Change Data Capture (CDC) 是一种高效的数据同步技术,能够捕获数据库的变更(插入、更新、删除)并实时传输到其他系统。结合 Kafka Connect,我们可以构建一个可靠、可扩展的 CDC 管道,实现数据库与数据湖、数据仓库或消息队列的无缝集成。
本文将介绍:
- CDC 的基本概念 及其应用场景
- Kafka Connect 的架构 及其在 CDC 中的作用
- Debezium 作为 CDC 工具 的工作原理
- 完整示例:如何使用 Kafka Connect + Debezium 捕获 MySQL 变更并写入 Kafka
- 最佳实践 与常见问题
1. Change Data Capture (CDC) 简介
什么是 CDC?
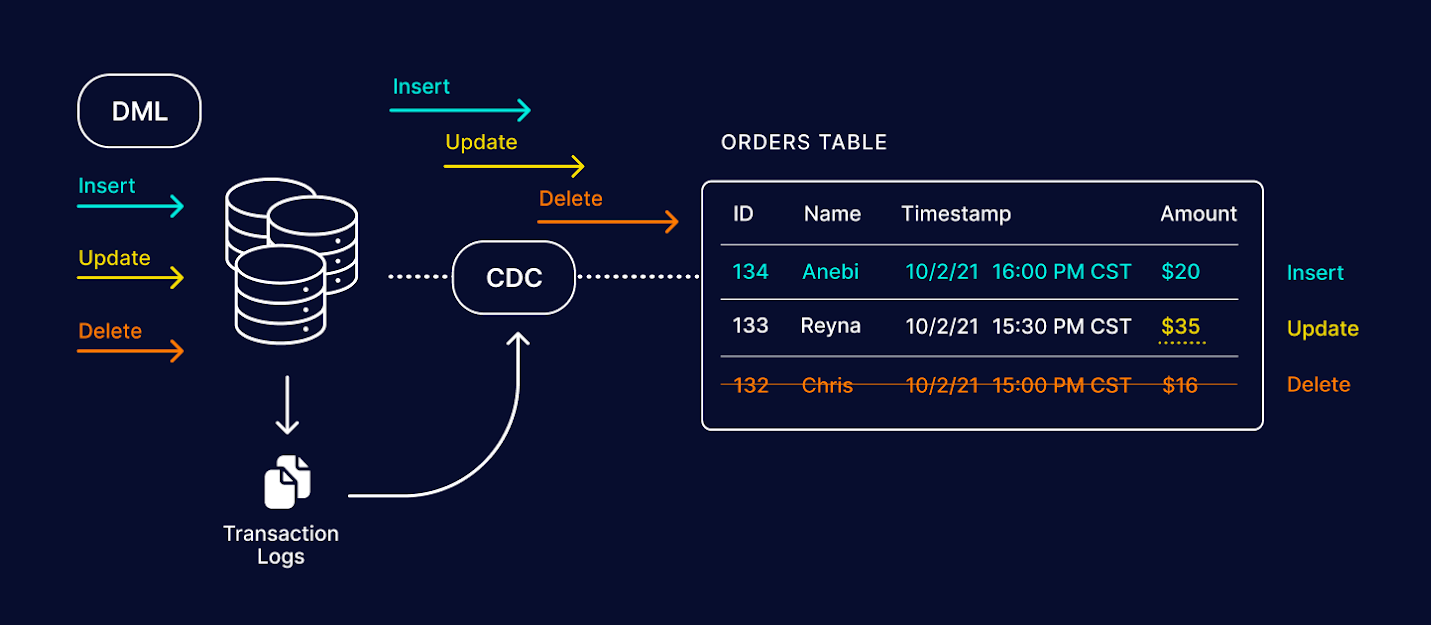
CDC 是一种实时数据变更捕获技术,它监听数据库的日志(如 MySQL 的 binlog、PostgreSQL 的 WAL),提取变更事件(INSERT/UPDATE/DELETE),并将其传输到下游系统(如 Kafka、数据仓库、搜索引擎等)。
CDC 的典型应用场景
- 实时数据分析:将数据库变更同步到数据湖或数据仓库(如 Snowflake、BigQuery)
- 事件驱动架构:数据库变更触发下游微服务处理(如订单状态更新触发通知)
- 缓存更新:数据库变更自动更新 Redis 或 Elasticsearch
- 数据备份与同步:跨数据中心或云环境的数据同步
2. Kafka Connect 与 CDC
Kafka Connect 是什么?
