在前几章中,我们了解到知识图谱作为一种变革性工具出现,提供了一种结构化方式连接多样化的数据点,支持更智能的搜索、推荐和推理能力,应用范围广泛。
知识图谱擅长捕捉实体间复杂关系,是需要深度上下文理解的应用不可或缺的工具。
Neo4j 作为领先的图数据库技术平台,专注于构建和管理知识图谱。正如上一章所示,与传统关系型数据库不同,Neo4j 设计用于轻松处理高度关联的数据,实现更直观的查询和更快速的洞察获取。这使其成为希望将原始非结构化数据转化为有意义洞察、驱动AI应用的开发者和数据科学家的理想选择。
本章主要内容包括:
- 设计高效搜索的Neo4j图谱的考虑因素
- 利用电影数据集
- 结合代码示例构建电影知识图谱
- 进阶内容:复杂图结构的高级Cypher技巧
技术要求
成功完成本章练习,你需要准备以下工具:
-
Neo4j AuraDB :可使用Neo4j云端版本AuraDB,访问:neo4j.com/aura
-
Cypher查询语言 :需熟悉Cypher语法,因本章大量使用Cypher进行图创建与查询。详见:neo4j.com/docs/cypher...
-
Python :需安装Python 3.x,用于脚本编写和Neo4j数据库交互。官方下载:www.python.org/downloads/
-
Python库:
- Neo4j Python驱动:通过pip安装,命令为
pip install neo4j - pandas:用于数据处理与分析,命令为
pip install pandas
- Neo4j Python驱动:通过pip安装,命令为
-
集成开发环境(IDE) :推荐使用PyCharm、VS Code或Jupyter Notebook等高效管理Python代码的IDE
-
Git与GitHub:需具备基本Git知识进行版本控制,并拥有GitHub账号以访问本章代码仓库
-
电影数据集 :使用Movie Database (TMDb),可在Kaggle下载:www.kaggle.com/datasets/ro...
该数据集衍生自Movie Lens Datasets(F. Maxwell Harper and Joseph A. Konstan, 2015)。部分数据文件如credits.csv和ratings.csv由于存储限制可能未托管于GitHub,但你可通过GCS桶获取所有原始数据文件。
本章所有代码托管于GitHub仓库:github.com/PacktPublis...。
该文件夹包含使用电影数据集和Cypher代码构建Neo4j图谱所需的全部文件和脚本。
请确保克隆或下载该仓库,以便跟进本章中的代码示例,仓库中提供了访问GCS以获取原始数据文件的路径。
为高效搜索设计Neo4j图谱的考虑事项
一个设计良好的Neo4j图谱不仅能保证搜索功能的准确性,还能提升效率,实现快速检索相关信息。数据在图中的组织方式直接影响搜索结果的性能和相关性,因此理解有效图建模的原则至关重要。
本节将深入探讨正确构建Neo4j图谱结构的重要性,它如何影响搜索过程,以及设计图模型时需要重点关注的关键因素。
节点与关系类型定义的考虑
回顾第3章,任何Neo4j图谱的基础都是节点和关系。节点表示实体,如电影或人物(例如演员或导演),而关系定义这些实体之间的连接方式。你选择的节点和关系类型在决定搜索查询的效果中起着关键作用。
在电影数据集中,传统上节点可能分别代表不同实体,如电影(Movies)、演员(Actors)、导演(Directors)和类别(Genres)。关系则描述这些节点如何互动,例如ACTED_IN、DIRECTED或BELONGS_TO。但还有一种更高效的替代方法------将相似实体合并为单一节点类型。
与其为演员和导演分别创建节点,不如创建单一的Person节点。每个Person节点的具体属性------是演员、导演,还是两者兼有------由其与电影节点之间的关系类型决定。例如,Person节点通过ACTED_IN关系连接到电影节点,表示该人是电影的演员;通过DIRECTED关系连接则表示该人为导演。我们将在后续章节创建完整图谱。
为什么这种方法更优?
