目录
- [Deep Agents](#Deep Agents)
-
- [何时使用 Deep Agents](#何时使用 Deep Agents)
- 核心能力
- 快速开始
-
- [步骤 1:安装依赖](#步骤 1:安装依赖)
- [步骤 2:配置 API Key](#步骤 2:配置 API Key)
- [步骤 3:创建搜索工具](#步骤 3:创建搜索工具)
- [步骤 4:创建 Deep Agent](#步骤 4:创建 Deep Agent)
- [步骤 5:运行代理](#步骤 5:运行代理)
- 发生了什么?
- 核心能力详解
-
- [Agent Harness 能力](#Agent Harness 能力)
-
- 文件系统访问
- [大型工具结果自动转储(Large tool result eviction)](#大型工具结果自动转储(Large tool result eviction))
- [可插拔的存储后端(Pluggable storage backends)](#可插拔的存储后端(Pluggable storage backends))
- [任务委派(子代理 / Subagents)](#任务委派(子代理 / Subagents))
- [会话历史摘要(Conversation history summarization)](#会话历史摘要(Conversation history summarization))
- [悬挂工具调用修复(Dangling tool call repair)](#悬挂工具调用修复(Dangling tool call repair))
- [待办事项列表追踪(To-do list tracking)](#待办事项列表追踪(To-do list tracking))
- 人类参与(Human-in-the-Loop)
- [Prompt 缓存(Anthropic)](#Prompt 缓存(Anthropic))
- 后端(Backends)
-
- [内置后端(Built-in backends)](#内置后端(Built-in backends))
-
- [StateBackend(临时 / Ephemeral)](#StateBackend(临时 / Ephemeral))
- FilesystemBackend(本地磁盘)
- [StoreBackend(LangGraph Store)](#StoreBackend(LangGraph Store))
- [CompositeBackend(路由 / Router)](#CompositeBackend(路由 / Router))
- [指定后端(Specify a backend)](#指定后端(Specify a backend))
- [路由到不同后端(Route to different backends)](#路由到不同后端(Route to different backends))
- [使用虚拟文件系统(Use a virtual filesystem)](#使用虚拟文件系统(Use a virtual filesystem))
- [添加策略钩子(Add policy hooks)](#添加策略钩子(Add policy hooks))
- [协议参考(Protocol reference)](#协议参考(Protocol reference))
- 子代理(Subagents)
-
- [使用子代理(Using SubAgent)](#使用子代理(Using SubAgent))
- [通用子代理(General-purpose subagent)](#通用子代理(General-purpose subagent))
- [最佳实践(Best Practices)](#最佳实践(Best Practices))
- [常见模式(Common patterns)](#常见模式(Common patterns))
- 故障排查(Troubleshooting)
-
- [子代理未被调用(Subagent not being called)](#子代理未被调用(Subagent not being called))
- [上下文仍然膨胀(Context still getting bloated)](#上下文仍然膨胀(Context still getting bloated))
- [选择了错误的子代理(Wrong subagent being selected)](#选择了错误的子代理(Wrong subagent being selected))
- 人工介入(Human-in-the-loop)
-
- [基本配置(Basic configuration)](#基本配置(Basic configuration))
- [决策类型(Decision types)](#决策类型(Decision types))
- [处理中断(Handle interrupts)](#处理中断(Handle interrupts))
- [多个工具调用(Multiple tool calls)](#多个工具调用(Multiple tool calls))
- [编辑工具参数(Edit tool arguments)](#编辑工具参数(Edit tool arguments))
- [子代理的中断(Subagent interrupts)](#子代理的中断(Subagent interrupts))
- [最佳实践(Best practices)](#最佳实践(Best practices))
-
- [始终使用检查点(Always use a checkpointer)](#始终使用检查点(Always use a checkpointer))
- [使用相同的线程 ID(Use the same thread ID)](#使用相同的线程 ID(Use the same thread ID))
- [决策顺序必须与操作顺序一致(Match decision order to actions)](#决策顺序必须与操作顺序一致(Match decision order to actions))
- [根据风险调整配置(Tailor configurations by risk)](#根据风险调整配置(Tailor configurations by risk))
- [长期记忆(Long-term memory)](#长期记忆(Long-term memory))
-
- [跨线程持久化(Cross-thread persistence)](#跨线程持久化(Cross-thread persistence))
- [使用场景(Use cases)](#使用场景(Use cases))
- [存储实现(Store implementations)](#存储实现(Store implementations))
- [最佳实践(Best practices)](#最佳实践(Best practices))
-
- [使用描述性路径(Use descriptive paths)](#使用描述性路径(Use descriptive paths))
- [文档化内存结构(Document the memory structure)](#文档化内存结构(Document the memory structure))
- [清理旧数据(Prune old data)](#清理旧数据(Prune old data))
- [选择合适的存储(Choose the right storage)](#选择合适的存储(Choose the right storage))
- [深度代理中间件(Deep Agents Middleware)](#深度代理中间件(Deep Agents Middleware))
-
- [待办列表中间件(To-do list middleware)](#待办列表中间件(To-do list middleware))
- [文件系统中间件(Filesystem Middleware)](#文件系统中间件(Filesystem Middleware))
-
- [短期 vs 长期文件系统](#短期 vs 长期文件系统)
- [子代理中间件(Subagent Middleware)](#子代理中间件(Subagent Middleware))
- 源码解析
Deep Agents
Deep Agents(deepagents)是一个用于构建智能代理的独立库,专门应对复杂的、多步骤任务。它基于 LangGraph 构建,并受到 Claude Code、Deep Research、Manus 等应用的启发。Deep Agents 内置了任务规划能力、用于上下文管理的文件系统,以及创建子代理的能力。
何时使用 Deep Agents
当你需要的代理具备以下能力时,适合使用 Deep Agents:
- 处理需要规划与任务拆解的复杂、多步骤任务
- 通过文件系统工具管理大量上下文
- 将工作委派给专用子代理,实现上下文隔离
- 在多轮对话和不同线程之间持久化记忆
对于更简单的使用场景,可以考虑使用 LangChain 的 create_agent,或直接构建自定义的 LangGraph 工作流。
Deep Agents 构建在以下组件之上:
- LangGraph:提供底层的图执行机制和状态管理
- LangChain:工具与模型集成可与 Deep Agents 无缝协作
- LangSmith:用于可观测性、评估与部署
Deep Agents 应用可以通过 LangSmith Deployment 进行部署,并使用 LangSmith Observability 进行监控。
核心能力
规划与任务拆解
Deep Agents 内置了 write_todos 工具,使代理能够将复杂任务拆分为离散步骤、跟踪执行进度,并在新信息出现时动态调整计划。
上下文管理
文件系统工具(ls、read_file、write_file、edit_file)允许代理将大量上下文卸载到外部存储中,从而避免上下文窗口溢出,并支持处理长度可变的工具返回结果。
子代理创建
内置的 task 工具支持代理生成专门的子代理,用于实现上下文隔离。这样可以在保持主代理上下文简洁的同时,对特定子任务进行深入处理。
长期记忆
通过 LangGraph 的 Store,可为代理扩展跨线程的持久化记忆能力,使其能够保存并检索来自以往对话的信息。
快速开始
步骤 1:安装依赖
pip
bash
pip install deepagents tavily-pythonuv
bash
uv init
uv add deepagents tavily-python
uv sync步骤 2:配置 API Key
bash
export ANTHROPIC_API_KEY="your-api-key"
export TAVILY_API_KEY="your-tavily-api-key"步骤 3:创建搜索工具
python
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""执行一次网络搜索"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)步骤 4:创建 Deep Agent
python
# 系统提示词:引导代理成为一名专业研究员
research_instructions = """You are an expert researcher. Your job is to conduct thorough research and then write a polished report.
You have access to an internet search tool as your primary means of gathering information.
## `internet_search`
Use this to run an internet search for a given query. You can specify the max number of results to return, the topic, and whether raw content should be included.
"""
agent = create_deep_agent(
tools=[internet_search],
system_prompt=research_instructions
)步骤 5:运行代理
python
result = agent.invoke({"messages": [{"role": "user", "content": "What is langgraph?"}]})
# 打印代理的回复
print(result["messages"][-1].content)发生了什么?
