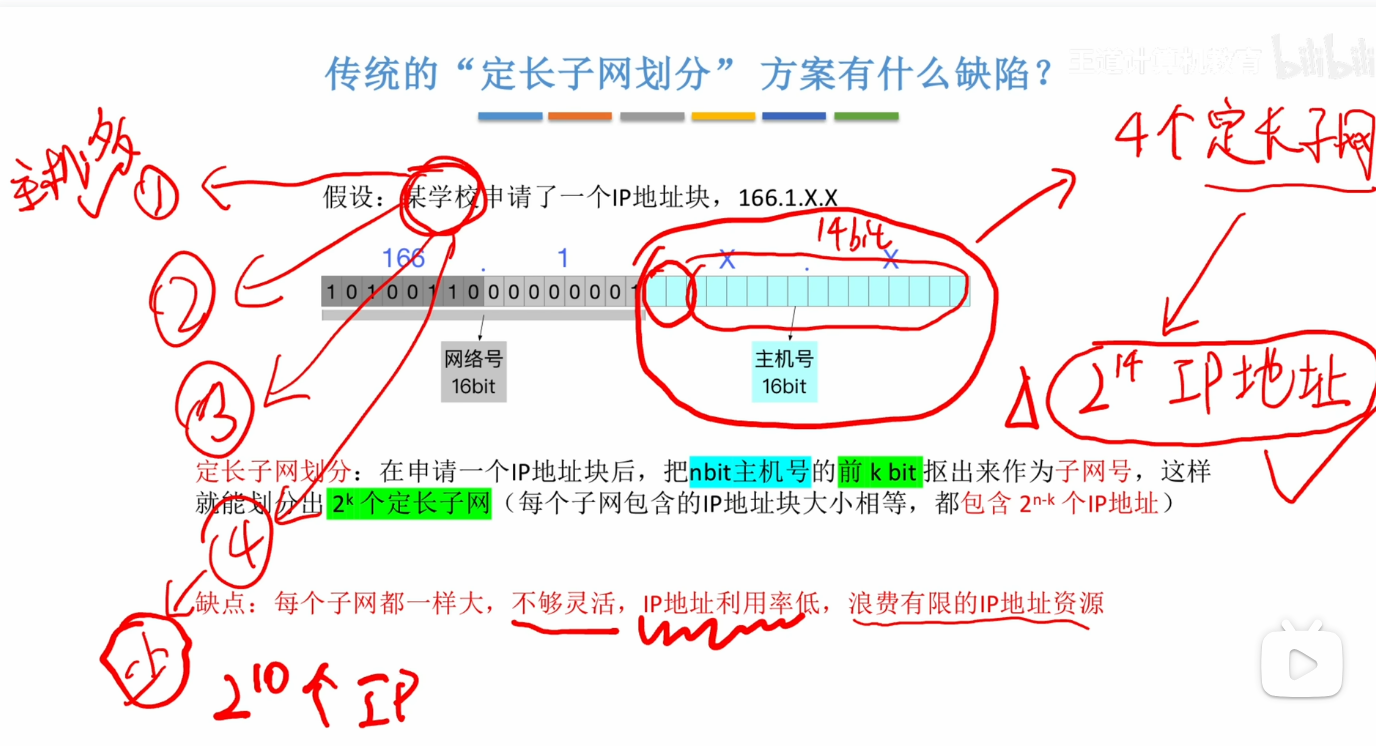
变长子网
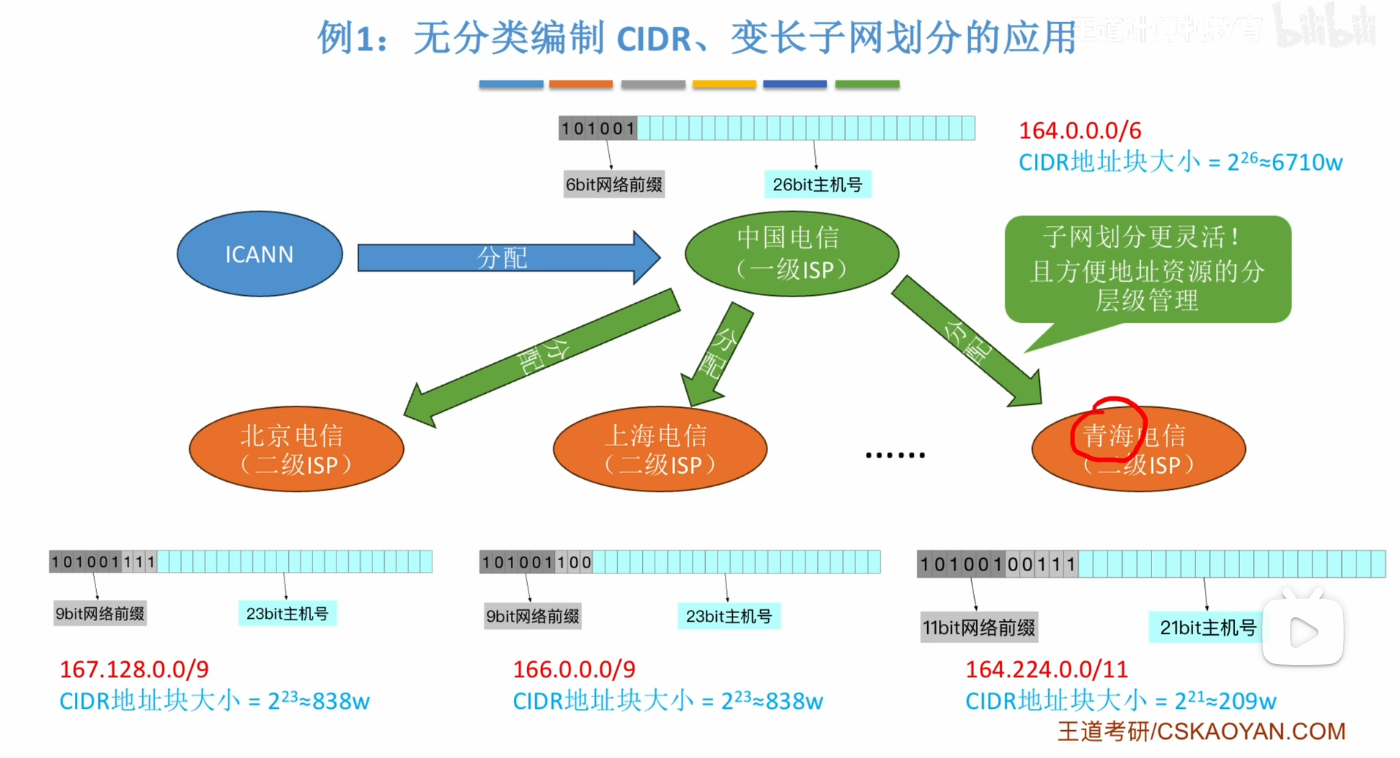
- 案例

- 实现
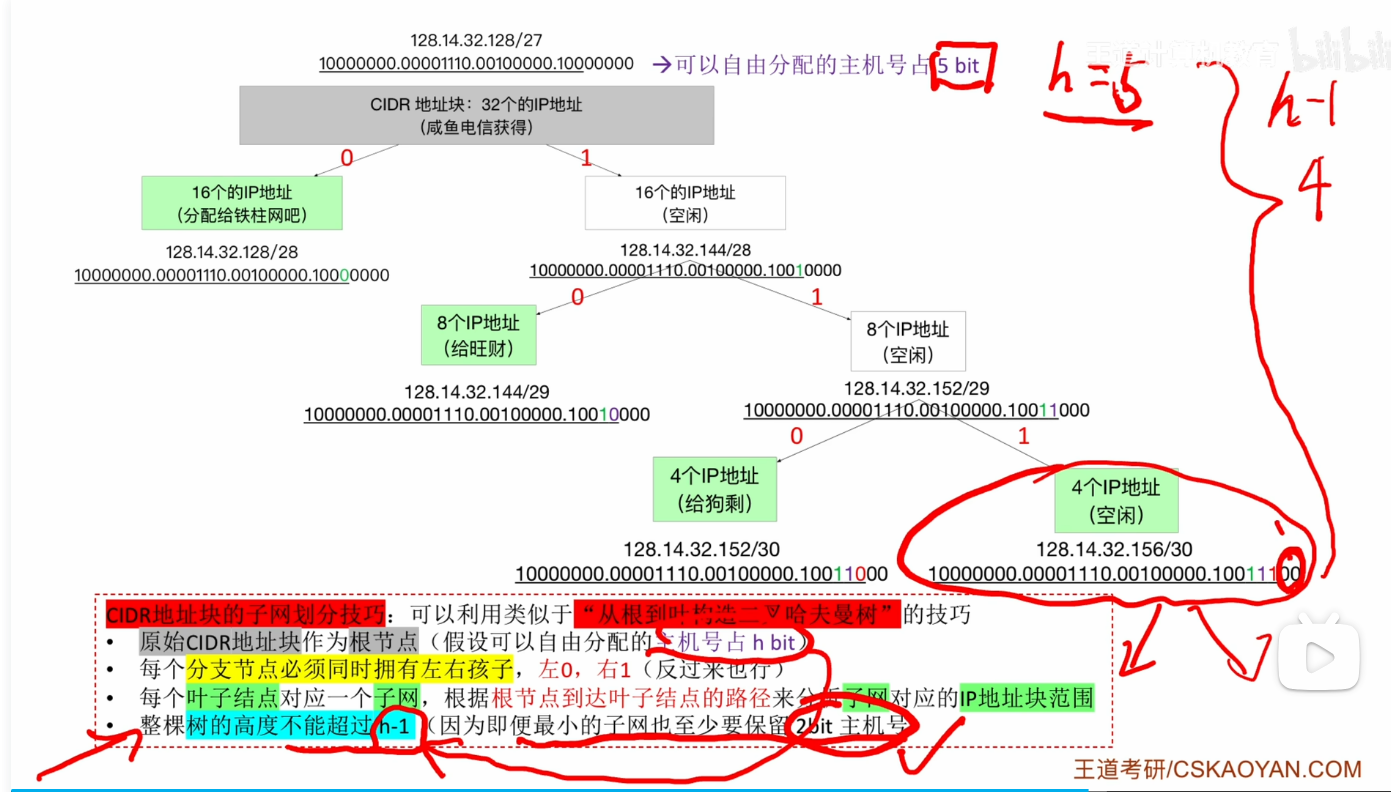
- 例题

小节
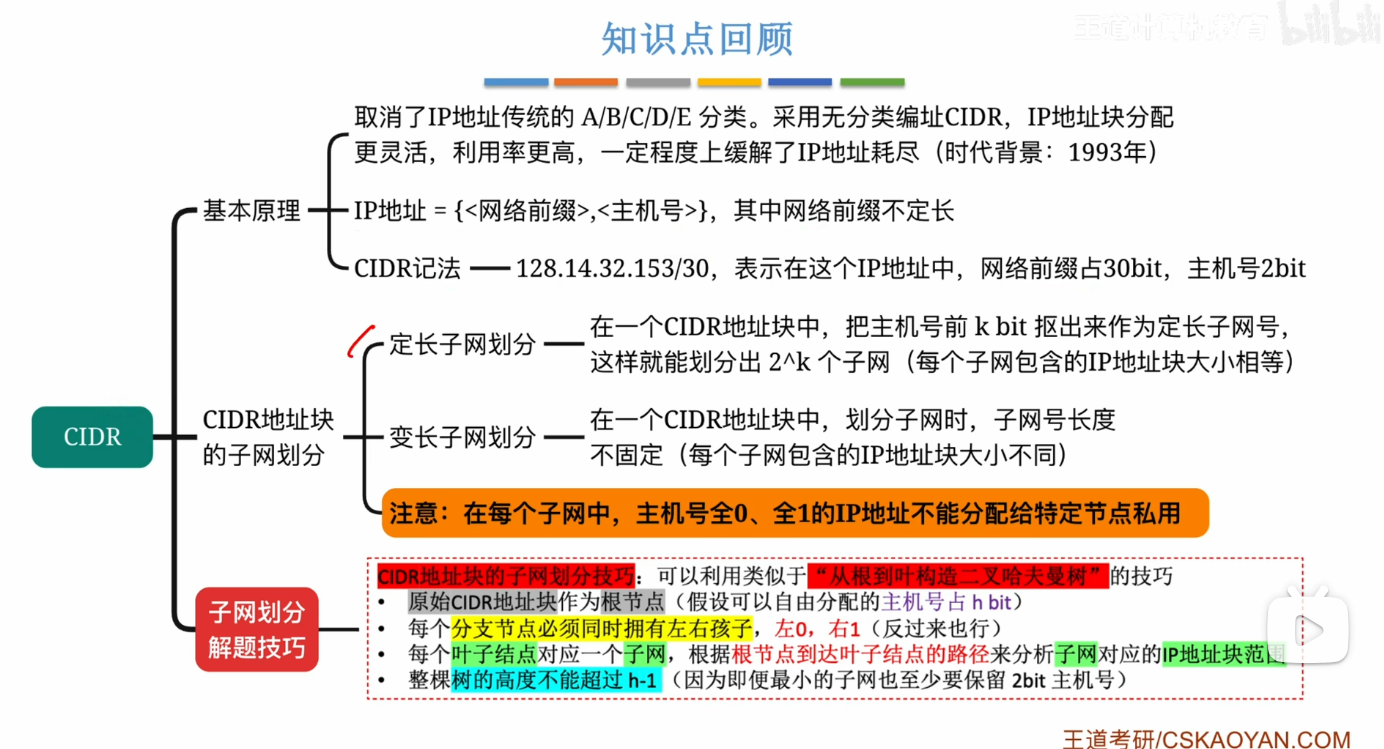
