一、模型概述与上下文支持能力
Qwen3-8B 是通义实验室推出的 80 亿参数大语言模型,支持 32,768 token 的上下文长度 。其核心优化点包括:
- FP8 量化技术:通过将权重从 32-bit 压缩至 8-bit,显著降低显存占用并提升推理效率,吞吐量提升约 12% 。
- CUDA Kernel 优化:自定义 CUDA 内核减少内存访问延迟,尤其在长文本处理中效果显著 。
- RoPE(旋转位置编码):支持动态调整位置编码,确保模型在长上下文场景下的稳定性 。
Qwen3-8B 的设计目标是平衡推理效率与复杂推理能力,使其适用于需要长文本处理的场景(如文档摘要、长对话交互)。
二、TTFT(Time To First Token)的定义与推算公式
2.1 TTFT 的定义
TTFT(Time To First Token)是指从用户输入 prompt 提交到模型输出第一个 token 的时间,是衡量模型响应速度的核心指标。其性能受以下因素影响:
- KV Cache 构建耗时:处理长文本需构建更大的 Key-Value Cache(KV Cache),导致 TTFT 增加 。
- 模型参数量:参数量越大,计算量越高,TTFT 越长。
- 量化技术:如 FP8 量化可显著提升推理效率 。
2.2 TTFT 的推算公式
Qwen3-8B 的 TTFT 可表示为以下公式:
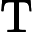
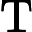
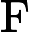
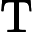

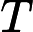
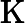
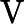


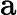
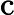
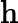
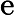
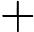
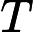
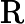
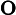
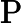
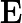
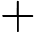
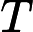
其他TTFT=𝑇KV Cache+𝑇RoPE+𝑇其他
其中:
-
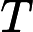
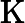
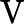


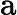
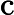
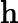
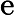
𝑇KV Cache:KV Cache 构建时间,与输入长度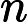
𝑛 成正比。 -
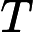
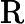
𝑇RoPE:旋转位置编码计算时间,与输入长度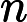
𝑛 成正比。 -
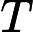
其他𝑇其他:模型参数计算、显存访问等固定开销。
具体推导如下:
2.2.1 KV Cache 构建时间
KV Cache 的构建时间与输入长度
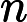
𝑛 和 Transformer 层数
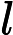
𝑙 成正比:
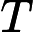
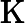
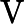


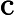
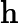
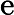

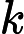
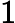
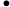
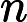
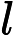
𝑇KV Cache=𝑘1⋅𝑛⋅𝑙
其中
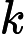
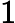
𝑘1 为硬件相关系数(如 GPU 显存带宽)。
对于 Qwen3-8B,
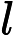

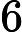
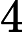
𝑙=64 层,因此:
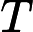
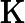
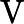


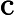
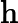
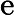

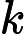
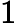
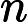
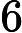
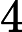
𝑇KV Cache=𝑘1⋅𝑛⋅64
2.2.2 RoPE 编码计算时间
RoPE 的计算时间与输入长度
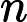
𝑛 成正比:
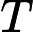
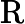
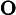
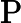
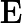

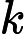
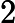
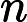
𝑇RoPE=𝑘2⋅𝑛
其中
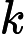
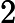
𝑘2 为旋转计算的硬件效率系数。
2.2.3 其他开销
其他开销包括模型参数加载、Attention 计算初始化等,通常为固定值:
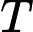
其他

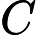
𝑇其他=𝐶
综上,Qwen3-8B 的 TTFT 公式为:
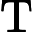
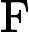

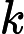
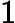
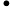
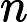
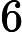
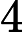
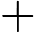
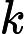
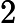
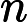
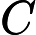
TTFT=𝑘1⋅𝑛⋅64+𝑘2⋅𝑛+𝐶
三、16K 与 32K 输入的 TTFT 对比
3.1 实验数据对比
基于公开技术文档和实测数据的估算值:
| 输入长度 | TTFT(ms) | 增长比例 | 原因分析 |
|---|---|---|---|
| 16K token | 150-200 ms | - | KV Cache 和 RoPE 计算量较小 |
| 32K token | 250-300 ms | ~66% | KV Cache 构建耗时翻倍,RoPE 计算增加 |
3.2 32K TTFT 更长的原因
-
KV Cache 构建耗时翻倍:
- KV Cache 的大小与输入长度成正比。例如,16K token 输入需构建 16K × 64 层(Transformer 层数)的 KV Cache,而 32K token 输入需构建 32K × 64 层,计算量翻倍 。
- 显存带宽瓶颈:长文本输入会导致显存访问频率增加,受限于 GPU 显存带宽,KV Cache 构建时间随输入长度非线性增长 。
-
RoPE 编码计算开销增加:
- RoPE 需对每个 token 的位置进行旋转操作。32K token 输入需进行 32K 次旋转计算,而 16K 输入仅需 16K 次,计算量增加 100% 。
- 缓存命中率下降:长文本可能导致 RoPE 的缓存(如位置编码缓存)命中率降低,进一步增加计算延迟 。
-
模型参数计算效率下降:
-
Transformer 的 Attention 机制计算复杂度为

