前言
年初DeepSeek-R1发布后各大模型掌握了性能飞升的核心能力,当今大模型领域已然发展成为百家争鸣的态势。国内有深度求索DeepSeek, 阿里巴巴Qwen3扛大旗,国外有Google Gemini, Anthropic Claude4龙争虎斗。作为老牌王者OpenAI虽然仍然有GPT-4o领先榜单,但相比这些后起之秀热度明显低了不少,各大公司也对最强大模型的王座虎视眈眈。然而近期OpenAI在开源、闭源领域齐发力发布了GPT-OSS 和最令人期待的GPT-5模型宣告了大模型领域的王座依然属于OpenAI,大有一统江湖之势。本篇分享笔者就和大家一起来看看OpenAI发布的这两款模型的核心特性。
笔者特别总结了国内GPT-OSS 模型和GPT-5 模型的使用方法,详细使用指南大家可关注笔者的同名微信号:大模型真好玩 并私信OpenAI模型调用指南免费获得。
一、开源模型------GPT-OSS
1.1 GPT-OSS模型背景
OpenAI一直希望通过自家具备先发优势闭源模型进行垄断,但各路开源大模型的异军突起和百家争鸣还是让这位王者感到危机。尤其是今年DeepSeek-R1的爆火让全世界看到了开源社区的力量以及开源背后巨大的商业价值,山姆奥特曼(OpenAI CEO)更是在1月31号的采访中公开承认闭源是历史发展的错误方向。

当地时间2025年8月5日,OpenAI发布了GPT-OSS-20B 和GPT-OSS-120B 两款模型。这是OpenAI自2019年开源GPT-2模型以来首个开源的对话模型。不仅性能上追平了自家的O4模型,并且得益于MOE架构以及原生混合FP4(MXFP4)权重精度,GPT-OSS-20B模型在最低16G显存即可运行。(OpenAI也开始追求显存占用性能了),并且响应速度极快。经实测,GPT-OSS-20B在3090上能达到40+tokens/s, 在5090上更是能达到恐怖的200+tokens/s。并且GPT-OSS模型还支持各类主流GPU及推理框架进行部署使用,同时支持CPU+GPU混合推理。
笔者第一时间对GPT-OSS模型进行了本地部署和调用测试,根据实际测试结果GPT-OSS在编程、推理、工具调用、Agent开发等方面表现非常惊艳,是目前当之无愧的开源SOTA大模型。
1.2 GPT-OSS核心特性
尽管OpenAI长期被业内嘲笑为是CloseAI, 但这次GPT-OSS模型的开源相比其它硅谷科研巨头:比如谷歌只开源小尺寸模型、马斯克只开源过时模型、Meta Llama的弄虚作假,OpenAI这次开源的模型才是真正意义的工业级可用的大模型。
