摘要
在 MySQL 的面试中有一类经典的面试题。比如《如何给正在线上运行的表执行 DDL 语句?》
回答这个问题,首先我们需要明确,执行 DDL 语句的时候,MySQL 会干什么
在 MySQL 5.6 之前,执行 DDL 语句的时候,会给表添加写锁,会阻塞该表其他所有的读写操作。这对生产来说,这个写锁占用的时间越久,对整个数据库带来的风险就越大。所以我们回答的核心就是如何避免这种影响,或者说如何将这种影响降低到最小
在 MySQL 中,DDL 算法有两种
- copy 算法
- inPlace 算法(Online DDL)
copy 算法
在 MySQL 5.6 之前,只有 copy 算法。当执行 DDL 语句或者重建表语句时,算法的流程如下图:首先会创建一个 tmp 临时表,然后将 A 表中的数据,向 tmp 表中移动;移动完成之后将 A 表改为 tmp 表,然后之前创建的 tmp 表就成为了新的 A 表。至此完成了 DDL 操作,或者重建表的操作
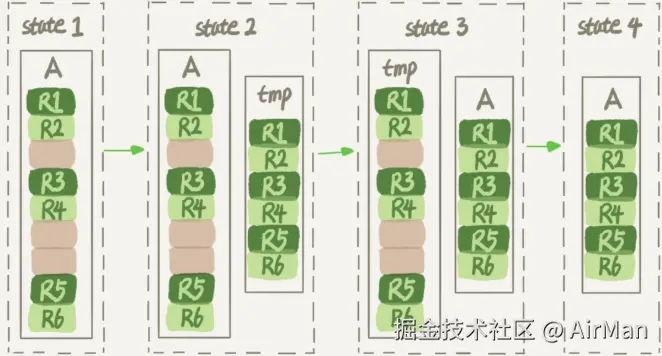
在 copy 算法中,不难发现。插入过程的 IO 操作是十分耗时的,如果这个时间有新的数据想写入 A 表的话,就可能造成数据的丢失。所以 copy 算法在整个 DDL 期间,或者重建表期间,A 表是不允许更新的,也就是说 copy 算法 state 4 之前都需要给表加写锁!
所以对应下面即将要讲的算法而言,copy 算法不是 Online 的
inPlace 算法
所以 MySQL 5.6 版本开始引入的 InPlace 算法,也就是 Online DDL 算法,主要解决的就是如何缩短写锁的时间
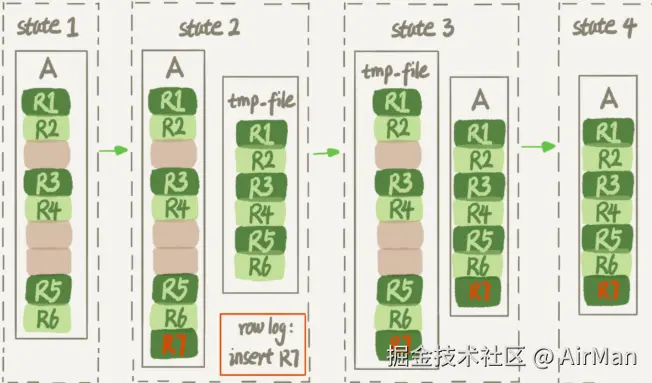
- 建立一个临时文件,扫描表 A 主键的所有数据页
- 用数据页中表 A 的记录生成 B+ 树,存储到临时文件中
- 生成临时文件的过程中,将所有对 A 的操作记录在一个**日志文件(row log)**中,对应的是下图 state2 的状态
- 临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件,对应的就是图中 state3 的状态
- 用临时文件替换表 A 的数据文件
copy 算法中,我们讲的是 DDL 语句,那么 inPlace 算法我们用 alter 语句来讲
alter table A engine = innodb,ALGORITHM = inplace;
所以 inPlace 算法,由于日志文件记录和重放操作这个功能的存在。这个方案在重建表或者执行 DDL 语句的过程中,允许对表 A 做增删改操作,这也就是 Online DDL 名字的来源
回答这个算法最初的目的,他是为了缩短写锁的占用的时间
既然有一个 row log 记录操作,那么是不是就不需要获取写锁了?
实则不然,在上图的流程中,DDL 语句在启动的时候需要获取 MDL 写锁。但是这个写锁在正在拷贝数据之前就退化为读锁了,而不是像 copy 算法在 state 4 之前一直占用
那面试官问你为什么需要重建表的语句需要退化为读锁?
