摘要: 本文旨在揭示大语言模型(LLM)应用开发的底层逻辑。我们将摒弃浅层的提示词技巧,从 Token 预测的概率本质出发,解析 Prompt 的工程化结构,并深入探讨基于 LLM 的对话系统(Dialogue System)架构设计。最后,针对"私有数据库与公有模型结合"及"负向约束"等工程难题进行实战分析。
内容借鉴于课程2、Prompt 的典型构成_哔哩哔哩_bilibili,十分推荐学习!
一、 核心原理:概率预测与数据对齐
要掌握 Prompt Engineering,首先必须祛魅:大模型并非具有人类意识的实体,其本质是一个基于概率统计的自回归预测器。
1. Token 叠加与概率选择
大模型的工作机制可以被概括为"基于上文预测下一个 Token"。模型在海量文本数据中通过自监督学习,习得语言的概率分布规律。当我们输入一段话时,模型实际上是在计算所有可能出现的下一个词元(Token)的概率,并根据采样策略(如 Temperature)选择其中一个,将其拼接到序列末尾,再进行下一轮预测。
简而言之,就是基于概率选择下一个Token,最后Token叠Token,最后拼成了一整句话。
2. "对齐"是 Prompt 的本质
既然模型是基于训练数据(Training Data)的统计规律运行的,那么最高效的 Prompt 策略,就是让我们的输入尽可能贴近模型训练时见过的高质量数据分布。
-
训练风格的模仿:如果我们知道模型主要使用科技论文进行训练,那么使用学术性的语言风格进行提问,往往能激活模型更深层的推理能力。例如,在构建"蓝碳"知识库系统时,如果提示词中包含了环境科学领域的专业术语(如"碳汇"、"红树林生态系统"),模型更有可能调动其内部相关的知识参数。
-
模型敏感性 :不同的基座模型(Base Model)有不同的"脾气"。如果我们更换了底层大模型 (如从 GPT-4 换到国产模型),由于预训练语料和微调策略的差异,原本表现优秀的 Prompt 可能失效,必须重新调优。
二、 工程化解构:Prompt 的函数式定义
在工程视角下,每一次对大模型的调用,都可以被视为执行一个函数(Function)。这个函数具有明确的输入(Input)和输出(Output)定义。为了保证函数执行的确定性,我们需要采用结构化的 Prompt 构成。
1. 结构化要素解析
一个工业级的 Prompt 通常包含四个核心维度:
Role(角色):这是消除歧义的关键。
Task(指令/任务):具体的行为描述。
Constraints(约束):边界条件与负向限制。
Example(示例/Few-shot):基于示例的学习。

