今天我们一起来学习一款团队自研的数据挖掘插件arff-output,首先先介绍下arff文件的相关知识。
1、什么是ARFF
ARFF(Attribute-Relation File Format)文件是一种专门用于数据挖掘工具Weka的数据格式。
ARFF文件主要由两部分组成:头部(Header)和数据部分(Data)。头部描述了数据集的元信息,包括数据集名称、关系(Relation)、属性(Attribute)和注释(Comment),而数据部分则包含具体的数据实例(Instance)。
@relation data
@attribute class {yes,no}
@attribute age numeric
@attribute income numeric
@data
yes,30,50000
no,25,30000在上述ARFF格式的头部信息中,定义了一个名为 data 的数据集,包含三个属性: class (类别,取值为 yes 或 no ), age (年龄,为数值类型)以及 income (收入,为数值类型)。接下来的数据部分则以 @data 标识开始,后面跟着具体的数据实例。
2、kettle 中生成arff文件
1)将自研插件arff-output.zip 解压直接放到kettle的plugins目录下面
2)重启spoon客户端。
3、设计流程
1)生成记录步骤模拟数据
2)arff-output步骤生成arff文件
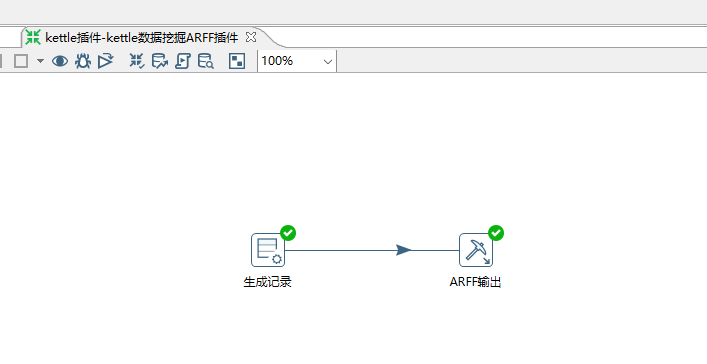
