
✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Rust开发,Python全栈,Golang开发,云原生开发,PyQt5和Tkinter桌面开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,云原生K8S,linux,shell脚本等实操经验,网站搭建,数据库等分享。
所属的专栏: Rust高性能并发编程
景天的主页: 景天科技苑

文章目录
- AI智能体
-
- LLM
-
- [🧠 一、基本概念](#🧠 一、基本概念)
- [⚙️ 二、核心技术](#⚙️ 二、核心技术)
- [💬 三、应用场景](#💬 三、应用场景)
- [🧩 四、代表性模型](#🧩 四、代表性模型)
- [🚀 五、大模型技术选型](#🚀 五、大模型技术选型)
-
- [1. Llama系列](#1. Llama系列)
- [2. Qwen系列](#2. Qwen系列)
- [3. prompt](#3. prompt)
- ollama
-
- [1. 基本介绍](#1. 基本介绍)
- [2. 安装使用](#2. 安装使用)
- [3. 模型仓库](#3. 模型仓库)
- [4. 自定义大模型](#4. 自定义大模型)
-
- [4.1 模型下载](#4.1 模型下载)
- [4.2 Modefile文件配置](#4.2 Modefile文件配置)
-
- [4.2.1 常用指令](#4.2.1 常用指令)
AI智能体
LLM
LLM 是 "Large Language Model"(大型语言模型)的缩写。
大型语言模型,基于海量的数据进行学习得到的模型。
它是一种基于深度学习(尤其是 Transformer 架构)的人工智能模型,用来理解、生成和处理自然语言。像(GPT-5)这样的模型就是 LLM 的一个例子。
🧠 一、基本概念
LLM 通过在海量文本上进行训练,学习语言的结构、语义、逻辑和世界知识。
它的目标是:预测下一个最可能出现的词。
这种简单的机制在大规模训练下,使模型能生成连贯、有逻辑、甚至有创造性的文本。
点积神经网络,各种参数,其实就是函数,参数越多,学习能力越强,商用价值越大。
⚙️ 二、核心技术
Transformer 架构
基于"注意力机制"(Attention),能同时处理句子中不同位置的词。
比传统的 RNN/LSTM 模型更擅长理解长距离依赖关系。
自监督学习
不需要人工标注数据,而是通过预测缺失的词来训练。
微调 (Fine-tuning)
训练好的基础模型(如 GPT、LLaMA、Claude)可以针对特定任务(客服、编程、翻译等)进行微调。
💬 三、应用场景
对话与问答(ChatGPT、Bing Copilot)
文本生成(写作助手、营销内容)
编程辅助(Copilot、Code Interpreter)
知识问答与检索增强生成(RAG)
教育与科研辅助
🧩 四、代表性模型

在线大模型,收费:
OpenAI GPT
Google Gemini
Authropic Claude
智谱AI GLM
百度 文心一言
优缺点:
都是甲方部署的,有资源优势。模型性能优越、研发成本低(0.005-0.008元/1000个token),每次向大模型发送的一段话,就是一个token。可以站在巨人的肩膀上快速探索前沿技术应用,稳定性和使用安全性高,
但数据安全存在隐患,客户聊天等数据不在自己手上,业务受制于人,上车容易下车难。
开源大模型:
所谓开源大模型,就是这些模型属于免费,他们把源代码,论文,训练出来的模型,文件等资料公开出来,供大家免费使用。
Meta Llama(3.1 405B)
Mistral AI
X AI Grok
阿里 通义千问 Qwen
Baichuan
360 zhinao
优缺点:( 7B大模型->70亿->4张4090 ->语料->上十亿 -> )
源代码在自己手上,完全自主可控,扩展性强,定制型强,数据安全有保障,但需要投入大量算力和开发成本,依赖开源,不好转身。
🚀 五、大模型技术选型
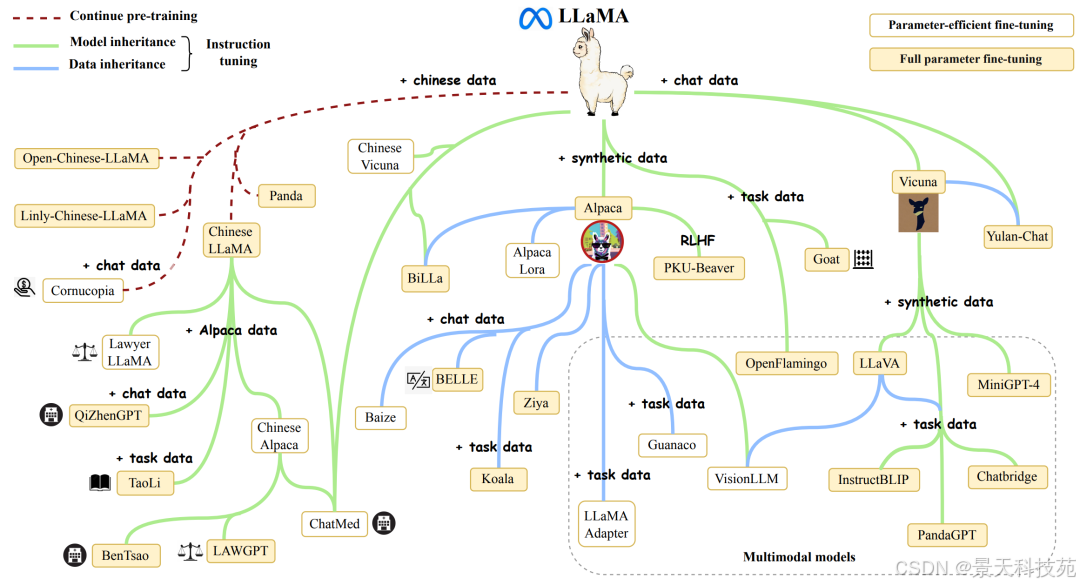
1. Llama系列
LLaMA系列大模型是Meta公司在2023年2月开源的基于 transformer 架构的大型语言模型, 包括四种尺寸(7B 、13B 、30B 和 65B),并在2024年进一步发展,推出了Llama 3版本。