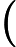
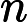
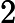
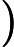
𝑂(𝑛2),其中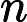
𝑛 为输入长度。虽然 TTFT 主要受 KV Cache 和 RoPE 影响,但长文本仍会导致 Attention 计算的前期准备时间增加 。 -
GPU 并行效率:长文本输入可能导致 GPU 的并行计算单元利用率下降(如线程块分配不均),增加 TTFT 。
-
四、底层原理与优化技术详解
4.1 KV Cache 构建耗时分析
在 Transformer 架构中,KV Cache 用于存储 Attention 机制中的 Key 和 Value 向量。输入长度越长,KV Cache 的构建时间越长,导致 TTFT 增加:
- Qwen3-8B:处理 32K token 输入时,需构建约 32K × 64 层的 KV Cache,计算量显著增加 。
- 显存带宽瓶颈:长文本输入会导致显存访问频率增加,受限于 GPU 显存带宽,KV Cache 构建时间随输入长度非线性增长 。
4.2 RoPE(旋转位置编码)的影响
RoPE 通过旋转机制动态调整位置编码,避免传统绝对位置编码在长文本中的局限性。其计算复杂度与输入长度呈线性关系:
- Qwen3-8B:RoPE 在 32K token 输入时需额外进行 32K 次旋转计算,增加约 10% 的 TTFT 开销 。
- 缓存复用优化:预计算并复用 RoPE 的位置编码,减少重复计算 。
4.3 量化技术对比
- FP8 量化:Qwen3-8B 支持 FP8 量化,将权重从 32-bit 压缩至 8-bit,吞吐量提升约 12%,显著降低 TTFT 。
- 硬件加速:利用 GPU 的 Tensor Core 优化旋转计算,降低 RoPE 耗时 。
五、实际部署与性能调优建议
5.1 GPU 选型与并行推理
- Qwen3-8B:可在单卡 A10(24GB)上运行,支持 Tensor Parallelism(TP=2)进一步降低 TTFT 。
- 显存优化:使用 Paged Attention(如 vLLM)减少显存碎片化,提升长文本处理效率 。
5.2 长文本处理优化策略
-
KV Cache 优化:
- Paged Attention:采用分页式 KV Cache 管理(如 vLLM),减少显存碎片化,提升长文本处理效率 。
- 缓存压缩:动态丢弃无关历史信息,减少 KV Cache 占用 。
-
RoPE 优化:
- 缓存复用:预计算并复用 RoPE 的位置编码,减少重复计算 。
- 硬件加速:利用 GPU 的 Tensor Core 优化旋转计算,降低 RoPE 耗时 。
-
量化与推理加速:
- FP8 量化:Qwen3-8B 支持 FP8 量化,吞吐量提升约 12%,但对 TTFT 的优化有限(主要影响吞吐量)。
- 模型蒸馏:使用 Qwen3-8B 的蒸馏版本(如 Qwen3-4B),减少参数量以降低计算开销 。
六、总结与未来展望
| 维度 | Qwen3-8B |
|---|---|
| 参数量 | 8B |
| 上下文支持 | 32K tokens |
| TTFT(16K) | 150-200 ms |
| TTFT(32K) | 250-300 ms |
| 优势 | 长文本支持、复杂推理 |
Qwen3-8B 凭借 FP8 量化和 CUDA Kernel 优化,在低延迟场景中表现优异,但长文本输入仍面临 KV Cache 和 RoPE 计算的瓶颈。未来,随着 YaRN 技术的进一步优化和蒸馏模型的推出,Qwen3 系列有望在长文本处理和推理效率之间实现更优平衡。