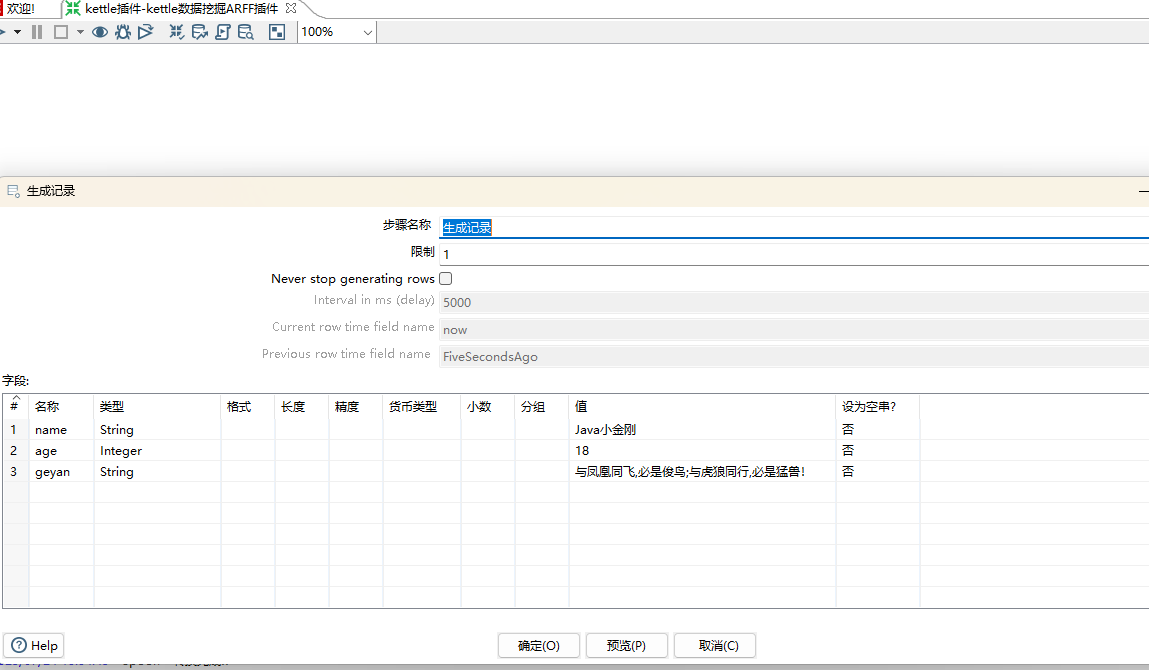
4、生成记录步骤设置
设置了三个字段name,age,geyan。限制设置为1,表示只执行一次。
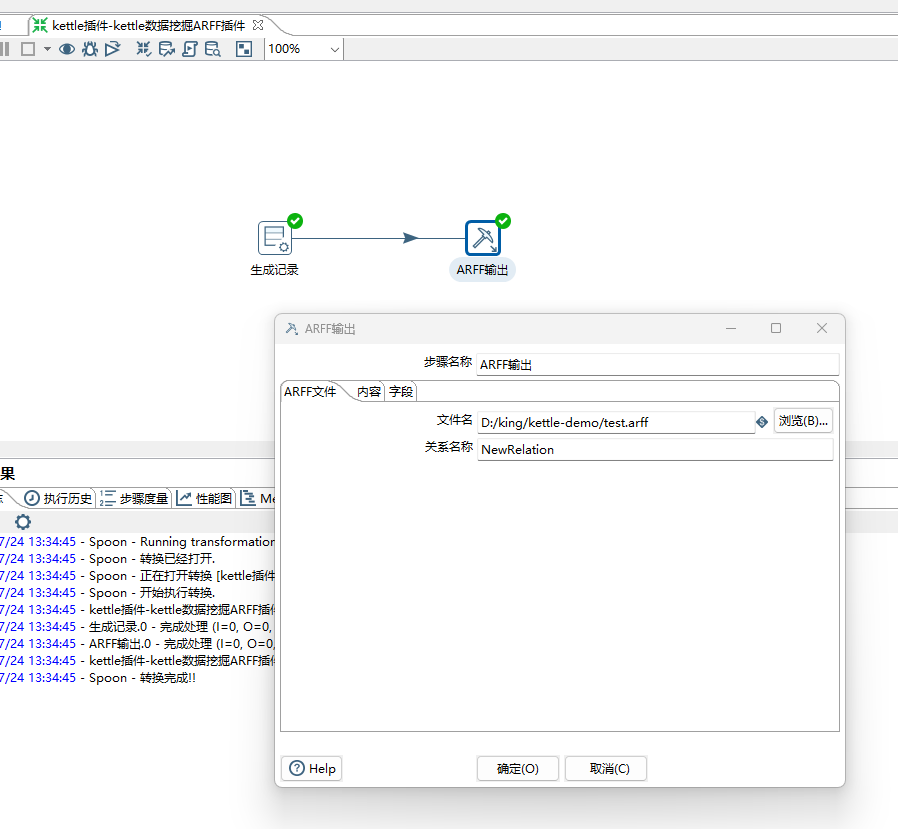
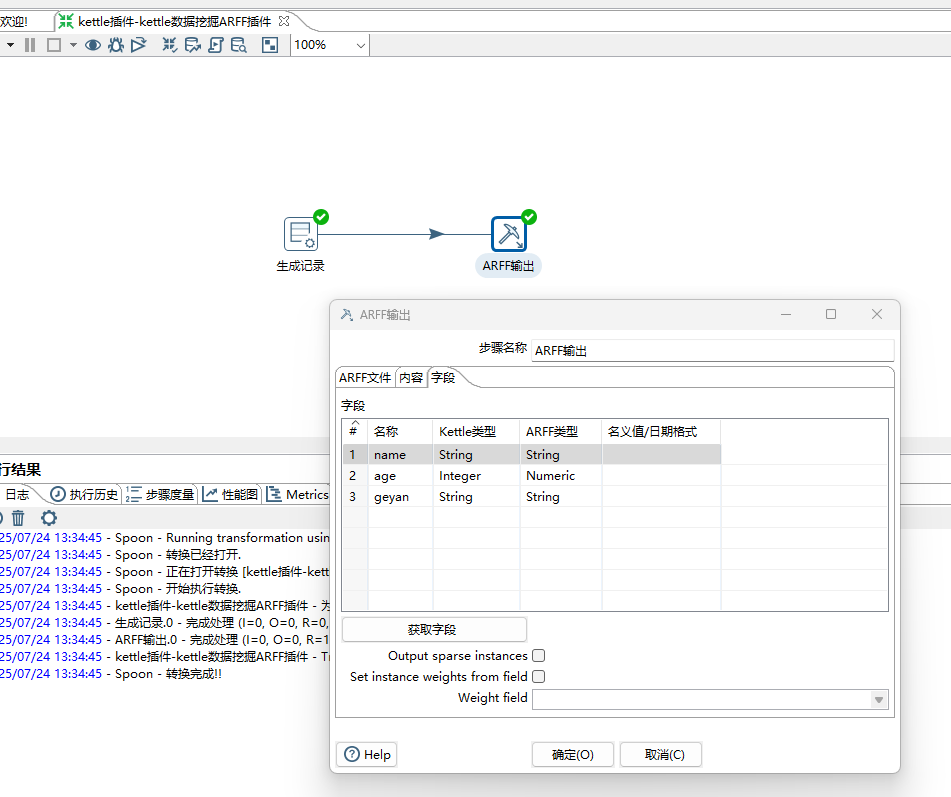
5、ARFF输出设置
1)设置文件路径和关系名称
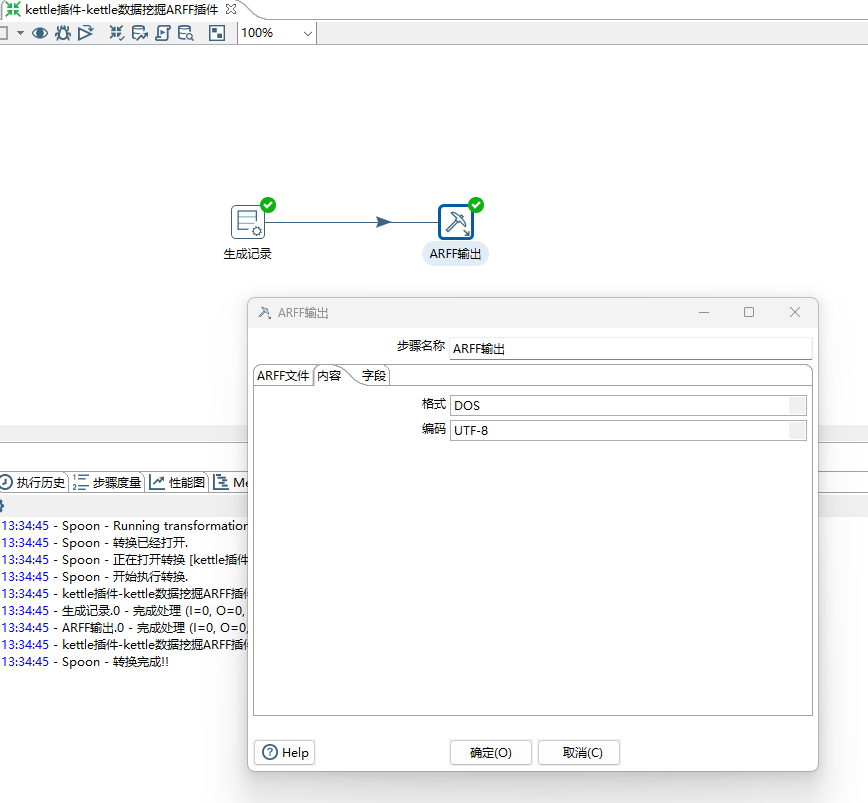
2)设置格式和编码
3)设置写入字段
6、保存&允许
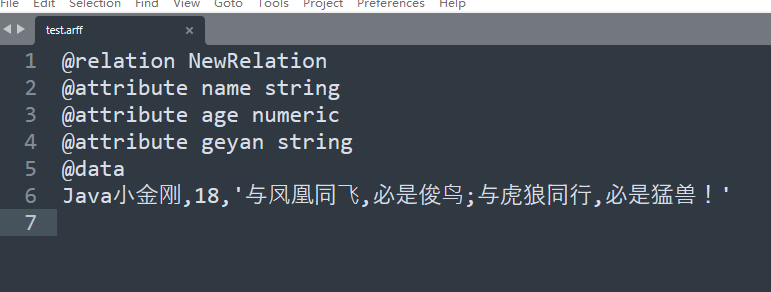
程序正常运行,生成文件test.arff,文件内容如下:
done!!!