Llama3在多种行业基准测试中展现了最先进的性能,提供了包括改进的推理能力在内的新功能,是目前市场上最好的开源大模型之一。
2. Qwen系列
文档:https://qwen.readthedocs.io/zh-cn/latest/getting_started/quickstart.html
随着GLM的闭源,阿里的通义千问已经成为了国内开源大模型的领袖。
Qwen平均1个季度发布一个版本,性能始终处于开源大模型的第一梯队水平。目前最新发布版本:Qwen3。
阿里的魔塔社区(https://modelscope.cn/models)
注册账号之后,就可以白嫖了。我们可以针对它进行学习。在魔塔上进行微调,部署到灵积平台上
也随着技术迭代更新,成为了国内第一AI模型社区,号称"中文版HuggingFace(https://huggingface.co/)",
吸引了大批优质的大模型开发者参与进来,同时魔塔社区不仅提供免费在线开发环境(类似谷歌的Colab)和限时GPU算力(100小时32GB显存),这100小时指的是连接到大模型里面,才计时的。
助力开发者在线训练微调大模型,还与阿里云灵积平台(DashScope)深度绑定,
让开发者训练微调完成的模型可以快速落地实施到阿里云架构服务器上(按量收费),形成了一整套混合模型在线服务的生态模式。
阿里还提供了高度适配的SWIFT轻量级微调框架和Qwen-Agent开发框架,可以让我们快速实现一些智能体。其中SWIFT提供了代码环境和脚本微调两种模式,
配套海量开源微调数据集,可以执行包括知识灌注、模型自我意识微调、Agent能力微调和领域能力微调等功能,还提供一键微调等功能。
Qwen-Agent则支持高效稳定Multi Function calling、ReAct功能,支持调用开源大模型以及灵积平台的在线模型。
3. prompt
提示工程(Prompt Engineering)是一项通过优化提示词(Prompt)和生成策略,从而获得更好的模型返回结果的工程技术。
其基本实现逻辑如下:
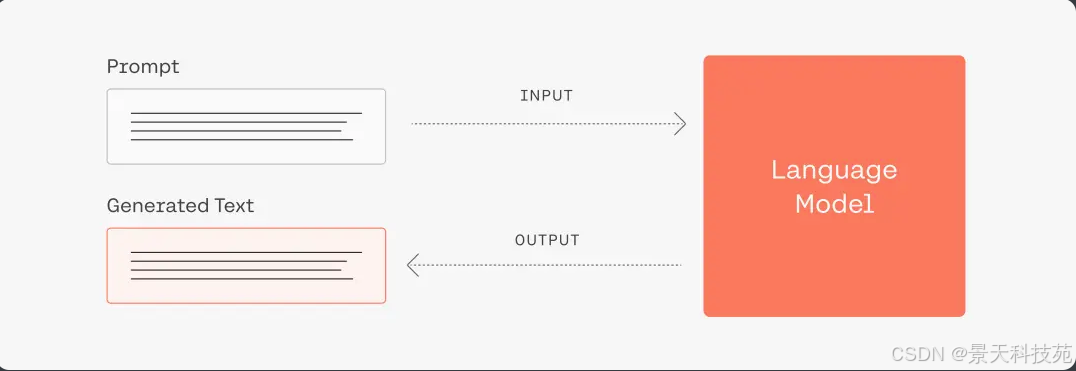
简单而言,大模型的运行机制是"下一个字词预测"。用户输入的prompt即为大模型所获得上下文,大模型将根据用户的输入进行续写,返回结果。
因此,输入的prompt的质量将极大地影响模型的返回结果的质量和对用户需求的满足程度,总的原则是"用户表达的需求越清晰,模型更有可能返回更高质量的结果"。
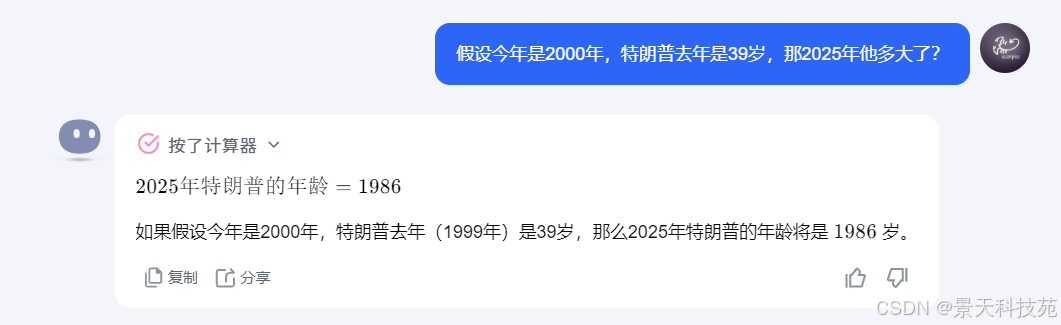
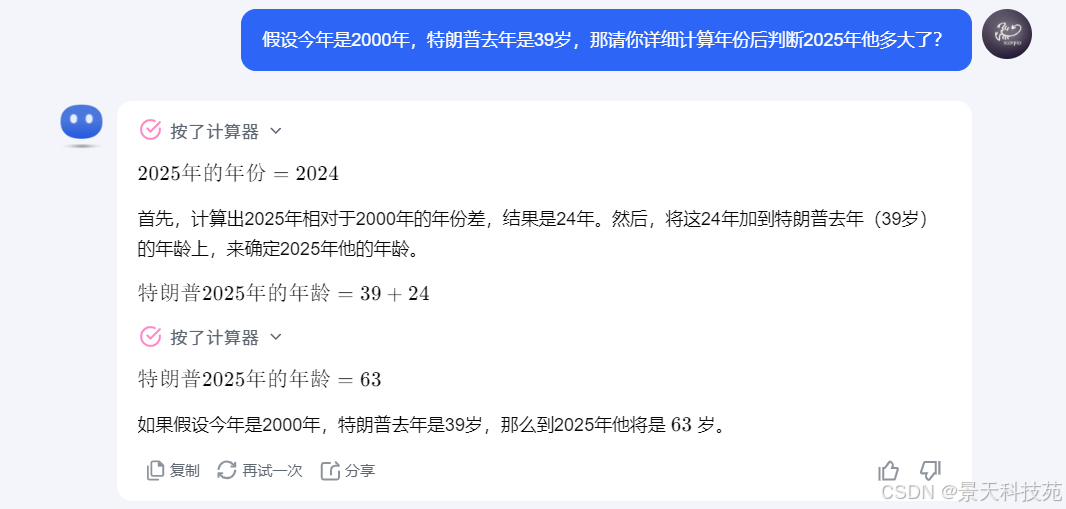
prompt工程这种微调手段对于大模型本身的推理能力的提升的范围大概也就10%左右。大模型训练工程师,prompt工程多数用在在线大模型,而不是开源大模型。
prompt工程对于大模型本身推理能力的微调有效性是有上限的,并不能大幅度提升体力能力。
Prompt经验总结:清晰易懂、提供例子和锁定上下文、明确步骤、准确表达意图。
去玩一下吧:https://modelscope.cn/studios/LLMRiddles/LLMRiddles/summary
通常情况下,每条信息都会有一个角色(role)和内容(content):
- 系统角色(system)用来向语言模型传达开发者定义好的核心指令,优先级是最高的。
- 用户角色(user)则代表着用户自己输入或者产生出来的信息。
- 助手角色(assistant)则是由语言模型自动生成并回复出来。
系统指令(system)
system message系统指令为用户提供了一个易组织、上下文稳定的控制AI助手行为的方式,可以从多种角度定制属于你自己的AI助手。
系统指令允许用户在一定范围内规定LLM的风格和任务,使其更具可定性和适应各种用例。
大部分LLM模型的系统指令System message的权重强化高于人工输入的prompt,并在多轮对话中保持稳定,您可以使用系统消息来描述助手的个性,
定义模型应该回答和不应该回答的内容,以及定义模型响应的格式。
默认的System message:You are a helpful assistant.
