摘要:原文探讨了TimeGPT,一个为时间序列预测而设计的生成式预训练Transformer模型。文章详细介绍了其零样本推理、微调能力、API访问、外生变量支持、多序列预测等功能,并提供了使用Python进行数据准备、预测、趋势分类和不确定性量化的代码示例。
文章目录
- [1 什么是TimeGPT](#1 什么是TimeGPT)
-
- [1.1 特性和功能](#1.1 特性和功能)
- [1.2 入门](#1.2 入门)
- [2 使用TimeGPT进行预测](#2 使用TimeGPT进行预测)
-
- [2.1 准备数据](#2.1 准备数据)
- [2.2 使用TimeGPT预测未来值](#2.2 使用TimeGPT预测未来值)
- [3 TimeGPT模型选择:短序列 vs 长序列](#3 TimeGPT模型选择:短序列 vs 长序列)
-
- [3.1 分类趋势](#3.1 分类趋势)
- [3.2 可视化结果](#3.2 可视化结果)
- [3.3 不确定性量化](#3.3 不确定性量化)
- [3.4 使用TimeGPT进行分位数预测](#3.4 使用TimeGPT进行分位数预测)
- [4 结论](#4 结论)
1 什么是TimeGPT
TimeGPT是一个生产就绪、生成式、预训练的Transformer,用于时间序列。TimeGPT模型不基于任何现有的大型语言模型(LLM)。相反,它是在大量时间序列数据上独立训练的,大型Transformer模型旨在最小化预测误差。
您可以通过https://dashboard.nixtla.io上的托管API将TimeGPT无缝集成到您的应用程序中。TimeGPT还通过Azure Studio提供支持,以实现更灵活的集成选项。或者,您可以在自己的基础设施上部署TimeGPT,以保持对数据和工作流的完全控制。
TimeGPT还提供了一个功能,可以在您的特定数据集上微调模型,使模型能够适应您独特时间序列数据的细微差别,并增强在定制任务上的性能。
- TimeGPT在免费套餐中提供每月10,000次API请求的免费试用。
- 通过仪表板获取API密钥。
1.1 特性和功能
- 低代码:用户友好且低代码。用户可以上传时间序列数据,并用一行代码生成预测或检测异常。能够在各个领域准确预测时间序列值。
- 零样本推理:开箱即用即可生成预测和检测异常,无需先前的训练数据。能够立即部署并从任何时间序列数据中快速获得见解。
- 添加外生变量:此功能允许合并可能影响预测的附加变量(例如特殊日期、事件或价格),从而提高预测准确性。
- 多序列预测:支持同时预测多个时间序列,优化工作流和资源。
- 特定损失函数:允许在微调期间选择不同的损失函数,以满足特定的性能指标。
- 交叉验证:提供内置的交叉验证技术,以确保模型的鲁棒性和泛化能力。
- 预测区间:在预测中提供区间,以有效量化不确定性。
- 不规则时间戳:处理具有不规则时间戳的数据,适应非均匀间隔序列,无需预处理。
- 异常检测:自动检测时间序列中的异常,并可使用外生特征增强性能。
在本文中,我们将探讨零样本预测,将其用于趋势检测和预测区间以量化不确定性。
1.2 入门
要安装TimeGPT:
python
!pip install pandas numpy matplotlib nixtla2 使用TimeGPT进行预测
在预测之前,处理时间序列中的缺失数据非常重要。由于数据收集不规律、中断或其他问题,可能会出现缺失的时间戳或值。数据中的空白会对模型性能产生负面影响,并导致预测不准确。
如何填补时间序列数据中的空白:
- 填补空白涉及通过插入缺失的时间戳来确保您的时间序列具有规律的频率(例如,每日、每小时)。
- 填补空白后,可以使用插值方法估计缺失值。
常见的插值方法:
- 线性插值:通过用直线连接已知数据点来估计缺失值。适用于变化平缓的数据。
- 前向/后向填充:使用前一个或后一个可用值填充缺失值。适用于分类或变化缓慢的数据。
- 样条插值:使用多项式函数进行更平滑的估计,非常适合具有非线性趋势的数据。
- 均值/中位数插补:用序列的均值或中位数替换缺失值。简单但可能无法捕捉局部模式。
选择正确的插值方法取决于您的数据特征和领域。
2.1 准备数据
python
import pandas as pd
# 加载时间序列数据(列:'timestamp', 'close')
df = pd.read_csv('ohlcv.csv')
df['timestamp'] = pd.to_datetime(df['timestamp'])
df = df.sort_values('timestamp')
df['unique_id'] = 'id1'
from utilsforecast.preprocessing import fill_gaps