路由聚合
路由聚合的概念是基于前面而来的 并不是一个新的东西
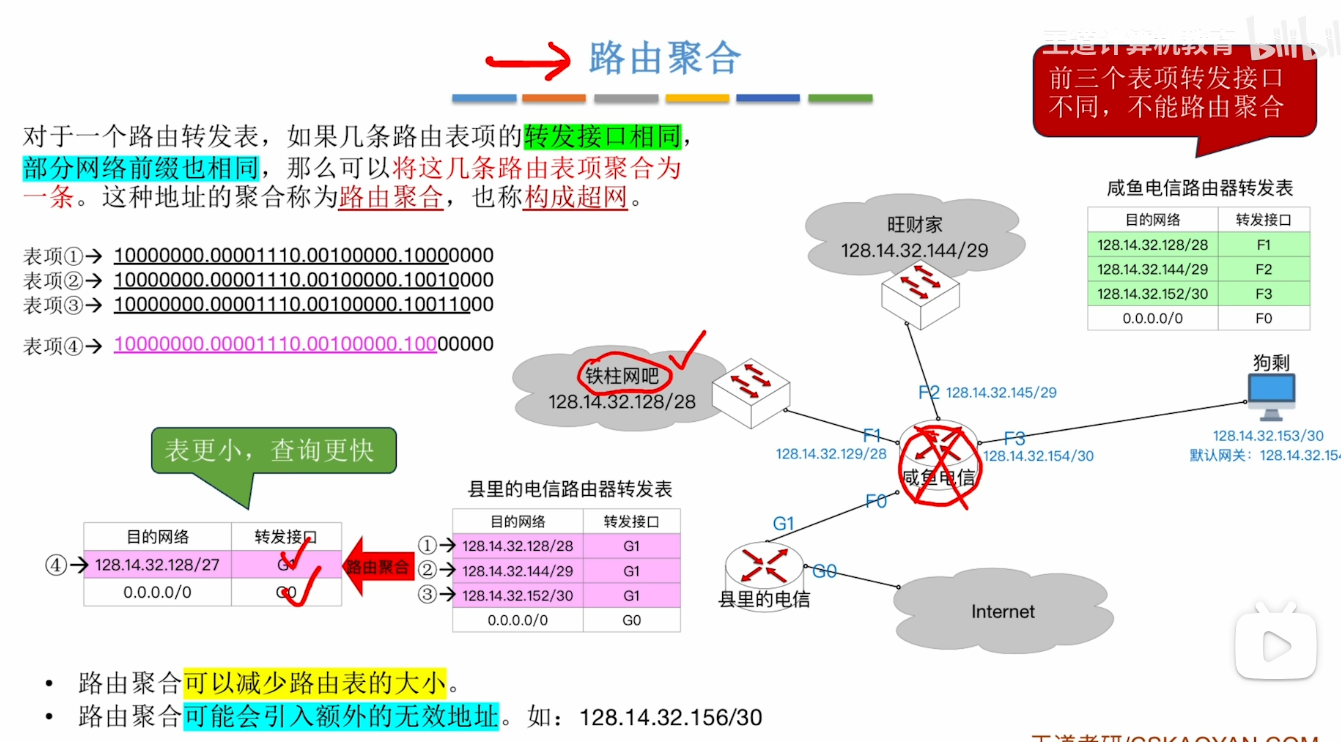
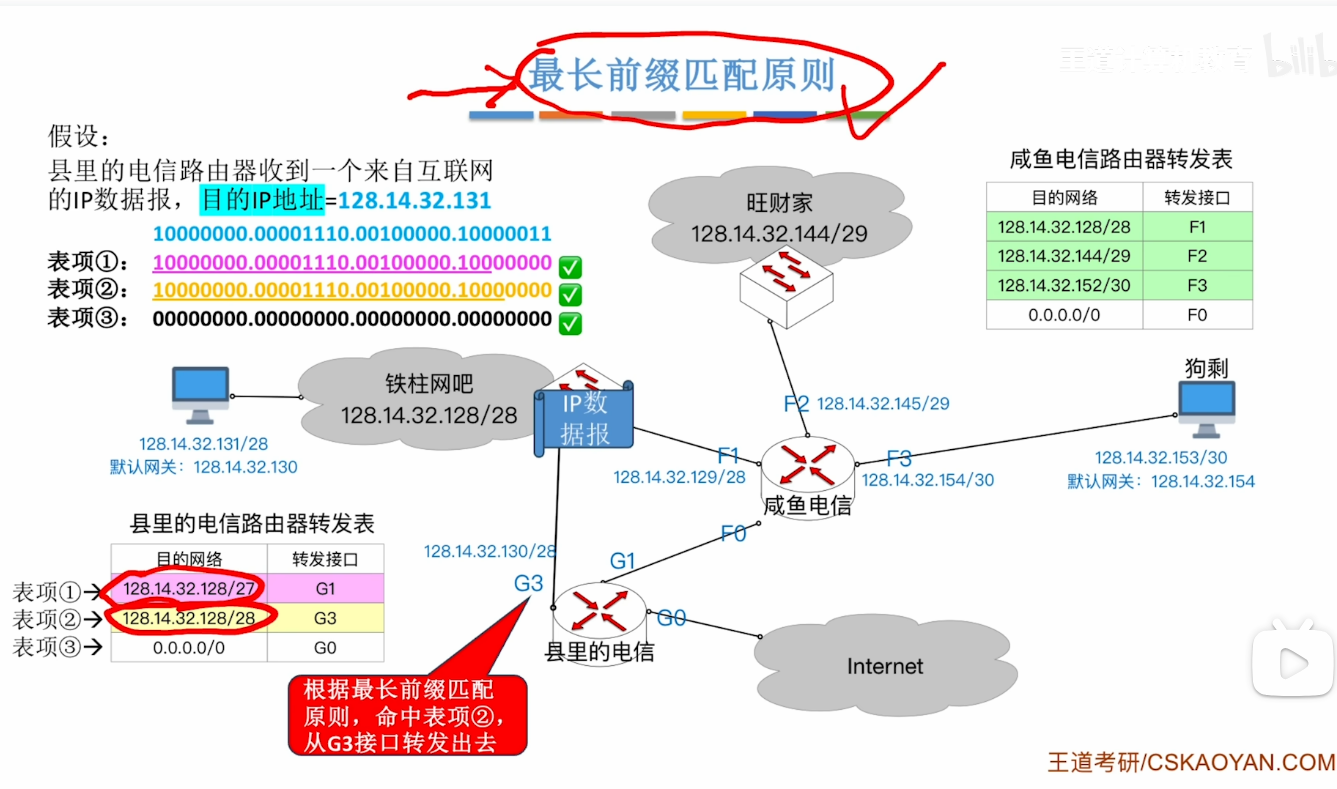
最长前缀匹配原则
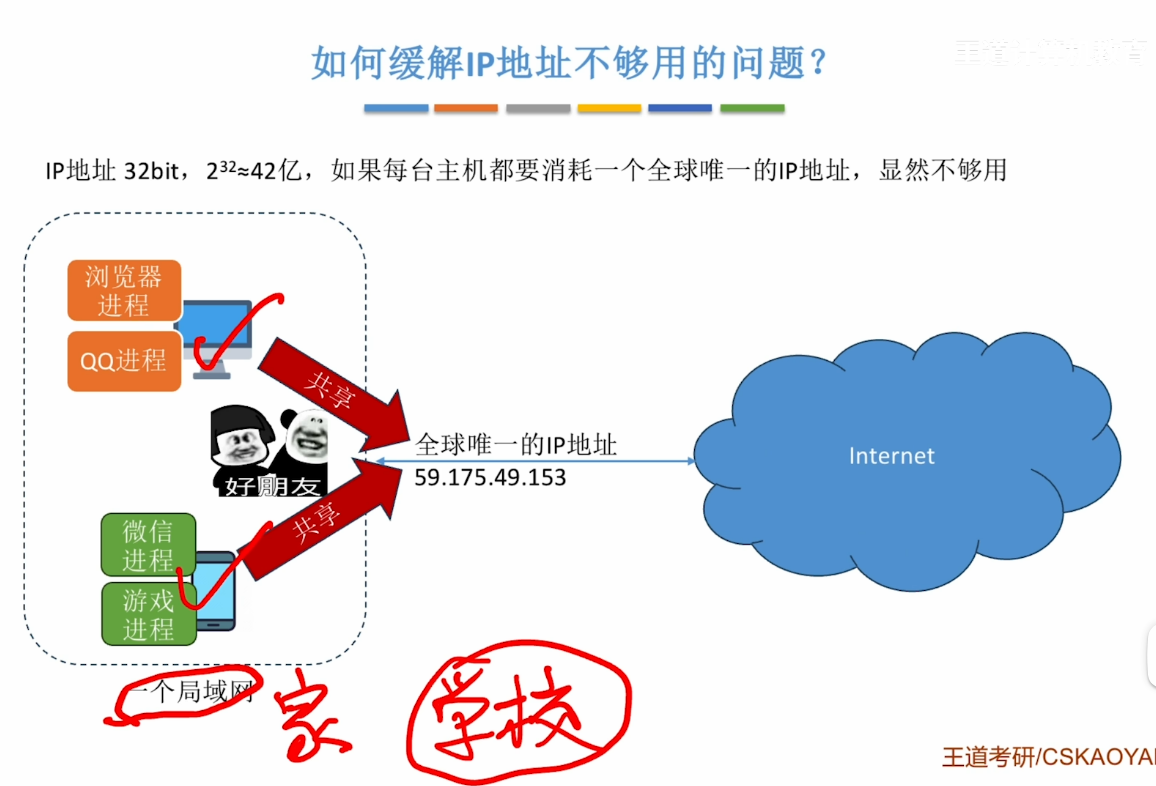