上面已经回答你了,肯定是为了 Online 啊,只有 MDL 读锁才不会阻塞增删改操作
那面试官继续问你为什么不干脆直接解锁呢?
inPlace 算法也需要保护自己,它需要先获取到 MDL 写锁,然后安全地操作表的物理和元数据文件。因为只有 MDL 写锁才能保证全局唯一、100%安全的操作。如果在执行 Alter 语句时有其他线程对这个表同时做 DDL,可能就会造成元数据损坏,死锁等问题
但是我想告诉的你,DDL 语句中,如果是在末尾增加列,那么 DDL 语句是完全不会阻塞的。只有在中间增加列,才有一个加锁的过程。因为只有修改中间,才会导致数据的排列变更,也就需要更改元数据。但是即使上面的 Online DDL 需要加锁,也只是一个元数据的更新,占用的时间很短。
copy 算法和 inPlace 算法创建的 tmp 都一样吗?
其实你仔细观察上面的两个图,你就发现了 copy 算法使用的是 tmp;inPlace 使用的是 tmp_file
- 如果在 tmp_table 中,这个临时表是在 server 层创建的。这就是 copy 算法
- 如果在 tmp_file 中,这个临时文件是 InnoDB 在内部创建出来的。这就是 inPlace 算法
tmp_file 整个 DDL 过程或者重建表的过程都在 InnoDB 内部完成。而对于 server 层来说,没有把数据挪动到 tmp_table 中。所以从 server 层看这就是一个"原地"操作,这就是"inplace"名称的来源
Online 和 inplace 两个逻辑之间的关系是什么?
- DDL 过程如果是 Online 的话,就一定是 inplace
- 反过来未必,也就是说 inplace 的 DDL,有可能不是 Online 的
- 截止到 MySQL 8.0,添加全文索引(FULLTEXT index)和空间索引 (SPATIAL index) 就属于是 inplace 操作,但不属于 Online(会阻塞增删改操作)
当然,也不是所有的 DDL 语句都支持 inPlace 操作,比如修改字段的类型就不支持 inPlace 算法
详细可以看官方文档
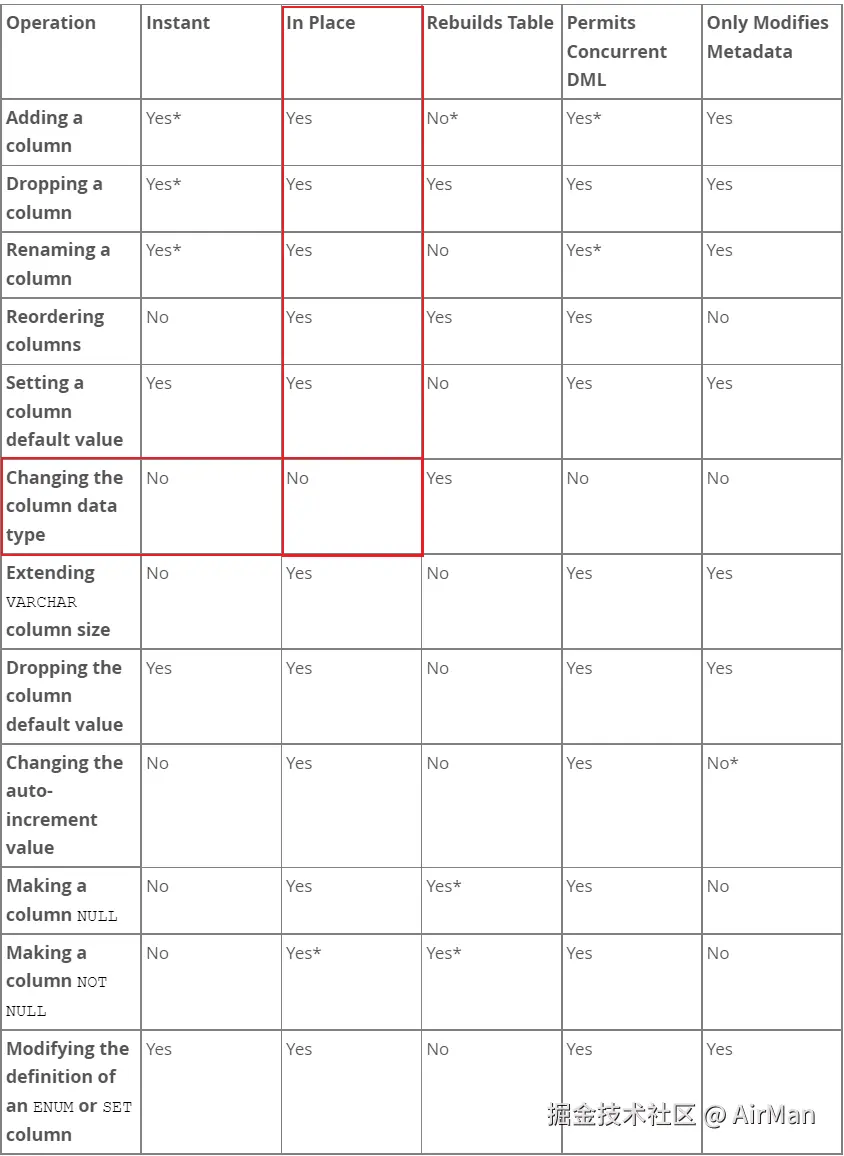
Instant Add Column
Inplace 虽然不会阻塞 DML,也就是数据库的读写操作。但是如果表结构很大,持续的事件会比较久,也就是更新可能会在分钟级别的时间生效,这就产出了一个长事务(长事务的影响不是本章讨论的重点,不再过多赘述)。
而为了让这个生效的事件更加实时,MySQL 8 推出了新的功能:Instant Add Column
java