你的 Deep Agent 会自动完成以下事情:
- 规划执行方案 :使用内置的
write_todos工具拆解研究任务 - 开展调研 :调用
internet_search工具收集信息 - 管理上下文 :使用文件系统工具(
write_file、read_file)卸载大量搜索结果,避免上下文溢出 - 创建子代理(如需要):将复杂子任务委派给专用子代理
- 综合生成报告:将研究结果整理为连贯、完整的回答
核心能力详解
Agent Harness 能力
我们可以将 deepagents 视为一种 "Agent Harness(代理执行框架 / 代理承载层)" 。
它与其他 Agent 框架一样,核心仍是同一套工具调用循环,但内置了更丰富的工具和能力。
文件系统访问
Agent Harness 提供了 6 个文件系统操作工具,使文件成为代理环境中的"一等公民":
| 工具 | 说明 |
|---|---|
| ls | 列出目录中的文件及其元数据(大小、修改时间) |
| read_file | 读取文件内容并显示行号,支持 offset / limit 以处理大文件 |
| write_file | 创建新文件 |
| edit_file | 对文件执行精确的字符串替换(支持全局替换模式) |
| glob | 查找匹配模式的文件(例如 **/*.py) |
| grep | 搜索文件内容,支持多种输出模式(仅文件名、带上下文的内容、或计数) |
大型工具结果自动转储(Large tool result eviction)
当工具调用结果过大时,Harness 会自动将其转储到文件系统中,从而防止上下文窗口被占满。
工作机制:
- 监控工具调用结果的大小(默认阈值:20,000 tokens)
- 超过阈值时,将结果写入文件而不是直接放入上下文
- 用一个简要的文件引用替换原始工具结果
- 代理在需要时可再通过读取文件来获取完整内容
可插拔的存储后端(Pluggable storage backends)
Agent Harness 通过一个统一协议抽象了文件系统操作,从而支持针对不同使用场景采用不同的存储策略。
可用后端:
StateBackend ------ 临时内存存储
- 基于内存的临时存储
- 文件保存在代理的 state 中(随对话进行 checkpoint)
- 在同一线程内持久,但不会跨线程保存
- 适用于临时工作文件
FilesystemBackend ------ 真实文件系统
- 直接读写实际磁盘
- 支持虚拟模式(限制在指定根目录内,沙箱化)
- 可集成系统工具(例如使用 ripgrep 实现
grep) - 内置安全机制:路径校验、文件大小限制、防止符号链接攻击
StoreBackend ------ 跨会话持久化存储
- 基于 LangGraph 的
BaseStore实现持久化 - 按
assistant_id进行命名空间隔离 - 文件可在不同对话之间持续存在
- 适用于长期记忆或知识库场景
CompositeBackend ------ 组合后端
-
将不同路径路由到不同存储后端
-
示例:
/→ StateBackend/memories/→ StoreBackend
-
使用最长前缀匹配进行路径路由
-
支持混合存储策略,灵活性最高
任务委派(子代理 / Subagents)
Agent Harness 允许主代理为隔离的多步骤任务创建临时性的"子代理"。
- 上下文隔离:子代理的工作不会污染主代理的上下文
- 并行执行:多个子代理可以同时运行
- 专业化:子代理可以配置不同的工具或参数
- Token 高效:大型子任务的上下文会被压缩为一个最终结果返回
工作机制:
- 主代理内置一个
task工具 - 调用该工具时,会创建一个全新的代理实例,拥有独立上下文
- 子代理会自主执行,直到任务完成
- 最终只向主代理返回一份汇总结果
- 子代理是无状态的(不能多次往返发送消息)
默认子代理:
- 自动提供一个"通用型"子代理
- 默认具备文件系统工具
- 可通过添加额外工具或中间件进行定制
自定义子代理:
- 可定义具备特定工具的专用子代理
- 示例:
code-reviewer、web-researcher、test-runner - 通过
subagents参数进行配置
会话历史摘要(Conversation history summarization)
当 Token 使用量过高时,Agent Harness 会自动压缩较早的对话历史。
配置方式:
- 在 170,000 tokens 时触发
- 保留最近 6 条消息不变
- 更早的消息由模型自动总结
为什么有用:
- 支持超长对话而不触及上下文上限
- 在保留近期上下文的同时压缩"远古"历史
- 对代理透明(表现为一条特殊的 system message)
悬挂工具调用修复(Dangling tool call repair)
当工具调用在返回结果之前被中断或取消时,Harness 会自动修复消息历史。
- 代理请求工具调用:"请运行 X"
- 工具调用被中断(用户取消、执行错误等)
- 消息历史中存在带
tool_call的 AIMessage,但没有对应的 ToolMessage - 这会导致消息序列不合法
解决方案:
- 检测没有返回结果的
tool_call - 构造一个合成的 ToolMessage,标记该调用已取消
- 在代理继续执行前修复消息历史
为什么有用:
- 避免代理因不完整的消息链而产生困惑
- 优雅处理执行中断和异常情况
- 保持对话流程的一致性与连贯性
待办事项列表追踪(To-do list tracking)
Agent Harness 提供了一个 write_todos 工具,供代理维护结构化的任务列表。
- 支持跟踪多个任务及其状态(
pending、in_progress、completed) - 持久化存储在代理的 state 中
- 帮助代理组织复杂的多步骤工作
- 特别适合长期运行任务和规划型场景
人类参与(Human-in-the-Loop)
Agent Harness 可以在指定的工具调用处暂停代理执行,以便人工进行审批或修改。
配置方式:
- 将工具名称映射到中断配置
- 示例:
{"edit_file": True}------ 在每次执行文件编辑前暂停 - 人类可以提供审批信息,或直接修改工具输入参数
为什么有用:
- 为破坏性操作设置安全闸口
- 在高成本 API 调用前进行用户确认
- 支持交互式调试与人工引导
Prompt 缓存(Anthropic)
Agent Harness 支持 Anthropic 的 Prompt Caching 功能,用于减少重复的 token 处理。
- 缓存跨多轮对话中重复出现的提示词片段
- 对于较长的系统提示词,可显著降低延迟和成本
- 对非 Anthropic 模型会自动跳过该机制
为什么有用:
- 系统提示词(尤其包含文件系统说明时)通常会超过 5k+ tokens
- 在没有缓存的情况下,这些内容会在每一轮对话中重复发送
- 启用缓存后,可获得约 10 倍 的性能提升和成本降低
后端(Backends)
为 Deep Agents 选择并配置文件系统后端。你可以将不同路径路由到不同后端、实现虚拟文件系统,并强制执行策略。
Deep Agents 通过 ls、read_file、write_file、edit_file、glob、grep 等工具,向代理暴露一个文件系统接口。这些工具的实际操作都通过**可插拔的后端(backend)**来完成。
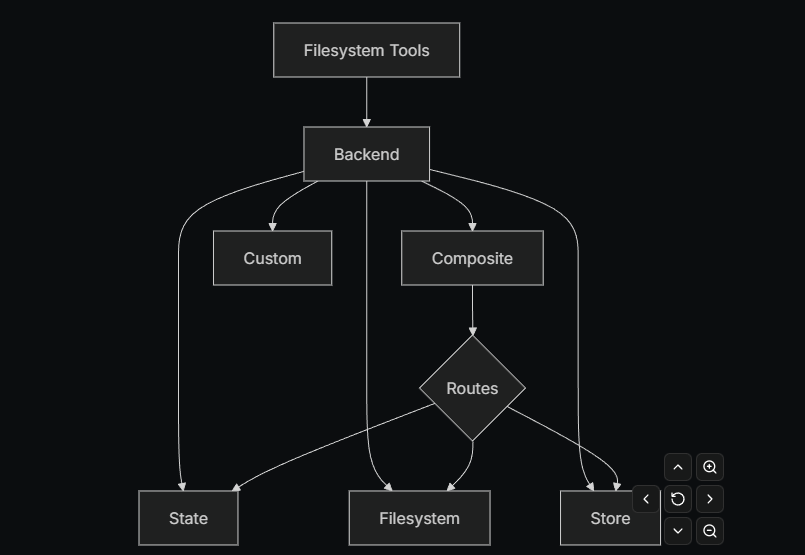
以下是一些内置的文件系统后端,可以快速与 Deep Agent 一起使用:
| 内置后端(Built-in backend) | 说明(Description) |
|---|---|
| Default | agent = create_deep_agent() 默认文件系统后端,存储在 LangGraph 的 state 中。属于临时存储(ephemeral) ,只在单个线程内持久化。 |
| Local filesystem persistence | agent = create_deep_agent(backend=FilesystemBackend(root_dir="/Users/nh/Desktop/")) 允许 Deep Agent 访问本地机器的文件系统。可以指定代理可访问的根目录。注意:root_dir 必须是绝对路径。 |
| Durable store(LangGraph store) | agent = create_deep_agent(backend=lambda rt: StoreBackend(rt)) 为代理提供跨线程持久化的长期存储。非常适合存储长期记忆,或在多次执行中都适用的指令和知识。 |
| Composite | 默认路径为临时存储,/memories/ 路径下的数据会被持久化。Composite 后端具备最高的灵活性,可以将文件系统中的不同路径路由到不同后端。下文提供了可直接使用的路由示例。 |
内置后端(Built-in backends)
StateBackend(临时 / Ephemeral)
python
# 默认情况下提供 StateBackend
agent = create_deep_agent()
# 实际底层等价于
from deepagents.backends import StateBackend
agent = create_deep_agent(
backend=(lambda rt: StateBackend(rt)) # 注意:工具是通过 runtime.state 访问 State
)工作原理
- 将文件存储在 LangGraph 的 agent state 中(仅限当前线程)
- 通过 checkpoint 机制,在同一线程内的多轮 agent 执行中保持持久
适用场景
- 作为代理的临时草稿区,用于写入中间结果
- 自动转储(evict)过大的工具输出,代理随后可以分块再读回这些内容
FilesystemBackend(本地磁盘)
python
from deepagents.backends import FilesystemBackend
agent = create_deep_agent(
backend=FilesystemBackend(root_dir=".", virtual_mode=True)
)工作原理
- 在可配置的
root_dir下读写真实文件 - 可选启用
virtual_mode=True,将路径限制并规范化在root_dir下(沙箱化) - 使用安全的路径解析机制,在可能的情况下防止不安全的符号链接遍历
- 可使用
ripgrep来实现高性能的grep
适用场景
- 本地机器上的项目
- CI 沙箱环境
- 挂载的持久化存储卷
StoreBackend(LangGraph Store)
python
from langgraph.store.memory import InMemoryStore
from deepagents.backends import StoreBackend
agent = create_deep_agent(
backend=(lambda rt: StoreBackend(rt)), # 注意:工具是通过 runtime.store 访问 Store
store=InMemoryStore()
)工作原理
- 将文件存储在运行时提供的 LangGraph BaseStore 中
- 支持跨线程的持久化存储
适用场景
- 你已经在使用配置好的 LangGraph Store(例如 Redis、Postgres,或其他基于 BaseStore 的云实现)
- 通过 LangSmith Deployment 部署代理(系统会自动为代理提供 Store)
CompositeBackend(路由 / Router)
python
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
composite_backend = lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": StoreBackend(rt),
}
)
agent = create_deep_agent(
backend=composite_backend,
store=InMemoryStore() # Store 传给 create_deep_agent,而不是 backend
)工作原理
- 根据路径前缀将文件操作路由到不同的后端
- 在文件列表和搜索结果中保留原始路径前缀
适用场景
-
同时为代理提供临时存储 与跨线程持久化存储(例如同时使用 StateBackend 和 StoreBackend)
-
需要将多个信息源统一呈现为一个文件系统
-
例如:
/memories/下是长期记忆(StoreBackend)/docs/下是自定义后端中的文档数据
-
指定后端(Specify a backend)
通过 create_deep_agent(backend=...) 向 Deep Agent 传入一个后端。文件系统中间件会在所有工具调用中使用该后端。
你可以传入以下两种形式之一:
- 实现了
BackendProtocol的实例
例如:FilesystemBackend(root_dir=".") - 后端工厂(BackendFactory) :
Callable[[ToolRuntime], BackendProtocol]
适用于需要运行时信息的后端(如StateBackend、StoreBackend)
如果省略不传,默认值为:
python
lambda rt: StateBackend(rt)路由到不同后端(Route to different backends)
可以将文件系统命名空间的不同部分路由到不同后端。最常见的用法是:将 /memories/* 持久化,其余路径保持临时(ephemeral)。
python
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, FilesystemBackend
composite_backend = lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": FilesystemBackend(
root_dir="/deepagents/myagent",
virtual_mode=True
),
},
)
agent = create_deep_agent(backend=composite_backend)行为示例
/workspace/plan.md→ StateBackend(临时)/memories/agent.md→ FilesystemBackend (位于/deepagents/myagent下)
ls、glob、grep 会聚合不同后端的结果,并显示原始路径前缀。
注意事项
- 更长的路径前缀优先生效
例如:"/memories/projects/"会覆盖"/memories/" - 如果将路径路由到 StoreBackend ,需要确保 agent 的 runtime 提供了
store(即runtime.store存在)
使用虚拟文件系统(Use a virtual filesystem)
你可以构建一个自定义后端 ,将远程存储或数据库文件系统(如 S3、Postgres)映射到工具可见的文件系统命名空间中。
-
所有路径都是绝对路径 (如
/x/y.txt),需要自行决定如何映射到存储系统中的 key / 行 -
高效实现
ls_info和glob_info:- 能服务端列举就服务端列举
- 否则在本地做过滤
-
对于文件不存在或正则表达式非法等情况,返回用户可读的错误字符串
-
对于外部持久化存储,返回结果中应设置
files_update=None,只有基于 state 的后端才应返回files_update字典
S3 风格示例
python
from deepagents.backends.protocol import BackendProtocol, WriteResult, EditResult
from deepagents.backends.utils import FileInfo, GrepMatch
class S3Backend(BackendProtocol):
def __init__(self, bucket: str, prefix: str = ""):
self.bucket = bucket
self.prefix = prefix.rstrip("/")
def _key(self, path: str) -> str:
return f"{self.prefix}{path}"
def ls_info(self, path: str) -> list[FileInfo]:
# 列出 _key(path) 下的对象;构造 FileInfo(path, size, modified_at)
...