正如第3章所示,这种方法带来以下优势:
- 简化数据模型
使用单一的Person节点同时表示演员和导演,使数据模型更简洁,降低图的复杂度,便于理解和管理。 - 提升查询性能
节点类型减少,图数据库在查询时能更高效地遍历关系,因为数据库引擎需要区分的实体更少,查询执行更快。 - 减少冗余
统一的Person节点避免重复信息存储。对于既是演员又是导演的人,无需创建两个节点,减少冗余,节省存储空间。 - 灵活的关系定义
此方法支持更灵活且细粒度的关系定义。如果一个人在不同电影中扮演多重角色(如一部电影出演,一部电影导演),关系可以清晰区分这些角色,无需多个节点。 - 便于维护和扩展
随着数据集增长,维护简洁的节点结构愈发重要。新增角色或关系时,操作更简单高效。
通过谨慎选择和定义节点类型及关系,你能够构建一个贴合真实世界连接的图结构,使搜索查询更直观,结果更具意义,整体系统效率更高。
索引和约束对搜索性能的影响
随着Neo4j图谱的不断增长,索引和约束的重要性日益凸显。索引使Neo4j能够快速定位查询的起点,极大提升搜索性能,尤其是在大规模数据集中。而约束则保证数据完整性,防止创建重复节点或无效关系。
在我们使用统一Person节点表示演员和导演的电影数据集中,索引变得尤为关键。你可以基于节点属性如person_name或role建立索引,确保针对特定人物或其在电影中角色的搜索能够迅速返回结果。例如,你可以在关系的role属性(如ACTED_IN或DIRECTED)上建立索引,以便快速筛选某人在特定电影中的参与角色。
约束对于维护图谱的完整性同样必不可少。以下是一些示例,展示如何针对电影数据集创建约束和索引。这些示例涵盖了常见场景,如保证person标识的唯一性,以及优化节点和关系属性上的搜索性能。你可以根据具体使用场景和数据质量,调整这些模式以保障数据完整性和提升查询速度。
-
person_name的唯一约束(简化场景)
在许多情况下,比如我们的电影数据集中,假设每个人名唯一,你可以对person_name属性施加唯一约束,确保每个个体只对应一个节点,即使他们在不同电影中担任多个角色(演员、导演等)。示例如下:
sqlCREATE CONSTRAINT unique_person_name IF NOT EXISTS FOR (p:Person) REQUIRE p.person_name IS UNIQUE;这样有助于避免重复节点的产生,保持图谱整洁高效。
-
更可靠的唯一ID约束(如person_id)
上述唯一性约束基于对数据的假设,而实际场景中常见同名不同人。
此时应使用更可靠的标识符,如来自外部源(IMDb或TMDb)的person_id,来保证唯一性。示例代码:
sqlCREATE CONSTRAINT unique_person_id IF NOT EXISTS FOR (p:Person) REQUIRE p.person_id IS UNIQUE; -
person_name索引(若不强制唯一性)
若不强制唯一约束但频繁按名称查找人物,可为person_name属性建立索引,加快查询速度:
cssCREATE INDEX person_name_index IF NOT EXISTS FOR (p:Person) ON (p.person_name); -
Movie的title属性索引
电影常按标题查询,尤其在推荐系统和搜索功能中。对title属性建索引能保证快速定位电影:
scssCREATE INDEX movie_title_index IF NOT EXISTS FOR (m:Movie) ON (m.title); -
ACTED_IN关系的role属性索引
若应用需按角色类型(主角、客串等)过滤演员,为ACTED_IN关系的role属性建立索引,有助于避免全量扫描关系,加速查询:
scssCREATE INDEX acted_in_role_index IF NOT EXISTS FOR ()-[r:ACTED_IN]-() ON (r.role);
注意
Neo4j仅在5.x及以上版本支持关系属性索引。
合理实施索引和约束,可增强图谱的健壮性,使搜索过程更快、更可靠。这不仅提升用户体验,还能减轻系统计算负载,助力解决方案的可扩展性。
下一节,我们将探讨如何利用公开电影数据集的力量,构建你的图谱。
利用电影数据集
本节将重点介绍如何使用TMDb(The Movie Database)数据集,这是一个在Kaggle上提供的全面元数据集合:www.kaggle.com/datasets/ro...。该数据集包含丰富的电影信息,如标题、类型、演员、工作人员、上映日期和评分等。拥有超过45,000部电影以及详细的相关人员信息,这个数据集为构建能够捕捉电影行业复杂关系的Neo4j图谱提供了坚实基础。
你将使用该数据集将数据建模为知识图谱,学习如何在实际环境中进行数据集成。你将了解如何获取、准备并导入数据到Neo4j中。
在处理像TMDb这样的大型数据集时,确保数据干净、一致且结构合理,是集成到Neo4j图谱前的关键步骤。尽管原始数据包含丰富信息,但往往存在不一致、冗余及复杂结构,这会影响知识图谱的性能和准确性。因此,数据规范化和清洗非常必要。
为什么要规范化和清洗数据?
