目录
在消息队列(如 Kafka)的世界里,消费者组是实现高效消息消费、负载均衡和高可用的核心机制。它并非单个消费者,而是由多个消费者组成的协同群体,能共同处理主题中的消息,既避免重复消费,又能应对流量波动。
什么是消费者组?
消费者组是指共同订阅同一个主题(Topic) 的多个消费者的集合。每个消费者组都有一个唯一的标识(Group ID),组内的消费者通过协作分工,共同消费主题中的消息。
其核心特点包括:
- 组内消费者共享消费进度,由消息队列的协调器(Coordinator) 统一管理。
- 主题中的每个分区(Partition) 只能被同一消费者组内的一个消费者消费(避免重复消费)。
- 消费者组之间相互独立,不同组可以同时消费同一主题的消息(实现多场景消费)。
理想情况下,Consumer 实例的数量应该等于该 Group 订阅主题的分区总数。
Kafka 仅仅使用 Consumer Group 这一种机制,却同时实现了传统消息引擎系统的两大模型:如果所有实例都属于同一个 Group,那么它实现的就是消息队列模型;如果所有实例分别属于不同的 Group,那么它实现的就是发布 / 订阅模型。
消费者组如何工作?
消费者组的运行逻辑围绕 "分区分配" 和 "消费进度同步" 展开,具体流程如下:
- 加入组:新消费者启动时,会向协调器发送 "加入组" 请求,协调器收集组内所有消费者信息。
- 分配分区:协调器选择一个消费者作为 "领导者(Leader)",由其制定分区分配方案(如按范围分配、轮询分配等),确保每个分区只分配给组内一个消费者。
- 消费消息:消费者按分配到的分区消费消息,并定期向协调器提交消费偏移量(Offset)(记录已消费到的位置)。
- 重平衡(Rebalance):当组内消费者数量变化(新增 / 下线)、主题分区数量变化时,协调器会触发重平衡,重新分配分区,保证消费继续。
位移(Offset)
消费者在消费的过程中需要记录自己消费了多少数据,即消费位置信息。在 Kafka 中,这个位置信息有个专门的术语:位移(Offset)。
在新版本的 Consumer Group 中,Kafka 社区重新设计了 Consumer Group 的位移管理方式,采用了将位移保存在 Kafka 内部主题的方法。这个内部主题就是让人既爱又恨的 __consumer_offsets。
将 Consumer 的位移数据作为一条条普通的 Kafka 消息,提交到 __consumer_offsets 中。可以这么说,__consumer_offsets 的主要作用是保存 Kafka 消费者的位移信息。
消费者组的核心机制:重平衡(Rebalance)
Rebalance 就是让一个 Consumer Group 下所有的 Consumer 实例就如何消费订阅主题的所有分区达成共识的过程。在 Rebalance 过程中,所有 Consumer 实例共同参与,在协调者组件的帮助下,完成订阅主题分区的分配。但是,在整个过程中,所有实例都不能消费任何消息,因此它对 Consumer 的 TPS 影响很大。
触发条件
重平衡是消费者组应对变化的关键机制,但也可能带来问题,需要重点理解:
- 触发条件:
- 消费者组内新增或移除消费者(如节点宕机、新实例启动)。
- 订阅主题的分区数发生变更。Kafka 当前只能允许增加一个主题的分区数。当分区数增加时,就会触发订阅该主题的所有 Group 开启 Rebalance。
- 订阅主题数发生变更。Consumer Group 可以使用正则表达式的方式订阅主题,比如 consumer.subscribe(Pattern.compile("t.*c")) 就表明该 Group 订阅所有以字母 t 开头、字母 c 结尾的主题。在 Consumer Group 的运行过程中,你新创建了一个满足这样条件的主题,那么该 Group 就会发生 Rebalance。
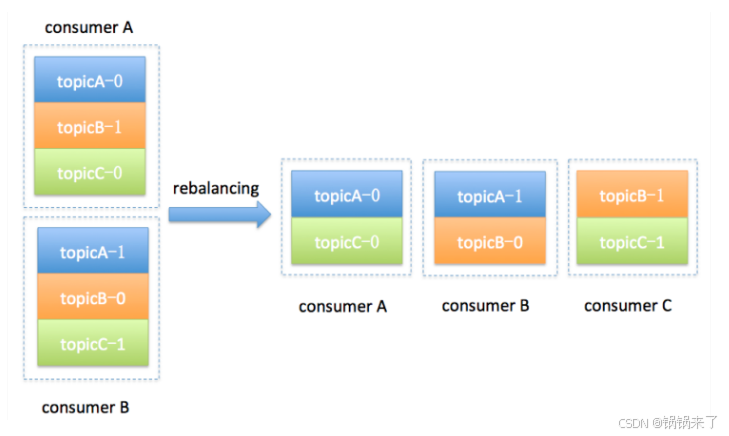
假设目前某个 Consumer Group 下有两个 Consumer,比如 A 和 B,当第三个成员 C 加入时,Kafka 会触发 Rebalance,并根据默认的分配策略重新为 A、B 和 C 分配分区,如下图所示
重平衡影响
重平衡期间,所有消费者会暂停消费,等待 Rebalance 完成。导致消息处理延迟。
频繁重平衡会严重影响消费效率,需尽量避免。