一:引言
通过《Java连接RabbitMQ(原生版)》一文中,我们了解了RabbitMQ的一些基本的使用方式,如交换机的创建及消息的投递,但是在企业中我们大部分都是把RabbitMQ集成到SpringBoot中的,所以原生的方式我们则不怎么使用到,下面我将和大家一起走入SpringBoot整合RabbitMQ的世界的下半部分。
本系列博文主要包含如下:
①:关于RabbitMQ部署和命令使用请参考: 彻底掌握RabbitMQ部署和操作(超详细)
②:使用官方自带Java API 连接RabbitMQ: Java连接RabbitMQ(原生版)
③:将RabbitMQ客户端集成进SpringBoot(上): Java连接RabbitMQ(SpringBoot版·上)
④:将RabbitMQ客户端集成进SpringBoot(下): Java连接RabbitMQ(SpringBoot版·下)
本文全部代码拉取地址Gitee:
本文给出的只是核心代码,完整代码请参考Gitee:所有案例完整代码
下面的所有示例只是核心代码,具体环境得参考完整案例代码。
关于SpringBoot集成RabbitMQ,在上篇已经说明了基本的使用,如工作队列、消息应答、消息分发、扇出、主题、直接交换机、死信、延迟队列、消息发布确认等等,而在这章主要讲解的是在实际开发中的一些问题的说明。比如最重要的幂等性问题啦。
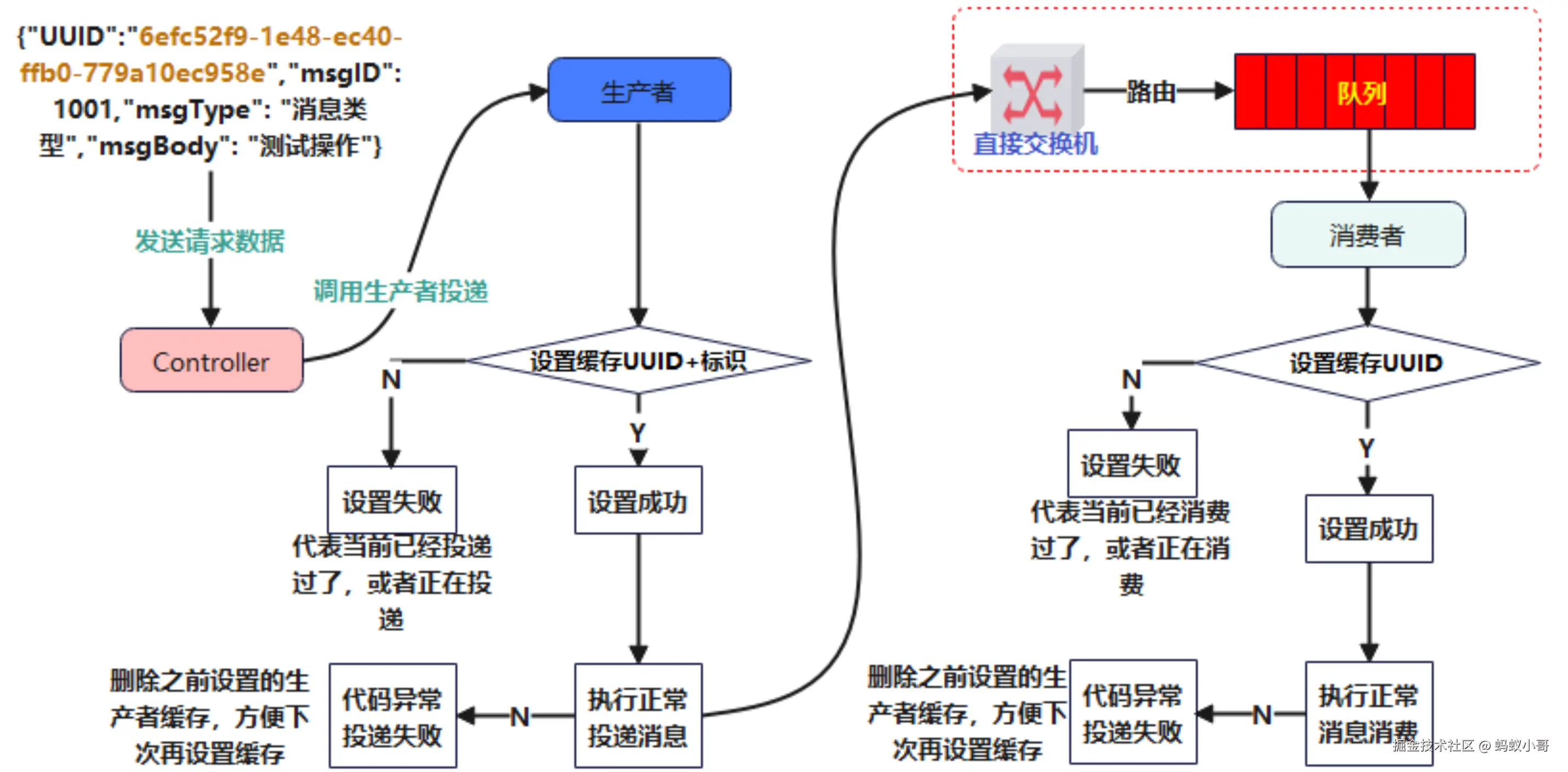
二:幂等性(消息重复消费问题)
幂等性(Idempotency) 是指:无论同一条消息被消费多少次,最终业务系统的处理结果都是一致的,且不会产生副作用或重复影响。
在使用 RabbitMQ 进行消息通信的过程中,虽然在正常流程下消息投递和消费都应是一次性的,但由于系统的复杂性和分布式环境中的各种不可控因素,消息重复投递或重复消费是无法完全避免的现象 。因此,生产者和消费者都应做好幂等性处理,以保证业务逻辑的稳定性和一致性。
⭕可能导致重复消息的常见场景:
| 场景名称 | 原因描述 | 后果影响 | 典型触发时机 |
|---|---|---|---|
| 生产者重复投递 | Web 接口被多次调用,每次调用均发送消息 | RabbitMQ 接收到多条内容相同但消息 ID 不同的消息,导致消费者重复处理 | 前端多次点击、网关重试、接口幂等性缺失 |
| 消息队列中消息重复 | 消费者处理完成但 ACK 尚未发送,RabbitMQ 宕机或网络异常,ACK 丢失 | RabbitMQ 认为消息未被确认,重启后重新投递该消息 | RabbitMQ 重启、ACK 被拦截或超时 |
| 消费者处理异常或连接中断 | 消费者业务处理完成,但在 ACK 发送前宕机或断网 | 消息未确认,被 RabbitMQ 再次推送,导致重复消费 | 消费者故障、容器崩溃、网络断开 |
✅ Redis实现消息幂等性的通用方案说明(解决方式千千万,具体看自己项目):
为了解决消息重复投递与重复消费的问题,我采用了的是基于Redis的幂等性控制策略,核心思路是为每条消息设置一个全局唯一标识(如业务拼接生成的唯一ID或UUID),并结合缓存状态实现幂等校验。具体如下:
- 生产者端处理逻辑: 在生产者投递消息前,首先将该消息的唯一标识写入Redis,并设置一个合理的过期时间。这个过期时间的作用是用于清理历史缓存记录,防止内存冗余,同时在一定时间窗口内避免重复投递。如果消息投递成功,则不需要手动删除该缓存项,等待其自动过期即可;如果投递失败,则需主动删除该缓存键,以便下次重试时能重新标记。
- 消费者端处理逻辑: 消费者在接收到消息后,首先检查 Redis 中是否存在该唯一标识。如果标识不存在,说明是首次消费,则执行业务逻辑,并立即将该标识写入 Redis 表示"已处理"状态,同时设置相同的过期时间;如果标识已存在,则说明该消息已被处理或正在处理,直接跳过以防止重复消费操作。若业务处理过程中发生异常,需删除 Redis 中的该标识键,以允许后续重新处理。
- 过期时间的设计说明: Redis 缓存键的过期时间应根据业务实际情况(如消息投递频率、消息生命周期)设置,通常为几分钟至几小时不等。其作用既是防止缓存堆积,也是避免历史重复消息误拦截新请求。
