文章目录
- MYSQL:数据库设计
-
- [1. 本节简述](#1. 本节简述)
- [2. 范式](#2. 范式)
-
- [2.1 第一范式 (1NF)](#2.1 第一范式 (1NF))
-
- [2.1.1 定义](#2.1.1 定义)
- [2.1.2 示例](#2.1.2 示例)
-
- [2.1.2.1 反例](#2.1.2.1 反例)
- [2.1.2.2 正例](#2.1.2.2 正例)
- [2.2 第二范式 (2NF)](#2.2 第二范式 (2NF))
-
- [2.2.1 定义](#2.2.1 定义)
- [2.2.2 示例](#2.2.2 示例)
-
- [2.2.2.1 反例](#2.2.2.1 反例)
- [2.2.2.2 不满足第二范式可能带来的问题](#2.2.2.2 不满足第二范式可能带来的问题)
- [2.2.2.3 正例](#2.2.2.3 正例)
- [2.3 第三范式 (3NF)](#2.3 第三范式 (3NF))
-
- [2.3.1 定义](#2.3.1 定义)
- [2.3.2 示例](#2.3.2 示例)
-
- [2.3.2.1 反例](#2.3.2.1 反例)
- [2.3.2.2 正例](#2.3.2.2 正例)
- [3. 设计过程](#3. 设计过程)
- [4. 实体-关系图](#4. 实体-关系图)
-
- [4.1 E-R图的基本组成](#4.1 E-R图的基本组成)
- [4.2 关系的类型](#4.2 关系的类型)
-
- [4.2.1 一对一关系 (1 : 1)](#4.2.1 一对一关系 (1 : 1))
- [4.2.2 一对多关系 (1 : N)](#4.2.2 一对多关系 (1 : N))
- [4.2.3 多对多关系 (M : N)](#4.2.3 多对多关系 (M : N))
- [5. 练习:设计表](#5. 练习:设计表)
-
- [5.1 用户与账户的一对一关系](#5.1 用户与账户的一对一关系)
- [5.2 学生与班级的一对多关系](#5.2 学生与班级的一对多关系)
- [5.3 学生、课程与成绩的多对多关系](#5.3 学生、课程与成绩的多对多关系)