def read(self, file_path: str, offset: int = 0, limit: int = 2000) -> str:
# 获取对象;返回带行号的内容或错误字符串
...
def grep_raw(
self,
pattern: str,
path: str | None = None,
glob: str | None = None
) -> list[GrepMatch] | str:
# 尽量在服务端过滤;否则列举后扫描内容
...
def glob_info(self, pattern: str, path: str = "/") -> list[FileInfo]:
# 在 key 集合上相对 path 应用 glob
...
def write(self, file_path: str, content: str) -> WriteResult:
# 强制"仅创建"语义;返回 WriteResult(path=file_path, files_update=None)
...
def edit(
self,
file_path: str,
old_string: str,
new_string: str,
replace_all: bool = False
) -> EditResult:
# 读取 → 替换(遵守唯一性或 replace_all)→ 写入 → 返回替换次数
...Postgres 风格示例
表结构
sql
files(
path text primary key,
content text,
created_at timestamptz,
modified_at timestamptz
)将工具操作映射到 SQL:
ls_info:使用WHERE path LIKE $1 || '%'glob_info:在 SQL 中过滤,或先拉取再在 Python 中应用 globgrep_raw:可先按扩展名或最近修改时间筛选候选行,再逐行扫描内容
添加策略钩子(Add policy hooks)
可以通过子类化或包装后端来强制执行企业规则,例如禁止在指定路径下写入或编辑文件。
子类化示例(阻止指定前缀下的写入/编辑)
python
from deepagents.backends.filesystem import FilesystemBackend
from deepagents.backends.protocol import WriteResult, EditResult
class GuardedBackend(FilesystemBackend):
def __init__(self, *, deny_prefixes: list[str], **kwargs):
super().__init__(**kwargs)
self.deny_prefixes = [
p if p.endswith("/") else p + "/" for p in deny_prefixes
]
def write(self, file_path: str, content: str) -> WriteResult:
if any(file_path.startswith(p) for p in self.deny_prefixes):
return WriteResult(error=f"Writes are not allowed under {file_path}")
return super().write(file_path, content)
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
if any(file_path.startswith(p) for p in self.deny_prefixes):
return EditResult(error=f"Edits are not allowed under {file_path}")
return super().edit(file_path, old_string, new_string, replace_all)通用包装器示例(适用于任意后端)
python
from deepagents.backends.protocol import BackendProtocol, WriteResult, EditResult
from deepagents.backends.utils import FileInfo, GrepMatch
class PolicyWrapper(BackendProtocol):
def __init__(self, inner: BackendProtocol, deny_prefixes: list[str] | None = None):
self.inner = inner
self.deny_prefixes = [
p if p.endswith("/") else p + "/" for p in (deny_prefixes or [])
]
def _deny(self, path: str) -> bool:
return any(path.startswith(p) for p in self.deny_prefixes)
def ls_info(self, path: str) -> list[FileInfo]:
return self.inner.ls_info(path)
def read(self, file_path: str, offset: int = 0, limit: int = 2000) -> str:
return self.inner.read(file_path, offset=offset, limit=limit)
def grep_raw(self, pattern: str, path: str | None = None, glob: str | None = None) -> list[GrepMatch] | str:
return self.inner.grep_raw(pattern, path, glob)
def glob_info(self, pattern: str, path: str = "/") -> list[FileInfo]:
return self.inner.glob_info(pattern, path)
def write(self, file_path: str, content: str) -> WriteResult:
if self._deny(file_path):
return WriteResult(error=f"Writes are not allowed under {file_path}")
return self.inner.write(file_path, content)
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
if self._deny(file_path):
return EditResult(error=f"Edits are not allowed under {file_path}")
return self.inner.edit(file_path, old_string, new_string, replace_all)协议参考(Protocol reference)
所有后端必须实现 BackendProtocol,并提供以下接口:
| 方法 | 说明 | |
|---|---|---|
ls_info(path: str) -> list[FileInfo] |
返回文件条目,至少包含 path 字段。可选包含 is_dir、size、modified_at。按 path 排序以保证输出确定性。 |
|
read(file_path: str, offset: int = 0, limit: int = 2000) -> str |
返回带行号的内容。文件不存在时返回 "Error: File '/x' not found"。 |
|
| `grep_raw(pattern: str, path: Optionalstr = None, glob: Optionalstr = None) -> listGrepMatch | str` | 返回结构化匹配。正则表达式无效时返回 "Invalid regex pattern: ..." 字符串(不要抛异常)。 |
glob_info(pattern: str, path: str = "/") -> list[FileInfo] |
返回匹配的文件条目(FileInfo 列表),如果没有匹配则返回空列表。 |
|
write(file_path: str, content: str) -> WriteResult |
仅创建(Create-only) 。冲突时返回 WriteResult(error=...)。成功时设置 path;state 后端可设置 files_update={...},外部后端应返回 files_update=None。 |
|
edit(file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult |
强制 old_string 唯一性,除非 replace_all=True。未找到时返回错误。成功时返回 occurrences。 |
支持类型
WriteResult(error, path, files_update)EditResult(error, path, files_update, occurrences)FileInfo:字段包括path(必填),可选is_dir、size、modified_atGrepMatch:字段包括path、line、text
子代理(Subagents)
Deep Agents 可以创建**子代理(subagents)**来委派任务。你可以在 subagents 参数中指定自定义子代理。
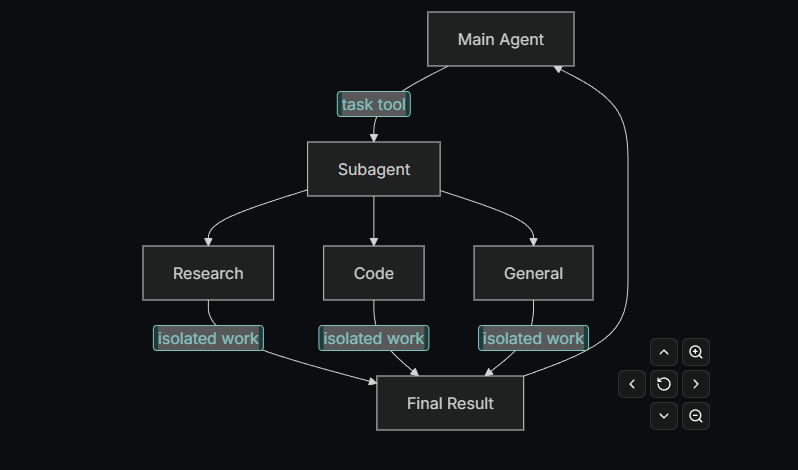
子代理的作用:
- 隔离上下文(context quarantine):保持主代理的上下文干净
- 提供专门指令:为特定任务提供定制化操作
当代理使用输出很大的工具(如网络搜索、文件读取、数据库查询)时,中间结果会迅速填满上下文窗口。
子代理可以将这些详细工作隔离开------主代理只收到最终结果,而不是生成这些结果的所有中间工具调用。
适用场景(何时使用子代理)
✅ 多步任务,否则会污染主代理上下文
✅ 专业领域任务,需要自定义指令或工具
✅ 任务需要不同模型能力
✅ 想让主代理专注于高层协调
不适用场景(何时不使用子代理)
❌ 简单、单步任务
❌ 需要保留中间上下文
❌ 子代理开销大于收益
subagents 应为字典列表 或 CompiledSubAgent 对象,主要有两种类型:
1️⃣ SubAgent(基于字典),大多数情况下使用字典定义子代理。
必填字段:
| 字段 | 类型 | 说明 |
|---|---|---|
name |
str |
子代理的唯一标识,主代理调用 task() 工具时使用 |
description |
str |
子代理执行的任务,需具体且可操作,主代理据此决定何时委派 |
system_prompt |
str |
子代理指令,包括工具使用指南和输出格式要求 |
tools |
List[Callable] |
子代理可用的工具,保持最小化,仅包含必需工具 |
可选字段:
| 字段 | 类型 | 说明 |
|---|---|---|
model |
str 或 BaseChatModel |
覆盖主代理的模型,例如 "openai:gpt-4o" |
middleware |
List[Middleware] |
自定义中间件,可用于行为定制、日志或速率限制 |
interrupt_on |
Dict[str, bool] |
为特定工具配置人类在环(human-in-the-loop),需要 checkpointer 支持 |
2️⃣ CompiledSubAgent(编译型子代理),用于复杂工作流,使用预构建的 LangGraph 图。
字段:
| 字段 | 类型 | 说明 |
|---|---|---|
name |
str |
唯一标识 |
description |
str |
子代理执行的任务 |
runnable |
Runnable |
已编译的 LangGraph 图(必须先调用 .compile()) |
使用子代理(Using SubAgent)
1️⃣ 基于字典的子代理示例
python
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
# 初始化 Tavily 客户端
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
# 定义网络搜索工具
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""执行网络搜索"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
# 定义研究子代理
research_subagent = {
"name": "research-agent",
"description": "用于深入研究问题",
"system_prompt": "You are a great researcher",
"tools": [internet_search],
"model": "openai:gpt-4o", # 可选覆盖,默认为主代理模型
}
subagents = [research_subagent]
# 创建主代理,并指定子代理
agent = create_deep_agent(
model="claude-sonnet-4-5-20250929",
subagents=subagents
)2️⃣ 使用 CompiledSubAgent(编译型子代理)适用于更复杂的工作流,可以提供预先构建好的 LangGraph 图作为子代理:
python
from deepagents import create_deep_agent, CompiledSubAgent
from langchain.agents import create_agent
# 创建自定义代理图
custom_graph = create_agent(
model=your_model,
tools=specialized_tools,
prompt="You are a specialized agent for data analysis..."
