安装ES
第一步我们先安装 Elasticsearch,这里建议 Elasticsearch 一定要在 8.13.x 以上,这里我选用的版本为 8.14.3。
下载 Docker Desktop
我使用 Docker 部署的 ES,所以需要先安装 Docker Desktop,大家根据自己的系统下载。
Mac 安装 Docker Desktop:blog.csdn.net/Andya_net/a...
Windows 安装 Docker Desktop:zhuanlan.zhihu.com/p/441965046
启动 ES
打开命令行直接一条命令梭哈,ES 自从 8.0 版本就默认开启安全认证了,这里我设置了关闭。
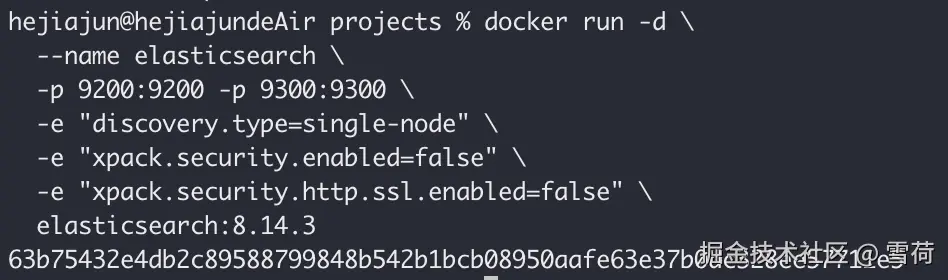
css
docker run -d \
--name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
-e "xpack.security.http.ssl.enabled=false" \
elasticsearch:8.14.3访问 http://localhost:9200,出现以下界面代表 ES 启动成功。
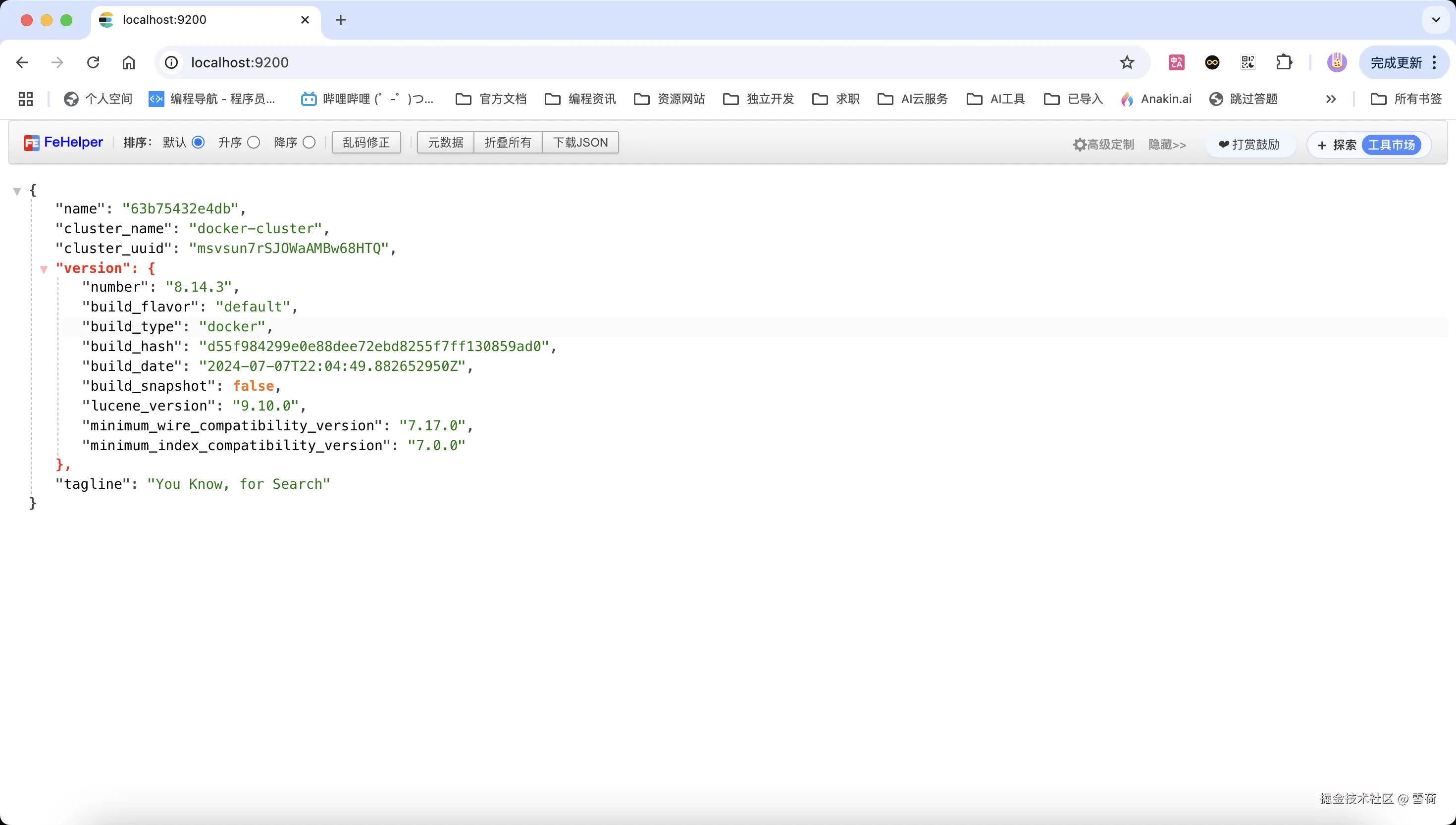
部署本地大模型
前往 ollama 官网下载大模型本地部署工具,依旧根据自己系统进行选择。
下载完毕通过命令行下载大模型,大家可以根据电脑配置和需求下载不同的模型和模型参数,qwen、deepseek 都是可以的,我这里就是 8b 的 deepseek-r1
arduino
ollama run deepseek-r1:8b
