从文档上传到模型应答,一步步解构知识增强问答系统的底层逻辑。
一、什么是知识库问答(RAG)?
传统大模型在回答专业问题时,常会编造(hallucination) ,因为它的"知识"来自训练语料,而非实时信息。为此,Langchain-Chatchat 构建了知识增强问答系统(RAG) ,通过"文档检索 + 模型生成"组合提升回答的准确性。
RAG 的基本流程是:
graph LR
用户问题 --> 检索相关文档 --> 搭建提示词 --> 输入语言模型 --> 输出更准确回答
二、知识库问答的整体流程图(逻辑视角)
graph TD
文档上传 --> B[文本预处理: 分段/清洗] --> C[向量化: Embedding] --> D[向量索引构建: FAISS等] --> E[知识库建立完成];
E --- 用户提出问题 --> F[查询向量检索: Retriever] --> G[构造提示词: Prompt] --> H[模型回答: LLM] --> 最终输出回答;
本地安装部署 Langchain-Chatchat
- 安装 Langchain-Chatchat
bash
pip install langchain-chatchat -U模型部署框架 Xinference 接入 Langchain-Chatchat 需要额外安装对应的 Python 依赖库,因此如需搭配 Xinference 框架使用时如下安装方式:
bash
pip install "langchain-chatchat[xinference]" -U- 模型推理框架并加载模型
启动 Langchain-Chatchat 项目前,首先进行模型推理框架的运行,并加载所需使用的模型。本文中 Embedding 模型使用 bge-large-zh-v1.5 通过 Xinference 本地运行,LLM 使用 deepseek-chat 在线API。
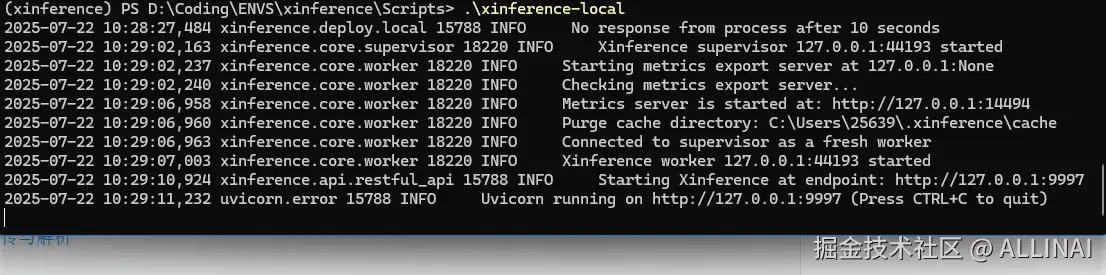
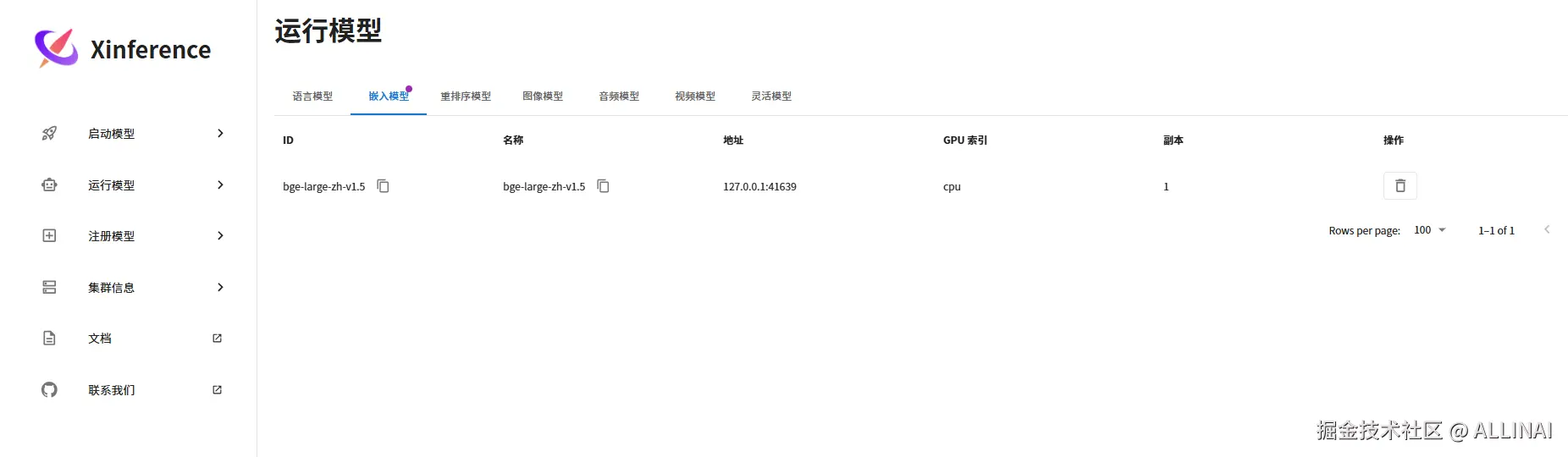
-
初始化项目配置与数据目录
- 设置 Chatchat 存储配置文件和数据文件的根目录(可选):
export CHATCHAT_ROOT=xxx - 执行初始化:
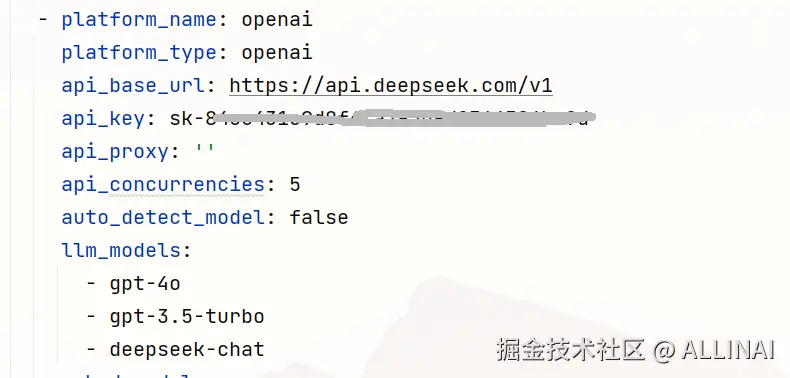
chatchat init - 修改配置文件
- 配置模型(model_settings.yaml)
- 配置知识库路径(basic_settings.yaml)(可选)
- 配置知识库(kb_settings.yaml)(可选)
- 设置 Chatchat 存储配置文件和数据文件的根目录(可选):

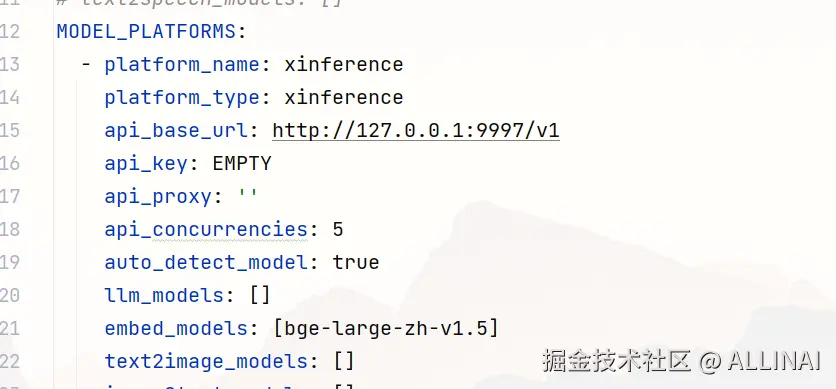
- 初始化知识库