MYSQL:数据库设计
大家好!在之前的学习中,我们已经掌握了数据库和表的基本操作。然而,仅仅会写SQL是远远不够的,如何设计出结构合理、性能高效的数据库,才是衡量一位开发者能力的关键。这就像盖房子,地基打得好,上层建筑才能稳固。
今天,我们就来深入探讨数据库设计的核心------范式理论,并学习如何将现实世界的需求,一步步转化为具体的数据库表结构。
1. 本节简述
- 理解数据库设计的灵魂------范式 (Normal Form)。
- 掌握实体之间常见的几种关系。
- 梳理清晰的数据库设计流程。
- 搞懂类、实体、表这三者之间的映射关系。
数据库设计的核心思路
我们可以把数据库设计的核心过程,理解为一个从抽象到具体的过程,通常遵循一个清晰的思路:
- 识别实体 :首先,我们需要从业务需求中识别出关键的"角色"或"事物",在面向对象的思想里我们称之为类 (Class)。
- 映射为表 :接着,这些类会映射成数据库中的实体 (Entity) ,每个实体最终会变成一张具体的数据表 (Table) 。而类所拥有的特征或属性,自然就成了表中的字段 (Column)。
- 确定关系:理清各个实体之间的相互关系(比如一对一、一对多)。
- 物理实现:最后,在明确了所有设计细节后,我们就可以用 SQL 语言来将这些设计稿变为现实了。
2. 范式
谈到数据库设计,有一个概念我们绕不过去,那就是范式 (Normal Form)。
我们可以把范式理解为一套设计数据库的"指导原则"或"最佳实践"。遵循这些规范,可以帮助我们设计出结构更合理、数据冗余更少的数据库。关系数据库的范式目前有六种,从低到高分别是:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。范式的级别越高,对数据关系的约束就越强,数据冗余也越小。
不过,在实际项目中,我们并不需要盲目追求最高的范式。过高的范式虽然能最大程度地减少数据冗余,但有时也会牺牲查询效率,导致数据库I/O操作变得更加频繁。因此,在大多数应用场景下,将数据库设计满足到第三范式(3NF),通常是一个兼顾了规范性和性能的理想选择。
2.1 第一范式 (1NF)
2.1.1 定义
