GPU并行计算是什么?
GPU(Graphics Processing Unit Parallel Computing)并行计算是一种利用图形处理单元的硬件架构,通过大规模并行执行来加速计算任务的技术。
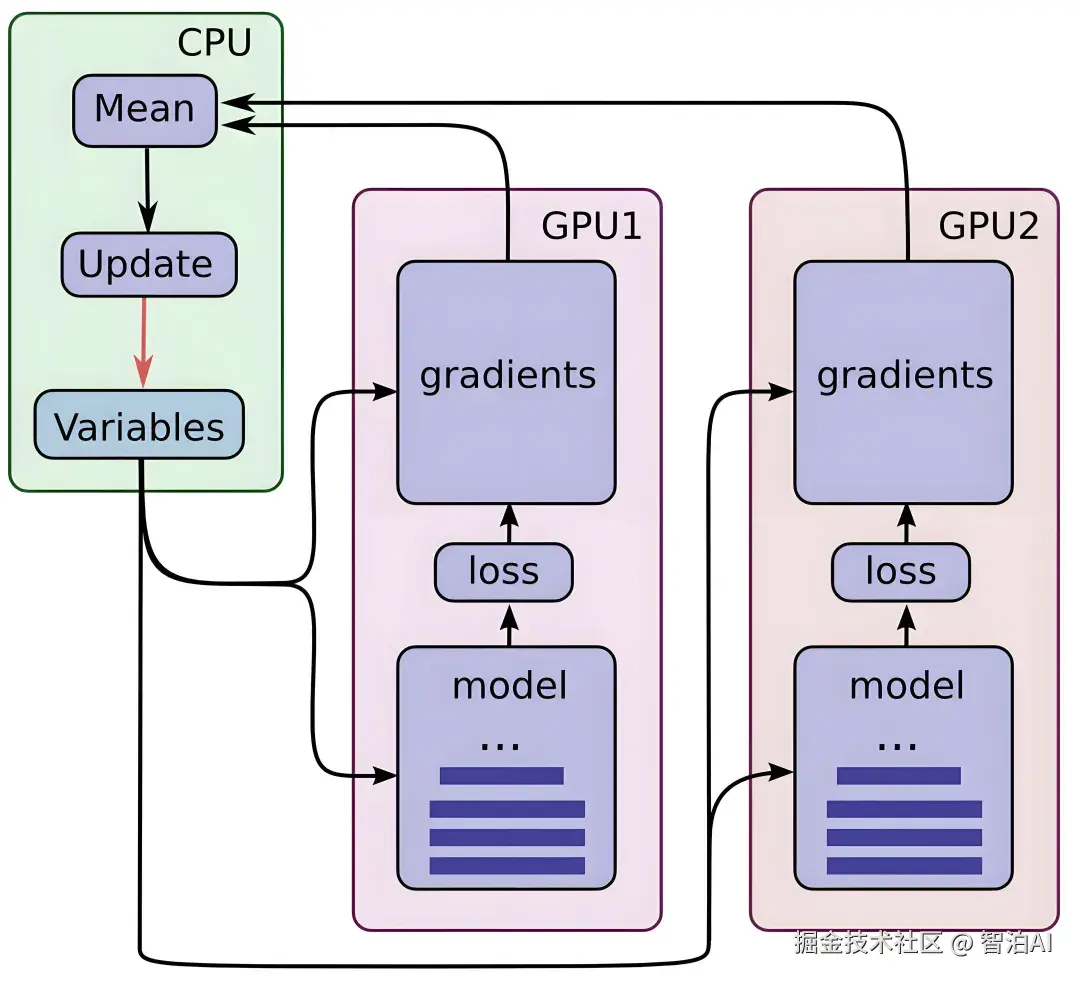
GPU由数千个计算核心组成,专为处理数据密集型应用设计,如渲染图形或科学模拟。
它采用SIMT(单指令多线程)模型,允许同时操作多个数据线程,显著提升吞吐量和效率。与CPU相比,GPU更擅长批量处理统一数据类型,但需CPU控制调用。
讲人话
GPU并行就像雇一群小工人一起干活:GPU是专门干"体力活"的芯片,里面有成千上万个核心,能同时处理大量简单任务(比如算一堆数字或画像素)。
而CPU是"大脑",负责指挥和复杂逻辑。GPU适合批量工作,比如游戏画面渲染或A学习,速度超快,但自己不会动,得听CPU安排。