下面是一些system message的使用示例:

System message可以被广泛应用在:角色扮演、语言风格、任务设定、限定回答范围。
用户指令(user)
用户指令是最常用的提示组件,主要功能是向模型说明要执行的操作。以下举例:

ollama
1. 基本介绍
Ollama 是一个开源的大型语言模型服务工具,专为在服务器上便捷部署和运行大型语言模型(LLMs)而设计,
它提供了一个简洁且用户友好的命令行界面,通过这一界面,用户可以轻松地部署和管理各类开源的 LLM。
Ollama 是一个开源(MIT 许可证)工具 / 框架,用来在本地或私人设备上运行和管理大语言模型(LLM)。
它提供一种"下载模型 + 本地运行"的方式,让用户不必完全依赖云端服务就能使用强大的语言模型
具有以下特点和优势:
开源免费:Ollama 以及其支持的模型完全开源免费,任何人都可以自由使用、修改和分发
简化部署:Ollama 目标在于简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型,无需复杂的配置和安装过程,只需几条命令即可启动和运行Ollama
轻量级与可扩展:作为轻量级框架,Ollama 保持了较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件,即使在普通笔记本电脑上也能流畅运行。
API支持:提供了一个简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
预构建模型库:包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源。
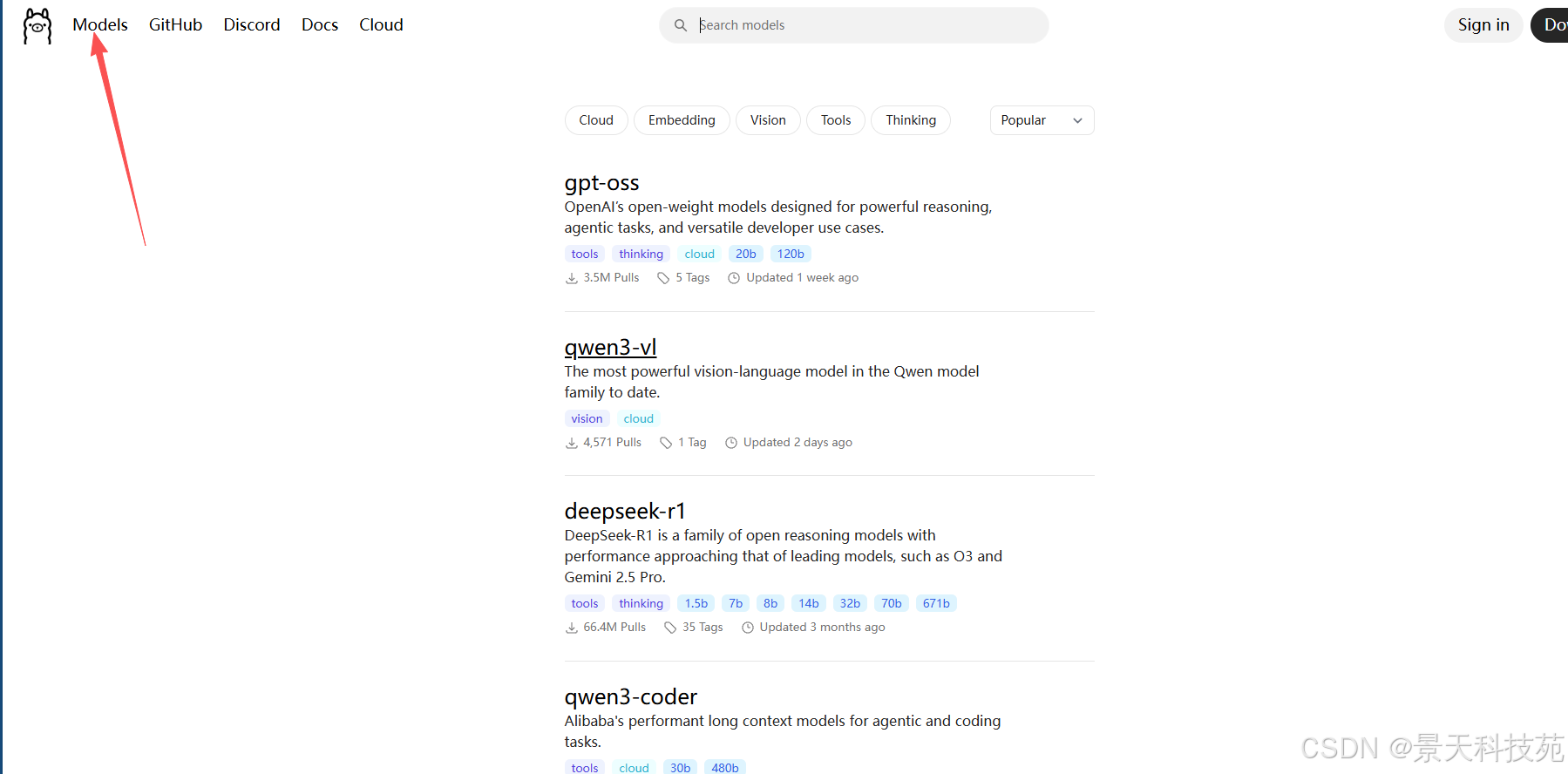
模型生态 / 支持的模型
Ollama 拥有自己的模型库 ("library"),提供一系列开源 / 公开模型可供下载和使用。
常见支持模型包括例如 LLaMA 系列、Mistral、Gemma、DeepSeek-R1 等。
如 DeepSeek-R1 系列模型,就可以在 Ollama 上直接运行:如 ollama run deepseek-r1
官方站点:https://ollama.com/
看下模型库
像docker一样运行
Github:https://github.com/ollama/ollama
2. 安装使用
下载地址:https://ollama.com/download,根据系统类型进行安装,这里演示的是window系统安装过程。
注意,在windows下安装ollama是不允许自定义位置的,会默认安装在系统盘,而后续使用的大模型可以选择自定义保存路径。
安装过程比较简单,现在下来,双击安装
路径不能自己选,全程自动安装
安装完成以后,新开一个命令终端并输入命令ollama,如果效果如下则表示安装成功:
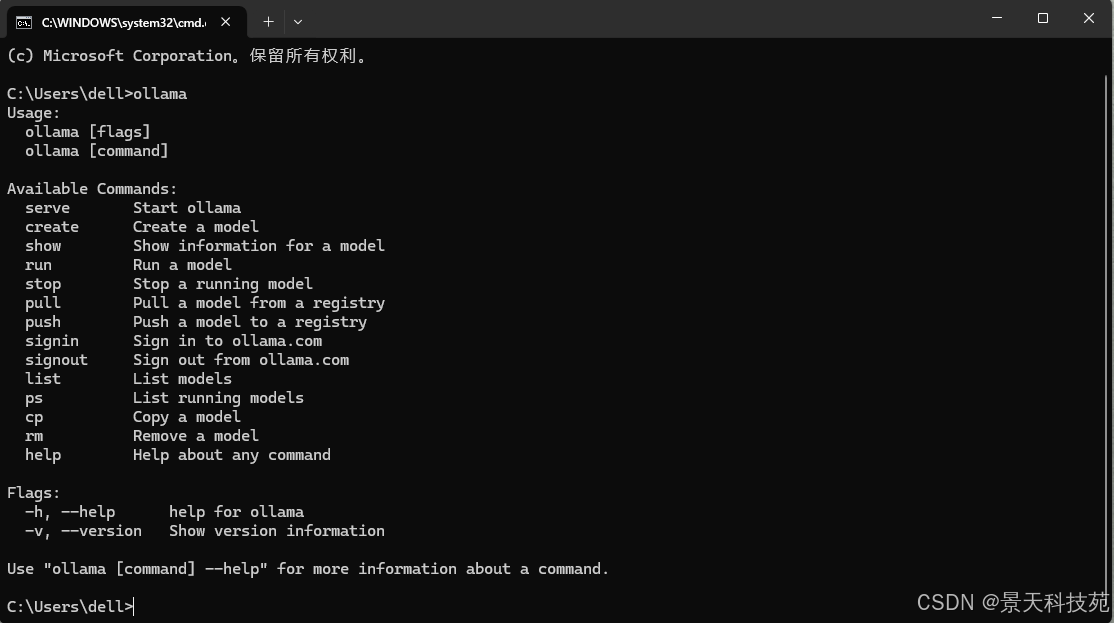
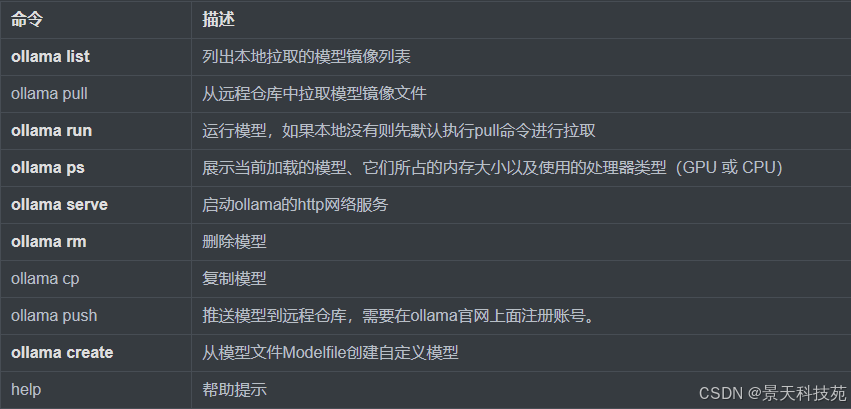
常用命令
这里的命令,全系统通用的。
ollama serve 启动网络服务之后,就可以使用它的restful接口了
ollama create操作步骤:
Modelfile文件不能有后缀名;如下一个简单的Modelfile文件
第一步:创建Modelfile文件
#指定本地模型的位置
FROM /root/auto-temp/Qwen2.5-0.5B-Instruct-F16.gguf
#指定模型参数
PARAMETER temperature 0.7
#设置系统消息,定义助手行为
SYSTEM """
You are a helpful assistant.
"""
Modelfile文件只有第一行是必须的,其他配置都可以不指定。
第二步:执行命令加载模型到Ollama的模型列表中
在Modelfile文件所在路径下执行命令:
bash
ollama create my_qwen -f Modelfile拉取并运行一个大模型:
bash
ollama run qwen3:0.6b
运行之后,就可以聊天了


输入 /bye 退出

3. 模型仓库
模型可以从哪里去下载呢?很多模型都可以从很多地方下载,如下常见几个下载地址
ollama仓库地址:https://ollama.com/library
hugging face仓库地址:https://huggingface.co/models
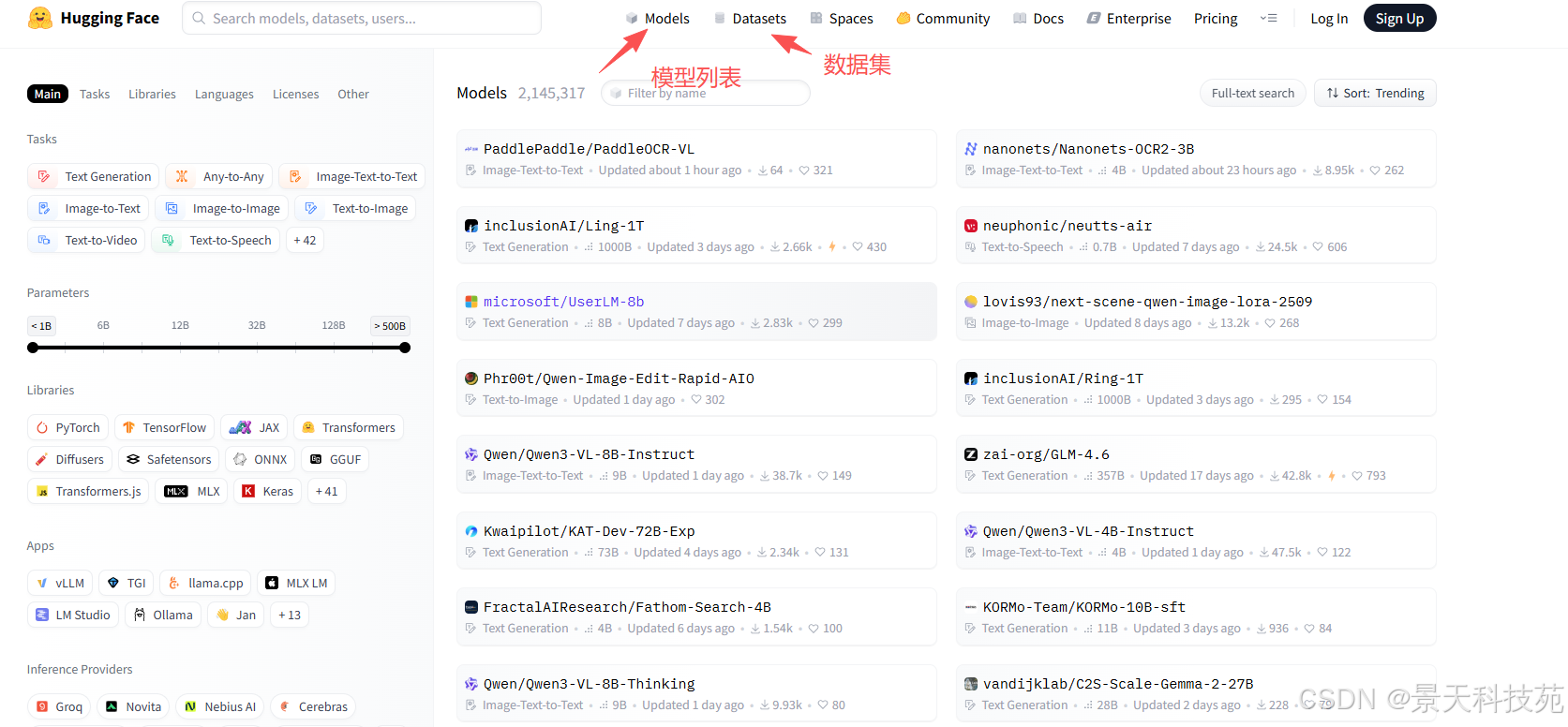
【镜像】https://hf-mirror.com/models
这里汇集了所有大模型了面最多的镜像,有各种垂直领域训练好的大模型
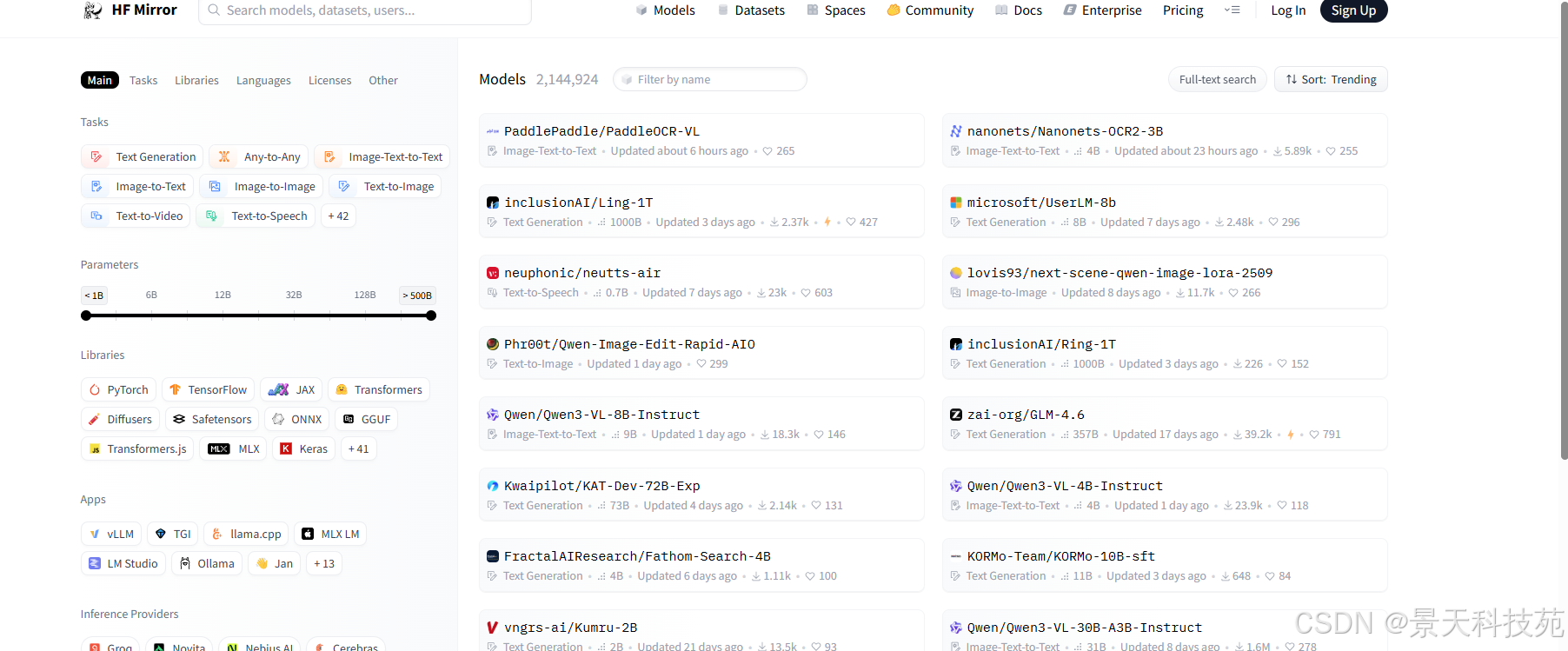
每个镜像点击进去,都有告诉你怎么使用,怎么调用,怎么开发
魔塔社区:https://modelscope.cn/models
如果想要在云服务器上面部署大模型,可以使用选择华为的升腾云服务器,阿里的灵积平台
临时用可以租AI算力服务器 https://autodl.com/market/list
非常划算
算力云,升腾都是可以商用的。
如果只是自己部署练手,直接使用功能魔塔就行了
魔塔提供创空间
创建好的,可以直接在灵积平台用了
4. 自定义大模型
有些公司,并不会把模型上传到ollama上去,而是有可能上传到魔塔或者hugging face上面
4.1 模型下载
魔塔下载大模型说明文档:https://www.modelscope.cn/docs/models/download
使用魔塔下载大模型文件,安装魔塔工具(python3.11^):
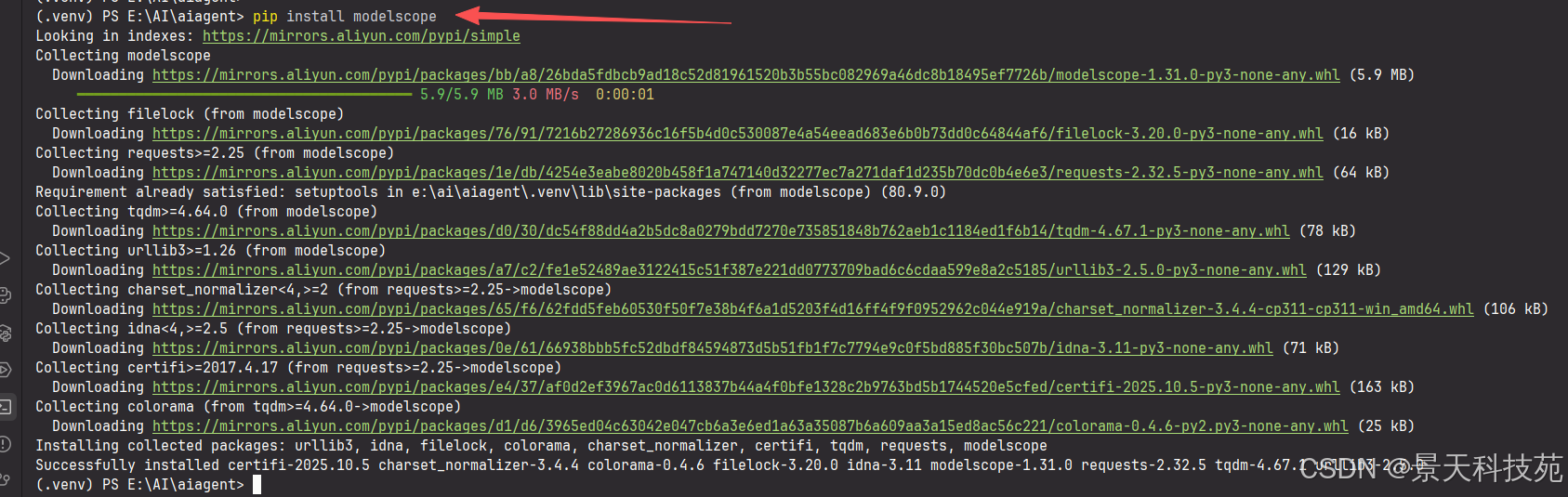
Ollama 只能加载 GGUF 格式 的模型
ollama create 只能识别:
.gguf 模型文件(来自 llama.cpp)
或从 Ollama 官方库拉取的模型名(如 FROM qwen2)
注意:此种方式,自定义模型,只能自定义GGUF格式的模型
Ollama 原生最稳的输入格式是 GGUF(llama.cpp 系列)。在魔搭搜索带有 GGUF/Q4_0/Q5_K_M 等量化后缀的条目。
基于python脚本调用魔塔拉取模型文件,modelscope_download.py,代码:
python
from modelscope import snapshot_download
