国产AI大模型API入门指南:从文本生成到工具调用
一行代码调用千模之力,中国AI生态正迎来黄金时代
在AI大模型爆发的今天,API已成为连接智能能力与现实应用的桥梁 。无论是通义千问、DeepSeek还是百度文心,越来越多企业通过开放API,让开发者无需从头训练就能集成顶尖AI能力。但一个现实问题是:不同平台的API协议各异,调用方式五花八门,开发成本陡增。
一、为什么大模型平台都在做API兼容?
生态效率驱动标准化 。当前国内主流平台如阿里云百炼、火山方舟、DeepSeek、Moonshot等,纷纷兼容OpenAI风格的API协议,背后是三大动因:
- 降低开发者迁移成本:OpenAI已成为事实标准,兼容其协议可吸引庞大开发者生态
- 加速工具链统一:如LangChain、LlamaIndex等框架已内置OpenAI适配器
- 促进模型即插即用:通过统一接口,开发者可灵活切换不同模型供应商
以阿里云百炼为例,它虽自研底层架构,却完整支持OpenAI SDK调用------这正是生态智慧的体现。
二、API基础:从文本生成到工具调用
通过Node.js调用阿里云百炼API,需要先注册。
注册阿里云百炼 :新用户领千万Tokens免费额,点击开通,学习完全够用!!!
1. 文本生成(阿里云百炼实战)
javascript
/**
* 第一个文本生成对话应用
* OpenAI文本聊天功能测试应用
* 集成OpenAI SDK实现简单的文本对话功能,阿里云通义千问API
* 模型:qwen-plus
*/
import { initOpenAI } from './initOpenAI.js';
async function main() {
const completion = await initOpenAI().chat.completions.create({
model: "qwen-plus", //模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages: [
{ role: "system", content: "你是一名舆情分析师,帮我判断产品口碑的正负向,回复请用一个词语:正向 或者 负向" },
{ role: "user", content: "这款音乐软件很棒" }
],
});
console.log(JSON.stringify(completion.choices[0].message, null, 2))
}
main();输出
bash
{
"role": "assistant",
"content": "正向"
}核心参数解析
-
model: "qwen-plus"- 指定阿里云百炼平台的大模型(通义千问增强版),需在平台申请API Key并配置。
- 模型列表参考:阿里云官方模型文档。
-
messages消息结构-
role: system:设定AI角色为舆情分析师,强制约束输出格式(仅返回"正向/负向")。css{ role: "system", content: "你是一名舆情分析师...回复请用一个词语:正向 或者 负向" } -
role: user :用户输入待分析的文本,如"这款音乐软件很棒"。
-
-
输出控制
- 通过
systemprompt的严格指令,确保返回结果精简为单次(如"正向"),避免冗余解释。
- 通过
2. 工具调用-一个天气查询
大模型在面对实时性问题、数学计算等问题时可能效果不佳。可以使用 Function Calling 功能,通过引入外部工具,使得大模型可以与外部世界进行交互。 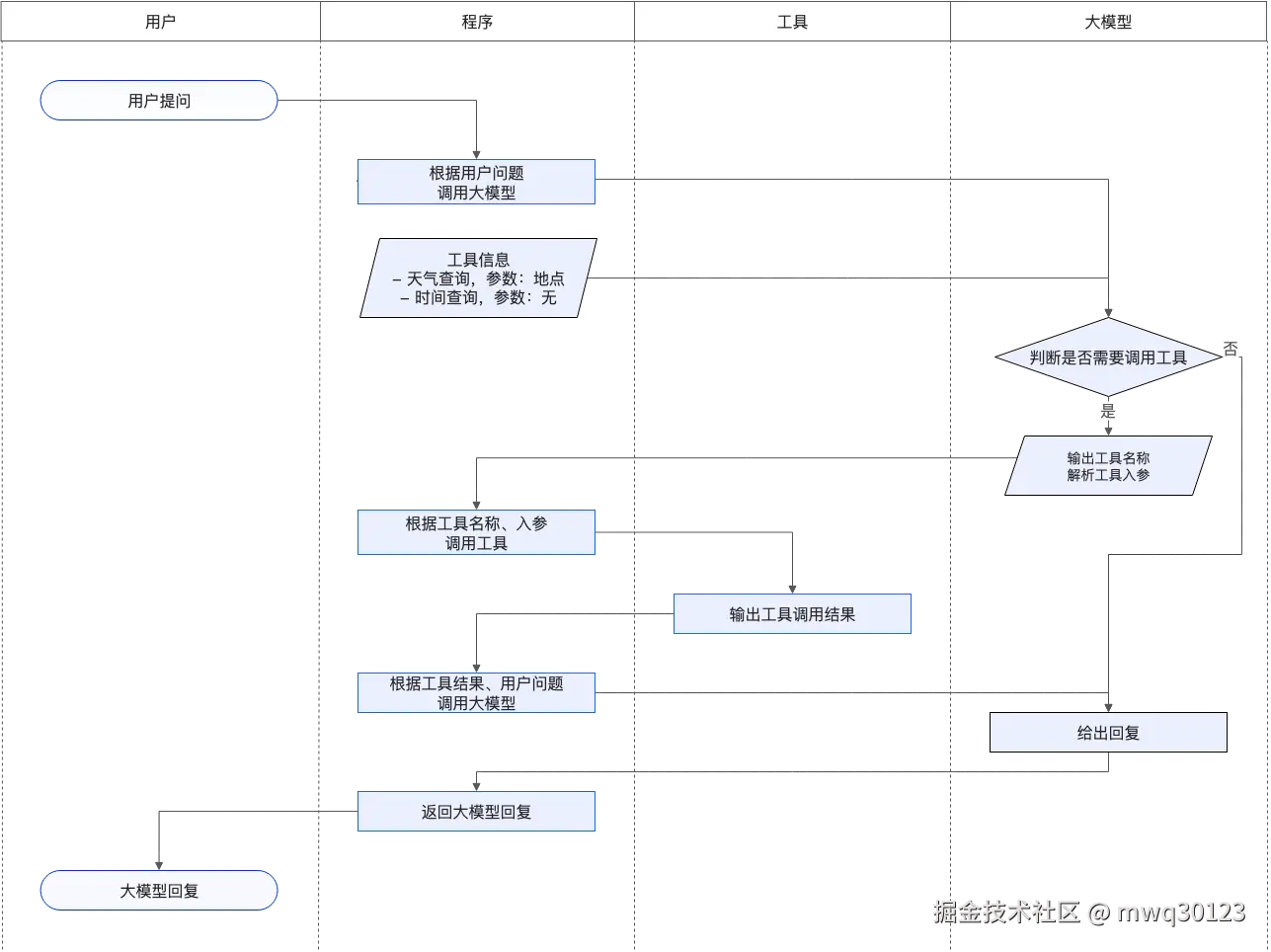 1-API使用/2-天气-FunctionCall-Qwen.js
1-API使用/2-天气-FunctionCall-Qwen.js
javascript
/**
* Function Call使用 - 天气查询功能
* 实现天气查询Function Call,支持查询城市的天气信息
*
* 关键技术点:
* 1. 使用阿里云百炼平台的qwen-turbo模型
* 2. 实现OpenAI兼容的Function Calling功能
* 3. 完整的两轮对话流程(模型决策->函数执行->结果生成)