架构方面: GPT-OSS是MoE混合专家模型,并且采用了目前最先进的分组多查询注意力机制,能更好的平衡模型性能和实际响应效率。可以说尽管GPT-OSS是推理模型,但实际响应效率无限接近于对话模型。并且模型原生支持FP4混合精度,能够进一步压缩模型推理和微调所需的硬件成本,其中20B版本的模型推理仅需16G显存,微调仅需24G显存,是真正意义上的消费级显卡可用的大模型。

性能卓越: GPT-OSS-20B模型拥有堪比o3-mini级别模型的性能,而GPT-OSS-120B模型能力更是达到了o4-mini模型级别。根据官方给出的评分结果:无论是在数学、推理、编程还是在前段时间Grok-4发布会上大放异彩的人类终极测试(HLE)等评估指标上,GPT-OSS-20B模型能力都介于o3-mini和o4-mini之间,而GPT-OSS-120B模型则是和o4-mini模型不相上下。也就是OpenAI开源的OSS系列模型是仅次于OpenAI o3模型的第二梯队模型。与Qwen3-235B-A22B-Thinking-2507进行比较,GPT-OSS-120B以不到一半的参数量和硬件成本就超越了235B的模型性能。此外GPT-OSS还支持工具调用、结构化输出等各项功能,甚至和o3、o4模型一样,GPT-OSS还可以自由控制模型的推理强度,从而更好的平衡响应速度和推理性能。
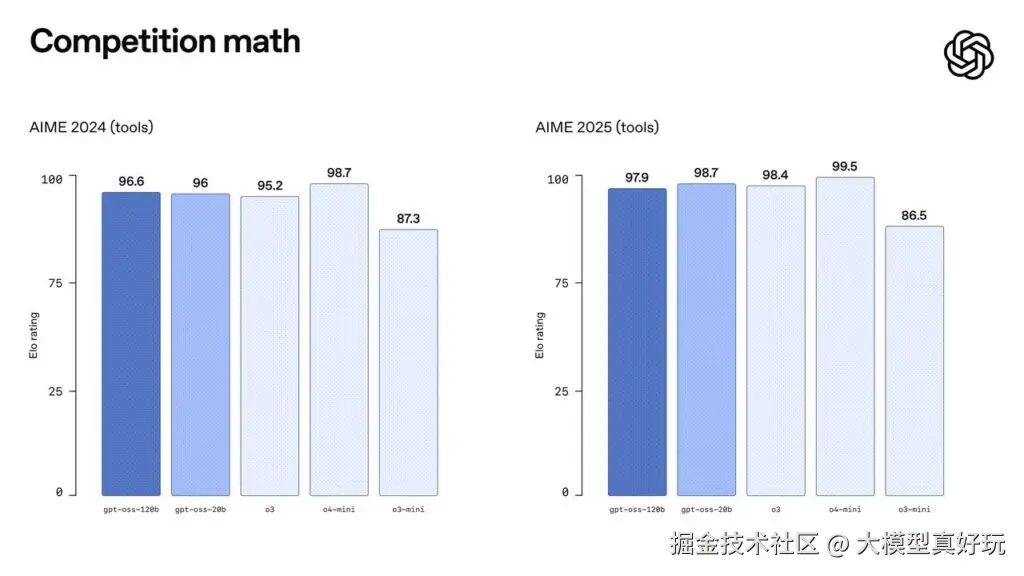
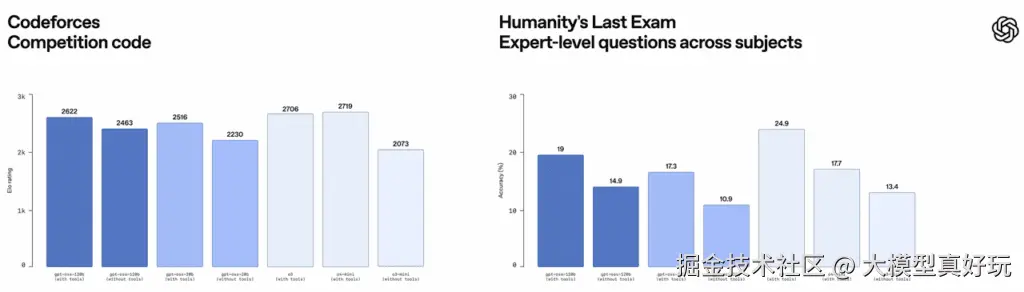
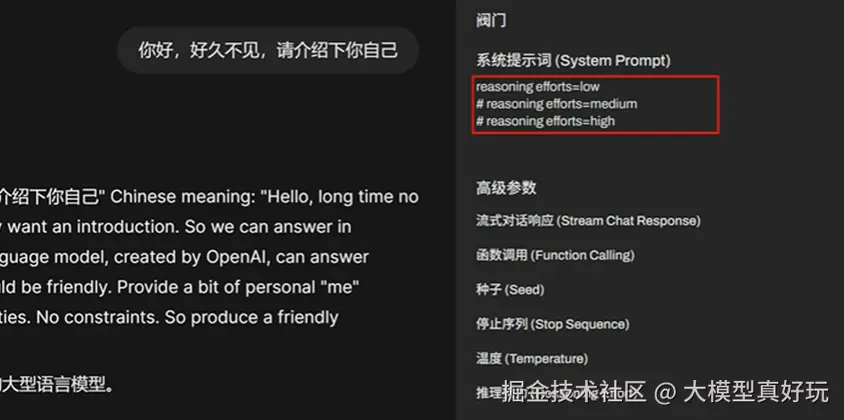
训练流程: GPT-OSS如此高性能的原因是该模型采用了和o4模型完全相同的训练流程,也就是先进行模型预训练,然后进行全量指令微调,最后进行RL强化学习后训练这一训练流程。并且相比DeepSeek-R1,GPT-OSS采用了更加严格的无监督CoT对齐方法,从而使得模型推理更加高效严谨。和o3、o4模型类似,GPT-OSS模型也支持通过系统提示词来手动设置模型推理强度,推理强度越高推理时间越久能够更好解决更复杂的问题,但响应速度会变慢。反之推理强度越低模型有可能在1s内就返回思考但是解决复杂问题的能力下降。
1.3 GPT-OSS发布的意义
GPT-OSS模型是OpenAI最有诚意的一次开源,同时这款模型也再次刷新了开源模型能力上限。笔者也非常期待伴随这款模型的诞生,能否更快速的推动开源大模型技术社区发展。
二、GPT-5: 真神降临?
