底层结构
Redis 的字符串对象(OBJ_STRING)底层实现主要有三种方式:
SDS(Simple Dynamic String):大多数字符串用SDS实现,支持二进制安全、动态扩容、空间预分配等特性。
整数编码:如果字符串内容可以表示为 long long 类型的整数,Redis 会直接用整数存储,节省空间和提升效率。
embstr 编码:短字符串(≤44字节)采用 embstr 编码,将 redisObject 和 SDS 一次性分配在一块连续内存中,减少内存碎片和分配次数。
简单动态字符串SDS
我们看一下简单动态字符串SDS的底层结构,源码中定义了多种结构:
java
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 已使用的长度
uint8_t alloc; /* 总分配容量(不包括头部和空终止符) */
unsigned char flags; /* 低3位标识类型 */
char buf[];
};
// ...
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};SDS会根据字符串长度选择不同的结构体,以节省内存。
java
static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5)
return SDS_TYPE_5;
if (string_size < 1<<8)
return SDS_TYPE_8;
if (string_size < 1<<16)
return SDS_TYPE_16;
#if (LONG_MAX == LLONG_MAX)
if (string_size < 1ll<<32)
return SDS_TYPE_32;
return SDS_TYPE_64;
#else
return SDS_TYPE_32;
#endif
}我们看一下创建一个SDS对象的流程:
java
sds _sdsnewlen(const void *init, size_t initlen, int trymalloc) {
sds s;
char type = sdsReqType(initlen); // 根据字符串长度选择类型
int hdrlen = sdsHdrSize(type); // 计算头部长度
unsignedchar *fp; /* flags pointer. */
size_t usable;
// 分配内存
void *sh = trymalloc?
s_trymalloc_usable(hdrlen+initlen+1, &usable) :
s_malloc_usable(hdrlen+initlen+1, &usable);
if (sh == NULL) returnNULL;
if (init==SDS_NOINIT)
init = NULL;
elseif (!init)
memset(sh, 0, hdrlen+initlen+1);
s = (char*)sh+hdrlen;
fp = ((unsignedchar*)s)-1;
usable = usable-hdrlen-1;
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);
switch(type) {
case SDS_TYPE_5: {
// ...
}
case SDS_TYPE_8: {
// ...
}
case SDS_TYPE_16: {
// ...
}
case SDS_TYPE_32: {
// ...
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen; // 已用长度赋值
sh->alloc = usable; // 总分配容量赋值
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen); // 初始值复制
s[initlen] = '\0';
return s;
}那么向一个SDS对像追加一个SDS对象是如何实现的呢?
java
sds sdscatsds(sds s, const sds t) {
return sdscatlen(s, t, sdslen(t));
}
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len); // 确保有足够的空间
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}其中sdsMakeRoomFor函数用于确保sds对象的可用空间,如果可用空间不足,则通过realloc函数进行扩容。
embstr编码
embstr编码是一种用于存储短字符串的编码方式,它将 redisObject 和 SDS 一次性分配在一块连续内存中| redisObject | sdshdr | 字符串内容 |,从而避免了内存碎片和分配次数。
在创建字符串对象时,如果字符串长度小于等于44字节,则使用embstr编码。
java
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
// 申请内存,redisObject和sdshdr8以及字符串存储空间一起分配
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
elseif (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}内存管理与优化
任何数据库内存都是十分宝贵的资源,对于内存数据库尤甚,在Redis中,有非常多针对内存优化的设计,对于字符串类型的设计也是如此:
空间预分配:SDS 会为字符串预留空间,减少频繁 realloc。
惰性空间释放:SDS 支持惰性空间回收,避免频繁收缩内存。
对象共享:对于常用小整数,Redis 采用对象共享池,减少内存分配。
事务与事件通知
每次字符串被修改(如 set、append、incr 等),都会调用 signalModifiedKey 和 notifyKeyspaceEvent,前者用于事务WATCH机制,后者用于事件通知机制。
典型代码流程
这里以SET命令为例。
java
void setCommand(client *c) {
robj *expire = NULL;
int unit = UNIT_SECONDS;
int flags = OBJ_NO_FLAGS;
// 解析各种命令参数,如NX,EX等
if (parseExtendedStringArgumentsOrReply(c,&flags,&unit,&expire,COMMAND_SET) != C_OK) {
return;
}
// 根据字符串长度和内容,选择合适的编码方式
c->argv[2] = tryObjectEncoding(c->argv[2]);
// 执行写入
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}
最终setGenericCommand会调用genericSetKey函数完成写入操作。
void genericSetKey(client *c, redisDb *db, robj *key, robj *val, int keepttl, int signal) {
if (lookupKeyWrite(db,key) == NULL) { // 键是否存在
dbAdd(db,key,val); // 添加键值对
} else {
dbOverwrite(db,key,val); // 覆盖键值对
}
incrRefCount(val); // 增加引用计数
if (!keepttl) removeExpire(db,key); // 删除过期时间
if (signal) signalModifiedKey(c,db,key); // 是否通知键被修改
}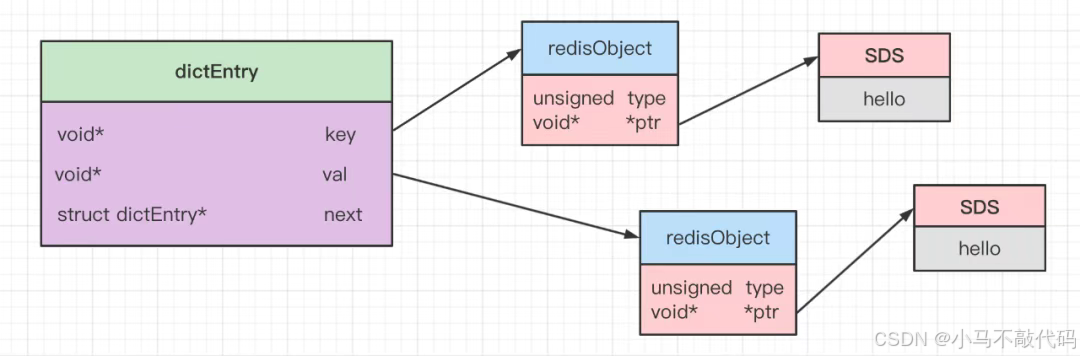
字符串类型底层通过字典dict实现,其key和value都是robj对象,value对象存储了字符串内容。因前面分析过Hash类型的实现,字符串类型其他命令的具体实现这里就不再赘述。