消息模型
- Producer:生产消息
- Consumer:消费消息
- Broker:Kafka 服务器,存储消息
- Topic:消息的分类,类似 "文件夹"
- Partition:Topic 分成多个分区,每个分区是有序、不可变的消息日志
- Offset:分区内每条消息的唯一序号
内存结构
topic是逻辑分层,而Partition是真实的物理分层
每个partition就是存储的一个文件夹,里面有三个文件组成
- .log 文件
真正的消息数据
消息按顺序存储 - .index 文件
稀疏索引
记录 offset → 文件位置(position)
用于快速定位消息 - .timeindex 文件(可选)
时间戳索引
用于按时间查找消息
经典问题
kafka为什么快
- 顺序写磁盘
- 零拷贝
- 批量处理
- 分区并行
- 页缓存(OS cache)
零拷贝是什么
零拷贝是指零CPU拷贝,不需要CPU去操作
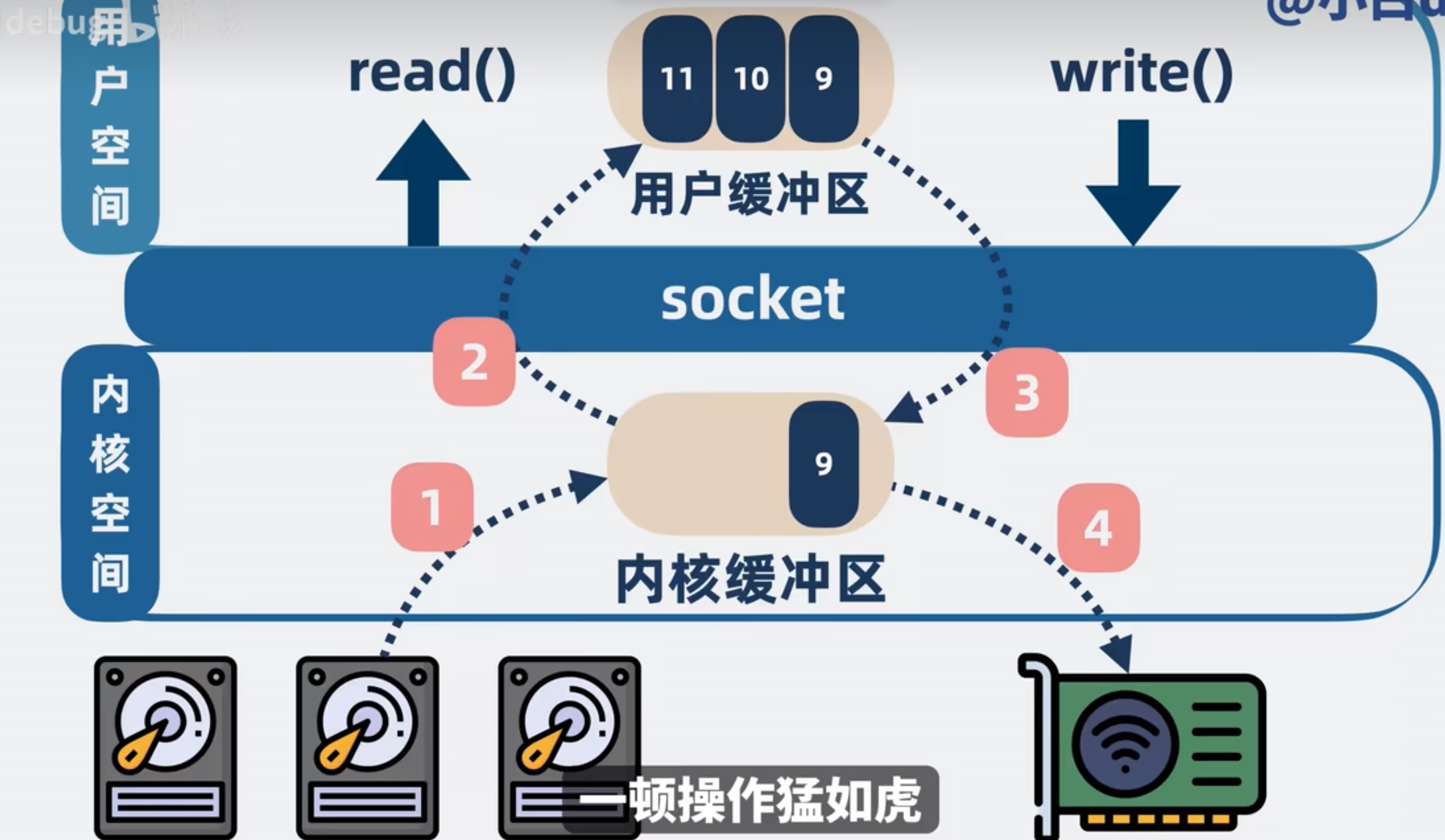
一次读取与发送程序都需要经过操作系统去操作磁盘,整体的流程如下:
