目录
[一. 范式](#一. 范式)
[二. 第一范式(1NF)](#二. 第一范式(1NF))
[三. 第二范式(2NF)](#三. 第二范式(2NF))
[四. 第三范式(3NF)](#四. 第三范式(3NF))
[4.2 示例1](#4.2 示例1)
一. 范式
数据库范式(Normal Form)是一系列用于指导关系数据库设计 的规范准则。这些准则旨在通过结构化数据、消除冗余和依赖异常,来设计出更加合理、高效和易于维护的关系数据模型。
目前,关系数据库理论主要定义了六种范式,层级依次递增:
-
第一范式 (1NF):确保每列具有原子性,数据项不可再分。
-
第二范式 (2NF):在满足1NF的基础上,消除非主属性对候选键的部分函数依赖。
-
第三范式 (3NF):在满足2NF的基础上,消除非主属性对候选键的传递函数依赖。
-
巴斯-科德范式 (BCNF / 3.5NF):在满足3NF的基础上,消除主属性对候选键的部分函数依赖和传递函数依赖。
-
第四范式 (4NF):在满足BCNF的基础上,消除非平凡的多值依赖。
-
第五范式 (5NF / 完美范式 - PJNF):在满足4NF的基础上,消除连接依赖。
范式层级与应用实践:
-
冗余控制: 通常而言,范式级别越高,数据冗余就越小(相同含义的字段出现在多个表中,数据的一致性和完整性约束也越强。
-
性能考量: 然而,追求过高的范式级别(如BCNF、4NF、5NF)会导致数据表被拆分成更细粒度的结构。这虽然减少了冗余,但在执行涉及多个表的查询操作(尤其是多表连接
JOIN)时,可能导致输入/输出(I/O)操作更加频繁,增加系统开销,从而影响查询性能。 -
平衡点:第三范式 (3NF): 鉴于上述性能因素与设计复杂性的权衡,在实际的数据库设计实践中,普遍认为满足第三范式(3NF)是一个较为理想的平衡点。3NF 已经有效地消除了大部分常见的冗余和更新异常(插入异常、删除异常、修改异常),同时保持了相对合理的查询性能。在需要更高查询性能的特定场景(如数据仓库、报表系统),甚至会进行有目的的反范式化(Denormalization)设计,即适当引入冗余以减少表连接操作。
什么是数据冗余?
数据冗余(Data Redundancy)是指在数据库或数据存储系统中,相同的信息(或语义上等价的信息)被重复存储多次的现象。
核心特征与理解
-
"相同"或"等价"的信息: 冗余指的是实质上代表同一事实的数据在多处出现。
-
例1: 在一个"员工"表中存储了员工姓名,又在另一个"部门"表中再次存储了该员工的姓名(而不是只存储员工ID来关联)。
-
例2: 在一个"订单"表中,每条订单记录都重复存储了客户的完整地址(而不是只存储客户ID,地址信息单独存放在"客户"表中)。
-
-
"不必要"的重复: 关键点在于这种重复是可以通过良好的设计避免的 ,或者其带来的问题大于收益。有些冗余是设计上故意引入 的(称为反范式化),用于优化特定查询性能,这通常是有目的的、可控的冗余。
在本文中,我们只会讲解1NF,2NF,3NF这3种范式
二. 第一范式**(1NF)**
2.1.定义
定义
第一范式(1NF)是关系数据库设计中最基本、必须满足的范式要求。
其核心原则是确保关系(表)中的每一列(属性)所包含的数据都是****原子的(Atomic),即:
-
不可再分: 每个数据项必须是数据库操作(如存储、检索、比较、更新)的最小逻辑单元,不能再被合理地分解为更小的、有独立意义的数据项。
-
单一值: 每个列在表的每一行(元组)中只能包含一个 该列定义类型的值。禁止在单个列中存储:
-
集合 (例如,用逗号分隔的多个电话号码存储在一个
phone_numbers列里)。 -
数组 (例如,一个包含多个颜色的数组存储在
colors列里)。 -
重复组 (例如,在一个订单行记录中,包含多个
product_id_1,product_id_2,product_name_1,product_name_2这样的重复字段结构)。 -
嵌套记录/对象 (例如,在一个
address列里存储一个包含街道、城市、邮编的复杂对象)。
-
本质要求: 表中的每个"单元格"位置(行与列的交点)有且仅有一个不可分割的、有意义的数据值。
重要性:
-
关系模型的基石: 1NF是关系数据库理论的基础要求。严格意义上,任何不满足第一范式的数据表,都不能被称为真正的关系型表。 它是构建更高范式(2NF, 3NF等)的前提条件。
-
保障数据操作可行性: 原子性是数据库管理系统(DBMS)能够有效执行查询(如WHERE条件过滤、JOIN连接)、更新、插入和删除操作的基础。非原子数据会使这些操作变得复杂、低效甚至无法进行。
-
消除基本结构冗余: 虽然主要解决结构问题而非依赖冗余,但1NF通过禁止重复组,初步避免了在单行内存储多个同类值造成的局部冗余。
-
简化设计与理解: 原子数据模型更直观,更容易被设计者、开发者和用户理解。
关键点与补充说明:
-
"合理分解"的边界: "原子性"并非绝对的物理不可分(比如一个字符串由多个字符组成),而是指在特定业务上下文中,该数据项作为整体具有独立意义,且在该数据库模型中无需或不应被进一步拆分。例如:
-
一个
full_name列存储"张三"通常被认为是原子的(尽管包含姓和名),除非业务明确要求单独处理姓氏和名字。 -
一个
address列存储"北京市海淀区中关村大街1号"可能被认为是原子的(如果地址作为一个整体使用),但也可能根据业务需求拆分为province、city、street、door_number等更原子的列。
-
-
主键要求: 满足1NF的表必须有一个主键(或候选键)来唯一标识每一行。主键本身也必须满足原子性(不能是复合列吗?复合主键是允许的,但复合主键中的每一列本身也必须是原子的)。
-
列值类型: 每个列的值必须属于同一数据类型(域)。
-
列顺序无关性: 列的物理存储顺序不影响其逻辑含义(关系模型的基本性质之一)。
-
与性能的权衡: 虽然拆分非原子数据是必须的,但过度拆分(如将地址拆分成省、市、区、街道、门牌号、楼号、单元号、房间号等7-8个字段)也可能增加查询复杂度。设计时需在原子性和实际查询需求间找到平衡点。
违反1NF的示例:
| 订单ID (PK) | 客户ID | 产品列表 (违反1NF) |
|---|---|---|
| 1001 | C001 | P100(手机), P200(耳机) |
| 1002 | C002 | P300(笔记本), P150(充电器) |
- 问题:
产品列表列包含了多个产品信息(产品ID和名称),是集合/重复组,不是原子值。无法直接查询某个特定产品出现在哪些订单中,也无法有效地对产品进行统计或连接操作。
满足1NF的改进设计:
| 订单ID (PK) | 产品项ID (PK) | 客户ID | 产品ID | 产品名称 |
|---|---|---|---|---|
| 1001 | 1 | C001 | P100 | 手机 |
| 1001 | 2 | C001 | P200 | 耳机 |
| 1002 | 1 | C002 | P300 | 笔记本 |
| 1002 | 2 | C002 | P150 | 充电器 |
- 解决: 将非原子的
产品列表拆分到多行(引入产品项ID作为主键的一部分)。现在每个"单元格"都是原子值(单一的产品ID、单一的产品名称),满足了1NF,并为进一步规范化(如将产品名称拆分到单独的产品表)奠定了基础。
2.2.示例
示例
1NF的核心就是------>确保关系(表)中的每一列(属性)所包含的数据都是****原子的(Atomic)
我们必须得知道:在关系型数据库中,每⼀列都使⽤基本数据类型(如整数、字符串、日期、布尔值等)定义,就天然满⾜第⼀范式.
