系列文章目录
python办公自动化--数据可视化(pandas+matplotlib)--生成条形图和饼状图
python办公自动化--数据可视化(pandas+matplotlib)--生成折线图
python办公自动化--数据可视化(pandas读取excel文件,matplotlib生成可视化图表)
python办公自动化-openpyxl学习-工资表生成工资条
python办公自动化--使用将csv大文件分割为xlsx小文件
python办公自动化----使用pandas和os合并多个订单表
三种方法批量填充订单表中的空白单元格--python,excel vba,excel
python办自动化--批量发送带附件的变量邮件(示例:给员工发送工资条)
文章目录
前言
今天我们来学习使用python读取邮箱中的邮件,并且将里面的附件表格下载到我们本地的文件夹中。
我们这个系列叫做python自动化办公,要实现真正意义上的办公自动化,就是要解放我们的双手,实现全过程的自动化。基本上数据分析的工作分为以下流程:收集数据----清晰整理数据-----分析数据-----发送结果
我们前面学习了使用pandas清洗整理数据(结合我的另一个专栏--python数据分析),学习了python发送带附件的变量邮件(发送结果),至于最精彩最关键的分析数据这个阶段,我们也略微接触了一些,今天我们就好好学习一下python读取邮件。
情景设置:你是公司的数据分析师,每天各个部门的负责人每天八点会将昨天的数据作为附件表格,以"order"和"kucun"作为主题发送到你的邮箱,你需要使用将每天的邮件里面的附件下载到本地的E盘的"附件下载"这个文件夹中。
一、登录邮箱
python
# 导入imaplib库用于IMAP协议邮箱操作
import imaplib
# 邮箱登录用户名
email_user = "youremail"
# 邮箱授权码(非登录密码),用于IMAP协议认证
email_password = "yourpassword"
# IMAP服务器地址,Foxmail使用QQ邮箱的IMAP服务器
imap_server = "imap.qq.com"
mail = imaplib.IMAP4_SSL(imap_server)
# 使用用户名和授权码登录邮箱
mail.login(email_user, email_password)
print("邮箱登录成功")首先我们要在邮箱的设置界面打开我们的smtp/imap/pop3等服务,在这个过程中,我们会获得一个授权码,通过这个授权码,我们就可以将连接到我们的邮箱。我这里登录的是QQ邮箱,所以服务器地址就是"imap.qq.com",那么大家在尝试登录的时候,就要先把上面的用户名,授权码以及邮箱地址改为自己的地址和授权码。
登录成功以后,我们才可以进行下面的操作。
二、记录日志
因为我们读取邮件下载附件这个动作并不是只做一次,所以我们需要设置日志来记录脚本的运行信息。
python
# 导入logging库用于记录日志
import logging
# 导入os库用于文件和目录操作
import os
# 附件下载目录,使用双反斜杠转义
download_folder = "E:\\附件下载"
# 日志系统配置
# ============
logging.basicConfig(
level=logging.DEBUG, # 设置日志级别为DEBUG,记录所有级别日志
format="%(asctime)s - %(levelname)s - %(message)s", # 日志格式: 时间-级别-消息
handlers=[
# 文件处理器,将日志写入到下载目录中的email_downloader.log文件
logging.FileHandler(os.path.join(download_folder, "email_downloader.log")),
# 控制台处理器,将日志输出到标准输出
logging.StreamHandler()
]
)
# 获取当前模块的日志记录器实例
logger = logging.getLogger(__name__)这里我们在E盘新建一个文件夹叫做"附件下载",在这里面我们会新建一个log文件来保存日志
三、搜索解析邮件
python
# 导入email.utils用于邮件日期解析
import email.utils
# 导入email.header用于解码邮件头
import email.header
python
# 选择收件箱文件夹
mail.select("inbox")
python
# 执行IMAP搜索命令
status, messages = mail.search(None, search_criteria)
if status != "OK": # 检查搜索是否成功
raise Exception("邮件搜索失败")
python
# 解析邮件内容为Message对象
email_message = email.message_from_bytes(msg_data[0][1])四、设置搜索条件
python
# 1. FROM 白名单中的任一发件人(使用OR连接)
# 2. SINCE 今天日期
# 3. HAS attachment 必须包含附件
from_clause = " OR ".join([f'FROM "{sender}"' for sender in sender_whitelist])
search_criteria = f'({from_clause} SINCE "{today}" HAS attachment)'