 📝案例代码目录:
📝案例代码目录:
java
./main/
├── java
│ └── cn
│ └── ant
│ ├── config
│ │ ├── RabbitMQConfig.java // 交换机和队列的创建和绑定关系
│ │ └── RabbitMQMyCallBack.java // 关于发布确认的回调方法编写
│ ├── controller
│ │ └── TestController.java // 接收前端发送的任务消息
│ ├── entity
│ │ └── MessageSendDTO.java // 消息封装类
│ ├── IdempotentConsumerApplication.java
│ └── mqHandle
│ ├── ProducerSend.java // 消息生产者
│ └── QueueConsumer.java // 普通消费者
└── resources
├── application.yml
└── log4j2.xml点开查看详情:关于生产者的幂等性处理
java
@Slf4j
@Component
@RequiredArgsConstructor
public class ProducerSend {
// 注入rabbitTemplate对象
private final RabbitTemplate rabbitTemplate;
// 注入StringRedisTemplate对象
private final StringRedisTemplate redisTemplate;
/***
* 生产者方法
* @param msg 需要投递的消息
*/
public void producerSendMsg(MessageSendDTO msg) {
// Redis Key
String key = "rabbit:confirm:order:" + msg.getMsgID();
// redis的键值操作对象
ValueOperations<String, String> forValue = redisTemplate.opsForValue();
try {
// 防止重复提交
// 若设置成功则为True,设置不成功或者设置的值已经存在则返回False
// 这里设置20秒代表自动过期,
// 一旦设置这个键值,消息被成功投递则不删除(防止20秒内重复提交),但是投递失败
// 以后我需要删除这个键值,方便下次继续设置投递;;具体按照实际设置过期时间
Boolean deliver = forValue.setIfAbsent(key, String.valueOf(msg.getMsgID()),
20, TimeUnit.SECONDS);
// 判断设置成功则发送消息(否则这个消息可能多次发送给消费者)
if (Boolean.TRUE.equals(deliver)) {
// 延迟测试(假设投递花了5秒),可以看到重复的问题演示
Thread.sleep(5000);
// 消息转换为JSON格式并转为字节数组
byte[] bytes = JSONObject.toJSONString(msg).getBytes(StandardCharsets.UTF_8);
// 设置回退的相关信息,并设置回调信息
//(里面包含交换机和路由key,方便后面在回调的时候重新投递)
CorrelationData cd = new CorrelationData();
cd.setReturned(new ReturnedMessage(new Message(bytes), 0, null,
RabbitMQConfig.ORDINARY_DIRECT_EXCHANGE, RabbitMQConfig.ROUTE_KEY));
// 发送消息
rabbitTemplate.convertAndSend(RabbitMQConfig.ORDINARY_DIRECT_EXCHANGE,