构建Neo4j图谱时,保持数据清洁和规范化至关重要,因为它直接影响应用的质量和性能。通过规范化和清洗数据,可以确保一致性、提升效率,并为分析创建可扩展的基础。具体原因如下:
- 一致性
原始数据中相似信息的记录方式可能存在差异。例如,电影类型可能以不同格式出现,甚至有重复。规范化能保证相似数据点以统一格式记录,便于查询和分析。
现实数据集中解决这些问题往往具有挑战性。Neo4j提供了强大功能,如Cypher模式匹配、APOC过程用于合并节点和去重,以及图数据科学库中的节点相似性算法,帮助识别并合并相关实体。这些能力使你能构建一个清洁可靠、真实反映数据结构的图谱。 - 效率
规范化数据能减少冗余,从而提升Neo4j图谱的效率。通过将数据组织成标准格式,减少存储需求,优化查询性能。 - 准确性
清洗数据包括删除或修正不准确记录,确保从图谱中获得的洞察基于准确可靠的数据。 - 可扩展性
清洁且规范化的数据集更易于扩展。随着数据集增长,保持标准化结构有助于图谱管理,并保证系统在负载增加时依然高效运行。
接下来,我们将开始清洗和规范化CSV文件的步骤。
清洗和规范化CSV文件
现在,我们将清洗并规范化TMDb数据集中的每个CSV文件。数据集中包含的CSV文件如下:
credits.csv
该文件包含数据集中每部电影的演员和工作人员详细信息,格式为字符串化的JSON对象。我们重点提取与角色、演员、导演和制片人相关的字段:
ini
# 读取CSV文件
df = pd.read_csv('./raw_data/credits.csv')
# 提取演员信息函数
def extract_cast(cast_str):
cast_list = ast.literal_eval(cast_str)
return [
{
'actor_id': c['id'],
'name': c['name'],
'character': c['character'],
'cast_id': c['cast_id']
}
for c in cast_list
]
# 提取工作人员信息函数
def extract_crew(crew_str):
crew_list = ast.literal_eval(crew_str)
relevant_jobs = ['Director', 'Producer']
return [
{
'crew_id': c['id'],
'name': c['name'],
'job': c['job']
}
for c in crew_list if c['job'] in relevant_jobs
]
# 应用提取函数
df['cast'] = df['cast'].apply(extract_cast)
df['crew'] = df['crew'].apply(extract_crew)
# 将列表拆分成单独的行
df_cast = df.explode('cast').dropna(subset=['cast'])
df_crew = df.explode('crew').dropna(subset=['crew'])
# 规范化拆分的数据
df_cast_normalized = pd.json_normalize(df_cast['cast'])
df_crew_normalized = pd.json_normalize(df_crew['crew'])
# 重置索引以避免重复
df_cast_normalized = df_cast_normalized.reset_index(drop=True)
df_crew_normalized = df_crew_normalized.reset_index(drop=True)
# 删除重复行
df_cast_normalized = df_cast_normalized.drop_duplicates()
df_crew_normalized = df_crew_normalized.drop_duplicates()
# 添加电影ID
df_cast_normalized['tmdbId'] = df_cast.reset_index(drop=True)['id']
df_crew_normalized['tmdbId'] = df_crew.reset_index(drop=True)['id']
# 保存规范化数据
df_cast_normalized.to_csv(os.path.join(output_dir, 'normalized_cast.csv'), index=False)
df_crew_normalized.to_csv(os.path.join(output_dir, 'normalized_crew.csv'), index=False)
# 显示样例数据进行验证
print("规范化演员数据样例:")
print(df_cast_normalized.head())
print("规范化工作人员数据样例:")
print(df_crew_normalized.head())keywords.csv
此文件包含每部电影的剧情关键词,有助于分类和主题识别,支持搜索、推荐和内容分析等功能:
ini
# 读取CSV文件
df = pd.read_csv('./raw_data/keywords.csv') # 根据实际路径调整
# 规范化关键词函数
def normalize_keywords(keyword_str):
if pd.isna(keyword_str) or not isinstance(keyword_str, str):
return []
keyword_list = ast.literal_eval(keyword_str)
return [kw['name'] for kw in keyword_list]
# 应用规范化
df['keywords'] = df['keywords'].apply(normalize_keywords)
# 合并每个tmdbId的所有关键词
df_keywords_aggregated = df.groupby('id', as_index=False).agg({