进行知识库初始化前,请确保已经启动模型推理框架及对应 embedding 模型,且已按照上述步骤3完成模型接入配置。
chatchat kb -r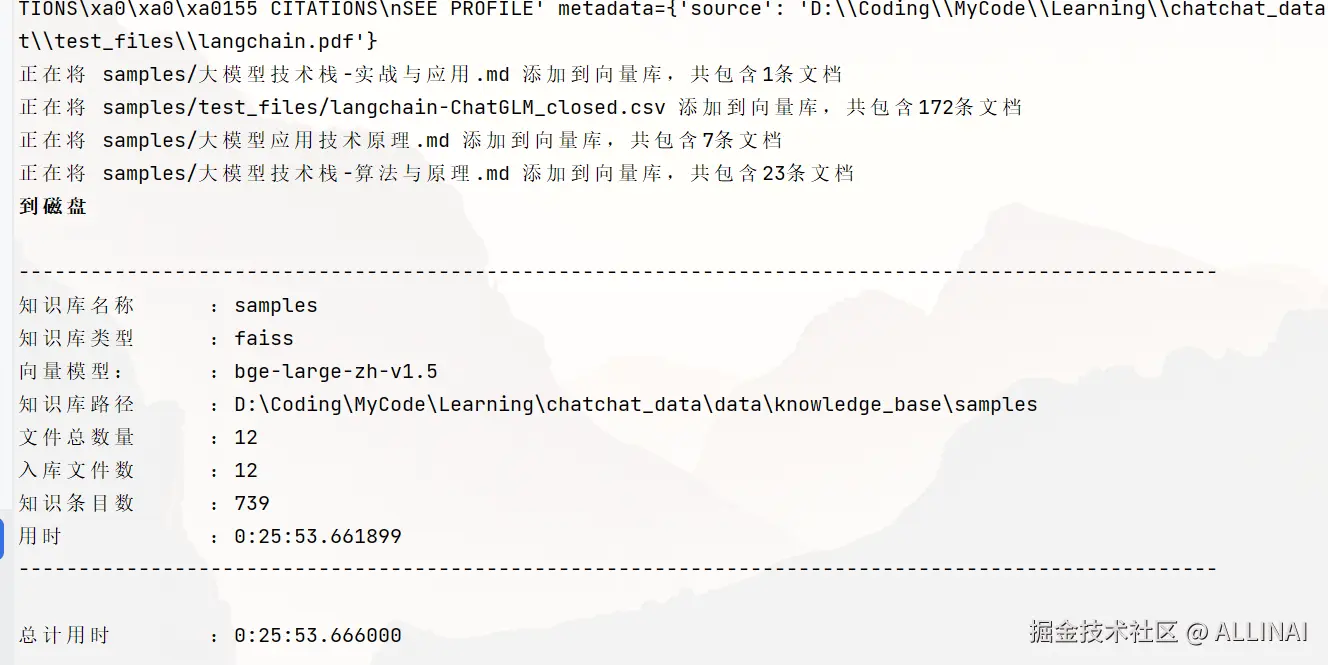
- 启动项目
css
chatchat start -a
三、每个阶段的实现细节
1. 文档上传与解析
文档上传
- 模块位置:
server\knowledge_base\kb_doc_api.py - API路由:
knowledge_base/upload_docs - 函数名称:
upload_docs
python
def upload_docs(
files: List[UploadFile] = File(..., description="上传文件,支持多文件"),
knowledge_base_name: str = Form(
..., description="知识库名称", examples=["samples"]
),
override: bool = Form(False, description="覆盖已有文件"),
to_vector_store: bool = Form(True, description="上传文件后是否进行向量化"),
chunk_size: int = Form(Settings.kb_settings.CHUNK_SIZE, description="知识库中单段文本最大长度"),