print('填补空白前的行数:', len(df))
train_df_complete = fill_gaps(df, freq='D', time_col='timestamp')
train_df_complete.head()
train_df_complete['close'] = train_df_complete['close'].interpolate(method='linear', limit_direction='both')
# 其他插值选项:
# train_df_complete['close'] = train_df_complete['close'].interpolate(method='spline', order=2, limit_direction='both') # 样条插值
# train_df_complete['close'] = train_df_complete['close'].fillna(method='ffill') # 前向填充
# train_df_complete['close'] = train_df_complete['close'].fillna(method='bfill') # 后向填充
# train_df_complete['close'] = train_df_complete['close'].fillna(train_df_complete['close'].mean()) # 均值插补
# train_df_complete['close'] = train_df_complete['close'].fillna(train_df_complete['close'].median()) # 中位数插补
print('填补空白后的行数:', len(train_df_complete))2.2 使用TimeGPT预测未来值
python
from dotenv import load_dotenv
import os
from nixtla import NixtlaClient
variables = load_dotenv()
api_key = os.environ.get("TIMEGPT_API_KEY")
nixtla_client = NixtlaClient(api_key=api_key)
nixtla_client.validate_api_key()
hist = train_df_complete
forecast = nixtla_client.forecast(
hist,
h=36, freq="D",
time_col="timestamp",
target_col="close",
model="timegpt-1-long-horizon",
)
print(forecast.head())3 TimeGPT模型选择:短序列 vs 长序列
TimeGPT提供了几种针对不同预测视距优化的模型变体:
- timegpt-1-short-horizon:专为短期预测(例如,未来几天或几周)设计。当您需要对近期预测具有高精度且您的时间序列表现出强烈的短期模式时,请使用此模型。
- timegpt-1-long-horizon:专为长期预测(例如,未来几个月)优化。当您需要预测遥远的未来且您的数据具有较长期的趋势或周期时,建议使用此模型。
- timegpt-1:适用于大多数用例的通用模型。如果您不确定视距或想要一种平衡的方法,请从此模型开始。
您应该使用哪个模型?
- 对于短视距 预测(例如,下周的每日销售额),请使用
timegpt-1-short-horizon。 - 对于长视距 预测(例如,下一季度的能源需求),请使用
timegpt-1-long-horizon。 - 对于一般用途或实验,请使用
timegpt-1。
在调用API时,在model参数中指定模型:
python
forecast = nixtla_client.forecast(
hist,
h=36, freq="D",
time_col="timestamp",
target_col="close",
model="timegpt-1-long-horizon",
)3.1 分类趋势
python
import numpy as np
def classify_trend(values):
"""根据值的斜率对趋势进行分类"""
x = np.arange(len(values))
y = np.array(values)
coef = np.polyfit(x, y, 1)[0]
if coef > 0.01:
return "上升趋势"