需要经历四次内存拷贝,可以通过mmap跟sendfile去做到零拷贝
mmap
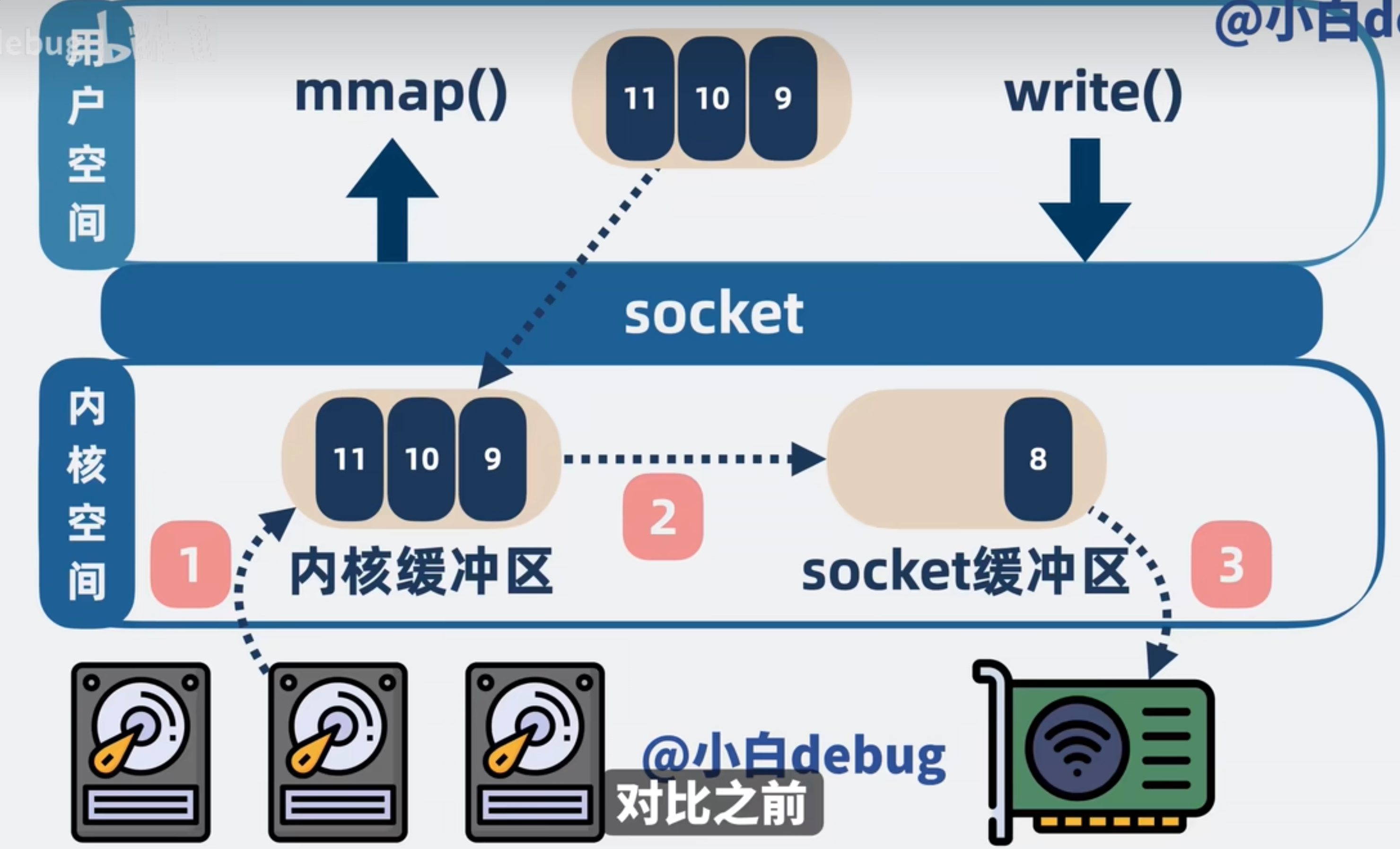
mmap是操作系统提供的一个方法,可以将内核空间的缓冲区映射到用户空间(在用户区开辟一个空间与内核缓冲区直接映射)
如下图:直接通过mmap将内核缓冲区映射到用户空间.省去了从用户区到内核区写入去发送这一步
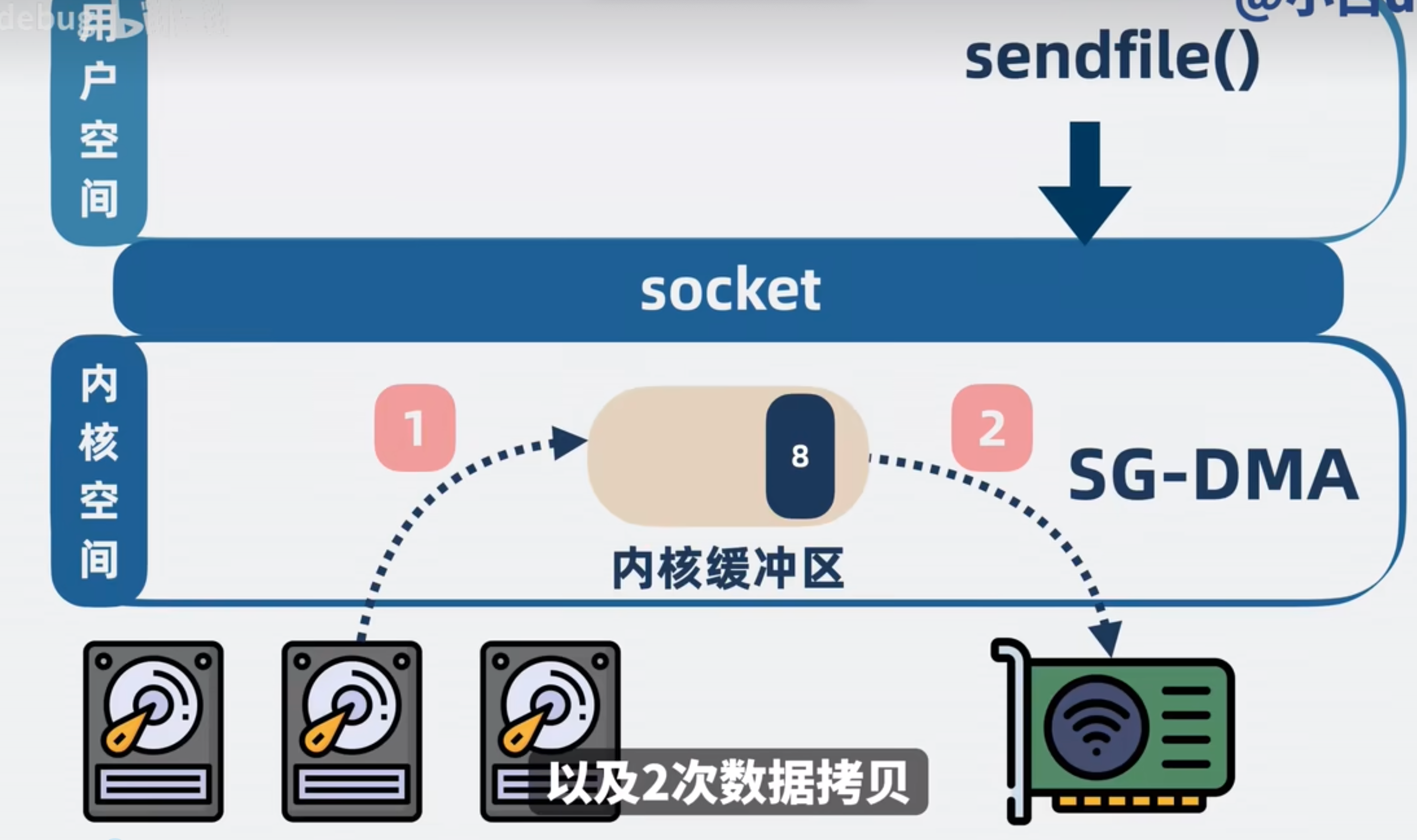
sendfile
sendfile是操作系统提供的一个方法.程序调用sendfile会将内核缓冲区直接写入网卡,不需要过用户内存
sendfile不需要CPU参与,而是DMA控制器直接操作就好。CPU还能正常运作
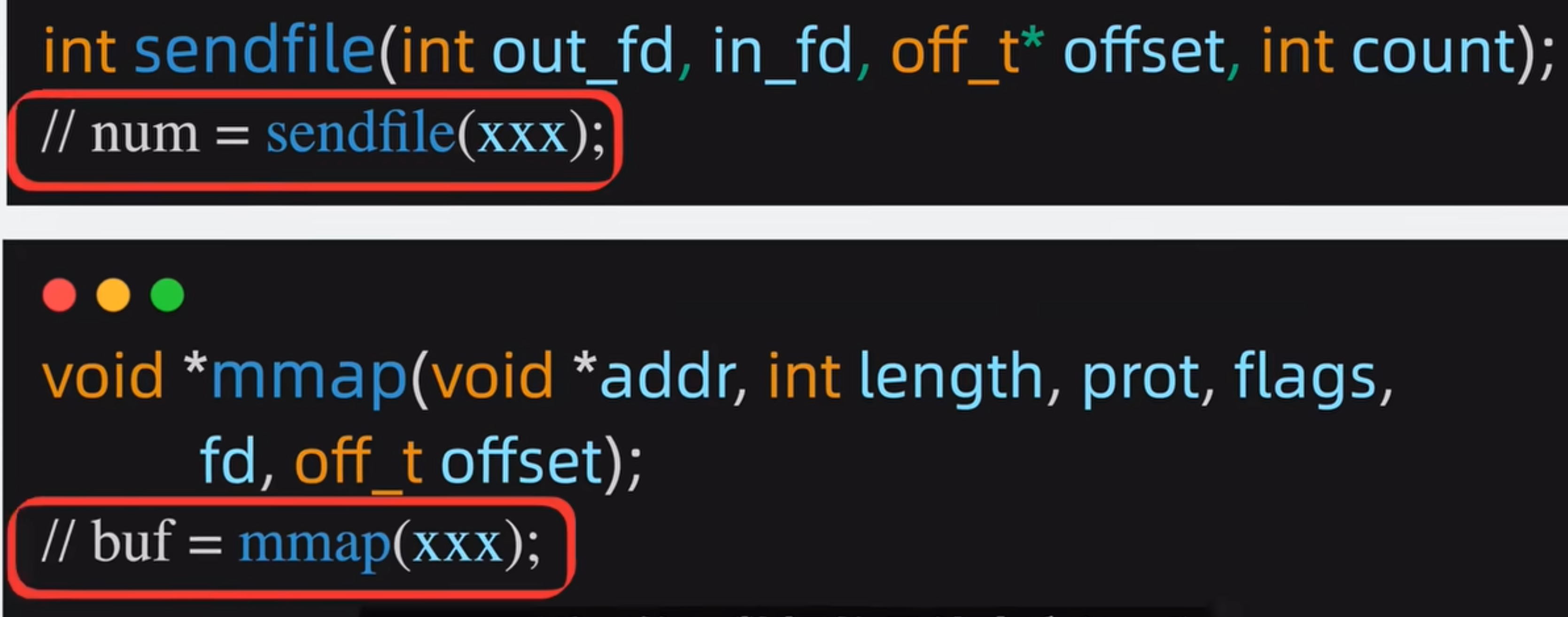
sendfile跟mmap区别
- sendfile返回发送数
- mmap返回发送的具体内容
- kafka使用的是sendfile,rocketMQ使用的是mmap,所以kafka更快
为啥rocketMQ不能使用sendfile?