RabbitMQConfig.ROUTE_KEY, bytes, cd);
} else {
log.info("消息已经由生产者发送投递了,请忽重复投递!");
}
} catch (Exception e) {
// 若生产者投递出现问题则代表投递不成功,删除这次缓存
redisTemplate.delete(key);
}
}
}点开查看详情:关于消费者的幂等性处理
java
@Slf4j
@Component
@RequiredArgsConstructor
public class QueueConsumer {
// 注入StringRedisTemplate对象
private final StringRedisTemplate redisTemplate;
/***
* 消费者(监听队列ordinaryQueue)
* @param msgData 传递的具体消息内容,最好是生产者发送使用什么类型,这里接收就用什么类型
* @param deliveryTag 处理消息的编号,一般在消息确认时要使用
* @param message 这个就类似我们原生的message
* @param channel 这个就类似我们原生的channel
* 关于@RabbitListener:只需要监听队列即可,多个则在{}里面逗号分割;ackMode确认模式
*/
@RabbitListener(queues = {RabbitMQConfig.ORDINARY_QUEUE}, ackMode = "MANUAL")
public void ordinaryQueueConsumption(@Payload String msgData,
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag,
Message message,
Channel channel) throws IOException {
// redis的键值操作对象
ValueOperations<String, String> forValue = redisTemplate.opsForValue();
// 获取到队列消息,因为发送是JSON格式,我们要解析对象格式
// message.getBody():存储消息的具体内容(序列化后的二进制数据)
String msgJsonStr = new String(message.getBody(), StandardCharsets.UTF_8);
MessageSendDTO msg = JSONObject.parseObject(msgJsonStr, MessageSendDTO.class);
// Redis Key
String key = "rabbit:consume:order:" + msg.getMsgID();
try {
// 判断消息有没有被消费过,没有消费过则设置(代表有消费者准备消费了)
Boolean result = forValue.setIfAbsent(key,
String.valueOf(msg.getMsgID()), 1, TimeUnit.DAYS);
// 判断,若设置成功代表可以消费此条消息
if (Boolean.TRUE.equals(result)) {
log.info("A:消息由消费者A消费:{},并消费完成", msg);
// 手动确认,deliveryTag可以通过message.getMessageProperties().getDeliveryTag()拿到
channel.basicAck(deliveryTag, false);
} else {
log.info("消费者当前消费的消息被别的消费者已经消费过了,或者正在消费:{}", msg);
// 重复发送的也得手动确认掉,但是不处理
channel.basicAck(deliveryTag, false);
}
} catch (Exception e) {
// 若消费失败则删除之前的锁定(缓存),下次队列投递给消费者的时候可以继续消费
redisTemplate.delete(key);