关系型数据库中的基本数据类型(INT, VARCHAR, DATE, BOOLEAN等)定义了一个列所能存储数据的最基础、最原子的形态 。当你为表的每一列都选择了这样的基本数据类型,就意味着数据库引擎在存储和操作该列数据时,会将其视为一个不可分割的整体单元 。这种"整体单元"的特性,正是第一范式(1NF)所要求的原子性的体现。
因此,使用基本数据类型定义列,是设计上天然满足1NF的最直接方式。
例1:员工信息表
❌ 违反1NF的设计 (常见错误):
| 员工ID | 姓名 | 联系方式 | 部门 |
|---|---|---|---|
| 001 | 张三 | 手机:13800138000, 邮箱:zhang@abc.com | 销售部 |
| 002 | 李四 | 手机:13900139000, 座机:010-123456 | 技术部 |
问题在哪?
-
问题出在
联系方式列。如果该列被定义为某种可以容纳复杂结构或非原子值的类型(例如,某些数据库支持的自定义对象类型、数组类型,或者简单地用一个超长的VARCHAR来塞多种信息),它就没有强制使用基本数据类型来表示原子信息。 -
数据库把"手机:13800138000, 邮箱:zhang@abc.com"这一串文本当作一个完整的字符串值(VARCHAR)来存储和处理 。虽然VARCHAR是基本类型,但这里存储的内容语义 包含了多个独立的业务信息项(手机号、邮箱)。数据库本身无法自动识别和拆分这个字符串内部的多个信息点。
-
这个违反了1NF的核心概念------>关系(表)中的每一列(属性)所包含的数据都是****原子的(Atomic)
-
关键: 虽然列本身 用了基本类型(VARCHAR),但该列所承载的业务信息不是原子的 。设计者错误地用一个基本类型的列去存储了本应拆分成多个原子列(每个列用基本类型表示单一信息)的数据。这违反了1NF的意图。
✅ 满足1NF的设计:
| 员工ID (PK) | 姓名 | 手机号 | 电子邮箱 | 座机号 | 部门 |
|---|---|---|---|---|---|
| 001 | 张三 | 13800138000 | zhang@abc.com | NULL | 销售部 |
| 002 | 李四 | 13900139000 | NULL | 010-123456 | 技术部 |
为什么满足?
-
手机号列:定义为VARCHAR(15),只存储一个电话号码字符串。数据库将其视为一个原子单元。 -
电子邮箱列:定义为VARCHAR(100),只存储一个邮箱地址字符串。数据库将其视为一个原子单元。 -
座机号列:定义为VARCHAR(20),只存储一个座机号码字符串。数据库将其视为一个原子单元。 -
姓名、部门列同理。 -
这个满足了1NF的核心概念------>关系(表)中的每一列(属性)所包含的数据都是****原子的(Atomic)
-
每一列都严格使用基本数据类型(这里主要是VARCHAR)来表示一个且仅一个业务上的原子信息项。 数据库对每一列的操作(存储、读取、比较、更新)都作用在这个不可再分的原子值上,因此天然满足1NF。
例2:订单记录表
❌ 违反1NF的设计:
| 订单号 | 客户名 | 商品列表 (数量) | 总金额 |
|---|---|---|---|
| ORD100 | 王五 | T恤(2), 牛仔裤(1), 帽子(1) | ¥550 |
| ORD101 | 赵六 | 笔记本电脑(1), 鼠标(1), 背包(1) | ¥6500 |
问题在哪?
-
问题出在
商品列表 (数量)列。假设它被定义为一个VARCHAR(255)类型。 -
数据库将"T恤(2), 牛仔裤(1), 帽子(1)"整体视为一个字符串值进行存储。它不知道"T恤"、"牛仔裤"、"帽子"是独立的商品,也不知道"(2)"、"(1)"是数量。它看到的只是一个长文本块。
-
设计者错误地用一个基本类型(VARCHAR)的列去存储了多个商品及其数量的组合信息(非原子业务信息) 。数据库缺乏内在机制去解析和处理这个组合信息内部的各个独立部分。这个违反了1NF的核心概念------>关系(表)中的每一列(属性)所包含的数据都是****原子的(Atomic)
✅ 满足1NF的设计:
| 订单号 | 商品项ID (PK) | 客户名 | 商品名称 | 数量 | 单价 | 总金额* |
|---|---|---|---|---|---|---|
| ORD100 | 1 | 王五 | T恤 | 2 | ¥100 | |
| ORD100 | 2 | 王五 | 牛仔裤 | 1 | ¥300 | |
| ORD100 | 3 | 王五 | 帽子 | 1 | ¥50 | |
| ORD101 | 1 | 赵六 | 笔记本电脑 | 1 | ¥6000 | |
| ORD101 | 2 | 赵六 | 鼠标 | 1 | ¥100 | |
| ORD101 | 3 | 赵六 | 背包 | 1 | ¥400 |
为什么满足?
-
将订单项拆分为独立的行后:
-
商品名称列:定义为VARCHAR(50),存储一个商品的名称(原子信息)。 -
数量列:定义为INT,存储一个整数(原子信息),代表该商品的数量。 -
单价列:定义为DECIMAL(10,2),存储一个小数(原子信息),代表该商品的单价。
-
-
拆分后的每一列都使用了恰当的基本数据类型(VARCHAR, INT, DECIMAL)来精确表示一个业务上的原子信息项(商品名、数量、价格)。
-
这个满足了1NF的核心概念------>关系(表)中的每一列(属性)所包含的数据都是****原子的(Atomic)
-
数据库可以独立地操作每一列上的原子值(例如,对
数量列求和,对单价列求平均值),这正是满足1NF的直接结果。
例3:学生选课表
❌ 违反1NF的设计:
| 学号 | 姓名 | 所选课程 |
|---|---|---|
| S1001 | 小明 | 数学, 英语, 物理 |
| S1002 | 小红 | 英语, 化学, 历史, 音乐 |
问题在哪?
-
问题出在
所选课程列。假设它被定义为VARCHAR(100)。 -
数据库将"数学, 英语, 物理"整体视为一个字符串值。它不知道逗号分隔的是不同的课程名称。对这个列进行查询(如找选了"英语"的学生),数据库只能做低效的全字符串匹配或复杂的字符串解析,因为它操作的对象是整个字符串,而非独立的课程项。
-
设计者错误地用一个基本类型(VARCHAR)的列存储了多个课程名称的集合(非原子业务信息) 。数据库无法将其视为多个独立的原子值进行处理。
-
这个违反了1NF的核心概念------>关系(表)中的每一列(属性)所包含的数据都是****原子的(Atomic)
✅ 满足1NF的设计:
| 学号 | 课程ID (PK) | 姓名 | 课程名称 |
|---|---|---|---|
| S1001 | MATH101 | 小明 | 数学 |
| S1001 | ENG201 | 小明 | 英语 |
| S1001 | PHYS301 | 小明 | 物理 |
| S1002 | ENG201 | 小红 | 英语 |
| S1002 | CHEM202 | 小红 | 化学 |
| S1002 | HIST102 | 小红 | 历史 |
| S1002 | MUSIC401 | 小红 | 音乐 |
为什么满足?