chunk_overlap: int = Form(Settings.kb_settings.OVERLAP_SIZE, description="知识库中相邻文本重合长度"),
zh_title_enhance: bool = Form(Settings.kb_settings.ZH_TITLE_ENHANCE, description="是否开启中文标题加强"),
docs: str = Form("", description="自定义的docs,需要转为json字符串"),
not_refresh_vs_cache: bool = Form(False, description="暂不保存向量库(用于FAISS)"),
) -> BaseResponse:
"""
API接口:上传文件,并/或向量化
"""文档解析成文本
- 模块位置:
server\file_rag\document_loaders
python
class KnowledgeFile:
def __init__(
self,
filename: str,
knowledge_base_name: str,
loader_kwargs: Dict = {},
):
"""
对应知识库目录中的文件,必须是磁盘上存在的才能进行向量化等操作。
"""
...
self.document_loader_name = get_LoaderClass(self.ext)
...
def file2docs(self, refresh: bool = False):
if self.docs is None or refresh:
...
loader = get_loader(
loader_name=self.document_loader_name,
file_path=self.filepath,
loader_kwargs=self.loader_kwargs,
)
...
2. 文本切分与清洗
- 使用
TextSplitter(如ChineseRecursiveTextSplitter) - 模块位置
server\file_rag\text_splitter - 参数
chunk_size- 控制单个文本块的最大长度
- 太大:容易超过模型上下文限制
- 太小:语义不完整,影响 embedding 效果
- 参数
chunk_overlap- 保证上下文的连续性
- 防止信息"切断"导致语义断裂
- 尤其在问答中保持跨段引用的可能性(如引用上一句)
python
class KnowledgeFile:
...
def docs2texts(
self,
docs: List[Document] = None,
zh_title_enhance: bool = Settings.kb_settings.ZH_TITLE_ENHANCE,