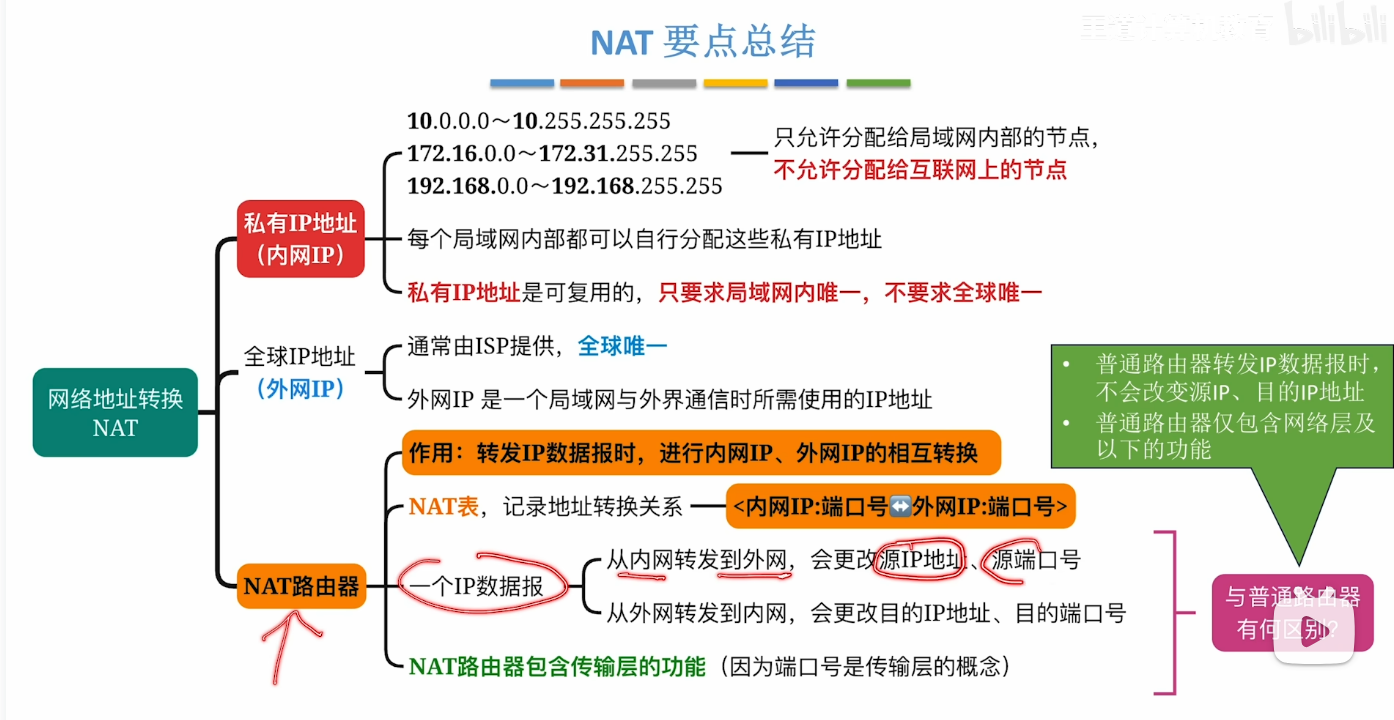
NAT
- 随着时代的发展 发现如果采用一台主机一个IP地址的方式 这是显然不够用的
- 用一句话来说:
- NAT技术就是 通过将私有IP地址映射为公有IP地址,实现多设备共享单一公网IP访问互联网。
端口号的概念
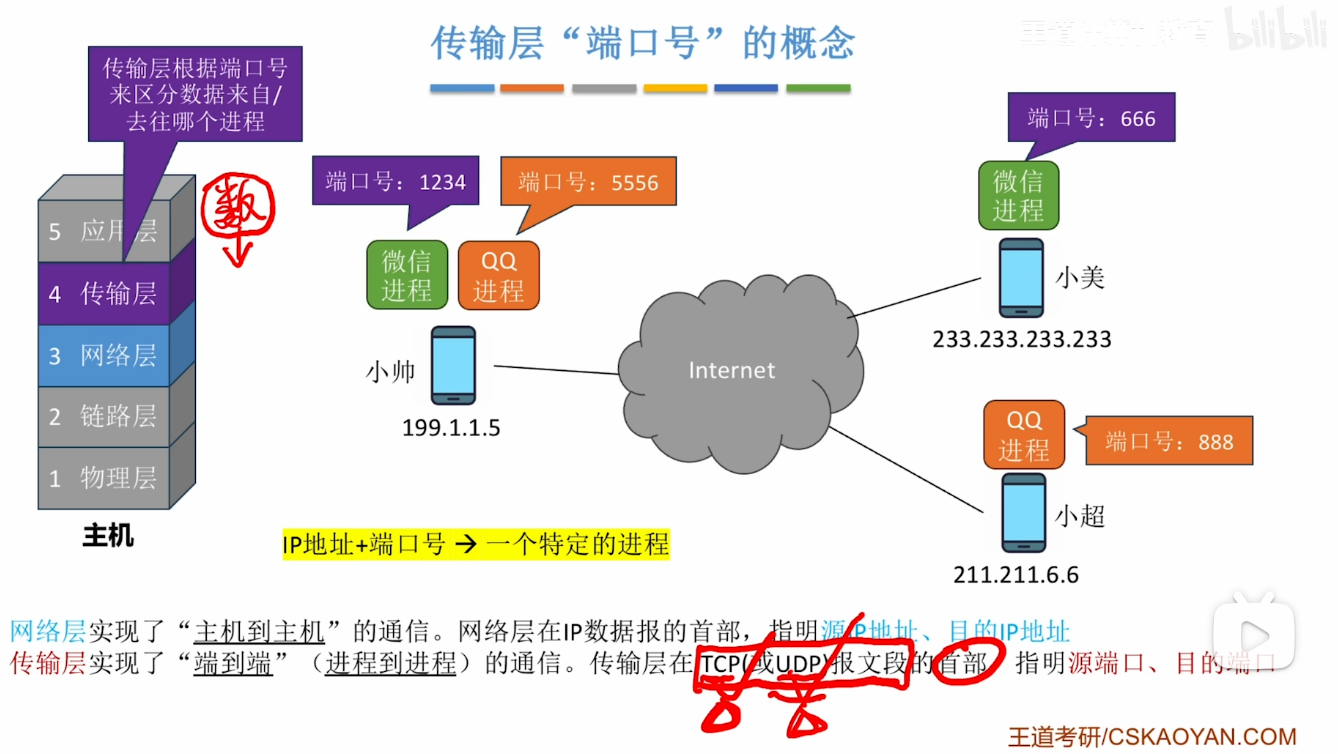