Kafka Connect 是 Apache Kafka 的数据集成框架 ,提供Source Connector (从外部系统读取数据)和Sink Connector(将数据写入外部系统)的能力。
Kafka Connect 在 CDC 中的角色
- Source Connector(如 Debezium)从数据库捕获变更并写入 Kafka
- Sink Connector 将 Kafka 中的数据写入目标系统(如 Elasticsearch、Snowflake)
Kafka Connect 的优势:
✅ 分布式 & 可扩展 :支持多 Worker 并行处理
✅ 插件化架构 :支持数百种 Connector(如 MySQL、PostgreSQL、MongoDB)
✅ 容错 & 恢复:自动记录偏移量(offset),故障后可恢复
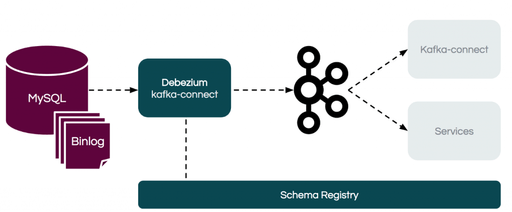
3. Debezium:开源 CDC 工具
Debezium 是什么?
Debezium 是一个开源的 CDC 平台,基于 Kafka Connect 构建,支持多种数据库(MySQL、PostgreSQL、MongoDB、SQL Server 等)。
Debezium 的工作原理
- 监听数据库日志(如 MySQL 的 binlog)
- 解析变更事件(INSERT/UPDATE/DELETE)
- 转换为 Kafka 消息(JSON 或 Avro 格式)
- 写入 Kafka Topic(每个表对应一个 Topic)
4. 完整示例:MySQL CDC + Kafka Connect
环境准备
- MySQL(启用 binlog)
- Kafka(单节点或集群)
- Zookeeper(Kafka 依赖)
- Kafka Connect(支持 Debezium Connector)
步骤 1:配置 MySQL 启用 binlog
在 MySQL 配置文件(my.cnf)中启用 binlog:
[mysqld]
server-id=1
log-bin=mysql-bin
binlog-format=ROW
binlog-row-image=FULL重启 MySQL 使配置生效。
步骤 2:启动 Kafka & Zookeeper
# 启动 Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# 启动 Kafka
bin/kafka-server-start.sh config/server.properties步骤 3:启动 Kafka Connect
bin/connect-distributed.sh config/connect-distributed.properties步骤 4:部署 Debezium MySQL Connector
向 Kafka Connect 提交 Connector 配置(JSON 格式):
{
"name": "mysql-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "debezium",
"database.password": "password",
"database.server.id": "184054",
"database.server.name": "mysql-server",
"database.include.list": "inventory",
"table.include.list": "inventory.products",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "schema-changes.inventory"
}
}通过 Kafka Connect REST API 提交:
curl -X POST -H "Content-Type: application/json" \
--data @mysql-connector.json http://localhost:8083/connectors步骤 5:验证 CDC 数据
-
在 MySQL 中插入数据:
INSERT INTO inventory.products (name, description) VALUES ('Laptop', 'High-performance laptop'); -
在 Kafka 中消费变更事件:
bin/kafka-console-consumer.sh \ --bootstrap-server localhost:9092 \ --topic mysql-server.inventory.products \ --from-beginning输出示例:
{ "before": null, "after": { "id": 1001, "name": "Laptop", "description": "High-performance laptop" }, "source": { "version": "1.9.6.Final", "connector": "mysql", "name": "mysql-server", "ts_ms": 1630000000000, "table": "products", "db": "inventory", "server_id": 1, "gtid": null, "file": "mysql-bin.000003", "pos": 456, "row": 0, "thread": 1, "query": null }, "op": "c", "ts_ms": 1630000000123 }op: "c"表示 INSERT 操作after包含变更后的数据
5. 最佳实践与常见问题
最佳实践
✔ 启用 binlog :确保数据库配置正确(MySQL 需 binlog-format=ROW)
✔ 合理分区 :Kafka Topic 分区策略影响并行消费能力
✔ 监控延迟 :使用 Kafka Lag 监控工具(如 Burrow、Confluent Control Center)
✔ 数据转换 :使用 Kafka Connect 的 Single Message Transform (SMT) 过滤或修改数据
常见问题
❌ 问题:Kafka Connect 无法连接 MySQL
✅ 解决 :检查 MySQL 用户权限(需 REPLICATION SLAVE 权限)
❌ 问题:CDC 数据丢失
✅ 解决 :确保 Kafka 和 Connect 的 offsets 正确持久化
❌ 问题:性能瓶颈
✅ 解决:增加 Kafka Partition 数量,优化 Connector 并行度
总结
Change Data Capture (CDC) 结合 Kafka Connect 是构建实时数据管道 的强大方案。通过 Debezium 捕获数据库变更,并利用 Kafka 的高吞吐能力,我们可以实现:
✅ 实时数据同步 (数据库 → 数据仓库/搜索引擎)
✅ 事件驱动架构 (数据库变更触发下游处理)
✅ 可靠的数据备份(跨数据中心同步)
无论是构建实时数据分析平台 ,还是实现微服务间的事件驱动通信,CDC + Kafka Connect 都是值得考虑的解决方案。