logger.info(f"严格模式: 只处理今天({today})收到的邮件")
logger.info(f"发件人白名单: {sender_whitelist}")
logger.info(f"主题白名单: {subject_whitelist}")
logger.info(f"搜索条件: {search_criteria}")1.前五十封
代码如下(示例):
c
# 获取邮件ID列表并只取最后50个(最新的50封)
mail_ids = messages[0].split()[-50:]
logger.info(f"找到 {len(mail_ids)} 封匹配邮件,只处理最近50封")
# 从最新到最旧处理邮件
for mail_id in reversed(mail_ids):
# 获取邮件完整内容(RFC822格式)
status, msg_data = mail.fetch(mail_id, "(RFC822)")
if status != "OK": # 如果获取失败则跳过
continue通常我们的邮箱每天不会收到太多邮件,50封这个量对于一天来说应该绰绰有余了
2.发件人白名单
python
# 发件人邮箱白名单列表
sender_whitelist = [
"fajianren1@163.com", # 示例邮箱1
"fajianren2@gmail.com", # 示例邮箱2
]
if from_header not in sender_whitelist: # 严格检查白名单
logger.debug(f"跳过非白名单发件人: {from_header}")
continue通常每天给我们发送邮件的人是固定的,我们只需要下载他们发送的邮件里面的附件,因此添加发件人白名单这一个限制条件。
3.邮件主题白名单
python
# 主题白名单列表(精确匹配)
subject_whitelist = [
"order", # 示例主题1
"kucun"
]
subject = email_message['Subject']
if subject not in subject_whitelist: # 严格检查主题白名单
logger.debug(f"跳过非白名单主题: {subject}")
continue有时候这部门负责人给我们发的邮件并不是昨天的销售数据,所以我们要用邮件主题进行区分
这里和上面的发件人白名单是一样的处理逻辑,这里注意两点;1.使用英文作为邮件主题,比如上面的"order"和"kucun";2.注意大小写,这里是严格匹配,所以大小写需要保持一致
4.发件日期为今天
python
# 从datetime导入datetime用于日期时间处理
from datetime import datetime
# 邮件日期验证
# ===========
try:
# 解析邮件日期头
mail_date = email.utils.parsedate_to_datetime(email_message['Date']) if email_message['Date'] else None
if mail_date and mail_date.date() != datetime.now().date(): # 如果不是今天则跳过
logger.debug(f"跳过非今天({mail_date.date()})收到的邮件")
continue这里我们需要设置时间为条件,确保我们每天下载的都是最新的数据,要不然会重复下载前面几天的数据。
五、下载.xlsx附件
python
# 遍历邮件各部分
# =============
for part in email_message.walk(): # 递归遍历邮件所有部分
if part.get_content_maintype() == "multipart": # 跳过multipart容器部分
continue
# 检查是否为.xlsx附件
# ==================
filename = part.get_filename() # 获取附件文件名
content_type = part.get_content_type() # 获取内容类型
# 判断条件:
# 1. 文件名以.xlsx结尾,或
# 2. 内容类型是Excel文件
if (filename and filename.lower().endswith(".xlsx")) or \
(content_type == "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"):
# 处理无文件名的情况
# ================
if not filename: # 如果附件没有文件名
# 使用邮件ID生成唯一文件名
filename = f"attachment_{mail_id.decode()}.xlsx"
# 文件名处理
# =========
# 解码邮件头中的文件名
decoded_name = email.header.decode_header(filename)[0][0]
if isinstance(decoded_name, bytes):
decoded_name = decoded_name.decode('utf-8')
today_str = datetime.now().strftime("%Y%m%d") # 获取当前日期字符串