*/
import { initOpenAI } from './initOpenAI.js';
/**
* 获取指定地点的天气信息(模拟函数)
* @param {string} location - 地点名称
* @param {string} unit - 温度单位,默认为"摄氏度"
* @returns {string} 天气信息的JSON字符串
*
* 关键说明:
* - 实际项目中应替换为真实天气API调用
* - 返回的JSON字符串将作为后续模型的输入
*/
function getCurrentWeather({ location, unit = "摄氏度" }) {
// 模拟数据(大连固定返回10度,其他城市36度)
const weatherInfo = {
location: location,
temperature: location.includes('大连') ? 10 : 36,
unit: unit,
forecast: ["晴天", "微风"]
};
return JSON.stringify(weatherInfo);
}
/**
* 工具函数映射对象
* 关键说明:
* - 用于动态调用工具函数(此处只有getCurrentWeather)
* - 函数名必须与tools定义中的name严格一致
*/
const toolFunctions = { getCurrentWeather };
/**
* 工具定义(核心配置)
* 关键参数解析:
* - type: "function" - 声明这是一个函数工具
* - function.name: 必须与实际函数名一致(大小写敏感)
* - function.description: 决定模型何时调用此函数的关键描述
* - parameters: 定义参数结构(JSON Schema格式)
* - properties: 定义每个参数的名称、类型和描述
* - required: 声明必填参数
*/
const tools = [
{
type: "function",
function: {
name: "getCurrentWeather",
description: "Get the current weather in a given location.",
parameters: {
type: "object",
properties: {
location: {
type: "string",
description: "The city and state, e.g. San Francisco, CA"
},
unit: {
type: "string",
enum: ["celsius", "fahrenheit"] // 限制可选值
}
},
required: ["location"] // 必须提供location参数
}
}
}
];
/**
* 获取模型响应
* @param {Array} messages - 消息历史数组
* @param {Array} tools - 工具定义数组
* @returns {Promise<Object>} API响应对象
*
* 关键参数说明:
* - model: "qwen-turbo" - 指定使用的阿里云百炼模型
* - messages: 包含role为system/user/assistant的对话历史
* - tools: 传入工具定义数组
* - tool_choice: "auto" - 让模型自主决定是否调用工具
*/
async function getModelResponse(messages, tools) {
const openai = initOpenAI();
return await openai.chat.completions.create({
model: "qwen-turbo",
messages: messages,
tools: tools,
tool_choice: "auto" // 也可指定为{"type: "function", function: {name: "getCurrentWeather"}}强制调用
});
}