refresh: bool = False,
chunk_size: int = Settings.kb_settings.CHUNK_SIZE,
chunk_overlap: int = Settings.kb_settings.OVERLAP_SIZE,
text_splitter: TextSplitter = None,
):
docs = docs or self.file2docs(refresh=refresh)
if not docs:
return []
if self.ext not in [".csv"]:
if text_splitter is None:
text_splitter = make_text_splitter(
splitter_name=self.text_splitter_name,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
)3. 文本向量化(Embedding)
- 使用 BGE、text2vec、GTE、MiniLM 等中文模型,本文使用 xinference 运行的 bge-large-zh-v1.5 模型。
- BGE 系列模型(Bidirectional Generative Embedding)是北京智源人工智能研究院(BAAI) 发布的高质量中文文本向量化(embedding)模型。
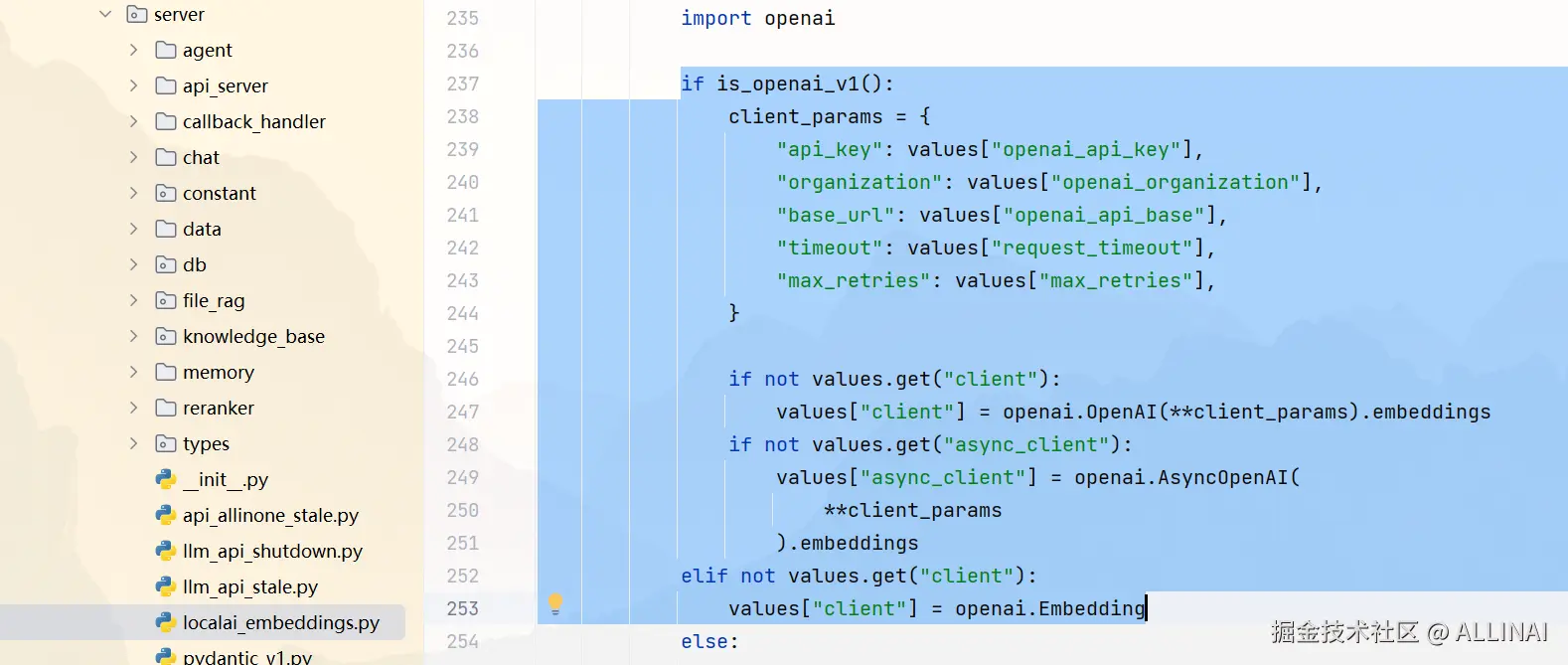
- 核心代码是函数
get_Embeddings和 类LocalAIEmbeddings。使用了openai.Embedding的进行向量化,因为 xinference 也是兼容 openai 接口格式的。
4. 向量索引构建(Vector Store)
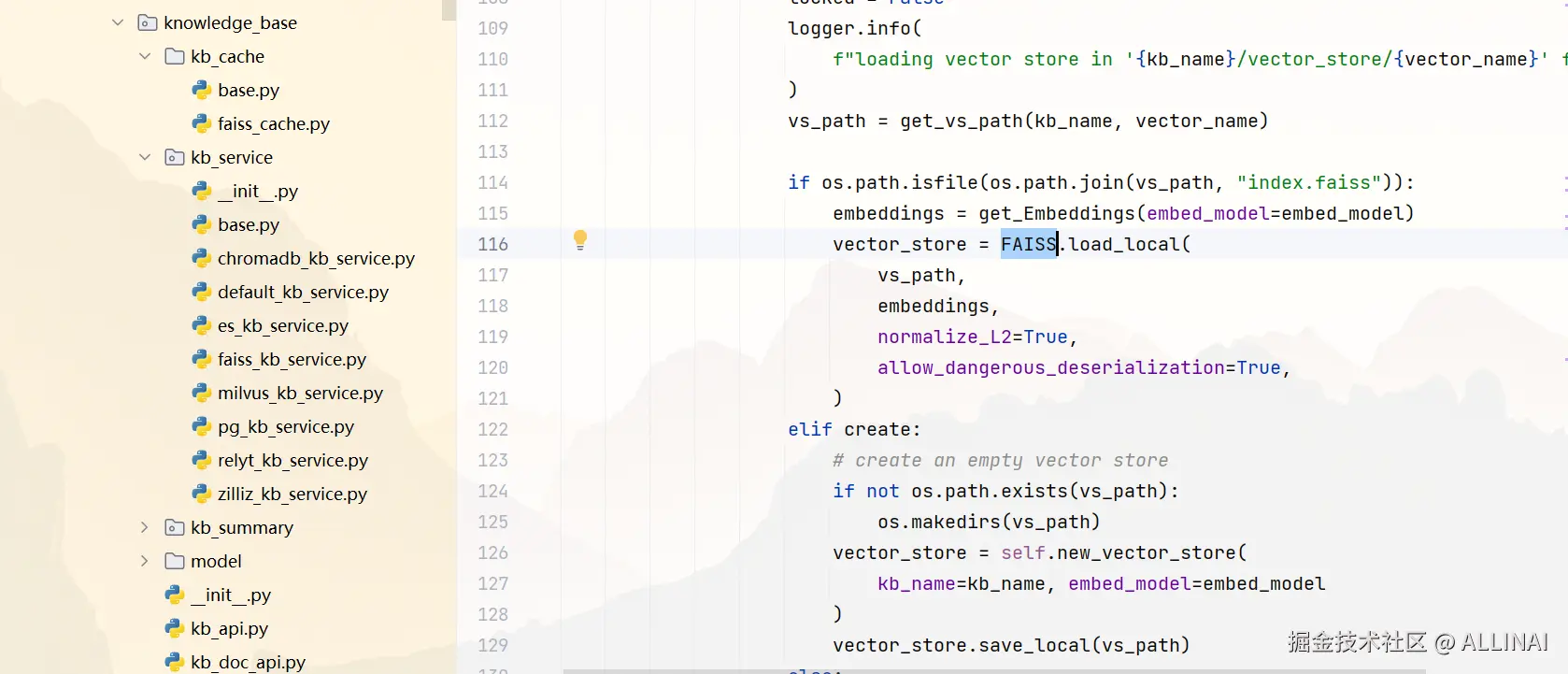
- 默认使用 FAISS
- 模块位置:
server\knowledge_base\kb_service和langchain_community\vectorstores\faiss.py
5. 用户提问 → 检索相关片段
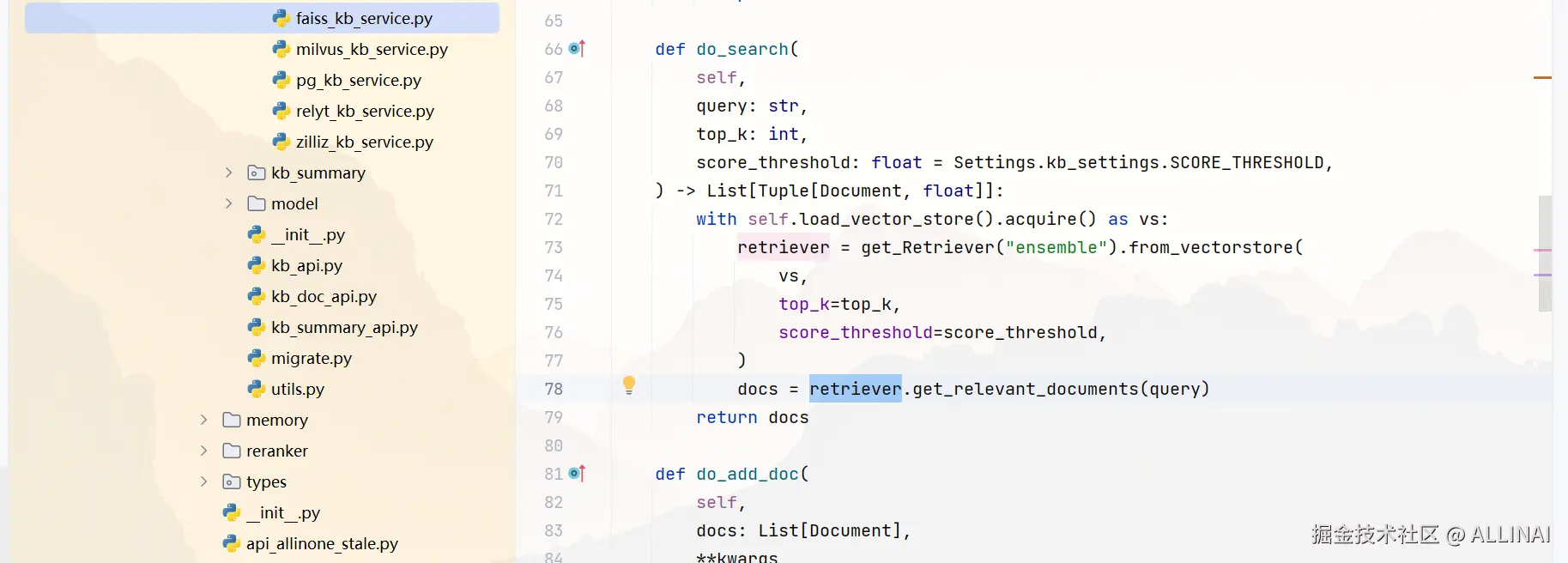
6. Prompt 构造:拼接文档 + 问题
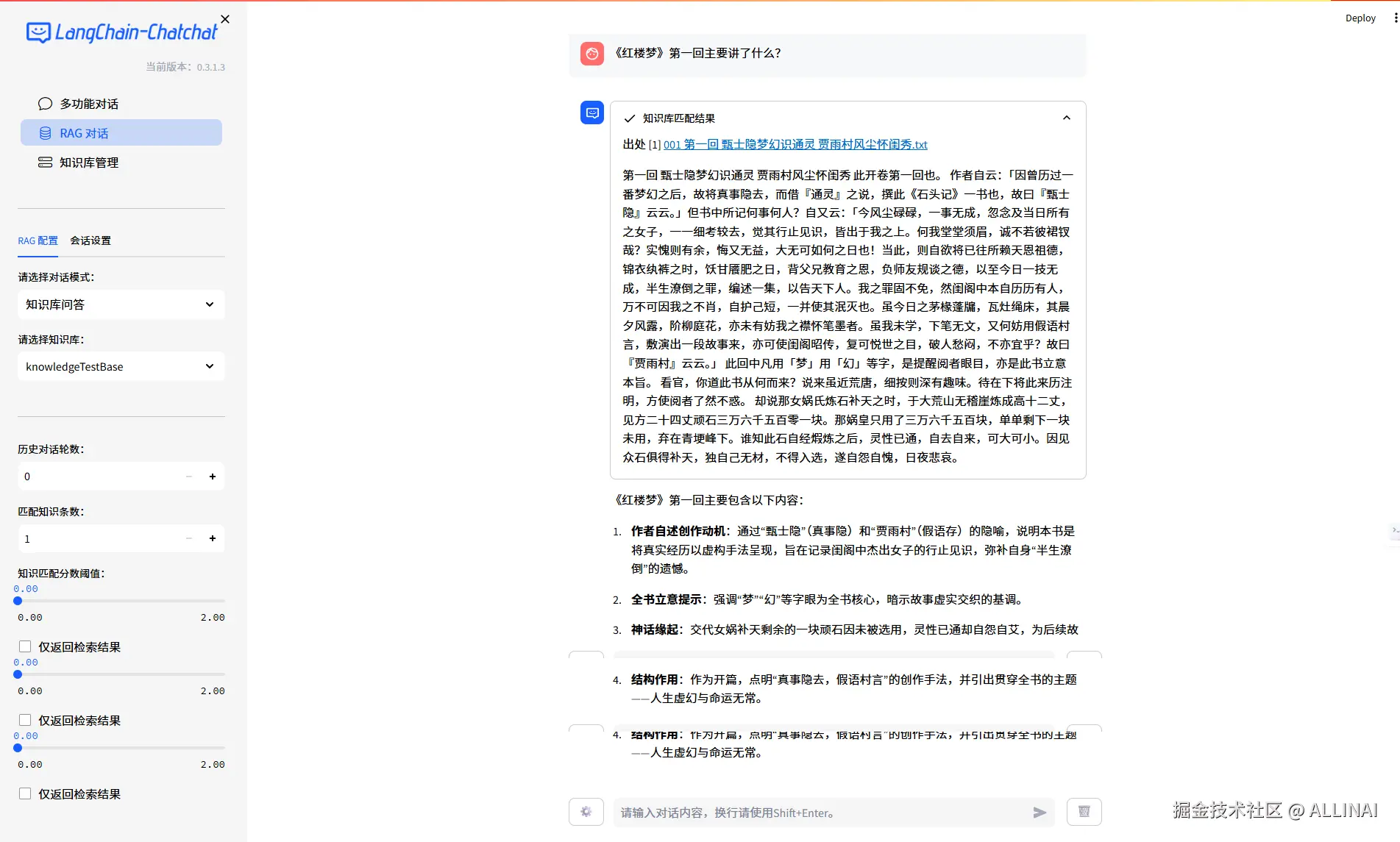
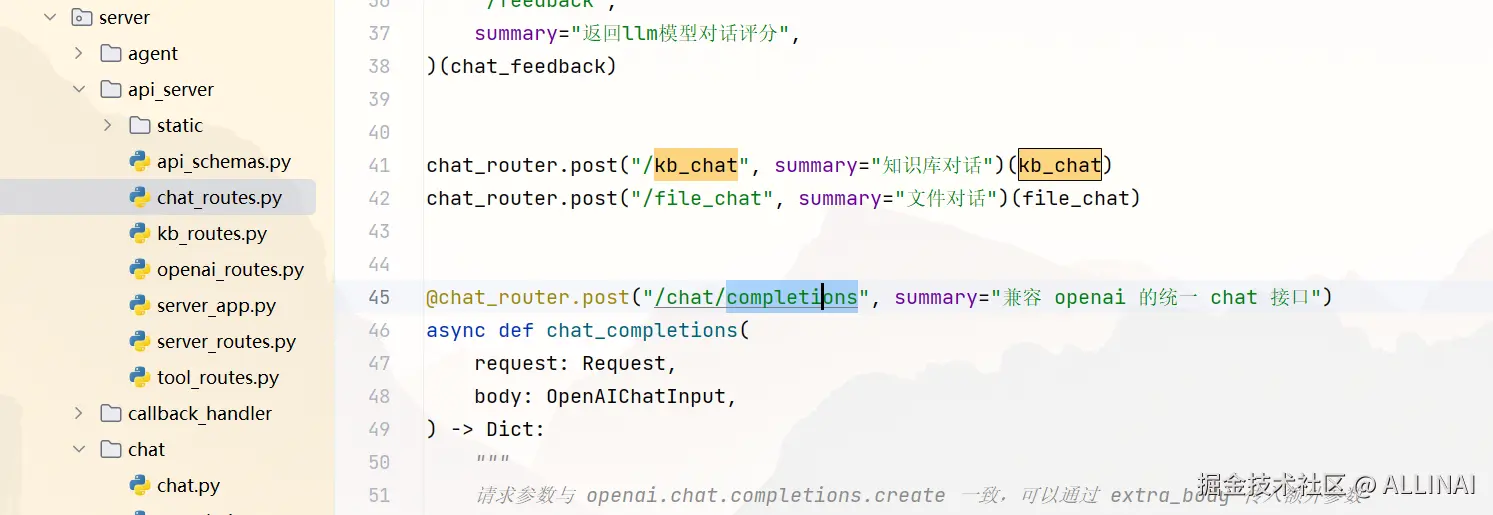
- API位置:
server\api_server\chat_routes.py
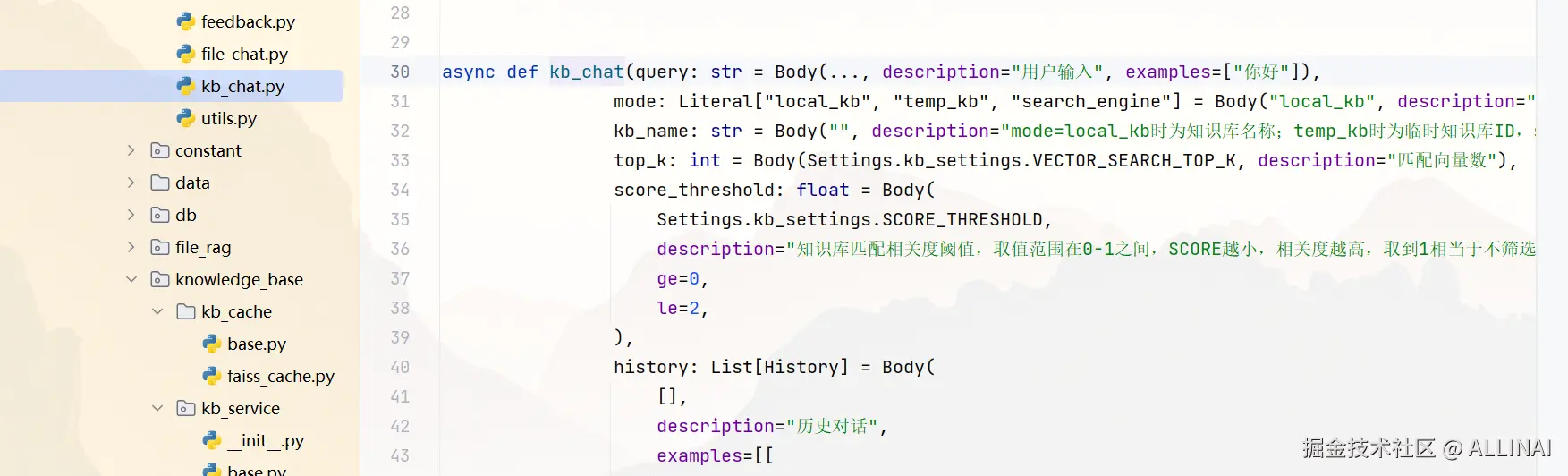
- Prompt 构造
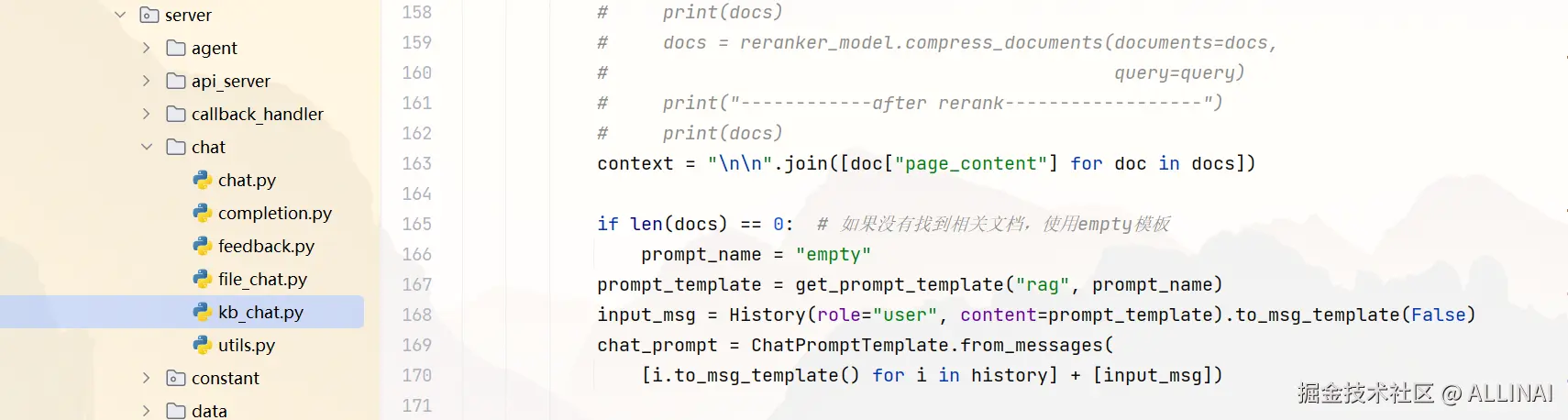