base_name, ext = os.path.splitext(decoded_name) # 拆分文件名和扩展名
# 生成新文件名格式:YYYYMMDD-原文件名.xlsx
new_filename = f"{today_str}-{base_name}{ext}"
# 拼接完整的文件保存路径
filepath = os.path.join(download_folder, new_filename)
# 附件保存处理
# ===========
if not os.path.exists(filepath): # 检查文件是否已存在
# 以二进制模式保存附件
with open(filepath, "wb") as f:
f.write(part.get_payload(decode=True)) # 解码并写入附件内容
logger.info(f"下载附件: {filename} -> {new_filename}")
else: # 文件已存在则跳过
logger.info(f"附件已存在,跳过: {new_filename}")首先我们根据文件类型筛选出.xlsx格式的附件,然后我们将当天的日期和附件的名字结合在一起,作为新名字,最后我们将附件以新名字命名保存到E盘的'附件下载"这个文件夹中
六、关闭邮箱安全退出
python
# 关闭邮箱连接
# ===========
mail.close() # 关闭当前邮箱文件夹
mail.logout() # 退出IMAP会话
logger.info("处理完成") # 记录处理完成信息
except Exception as e: # 异常处理部分
# 记录错误信息,包含堆栈跟踪
logger.error(f"发生错误: {str(e)}", exc_info=True)
# 确保邮箱连接被正确关闭
if 'mail' in locals() and mail.state != 'LOGOUT': # 检查mail对象是否存在且未退出
try:
mail.logout() # 尝试安全退出
except:
pass # 忽略退出时的任何错误
if __name__ == "__main__":
# 当脚本直接运行时执行主函数
download_specific_attachments() 七.代码整合(可直接使用)
python
# 导入imaplib库用于IMAP协议邮箱操作
import imaplib
# 导入email库用于解析邮件内容
import email
# 导入os库用于文件和目录操作
import os
# 导入logging库用于记录日志
import logging
# 从datetime导入datetime用于日期时间处理
from datetime import datetime
# 导入email.utils用于邮件日期解析
import email.utils
# 导入email.header用于解码邮件头
import email.header
def download_specific_attachments():
"""
下载指定发件人今天发送的邮件中的.xlsx附件
主要功能:
1. 连接IMAP邮箱服务器
2. 搜索指定发件人今天发送的邮件
3. 只处理最近20封邮件
4. 解析邮件内容并识别.xlsx附件
5. 下载附件并按指定格式重命名
6. 记录完整操作日志
"""
# 邮箱服务器配置部分
# ====================
# 邮箱登录用户名
email_user = "youremail"
# 邮箱授权码(非登录密码),用于IMAP协议认证
email_password = "yourpassword"
# IMAP服务器地址,Foxmail使用QQ邮箱的IMAP服务器
imap_server = "imap.qq.com"
# 发件人邮箱白名单列表
sender_whitelist = [
"fajianren1@163.com", # 示例邮箱1
"fajianren2@gmail.com", # 示例邮箱2
]
# 主题白名单列表(精确匹配)
subject_whitelist = [
"order" , # 示例主题1
"kucun"
]
# 附件下载目录,使用双反斜杠转义
download_folder = "E:\\附件下载"
# 日志系统配置
# ============
logging.basicConfig(
level=logging.DEBUG, # 设置日志级别为DEBUG,记录所有级别日志
format="%(asctime)s - %(levelname)s - %(message)s", # 日志格式: 时间-级别-消息
handlers=[
# 文件处理器,将日志写入到下载目录中的email_downloader.log文件
logging.FileHandler(os.path.join(download_folder, "email_downloader.log")),
# 控制台处理器,将日志输出到标准输出
logging.StreamHandler()
]
)
# 获取当前模块的日志记录器实例
logger = logging.getLogger(__name__)
# 创建附件下载目录
# exist_ok=True表示如果目录已存在不会报错
os.makedirs(download_folder, exist_ok=True)
try:
# 邮箱连接和登录部分
# ==================
logger.info("正在连接到IMAP服务器...")
