关注我的公众号:【编程朝花夕拾】,可获取首发内容。

01 引言
前一段时间和一个产品的朋友聊天,她问到:开发做报表的时候一般怎么做?是实时计算还是做一张宽表。我们聊了不少。
今天就整理一下自己在做报表的时候考虑的因素以及用到的技术方案。
02 报表的痛点
报表的内容一般都是统计数据、聚合数据。数据源常常来源于不同的表,再加上为了方便,查询条件上也可能会涉及不同表的字段,这就需要连表查询。
领导最喜欢的数据的比较,如同比、环比、日报、月报、年报等更是挑战报表的性能。主要表现在一下几点:
- 数据的实时性
- 数据的多样性
- 查询的便利性
领导不想知道你怎么实现的,他只要能够快速查看、任意维度的查询以及不同的数据结果。
为了满足这些需求,传统的连表查询处理加上大数据量的计算和读写,势必造成性能的拉胯。面临最大的挑战和痛点就是海量数据。
为了减少连表的数量,我们经常会选择多次查询,然后再内存里面筛选需要的数据。但是如果查询条件中包含了多个表的字段,那么这种方案也就失效了。
03 解决思路
大体的解决思路有以下几点:
- 提高硬件的性能(不太可能,公司不愿意)
- 解决提需求的人(不大可能,但是需求可以聊)
- 使用纯技术解决
- 建立宽表或临时表
- 使用其他数据库
提高硬件基本不太可能,而解决提需求的人也不可能,但是需求可以聊。怎么去聊需求?对于没有必要的展示或者查询且好性能的点可以协调是否可以砍掉,这个取决于公司的性质。
当然这些都是外力因素,我们主要介绍一下使用技术方案解决复杂的需求。
3.1 使用纯技术解决
使用纯技术解决,在不改变表的情况下,使用不同的技术栈解决。这个应该是我们经常面临的场景。为了满足查询的实时性,连表查询必不可少。我们如何在连表的情况下,最大限度的发挥程序的性能呢?
主要可以从一下几个角度着手:
- 合理的创建数据库索引和分区
- 对于复用的数据使用缓存
- 多线程异步处理
合理的创建数据库索引
合理的使用Mysql数据库索引单表可以支撑百万乃至千万的数据不成问题。索引创建的并不是越多越好,能用联合索引就用联合索引,索引字段创建在离散度比较高的字段上。连表的字段最好能够使用索引。
对于创建的索引,我们可以使用Mysql自带的分析工具Explain去分析SQL性能。
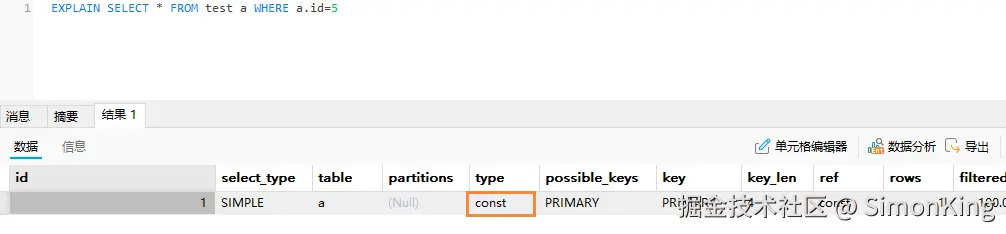
其中type的值尽量达到ref级别。
从最好到最差依次是:system>const>eq_ref>ref>range>index>ALL
Mysql有分区功能,可能很多人不知道,合理的使用分区会有意想不到的效果。比如以月为分区,那么按照月查询的时候就只会在分区里面查找,速度也会变快。
对于复用的数据使用缓存
对于经常查询的数据(热点数据),查询完成之后可以缓存到Redis或本地缓存中,二次查询的就可以直接返回。大致流程:
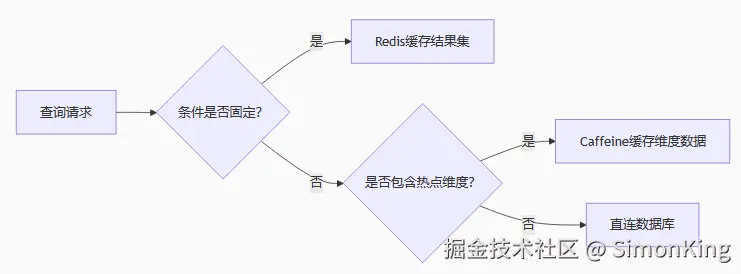
数据的缓存除了Redis或其他中间件以外,Mysql有视图功能也可以减少数据库的查询。虽然阿里规范里面不推荐使用,但也是一种方式。
多线程异步处理
对于没有关系的指标可以采取异步线程的方式分别获取常用的就是Java 8的java.util.concurrent.CompletableFuture或@Async或java.util.concurrent.ForkJoinPool等拆解任务,然后等待任务完成后合并数据即可。
3.2 建立宽表或临时表
这种解决方案针对性比较强,扩展性不足,因为建立的宽表或者临时表一般不可复用。可以从以下两个角度着手:
- 实时表
- T+1的表
实时表
建立宽表和临时表具备实时性,就需要保存基础字段,不能保存聚合字段,将所需要的字段全部同步到一张大的宽表里面,让报表的统计变成一张表的操作。
但是数据的全量和增量同步变成了重中之重。数据的增量和全量同步可以使用一些第三方插件如datax、binlog、canal、cloudCanal等同步工具。
T+1的表
T+1的表就不是实时的数据了,但是查询的性能比较高。一般的做法就是通过定时任务的方式,每天晚上计算所有的统计数据,将最终的结果保存到新表中。每天晚上的计算拉宽一点也不会影响查询的结果。
这种方案的不好的一点就是对于经常变动的数据不友好,已经处理好的数据那些数据变了需要更新则是本方案的难点。
3.3 使用其他数据库
我们经常使用的是Mysql这样的关系型数据库,他有他的性能瓶颈。我们可以使用其他数据库来弥补关系型数据库的不足。如ES、Solr等使用倒排索引的数据库。
随着大数据的普及,MPP分布式数据库悄然崛起,如Starrocks、Clickhouse、TiDb等列式存储的数据库,正是海量数据计算的处理引擎。
当然还有其他厂商推出一系列的查询工具,如阿里的open search等
当然使用这些数据库都将面临数据同步的问题,同步好了,皆大欢喜,同步延迟或者丢失,各种数据指标对不上。
04 小结
对于报表一般都有第三方工具如Tabluea、FineVis、PowerBI等,使用方便,价格也美丽。作为一个开发,要想实现报表,就得用技术去解决。
以上就是小编对于报表设计的浅薄认识,你们都是怎么实现的,评论区留言!