前段时间刷雪球,有人翻出了去年克来机电的一段K线图,回想当初在第五板的时候冲了进去,结果赚了股市上的第一桶金就让人热血沸腾。
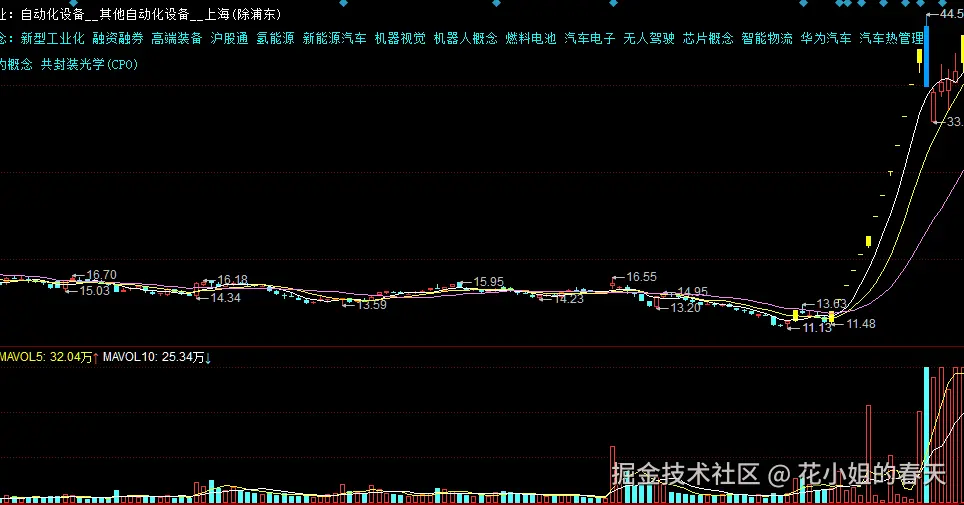
我当时就被那波走势吸引了......前半段洗得干干净净,后面直接13板起飞
我脑子一热,心里突然就冒出一个想法------ "如果我把这段走势复刻下来,用Python全市场扫一遍,会不会找到现在正在'模仿'它的股票?"
想归想,我这人说干就干。结果,一套脚本跑完之后,我还真找到了7只走势惊人相似的票......
那么问题来了------到底怎么找的?
流程很简单,首先把我想复刻的那段牛股K线,做成一个"模板",然后从所有A股最新N日的K线里,一个个去比,这里的N要和模版对应的K线保持长度一致,最后谁和模板"最像",就把它挑出来,当然也可以做个排名,比如找到最像的前100名
我罗列了几种常见的查找相似K线的方法
比对的思路有很多,我来一个个讲清楚:
1️⃣ 基于价格特征的相似度计算(归一 + 距离)
思路: 把收盘价序列归一化(消除价格影响),然后计算"距离"------谁离模板最近,谁最像。
实现方法:
python
import numpy as np
def guiyi(x):
return (x - np.min(x)) / (np.max(x) - np.min(x))
def euclidean_distance(x, y):
return np.linalg.norm(guiyi(x) - guiyi(y))用这个你就能跑一圈,把当前所有股票和目标段做逐一比对。
- 优点:实现最简单
- 缺点:只看形,不看节奏,不看量能,容易受"影线"干扰
2️⃣ 基于相关系数的形态匹配(形更像)
思路: 用皮尔逊相关系数来比较两个序列的"形状趋势"。
python
def similarity_corr(x, y):
return np.corrcoef(normalize(x), normalize(y))[0, 1]值越接近1,形状越像 这比"距离"更靠谱,哪怕价格起伏不同,但只要"节奏对",就能匹配出来。
- 优点:对"形态"更敏感
- 缺点:也只能处理一维价格,不看量价组合
3️⃣ 动态时间规整(DTW)------节奏错了也能比
思路: 就像你跳广场舞跳慢两拍,DTW能自动"对齐"两段数据的节奏,重新比形。
python
from dtaidistance import dtw
def dtw_score(x, y):
return dtw.distance(normalize(x), normalize(y))DTW本质是个"弹性尺子",你慢我快它都能修正。适合匹配节奏不一致但走势近似的情况。
- 优点:对节奏变化鲁棒
- 缺点:计算慢,对大规模匹配有点吃力
4️⃣ 多维度特征融合(价格 + 量能 + 技术指标)
思路: 只看价格太单一,我们可以融合多个维度,把每段K线变成"多维特征向量"后,再比较。
你可以加上这些维度:
- 涨跌幅(连续序列)
- 成交量比值(放量)
- 均线乖离率(bias)
- RSI、MACD等指标
举个例子:
python
def extract_features(df):
close = df['close'].values
volume = df['volume'].values
bias = (close - pd.Series(close).rolling(10).mean()) / pd.Series(close).rolling(10).mean()
return np.stack([
normalize(close),
normalize(volume),
normalize(bias.fillna(0))
], axis=1) # 每行是一天,每列是一个维度然后用cosine similarity或euclidean计算向量之间的距离。
- 优点:更贴近真实交易思维(形+量+指标)
- 缺点:特征选取主观性强,调参多
5️⃣ 深度学习模型(AutoEncoder、CNN、LSTM)
思路: 机器自己学,不需要你人工定义"像不像"。你给它大量K线图、涨幅图,它自己提特征。
最常见的是:
- AutoEncoder:先训练一个模型,把K线压缩成128维特征向量,再比相似度。
- CNN图像模型:把K线画成图,丢进预训练CNN,比如ResNet
- LSTM序列模型:吃下收盘价、成交量,输出预测向量,再比向量
示例(AutoEncoder思路):
python
# 拿历史大量K线训练 AutoEncoder
# 得到encoder(x) -> z 这样的压缩特征
# 然后每个股票当前60天的压缩向量 z_current
# 和 template_z 做 cosine similarity- 优点:最智能、可以自动捕捉复杂模式
- 缺点:训练门槛高,调参复杂,计算资源要求高
那么问题来了:哪种方法最好?
如果你是初级或实盘策略验证阶段,我建议:
🔹 相关系数 + 多维度特征融合
这是性价比最高的一套组合,简单、逻辑合理、对形态最敏感
如果你想上一个台阶,构建自动化系统,我推荐:
🔹 AutoEncoder + DTW/余弦匹配
模型自动压缩形态 → 生成表示 → 用简单方法匹配 → 准确率高、噪声低、适合批量跑全市场
但如果你只是单纯想找"有没有哪只股票现在在走我熟悉的那条路"?
那相关系数 + 成交量、涨幅、乖离 这几个拼一拼,能跑通一套完整扫描系统,效果其实已经够用。
花姐的建议(干货来了)
🌟 起步阶段:
用「相关系数 + 收盘价归一 + 成交量比例」搞一个简版扫描系统,每天扫一次最近N天,成本不高,效果不错。
🌟 提升阶段:
考虑加上DTW优化节奏比对,引入多维度特征,解决"节奏错位"但形态雷同的情况。
🌟 专业阶段:
用AutoEncoder训练「形态表示向量」,再配合L2或cosine匹配,可搭建整套K线智能识别系统。
结尾:炒股靠感觉,但更要靠模型
很多人炒股靠感觉,但真正能长期稳定跑策略的,一定是把感觉数字化的人。
找相似K线,就是把"盘感"交给机器,一天扫全市场,帮你找到"熟悉的味道"。
就像听见旋律就知道这歌你听过 股票也有节奏,找准了------就能上车了
有需要我可以帮你把整个扫描系统写出来,用最实战的代码,整成可落地工具,随时部署。
------花姐,今天这篇干货,希望你用得上