- 第一范式是所有关系型数据库设计的基础。它要求数据库表的每一列都必须是不可再分的原子数据项。也就是说,字段的值不能是集合、数组或对象这类复杂的数据结构。
- 任何不满足第一范式的数据库,都不能严格地称之为关系型数据库。
2.1.2 示例
- 假设我们要设计一个学生表,需要记录学生和其所在学校的信息。
2.1.2.1 反例
- 下面的设计中,"学校信息"这一列存储的是一个复合对象,它还可以继续拆分为"学校名称"和"学校地址"。这就违反了原子性的要求,因此不满足第一范式。
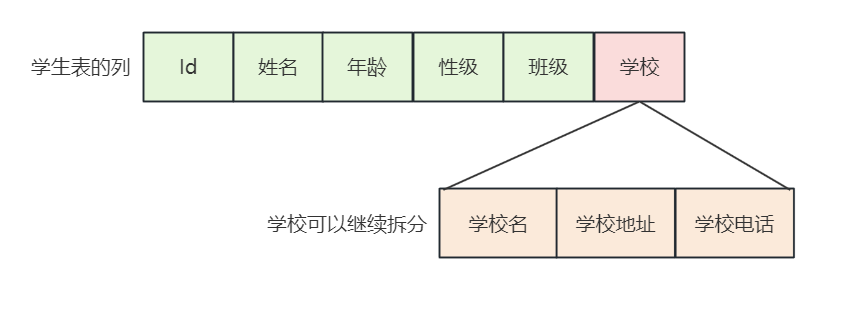
2.1.2.2 正例
- 我们将学校信息拆分成独立的"学校名称"和"学校地址"列。现在,表中的每一列都是不可再分的原子数据,这就满足了第一范式。

一个简单的判断方法:在关系型数据库中,如果一张表的每一列都可以用基本数据类型(如 INT, VARCHAR, DATE 等)来表示,那么它天然就满足第一范式。
2.2 第二范式 (2NF)
2.2.1 定义
第二范式(2NF)是在满足第一范式的基础上,提出了更高的要求。它的核心思想是:表中的所有非主键字段,都必须完全依赖于整个主键,而不能只依赖于主键的一部分。
这个规则主要是为了解决当表使用复合主键(由多个列共同组成的主键)时可能出现的问题。如果表只有一个单列作为主键,那么它天然就满足第二范式。
2.2.2 示例
- 需求:我们需要记录学生选修课程的成绩。一个学生可以选修多门课,每门课有固定的学分。
2.2.2.1 反例
- 为了方便,我们可能会尝试用一张大表来记录所有信息。
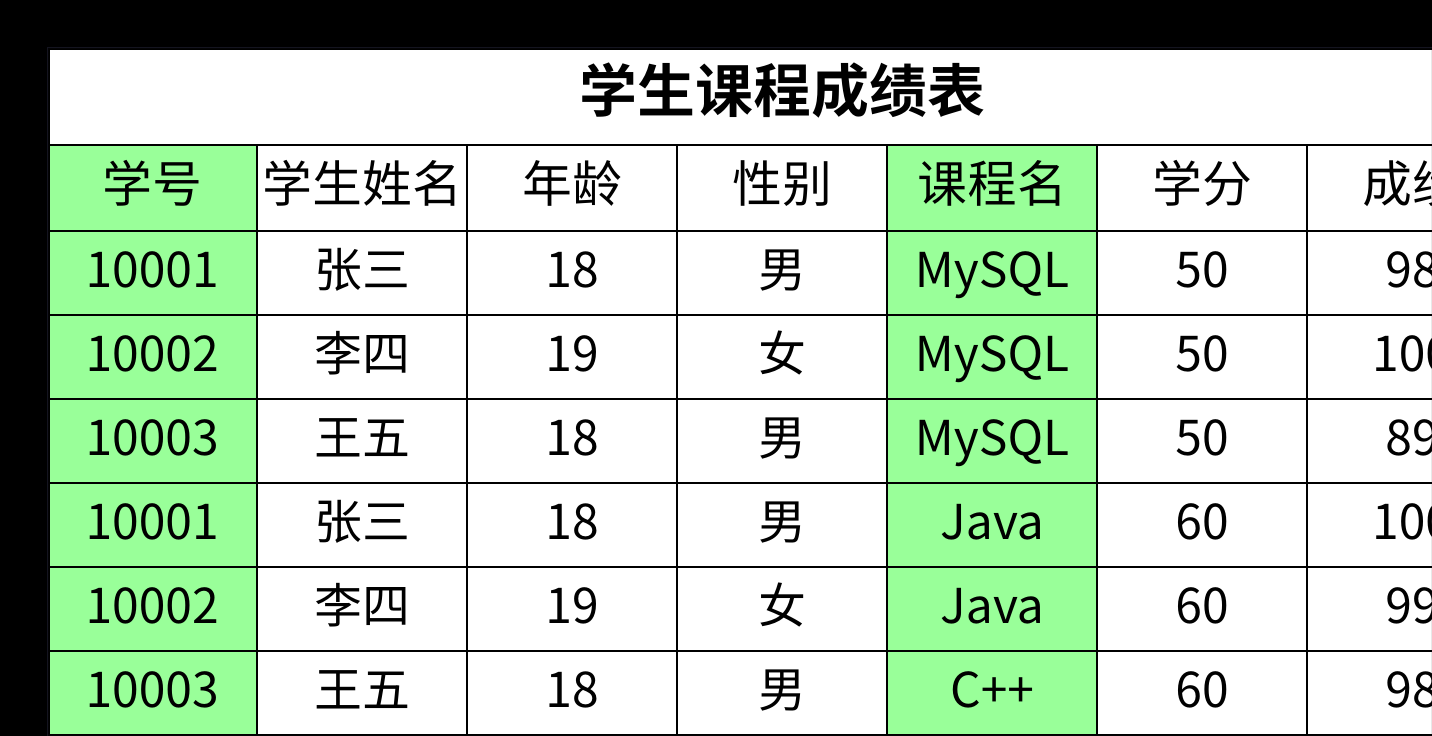
- 在这张表中,我们使用
(学号, 课程名)作为复合主键,这确实可以唯一地标识一条成绩记录。但问题也随之而来:姓名、年龄、性别这些信息,实际上只跟学号有关,和学生选了什么课没关系。- 同样,
学分这个信息只跟课程名有关,和哪个学生来选这门课也没关系。
- 这种非主键字段(如
姓名、学分)只依赖于复合主键中的一部分 (如学号或课程名)的现象,就叫做部分函数依赖。存在部分函数依赖的表,就不满足第二范式。