# 创建IMAP4_SSL安全连接对象
mail = imaplib.IMAP4_SSL(imap_server)
# 使用用户名和授权码登录邮箱
mail.login(email_user, email_password)
# 记录登录成功状态
logger.info("登录成功")
# 选择收件箱文件夹
mail.select("inbox")
# 构造IMAP搜索条件
# ===============
# 获取今天的日期,格式化为IMAP要求的格式(如"21-Jul-2025")
today = datetime.now().strftime("%d-%b-%Y")
# 构造IMAP搜索条件:
# 1. FROM 白名单中的任一发件人(使用OR连接)
# 2. SINCE 今天日期
# 3. HAS attachment 必须包含附件
from_clause = " OR ".join([f'FROM "{sender}"' for sender in sender_whitelist])
search_criteria = f'({from_clause} SINCE "{today}" HAS attachment)'
logger.info(f"严格模式: 只处理今天({today})收到的邮件")
logger.info(f"发件人白名单: {sender_whitelist}")
logger.info(f"主题白名单: {subject_whitelist}")
logger.info(f"搜索条件: {search_criteria}")
# 执行IMAP搜索命令
status, messages = mail.search(None, search_criteria)
if status != "OK": # 检查搜索是否成功
raise Exception("邮件搜索失败")
# 处理搜索结果
# =============
# 获取邮件ID列表并只取最后20个(最新的20封)
mail_ids = messages[0].split()[-20:]
logger.info(f"找到 {len(mail_ids)} 封匹配邮件,只处理最近20封")
# 从最新到最旧处理邮件
for mail_id in reversed(mail_ids):
# 获取邮件完整内容(RFC822格式)
status, msg_data = mail.fetch(mail_id, "(RFC822)")
if status != "OK": # 如果获取失败则跳过
continue
# 解析邮件内容为Message对象
email_message = email.message_from_bytes(msg_data[0][1])
# 验证发件人是否在白名单中
# ========================
# 验证邮件主题是否在白名单中,并处理中文汉字主题
# ========================
from_header = email.utils.parseaddr(email_message['From'])[1] # 解析发件人邮箱
if from_header not in sender_whitelist: # 严格检查白名单
logger.debug(f"跳过非白名单发件人: {from_header}")
continue
try:
# 尝试将邮件主题解码为utf-8,处理可能的中文字符问题
subject = email_message['Subject'].encode('latin1').decode('utf-8')
except UnicodeDecodeError:
# 如果解码失败,则记录日志并跳过该邮件
logger.warning("邮件主题编码问题,跳过该邮件")
continue
if subject not in subject_whitelist: # 严格检查主题白名单
logger.debug(f"跳过非白名单主题: {subject}")
continue
# 邮件日期验证
# ===========
try:
# 解析邮件日期头
mail_date = email.utils.parsedate_to_datetime(email_message['Date']) if email_message['Date'] else None
if mail_date and mail_date.date() != datetime.now().date(): # 如果不是今天则跳过
logger.debug(f"跳过非今天({mail_date.date()})收到的邮件")
continue
elif not mail_date: # 如果邮件没有日期信息则默认处理
logger.debug("邮件无日期信息,默认处理")
except Exception as e: # 日期解析错误处理
logger.warning(f"日期解析错误: {str(e)},默认处理")