elif coef < -0.01:
return "下降趋势"
else:
return "平稳"
trend = classify_trend(forecast["TimeGPT"])
print("预测趋势:", trend)3.2 可视化结果
python
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
plt.plot(df['timestamp'], df['close'], label='历史数据')
plt.plot(forecast['timestamp'], forecast['TimeGPT'], label='预测数据')
plt.title(f"TimeGPT预测 - 趋势: {trend}")
plt.xlabel('日期')
plt.ylabel('值')
plt.legend()
plt.show()3.3 不确定性量化
在时间序列预测中,重要的是考虑预测的完整概率分布,而不是单个点估计。这为预测的不确定性提供了更准确的表示,并允许更好的决策。TimeGPT通过分位数预测和预测区间支持不确定性量化。
分位数预测解释: 分位数预测估计了未来观测值中有一定百分比预期会低于的值。例如,第90个分位数(或百分位数)表示90%的未来值预期会低于此阈值。通过为多个分位数(例如,10%、50%、90%)生成预测,您可以构建捕获未来可能结果范围的预测区间。
分位数预测如何提供帮助:
- 它们提供了未来的概率视图,而不仅仅是单个预测值。
- 您可以评估极端结果的风险(例如,异常高或低的值)。
- 通过了解可能情景的范围和可能性,可以改进决策。
- 分位数预测在不确定性和风险管理至关重要的领域(例如,金融、供应链、能源)尤其有用。
- 0.5分位数(第50个百分位数)代表中位数预测。
- 0.1和0.9分位数(第10和第90个百分位数)显示了预测的外部边界。
我们可以检查上升和下降趋势预测是否适用于预测的外部边界。
3.4 使用TimeGPT进行分位数预测
python
quantile_forecast = nixtla_client.forecast(
hist,
h=36, freq="D",
time_col="timestamp",
target_col="close",
model="timegpt-1-long-horizon",
quantiles=[0.1, 0.5, 0.9]
)
print(quantile_forecast[["timestamp", "TimeGPT-0.1", "TimeGPT-0.5", "TimeGPT-0.9"]].head())
trend = classify_trend(quantile_forecast["TimeGPT-q-10"])
print("预测趋势 10:", trend)
trend = classify_trend(quantile_forecast["TimeGPT-q-90"])
print("预测趋势 90:", trend)我们还可以检查实际值是否接近或突破预测边界。这预计会在突然的冲击(急剧上升或下降)期间发生。在这样的波动期间,如果是预测用例,我们将避免预测,直到我们检测到强劲的趋势;在异常检测用例中,波动期将提供异常的强烈指示。
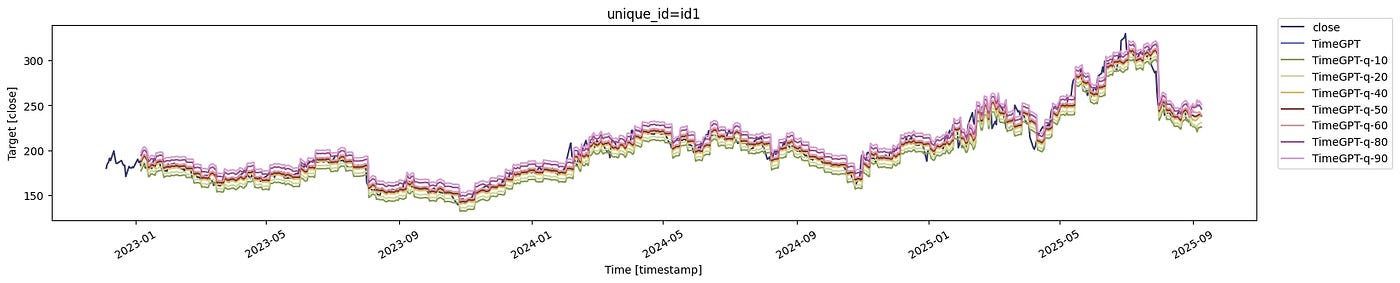
检查实际值在分位数带内的覆盖范围。
- 如果模型校准良好,大约80%的实际点应位于q=10和q=90之间 。在大部分历史记录(2023-2024年)中,实际的
close值整齐地保持在q=10-q=90带内。它们也聚集在**中位数预测(q=50)**附近,这表明偏差较低。 - 在2025年初 左右,实际值急剧上升,虽然它们仍然大多保持在q=10-q=90之间,但偶尔会触及上边界(q=90) 。在2025年中期 左右出现急剧下降,实际值短暂地超出了预测带------这表明模型低估了该时期的波动性。
解释
- ✅ 模型通常校准良好:大多数实际值落在10-90%的区间内。
- ⚠️ 在突然的冲击(急剧上升或下降)期间,实际值接近或突破预测边界。这表明模型在高波动性时期信心不足。
- 扇形展开(带随时间变宽)是一个好属性------它承认了不确定性的增加。
- 如果您关心风险控制,您可能会加宽带(q=5和q=95)以捕捉极端波动。
有关最新的模型选项和指导,请参阅TimeGPT文档。
4 结论
本文介绍了TimeGPT如何将Transformer模型应用于时间序列预测。工作流包括模型设置、预测和趋势分类。
有关AI、预测分析和建模的更多信息,请考虑订阅时事通讯以获取教程、访谈和研究更新。
反馈和讨论: 在评论中分享您对TimeGPT的问题或经验。