2.2.2.2 不满足第二范式可能带来的问题
- 数据冗余:最直观的问题。同一个学生的姓名、年龄、性别信息,以及同一门课程的学分,会随着选课记录的增加而大量重复存储。
- 更新异常:如果某门课程的学分需要调整(比如MySQL从2分改成3分),我们就必须更新所有包含这门课的记录。一旦操作中出现遗漏或中断,就会导致数据不一致。
- 插入异常:这个设计要求一条记录必须包含学生、课程和成绩。那么,如果我们要开设一门新课程,但还没有任何学生选修和考试,这门课程的信息(比如它的学分)就无法单独存入数据库中。
- 删除异常:如果某个学生毕业了,我们删除了他所有的选课成绩记录。那么,假如他是最后一个选修某门课程的学生,这门课程本身的信息(课程名和学分)也随之从数据库中消失了。
2.2.2.3 正例
- 正确的做法是进行"拆表",将不同的实体信息存放在各自的表中。针对这个需求,我们应该设计三张表:学生表 、课程表 和 成绩表。
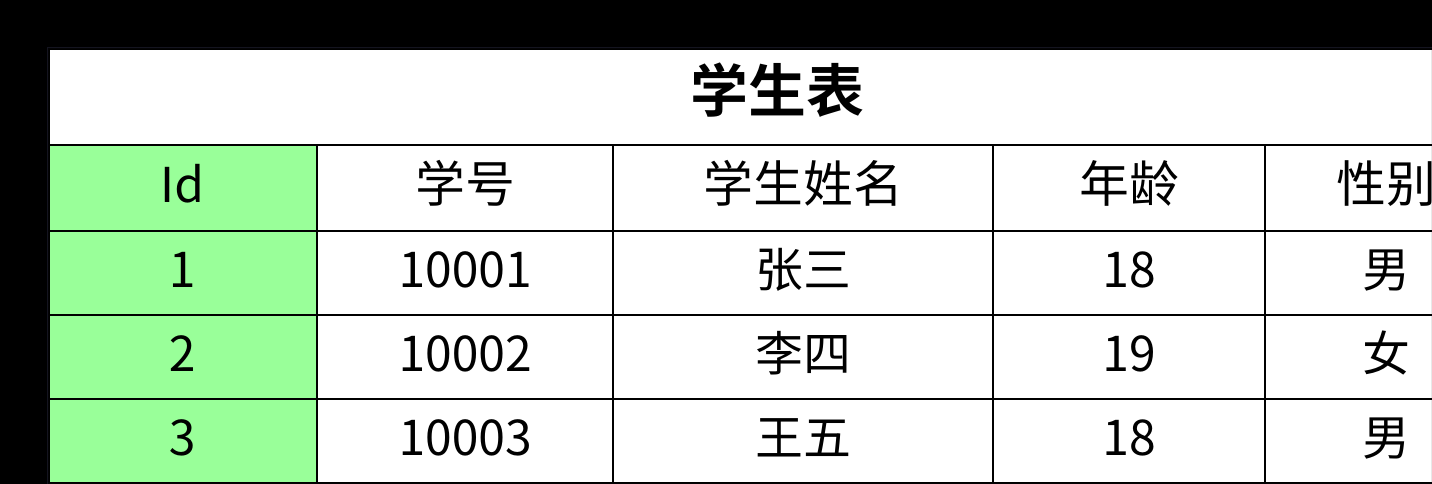
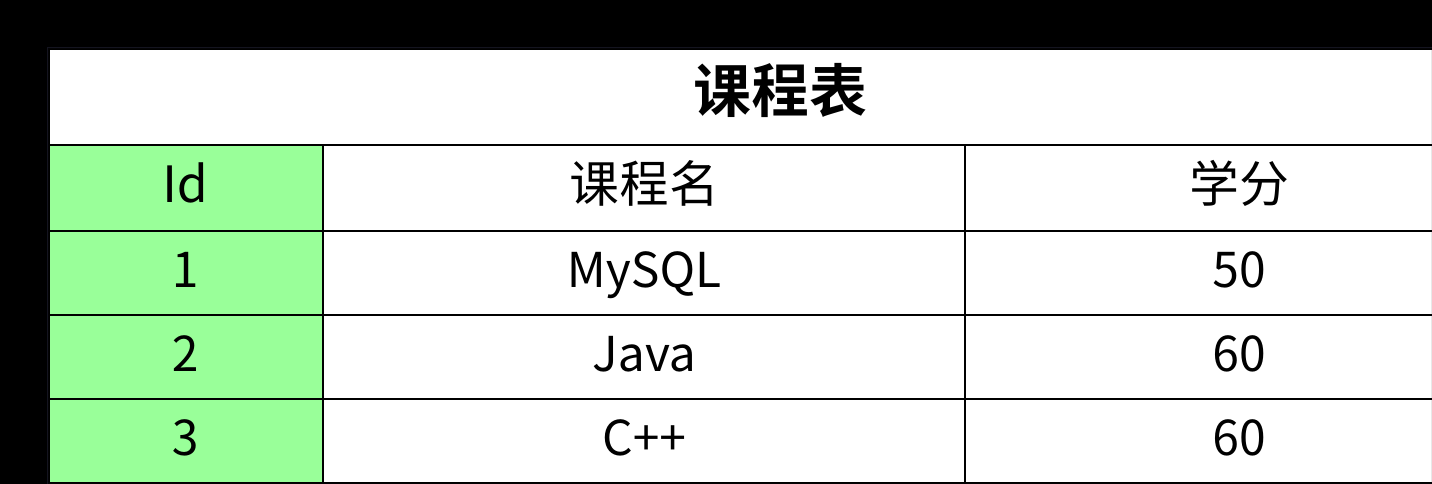
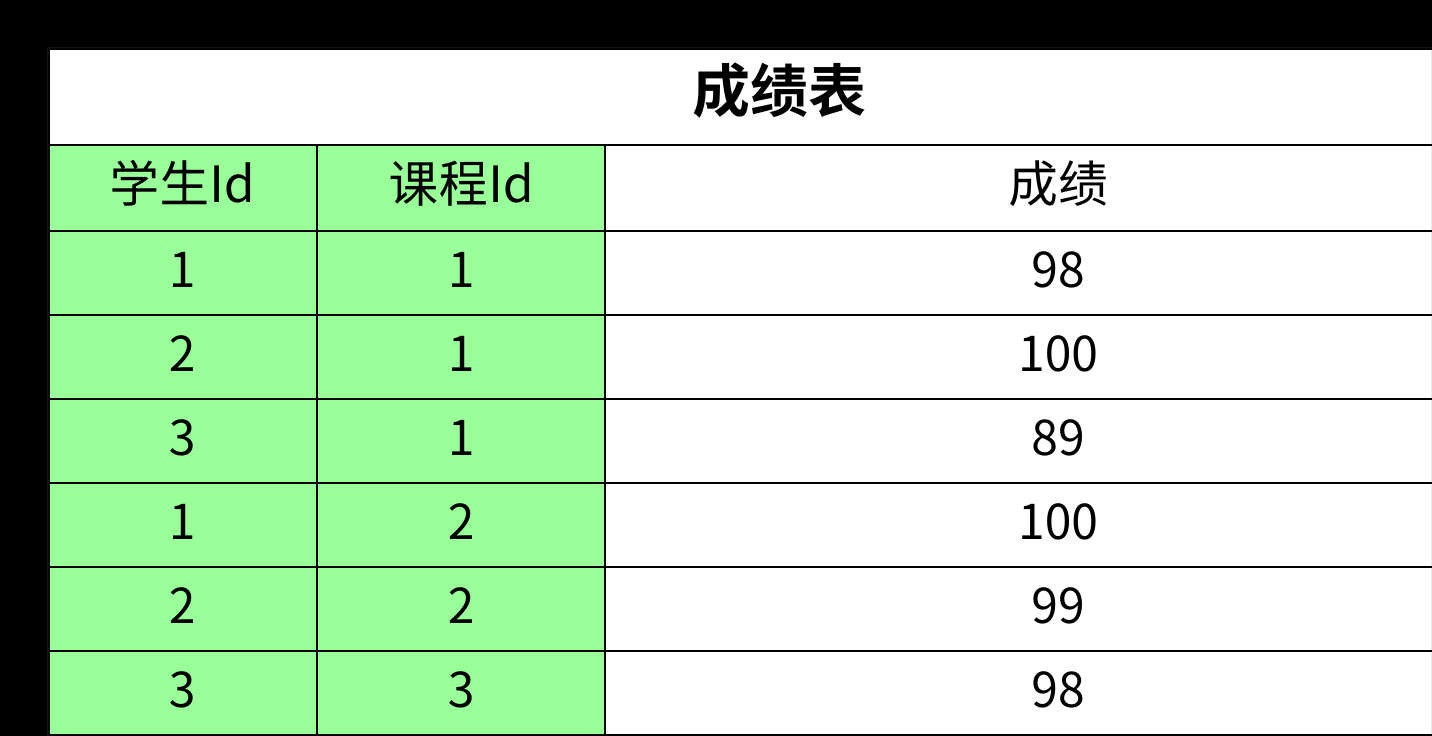
经过这样的拆分,每张表中的非主键字段都完全依赖于各自的主键,完美地满足了第二范式。
总结一下:第二范式主要解决的是"部分函数依赖"问题,通常在涉及复合主键时需要特别关注。如果一张表的主键只有一个字段,它就天然满足第二范式。
2.3 第三范式 (3NF)
2.3.1 定义
第三范式(3NF)是在第二范式的基础上更进一步。它要求:表中的所有非主键字段,都必须直接依赖于主键,而不能存在传递依赖。
什么是传递依赖 呢?简单来说,就是非主键字段 A 依赖于非主键字段 B,而非主键字段 B 又直接依赖于主键。这种 主键 -> B -> A 的依赖链条,就是传递依赖。
2.3.2 示例
- 需求:在学生表中,我们还需要记录学生所属学院的相关信息。
2.3.2.1 反例
- 我们在满足第二范式的学生表基础上,直接添加学院信息。
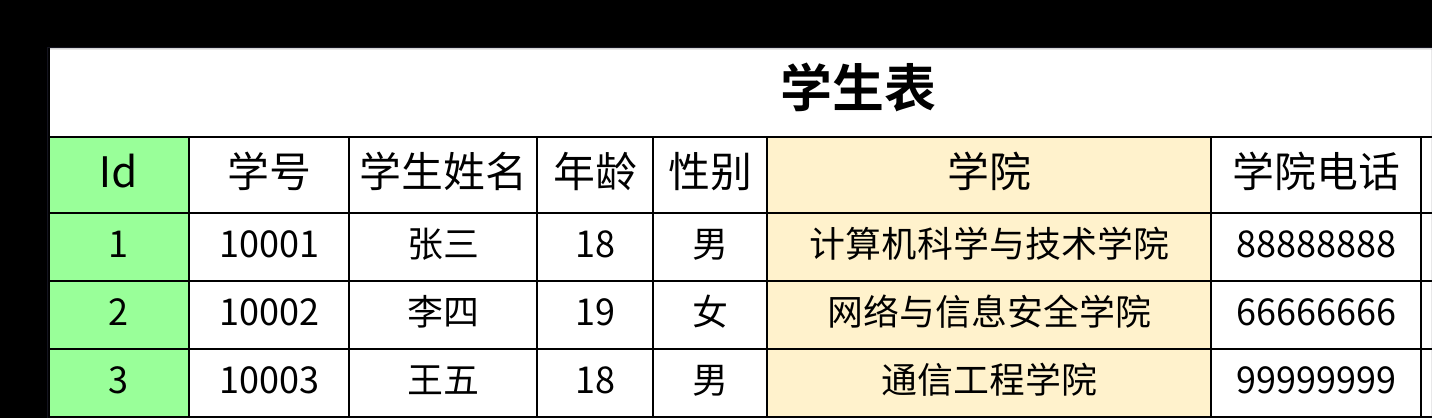
- 在这个设计中,