关键点:Consumer 需要的消息在 CommitLog 中不是连续的 !
这意味着:
Broker 无法直接把 "磁盘上的一段连续数据" 发给 Consumer
必须在用户态把分散的消息读取、组装成一个完整的响应包
因此无法使用 sendfile
那 RocketMQ 为什么不改成 Kafka 那种结构?
RocketMQ 设计目标不同:
Kafka 更适合大数据吞吐量场景
RocketMQ 更适合金融级可靠性、低延迟、大量 Topic 的业务场景
RocketMQ 的 ConsumeQueue 结构让它能:
支持按 tag 过滤
支持消息重试
支持消息轨迹
支持事务消息
Kafka 的高可用是怎么实现的
- 副本机制
- ISR 列表
- Leader 负责读写
- Follower 同步数据
- 副本故障时从 ISR 中重新选举 Leader
ISR是什么?怎么保障数据高可用?
ISR用一句话讲解就是什么时候去ack成功
有以下几种常见枚举,可根据业务场景,自己去配置
- 写入主Broker则直接返回(无保障)
- 写入一主一备则返回
- 写入一主一半的备份则返回
- 主跟备全写完再返回
综上,业务测可以自己配置ISR去保障数据不丢失
为什么 Kafka 不支持读写分离?
读写分离是指,读取节点跟写入节点不是同一个(读的是读从节点)
为了保证一致性,Follower 可能落后 Leader,如果允许读 Follower,会出现数据不一致
Kafka 的消息是否会丢失?如何避免?
同ISR原理。可设置ack=all,设置全部写完再返回.
Kafka 的再平衡是什么?为什么会发生?
再平衡是Partition重新分配的过程。
触发条件:
- partition扩缩
影响: - 期间消费者无法消费消息
如何保证消息的顺序性?
- 单分区 + 单消费者
- 多分区无法保证全局顺序,但可以保证分区内顺序
- 生产者按 key 发送(相同 key 进入同一分区)(美团saas的支付消息就是这么保障的)
MQ推跟拉的读取方式主要区别是啥?
最大的点如下:
主动权不同
推:Broker 主动推送,broker逻辑更复杂,且可能击垮消费者(需要维护状态、连接、限流)
Pull:消费者 主动拉取 broker逻辑更简单(需要处理轮询、阻塞、消息堆积)