今天的主题是无监督算法中的聚类,常利用聚类来发现数据中的模式,并对每一个聚类后的类别特征进行可视化,以此得到新的特征并赋予实际含义。
python
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载数据集
df = pd.read_csv('heart.csv')
# 1. 标准化数据
scaler = StandardScaler()
scaled_df = scaler.fit_transform(df.drop('target', axis=1))
# 2. 选择合适的算法(这里使用 KMeans),根据评估指标(轮廓系数)调参
silhouette_scores = []
for n_cluster in range(2, 11):
kmeans = KMeans(n_clusters=n_cluster)
kmeans.fit(scaled_df)
label = kmeans.labels_
sil_coeff = silhouette_score(scaled_df, label, metric='euclidean')
silhouette_scores.append(sil_coeff)
# 获取最佳簇数
best_n_clusters = silhouette_scores.index(max(silhouette_scores)) + 2
kmeans = KMeans(n_clusters=best_n_clusters)
kmeans.fit(scaled_df)
cluster_labels = kmeans.labels_
# 3. 将聚类后的特征添加到原数据中
df['Cluster'] = cluster_labels
# 4. 使用 t - SNE 进行 2D 可视化
tsne = TSNE(n_components=2, random_state=42)
tsne_result = tsne.fit_transform(scaled_df)
df['tsne-2d-one'] = tsne_result[:, 0]
df['tsne-2d-two'] = tsne_result[:, 1]
# 可视化聚类结果
plt.figure(figsize=(16, 10))
sns.scatterplot(
x="tsne-2d-one", y="tsne-2d-two",
hue="Cluster",
palette=sns.color_palette("hls", best_n_clusters),
data=df,
legend="full",
alpha=0.3
)
plt.title('t - SNE 2D Visualization of Clusters')
plt.show()
# 5. 聚类后分析
# 1、推断簇的类型
cluster_summary = df.groupby('Cluster').mean()
print("各簇的特征均值:")
print(cluster_summary)
# 2. 通过可视化图形定义簇的含义(这里简单描述,实际需结合专业知识深入分析)
# 从 t - SNE 可视化图形中,不同簇在二维空间中的分布位置和聚集程度可以推测簇的含义。
# 例如,彼此分离较远的簇可能代表具有明显不同特征的群体。
# 3. 通过精度判断特征工程价值
# 划分训练集和测试集
X = df.drop(['target', 'Cluster', 'tsne-2d-one', 'tsne-2d-two'], axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练逻辑回归模型
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
# 预测并计算精度
y_pred = logreg.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("逻辑回归模型的精度:", accuracy)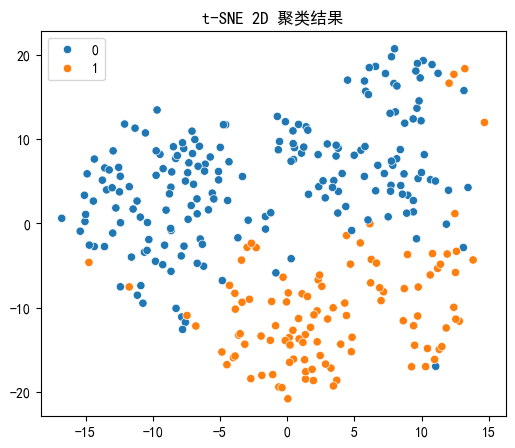
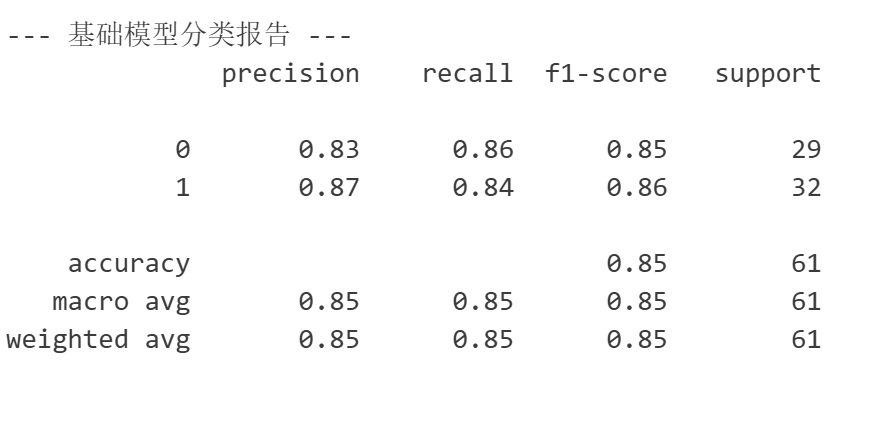

特征工程后模型精度有所提升
年龄方面,簇 0 的平均年龄(58.624)比簇 1 的平均年龄(51.376404)要高。这可能意味着簇 0 代表年龄较大的人群,而簇 1 代表相对年轻的人群。
目标方面,簇 0 的均值为 0.216000,簇 1 的均值为 0.775281,差异较大。推测簇 0 可能代表心脏病发病风险较低的人群,而簇 1 代表心脏病发病风险较高的人群。结合年龄特征,可能年龄较大的人群虽然某些指标看起来不太好(如胆固醇 chol 等),但实际发病风险相对低;而相对年轻人群在某些情况下发病风险却较高。