Id是主键。学号、姓名等字段都直接依赖于Id。但是,学院电话和学院地址这两个字段,它们直接依赖的是学院,再由学院依赖于主键Id。 - 这就形成了一个传递关系:
Id -> 学院 -> (学院电话, 学院地址)。这种现象就是传递依赖,因此这个表设计不满足第三范式。它同样会引发数据冗余、更新异常等问题。
2.3.2.2 正例
- 解决方案依然是拆表。我们将学院信息独立出来,形成一张学院表,然后在学生表中通过外键进行关联。
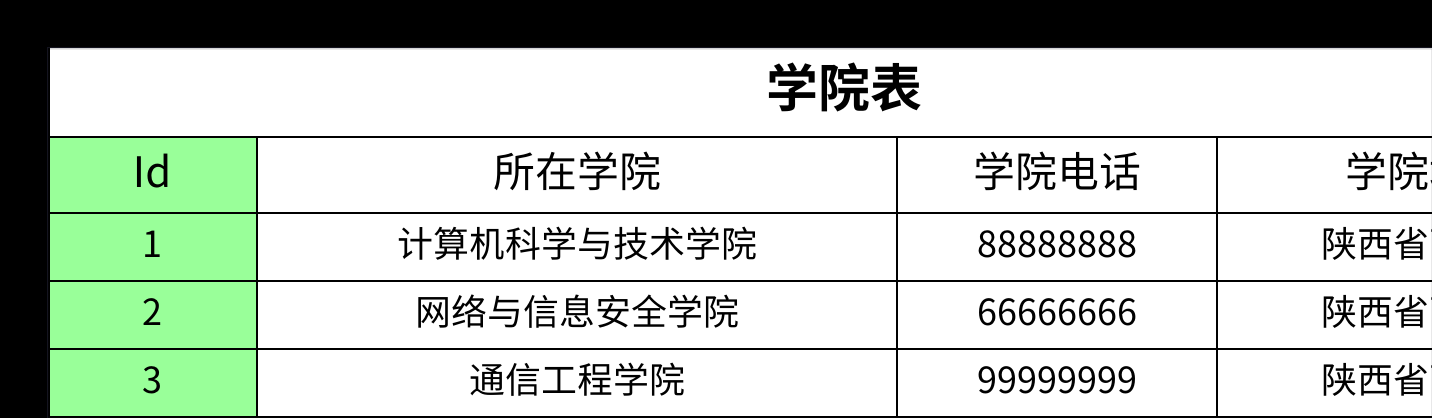
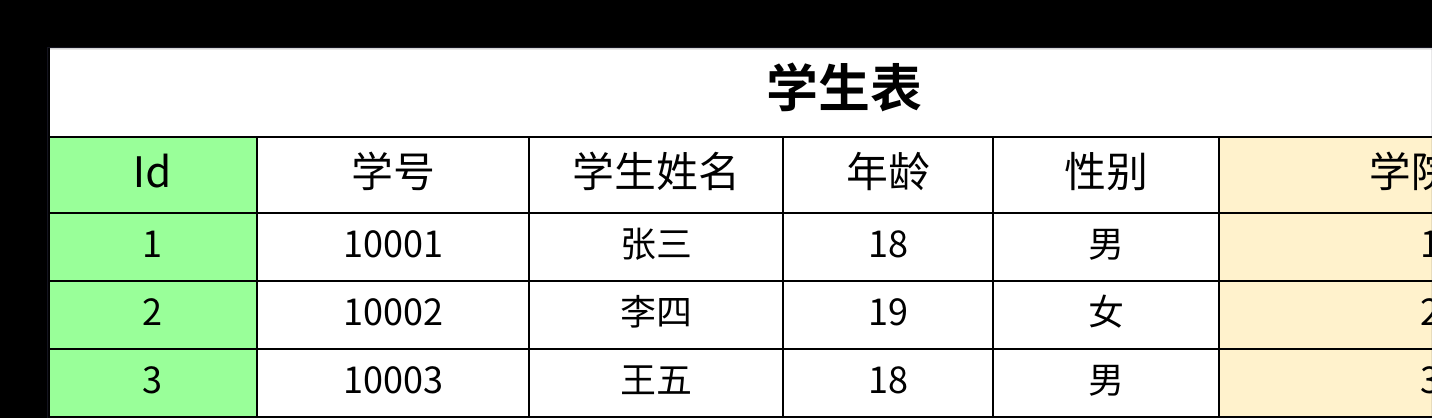
拆分之后,每个表中的非主键字段都直接依赖于主键,消除了传递依赖,满足了第三范式。
第三范式通过消除传递依赖,可以进一步解决数据冗余、更新异常、插入异常和删除异常等问题,让表结构更加清晰和健壮。
3. 设计过程
了解了范式理论后,我们来梳理一下一个完整的数据库设计流程是怎样的。通常可以分为三步走:
- 概念设计 :从现实世界的业务需求中抽象出概念类(即实体)。这个阶段主要搞清楚系统中有哪些核心对象,以及它们各自有什么属性。
- 逻辑设计 :确定实体与实体之间的关系 (一对一、一对多、多对多),并使用 E-R图(实体-关系图)将这些关系可视化地表达出来。这有助于团队成员之间的沟通和理解。
- 物理设计:根据设计好的E-R图,编写具体的SQL语句,在数据库中创建表、定义字段和约束,将设计蓝图变为现实。
4. 实体-关系图
实体-关系图(Entity-Relationship Diagram),简称E-R图,是数据库设计阶段非常重要的一个工具。它能帮助我们直观地展示数据模型。
4.1 E-R图的基本组成
E-R图主要由三种基本元素构成:
- 实体 (Entity) :指数据中的对象,通常是现实世界中的一个"事物",比如用户、学生、班级。在图中用矩形框表示。
- 属性 (Attribute) :指实体的特征或特性,比如学生的姓名、年龄。在图中用椭圆形 或圆角矩形表示。
- 关系 (Relationship) :指实体之间的联系,比如"选修"、"属于"等。在图中用菱形框表示,并用直线连接相关的实体。
4.2 关系的类型