7. 模型调用(LLM)

- 支持本地模型(ChatGLM、Qwen、GLM4)
- 支持远程模型(OpenAI、讯飞星火等)
8. 输出回答
- 支持显示参考文档片段
- 多轮对话(Memory)
- Agent 工具调用(可选)
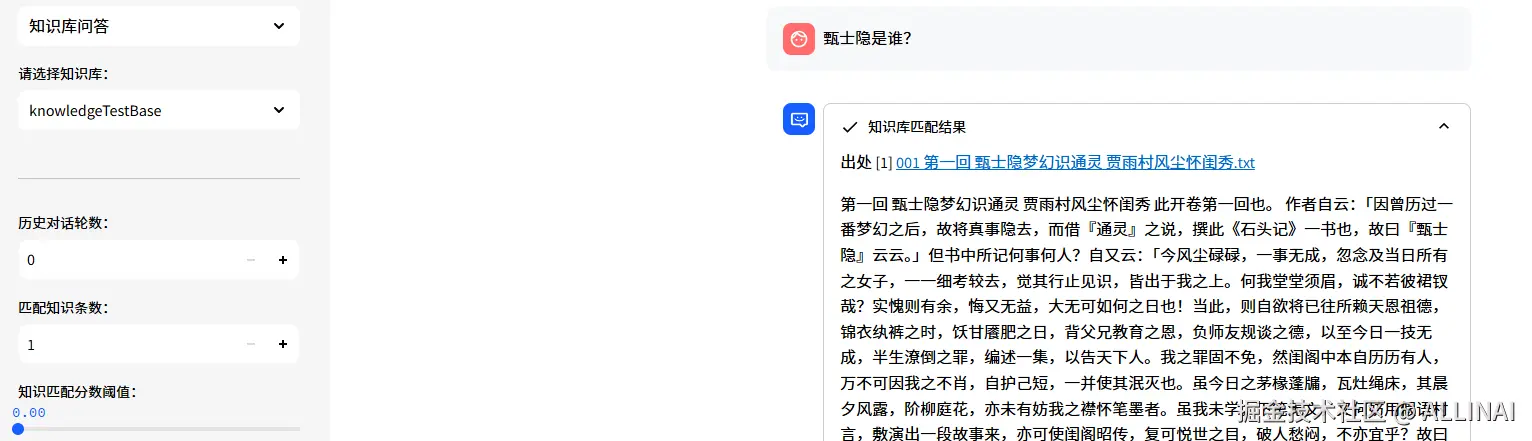
四、项目中各模块之间的协作结构图
graph TD
A[前端UI] -- 提问 --> B[FastAPI 接口];
B --- B1[向量库查询];
B --- B2[文档拼接];
B --> C[大模型推理];
C1[模型适配器 OpenAI/GLM/Qwen] --- C;
C --> D[结果生成 + 回传 UI];
五、知识库问答的优势与挑战
| 优势 | 挑战 |
|---|---|
| 🔍 提升回答准确性 | 📐 文本切分粒度需调优 |
| 💾 实时更新知识 | ⚡ 向量库查询性能 |
| 🎯 定向回答专业内容 | 🤖 模型对上下文利用能力有限 |
| 🧱 架构清晰,可扩展 | 🔗 多文档融合效果需评估 |
✅ 总结
知识库问答(RAG)是 Langchain-Chatchat 最核心的能力之一,它以模块化设计方式将文档解析、向量化、检索与提示词拼接串联起来,实现了一个"接入你自己知识"的智能问答系统。理解它的每一环节,可以帮助你掌握如何构建可控、可追溯、可自定义的大模型问答系统。