'keywords': lambda x: ', '.join(sum(x, []))
})
# 重命名列
df_keywords_aggregated.rename(columns={'id': 'tmdbId'}, inplace=True)
# 保存合并后的数据
df_keywords_aggregated.to_csv(os.path.join(output_dir, 'normalized_keywords.csv'), index=False)
# 显示数据验证
print(df_keywords_aggregated.head())links.csv 和 links_small.csv
- links.csv:连接完整MovieLens数据集中的电影与TMDb和IMDb的关键元数据文件。虽有重要性,但本项目当前不使用该文件,侧重其他更相关CSV文件。未来需要整合外部数据库时,该文件依然有价值。
- links_small.csv:MovieLens的9000部电影的TMDb和IMDb ID精简版。我们不使用此文件,因已采用完整Kaggle数据集。
movies_metadata.csv
该文件包含45000部电影的详细信息,如海报、预算、收入、上映日期、语言、制片国家及公司等。为了有效管理与分析,我们将其拆分并规范化成多个CSV文件,分别对应数据中的节点类别,如类型(genres)、制片公司(production companies)、制片国家(production countries)和语言(spoken languages)。这样便于管理和利用丰富信息。
示例代码(仅展示genres和production companies部分,完整代码见GitHub):
scss
import pandas as pd
import ast
df = pd.read_csv('./raw_data/movies_metadata.csv') # 根据实际路径调整
# 规范化类型字段
def extract_genres(genres_str):
if pd.isna(genres_str) or not isinstance(genres_str, str):
return []
genres_list = ast.literal_eval(genres_str)
return [{'genre_id': int(g['id']), 'genre_name': g['name']} for g in genres_list]
# 规范化制片公司字段
def extract_production_companies(companies_str):
if pd.isna(companies_str) or not isinstance(companies_str, str):
return []
companies_list = ast.literal_eval(companies_str)
if isinstance(companies_list, list):
return [{'company_id': int(c['id']), 'company_name': c['name']} for c in companies_list]
return []
# 应用规范化
df['genres'] = df['genres'].apply(extract_genres)
df['production_companies'] = df['production_companies'].apply(extract_production_companies)
df['production_countries'] = df['production_countries'].apply(extract_production_countries)
df['spoken_languages'] = df['spoken_languages'].apply(extract_spoken_languages)
# 拆分列表成行
df_genres = df.explode('genres').dropna(subset=['genres'])
df_companies = df.explode('production_companies').dropna(subset=['production_companies'])
df_countries = df.explode('production_countries').dropna(subset=['production_countries'])
df_languages = df.explode('spoken_languages').dropna(subset=['spoken_languages'])
# 规范化genres
df_genres_normalized = pd.json_normalize(df_genres['genres'])
df_genres_normalized = df_genres_normalized.reset_index(drop=True)
df_genres_normalized['tmdbId'] = df_genres.reset_index(drop=True)['id']
df_genres_normalized['genre_id'] = df_genres_normalized['genre_id'].astype(int)
# 保存规范化数据
df_genres_normalized.to_csv(os.path.join(output_dir, 'normalized_genres.csv'), index=False)集合名称提取
python
def extract_collection_name(collection_str):
if isinstance(collection_str, str):
try:
collection_dict = ast.literal_eval(collection_str)
if isinstance(collection_dict, dict):
return collection_dict.get('name', "None")