)
# 用作自定义子代理
custom_subagent = CompiledSubAgent(
name="data-analyzer",
description="用于复杂数据分析任务的专门代理",
runnable=custom_graph
)
subagents = [custom_subagent]
# 创建主代理
agent = create_deep_agent(
model="claude-sonnet-4-5-20250929",
tools=[internet_search],
system_prompt=research_instructions,
subagents=subagents
)通用子代理(General-purpose subagent)
除了用户定义的子代理外,Deep Agents 始终可以访问一个通用子代理:
- 使用与主代理相同的系统提示
- 访问所有相同工具
- 使用相同模型(除非被覆盖)
通用子代理适合上下文隔离但不需要特殊行为的任务。
例如:主代理需要执行一个复杂的多步任务,但不希望上下文被中间工具调用填满:
text
task(name="general-purpose", task="Research quantum computing trends")- 主代理将任务委派给通用子代理
- 子代理内部执行所有搜索和处理
- 主代理只收到简洁的最终总结,避免中间结果膨胀上下文
核心作用:保持主代理上下文干净,同时完成复杂任务。
最佳实践(Best Practices)
1️⃣ 写清晰的描述(Write clear descriptions)
主代理根据子代理的描述决定调用哪个子代理,因此描述要具体明确:
- ✅ 好的例子 :
"Analyzes financial data and generates investment insights with confidence scores" - ❌ 不好的例子 :
"Does finance stuff"
2️⃣ 保持系统提示详细(Keep system prompts detailed)
子代理的系统提示应包含如何使用工具 和输出格式的具体指导:
python
research_subagent = {
"name": "research-agent",
"description": "Conducts in-depth research using web search and synthesizes findings",
"system_prompt": """You are a thorough researcher. Your job is to:
1. Break down the research question into searchable queries
2. Use internet_search to find relevant information
3. Synthesize findings into a comprehensive but concise summary
4. Cite sources when making claims
Output format:
- Summary (2-3 paragraphs)
- Key findings (bullet points)
- Sources (with URLs)
Keep your response under 500 words to maintain clean context.""",
"tools": [internet_search],
}3️⃣ 最小化工具集(Minimize tool sets)
只给子代理必要的工具,可以提升专注度和安全性:
python
# ✅ 好:聚焦工具集
email_agent = {
"name": "email-sender",
"tools": [send_email, validate_email], # 仅限邮件相关工具
}
# ❌ 不好:工具过多,缺乏聚焦
email_agent = {
"name": "email-sender",
"tools": [send_email, web_search, database_query, file_upload], # 太杂乱
}4️⃣ 根据任务选择模型(Choose models by task)
不同模型适合不同任务:
python
subagents = [
{
"name": "contract-reviewer",
"description": "Reviews legal documents and contracts",
"system_prompt": "You are an expert legal reviewer...",
"tools": [read_document, analyze_contract],
"model": "claude-sonnet-4-5-20250929", # 大上下文,适合长文档
},
{
"name": "financial-analyst",
"description": "Analyzes financial data and market trends",
"system_prompt": "You are an expert financial analyst...",
"tools": [get_stock_price, analyze_fundamentals],
"model": "openai:gpt-5", # 数字分析更强
},
]5️⃣ 返回简明结果(Return concise results)
指示子代理返回摘要而非原始数据:
python
data_analyst = {
"system_prompt": """Analyze the data and return:
1. Key insights (3-5 bullet points)
2. Overall confidence score
3. Recommended next actions
Do NOT include:
- Raw data
- Intermediate calculations
- Detailed tool outputs
Keep response under 300 words."""
}核心思路:保持输出简洁、可操作,同时避免上下文膨胀。
常见模式(Common patterns)
为不同领域创建专门子代理:
python
from deepagents import create_deep_agent
subagents = [
{
"name": "data-collector",
"description": "从各种来源收集原始数据",
"system_prompt": "收集关于主题的全面数据",
"tools": [web_search, api_call, database_query],
},
{
"name": "data-analyzer",
"description": "分析收集的数据以获取洞见",
"system_prompt": "分析数据并提取关键洞见",
"tools": [statistical_analysis],
},
{
"name": "report-writer",
"description": "根据分析撰写专业报告",
"system_prompt": "将洞见整理成专业报告",
"tools": [format_document],
},
]
agent = create_deep_agent(
model="claude-sonnet-4-5-20250929",
system_prompt="你负责协调数据分析和报告撰写。对专门任务使用子代理。",
subagents=subagents
)工作流程(Workflow):
- 主代理制定高层计划
- 将数据收集任务委派给
data-collector - 将结果交给
data-analyzer分析 - 将分析洞见交给
report-writer撰写报告 - 汇总最终输出
每个子代理都在干净的上下文中,只关注自己的任务。
故障排查(Troubleshooting)
子代理未被调用(Subagent not being called)
问题:主代理尝试自己完成任务,而不是委派
解决方法:
-
使描述更具体
python# ✅ 好 {"name": "research-specialist", "description": "使用网络搜索对特定主题进行深入研究。需要多次搜索以获取详细信息时使用。"} # ❌ 不好 {"name": "helper", "description": "帮忙做一些事"} -
指示主代理委派任务
pythonagent = create_deep_agent( system_prompt="""...你的指令... 重要提示:对于复杂任务,请使用 task() 工具委派给你的子代理。 这样可以保持上下文干净,并提高结果质量。""", subagents=[...] )
上下文仍然膨胀(Context still getting bloated)
问题:即使使用子代理,上下文仍然填满
解决方法:
-
指示子代理返回简明结果
text重要提示:只返回必要的摘要。 不要包含原始数据、中间搜索结果或详细工具输出。 你的回答应少于 500 字。 -
使用文件系统处理大量数据
text当收集大量数据时: 1. 将原始数据保存到 /data/raw_results.txt 2. 处理和分析数据 3. 只返回分析摘要 这样可以保持上下文干净。
选择了错误的子代理(Wrong subagent being selected)
问题:主代理调用了不合适的子代理
解决方法:在描述中清晰区分子代理
python
subagents = [
{
"name": "quick-researcher",
"description": "用于简单、快速的研究问题,1-2 次搜索即可。适用于获取基础事实或定义。",
},
{
"name": "deep-researcher",
"description": "用于复杂、深入的研究,需要多次搜索、综合和分析。适用于撰写全面报告。",
}
]核心原则:描述越具体,主代理选择子代理越精准。
人工介入(Human-in-the-loop)
某些工具操作可能比较敏感,在执行前需要人工批准 。Deep Agents 支持通过 LangGraph 的 interrupt(中断)功能 实现人机协作工作流。你可以使用 interrupt_on 参数配置哪些工具需要人工批准。
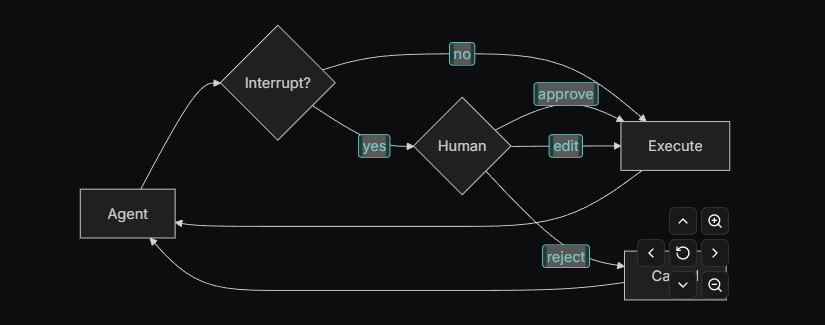
基本配置(Basic configuration)
interrupt_on 参数接收一个字典,将工具名称映射到中断配置。每个工具可以设置为:
True:启用中断,默认行为允许 approve(批准)、edit(编辑)、reject(拒绝)False:禁用该工具的中断{"allowed_decisions": [...]}:自定义允许的决策
python
from langchain.tools import tool
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
# 定义工具
@tool
def delete_file(path: str) -> str:
"""从文件系统删除文件"""
return f"Deleted {path}"
@tool
def read_file(path: str) -> str:
"""读取文件内容"""
return f"Contents of {path}"
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""发送邮件"""
return f"Sent email to {to}"
# 人工介入需要 Checkpointer
checkpointer = MemorySaver()
# 创建深度代理
agent = create_deep_agent(
model="claude-sonnet-4-5-20250929",
tools=[delete_file, read_file, send_email],
interrupt_on={
"delete_file": True, # 默认允许 approve/edit/reject
"read_file": False, # 不需要中断
"send_email": {"allowed_decisions": ["approve", "reject"]}, # 不允许编辑
},
checkpointer=checkpointer # 必须提供
)决策类型(Decision types)
allowed_decisions 列表控制人工在审核工具调用时可以采取的操作:
"approve":使用代理提供的原始参数执行工具"edit":在执行前修改工具参数"reject":完全跳过该工具调用
你可以为每个工具自定义允许的决策:
python
interrupt_on = {
# 高风险操作:允许所有选项
"delete_file": {"allowed_decisions": ["approve", "edit", "reject"]},
# 中等风险:只允许批准或拒绝
"write_file": {"allowed_decisions": ["approve", "reject"]},
# 必须批准(不允许拒绝)
"critical_operation": {"allowed_decisions": ["approve"]},
}处理中断(Handle interrupts)
当触发中断时,代理会暂停执行并返回控制权。你需要检查 __interrupt__ 并按需处理:
python
import uuid
from langgraph.types import Command
# 创建配置(用于状态持久化)
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
# 调用代理
result = agent.invoke({
"messages": [{"role": "user", "content": "Delete the file temp.txt"}]
}, config=config)
# 检查是否被中断
if result.get("__interrupt__"):
interrupts = result["__interrupt__"][0].value
action_requests = interrupts["action_requests"]