-
将选课关系拆分为独立的行后:
课程名称列:定义为VARCHAR(50),存储一个课程的名称(原子信息)。
-
拆分后的
课程名称列,严格使用基本数据类型(VARCHAR)来表示一个且仅一个原子信息项(一门课程的名字)。 数据库可以精确地基于这个单一、原子的课程名称进行查询、统计等操作(例如,WHERE课程名称= '英语'),这正是1NF保证的特性。 -
这个满足了1NF的核心概念------>关系(表)中的每一列(属性)所包含的数据都是****原子的(Atomic)
反正,大家记住,在关系型数据库中,每⼀列都使⽤基本数据类型(如整数、字符串、日期、布尔值等)定义,就天然满⾜第⼀范式。
三. 第二范式(2NF)
3.1.定义
定义
第二范式 (2NF) 是关系数据库规范化过程的第二个层级。
一个关系(表)满足第二范式,当且仅当它同时满足以下两个条件:
-
满足第一范式 (1NF): 该表的所有属性(列)都已经是原子的(不可再分)。
-
消除部分函数依赖: 不存在任何非主属性(非关键字段)对表的任何候选键存在部分函数依赖。
关键概念解释:
-
候选键 (Candidate Key):
-
核心定义: 表中一个或多个属性(列)组成的最小集合 ,该集合的值能够唯一标识 表中的每一行数据(元组)。
-
关键特性:
-
唯一性 (Uniqueness): 不同的行,其候选键的值必定不同。这是候选键存在的根本前提。
-
最小性 (Minimality / Irreducibility): 构成候选键的属性集合是最小的 。这意味着移除该集合中的任何一个属性 ,剩下的属性组合将不再具有唯一性,无法再唯一标识每一行。最小性是区分候选键和超键的关键。
-
非空性 (Not Null): 构成候选键的属性不允许包含空值 (NULL)。空值无法用于唯一标识。
-
多候选键: 一张表可以存在多个满足唯一性和最小性要求的候选键。
-
-
-
复合候选键 (Composite Candidate Key):
-
核心定义: 由两个或两个以上属性共同构成的候选键。
-
关键特性: 必须满足候选键的所有特性(唯一性、最小性、非空性)。其唯一性和最小性依赖于所有组成属性的组合值。
-
-
主键 (Primary Key):
-
核心定义: 数据库设计者从表的候选键集合中选定一个 ,作为该表官方且唯一的行标识符。
-
关键特性:
-
具备候选键的所有特性(唯一性、最小性、非空性)。
-
唯一性: 一张表有且仅有一个主键。
-
稳定性: 主键值一旦确定,通常不应改变。
-
实现机制: 数据库管理系统 (DBMS) 通常依赖主键来构建索引、强制唯一性约束、建立表间关系(外键)。
-
-
-
复合主键 (Composite Primary Key):
-
核心定义: 被选定为主键的候选键恰好是一个复合候选键。
-
关键特性: 同时具备主键和复合候选键的所有特性。
-
-
主属性 (Prime Attribute / Key Attribute):
-
核心定义: 至少包含在表的一个候选键中的属性。
-
关键特性:
-
主属性是构成候选键(包括主键)的基本元素。
-
一个属性可以是多个候选键的组成部分。
-
主属性不一定 是主键的一部分(如果表有多个候选键),但主键中的所有属性必然是主属性。
-
-
-
非主属性 (Non-Prime Attribute / Non-Key Attribute):
-
核心定义: 不包含在表的任何一个候选键中的属性。
-
关键特性:
-
非主属性不能单独或组合用于唯一标识表中的行(否则它就应该是候选键的一部分)。
-
第二范式 (2NF) 和第三范式 (3NF) 的核心约束对象就是非主属性。
-
-
-
函数依赖 (Functional Dependency - FD) X → Y:
-
核心定义: 表中属性集
X的值唯一决定 属性集Y的值。对于表中任意两行r1和r2,如果r1[X] = r2[X](即两行在X上的值相等),则必有r1[Y] = r2[Y](即两行在Y上的值也必须相等)。 -
关键特性:
-
语义性: FD 反映的是数据本身的语义关系,由现实世界的业务规则决定。数据库设计者需要根据业务逻辑识别 FD。
-
传递性: 如果
X → Y且Y → Z,则X → Z。 -
决定因素 (Determinant):
X称为决定因素。 -
被决定因素 (Dependent):
Y称为被决定因素。 -
平凡依赖 (Trivial FD): 如果
Y ⊆ X(即Y是X的子集),则X → Y总是成立,称为平凡函数依赖。范式理论通常关注非平凡函数依赖 (Y ⊈ X)。 -
完全/部分依赖的基础: 函数依赖是定义完全依赖和部分依赖的基础。
-
-
-
完全函数依赖 (Full Functional Dependency) (A, B) → C:
-
核心定义: 给定一个复合属性集
(A, B)和一个非主属性C,满足:-
函数依赖成立:
(A, B) → C(即(A, B)的值唯一决定C的值)。 -
最小依赖: 不存在
(A, B)的任何真子集S(S可以是A或B或空集) 能单独决定C。即A → C不成立 且B → C不成立。
-
-
关键特性:
-
C必须且只能 由(A, B)整体 来决定。(A, B)中的每个属性 对于确定C的值都是不可或缺的。 -
移除
(A, B)中的任何属性,剩下的属性将无法再唯一确定C。 -
满足 2NF 要求非主属性必须完全函数依赖于任何候选键(特别是复合候选键)。
-
-
-
部分函数依赖 (Partial Functional Dependency) (A, B) → C 且 A → C:
-
核心定义: 给定一个复合属性集
(A, B)和一个非主属性C,满足:-
函数依赖成立:
(A, B) → C(即(A, B)的值唯一决定C的值)。 -
子集依赖存在: 存在
(A, B)的一个真子集S(S可以是A或B),使得S → C成立 。即A → C成立 或B → C成立 或两者都成立。
-
-
关键特性:
-
虽然
(A, B)整体可以决定C,但C实际上只需要(A, B)的一部分 (S) 就能被唯一确定。 -
复合属性集
(A, B)中存在冗余的决定因素 。B(或A) 对于决定C是多余 的 (如果A → C成立,那么B是多余的;反之亦然)。 -
违反 2NF 的本质: 第二范式禁止非主属性对任何候选键存在部分函数依赖。部分依赖的存在意味着数据模型不够精简,存在潜在的数据冗余和操作异常。
-
-
核心要求:
-
第二范式特别关注存在复合主键(或复合候选键) 的表。
-
它要求表中的每一个非主属性,都必须完全函数依赖于整个候选键(即依赖于构成候选键的所有属性),而不能只依赖于候选键的一部分属性。
-
简而言之:非主属性必须完全依赖于整个"钥匙"(候选键),不能只依赖于"钥匙"的某一部分。
为什么强调"存在于表中定义了复合主键的情况下"?