/**
* 主对话流程
* 关键流程说明:
* 1. 初始化系统提示和用户问题
* 2. 第一次调用API获取模型响应
* 3. 检查是否需要调用工具函数
* 4. 执行工具函数并追加结果到对话历史
* 5. 第二次调用API获取最终回复
*/
async function main() {
const userQuery = "大连的天气怎样";
const messages = [
{
role: "system",
content: "你是一个很有帮助的助手。如果用户提问关于天气的问题,请调用天气查询函数。回答时请使用友好语气。",
},
{ role: "user", content: userQuery }
];
// 第一轮API调用:模型决策阶段
console.log('[1] 发送初始请求...');
const firstResponse = await getModelResponse(messages, tools);
const assistantMessage = firstResponse.choices[0].message;
messages.push(assistantMessage);
console.log('[2] 模型首次响应:', JSON.stringify(assistantMessage, null, 2));
// 检查工具调用
if (assistantMessage.tool_calls) {
const toolCall = assistantMessage.tool_calls[0];
console.log('[3] 检测到工具调用:', toolCall.function.name);
// 解析参数并执行函数
const args = JSON.parse(toolCall.function.arguments);
console.log('[4] 函数参数:', args);
const functionResult = toolFunctions[toolCall.function.name](args);
console.log('[5] 函数执行结果:', functionResult);
// 追加工具执行结果到对话历史
messages.push({
role: "tool",
tool_call_id: toolCall.id, // 必须与调用请求的ID匹配
content: functionResult
});
// 第二轮API调用:生成最终回复
console.log('[6] 发送工具执行结果给模型...');
const finalResponse = await getModelResponse(messages, tools);
console.log('[7] 最终回复:', JSON.stringify(finalResponse.choices[0].message, null, 2));
} else {
console.log('模型未触发工具调用,直接返回结果');
}
}
// 启动对话
console.log("启动天气查询对话系统...");
main().catch(err => console.error('流程执行出错:', err));
css
启动天气查询对话系统...
[1] 发送初始请求...
[2] 模型首次响应: {
"content": "",
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "getCurrentWeather",
"arguments": "{\"location\": \"大连\"}"
},
"index": 0,
"id": "call_5ffd203437414791a0a4c7",
"type": "function"
}
]
}
[3] 检测到工具调用: getCurrentWeather
[4] 函数参数: { location: '大连' }
[5] 函数执行结果: {"location":"大连","temperature":10,"unit":"摄氏度","forecast":["晴天","微风"]}
[6] 发送工具执行结果给模型...