2. 角色设定(Role)的深层机理
为什么"定义角色"是目前流传最广且最有效的方法?
从信息论的角度看,自然语言存在巨大的二义性。当我们设定"你是一个资深软件工程师"时,其实是在模型庞大的参数空间中划定了一个特定的搜索域,将问题域收窄。这能显著屏蔽掉与当前语境无关的通用知识,减少模型产生歧义(Hallucination)的概率,从而提升输出的精准度。
3. "迷失中间"现象与位置敏感性
在构建 Prompt 时,信息的摆放位置至关重要。研究表明(如下图所示),**大模型对prompt开头和结尾的内容更加敏感,**而放在中间的信息往往容易被忽略(Lost in the Middle)。
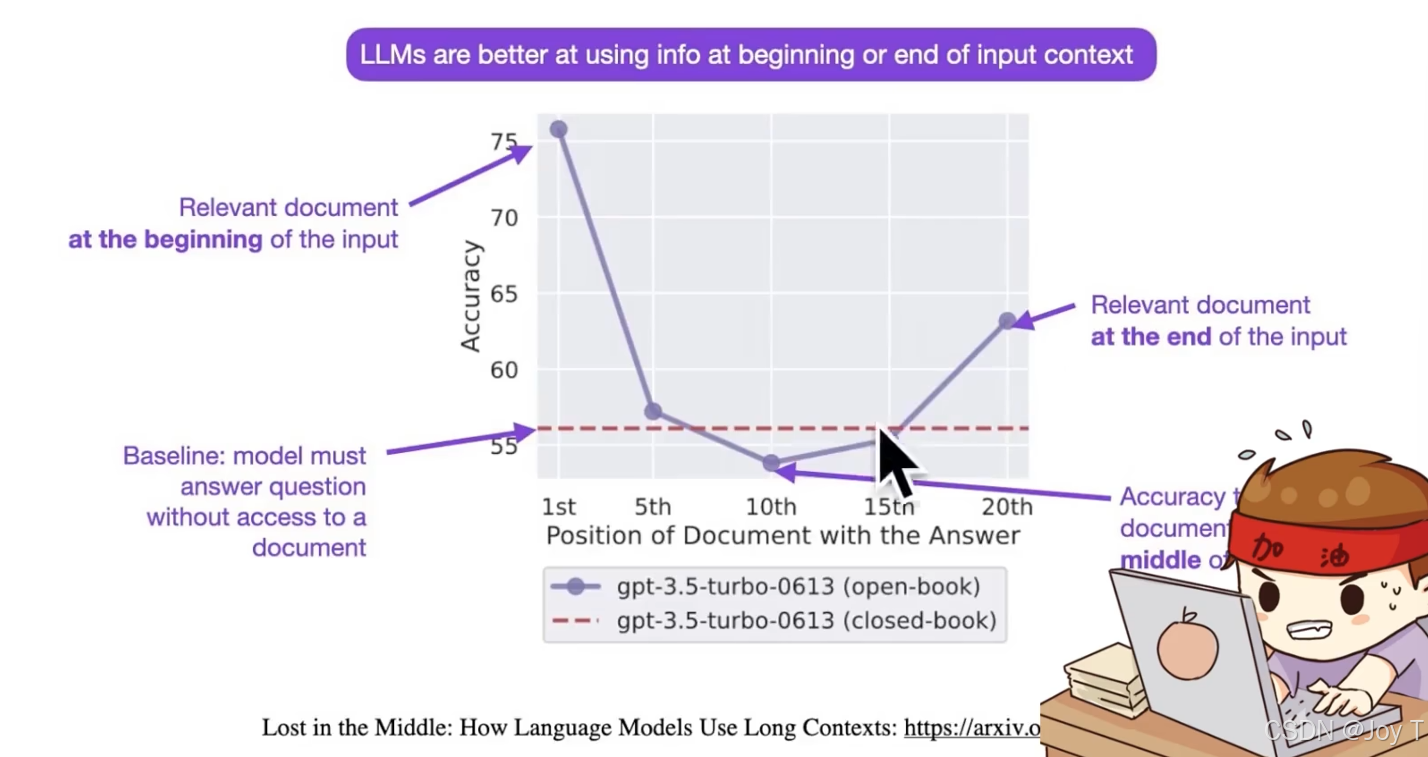
因此,在工程实践中,我们通常将角色定义放在最开头,将核心指令或最新问题放在最结尾,而将参考文档或背景资料放在中间。
三、 架构进阶:大模型对话系统的设计
对于聊天机器人或智能客服等应用,仅仅写好单次 Prompt 是不够的,我们需要理解任务型对话系统(Task-oriented Dialogue System) 的完整链路。
1. 传统 vs. 大模型时代的对话架构
在传统 NLP 时代,对话系统被严格拆分为流水线模块。而在大模型时代,这些模块既可以独立存在,也可以被 LLM 的端到端能力融合。对话系统的基本模块如下:
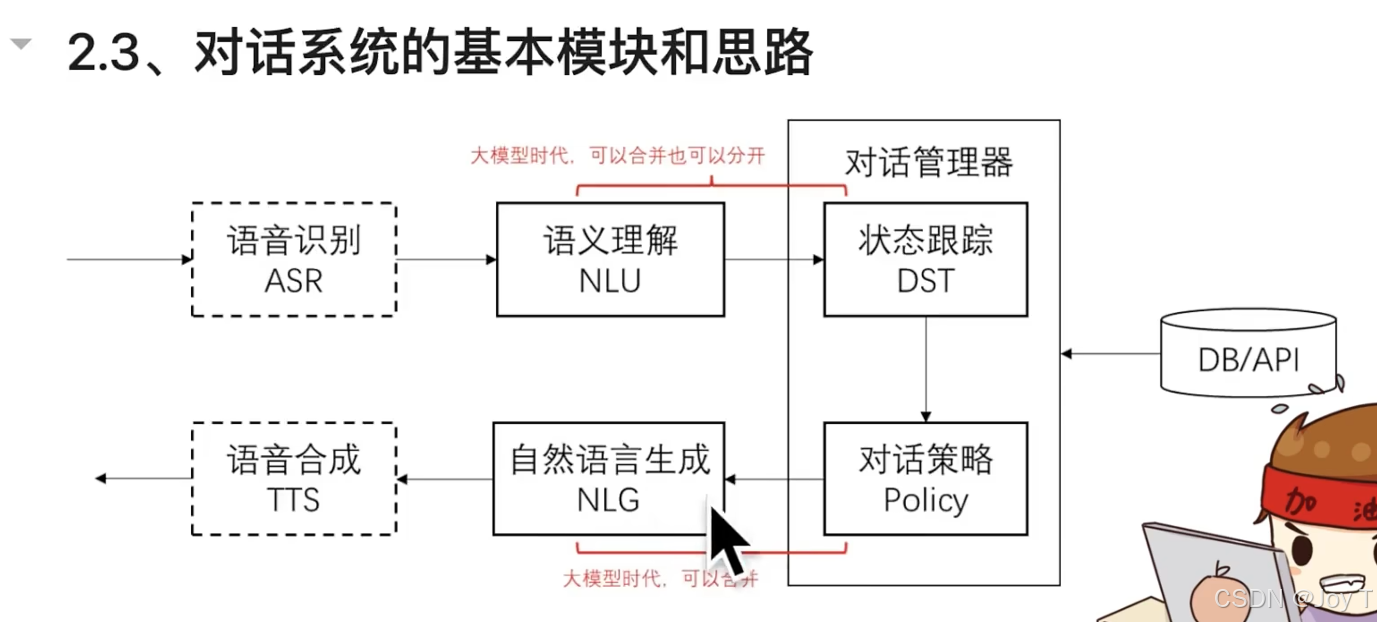
上图重点:自然语言输入--结构化表示与策略--自然语言输出。

下表展示了核心模块的功能流转:
| 模块名称 | 英文缩写 | 核心功能 | 大模型时代的演变 |
|---|---|---|---|
| 语音识别 | ASR | 声音转文字 | 依然独立,但精度提升 |
| 自然语言理解 | NLU | 意图识别与槽位填充(语义理解) | 可由 LLM 直接完成 |
| 对话状态追踪 | DST | 记忆当前对话的上下文状态 | 核心难点,需在 Prompt 中维护 |
| 对话策略 | Policy | 决定系统下一步该做什么 | 由 LLM 的推理能力接管 |
| 自然语言生成 | NLG | 生成最终回复 | LLM 的强项 |
| 语音合成 | TTS | 文字转声音 | 依然独立 |
2. 状态管理:DST 的实现
大模型本身是无状态(Stateless)的。模型不会"记住"你上一句话说了什么。所以当我们在开发多轮对话系统时,开发者必须充当"外部存储器"的角色。我们需要在代码层面维护一个 History 列表,将用户的每一轮输入和 AI 的每一轮输出拼接起来,形成完整的 Context,再传给大模型。