except (ValueError, SyntaxError):
return "None"
return "None"
df_movies = df[['id', 'original_title', 'adult', 'budget', 'imdb_id', 'original_language',
'revenue', 'tagline', 'title', 'release_date', 'runtime', 'overview', 'belongs_to_collection']].copy()
df_movies['belongs_to_collection'] = df_movies['belongs_to_collection'].apply(extract_collection_name)
df_movies['adult'] = df_movies['adult'].apply(lambda x: 1 if x == 'TRUE' else 0) # 转换adult为整数
df_movies.rename(columns={'id': 'tmdbId'}, inplace=True) # 重命名id为tmdbId
df_movies.to_csv('./normalized_data/normalized_movies.csv', index=False)ratings.csv 与 ratings_small.csv
- ratings.csv:包含270,000用户对45,000电影的2600万评分和75万标签。此数据详细记录用户互动,虽有价值,但本项目不使用。
- ratings_small.csv:ratings.csv的子集,包含700用户对9000电影的10万评分。本项目采用此小规模文件,便于处理。
通过以上步骤,我们学会了如何将原始非结构化数据转化为清晰、规范的数据集,为后续导入Neo4j图谱做好准备。这为构建稳健、高效的AI驱动搜索与推荐系统奠定了基础。下一节,我们将使用这些规范化的CSV文件,并通过Cypher代码构建知识图谱,充分发挥数据集的潜力。
用代码示例构建你的电影知识图谱
本节中,我们将导入你已规范化的数据集到Neo4j,并将其转化为一个功能完整的知识图谱。
设置你的AuraDB免费实例
要开始使用Neo4j构建知识图谱,首先需要创建一个AuraDB Free实例。AuraDB Free是Neo4j的云托管数据库,帮助你快速开始,无需担心本地安装或基础设施管理。
创建实例的步骤如下:
- 访问 console.neo4j.io。
- 使用Google账号或邮箱登录。
- 点击"Create Free Instance"创建免费实例。
- 实例创建过程中,会弹出窗口显示数据库的连接凭证。
请务必下载并安全保存以下信息,这些是连接你的应用程序与Neo4j所必需的:
ini
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>当AuraDB Free实例配置完成后,你就可以导入已规范化的数据集,并使用Cypher代码开始构建你的知识图谱了。接下来的章节将引导你完成数据导入及图中关系的构建。
将数据导入 AuraDB
现在你的 AuraDB 免费实例已经启动运行,接下来是导入规范化的数据集并构建知识图谱。在本节中,我们将通过一个 Python 脚本,演示如何准备 CSV 文件、设置索引与约束、导入数据以及创建关系:
准备 CSV 文件
确保你生成的 CSV 文件(如 normalized_movies.csv、normalized_genres.csv 等)已准备好导入。文件应清晰、结构良好,并托管在可访问的 URL 上。本示例中,graph_build.py 脚本会从公共云存储(例如 storage.googleapis.com/movies-pack...)自动获取文件,无需你手动上传。
添加索引和约束以优化查询
在加载数据之前,创建唯一约束和索引非常关键,能保证数据完整性并提升查询性能。脚本包含如下 Cypher 命令示例:
sql
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);导入数据并创建节点
在添加约束和索引后,脚本会从相应 CSV 文件加载节点:
load_movies()加载所有电影元数据load_genres()、load_production_companies()、load_countries()等加载对应的类型节点,如 Genre、ProductionCompany、Country、SpokenLanguageload_person_actors()和load_person_crew()加载与人物相关的数据- 额外属性通过
load_links()、load_keywords()和load_ratings()添加
例如:
rust
graph.load_movies('https://storage.googleapis.com/movies-packt/normalized_movies.csv', movie_limit)创建关系
每个加载函数不仅创建节点,也建立有意义的关系,比如:
- Movie 与 Genre 之间的
HAS_GENRE - Movie 与 ProductionCompany 之间的
PRODUCED_BY - Movie 与 SpokenLanguage 之间的
HAS_LANGUAGE - Movie 与 Country 之间的
PRODUCED_IN - Movie 与 Person 之间的
ACTED_IN、DIRECTED、PRODUCED - Movie 与 User 之间的
RATED等
运行完整脚本
确保已安装 Neo4j Python 驱动,安装命令:
pip install neo4j然后执行完整图谱构建脚本:
python graph_build.py脚本执行流程:
- 使用
.env文件中的凭据连接 AuraDB 实例 - 清理数据库
- 添加索引和约束
- 使用托管的 CSV 批量加载所有节点数据及关系
完整脚本请参考:
github.com/PacktPublis...