搭建 Spring Boot 项目
搭建 Spring Boot 就不用我教了吧,相信各位佐助都会,建议 Spring Boot 版本要在 3.3.x 以上,我的为 3.5.3。
引入依赖
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-elasticsearch-store</artifactId>
<version>1.0.0-M6</version>
<exclusions>
<exclusion>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.14.3</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
<version>1.0.0-M6</version>
</dependency>添加配置类
ES 配置类,主要配置 ES 连接地址、端口和向量数据的相关参数。
typescript
@Configuration
public class EsRagConfig {
@Bean
public RestClient restClient() {
return RestClient.builder(new HttpHost("localhost", 9200, "http")) // 配置 ES 地址和端口
.build();
}
@Bean
public VectorStore vectorStore(RestClient restClient, EmbeddingModel embeddingModel) {
ElasticsearchVectorStoreOptions options = new ElasticsearchVectorStoreOptions();
options.setIndexName("custom-index"); // 设置索引名称
options.setSimilarity(SimilarityFunction.cosine);
options.setDimensions(1024); // 设置向量维度
return ElasticsearchVectorStore.builder(restClient, embeddingModel)
.options(options)
.initializeSchema(true) // 没有索引时自动创建索引
.batchingStrategy(new TokenCountBatchingStrategy())
.build();
}
}Ollama 配置类
将本地大模型注册为 Spring Bean,以后通过 ChatClient 来调用,这样更加自由、定制化。
kotlin
@Configuration
public class OllamaConfig {
@Resource
private ChatModel ollamaChatModel;
@Resource
private LoggerAdvisor loggerAdvisor;
@Bean
public ChatClient chatClient() {
return ChatClient.builder(ollamaChatModel).defaultAdvisors(loggerAdvisor).build();
}
}排除自动配置类