GPU并行计算的原理
GPU并行原理源于其硬件架构:多个流处理器(SM)各含数十个CUDA核心,支持SIMT执行,单指令驱动多线程并行计算。
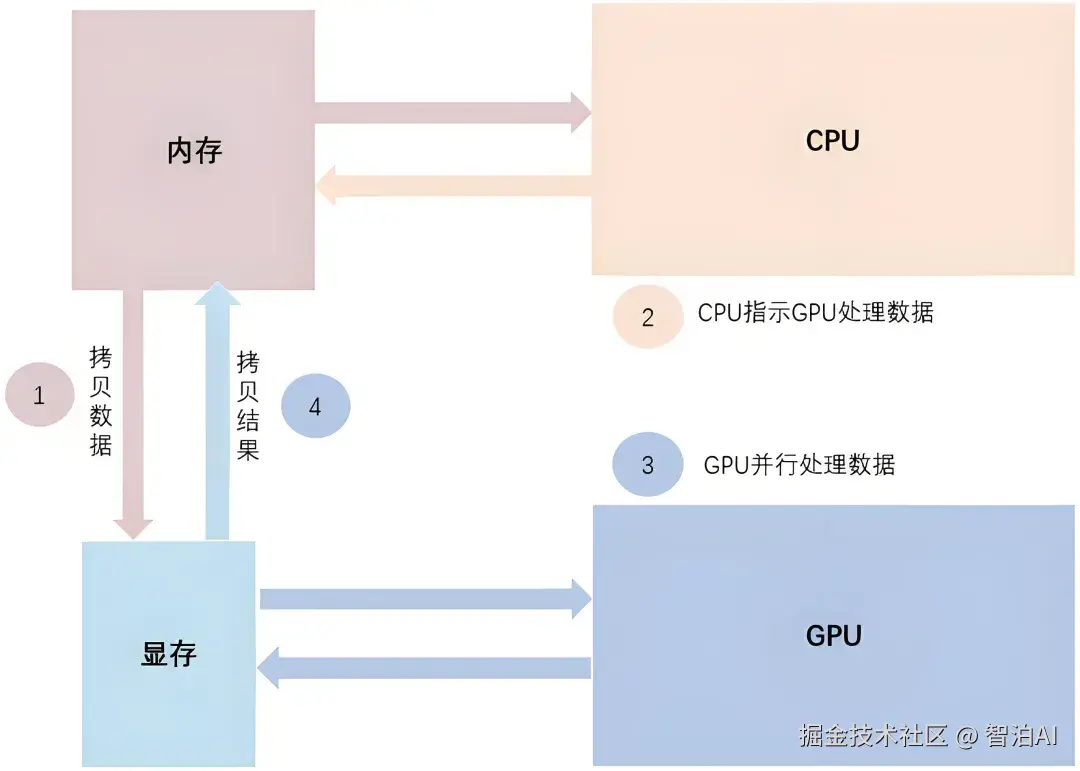
数据通过内存带宽优化(如共享内存和L2缓存)高效传输,避免CPU的串行瓶颈。
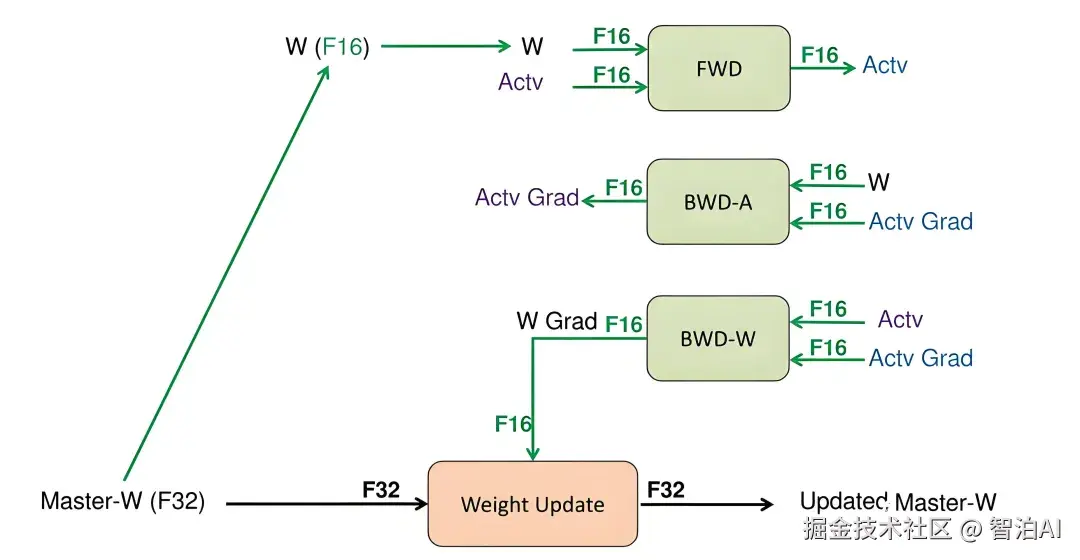
编程模型如CUDA或OpenCL抽象化硬件,让开发者将任务分解为可并行部分,利用GPU的算力密度(峰值计算能力远超CPU)。
核心技术包括线程块组织和数据局部性优化,以隐藏延迟并提升吞吐量。
讲人话
原理是GPU内部像工厂流水线:每个小核心(工人)同时干一样的活但不同数据(比如算1000个像素点)。