}
}
}在实际项目中,为确保消息系统的高可用与可靠性,建议结合多种机制共同保障。例如,虽然基于 Redis 实现的幂等性控制方案可能不是最严谨或最通用的方式,但它在多数业务场景下已具备良好的实用性与扩展性,具有实施成本低、易于集成等优势,相关实现可参考 Gitee 上的开源示例代码。
为了实现整体消息流程的可靠交付,还必须正确配置 RabbitMQ 的消息确认机制(Publisher Confirm)。当消息发布到交换机失败时,需设置回调处理逻辑(如 ConfirmCallback)进行异常捕捉与补偿;同样,交换机投递到队列的过程中也存在返回机制(如 ReturnCallback),用于处理无法路由的消息。但需注意,如果配置了备份交换机(Alternate Exchange),将无法再触发 ReturnCallback,这时应结合备份逻辑做统一监控处理。
在消费者侧,即便实现了幂等性校验机制,也仍需启用消息确认模式(如手动 ACK),确保消费处理成功后再通知 MQ 服务端完成确认。否则在处理异常、断网或服务宕机等场景下,可能会导致重复投递。
综上所述,幂等性控制 + 消息发布确认机制 是保障消息系统稳定性和数据一致性的核心手段,应在系统设计初期予以完整考虑与实施。
还有就是,生产者投递的幂等性Key不要和消费者幂等性的Key一样,推荐使用这种方式来命名Redis的Key信息rabbit:[confirm|consume]:{业务名}:{messageId};否则会出现生产者投递了,但Key没到过期时间,在消费者设置Key时发现有了,那消费者会认为他已经消费了这条消息。
三:优先级队列
队列通常遵循 先进先出(FIFO)的消费顺序,即后投递的消息需等待前面消息被消费后才能处理。 但在实际业务中,常会遇到生产者投递速度远快于消费者处理速度的情况,导致队列中积压大量消息。如果此时有一条需紧急处理的高优先级消息被投递,它也会被阻塞在队列尾部,必须等待前面的消息依次消费完毕后才能处理,显然无法满足实时性要求。为解决此类问题,RabbitMQ提供了消息优先级队列(Priority Queue)机制,允许为不同消息设置优先级,从而实现高优先级消息优先出队并被消费,提升关键任务的响应速度和系统的灵活性。
🔊需要修改的代码片段:
java
// RabbitMQConfig配置类修改:
/**
* 创建一个具备优先级支持的持久化队列。
* 此队列允许消费者根据消息设置的优先级(priority)顺序进行消费。
*
* RabbitMQ 官方支持的优先级范围是 0~255。
* 实际项目中建议使用 0~10 范围,优先级越高,越早被消费。
*
* ⚠️ 注意:
* - 如果消息没有设置优先级,默认优先级为 0。
* - 优先级设置过大,会造成调度开销增加,建议控制在合理范围内。
* - 不是所有消息都应设置为高优先级,避免"优先级失效"。
*
* @return 创建后的优先级队列对象 Queue
*/
@Bean(value = "priorityQueueName")
public Queue createPriorityQueueName() {
// 定义优先级队列的参数
Map<String, Object> args = new HashMap<>();
// 设置队列支持的最大优先级(官方支持 0~255,这里设置为 10)
// 设置过大可能导致 RabbitMQ 内部排序耗费较多资源(性能问题)
args.put("x-max-priority", 10);
// 构建一个持久化(durable=true)、非独占(exclusive=false)、不自动删除的队列
// 设置了 x-max-priority 参数以支持消息优先级
return QueueBuilder
.durable(PRIORITY_QUEUE_NAME) // 队列名为 PRIORITY_QUEUE_NAME(应为常量)
.withArguments(args) // 设置参数
.build(); // 构建队列
}
java
// 生产者代码修改:
/**
* 向优先级队列发送消息。