-
如果表的主键是单属性 (只有一个列),那么该主键本身就是一个最小集合,所有非主属性必然是完全函数依赖于这个单属性主键的。因此,满足1NF的单主键表天然满足2NF。
-
只有存在复合主键(或复合候选键)时,才可能出现非主属性只依赖于主键的一部分属性的情况(部分依赖),这是2NF需要解决的问题。
违反2NF的后果:
-
数据冗余: 部分依赖会导致相同的信息在表中重复出现多次。
-
更新异常 (Update Anomalies): 更新某个依赖于部分键的信息时,需要修改所有相关行,容易遗漏导致数据不一致。
-
插入异常 (Insertion Anomalies): 无法插入仅知道部分键信息的数据。
-
删除异常 (Deletion Anomalies): 删除一行数据可能意外删除仅依赖于部分键的唯一信息。
如何满足2NF?
-
确保表已满足1NF。
-
识别出所有候选键(特别是复合候选键)。
-
检查每一个非主属性 与每一个候选键的函数依赖关系。
-
如果发现某个非主属性只函数依赖于某个复合候选键的一部分属性(即存在部分依赖),则该表不满足2NF。
-
解决方法: 将存在部分依赖的属性拆分出去,与导致部分依赖的那个键子集组成新的表。原表保留复合键和完全依赖于整个复合键的属性。
3.2.示例1
考虑一个 订单明细 表,记录订单中的商品项:
❌ 违反2NF的设计 (复合主键:订单ID, 产品ID):
| 订单ID (PK) | 产品ID (PK) | 产品名称 | 产品类别 | 单价 | 数量 | 客户ID | 客户姓名 |
|---|---|---|---|---|---|---|---|
| ORD001 | P100 | T恤 | 服装 | 100 | 2 | C001 | 张三 |
| ORD001 | P200 | 鼠标 | 外设 | 50 | 1 | C001 | 张三 |
| ORD002 | P100 | T恤 | 服装 | 100 | 1 | C002 | 李四 |
- 候选键:
(订单ID, 产品ID) - 非主属性:
产品名称,产品类别,单价,数量,客户ID,客户姓名
我们来看这个表有没有存在任何非主属性(非关键字段)对表的任何候选键存在部分函数依赖的情况啊
非主属性 产品名称:
-
它函数依赖于复合主键
(订单ID, 产品ID)吗?
是的 ((订单ID, 产品ID) → 产品名称成立)。
(例如:(ORD001, P100)确定对应 "T恤") -
但它也函数依赖于复合主键的一部分 产品ID 吗?
是的! (产品ID → 产品名称成立)。
例如:产品IDP100对应的产品名称永远是 "T恤",不管它在哪个订单中出现(ORD001 或 ORD002)。结论:
产品名称部分函数依赖 于复合主键(订单ID, 产品ID)。不符合2NF要求。
非主属性 产品类别:
-
它函数依赖于复合主键
(订单ID, 产品ID)吗?
是的 ((订单ID, 产品ID) → 产品类别成立)。
(例如:(ORD001, P100)确定对应 "服装") -
但它也函数依赖于复合主键的一部分 产品ID 吗?
是的! (产品ID → 产品类别成立)。
例如:产品IDP100对应的产品类别永远是 "服装",无论订单是 ORD001 还是 ORD002。结论:
产品类别部分函数依赖 于复合主键(订单ID, 产品ID)。不符合2NF要求。
非主属性 单价:
-
它函数依赖于复合主键
(订单ID, 产品ID)吗?
是的 ((订单ID, 产品ID) → 单价成立)。
(例如:(ORD001, P100)确定单价为 100) -
但它也函数依赖于复合主键的一部分 产品ID 吗?
是的! (产品ID → 单价成立)。
例如:产品IDP100对应的单价永远是 100,与订单ID(ORD001 或 ORD002)无关。结论:
单价部分函数依赖 于复合主键(订单ID, 产品ID)。不符合2NF要求。
非主属性 客户ID:
-
它函数依赖于复合主键
(订单ID, 产品ID)吗?
是的 ((订单ID, 产品ID) → 客户ID成立)。
(例如:(ORD001, P100)确定客户ID为 C001) -
但它也函数依赖于复合主键的一部分 订单ID 吗?
是的! (订单ID → 客户ID成立)。
例如:订单IDORD001对应的客户ID永远是 C001,不管订单中包含什么产品(P100 或 P200)。结论:
客户ID部分函数依赖 于复合主键(订单ID, 产品ID)。不符合2NF要求。
非主属性 客户姓名:
-
它函数依赖于复合主键
(订单ID, 产品ID)吗?
是的 ((订单ID, 产品ID) → 客户姓名成立)。
(例如:(ORD001, P100)确定客户姓名为 "张三") -
但它也函数依赖于复合主键的一部分 订单ID 吗?
是的! (订单ID → 客户姓名成立)。
例如:订单IDORD001对应的客户姓名永远是 "张三",与订单中的产品无关。结论:
客户姓名部分函数依赖 于复合主键(订单ID, 产品ID)。不符合2NF要求。
非主属性 数量
-
它函数依赖于复合主键
(订单ID, 产品ID)吗?
是的 ((订单ID, 产品ID) → 数量成立)。
例如:(ORD001, P100)确定数量为 2 -
它函数依赖于复合主键的一部分 订单ID 吗?
不是! (订单ID → 数量不成立)。
例如:仅凭订单IDORD001无法确定数量(该订单有 P100:2 和 P200:1) -
它函数依赖于复合主键的一部分 产品ID 吗?