# 模型名字
name = 'Qwen/Qwen3-4B-GGUF'
# 模型存放路径,需要手动创建对应的目录,并保证有足够的空间,否则下载出错。
model_path = r'D:\huggingface'
model_dir = snapshot_download(
name, # 仓库中的模型名
cache_dir=model_path, # 本地保存路径,
revision='master', # 分支版本
allow_file_pattern="Qwen3-4B*.gguf" # 模糊匹配的文件名
)因为模型文件大于4G,会切片分片保存,所以下载时要把所有文件都下载下来
根据切片的文件名来正则匹配
还一种结尾safetensors是 PyTorch / Transformers 模型文件
D:\huggingface\Qwen\Qwen2.5-1.5B-Instruct
│
├── config.json
├── generation_config.json
├── model-00001-of-00004.safetensors
├── model-00002-of-00004.safetensors
├── model-00003-of-00004.safetensors
├── model-00004-of-00004.safetensors
├── model.safetensors.index.json
├── tokenizer.json
├── tokenizer_config.json
└── README.md
还 不是 Ollama / llama.cpp 可直接加载的 .gguf 模型。
如果Qwen 官方仓库只发布了 原始权重(safetensors / PyTorch);
.gguf 是 llama.cpp 系列工具生成的推理格式;
所以需要 自行转换。
右键执行下载模型文件
下载完成
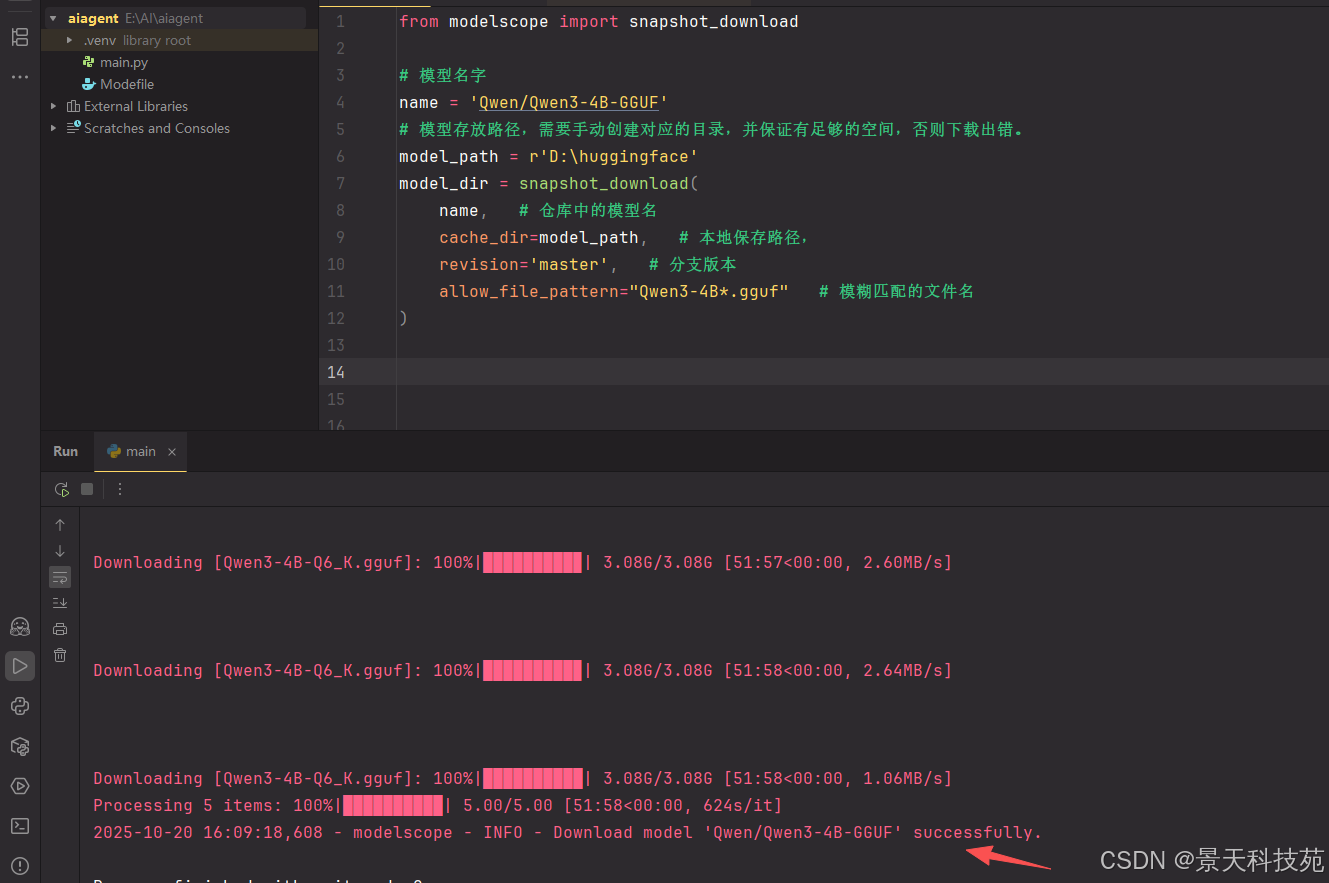
文件合并
查看下载好的文件,由于他是切片的,下载完成后需要合并
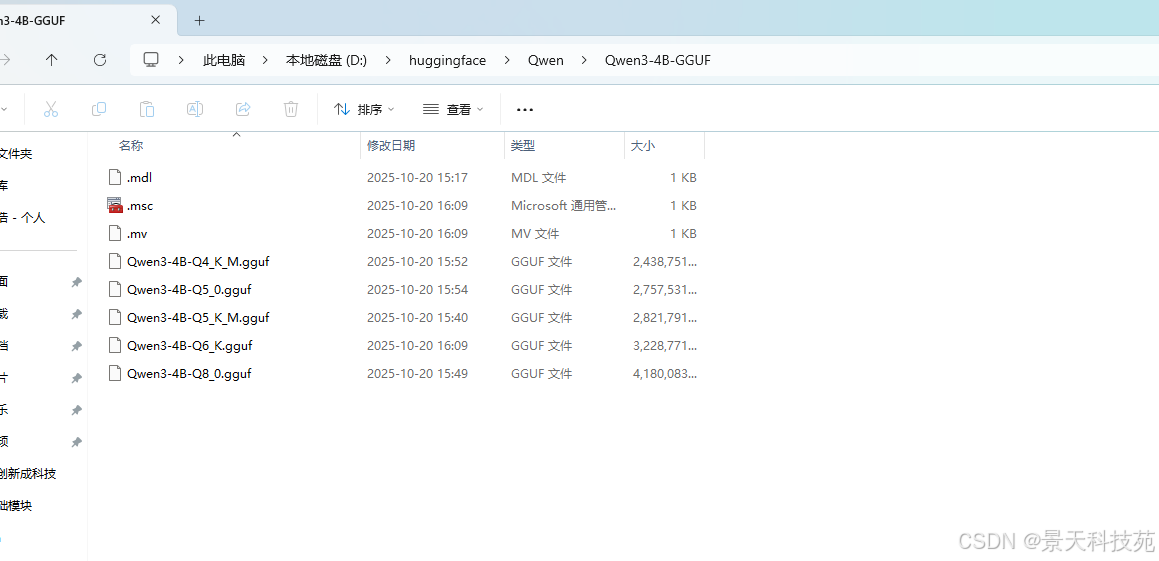
Windows中,合并使用 cpoy /B 文件1 + 文件2 + ... 最终文件
bash
copy /B Qwen3-4B-Q4_K_M.gguf + Qwen3-4B-Q5_0.gguf + Qwen3-4B-Q5_K_M.gguf + Qwen3-4B-Q6_K.gguf + Qwen3-4B-Q8_0.gguf Qwen3-4B.gguf
最终合成的文件
linux系统中,合并文件使用cat
bash
cat file1.txt file2.txt file3.txt > merged.txtfile1.txt file2.txt file3.txt:要合并的文件。
bash
>:表示重定向输出到新文件(如果文件已存在,会被覆盖)。
merged.txt:合并后的输出文件。4.2 Modefile文件配置
Ollama自定义大模型需要通过Modelfile定义和配置模型的行为和特性,在使用 Ollama 进行本地部署和运行大型语言模型时,Modelfile 扮演着至关重要的角色。