2.1 GPT-5模型背景
2023年3月14日,在绝大多数大模型还不会正常说人话时,OpenAI重磅发布了GPT-4模型正式开启了大模型时代。大模型技术给世界带来了革命性的影响,这一切GPT-4功不可没。可以说当时的GPT-4模型有多惊艳,大家对GPT-5模型的期待值就有多高。但不幸的是GPT-4模型发布后的两年时间里,GPT-5一直处于难产状态。令人意外的是,在GPT-OSS 发布后不久,GPT-5被隆重推出,这会是一个划时代的符号吗?
GPT-5本次共发布了三款模型,分别是大参数的GPT-5 、中参数的GPT-5 Mini 和小参数的GPT-5 Nano以满足不同场景的实际应用需求。

2.2 GPT-5核心特性
训练流程: GPT-5借助了合成数据进行预训练,同时借助强化学习后训练给模型赋予某些特定领域的能力,尤其是强化模型的推理、编程、指令跟随和工具调用能力,从而更好的满足当下用户以Agent开发和编程为主的使用需求。毫无疑问这个策略是非常成功的。
具备功能: GPT-5是最新一代的混合推理模型,开发者可以通过控制reasonning_effort参数来设置模型思考深度。和GPT-OSS类似,低推理模式下模型思维链较短推理性能较弱。