review_configs = interrupts["review_configs"]
# 创建工具名称到配置的映射
config_map = {cfg["action_name"]: cfg for cfg in review_configs}
# 展示待处理操作给用户
for action in action_requests:
review_config = config_map[action["name"]]
print(f"Tool: {action['name']}")
print(f"Arguments: {action['args']}")
print(f"Allowed decisions: {review_config['allowed_decisions']}")
# 用户决策(每个 action_request 一个,顺序对应)
decisions = [
{"type": "approve"} # 用户批准删除
]
# 使用用户决策恢复执行
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config # 必须使用相同配置
)
# 处理最终结果
print(result["messages"][-1].content)多个工具调用(Multiple tool calls)
当代理调用多个需要批准的工具时,所有中断会批量返回,必须按顺序提供决策:
python
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
result = agent.invoke({
"messages": [{
"role": "user",
"content": "Delete temp.txt and send an email to admin@example.com"
}]
}, config=config)
if result.get("__interrupt__"):
interrupts = result["__interrupt__"][0].value
action_requests = interrupts["action_requests"]
# 两个工具需要批准
assert len(action_requests) == 2
# 按顺序提供决策
decisions = [
{"type": "approve"}, # 第一个工具 delete_file
{"type": "reject"} # 第二个工具 send_email
]
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config
)编辑工具参数(Edit tool arguments)
当 edit 在允许操作中时,可以修改工具参数:
python
if result.get("__interrupt__"):
interrupts = result["__interrupt__"][0].value
action_request = interrupts["action_requests"][0]
# 原始参数
print(action_request["args"]) # {"to": "everyone@company.com", ...}
# 用户决定修改收件人
decisions = [{
"type": "edit",
"edited_action": {
"name": action_request["name"], # 必须包含工具名称
"args": {"to": "team@company.com", "subject": "...", "body": "..."}
}
}]
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config
)子代理的中断(Subagent interrupts)
每个子代理可以有自己的 interrupt_on 配置,覆盖主代理设置:
python
agent = create_deep_agent(
tools=[delete_file, read_file],
interrupt_on={
"delete_file": True,
"read_file": False,
},
subagents=[{
"name": "file-manager",
"description": "管理文件操作",
"system_prompt": "你是文件管理助手。",
"tools": [delete_file, read_file],
"interrupt_on": {
"delete_file": True,
"read_file": True, # 与主代理不同
}
}],
checkpointer=checkpointer
)当子代理触发中断时,处理方式与主代理相同 ------ 检查
__interrupt__并使用Command(resume=...)恢复执行。
最佳实践(Best practices)
始终使用检查点(Always use a checkpointer)
Human-in-the-loop(HITL)需要检查点来在中断与恢复之间持久化代理状态:
python
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
agent = create_deep_agent(
tools=[...],
interrupt_on={...},
checkpointer=checkpointer # HITL 必须
)使用相同的线程 ID(Use the same thread ID)
在恢复执行时,必须使用相同配置中的相同 thread_id:
python
# 第一次调用
config = {"configurable": {"thread_id": "my-thread"}}
result = agent.invoke(input, config=config)
# 恢复(使用相同 config)
result = agent.invoke(Command(resume={...}), config=config)决策顺序必须与操作顺序一致(Match decision order to actions)
decisions 列表必须与 action_requests 的顺序匹配:
python
if result.get("__interrupt__"):
interrupts = result["__interrupt__"][0].value
action_requests = interrupts["action_requests"]
# 为每个 action 创建决策,保持顺序
decisions = []
for action in action_requests:
decision = get_user_decision(action) # 用户逻辑
decisions.append(decision)
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config
)根据风险调整配置(Tailor configurations by risk)
根据工具的风险等级配置中断策略:
python
interrupt_on = {
# 高风险:完全控制(approve, edit, reject)
"delete_file": {"allowed_decisions": ["approve", "edit", "reject"]},
"send_email": {"allowed_decisions": ["approve", "edit", "reject"]},
# 中等风险:不允许编辑
"write_file": {"allowed_decisions": ["approve", "reject"]},
# 低风险:不需要中断
"read_file": False,
"list_files": False,
}长期记忆(Long-term memory)
Deep Agents 内置了本地文件系统用于卸载内存。默认情况下,这个文件系统存储在代理状态中,仅对单线程有效------会话结束后文件会丢失。
你可以通过使用 CompositeBackend 将特定路径路由到持久存储,从而扩展深度代理的长期记忆。这允许混合存储:部分文件跨线程持久存在,其他文件仍为短期临时存储。
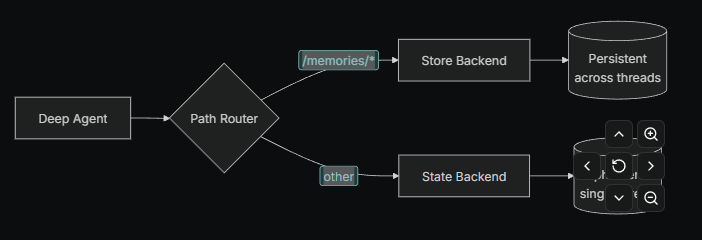
使用 CompositeBackend 将 /memories/ 路径路由到 StoreBackend 来配置长期记忆:
python
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
def make_backend(runtime):
return CompositeBackend(
default=StateBackend(runtime), # 临时存储
routes={
"/memories/": StoreBackend(runtime) # 持久存储
}
)
agent = create_deep_agent(
store=InMemoryStore(), # StoreBackend 必须
backend=make_backend,
checkpointer=checkpointer
)使用 CompositeBackend 时,Deep Agents 会维护两个独立的文件系统:
-
短期(临时)文件系统
- 存储在代理状态中(通过 StateBackend)
- 仅在单线程内有效
- 线程结束后文件丢失
- 访问路径示例:
/notes.txt,/workspace/draft.md
-
长期(持久)文件系统
- 存储在 LangGraph Store 中(通过 StoreBackend)
- 跨线程和会话持久存在
- 代理重启后仍可访问
- 路径前缀为
/memories/,示例:/memories/preferences.txt
CompositeBackend 根据路径前缀决定文件操作的存储位置:
- 以
/memories/开头的文件 → 持久存储 - 无此前缀的文件 → 临时存储
所有文件系统工具(ls、read_file、write_file、edit_file)均可操作两类存储。
示例:
python
# 临时文件(线程结束后丢失)
agent.invoke({
"messages": [{"role": "user", "content": "Write draft to /draft.txt"}]
})
# 持久文件(跨线程保存)
agent.invoke({
"messages": [{"role": "user", "content": "Save final report to /memories/report.txt"}]
})跨线程持久化(Cross-thread persistence)
/memories/ 路径下的文件可以在任意线程访问,实现跨会话持久存储。
示例:
python
import uuid
# 线程 1:写入长期记忆
config1 = {"configurable": {"thread_id": str(uuid.uuid4())}}
agent.invoke({
"messages": [{"role": "user", "content": "Save my preferences to /memories/preferences.txt"}]
}, config=config1)
# 线程 2:从长期记忆读取(不同会话)
config2 = {"configurable": {"thread_id": str(uuid.uuid4())}}
agent.invoke({
"messages": [{"role": "user", "content": "What are my preferences?"}]
}, config=config2)
# 代理可以读取线程 1 中的 /memories/preferences.txt使用场景(Use cases)
-
用户偏好(User preferences)
将用户偏好存储在长期记忆中,以便跨会话使用:
pythonagent = create_deep_agent( store=InMemoryStore(), backend=lambda rt: CompositeBackend( default=StateBackend(rt), routes={"/memories/": StoreBackend(rt)} ), system_prompt=""" When users tell you their preferences, save them to /memories/user_preferences.txt so you remember them in future conversations. """ ) -
自我优化指令(Self-improving instructions)
代理可以根据反馈更新自身指令:
pythonagent = create_deep_agent( store=InMemoryStore(), backend=lambda rt: CompositeBackend( default=StateBackend(rt), routes={"/memories/": StoreBackend(rt)} ), system_prompt=""" You have a file at /memories/instructions.txt with additional instructions and preferences. Read this file at the start of conversations to understand user preferences. When users provide feedback like "please always do X" or "I prefer Y", update /memories/instructions.txt using the edit_file tool. """ )
随着时间推移,指令文件会积累用户偏好,帮助代理不断改进。
-
知识库(Knowledge base)
在多次会话中积累知识:
python# 会话 1:学习项目 agent.invoke({ "messages": [{"role": "user", "content": "We're building a web app with React. Save project notes."}] }) # 会话 2:使用之前的知识 agent.invoke({ "messages": [{"role": "user", "content": "What framework are we using?"}] }) # 代理会读取前一次会话中的 /memories/project_notes.txt -
科研项目(Research projects)
在多个会话中保持研究状态:
pythonresearch_agent = create_deep_agent( store=InMemoryStore(), backend=lambda rt: CompositeBackend( default=StateBackend(rt), routes={"/memories/": StoreBackend(rt)} ), system_prompt=""" You are a research assistant. Save your research progress to /memories/research/: - /memories/research/sources.txt - List of sources found - /memories/research/notes.txt - Key findings and notes - /memories/research/report.md - Final report draft This allows research to continue across multiple sessions. """ )
存储实现(Store implementations)
-
InMemoryStore(开发环境)
适合测试和开发,重启后数据丢失:
pythonfrom langgraph.store.memory import InMemoryStore store = InMemoryStore() agent = create_deep_agent( store=store, backend=lambda rt: CompositeBackend( default=StateBackend(rt), routes={"/memories/": StoreBackend(rt)} ) ) -
PostgresStore(生产环境)
适合生产环境,提供持久存储:
pythonfrom langgraph.store.postgres import PostgresStore import os # 使用 PostgresStore.from_conn_string 作为上下文管理器 store_ctx = PostgresStore.from_conn_string(os.environ["DATABASE_URL"]) store = store_ctx.__enter__() store.setup() agent = create_deep_agent( store=store, backend=lambda rt: CompositeBackend( default=StateBackend(rt), routes={"/memories/": StoreBackend(rt)} ) )
最佳实践(Best practices)
使用描述性路径(Use descriptive paths)
使用清晰、有组织的路径管理持久化文件:
/memories/user_preferences.txt
/memories/research/topic_a/sources.txt
/memories/research/topic_a/notes.txt
/memories/project/requirements.md文档化内存结构(Document the memory structure)
在系统提示中告诉代理每类信息存储的位置:
Your persistent memory structure:
- /memories/preferences.txt: 用户偏好和设置
- /memories/context/: 用户的长期上下文
- /memories/knowledge/: 随时间积累的事实和知识清理旧数据(Prune old data)
定期清理过期的持久化文件,保持存储可管理性。
选择合适的存储(Choose the right storage)
- 开发环境 :使用
InMemoryStore快速迭代 - 生产环境 :使用
PostgresStore或其他持久化存储 - 多租户 :考虑在存储中使用
assistant_id进行命名空间隔离
深度代理中间件(Deep Agents Middleware)
深度代理(Deep Agents)采用模块化中间件架构构建,提供以下功能:
- 规划工具(Planning tool)
- 用于存储上下文和长期记忆的文件系统(Filesystem)
- 生成子代理的能力(Spawn subagents)
每个功能都通过独立的中间件实现。当你使用 create_deep_agent 创建深度代理时,系统会自动为代理附加以下中间件:
TodoListMiddleware(待办列表中间件)FilesystemMiddleware(文件系统中间件)SubAgentMiddleware(子代理中间件)
中间件是可组合的------你可以根据需要为代理添加任意数量的中间件,也可以单独使用任何中间件。
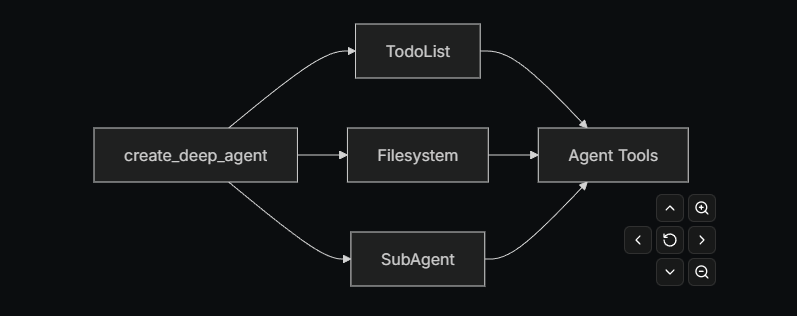
待办列表中间件(To-do list middleware)
规划是解决复杂问题的核心。如果你最近使用过 Claude Code,会发现它在处理复杂多步骤任务前会先写出待办列表(to-do list),并能根据新信息动态更新列表。
TodoListMiddleware 为代理提供了一个专门用于更新待办列表的工具。在执行多步骤任务前及执行过程中,代理会使用 write_todos 工具记录自己已经完成的工作和仍需完成的任务。
python
from langchain.agents import create_agent
from langchain.agents.middleware import TodoListMiddleware
# TodoListMiddleware 默认包含在 create_deep_agent 中
# 如果构建自定义代理,可自行配置
agent = create_agent(
model="claude-sonnet-4-5-20250929",
# 可以通过 middleware 添加自定义规划指令
middleware=[
TodoListMiddleware(
system_prompt="Use the write_todos tool to..." # 可选:对系统提示的自定义补充
),
],
)文件系统中间件(Filesystem Middleware)
上下文管理(Context engineering)是构建高效代理的主要挑战之一。当使用返回可变长度结果的工具(如 web_search 或 RAG)时,长结果会迅速占满上下文窗口,尤其困难。
FilesystemMiddleware 提供了四个工具,用于操作短期和长期记忆:
ls:列出文件系统中的文件read_file:读取整个文件或指定行数write_file:写入新文件edit_file:编辑文件系统中已存在的文件
python
from langchain.agents import create_agent
from deepagents.middleware.filesystem import FilesystemMiddleware
# FilesystemMiddleware 默认包含在 create_deep_agent 中
# 如果构建自定义代理,可自行配置
agent = create_agent(
model="claude-sonnet-4-5-20250929",
middleware=[
FilesystemMiddleware(
backend=None, # 可选:自定义后端(默认使用 StateBackend)
system_prompt="Write to the filesystem when...", # 可选:对系统提示的自定义补充
custom_tool_descriptions={
"ls": "Use the ls tool when...",
"read_file": "Use the read_file tool to..."
} # 可选:为文件系统工具提供自定义描述
),
],
)短期 vs 长期文件系统
默认情况下,这些工具会写入图状态中的本地"文件系统"。
如果想在不同线程间实现持久存储,可以配置 CompositeBackend ,将特定路径(例如 /memories/)路由到 StoreBackend。
python
from langchain.agents import create_agent
from deepagents.middleware import FilesystemMiddleware
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
agent = create_agent(
model="claude-sonnet-4-5-20250929",
store=store,
middleware=[
FilesystemMiddleware(
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
),
custom_tool_descriptions={
"ls": "Use the ls tool when...",
"read_file": "Use the read_file tool to..."
} # 可选:自定义文件系统工具描述
),
],
)配置后,任何以 /memories/ 为前缀的文件会保存到持久存储中,并可在不同线程间访问;没有该前缀的文件仍保存在临时状态存储中。
子代理中间件(Subagent Middleware)
将任务交给子代理(subagents)可以隔离上下文,使主(主管)代理的上下文窗口保持干净,同时仍能深入处理任务。
子代理中间件允许通过 task 工具 提供子代理。
python
from langchain.tools import tool
from langchain.agents import create_agent
from deepagents.middleware.subagents import SubAgentMiddleware
@tool
def get_weather(city: str) -> str:
"""获取城市的天气"""
return f"The weather in {city} is sunny."
agent = create_agent(
model="claude-sonnet-4-5-20250929",
middleware=[
SubAgentMiddleware(
default_model="claude-sonnet-4-5-20250929",
default_tools=[],
subagents=[
{
"name": "weather",
"description": "This subagent can get weather in cities.",
"system_prompt": "Use the get_weather tool to get the weather in a city.",
"tools": [get_weather],
"model": "gpt-4o", # 子代理可以使用自定义模型
"middleware": [], # 可以为子代理添加额外中间件
}
],
)
],
)子代理通过以下属性定义:
- name:子代理唯一名称
- description:描述子代理的功能
- system_prompt:子代理系统指令
- tools:子代理可用工具
此外,你可以为子代理指定自定义模型或额外中间件,这在你希望子代理使用与主代理共享的额外状态键时非常有用。
你可以将自定义的 LangGraph 图作为子代理提供:
python
from langchain.agents import create_agent
from deepagents.middleware.subagents import SubAgentMiddleware
from deepagents import CompiledSubAgent
from langgraph.graph import StateGraph
# 创建自定义 LangGraph 图
def create_weather_graph():
workflow = StateGraph(...)
# 构建自定义图
return workflow.compile()
weather_graph = create_weather_graph()
# 包装为 CompiledSubAgent
weather_subagent = CompiledSubAgent(
name="weather",
description="This subagent can get weather in cities.",
runnable=weather_graph
)
agent = create_agent(
model="claude-sonnet-4-5-20250929",
middleware=[
SubAgentMiddleware(
default_model="claude-sonnet-4-5-20250929",
default_tools=[],
subagents=[weather_subagent],
)
],
)除了用户定义的子代理外,主代理始终可以访问一个 通用子代理(general-purpose subagent):
- 与主代理具有相同的系统指令
- 拥有主代理可用的所有工具
- 主要用于上下文隔离
通用子代理允许主代理将复杂任务委派出去,只返回简洁结果,避免中间工具调用造成的上下文膨胀。
源码解析
create_deep_agent
导入地址:from deepagents import create_deep_agent,create_deep_agent=deep agent middleware+create_agent,该方法仅仅讲符合deepagent思想的一些中间件,如规划,文件系统,子agent,摘要,悬空tool处理...等加入到了内置middleware队列中!