分析传输过程(非常重要)
-
我们来试着模拟 手机1的微信要向手机2发送一段文字 的整个过程
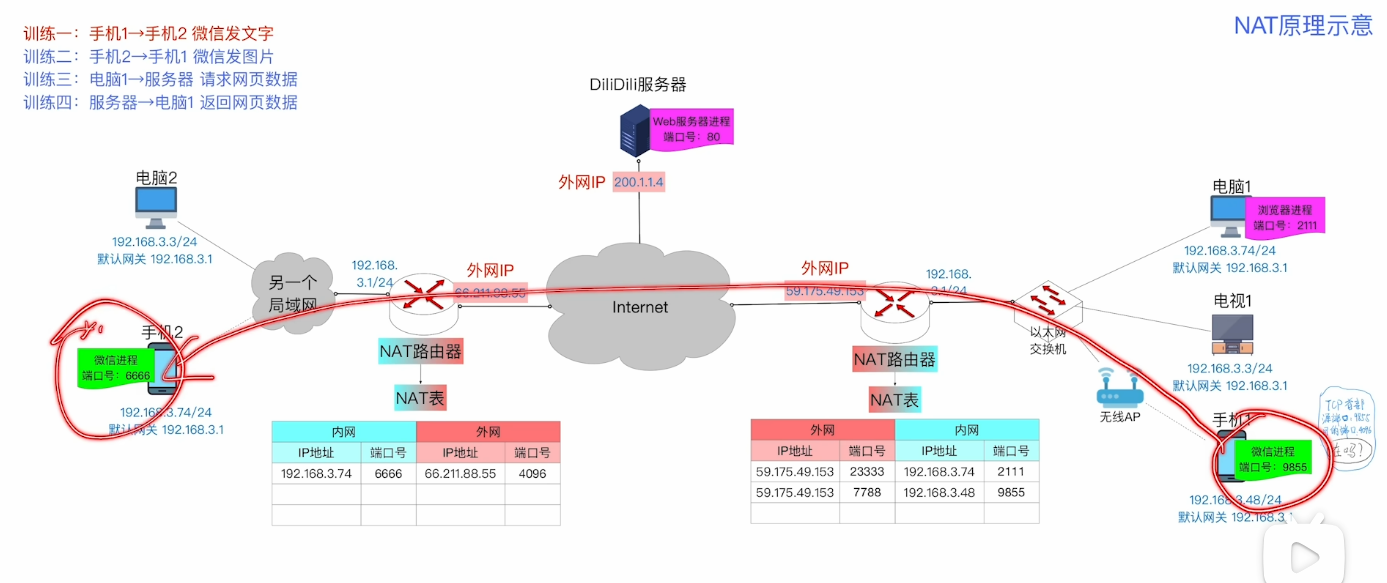
-
首先 我们用户在手机1中输入文字信息 这是最靠近用户的 所以是属于应用层的数据 之后他会交给我们的传输层 假设采用TCP协议 