* 其中第1005条消息被设定为优先级较高(priority=5),其余消息默认为priority=0。
*
* @param msg 消息数据实体(会被序列化为JSON字符串)
*/
public void sendMessage(MessageSendDTO msg) {
// 模拟发送10条消息(从1001到1010)
for (int i = 1001; i <= 1010; i++) {
msg.setMsgID(i); // 设置消息唯一编号
// 将消息对象转为 JSON 字节数组
byte[] bytes = JSONObject.toJSONString(msg).getBytes(StandardCharsets.UTF_8);
// 让第1005条消息拥有更高的优先级(优先被消费者处理)
if (i == 1005) {
// 创建消息属性对象,设置优先级
MessageProperties messageProperties = new MessageProperties();
messageProperties.setPriority(5); // 优先级范围通常为 0 ~ 10(必须与队列配置一致)
// 构造完整的消息对象(包含内容和属性)
Message message = new Message(bytes, messageProperties);
// 发送到指定交换机和路由键
rabbitTemplate.convertAndSend(
RabbitMQConfig.PRIORITY_DIRECT_EXCHANGE,RabbitMQConfig.PRIORITY_KEY,
message);
} else {
// 普通消息(无优先级,默认为0)
rabbitTemplate.convertAndSend(
RabbitMQConfig.PRIORITY_DIRECT_EXCHANGE,RabbitMQConfig.PRIORITY_KEY,
bytes);
}
}👀测试程序代码(具体代码请参考开头给出的Gitee代码):
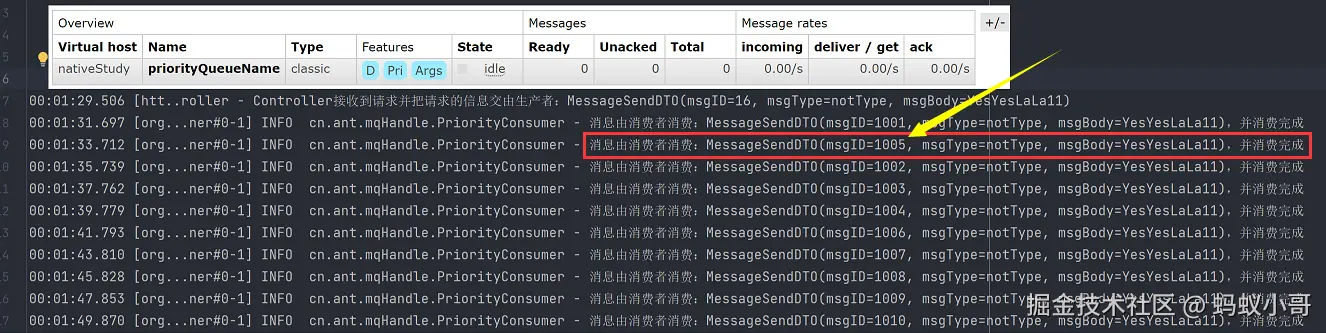
我们需要注意的是RabbitMQ的优先级队列并不是一种严格意义上的"优先级抢占式调度"。其核心机制是在先进先出的基础上进行优先级排序。首先,优先级机制 只有在队列中存在多个待处理消息(即出现消息堆积)的情况下才会生效 ;如果消息一入队就立即被消费,优先级不会起作用。其次,RabbitMQ 默认支持 0 到 255 的优先级范围,但通常推荐设置较小的范围(如 0~10),以避免资源消耗过大。最后,消息在进入队列时是按发送顺序依次存放的,只有在队列中有多个待处理消息时,RabbitMQ 才会根据优先级对它们进行重新排序,从而实现优先处理高优先级消息的效果。
如上图的消费者稍微存在延迟,导致队列中出现消息积压,就会触发RabbitMQ的优先级重排序机制。当消费者消费速度较慢,消息1001到1004陆续进入队列但尚未被消费,随后消息1005也被投递并设置了较高的优先级(如优先级5),此时RabbitMQ发现队列中已有多个待处理消息,就会对这些消息根据优先级进行重新排序。于是,虽然1001是最早入队的消息,但由于已经在队列头部,可能会先被消费;接着,系统会优先处理优先级较高的1005,再继续按顺序消费1002、1003等消息。这个机制确保在消息堆积时,高优先级消息能够尽快得到处理。
注意 :对于重要或时效性强的业务,建议使用独立队列或延迟队列进行拆分处理 ,以实现更好的隔离性和可控性。同时,优先级队列虽然提供消息排序能力,但其调度性能相对较低,不适合作为核心高性能业务的主要调度机制,应谨慎使用。
四:惰性队列
从 RabbitMQ 3.6.0 ~ 3.11.0 中间的版本,官方引入了 惰性队列(Lazy Queue) 的机制。与默认的内存优先型队列不同,惰性队列的核心设计目标是:将尽可能多的消息直接存储到磁盘中,仅在消费者即将消费时才将消息加载进内存 。该机制特别适用于消息堆积严重、消费延迟较长 的业务场景。