[7] 最终回复: {
"content": "大连现在的天气是晴天,气温为10摄氏度,微风。",
"role": "assistant"
}3. 多模态实践
什么是多模态(Multimodal)
多模态 是指模型能够同时处理并理解多种类型的数据输入,比如:
- 文本(Text)
- 图像(Image)
- 音频(Audio)
- 视频(Video)
甚至结构化数据或传感器数据,在本例中:
模型接受了 图像(image_url) 和 文本提问(text) 的联合输入,并输出对图片内容的理解结果(比如画面内容描述、对象识别、场景判断等)。这类多模态模型可以执行"看图说话"、"图文问答"、"图像摘要"等任务,是目前最前沿的AI能力之一。
3.1-图片分析-视觉理解-多模态-Qwen copy.js
javascript
/**
* 图片分析功能 - 多模态对话
* 使用通义千问API分析图片内容
* 支持图片URL和文本输入,输出图片分析结果
*/
import { initOpenAI } from './initOpenAI.js'; // 初始化通义千问兼容OpenAI风格的客户端实例
async function main() {
// 定义图像URL(可以是任意公网可访问的图片)
const imageUrl = "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg";
// 调用通义千问 qwen-vl-plus 模型进行多模态对话(支持图像+文字)
const response = await initOpenAI().chat.completions.create({
model: "qwen-vl-plus", // 多模态模型,支持图像与文字联合理解
messages: [
{
role: "user",
content: [
// 输入的图片内容,类型为 image_url
{ type: "image_url", image_url: { url: imageUrl } },
// 对图片提出的问题(图文混合输入)
{ type: "text", text: "图中描绘的是什么景象?" }
]
}
],
});
// 输出模型对图像及问题的分析结果
console.log("API响应:", response.choices[0].message.content);
}
main(); // 执行主函数
markdown
API响应: 图中描绘的是一幅温馨和谐的海滩景象。画面中有一个人和一只狗在沙滩上互动。具体细节如下:
1. **人物**:一位女性坐在沙滩上,穿着格子衬衫和黑色裤子,面带微笑,显得非常开心和放松。她的姿态自然,似乎在与狗进行友好互动。
2. **动物**:一只金毛犬坐在女性面前,戴着彩色的项圈,看起来很温顺。它正伸出前爪,与女性的手相触碰,显示出一种友好的交流。
3. **环境**:背景是广阔的海洋和天空,海浪轻轻拍打着岸边,远处的海水呈现出柔和的蓝色调。天空的颜色渐变,可能是日出或日落时分,光线温暖而柔和,给整个场景增添了一种宁静和美好的氛围。
4. **氛围**:整体画面给人一种轻松愉快的感觉,展现了人与宠物之间的亲密关系以及与自然环境的和谐共处。阳光洒在沙滩上,使得整个场景显得格外温暖和美丽。
这张照片捕捉到了一个简单而美好的瞬间,体现了生活中人与宠物之间的情感纽带以及与大自然的亲近感。参考图片 
php
/**
* 文字提取功能 - 多模态对话
* 使用通义千问API提取图片中的文字内容
* 支持图片URL和文本输入,输出JSON格式的文字数据
*/
import { initOpenAI } from './initOpenAI.js'; // 引入通义千问 OpenAI 兼容 SDK 初始化模块
async function main() {
// 图片地址:此处为一张车票图像,必须是公网可访问的 URL
const imageUrl = "https://img.alicdn.com/imgextra/i2/O1CN01ktT8451iQutqReELT_!!6000000004408-0-tps-689-487.jpg";
// 调用多模态 OCR 模型(专用于图像文字识别及结构化抽取)
const response = await initOpenAI().chat.completions.create({
model: "qwen-vl-ocr-latest", // 模型名称:通义千问 OCR 多模态模型,适合结构化文档识别
messages: [
{
role: "user",