那么TCP协议就会给我们的数据增加一层首部的信息 具体的可以回忆一下之前我们学习 网络模型的时候所看到的层层包装的效果 在这个首部里面我们需要指明源端口号9855和目的端口号4096
-
Q: 为什么端口号不是手机2的内网端口号 6666?
这是因为我们的手机1只知道手机2对外暴露的端口号(外网的端口号)这个信息是我们的服务器告诉手机1的 -
之后将打包好的数据再交给网络层去处理 IPv4协议又会再增添一个首部信息 根据上文学过的只是 这时需要指明源IP地址(手机1的内网IP)和目的IP地址 (手机2的外网IP)将它封装成帧
-
又由于在对比IP地址之后 发现这个数据报是需要发送至外网的 所以手机1就会根据默认网关的IP地址直接交给NAT路由器(网关)
-
这个路由器充当一个"货币中转站"的作用 帮助我们把手机1的内网IP和端口号统统转换修改成外网的
-
根据我们的目的IP 经过层层转发 到达手机2的NAT路由器 这时同样进行转换操作 只不过是将手机2的外网IP和端口号------>内网
-
之后我们就可以将这个IP数据报转发到内网上 成功到达手机2
-
这时候 就好比我们的快递到了 我们根据取件码找到包裹(目的端口号)此时就需要去掉层层包装得到我们的物品(应用层的数据)