不是! (产品ID → 数量不成立)。
例如:仅凭产品IDP100无法确定数量(在 ORD001 中为2,在 ORD002 中为1)结论:
数量完全函数依赖 于复合主键(订单ID, 产品ID)。符合2NF要求。
我们发现这个表有存在任何非主属性(非关键字段)对表的任何候选键存在部分函数依赖的情况啊。所以这个表不符合2NF的设计。
✅ 满足2NF的设计 (拆分后):
表1:订单表 (订单) - 解决客户信息部分依赖
| 订单ID (PK) | 客户ID | 客户姓名 |
|---|---|---|
| ORD001 | C001 | 张三 |
| ORD002 | C002 | 李四 |
- 候选键:
订单ID。非主属性客户ID,客户姓名完全依赖于单属性主键订单ID,满足2NF。
表2:产品表 (产品) - 解决产品信息部分依赖
| 产品ID (PK) | 产品名称 | 产品类别 | 单价 |
|---|---|---|---|
| P100 | T恤 | 服装 | 100 |
| P200 | 鼠标 | 外设 | 50 |
- 候选键:
产品ID。非主属性产品名称,产品类别,单价完全依赖于单属性主键产品ID,满足2NF。
表3:订单明细表 (订单明细) - 保留完全依赖
| 订单ID (PK, FK) | 产品ID (PK, FK) | 数量 |
|---|---|---|
| ORD001 | P100 | 2 |
| ORD001 | P200 | 1 |
| ORD002 | P100 | 1 |
-
复合主键:
(订单ID, 产品ID)。非主属性数量完全依赖于整个复合主键(知道订单ID和产品ID才能确定购买数量)。满足2NF。 -
订单ID是外键 (FK),引用订单表(订单ID)。 -
产品ID是外键 (FK),引用产品表(产品ID)。
结论:
第二范式(2NF)的核心目标是消除非主属性对复合候选键的部分函数依赖。它建立在1NF的基础上,通过确保非主属性必须完全依赖于整个候选键,有效解决了因部分依赖导致的数据冗余和基本更新异常问题。满足2NF是数据库设计走向更高规范化程度(如3NF)的重要一步。
3.3.示例2
需求:学生可以选择课程,课程有对应的学分,学生考试后每门课程会产生相应的成绩
问题表格(违反第二范式)
| 学号 | 学生姓名 | 年龄 | 性别 | 课程名 | 学分 | 成绩 |
|---|---|---|---|---|---|---|
| 10001 | 张三 | 18 | 男 | MySQL | 60 | 98 |
| 10002 | 李四 | 19 | 女 | MySQL | 60 | 100 |
| 10003 | 王五 | 18 | 男 | MySQL | 50 | 89 |
| 10001 | 张三 | 18 | 男 | Java | 60 | 100 |
| 10002 | 李四 | 19 | 女 | Java | 60 | 99 |
| 10003 | 王五 | 18 | 男 | C++ | 60 | 98 |
核心问题分析(违反第二范式):
-
表结构与主键:
-
表名:学生课程成绩表
-
复合主键 (Candidate Key / Primary Key):
(学号, 课程名)。这是合理的,因为一个学生的一门课程成绩是唯一的。 -
非主属性:
学生姓名,年龄,性别,学分,成绩。
-
-
识别函数依赖 (FD):
-
学号 → 学生姓名(知道学号,就能唯一确定该学生的姓名) -
学号 → 年龄(知道学号,就能唯一确定该学生的年龄) -
学号 → 性别(知道学号,就能唯一确定该学生的性别) -
课程名 → 学分(知道课程名,就能唯一确定该课程的学分) -
(学号, 课程名) → 成绩(知道是哪个学生学了哪门课,才能唯一确定该学生这门课的成绩)
-
-
识别部分函数依赖 (Partial Functional Dependency):
-
非主属性
学生姓名:-
它函数依赖于复合主键
(学号, 课程名)吗?是的 ((学号, 课程名) → 学生姓名成立)。 -
但它也函数依赖于复合主键的一部分
学号吗? 是的! (学号 → 学生姓名成立)。例如,学号10001对应的学生姓名永远是张三,不管他学的是MySQL还是Java。 -
结论:
学生姓名部分函数依赖于复合主键(学号, 课程名)。不符合2NF要求。
-
-
非主属性
年龄:-
同理,
(学号, 课程名) → 年龄成立,但学号 → 年龄也成立(学号10001年龄永远是18)。 -
结论:
年龄部分函数依赖于复合主键(学号, 课程名)。不符合2NF要求。
-
-
非主属性
性别:-
同理,
(学号, 课程名) → 性别成立,但学号 → 性别也成立(学号10001性别永远是男)。 -
结论:
性别部分函数依赖于复合主键(学号, 课程名)。不符合2NF要求。
-
-
非主属性
学分:-
它函数依赖于复合主键
(学号, 课程名)吗?是的 ((学号, 课程名) → 学分成立)。 -