在默认配置下,RabbitMQ 会尽可能将消息保留在内存中以提升吞吐性能,即使是标记为持久化的消息,也会在内存中保留副本。这种方式虽然高性能,但在消息量巨大或消费者宕机、下线、维护等场景下,容易导致内存压力剧增。而惰性队列则通过减少内存驻留量,显著降低了内存占用,增强了系统在高堆积压力下的稳定性和扩展性 。它有效避免了消息换页(paging)过程中可能出现的队列阻塞、性能抖动和新消息无法入队等问题。
需要注意的是,惰性队列在牺牲了一定的实时处理性能的同时,换取了更强的可堆积性和资源控制能力,因此适合用于不追求极致实时性但要求高可靠性或容错能力的场景。
java
1️⃣:RabbitMQ支持两种队列模式:default(默认模式)和 lazy(惰性模式)
Ⅰ:默认模式(default)
1.在RabbitMQ 3.6.0版本之前,所有队列默认使用该模式。
2.消息会尽可能存储在内存中,以提升处理速度。
3.不需要额外配置。
Ⅱ:惰性模式(lazy)
1.从3.6.0 ~ 3.11 中间版本引入。
2.消息默认存入磁盘,仅在消费者实际消费时才加载到内存中。
3.优势在于:更高的消息堆积能力、减少内存压力,适用于消费者处理较慢或消息堆积较多的场景。
2️⃣:惰性队列支持以下两种配置方式
Ⅰ:队列声明时设置:
- 原生方式:
使用channel.queueDeclare方法时,设置参数"x-queue-mode"为"lazy":
Map<String, Object> args = new HashMap<>();
args.put("x-queue-mode", "lazy");
channel.queueDeclare("my-lazy-queue", true, false, false, args);
- SpringBoot集成方式:
Map<String, Object> args = new HashMap<>();
args.put("x-queue-mode", "lazy");
QueueBuilder.durable(ORDINARY_QUEUE).withArguments(args).build();
Ⅱ:策略(Policy)方式设置:
可通过RabbitMQ管理控制台或命令行设置队列模式的策略。
若同时设置了声明参数与策略,策略(Policy)优先生效。
比如执行如下命令:
rabbitmqctl set_policy lazy-queue "^lazy-.*" '{"queue-mode":"lazy"}' --apply-to queues
参数说明
lazy-queue 策略名称
^lazy-.* 正则表达式,匹配所有以 lazy- 开头的队列
{"queue-mode":"lazy"} 设置为惰性队列模式
--apply-to queues 表示应用于队列(一):为啥移除惰性队列
RabbitMQ3.12+不再支持惰性队列?
是的!从RabbitMQ3.12开始,官方正式废弃了 x-queue-mode=lazy 参数及相关策略(如 "queue-mode": "lazy")。这意味着:即使你在队列创建时或策略中设置了该参数,RabbitMQ 也会默默忽略它,不会报错,但也不会起作用。 原因是:RabbitMQ 从 3.12 起引入了 统一的内存回收机制(paging system) ,用于替代手动设置的惰性队列逻辑。
RabbitMQ3.12+是如何处理消息堆积的?
| 内存状态 | 行为描述 | 特点 | 适用场景 |
|---|---|---|---|
| ✅ 内存压力较小时 | 队列消息保留在内存中,快速处理 | 高性能、低延迟 | 高吞吐、实时响应场景 |
| ✅ 内存占用上升(超过高水位线) | RabbitMQ 自动将部分消息分页到磁盘(page-out) | 减少内存占用,避免 OOM,无需人工干预 | 消息堆积、慢消费者、突发高峰场景 |
RabbitMQ 3.12+ 采用自动调度和动态分页机制,既保留了小量消息的内存高性能优势,又在内存压力过大时自动落盘,无需手动区分惰性队列,简化配置同时避免因误用x-queue-mode带来的性能与稳定性问题。 关于解决堆积的阈值配置设置说明点这里