通过在 Prompt 中注入多轮对话的历史(Few-shot Examples),我们可以让 AI 模拟出"有记忆"的行为,这实际上是在 Prompt 层面实现了 DST(状态追踪)。
3. 代码实例:给例子(Few-shot)
利用 get_completion(prompt) 这样的函数调用时,提供示例(One-shot 或 Few-shot)不仅是教会模型格式,更是为了"带徒弟"------通过演示逻辑,让模型模仿推理过程。

四、 关于数据库与约束的深度思考
在实际开发中,单纯依靠 Prompt 往往无法满足业务需求,以下是对两个关键工程问题的解答。
1. 公有模型与私有数据(Mocked DB)的结合
问题:使用公共模型(如 GPT/文心)时,自研系统的数据库意义何在?
解答:这涉及到了目前最主流的 RAG(检索增强生成) 架构。
-
数据库的价值(Grounding) :大模型的知识是静止的(截止于训练结束那一刻),且存在幻觉。而自研的数据库存储的是实时、私有、精确的业务数据。
-
结合方式 :数据库主要用于检索(Retrieval)。当用户提问时,系统先在你的数据库中查出相关数据(Context),然后将这些数据作为 Prompt 的一部分喂给大模型。
-
结论 :在垂直领域应用中,数据库的数据查询与策略构建(Policy)的重要性远大于文案生成本身。模型在这里更像是一个"翻译官",负责将数据库里的硬数据翻译成人类好理解的软文案。
2. 负向约束(Negative Constraints)的重要性
问题:添加"抱歉,我无法......"这类强约束是否更好?
解答:是的,这是一个非常高阶且必要的工程实践,学术上称为拒识(Rejection)或鲁棒性控制。
-
减少幻觉:如果用户问了一个超出自研系统范围的问题(比如"如何做红烧肉"),如果不加约束,模型会一本正经地胡说八道。
-
明确边界 :通过 Prompt 明确告知模型"如果你不知道答案,请直接说不知道,不要编造",或者"你只回答与本系统相关的问题",可以极大地提升系统的可信度(Faithfulness)。
-
适用性:这不仅适用于对话系统,在文生图、文生视频中同样适用(例如 Negative Prompt)。明确"不做什么",往往比告诉模型"做什么"更能保证结果的安全与合规。
Prompt Engineering 正在演变为一门严谨的语义编程工程。从理解底层的概率 Token,到设计无状态的 DST 流程,再到结合私有数据库的 RAG 架构,这才是从"玩家"进阶为"开发者"的必经之路。