树的深处,宝藏何在?------我的日志系统重构与层序遍历的奇遇记 😎
嘿,各位在代码世界里探索的朋友们!我是你们的老伙计,一个坚信"万物皆可抽象"的开发者。今天,我想和大家聊聊最近在项目中遇到的一个棘手问题,以及我是如何从一道经典的算法题------LeetCode 513. 找树左下角的值------中找到灵感,并最终优雅地解决它的。这趟旅程,充满了"噢,原来如此!"的恍然大悟,一起来看看吧!
我遇到了什么问题?
我正在维护一个复杂的分布式任务调度系统。系统会创建一个主任务,主任务再派生出多个子任务,子任务可能还会继续派生......这就自然形成了一棵"任务树"。
最近系统出了个偶发性的问题,排查起来非常头疼。为了定位问题,我需要在故障发生时,快速找到最后一批被同时调度 的子任务中,第一个开始执行的那一个,然后捞取它的详细日志进行分析。
这个需求翻译成"人话"就是:
- 最后一批 :意味着任务树的最底层。
- 第一个开始执行 :因为我的任务是按顺序从左到右创建的,所以它就是最底层节点中的最左边那一个。
瞧,我面对的现实问题,被完美地抽象成了这道算法题:找出二叉树最底层、最左边的节点值。
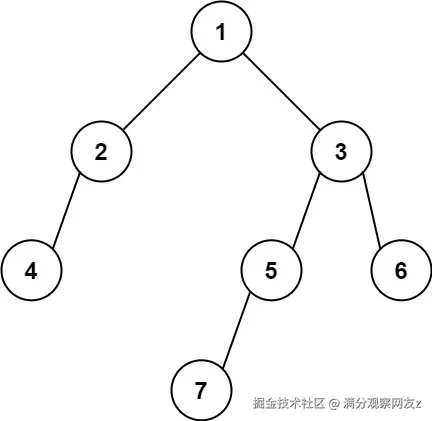
注意事项
在动手之前,瞄一眼题目的提示总是好习惯:
- 节点数在
[1, 10^4]:这个量级不算太大,意味着无论是深度优先(DFS)还是广度优先(BFS),在时间和空间上都是可行的,不用太担心递归爆栈。 Node.val范围:就是标准的int,没啥特别的。- 树中至少有一个节点:太棒了,省去了处理
root为null的初始边界情况。
我是如何用"遍历"找到宝藏的
解法一:广度优先搜索(BFS)------最直观的层层推进
广度优先搜索(BFS)是解决这个问题的最直观方法。BFS的特性是层序遍历,它会逐层地、从左到右地探索树的节点。这个特性与题目的要求"最底层"、"最左边"完美契合。
我们的策略如下:
- 使用一个队列(Queue)来进行层序遍历。
- 我们一整层一整层地处理节点。在每一层开始处理之前,队列里存储的就是当前这一整层的节点。
- 因此,在每一层的处理循环开始时,队列的队首元素 (
queue.peek()) 就是这一层的最左边的节点。 - 我们用一个变量
result来记录下每一层最左边节点的值。 - 当整个BFS过程结束时,
result变量里存储的自然就是最后一层(即最底层)的最左边节点的值。
这个方法的巧妙之处在于,它利用了BFS的内在顺序,不断用更深层级的最左节点值去覆盖之前层级的,最终留下的就是答案。
java
/*
* 思路:广-度优先搜索(BFS)。利用队列实现层序遍历,这是最符合"分层"思想的解法。
* 我们逐层遍历,在每一层开始前,队首的元素一定是该层最左边的节点。
* 我们用一个变量result持续记录每层最左边的节点值,当遍历结束,result的值自然就是最后一层最左边的值。
* 时间复杂度:O(N),每个节点入队出队一次。
* 空间复杂度:O(W),W是树的最大宽度,用于队列。
*/
import java.util.Queue;
import java.util.LinkedList;
class Solution {
public int findBottomLeftValue(TreeNode root) {
// Queue是接口,LinkedList是其经典实现,提供高效的FIFO(先进先出)操作。
Queue<TreeNode> queue = new LinkedList<>();
// offer()用于入队,相比add(),在有容量限制时更安全,不会抛异常。
queue.offer(root);
int result = 0; // 用来存储每一层最左边的值
while (!queue.isEmpty()) {
int levelSize = queue.size(); // 获取当前层的节点总数
// 在新的一层开始时,队首元素就是该层的最左节点。
// peek()只查看队首元素,不移除,正是我们需要的。
result = queue.peek().val;
// 遍历并处理当前层的所有节点
for (int i = 0; i < levelSize; i++) {
// poll()移除并返回队首元素。
TreeNode node = queue.poll();
// 经典的从左到右将下一层节点入队
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
}
return result;
}
}- 时间复杂度:O(N)。N是节点总数。每个节点都会被入队一次、出队一次,不多不少。
- 空间复杂度:O(W)。W是树的最大宽度。队列中最多会存储树最宽一层的所有节点。
解法二:深度优先搜索(DFS)------另辟蹊径的深潜
深度优先搜索(DFS)同样可以解决此问题,但需要更巧妙的设计。DFS的本质是"一路走到黑",所以我们需要一种方法来比较不同路径上的节点,判断哪一个才是"最底层最左边"的。
我们的策略如下:
- 定义一个递归函数,该函数需要携带两个关键信息:当前节点
node和它所处的深度depth。 - 我们需要两个全局变量(或作为类的成员变量)来追踪状态:
maxDepth记录已发现的最大深度,result记录在maxDepth深度下最左边的节点值。 - 递归遍历时,我们遵循先左后右的顺序。
- 在访问每个节点时,我们检查其深度
depth。如果depth > maxDepth,这意味着我们第一次到达了一个更深的层级。由于我们是先左后右遍历的,所以当前这个节点一定是这个新层级中最左边的节点。此时,我们更新maxDepth = depth,并记录result = node.val。 - 如果