ALTER TABLE A ADD COLUMN new_column INT, ALGORITHM = INSTANT;问题的来源是我们需要新建一个临时文件,那我们是不是不创建临时文件就解决了问题?
Instant Add Column 算法就是这么做的,具体的原理如下
- 只修改表的元数据,不重写一行数据,不产生临时表,也不拷贝表数据!
- 添加的字段,实际物理上不会在磁盘页里新增内容,只是在表的"数据字典"中记录"新加了一个字段,默认值为XXX,排在第几列"
- 读取老数据页时,遇到没有物理存储的字段,自动用默认值补齐(MySQL 8.0页格式的能力)
- 只有新插入/修改的数据,才会真正把新字段内容写进磁盘页(老行还是只有旧字段,新行是新字段格式)
Instant Add Column 算法速度极快:表再大,加字段都只需几毫秒到一秒钟,无论几十 G 还是几百 G 表
当然它的限制条件也很多,Instant Add Column 只能加在表的最后一列,不支持中间插入。
因为讲 inplace 算法的时候,就提及过在末尾增加列的事情。那这里我们在重点讨论一下为什么 Instant Add Column 算法不能在中间插入。因为如果新列只加在最后一列,原有的数据页中的所有行的字段顺序和偏移都不需要变。读取时,只需在"旧行"后面补上新列的默认值,不会出错,也不需要改数据页。如果你要求在中间插入一个字段,所有后面的每一列的偏移都要变,整个数据页里每一行的物理存储结构(列偏移信息)都要修改。所有旧数据行都要被重新解析、重写、移动,否则读取时会乱套,甚至解析出错。
还有其他的限制如下,都很好理解,不再一一解释
- 字段必须允许NULL或者有默认值(NOT NULL 且无默认值肯定是不行的)
- 新字段也不能有 UNIQUE、PRIMARY KEY 等唯一约束,不能加自增
- 表必须是 InnoDB,且使用 MySQL 8.0.12+ 的新数据页格式
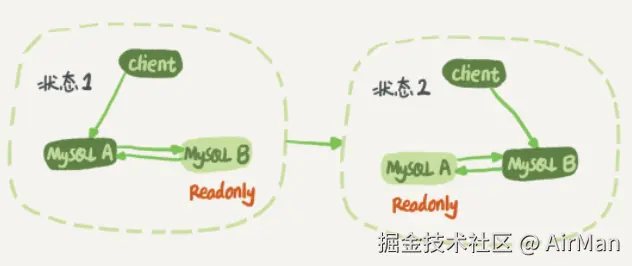
主从切换
在双 Master 的集群中。可以先在 Master B 中执行 DDL 语句,之后再将 client 接入到 Master B 中。然后再去修改 Master A
5. 总结
如何给正在线上运行的表执行 DDL 语句?
- DDL 我们需要结合业务场景和环境来看
- 如果新增列,并且 MySQL 使用的是MySQL 8,优先使用 instant 算法,这样既可以避免锁表,又能快速生效
- 如果是 5.6/5.7 版本,优先使用 Online DDL 功能,具体来说就是更新时指定算法是 inplace,可以避免重建表带来的锁表
- 如果上述方案都不能用,例如指定列更新或者更低版本,可以采用主从切换的方式来更新