content: [
// 图像输入:用于识别的车票图像
{ type: "image_url", image_url: { url: imageUrl } },
// 任务指令:使用自然语言明确指定要提取的字段
{
type: "text",
text: `请提取车票图像中的发票号码、车次、起始站、终点站、发车日期和时间点、座位号、席别类型、票价、身份证号码、购票人姓名。
要求准确无误地提取上述关键信息,不要遗漏,也不要捏造虚假信息。
对于模糊或强光遮挡导致无法识别的字符,请用英文问号 ? 替代。
返回格式请使用 JSON,结构如下:
{'发票号码':'xxx','车次':'xxx','起始站':'xxx','终点站':'xxx','发车日期和时间点':'xxx','座位号':'xxx','席别类型':'xxx','票价':'xxx','身份证号码':'xxx','购票人姓名':'xxx'}`
}
]
}
]
});
// 输出提取结果(控制台打印 JSON 格式)
console.log("API响应:", response.choices[0].message.content);
}
main(); // 执行主程序
json
{
"发票号码": "2432911680400000000",
"车次": "G1948",
"起始站": "南京南站",
"终点站": "郑州东站",
"发车日期和时间点": "11:46开",
"座位号": "04车12A号",
"席别类型": "二等座",
"票价": "337.50",
"身份证号码": "4107281991****5515",
"购票人姓名": "读小光"
}这部分内容展示了如何通过 Node.js 使用阿里云百炼平台(通义千问)的 API,实现从基础文本生成到多模态感知的完整应用流程。以下是总结与说明:
三、API 基础能力总结
1. 文本生成:舆情分析
-
应用场景:判断一句话是正面还是负面情绪。
-
实现要点:
- 使用模型:
qwen-plus systemprompt 设定角色(如舆情分析师),明确输出格式(如只返回"正向"或"负向")。- 优势:可构建自动化评论分析、产品反馈判定、AI客服预判断等能力。
- 使用模型:
2. 工具调用(Function Calling):天气查询
-
应用场景:用户提问天气,AI判断意图后自动调用"getCurrentWeather"函数查询。
-
实现要点:
- 使用模型:
qwen-turbo - 注册函数(
tools)→ 模型自动判断是否调用 → 模拟执行 → 回传结果再生成最终答复。 - 关键逻辑:两轮对话处理流程(模型先判断,再处理函数结果)。
- 扩展能力 :天气查询只是范例,实际上你可以定义 任意函数(如搜索航班、查汇率、查日程等)并通过模型调用。
- 使用模型:
3. 多模态能力(图文结合)
📸 图像理解
- 应用场景:看图说话、图片问答、画面情感判断。
- 使用模型 :
qwen-vl-plus - 功能:输入图像 URL 和提问文本,模型能结合图像内容作出自然语言回答。
🧾 图像文字提取(OCR)
- 应用场景:从图片中提取结构化文字(如车票、发票、证件等)。
- 使用模型 :
qwen-vl-ocr-latest - 功能:结合视觉+语言理解,实现表单式字段抽取,并输出为 JSON。
🧭 还有更多 API 值得探索(可参考阿里云百炼控制台)
- 代码生成与解释:构建编程助手。
- 语义搜索:智能问答系统、知识库检索。
- 音频转文本 / 语音问答:打造语音助手。
- 视频内容分析:理解视频片段、生成视频摘要。
- 长文本摘要 / 文本翻译:文档处理、跨语言沟通。
- 角色扮演对话:客服机器人、教育陪练。
- 结构化信息提取:合同字段抽取、信息聚合等。
📌 建议下一步:你可以尝试自定义函数并结合模型使用(如股票价格查询、日历提醒等),打造你自己的 AI 工具箱。
总结
通过上文我们可以看到,阿里云百炼等平台已经提供了统一、兼容 OpenAI API 的调用方式,让开发者可以快速接入通义千问的文本生成、多模态理解、OCR识别等强大能力。但平台调用并非唯一选择 ,对于有更高自定义需求、私有化部署要求或成本控制目标的团队来说,也可以选择在本地或云端自行部署 DeepSeek、Moonshot、LLaMA、Qwen 等开源大模型,形成"自部署 + API 调用"双轨并行的架构。这样不仅可以避免部分调用限制,还能根据业务场景灵活控制模型精度、推理速度与成本。
下篇内容我们将重点介绍如何部署 DeepSeek 大模型,以及如何通过 API 对接,实现类似 OpenAI 的推理调用体验。