PDF作为广泛使用的文档格式,转换为轻量级标记语言Markdown后,可无缝集成到技术文档、博客平台和版本控制系统中,提高内容的可编辑性和可访问性。本文将详细介绍如何使用国产Spire.PDF for Python 库将 PDF 文档转换为 Markdown 格式。
技术优势:
- 精准保留原始文档结构(段落/列表/表格)
- 完整提取文本和图像内容
- 无需 Adobe 依赖的纯 Python 实现
- 支持 Linux/ Windows/ macOS 全平台
安装依赖
在使用之前,需要先安装该库。可以通过 pip 命令进行安装,具体步骤如下:
打开命令提示符(CMD)或终端,输入以下命令并回车:
pip install Spire.Pdf等待安装完成即可。
要移除水印,可**申请免费授权**后再应用:
python
from spire.pdf.common import *
from spire.pdf import *
# 应用授权
pdfLicense.SetLicenseKey(key)PDF转Markdown - Python代码
仅需以下5行核心代码就可以将PDF文档转换为Markdown格式:
python
from spire.pdf.common import *
from spire.pdf import *
# 加载PDF文档
pdf = PdfDocument()
pdf.LoadFromFile("测试.pdf")
# 将PDF转换为Markdown文件
pdf.SaveToFile("PDF转Markdown.md", FileFormat.Markdown)
pdf.Close()功能特点详解:
1. 文本转换
- 准确提取PDF中的文本内容
- 保留段落结构和换行
2. 格式保留
- 样式识别:自动检测字体样式(加粗、斜体)
- 列表处理:有序列表和无序列表转换
3. 表格转换
- 自动检测表格结构
- 保留行列对齐关系
4. 图像处理
- 图像默认会以Base64格式内嵌在Markdown文件中
提示: 对于扫描版PDF,建议先使用OCR工具进行文本识别再转换。
转换效果:
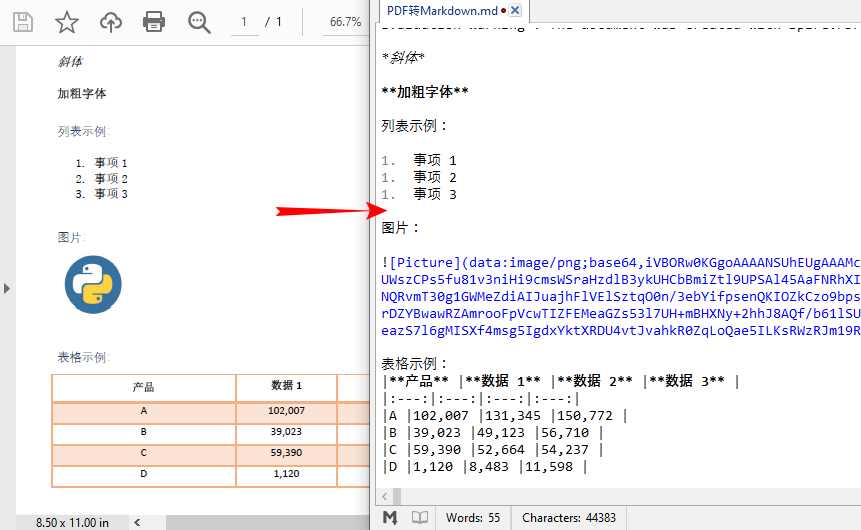
注意事项
- 转换后的 Markdown 文件可能需要进行一些微调,因为 PDF 的格式较为复杂,有时转换后的内容可能会存在一些格式上的小问题。
- 对于包含复杂布局或特殊格式的 PDF 文件,转换效果可能会受到一定影响,建议转换后仔细检查并进行必要的编辑。
- 确保输入的 PDF 文件路径和输出的 Markdown 文件路径正确,避免因路径错误导致转换失败。
- 当 PDF 文件较大或内容较多时,转换过程可能需要一定的时间,请耐心等待。
**结论:**通过Spire.PDF for Python,开发者可快速构建自动化文档转换工作流。虽然复杂排版可能需要微调,但其代码友好性简化了很多操作需求。
---------- 👇 技术问题 ----------