Modelfile 是使用 Ollama 创建和共享模型的方案。它包含了构建模型所需的所有指令和参数,使得模型的创建和部署变得简单而直接。
Modelfile 是用于定义、定制并构建 Ollama 模型的说明文件(有点像 Dockerfile)。
它支持多条"指令"(指令名不区分大小写)来设置基模型、推理参数、系统提示词、模板、LoRA 适配器、示例对话等。语法仍在演进中。
4.2.1 常用指令
Modelfile中不区分大小写,但是强烈要求一定大写!!
参数说明,FROM是必填的。其他的可以不写
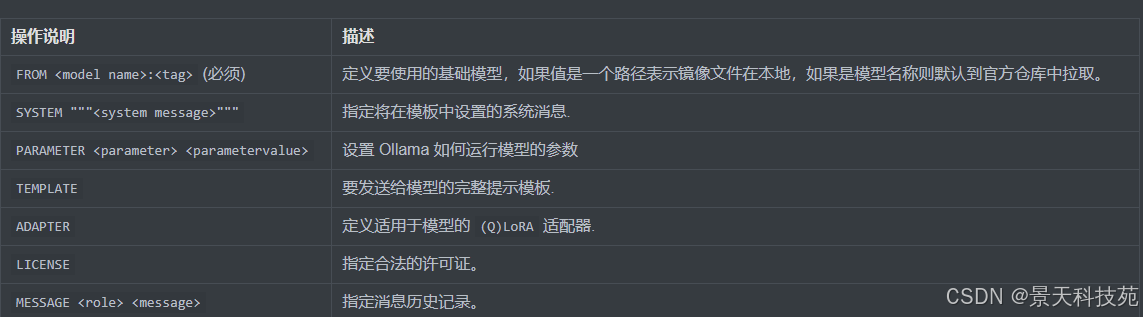
FROM 用法
支持三种来源:
1)直接用库里的现成模型:
FROM llama3.2
2)从 Safetensors 目录导入(架构需支持,如 Llama/Mistral/Gemma/Phi3 等):
FROM /path/to/safetensors_dir
3)从 GGUF 文件导入:
FROM ./mymodel.gguf
(GGUF 路径相对 Modelfile 或绝对路径均可。)
SYSTEM就是上面我们讲的系统指令
System message可以被广泛应用在:角色扮演、语言风格、任务设定、限定回答范围等。
在 ollama create 用的 Modelfile 里,SYSTEM 用来设置模型的"系统提示"(system prompt)。
它会作为模板中的系统消息注入到提示词里,从而长期定义模型的人设、口吻与边界。
是否生效取决于模板是否包含 {{ .System }} 这个占位符(Ollama 默认/示例模板里就有)。
怎么写
最简单写法(单行或多行三引号):
yaml
FROM llama3.2
PARAMETER temperature 0.7
SYSTEM You are a concise Chinese assistant that answers in Simplified Chinese.或:
yaml
FROM llama3.2
SYSTEM """
你是一个只用简体中文回答问题的技术助理。
回答尽量简洁,并给出代码示例。
"""它如何插入到提示里
模板(TEMPLATE 指令)通常会长这样,包含 {{ .System }}、{{ .Prompt }} 等变量;如果有系统消息,就会把它作为"system"角色拼进提示:
markup
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
"""关键点:只有当模板里使用了 {{ .System }},SYSTEM 才会被注入。
PARAMETER的有效参数和值

TEMPLATE的模板变量
自定义完整提示模板(Go template 语法,含 .System/.Prompt/.Response 变量)。

SYSTEM 与 TEMPLATE
SYSTEM:直接写系统提示,一般用于设定口吻/边界。
TEMPLATE:完全自定义提示拼接方式,使用 Go 模板变量:{{ .System }}、{{ .Prompt }}、{{ .Response }}。生成时 .Response 之后的模板内容会被忽略。示例:
markup