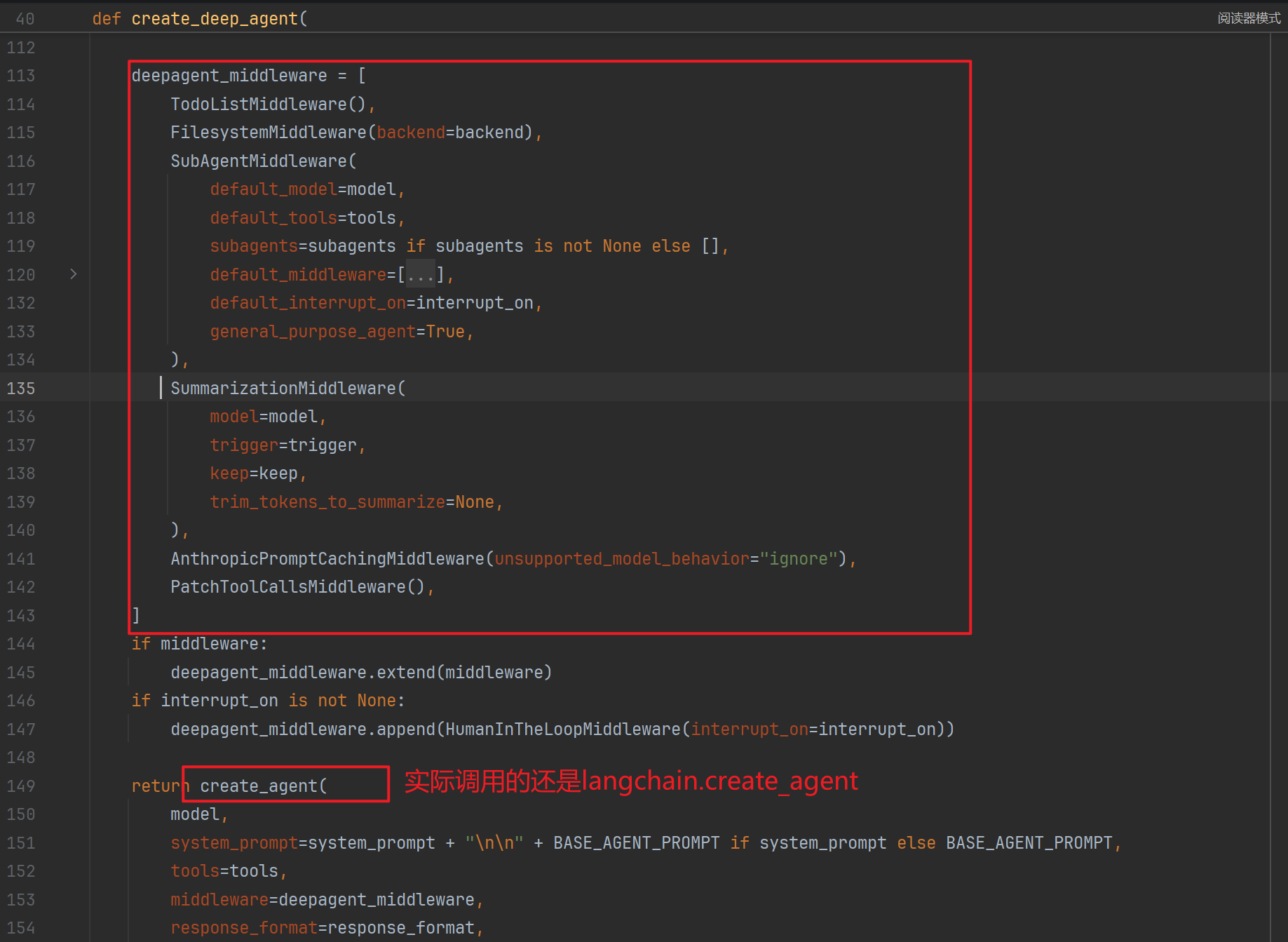
这些中间件类内动态定义了工具:
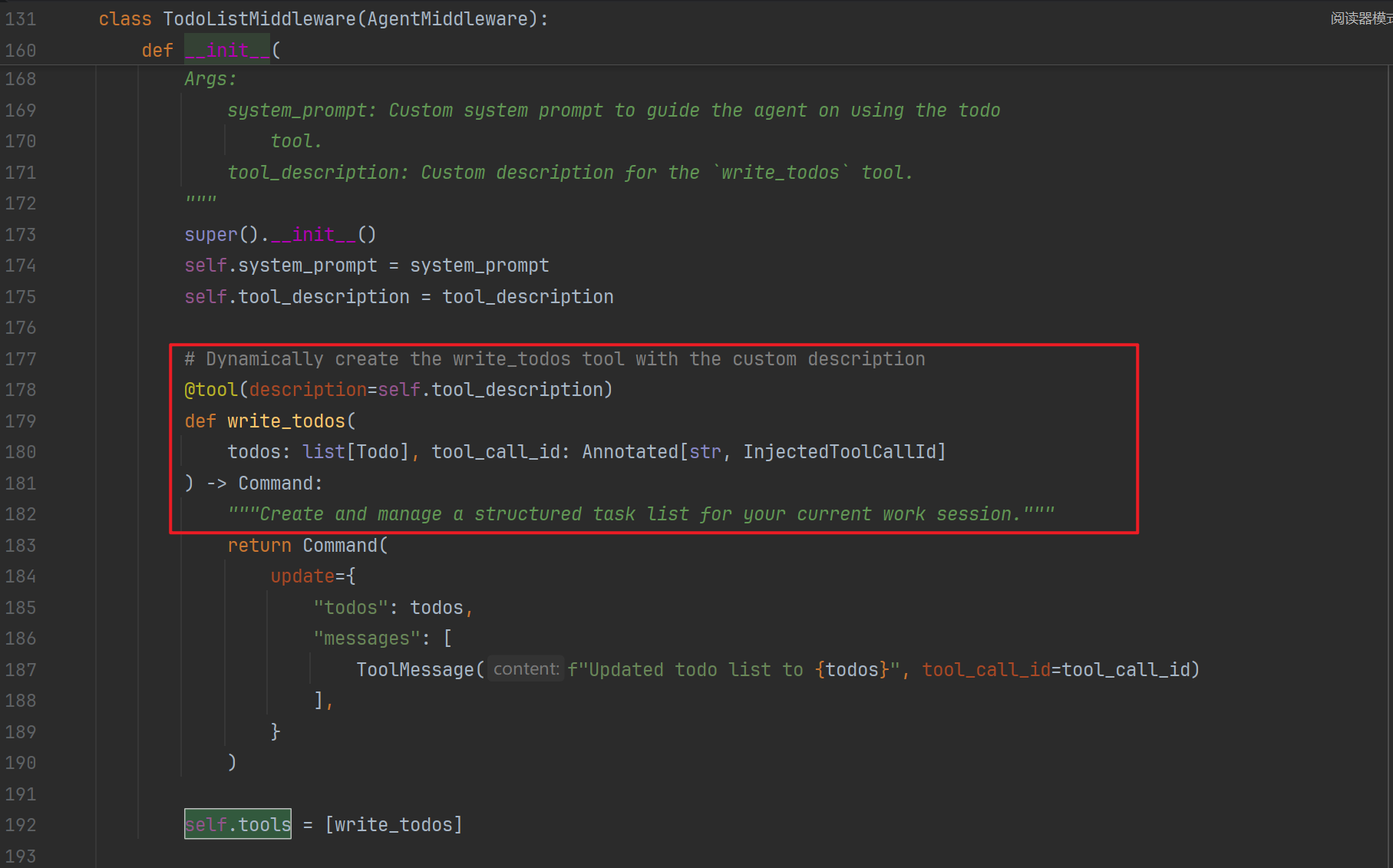
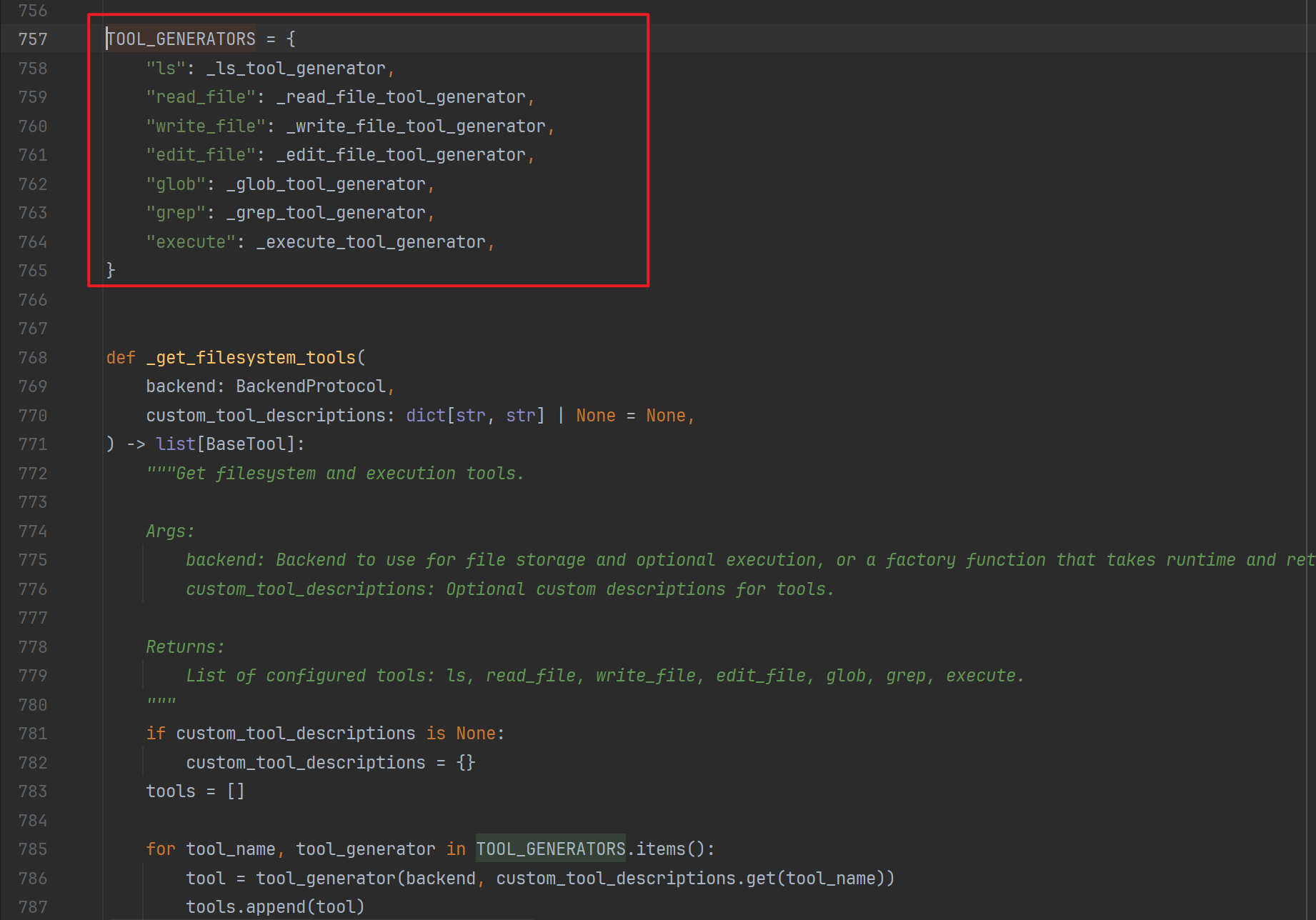