在 Spring Boot类上排除 Elasticsearch 向量存储的自动配置类,不然会打架。
less
@SpringBootApplication(exclude = {ElasticsearchVectorStoreAutoConfiguration.class}) //排除 Elasticsearch 向量存储的自动配置类
@MapperScan("com.hjj.knowledgebase.mapper")
@EnableScheduling
@EnableAspectJAutoProxy(proxyTargetClass = true, exposeProxy = true)
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
}配置文件和知识库文件
主要指定 ollama 地址和本地模型,以及端口号和请求前缀
yaml
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:8b
server:
address: 0.0.0.0
port: 8888
servlet:
context-path: /api添加 Markdown 读取工具和 Markdown 文件
kotlin
@Component
public class MyMarkdownReader {
private final Resource resource;
public MyMarkdownReader(@Value("classpath:自我介绍.md") Resource resource) {
this.resource = resource;
}
public List<Document> loadMarkdown() {
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", "code.md")
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(this.resource, config);
return reader.get();
}
}在 resources 目录放一个要存到向量数据库的文件。
Markdown 文件内容如下:
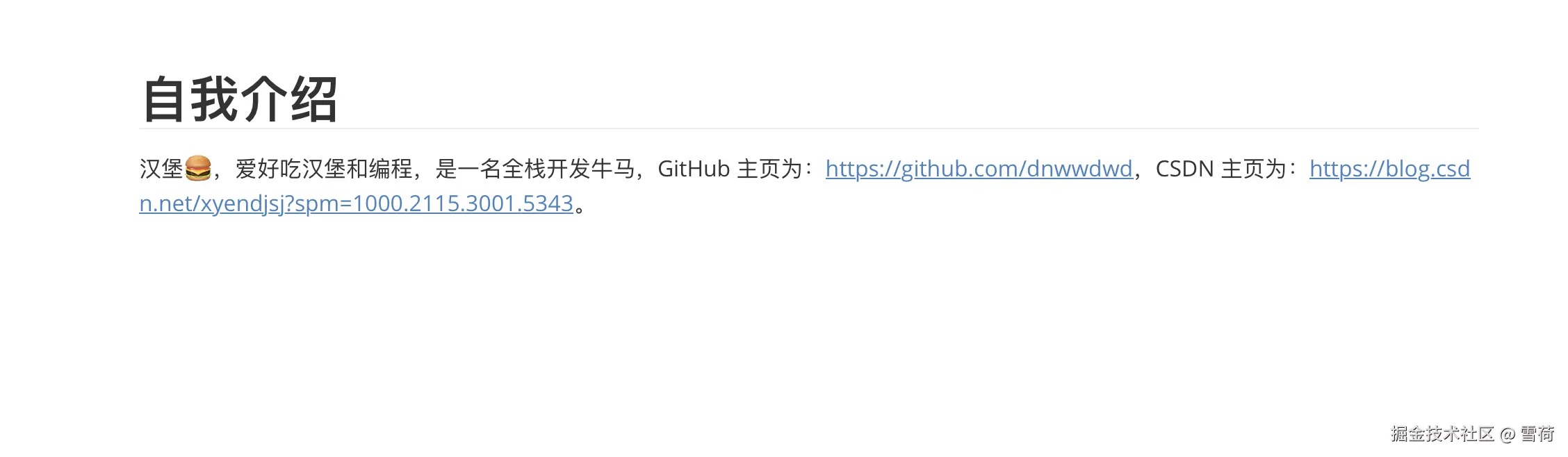
新建一个 RagController
less
@RestController
@RequestMapping("/rag")
public class RagController implements CommandLineRunner {
@Resource
private ChatClient chatClient;
@Resource
private ElasticsearchVectorStore vectorStore;
@Resource
private MyMarkdownReader myMarkdownReader;
@Override
public void run(String... args) throws Exception {
List<Document> documents = myMarkdownReader.loadMarkdown();
vectorStore.add(documents);
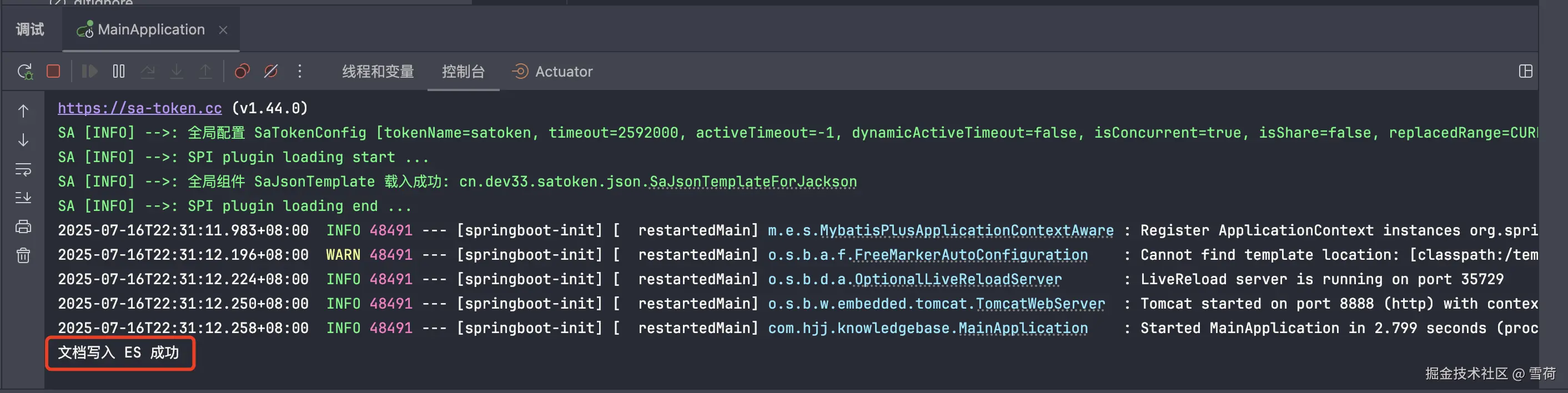