要点总结
ARP协议
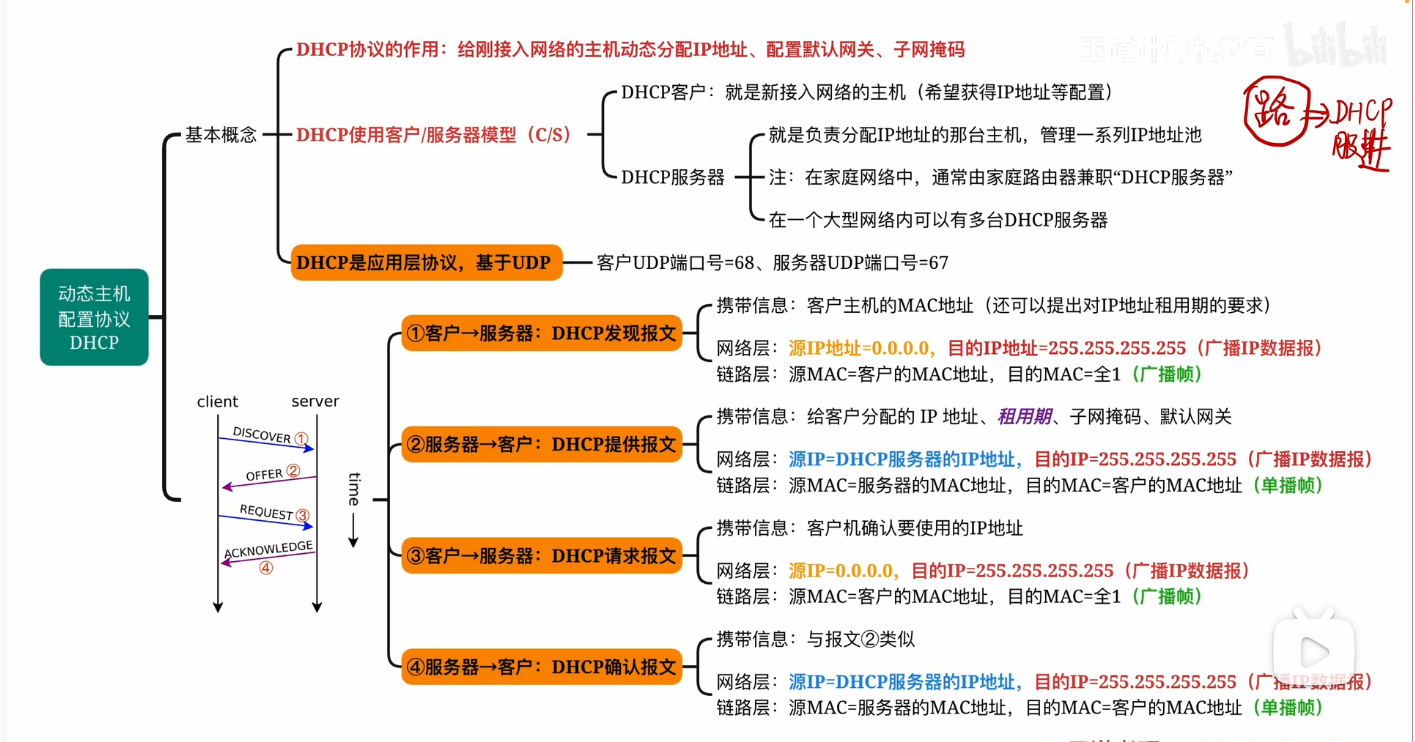
DHCP协议
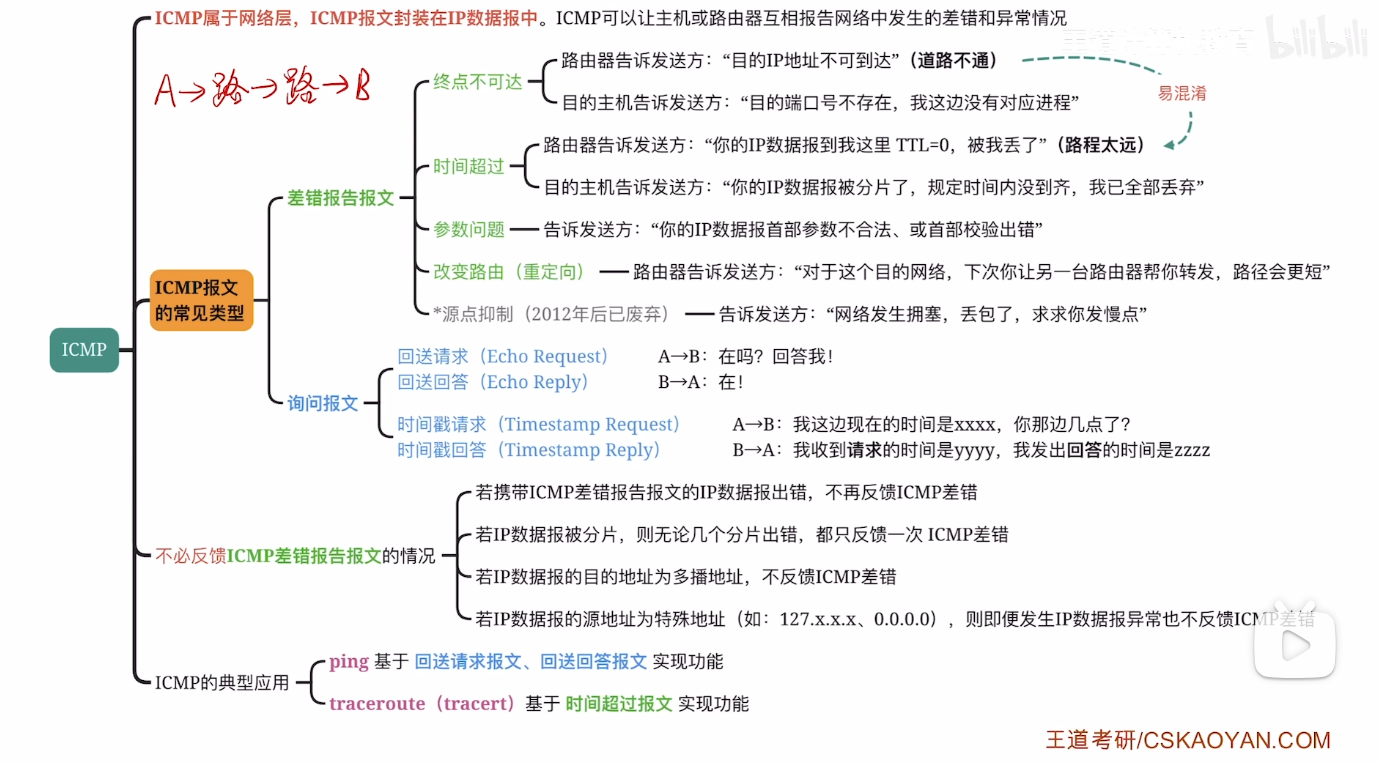
ICMP协议
结语
对于计算机网络层和数据链路层的知识真的是杂乱繁多 而且理解起来并不容易 所以我在每个小点都附上了注释 希望能够帮助大家理解