验证导入
导入完成后,可用 Neo4j Browser 验证数据:
less
MATCH (m:Movie)-[:HAS_GENRE]->(g:Genre)
RETURN m.title, g.genre_name
LIMIT 10;图4.1展示了一个包含超过9万个节点和32万个关系的连通电影图谱。节点如 Movie、Genre、Person、ProductionCompany 用不同颜色表示,关系如 ACTED_IN、HAS_GENRE、PRODUCED_BY 展示了相互连接的元数据网络。
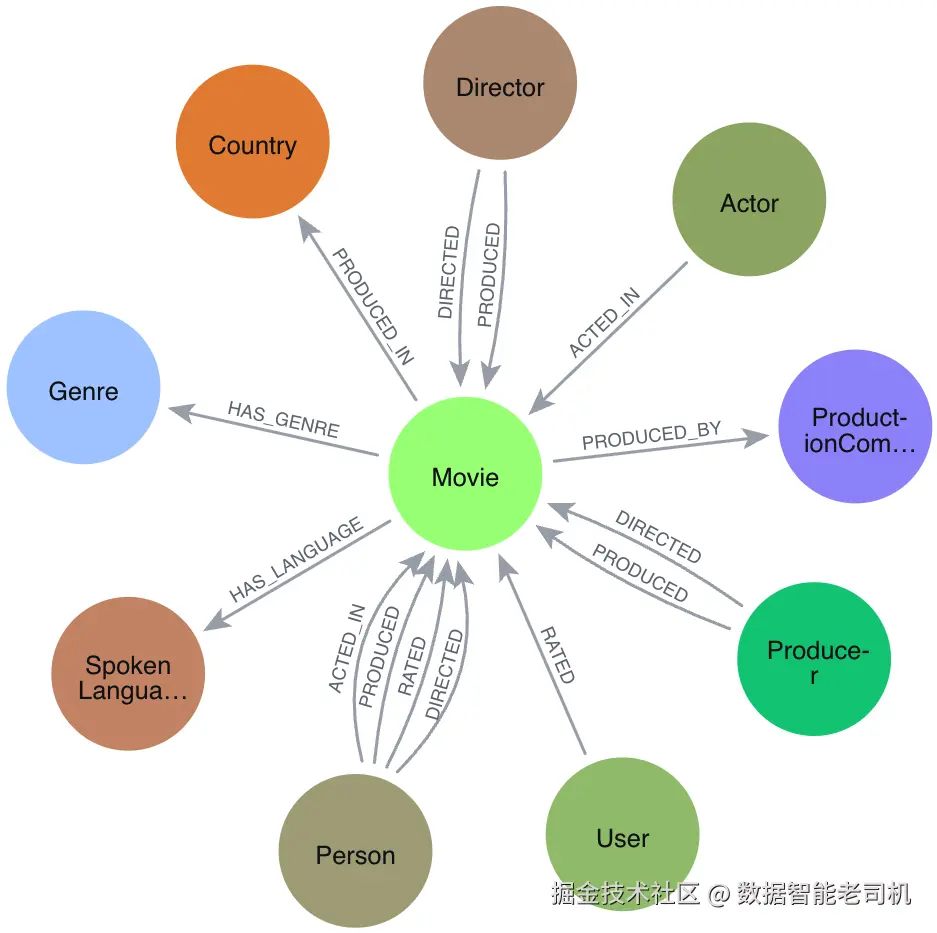
成功导入数据并使用 Python 和 Cypher 完成知识图谱构建后,你已准备好在下一章构建基于生成式人工智能(GenAI)的搜索应用。在接下来的部分,我们将深入介绍高级 Cypher 技巧,助你处理复杂关系并从数据中提炼更深层次的洞见。
超越基础:应对复杂图结构的高级 Cypher 技巧
随着你的知识图谱规模和复杂度不断增长,对查询和数据管理能力的要求也随之提升。Neo4j 强大的查询语言 Cypher 提供了一系列高级功能,专门用来处理复杂的图结构,并支持更为复杂的数据分析。在本节中,我们将探讨这些高级 Cypher 技巧,包括路径模式、可变长度关系、子查询以及图算法。理解这些技巧将帮助你高效管理复杂的关系,进行更深入的分析,释放知识图谱在高级场景中的全部潜力。
让我们一起深入了解以下关键的高级 Cypher 技巧:
可变长度关系(Variable-length relationships)
Cypher 中的可变长度关系允许你匹配节点之间路径长度可变的关系。这在探索层级结构或多级分离的网络时尤为有用。例如,查找某演员三度关系内所有相关的电影:
css
MATCH (a:Actor {name: 'Tom Hanks'})-[:ACTED_IN*1..3]-(m:Movie)
RETURN DISTINCT m.title;这里,*1..3 指定关系路径长度在1到3步之间。
使用场景:可变长度关系非常适合社交网络分析(比如查找某人一定度数内的所有联系人),或者层级数据中探索多层父子关系。
路径模式匹配(Pattern matching with path patterns)
你可以在 Neo4j 中定义命名的路径模式,并且可以将路径模式进行链式组合。
- 定义路径模式:Cypher 允许你定义可复用的命名路径模式,这使查询更具可读性,并将复杂关系封装成单一模式。例如:
ini
MATCH path = (a:Actor)-[:ACTED_IN]->(m:Movie)
RETURN path;这里 path 是一个命名的路径模式,可以在后续操作或子查询中复用。
- 链式路径模式:Cypher 支持将多个路径模式组合,以执行复杂的图遍历。此功能在揭示间接关系或发现满足特定条件的多条路径时非常实用。
举个例子,探索电影数据集中合作关系:
假设想找出某演员与其曾合作导演的电影,可能通过另一部电影间接关联。即,从演员到电影,再到导演,然后查找另一个不同的电影也连接该演员和导演:
scss
MATCH (a:Actor {name: "Tom Hanks"})-[:ACTED_IN]->(m1:Movie)<-[:DIRECTED_BY]-(d:Director)
MATCH (a)-[:ACTED_IN]->(m2:Movie)<-[:DIRECTED_BY]-(d)
WHERE m1 <> m2
RETURN a.name AS actor, d.name AS director, collect(DISTINCT m1.title) + collect(DISTINCT m2.title) AS movies;这种链式模式极大地帮助识别专业关系、反复合作或分析网络中的间接影响。