CPU发指令,GPU用超多核心"并行爆发",速度飙升。为啥快?因为它专为批量设计,内存带宽大,能避免CPU的"排队"问题。
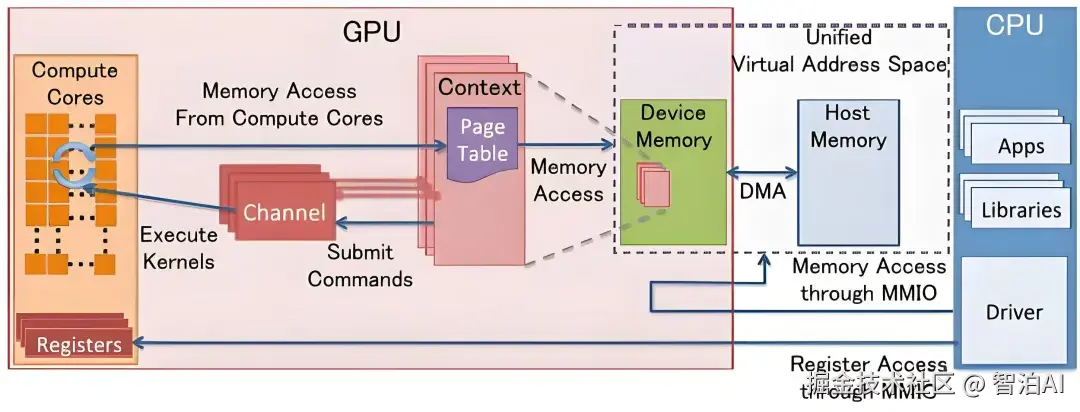
技术如CUDA让程序员轻松写代码调用GPU。但注意,GPU只负责"可并行"部分,复杂逻辑还得CPU处理。
GPU并行计算实践案例
深度学习: TensorFlow/PyTorch框架用GPU加速大模型训练,实现百倍速度提升(如LLM训练),通过数据并行和优化显存管理。
科学计算: 赫歇尔天文台用GPU并行处理远红外数据,加速星际介质分析。
医疗成像: 光学相干断层成像(OCT)中,GPU实时处理非线性-k空间问题,提升诊断效率。
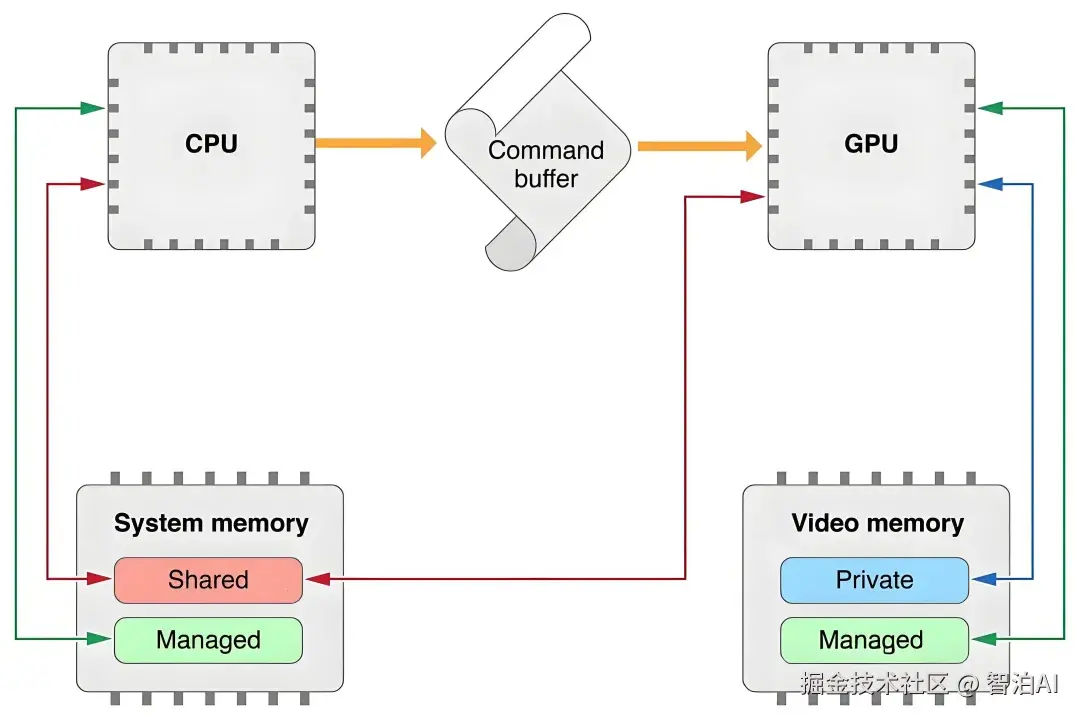
讲人话