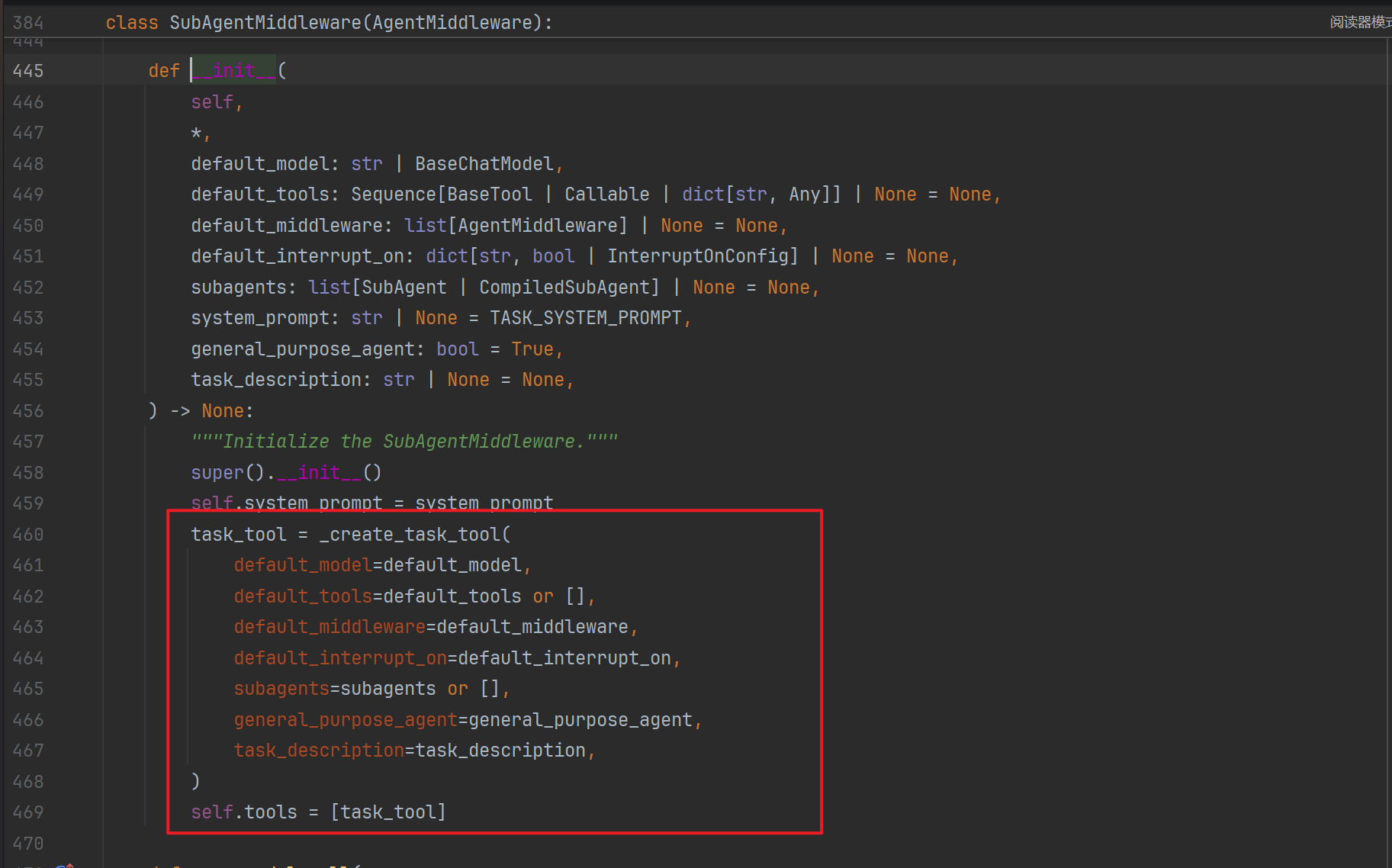
这些工具,在create_agent中会被通过反射注册到model工具列表中:
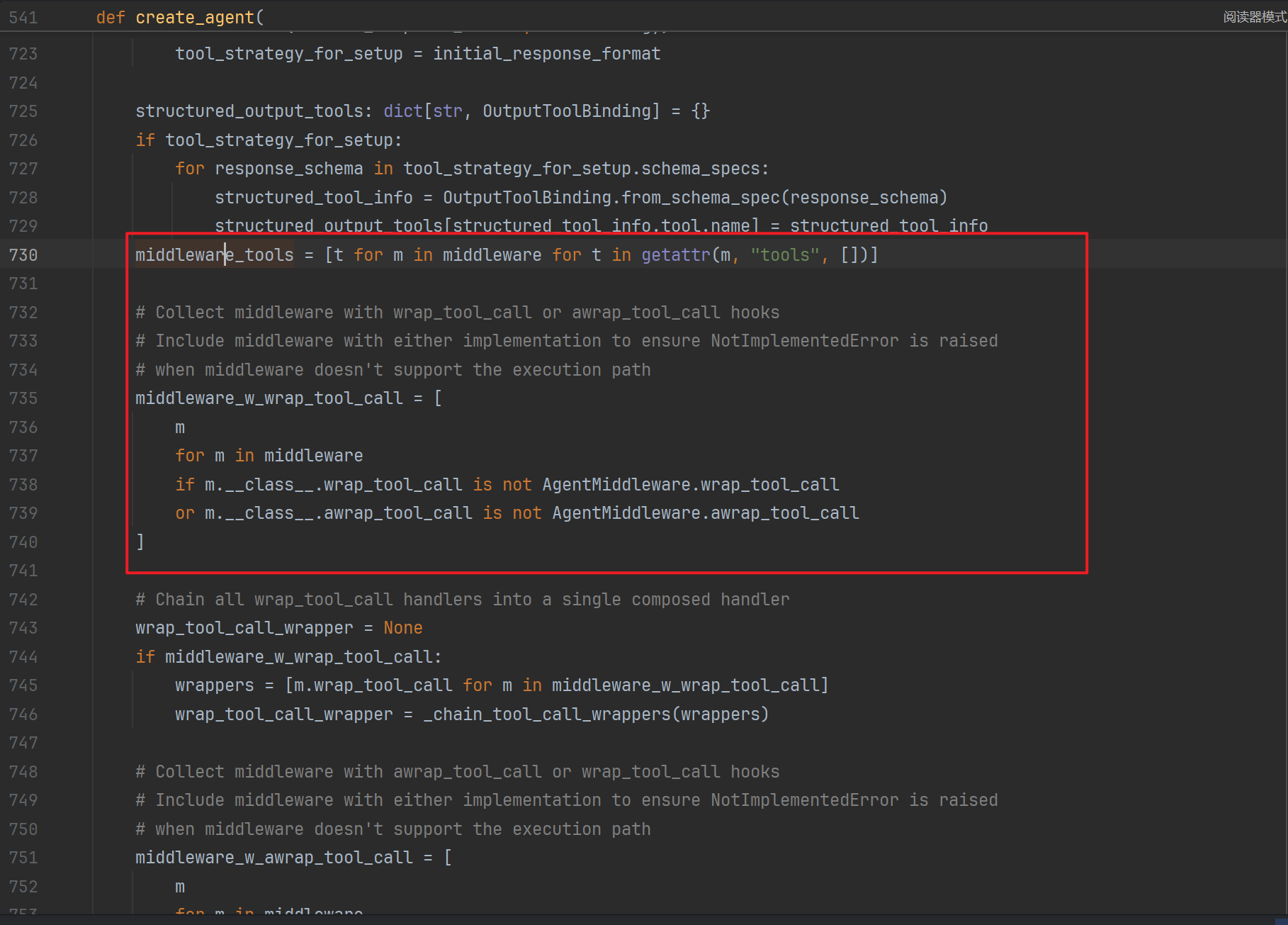
然后agent就有了深度思考的能力。