子查询与过程逻辑(Subqueries and procedural logic)
你可以使用子查询和存储过程来处理复杂查询。
- 模块化查询的子查询:Cypher 的子查询允许将复杂查询拆分成模块化、可复用的组件。这在处理大图或对同一数据集执行多次操作时非常有用。示例:
scss
CALL {
MATCH (m:Movie)-[:HAS_GENRE]->(g:Genre {name: 'Action'})
RETURN m
}
MATCH (m)-[:DIRECTED_BY]->(d:Director)
RETURN d.name, COUNT(m) AS action_movies_directed;这里,子查询先检索所有动作片,外层查询则匹配这些电影的导演。
- CALL 过程调用的过程逻辑 :Cypher 的
CALL语句允许调用存储过程,并在后续查询中使用结果。它是进行高级数据处理的关键,如运行图算法或调用自定义过程。
例如,我们在 graph_build.py 文件的 load_ratings() 函数中使用了 CALL { ... } IN TRANSACTIONS 模式,批量处理大数据集,每次处理 5 万行:
sql
LOAD CSV WITH HEADERS FROM $csvFile AS row
CALL (row) {
MATCH (m:Movie {movieId: toInteger(row.movieId)})
WITH m, row
MERGE (p:Person {user_id: toInteger(row.userId)})
ON CREATE SET p.role = 'user'
MERGE (p)-[r:RATED]->(m)
ON CREATE SET r.rating = toFloat(row.rating), r.timestamp = toInteger(row.timestamp)
} IN TRANSACTIONS OF 50000 ROWS;该方式保证了导入大规模 CSV 时的性能与事务完整性,是 CALL 在实际图应用中的强大用例之一。
- 嵌套查询:在复杂图结构中,可能需要将多个查询结果组合。Cypher 允许嵌套查询,将一个查询的结果传递给另一个,用于多条件过滤或结果精炼。示例:
sql
MATCH (m:Movie)
WHERE m.revenue > 100000000
CALL {
WITH m
MATCH (m)-[:HAS_GENRE]->(g:Genre)
RETURN g.name AS genre
}
RETURN m.title, genre;这里,嵌套查询先筛选收入超过1亿的电影,然后找出它们所属的类型。
这些 Cypher 技巧使你能够应对复杂的图结构,实现更深层次的洞察和更复杂的分析。你可以访问 neo4j.com/docs/cypher... 进一步探索这些技巧。
小结
本章中,我们将原始的半结构化数据转化为干净且规范化的数据集,为知识图谱的集成做好准备。接着,我们探讨了图建模的最佳实践,重点讲解了如何构建节点和关系,以提升搜索效率,并确保图谱的可扩展性与性能表现。随后,我们学习了更多 Cypher 技巧,掌握了处理可变长度关系、路径模式匹配、子查询以及图算法的能力。现在,你已经准备好构建能够处理复杂数据关系的知识图谱驱动搜索系统。
在下一章,我们将更进一步,探索如何将 Haystack 集成到 Neo4j 中。这份实用指南将教你如何在知识图谱中构建强大的搜索功能,充分发挥 Neo4j 和 Haystack 的优势,实现智能搜索解决方案。