实体之间的关系,主要有以下三种:
4.2.1 一对一关系 (1 : 1)
- 场景:一个用户实体对应一个账户实体。
- E-R图示例 :
- 用户实体属性:用户昵称、真实姓名、手机号等。
- 账户实体属性:登录用户名、密码。
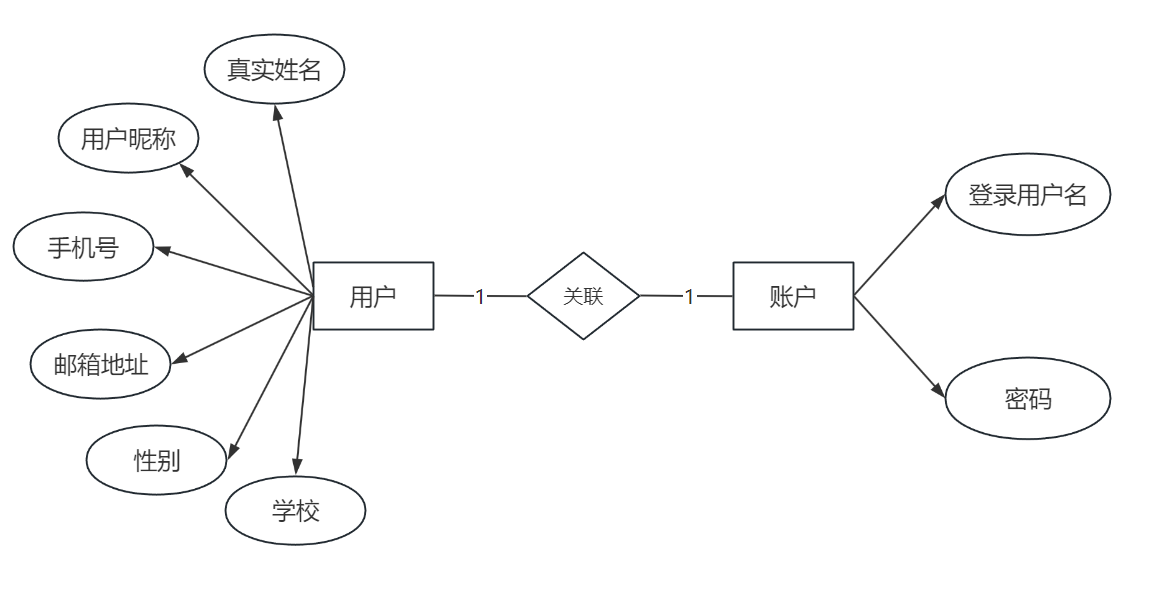
- 实现方式 :
- 合并为一张表:如果两个实体的关系非常紧密,且总是一起被查询,可以考虑合并。
- 创建两张表,用外键关联:这是更常见的做法,可以保持实体独立性。外键可以放在任意一方的表中。
4.2.2 一对多关系 (1 : N)
- 场景:一个班级实体可以包含多个学生实体。反过来看,一个学生实体只属于一个班级实体,这就是多对一关系。
- E-R图示例 :
- 学生实体属性:真实姓名、学号、年龄等。
- 班级实体属性:班级名、学生人数。
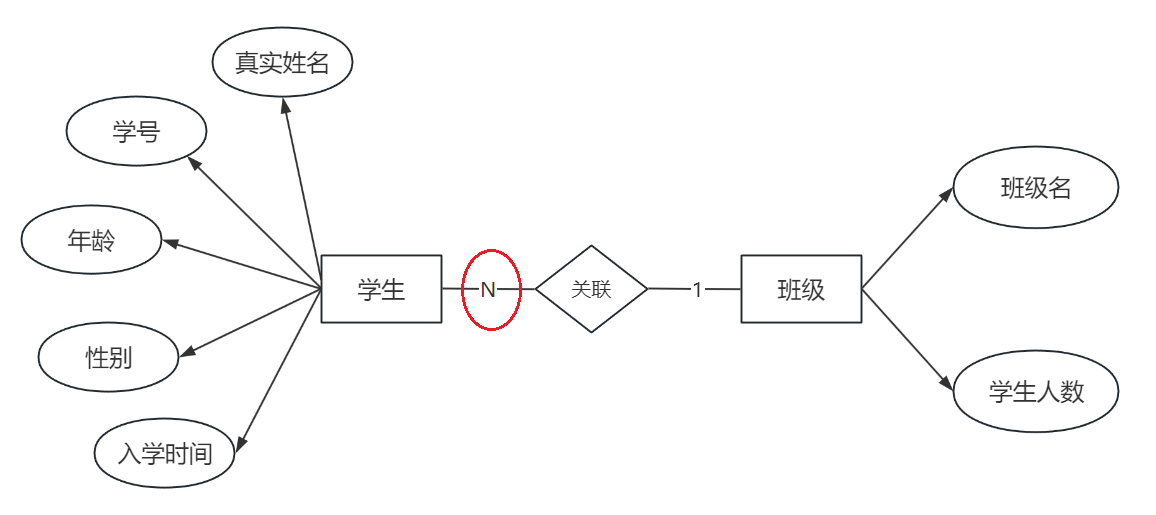
- 实现方式 :分别为两个实体创建表。关键在于,外键要添加在"多"的那一方 。在这个例子中,我们应该在学生表中添加一个
class_id字段,用来关联班级表。
4.2.3 多对多关系 (M : N)
- 场景:一个学生实体可以选修多门课程实体,同时一门课程实体也可以被多个学生选修。
- E-R图示例 :
- 学生实体属性:真实姓名、学号等。
- 课程实体属性:课程名。
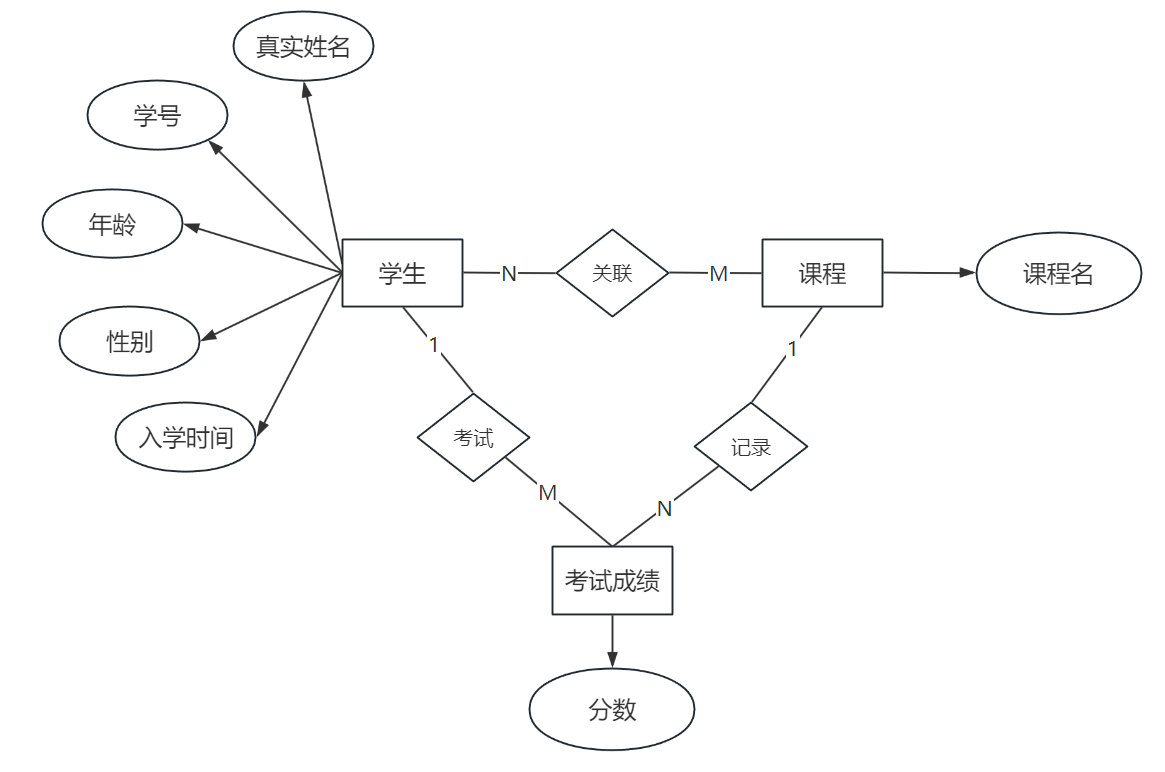
- 实现方式 :对于多对多关系,我们无法直接在两个实体表之间建立关联。标准做法是引入一个中间表 (也叫关系表或连接表)。
- 这个中间表至少包含两个外键,分别指向学生表和课程表的主键,从而将一个 M:N 关系拆解为两个 1:N 关系。
- 如果关系本身也有属性(比如学生选修某门课的"成绩"),这个属性也应该放在中间表中。
5. 练习:设计表
现在,我们根据上面绘制的E-R图,来动手创建具体的数据库表。
5.1 用户与账户的一对一关系
实现思路:对于一对一关系,我们可以在任意一张表中添加一个外键字段,来关联另一张表。
sql
-- 方案一:在用户表中添加对账户表的关联