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
"""(不同基模型的特殊 token/头标可能不同,需按模型兼容性调整。)
TEMPLATE决定"用户输入 + 系统提示 + 模型回复"被拼接成什么样的提示串发送给底层模型。
语法是 Go template,并且不同模型家族的对话标记可能不同(必须按模型的惯例来写)
-
可用变量(最核心)
TEMPLATE 里通常会用到 3 个内置变量(大小写敏感):
{{ .System }}:系统消息(行为/角色设定)。
{{ .Prompt }}:用户输入。
{{ .Response }}:模型要生成的内容。生成时,放在 .Response 之后的模板文本会被忽略(也就是 .Response 后面写再多,也不会发出去/不会被继续渲染)。
-
最小范式(官方示例思路)
典型的聊天模板会把 system / user / assistant 各段包在模型习惯的标记里,最后以 assistant 段开头并把光标留在 {{ .Response }} 处让模型续写。例如(示意,对标某些 ChatML 风格):
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
"""
这段表达了:如果有 .System 就插入 system 段;如果有 .Prompt 就插入 user 段;然后开启 assistant 段,让模型在这里继续写(.Response 位置省略写法,也等价于将其紧随其后)。
-
Llama 3.x(举例说明"跟随模型标记")
以 Llama 3.2 的默认模板为例(用 ollama show --modelfile llama3.2 能看到):
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
要点:
这些 <|start_header_id|> / <|end_header_id|> / <|eot_id|> 是 Llama 3.x 的特殊标记。
因为模板里用了这些标记,必须把它们配成 stop,避免模型把结束标记"说出来"。
实操建议:先用 ollama show --modelfile <基模型> 把官方/默认模板拷出来,再按你的需求微调,成功率最高。
MESSAGE的有效角色
可内置几轮对话来"校准"风格(role: system|user|assistant):

MESSAGE user 你在加拿大吗?
MESSAGE assistant 是的
(也可以用 SYSTEM 写一次性系统提示。)
ADAPTER(LoRA/QLoRA)
对已 FROM 的基模型追加一个或多个 LoRA 适配器(safetensors 目录或 GGUF 文件):
FROM llama3.2
ADAPTER /path/to/lora_dir # safetensors
#或
ADAPTER ./mylora.gguf # GGUF 适配器
适配器需与基模型同一架构&版本族,否则推理行为会异常。
模板里的特殊标记需要与你的基模型对齐;可先用 ollama show --modelfile <模型名> 查看该模型默认模板作为参考。

调参建议(实践向)