强推理模式下模型思考链很长,模型推理能力更强但响应速度会变慢。甚至可以将模型参数设置为minimal使模型不进行任何思考快速回答。这种可控的混合推理模式无疑为开发者提供了极大的便利。此外 GPT-5模型还支持输出不同详细程度的结果以更好应对不同使用场景。

性能方面: GPT-5可以说是刷爆了所有榜单,无论是推理能力,还是代码能力。无论是指令跟随能力还是工具调用能力,GPT-5模型的评分相比于o3模型暴涨了10%以上,并且完胜目前市面上各类大模型,这也使得GPT-5模型成为当之无愧的最佳编程模型和Agent开发基座模型。同时GPT-5还是独一无二的博士级科研助手,最重要的使GPT-5的幻觉大幅度减少,仅为O3模型的10%左右,模型整体的可用性大幅提升。此外面对一些敏感问题,GPT-5也不再会简单粗暴地拒绝回答,而是谆谆善诱地指出问题的不合理性并引导用户提出更加合理的问题。
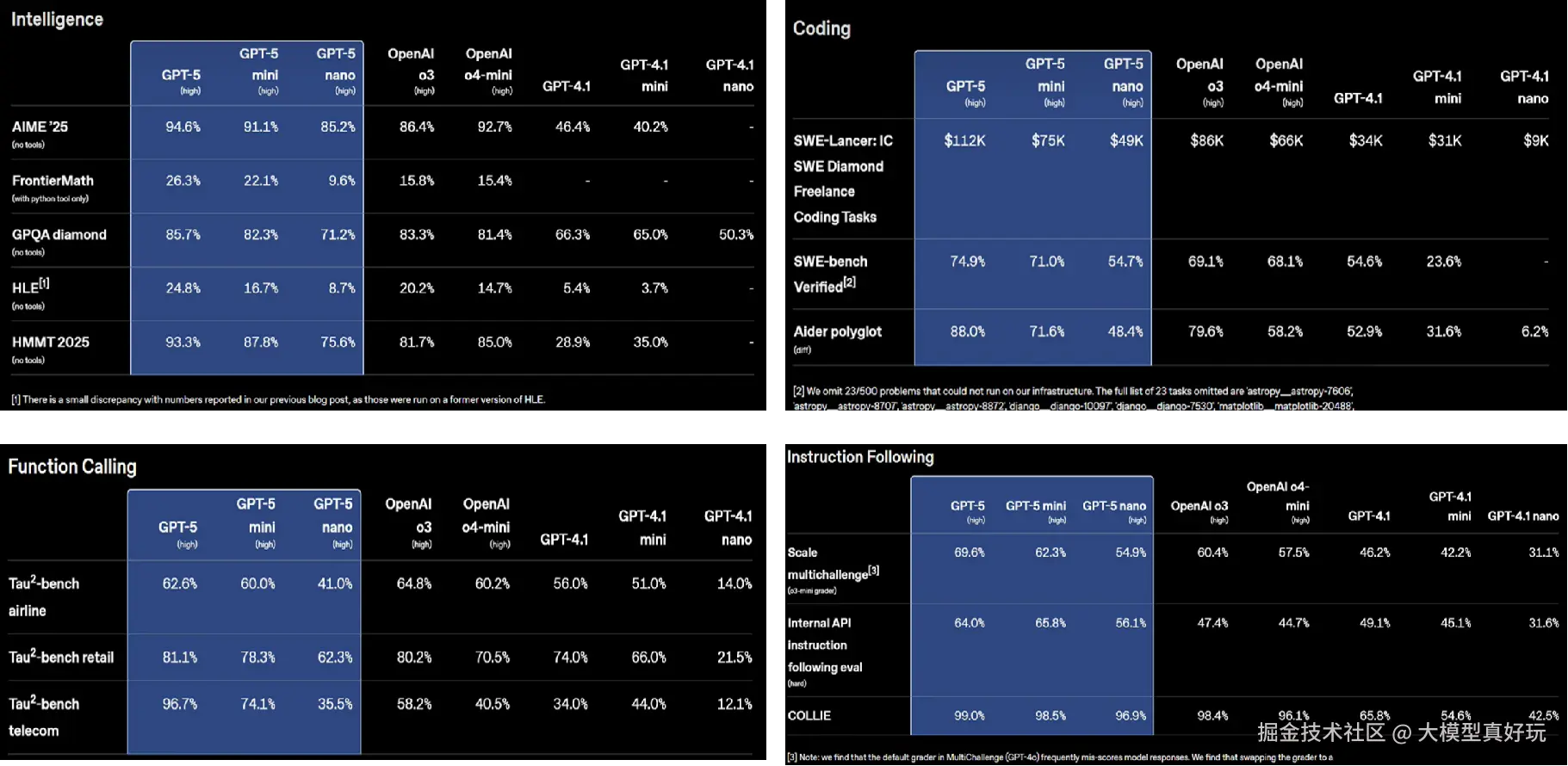
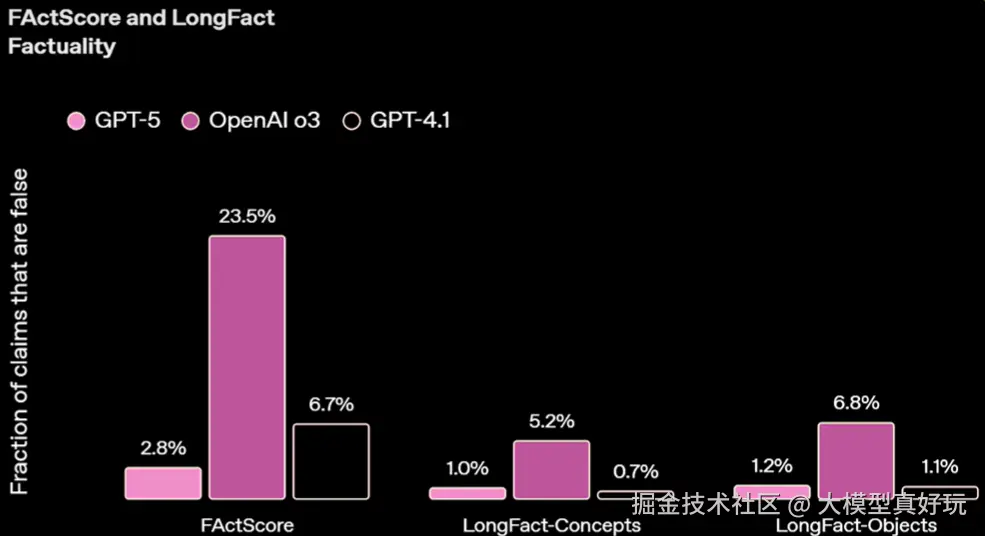