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
nickname VARCHAR(20),
phone_num VARCHAR(11),
email VARCHAR(50),
gender TINYINT(1),
-- 外键,用于关联账户表
account_id BIGINT
);
DROP TABLE IF EXISTS account;
CREATE TABLE account (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(20) NOT NULL,
password VARCHAR(32) NOT NULL
);
-- 方案二:在账户表中添加对用户表的关联 (更常见)
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
nickname VARCHAR(20),
phone_num VARCHAR(11),
email VARCHAR(50),
gender TINYINT(1)
);
DROP TABLE IF EXISTS account;
CREATE TABLE account (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(20) NOT NULL,
password VARCHAR(32) NOT NULL,
-- 外键,用于关联用户表
users_id BIGINT
);5.2 学生与班级的一对多关系
实现思路:分别创建学生表和班级表,在"多"的一方(学生表)中添加外键,关联"一"的一方(班级表)。
sql
-- 班级表 ("一"的一方)
DROP TABLE IF EXISTS class;
CREATE TABLE class (
class_id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
-- 学生表 ("多"的一方)
DROP TABLE IF EXISTS student;
CREATE TABLE student (
student_id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
sno VARCHAR(10) NOT NULL,
age INT DEFAULT 18,
gender TINYINT(1),
enroll_date DATE,
-- 外键,关联班级表的id
class_id BIGINT
);5.3 学生、课程与成绩的多对多关系
实现思路:创建学生表和课程表,并额外创建一个中间表(成绩表)来连接它们,从而将多对多关系分解为两个一对多关系。
sql
-- 学生表
DROP TABLE IF EXISTS student;
CREATE TABLE student (
student_id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
sno VARCHAR(10) NOT NULL,
age INT DEFAULT 18,
gender TINYINT(1),
enroll_date DATE,
-- 学生与班级是一对多,外键放在学生表
class_id BIGINT,
FOREIGN KEY (class_id) REFERENCES class(id)
);
-- 课程表
DROP TABLE IF EXISTS course;
CREATE TABLE course (
course_id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
-- 成绩表 (中间表)
DROP TABLE IF EXISTS score;
CREATE TABLE score (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
-- 关系自身的属性:分数
score FLOAT,
-- 外键,关联学生表,构成了与学生表的"多对一"
student_id BIGINT,
-- 外键,关联课程表,构成了与课程表的"多对一"
course_id BIGINT,
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);