稳健输出:temperature 0.2--0.5、top_p 0.8--0.95、repeat_penalty 1.1--1.2。
长文档/检索:增大 num_ctx(受模型与显存约束),并合理设置 stop 以避免多轮串扰。
复现性:固定 seed。
防复读:提高 repeat_penalty,或增大 repeat_last_n。
受控发散:尝试 mirostat 2,微调 mirostat_tau 和 mirostat_eta。
(这些旋钮的语义与默认值详见参数表。)
创建模型描述文件Modelfile,编写内容如下:
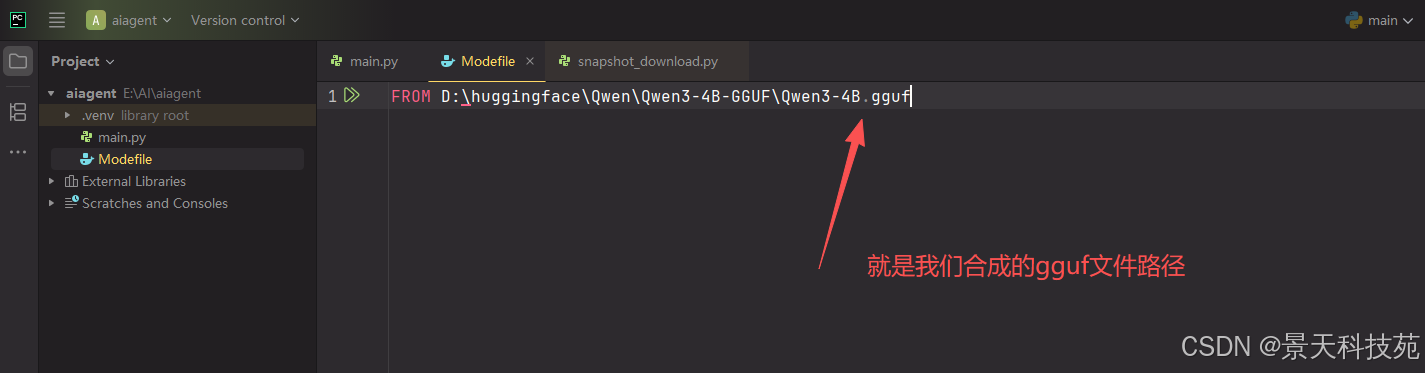
先写个最简单的,只需要 FROM 我们下载的模型路径
FROM D:\huggingface\Qwen\Qwen3-4B-GGUF\Qwen3-4B.gguf
通过运行以下命令来创建ollama模型
bash
ollama create qwen3-4b -f .\Modefile创建成功

运行新建的ollama模型:
bash
ollama run qwen3-4b
Modefile写法参考文档:https://qwen.readthedocs.io/en/latest/run_locally/ollama.html
完整的Modefile
markup
FROM D:\huggingface\Qwen\Qwen3-4B-GGUF\Qwen3-4B.gguf
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
PARAMETER top_k 20
TEMPLATE """{{ if .Messages }}
{{- if or .System .Tools }}<|im_start|>system
{{ .System }}
{{- if .Tools }}
# Tools
You are provided with function signatures within <tools></tools> XML tags:
<tools>{{- range .Tools }}
{"type": "function", "function": {{ .Function }}}{{- end }}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end }}<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
<tool_response>
{{ .Content }}
</tool_response><|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}{{ .Response }}{{ if .Response }}<|im_end|>{{ end }}"""
SYSTEM <你是周文亮,由景浩的大模型创造,你喜欢跟别人聊天,是一个非常聪明的小助手!>本地大模型,一般数据更新都是滞后于当下的,后续我们可以通过langchain,来给大模型注入向量数据,大模型在数据处理的时候,先经过向量数据库
到这里,本地大模型就搭建完成了,感兴趣的小伙伴赶紧去试试吧!