本次GPT-5模型最大的功能特点是其强悍的编程能力,在GPT-5的发布会上甚至有一半的时间都用来演示GPT-5模型的编程性能。在GPT-5发布的第一时间OpenAI更是在官网上提供了上百个GPT-5编程demo及背后的提示词模板,这也足见OpenAI对GPT-5模型编程能力的自信。根据笔者的实际测试结果,GPT-5单次响应可以完成上千行代码的编写,制作的前端页面美观大方,功能完整。制作的各类小游戏互动性强,功能齐全,制作的仪表盘条理清晰,整洁美观。此外无论是制作功能向的工作流插件还是各类小游戏GPT-5都是手到擒来。
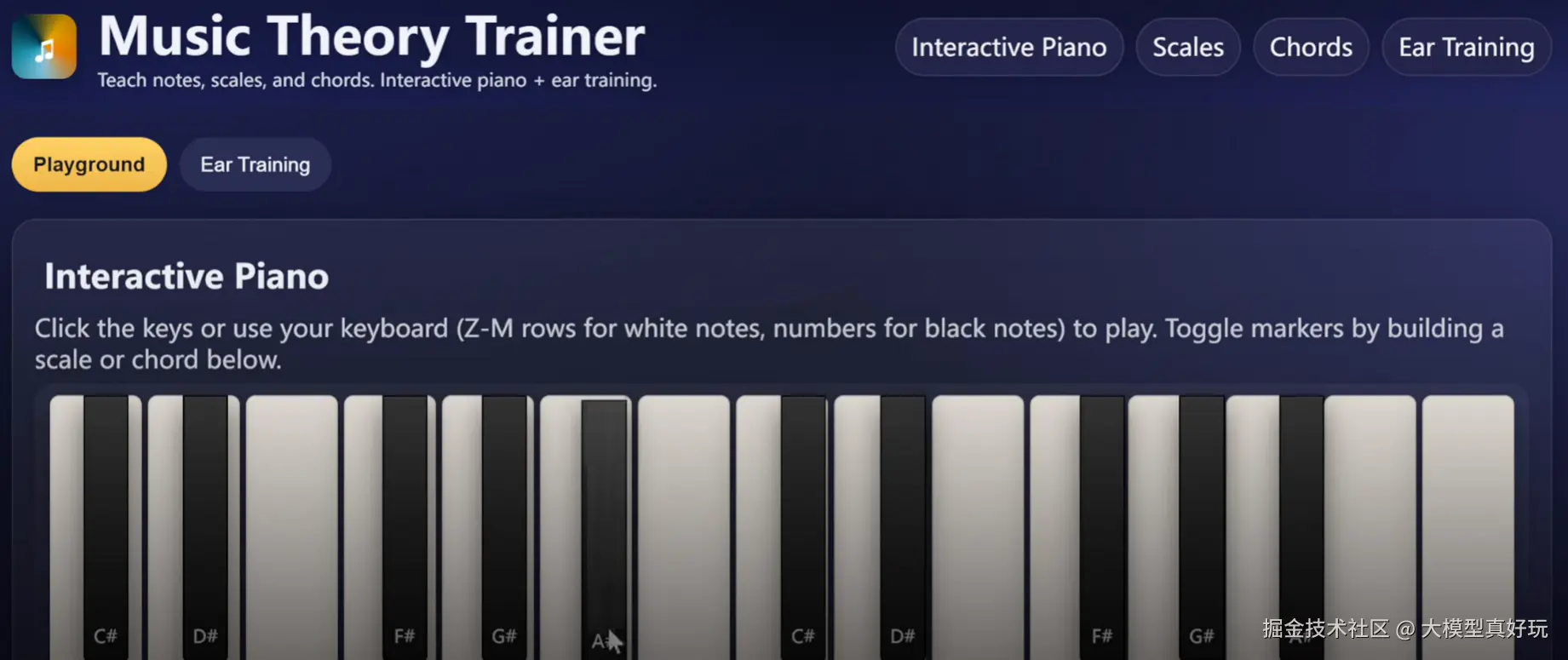
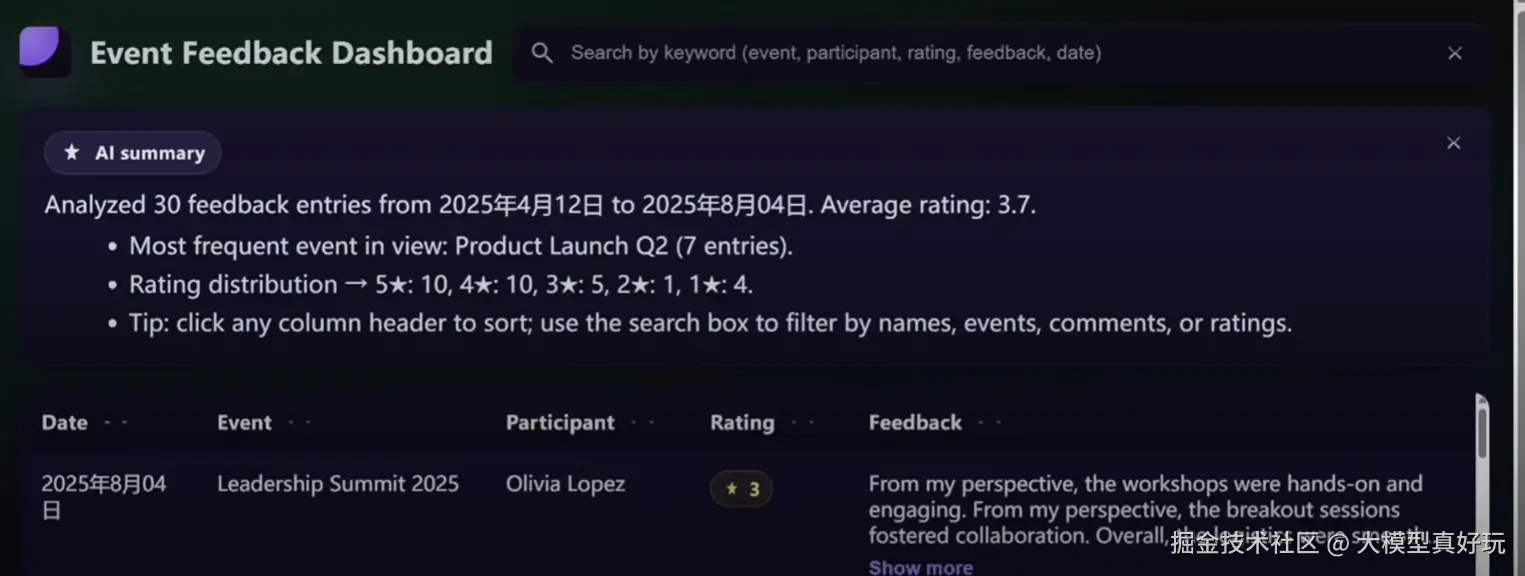
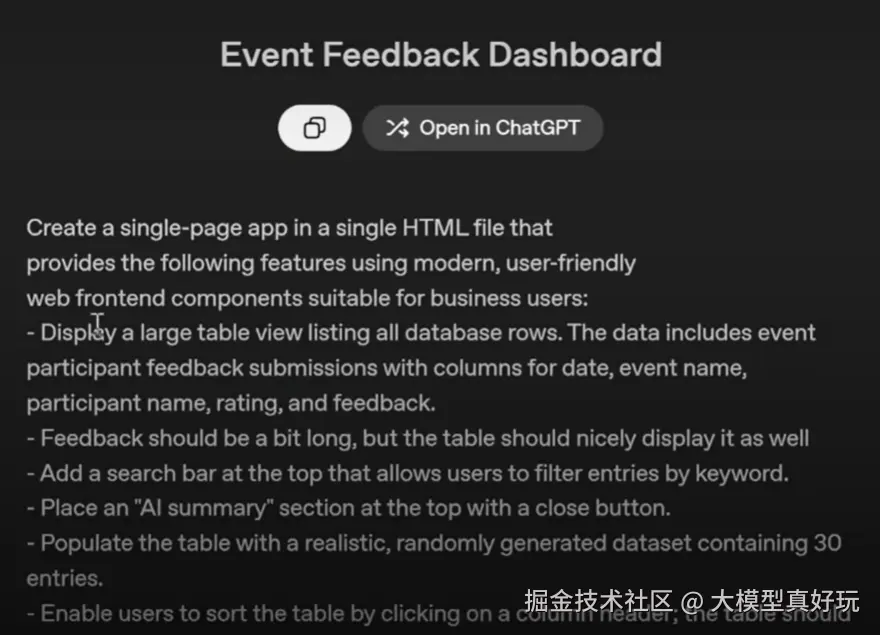
除了拥有非常强大的原生编程能力外,GPT-5还擅长调用各类工具来完成复杂编程任务,例如GPT-5在Cursor的Agent模式中借助Cursor内置的summary等工具一次性读取上万行代码并进行debug, 还能借助Cursor的files等工具一次性创建包含多个代码文件并且拥有复杂前后端功能的完整项目。简而言之就是各类编程Agent还能进一步放大GPT-5模型的编程能力,这也是为何Cursor的CEO和Windsurf CEO等一众大佬齐声惊呼GPT-5是最强编程大模型的原因了。