实际应用超多:AI领域,GPU让ChatGPT学习快如闪电(TensorFlow自动分配任务);天文台用GPU分析星星数据,省时省力;医生做眼部OCT检查时GPU帮忙秒出图像。
游戏里物理效果(比如爆炸碎片)靠GPU批量计算,流畅又真实。工具如PyTorch点一下代码就能用GPU。
这些案例证明GPU在批量任务中碾压CPU,但需注意高并发时资源限制。
总结
总之,GPU并行就是"人多力量大":利用GPU的数千核心同时处理数据,大幅加速计算。
它专为图形、A1、科学等批量任务设计,原理是SIMT流水线操作(核心们齐步走),但需CPU当"指挥官"。
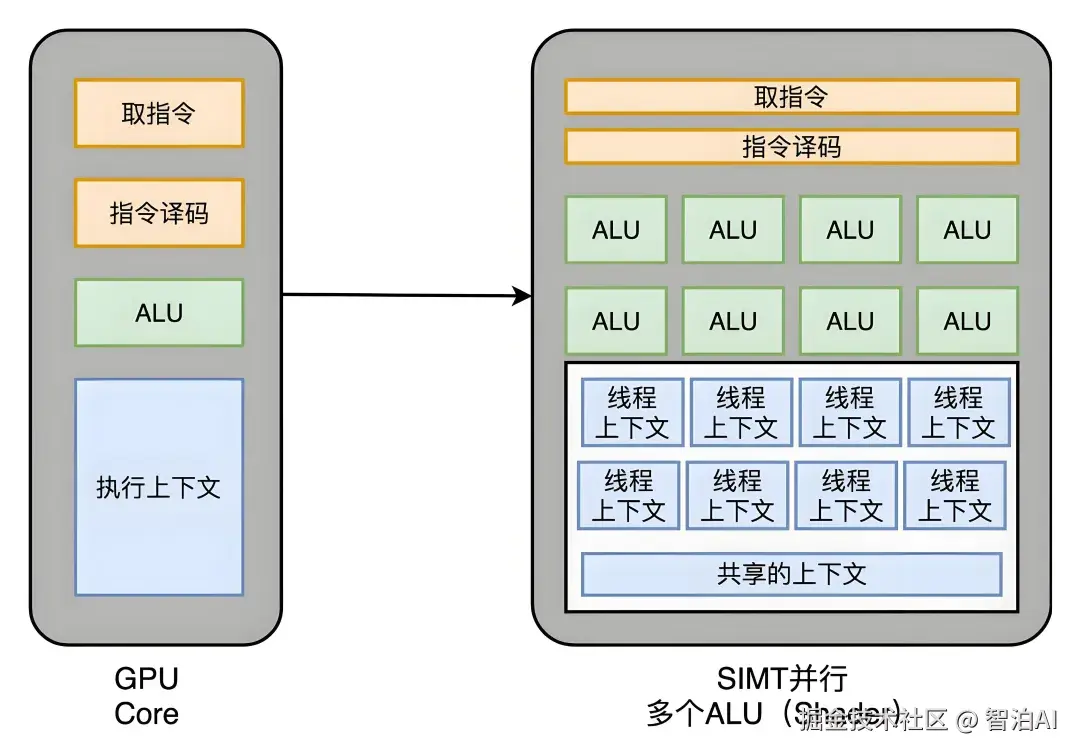
实际中,深度学习、医疗成像等案例已证明其威力,工具如CUDA让开发更简单。
未来GPU集群将更强大,但记住,它不是万能,复杂逻辑还得靠CPU配合。核心价值是高效并行,让计算飞起来!