但它也函数依赖于复合主键的一部分
课程名吗? 是的! (课程名 → 学分成立)。例如,课程名MySQL对应的学分在表中是60(前两行)或50(第三行,此处数据存在不一致,但逻辑上同一课程学分应固定),但重要的是,学分只由课程决定,与学生无关 。学号10001学MySQL和学号10002学MySQL,MySQL的学分应该是相同的。 -
结论:
学分部分函数依赖于复合主键(学号, 课程名)。不符合2NF要求。
-
-
非主属性
成绩:-
(学号, 课程名) → 成绩成立。 -
它是否函数依赖于复合主键的一部分
学号? 不能! (学号 → 成绩不成立)。知道学号10001,无法确定他的成绩(他可能有MySQL:98,Java:100)。 -
它是否函数依赖于复合主键的一部分
课程名? 不能! (课程名 → 成绩不成立)。知道课程名MySQL,无法确定成绩(学生10001:98,10002:100,10003:89)。 -
结论:
成绩完全函数依赖 于复合主键(学号, 课程名)。✅ 符合2NF要求。
-
-
我们发现 存在很多非主属性(非关键字段)对表的任何候选键存在部分函数依赖,也就是说不符合2NF要求。
违反第二范式(2NF)的后果详解
核心问题根源:
由于存在部分函数依赖,导致非主属性(如学生姓名、学分)只需复合主键的一部分就能确定。这会引发四大严重问题:
- 数据冗余(Data Redundancy)
问题本质: 相同数据在表中重复存储多次。
具体表现:
-
学生信息重复 :
同一个学生的姓名、年龄、性别在其选修的每门课程中重复出现。
例:张三(10001)选了2门课(MySQL/Java),他的信息
(张三,18,男)重复存储2次。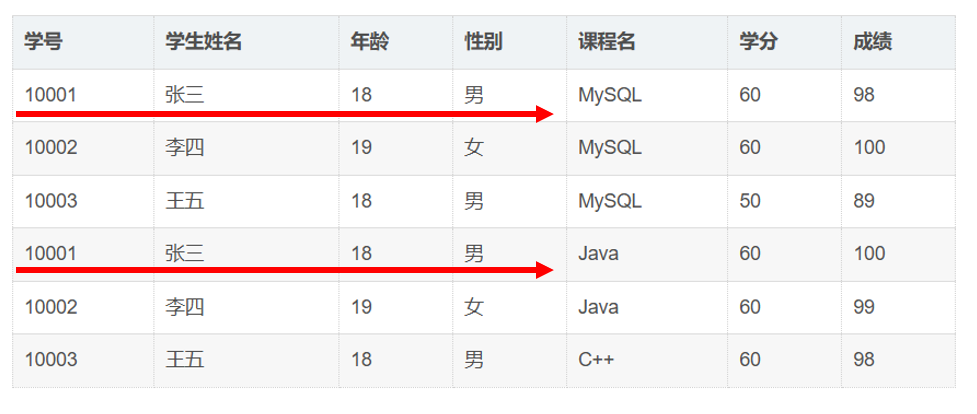
→ 存储空间浪费:学生选修N门课,其信息就重复N次。
-
课程信息重复 :
同一门课程的学分在选修该课程的每个学生记录中重复出现。
例:MySQL课程被3个学生选修,学分
60或50重复存储3次(第三行异常值为50)。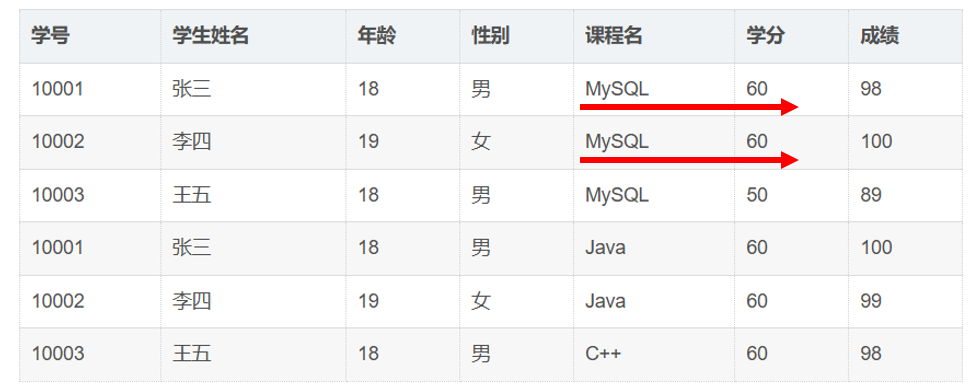
→ 存储空间浪费:课程被M个学生选修,其学分就重复M次。
后果:
-
数据库存储空间被大量无效重复数据占用
-
相同信息在多处存在,维护成本剧增
- 更新异常(Update Anomalies)
问题本质: 修改一个数据需要更新多处,否则会产生不一致。
典型案例:
-
修改学生信息 :
学生改名时,必须修改其所有课程记录中的姓名字段。
例:张三(10001)改名为"张四":
❌ 需手动修改2处(MySQL行和Java行)
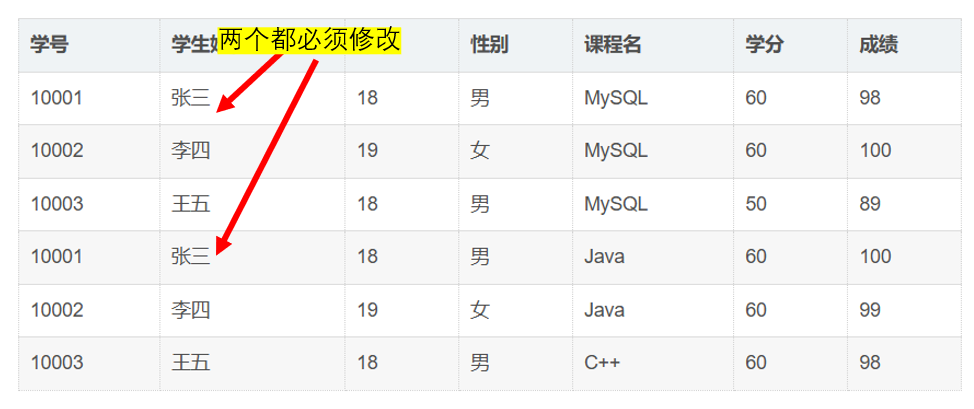
⚠️ 若漏改Java行 → 出现不一致:
MySQL行:张四vsJava行:张三 -
修改课程学分 :
课程学分变更时,需更新所有相关学生的记录。
例:Java学分从60改为65:
❌ 需修改所有选修Java的学生记录(10001和10002行)
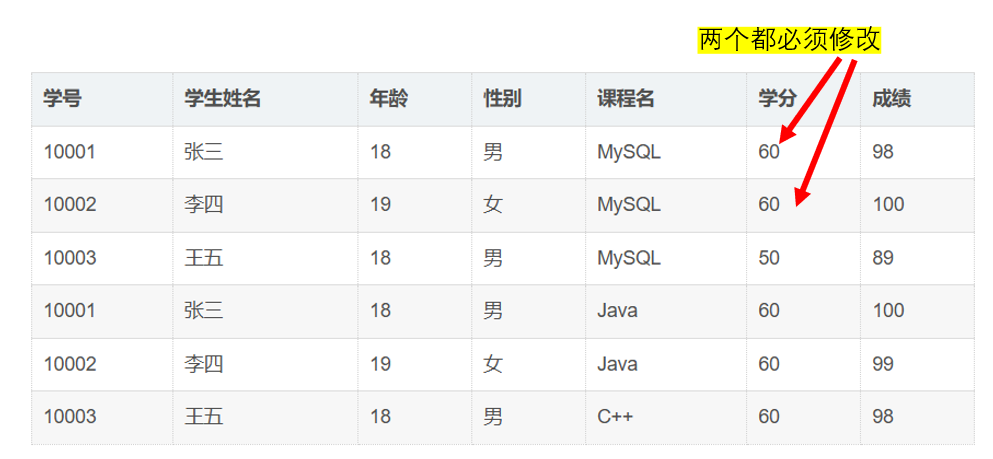
⚠️ 若漏改10002行 → 出现不一致:
10001行:65vs10002行:60
后果:
-
简单操作变复杂(需定位并修改多处)
-
极高的人为错误风险(易遗漏部分修改)
-
数据一致性被破坏
- 插入异常(Insertion Anomalies)
问题本质: 无法插入某些必要数据,除非同时插入无关数据。
典型案例:
-
无法添加新课程 :
新课程无学生选课时,因缺少主键中的"学号"而无法插入。
例:新增Python课程(学分55),但尚未有学生选修:
❌ 插入失败:
INSERT INTO 表 (课程名,学分) VALUES ('Python',55)我们新增不了这个Python课程,因为插入数据必须要带复合主键(这里违反主键约束,因为还差学号)
-
无法添加新学生 :
新生未选课时,因缺少主键中的"课程名"而无法插入。
例:新增学生赵六(10004,20,男),尚未选课:
❌ 插入失败:
INSERT INTO 表 (学号,姓名) VALUES (10004,'赵六')我们新增不了这个新学生,因为插入数据必须要带复合主键(这里违反主键约束,因为这里还差课程)
后果:
-
业务关键数据无法正常入库(如新课程/新生)
-
必须伪造无关数据才能插入(破坏数据真实性)
- 删除异常(Deletion Anomalies)
问题本质: 删除一条记录时意外删除其他关键信息。
典型案例:
-
删除学生最后课程 → 丢失学生信息 :
删除学生唯一课程记录时,其个人信息被连带删除。
例:王五(10003)退选C++(唯一课程):
❌ 删除
(10003,C++)行 → 王五的信息(王五,18,男)永久丢失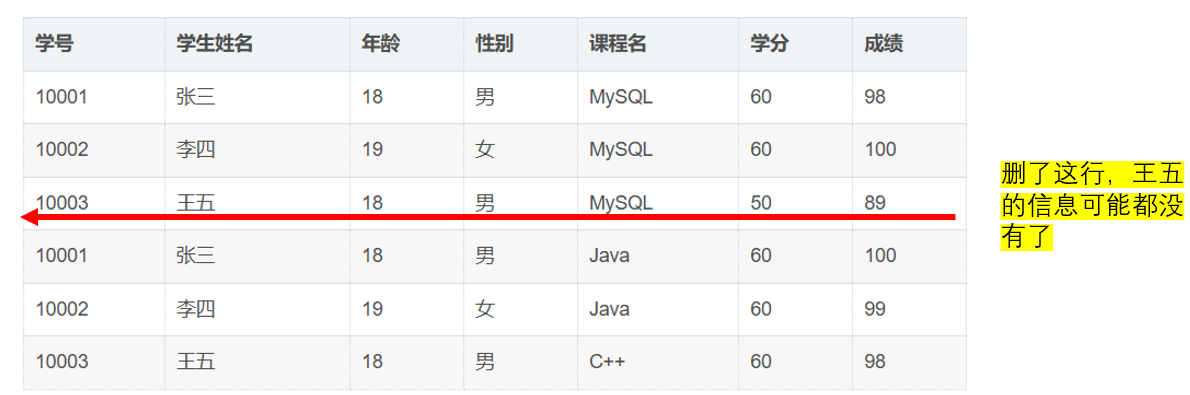
⚠️ 即使他仍是本校学生!