价格低廉: 拥有如此强大的编程性能GPT-5的使用费用更让人惊喜,只有Claude-4的1/3,笔者也是第一时间将GPT-5设置为我Cursor的首选模型。

2.3 GPT-5争议频出
GPT-5的发布并不如GPT-OSS一样顺风顺水,相反争议频出。有人表示,GPT-5在前端体验、减少幻觉和提升写作质量方面有显著改进,免费用户和企业用户将感受到明显的提升。但也有不少人给出了差评。
有网友让GPT-5制作了一个《Flappy Bird》小游戏,GPT-5 生成的游戏网页根本点不进去,相比之下,Claude Sonnet4 生成效果相当不错,画风可爱、真实可玩。还有网友使用 GPT-5 重构代码库,尽管代码看起来非常漂亮、整洁,但最终并没有成功运行。
明明都是 GPT-5,为什么大家的体验结果大相径庭?难道说Cursor和WindSurf创始人不懂大模型,显然不是。宾夕法尼亚大学沃顿商学院教授 Ethan Mollick 认为,由于 GPT-5 是个集成模型,其中一些模型表现优异,而另一些则较为平庸。 OpenAI 并未公开底层模型选择的细节,这种不透明性可能导致用户对 GPT-5 的表现感到困惑。
笔者通过将近10天的实际评测发现,GPT-5更适合于提示词完整、逻辑明确的问题,GPT-5在简单问题和复杂问题的表现不太稳定,复杂问题上的表现有时比简单问题还要好。但总体来说GPT-5还是一个非常好用的编程助手。
三、 总结
OpenAI在开源和闭源双向发力的举动坐实了大模型领域的头号交椅,在基座模型发展竞争如此激烈的今天,OpenAI全新一代GPT-5模型还能有如此重大的能力突破确实让人非常惊喜。但值得注意的是大模型的进步范围确实放缓了,如果说GPT-4是"生产汽车本身",那之后训练优化的GPT-5就是"给汽车升级性能",虽然汽车一直在进步,但什么时候才能出现超脱汽车本身的交通工具呢?
本篇文章是笔者对于近期OpenAI系列模型测评使用的感悟分享,笔者的《深入浅出LangChain&LangGraph》系列文章本周也会继续更新,保证大家看完一定能够掌握LangChain&LangGraph的开发能力,大家感兴趣可关注笔者掘金账号和专栏,更可关注笔者的同名微信公众号:大模型真好玩, 免费获得笔者工作实践中的大模型相关资料分享。