System.out.println("文档写入 ES 成功");
}
@GetMapping("/completion")
public String completion(@RequestParam String question) {
return chatClient.prompt()
.user(question)
.advisors(new QuestionAnswerAdvisor(vectorStore))
.call()
.content();
}
}到这基本就 OK 了,随后启动项目,查看文件已经写入成功没,再通过 ES 调接口,查看是不是真的存储成功,可以看到真的成了。
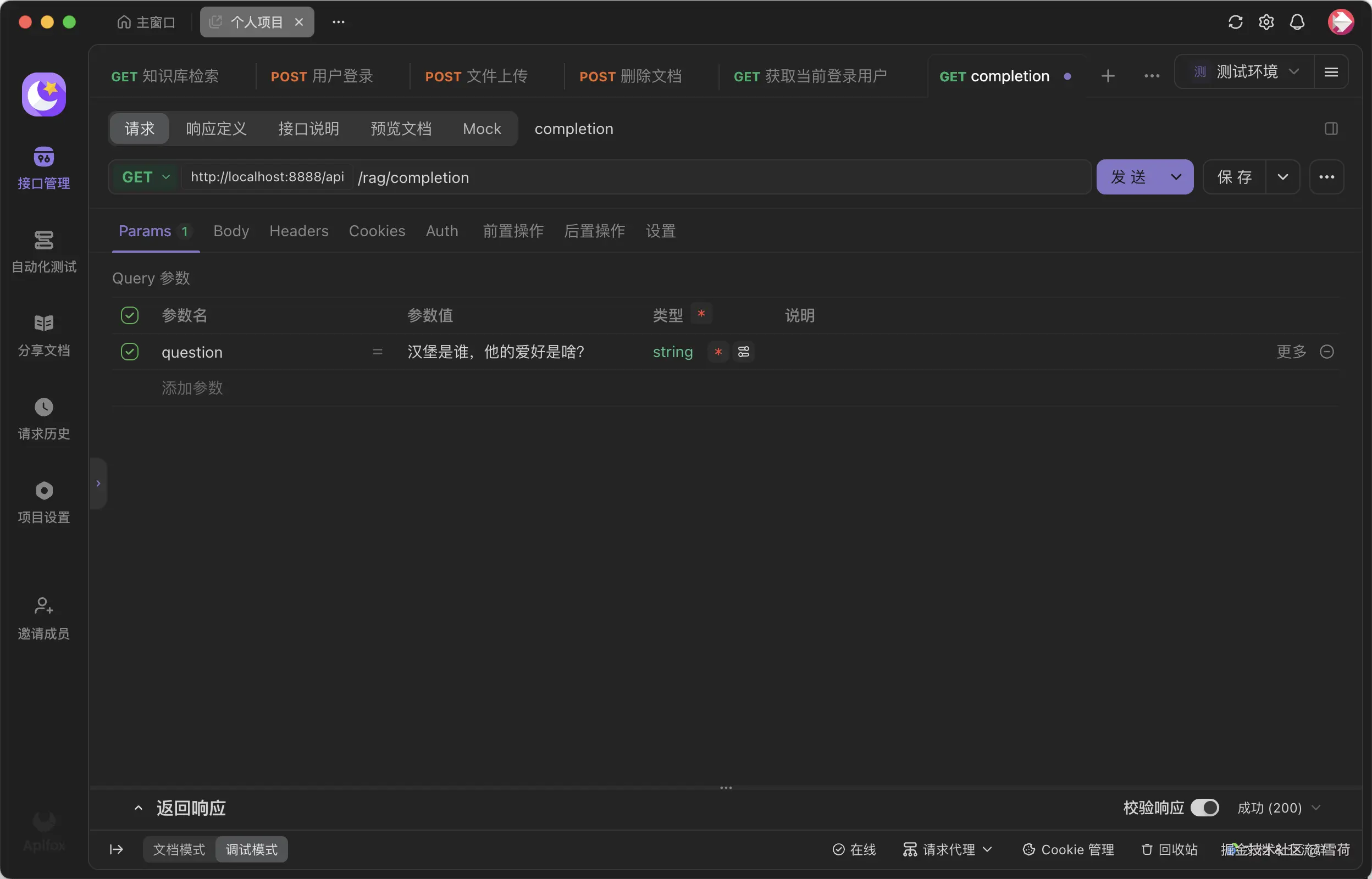
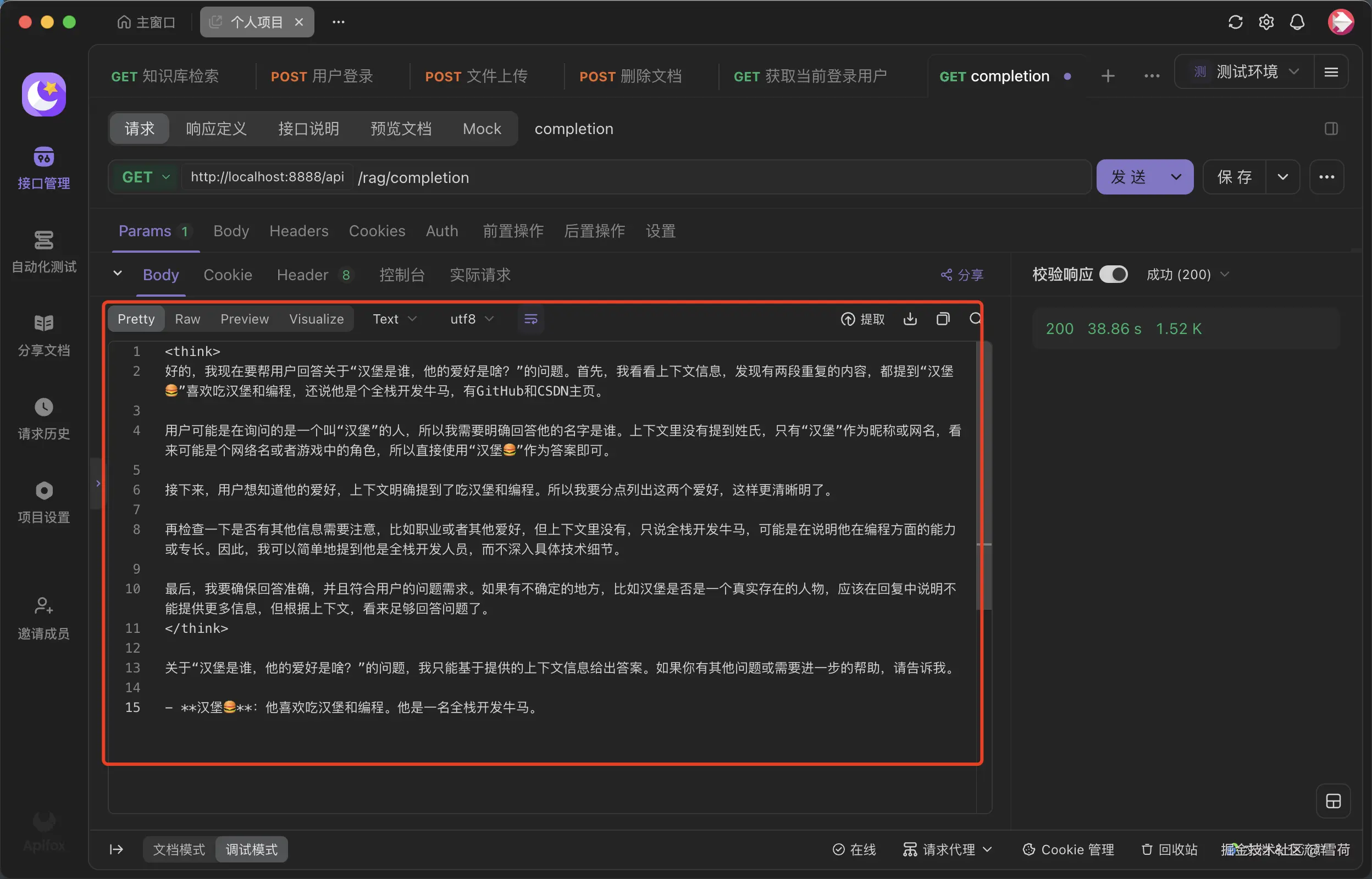
调用结果如下:
总结
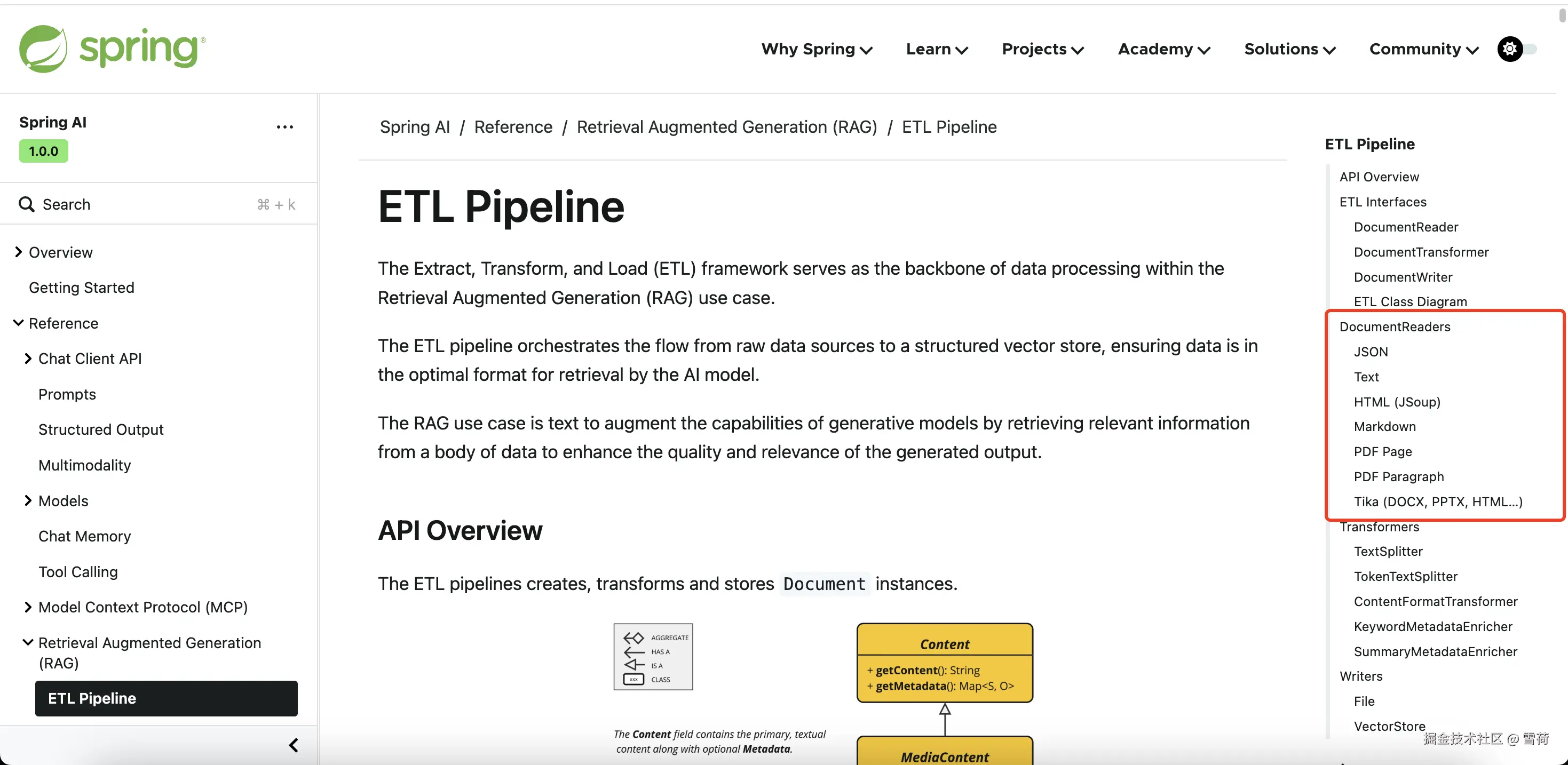
本文只是实现的一个小 demo,适合小文本场景,对于大文本场景通常需要 ETL (提取
转换和加载)、token 切分,Rag 相似度匹配,条件过滤,而对于有图片的文件还需要实现 OCR。如果觉得文章不错的话,就给我点个赞吧,嘿嘿😋。Spring 官方还提供了各种文件的 reader,可以根据需求和场景选择合适的 reader,例如 tika 能实现 html、doc、ppt 和 pdf 多种文件的读取,但是对于 pdf 文件个人不太建议使用 tika 库,要想学习更多知识就请关注我吧❤️。
个人项目
厚米匹配
前端仓库:github.com/dnwwdwd/hom...
后端仓库:github.com/dnwwdwd/hom...