-
删除课程最后学生 → 丢失课程信息 :
删除课程最后一条选课记录时,课程信息被连带删除。
例:C++课程只剩王五选修:
❌ 删除
(10003,C++)行 → C++的学分60永久丢失⚠️ 即使该课程仍在开设!
后果:
-
关键业务数据意外丢失(学生档案/课程信息)
-
数据完整性被破坏
-
系统可能产生致命业务错误(如财务系统丢失课程学分)
解决方案(满足第二范式):
原则:将存在部分依赖的非主属性拆分出去,与决定它们的那个"键子集"组成新表。 原表只保留复合键和完全依赖于整个复合键的属性。
拆分学生信息: 创建 学生表
-
主键:
学号(单属性) -
属性:
学生姓名,年龄,性别 -
为什么满足2NF? 所有非主属性 (
学生姓名,年龄,性别) 完全函数依赖 于单属性主键学号(不存在部分依赖问题)。
学生表
| id | 学号 | 学生姓名 | 年龄 | 性别 |
|---|---|---|---|---|
| 1 | 10001 | 张三 | 18 | 男 |
| 2 | 10002 | 李四 | 19 | 女 |
| 3 | 10003 | 王五 | 18 | 男 |
拆分课程信息: 创建 课程表
-
主键:
课程名(单属性) 或id(代理键)。使用id更常见(避免主键过长或修改)。 -
属性:
学分(如果主键是课程名),或课程名+学分(如果主键是id)。 -
为什么满足2NF? 非主属性
学分完全函数依赖 于单属性主键 (课程名或id)。如果主键是id,则id → 课程名且id → 学分成立。
课程表
| Id | 课程名 | 学分 |
|---|---|---|
| 1 | MySQL | 50 |
| 2 | Java | 60 |
| 3 | C++ | 60 |
保留成绩核心信息: 创建 成绩表
-
复合主键:
(学生Id, 课程Id)或(学号, 课程Id)或(学生Id, 课程名)。最佳实践是使用关联表的ID(外键)。 -
属性:
成绩 -
外键:
学生Id引用学生表(id)(或学号),课程Id引用课程表(Id)。 -
为什么满足2NF? 唯一的非主属性
成绩完全函数依赖 于整个复合主键(学生Id, 课程Id)。它需要同时知道"哪个学生"学了"哪门课"才能确定"考了多少分"。学生Id或课程Id单独都无法决定成绩。
成绩表
| 学生Id | 课程Id | 成绩 |
|---|---|---|
| 1 | 1 | 98 |
| 2 | 1 | 100 |
| 3 | 1 | 89 |
| 1 | 2 | 100 |
| 2 | 2 | 99 |
| 3 | 3 | 98 |
从上面这些例子也能看出:第二范式强调的是部分函数依赖,当一张表中的主键只有一列时(也就是说没有复合主键的时候),天然满足第二范式
四. 第三范式(3NF)
4.1.定义
-
核心目标: 消除数据冗余(重复存储)和潜在的更新异常(确保数据修改操作的一致性与可靠性)。
-
前提条件: 关系必须首先满足第二范式(2NF)。这要求:
-
关系中存在主键或候选键。
-
所有非主属性(非关键字段)必须完全依赖于整个候选键(不存在部分函数依赖)。
-
-
核心要求: 在满足第二范式(2NF)的基础上,任何非主属性都不传递依赖于关系中的任一候选键。
-
解决的问题: 传递函数依赖。
什么是传递函数依赖?
想象你管理着一份巨大的员工信息表。
| 员工ID (主键) | 员工姓名 | 部门ID | 部门名称 | 部门地点 |
|---|---|---|---|---|
| 101 | 张伟 | D01 | 研发部 | 北京科技园3号楼 |
| 102 | 李娜 | D01 | 研发部 | 北京科技园3号楼 |
| 103 | 王芳 | D02 | 市场部 | 上海浦东中心 |
| 104 | 赵明 | D02 | 市场部 | 上海浦东中心 |
这份表已经满足了第二范式(2NF),这意味着每个员工的信息都围绕着员工ID(主键)组织好,没有"部分依赖"的问题了(比如不会出现同一个部门信息重复挂在不同员工ID下的零散情况)。
现在第三范式(3NF)要解决的核心问题是:避免"拐弯抹角"的依赖关系。
-
关键人物(候选键): 就是能唯一锁定一个员工的身份标识,比如员工ID。它是整张表的"锚点",所有信息都应该直接和它挂钩。
-
非关键信息(非关键字段): 就是除了员工ID以外的其他信息,比如员工姓名、所属部门、部门地址、部门电话等等。
-
传递依赖是什么? 想象一下,有些信息不是直接和员工ID(锚点)挂钩,而是通过其他非关键信息"拐了个弯"才挂上的。
-
直接依赖: 员工ID -> 员工姓名。 (知道员工ID,直接就知道他叫张三。)
-
直接依赖: 员工ID -> 所属部门ID。 (知道员工ID,直接就知道他在哪个部门,比如D001。)
-
潜在问题: 部门ID -> 部门地址。 (知道部门ID是D001,就能知道这个部门在"科技园3号楼"。)
-
传递依赖链: 员工ID -> 部门ID -> 部门地址。
-
这里的问题就出在"部门地址"上:
-
它不是直接由员工ID决定的(员工ID本身并不包含地址信息)。
-
它是先通过员工ID找到部门ID,再通过部门ID才找到部门地址。
-
换句话说,部门地址依赖 于部门ID,而部门ID依赖 于员工ID。部门地址是"拐了个弯"(通过部门ID)才依赖到员工ID这个锚点上的。这就是"传递函数依赖"------信息A(部门地址)通过信息B(部门ID)传递着依赖到了锚点(员工ID)。
为什么这个"拐弯抹角"不好?
因为部门ID在这里扮演了双重角色:
-
它是员工的一个属性(员工属于哪个部门)。
-
它又"偷偷地"成为了另一个信息(部门地址)的"代理锚点"。
这会导致什么麻烦?
-
信息重复: 同一个部门(比如D001)的所有员工记录里,都要重复存储一遍"科技园3号楼"这个地址。招100个员工,这个地址就存了100遍。
-
修改麻烦: 如果D001部门搬家了,地址变成"创新大厦5层",你就必须 找到所有属于D001部门的员工记录,一个一个去修改他们的"部门地址"字段。漏改一个,数据就不一致了。
-
插入麻烦: 如果公司新成立了一个部门D999,但暂时还没有员工,你就没法在员工表里记录这个新部门的地址信息,因为没有员工ID(锚点)可以挂。
-
删除风险: 如果某个部门只剩下最后一个员工,你把这个员工的记录删了,那么这个部门的信息(部门地址)也就跟着一起消失了,即使这个部门还存在。
第三范式(3NF)的要求就是:消灭这种"拐弯抹角"!
它要求:所有非关键信息(比如部门地址),都必须像员工姓名一样,直接挂在"锚点"(员工ID)上,一步到位,中间不能有任何"二道贩子"(比如部门ID)来转手依赖。
怎么做到?