# 遍历邮件各部分
# =============
for part in email_message.walk(): # 递归遍历邮件所有部分
if part.get_content_maintype() == "multipart": # 跳过multipart容器部分
continue
# 检查是否为.xlsx附件
# ==================
filename = part.get_filename() # 获取附件文件名
content_type = part.get_content_type() # 获取内容类型
# 判断条件:
# 1. 文件名以.xlsx结尾,或
# 2. 内容类型是Excel文件
if (filename and filename.lower().endswith(".xlsx")) or \
(content_type == "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"):
# 处理无文件名的情况
# ================
if not filename: # 如果附件没有文件名
# 使用邮件ID生成唯一文件名
filename = f"attachment_{mail_id.decode()}.xlsx"
# 文件名处理
# =========
# 解码邮件头中的文件名
decoded_name = email.header.decode_header(filename)[0][0]
if isinstance(decoded_name, bytes):
decoded_name = decoded_name.decode('utf-8')
today_str = datetime.now().strftime("%Y%m%d") # 获取当前日期字符串
base_name, ext = os.path.splitext(decoded_name) # 拆分文件名和扩展名
# 生成新文件名格式:YYYYMMDD-原文件名.xlsx
new_filename = f"{today_str}-{base_name}{ext}"
# 拼接完整的文件保存路径
filepath = os.path.join(download_folder, new_filename)
# 附件保存处理
# ===========
if not os.path.exists(filepath): # 检查文件是否已存在
# 以二进制模式保存附件
with open(filepath, "wb") as f:
f.write(part.get_payload(decode=True)) # 解码并写入附件内容
logger.info(f"下载附件: {filename} -> {new_filename}")
else: # 文件已存在则跳过
logger.info(f"附件已存在,跳过: {new_filename}")
# 关闭邮箱连接
# ===========
mail.close() # 关闭当前邮箱文件夹
mail.logout() # 退出IMAP会话
logger.info("处理完成") # 记录处理完成信息
except Exception as e: # 异常处理部分
# 记录错误信息,包含堆栈跟踪
logger.error(f"发生错误: {str(e)}", exc_info=True)
# 确保邮箱连接被正确关闭
if 'mail' in locals() and mail.state != 'LOGOUT': # 检查mail对象是否存在且未退出
try:
mail.logout() # 尝试安全退出
except:
pass # 忽略退出时的任何错误
if __name__ == "__main__":
# 当脚本直接运行时执行主函数
download_specific_attachments() 点击运行后,在我本地的E盘里面的"附件下载"这个文件夹内容如下
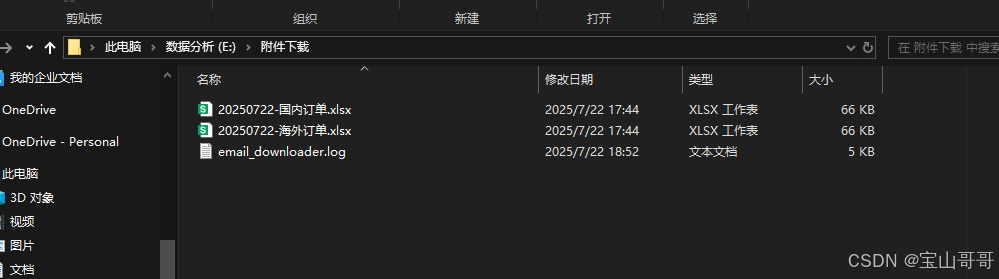
可以看到,成功下载了附件以及生成了log日志
那么大家在使用上面的代码的时候,需要修改的就是邮箱,授权码,以及发件人白名单和邮件主题白名单了。
总结
今天我们学习了用python读取邮箱里面的邮件,并且下载附件到本地,我们还设置了时间、发件人以及邮件主题等多个限制条件。其实这里面可以玩的东西远不止这么多,我大家可以自行去探索。
OK,那么到今天为止,我们就讲完了python发邮件以及收邮件,我们得到了数据源,那么下阶段将正式开始学习python处理数据,当然主要是excel表格的数据,包括一些匹配、聚合等等,当然如果有空也会更新python处理word或者pptx等。
至于下阶段的更新,我会放在python数据分析这个专栏。如果大家对上面的文章有不懂的地方,也可以随时私信我。同样的,如果大家发现哪里不对,也欢迎批评指正哈。
大家有兴趣的可以点个关注以及免费的赞赞哟,爱你们!!