在对某电商项目进行接口性能压测时,发现 /product/search 接口响应缓慢,存在明显性能瓶颈。通过慢查询日志排查和 SQL 优化,最终实现了接口响应速度的显著提升。本文完整还原此次优化过程,特别强调操作步骤和问题分析过程,为后续类似问题提供可复用参考。
一、问题背景
接口地址:
bash
GET /product/search?keyword=手机&pageNum=1&pageSize=10该接口支持关键词模糊搜索和分页查询,是产品列表页的重要入口。
二、JMeter 接口压测
使用 JMeter 进行 50 和 100 并发下的性能测试,结果如下:


| 并发数 | 样本数 | 平均响应时间(ms) | 最小值 | 最大值 | 标准差 | 吞吐量(req/s) |
|---|---|---|---|---|---|---|
| 50 | 50 | 5869 | 2364 | 8465 | 1939 | 5.3 |
| 100 | 100 | 10791 | 2364 | 21543 | 5727 | 6.71 |
接口平均响应时间达到 5~10 秒,明显偏高,响应抖动也较严重。
三、开启 MySQL 慢查询日志
为定位 SQL 性能瓶颈,需先开启 MySQL 的慢查询日志。步骤如下:
1. 登录数据库
、
bash
mysql -uroot -p2. 临时开启慢查询日志(即时生效)
bash
SET GLOBAL slow_query_log = 1;
SET GLOBAL slow_query_log_file = '/var/lib/mysql/mysql-slow.log';
SET GLOBAL long_query_time = 1; -- 超过1秒即记录为慢查询
SET GLOBAL log_queries_not_using_indexes = 1;3. 查看设置是否生效
bash
SHOW VARIABLES LIKE 'slow_query_log%';
SHOW VARIABLES LIKE 'long_query_time';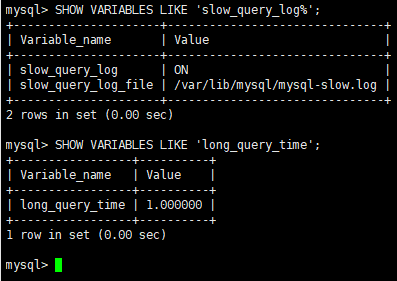
4. 永久配置(推荐)
编辑配置文件 /etc/my.cnf:
bash
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/lib/mysql/mysql-slow.log
long_query_time = 1
log_queries_not_using_indexes = 1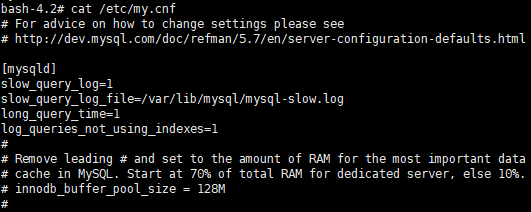
重启 MySQL 生效:
bash
docker restart mysql四、慢 SQL 日志分析
压测执行期间,慢查询日志出现以下记录:
tail -n 50 /var/lib/mysql/mysql-slow.log
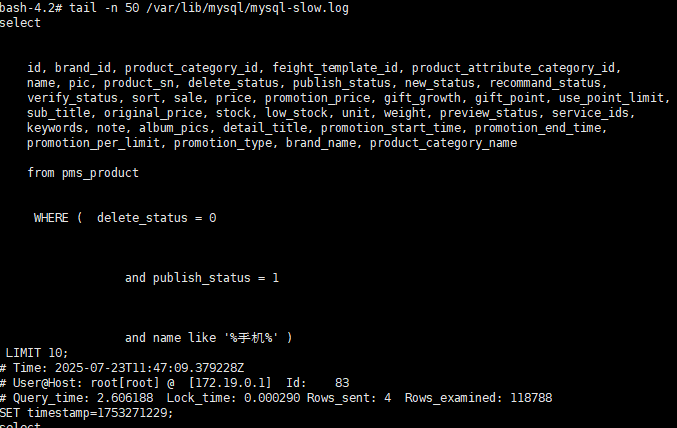
bash
Query_time: 2.606188 Rows_examined: 118788
SELECT id, name, price, ...
FROM pms_product
WHERE delete_status = 0
AND publish_status = 1
AND name LIKE '%手机%'
LIMIT 10;分析结果:
- LIKE '%手机%' 会导致 无法使用索引;
- Rows_examined 超过 11 万,全表扫描严重拖慢性能;
- 查询时间达 2.606188 秒,符合慢 SQL 记录门槛;
- 实际仅返回几行数据,说明检索效率极低。
五、SQL 优化策略
✅ 优化 1:添加联合索引(过滤条件优化)
bash
CREATE INDEX idx_publish_delete ON pms_product (publish_status, delete_status);目标:加速前置过滤条件,缩小扫描范围。
✅ 优化 2:替换模糊搜索模式(条件允许时)
将:
bash
name LIKE '%手机%'替换为前缀匹配:
bash
name LIKE '手机%'并添加索引:
bash
CREATE INDEX idx_name ON pms_product(name);说明:前缀匹配可命中索引,大幅提升查询性能。
✅ 优化 3:MySQL FULLTEXT 索引(英文关键词可用)
bash
ALTER TABLE pms_product ADD FULLTEXT(name);使用:
bash
MATCH(name) AGAINST('手机');注意:MySQL 原生不支持中文分词,适用于英文搜索场景。
✅ 优化 4:引入 Elasticsearch(推荐)
对于中文模糊搜索,应优先考虑引入 Elasticsearch:
- 支持中文分词(如 IK Analyzer);
- 查询速度快,灵活性强;
- 支持高亮、相关度排序、纠错、自动补全等高级搜索功能。
七、总结
🎯 优化流程回顾:
- 压测工具发现接口响应慢
- 开启慢查询日志,定位 SQL 问题
- 分析执行计划,确认未命中索引、全表扫描
- 针对性优化索引和搜索逻辑
- 回归验证优化效果
📌 经验建议:
| 建议 | 说明 |
|---|---|
| 开启慢查询日志 | 持续监控系统中潜在瓶颈 SQL |
| 适当控制模糊查询的使用 | %关键词% 频繁使用时应考虑全文检索方案 |
| 数据量较大时应提前评估查询方式 | 多字段过滤、分页查询要设计好索引策略 |
| 中文搜索建议引入搜索引擎 | 如 Elasticsearch,提升性能和用户体验 |