很简单:把那些充当了"二道贩子"的信息(部门ID)以及它所"代理"的信息(部门地址、部门电话等)一起拆分出去 ,放到另一张专门记录部门信息的表里。在员工表里,只保留直接指向部门表的部门ID(作为"链接")。这样:
-
在员工表里,部门ID只代表"这个员工属于哪个部门",它本身就是一个直接依赖于员工ID的属性。
-
部门地址等信息,被挪到了部门表里,在那里它们直接依赖于部门ID(部门ID成为部门表的新锚点)。
-
员工表里不再有部门地址,彻底斩断了"员工ID -> 部门ID -> 部门地址"这个传递依赖链。
4.2 示例1
场景: 你有一张记录公司所有员工信息的表格。这张表已经满足了第二范式 (2NF),意味着每个员工的信息都围绕着唯一的"身份证"------员工ID(主键)来组织。每个员工占一行,像员工姓名这种信息,只要知道员工ID就能直接找到,没有混乱的部分依赖问题。
这张表长这样:
| 员工ID (主钥匙) | 员工姓名 | 部门ID | 部门名称 | 部门地点 |
|---|---|---|---|---|
| 101 | 张伟 | D01 | 研发部 | 北京 |
| 102 | 李娜 | D01 | 研发部 | 北京 |
| 103 | 王芳 | D02 | 市场部 | 上海 |
| 104 | 赵明 | D02 | 市场部 | 上海 |
问题在哪?满足第三范式 (3NF) 了吗?没有!
问题出在部门名称和部门地点这两个信息上。它们对主钥匙员工ID的依赖是"拐了弯"的,形成了"传递依赖"链:
-
第一步依赖 (直接且合理): 知道一个员工的员工ID (比如101),你就能直接查出他属于哪个部门ID (D01)。这没问题,员工属于哪个部门是他的直接属性。
-
第二步依赖 (问题根源): 知道部门ID (D01),你就能查出这个部门的部门名称 (研发部) 和 部门地点 (北京)。这里的关键是:部门名称和部门地点不是直接由员工ID决定的,而是由部门ID决定的。
-
传递链条: 所以,部门名称和部门地点传递依赖于员工ID:员工ID -> 部门ID -> (部门名称, 部门地点)。它们是通过部门ID这个"二道贩子"才和主钥匙员工ID联系上的。
这种"拐弯抹角"的依赖会带来什么麻烦?
-
信息存得太多太重复 (数据冗余): 你看张伟 (101) 和李娜 (102) 都在研发部 (D01)。结果,"研发部"这个名称和"北京"这个地点,在张伟的记录里存了一遍,在李娜的记录里又一模一样地存了一遍!如果研发部有100个员工,这个信息就要重复存100次,白白浪费空间。
-
改信息时容易出错 (修改异常): 假设"研发部"改名叫"创新研发部"了。现在你需要做什么?你必须把所有属于D01部门的员工记录(张伟、李娜以及研发部其他所有员工)找出来,一个一个去把他们记录里的"部门名称"从"研发部"改成"创新研发部"。万一漏掉了李娜没改?那她的记录里部门名称还是旧的"研发部",而张伟的已经是新的了,数据就乱套不一致了。
-
加新部门加不进去 (插入异常): 公司新成立了一个"法务部",部门ID是D03,地点在深圳。但现在这个部门还没招人,没有员工。你能把这个部门的信息加到员工表里吗?加不进去! 因为员工表的主钥匙是
员工ID,你要加一行新记录,必须提供一个员工ID。没有员工,就没有员工ID,也就没法记录这个新部门的存在。新部门的信息就被卡住了。 -
删员工可能删掉部门 (删除异常): 假设市场部 (D02) 现在只有赵明 (104) 一个员工了。如果赵明离职了,你把赵明这条记录从表里删除。会发生什么?赵明的记录删掉了,同时记录里包含的"市场部"这个名称和"上海"这个地点信息也跟着一起被删掉了!即使市场部这个部门还在,只是赵明一个人走了,但部门信息却因为最后一名员工的删除而丢失了。
第三范式 (3NF) 怎么解决这个问题?核心:斩断"拐弯抹角"的链条!
3NF 要求:表里的每一条非关键信息 (比如部门名称、地点),都必须能直接通过主钥匙(员工ID)找到,中间不能经过其他非关键信息(比如部门ID)来"转手"。
怎么做?把那些充当"二道贩子"的信息(部门ID)和它所"代理"的信息(部门名称、地点)打包移走 ,放到一张专门的新表里去。
-
创建部门信息专属表:
-
这张新表的核心是
部门ID,它成为这张表的"主钥匙"。 -
把
部门名称和部门地点放进去,它们直接 依赖于部门ID(知道部门ID就能直接查到名称和地点,一步到位)。 -
现在可以记录所有部门的信息,即使这个部门还没员工。比如新成立的"法务部"(D03, 深圳) 可以直接加进来。
| 部门ID (新表的主钥匙) | 部门名称 | 部门地点 |
|---------------|------|------|---------------|
| D01 | 研发部 | 北京 |
| D02 | 市场部 | 上海 |
| D03 | 法务部 | 深圳 | (没有员工也能存在!) | -
-
简化员工信息表:
-
员工表只保留直接 依赖于
员工ID的信息:员工姓名和部门ID。 -
部门ID在这里的作用变了:它不再"代理"部门名称和地点,它仅仅表示"这个员工属于哪个部门",这是一个员工自身的直接属性。 -
如果想知道员工的具体部门名称和地点?很简单,通过
部门ID这个"门牌号"或者"链接",去部门信息专属表里查一下就行了。
员工ID (主钥匙) 员工姓名 部门ID (指向部门表的链接) 101 张伟 D01 102 李娜 D01 103 王芳 D02 104 赵明 D02 -
为什么现在满足第三范式 (3NF) 了?
-
在员工表里:
-
员工姓名直接依赖于主钥匙员工ID(知道ID就知道名字)。 -
部门ID也直接依赖于主钥匙员工ID(知道ID就知道他属于哪个部门ID)。这里部门ID就是一个简单的属性值,它不再负责去决定其他信息(如名称、地点)。 -
表内不存在 像"员工ID -> 部门ID -> 部门名称"这样的"拐弯抹角"链条了。所有信息(姓名、所属部门ID)都直接挂在
员工ID这把主钥匙上。
-
-
在部门表里:
部门名称和部门地点直接 依赖于它们自己的主钥匙部门ID(知道部门ID就能直接查到名称和地点),没有传递依赖。
-
所有麻烦都解决了:
-
不重复存: "研发部-北京"只在部门表里存一次,所有D01部门的员工记录里只存一个轻量的"D01"。
-
改起来容易: 研发部改名?只需要去部门表 里把D01对应的"部门名称"从"研发部"改成"创新研发部"一次 ,所有关联到D01的员工信息自动就更新了(因为员工表里只存了D01这个链接,名称在部门表里统一管理)。
-
能加空部门: 新部门没员工?直接在部门表里加一行记录就行(如D03法务部)。
-
删员工不丢部门: 删掉市场部最后一个员工赵明?只是员工表里少了一行指向D02的记录。部门表里D02市场部(上海)的信息纹丝不动,完好无损。
-