depth不大于maxDepth,我们什么也不做,因为我们只关心第一次发现新深度时的那个节点。
这个方法利用DFS的遍历顺序,确保在任何深度,我们总是先访问左边的节点。
java
/*
* 思路:深度优先搜索(DFS)递归。通过传递深度信息来解决问题。
* 我们需要两个成员变量:maxDepth记录已知的最大深度,result记录该深度下的最左节点值。
* 我们进行先序遍历(根-左-右),保证在任何深度,总是左边的节点先被访问。
* 当访问到一个节点,其深度 > maxDepth时,我们知道这是第一次踏入一个更深的层级,它就是我们要找的"最左"节点。
* 时间复杂度:O(N),每个节点访问一次。
* 空间复杂度:O(H),H是树的高度,用于递归调用栈。
*/
class Solution {
private int maxDepth = -1; // 记录已发现的最大深度,初始为-1
private int result = 0; // 存储结果
public int findBottomLeftValue(TreeNode root) {
dfs(root, 0); // 从根节点(深度0)开始深潜
return result;
}
private void dfs(TreeNode node, int depth) {
if (node == null) {
return;
}
// 核心判断逻辑!
if (depth > maxDepth) {
maxDepth = depth; // 发现了新大陆!更新最大深度
result = node.val; // 记录下这块新大陆的第一个"居民"(最左节点)
}
// 顺序至关重要:必须先左后右
dfs(node.left, depth + 1);
dfs(node.right, depth + 1);
}
}- 时间复杂度:O(N)。每个节点还是只被访问一次。
- 空间复杂度:O(H)。H是树的高度。递归调用栈的深度最多等于树的高度。对于一个"瘦高"的树,这个方法比BFS更省空间。
解法三:BFS的优雅变体------反向思考的魅力 ✨
写完前两种解法,我喝了口咖啡,突然冒出一个想法:既然BFS是从左到右遍历,那我能不能让它从右到左遍历呢?
答案是肯定的,而且代码会变得异常简洁!
思路是这样的:我们还用队列,但在把子节点加入队列时,反过来,先加右孩子,再加左孩子 。这样一来,每一层的节点在队列里的顺序就变成了从右到左。整个遍历下来,最后一个被访问到的节点,不就恰好是我们梦寐以求的"最底层最左边"的那个吗?
这个方法简直是神来之笔!我们不需要按层统计 size,只需要一个变量不断记录最新访问的节点,循环结束时,它就是答案。
java
/*
* 思路:变种BFS,通过改变入队顺序来简化逻辑。
* 我们在遍历时,让右孩子先入队,左孩子后入队。
* 这就保证了在同一层,左边的节点会比右边的节点晚出队。
* 因此,整个BFS过程中,最后一个从队列里取出的节点,一定是整个树最底层最左边的那个。
* 时间复杂度:O(N)。
* 空间复杂度:O(W)。
*/
import java.util.Queue;
import java.util.LinkedList;
class Solution {
public int findBottomLeftValue(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
TreeNode lastNode = null; // 用于记录最后一个被访问的节点
while (!queue.isEmpty()) {
lastNode = queue.poll();
// ✨ 核心魔法在这里:先右后左!
if (lastNode.right != null) {
queue.offer(lastNode.right);
}
if (lastNode.left != null) {
queue.offer(lastNode.left);
}
}
return lastNode.val;
}
}- 时间复杂度:O(N)。
- 空间复杂度:O(W)。
解法对比
| 对比维度 | 解法一: 标准BFS | 解法二: 递归DFS | 解法三: 变种BFS (右-左) |
|---|---|---|---|
| 核心思想 | 层序遍历,逐层更新该层最左节点值。 | 深度优先,通过记录和比较深度,找到第一个到达最深层的节点。 | 也是层序遍历,但通过改变子节点入队顺序,使最后一个访问的节点即为答案。 |
| 代码简洁度 | 中等 | 中等 | 高,逻辑最直接,代码量最少。 |
| 空间效率 | O(W),适用于"瘦高"树 | O(H),适用于"矮胖"树 | O(W),与标准BFS相同 |
| 推荐场景 | 最通用、最易于理解的解法。 | 当树非常"瘦高",且不担心递归深度时,空间上更优。 | 代码最优雅,面试时能展示出思维的灵活性。 |
举一反三,生活处处是"遍历"
这个"寻找特定位置节点"的思想,在实际开发中应用广泛:
- UI布局 : 想象一个动态生成的网格布局,你需要给最后一行的第一个元素一个特殊的
margin或样式。这就可以通过类似BFS的方法,找到最后一层的第一个元素。 - 游戏AI: 在棋类游戏的决策树中,AI可能需要评估最深层搜索路径中的第一个"劣势"局面,以便尽早剪枝或调整策略。
- 依赖分析: 在一个项目的依赖树中,找到最深层级的、字典序最小的那个依赖库,可能有助于分析项目中是否存在过度或陈旧的依赖。
类似好题推荐
想继续在树的海洋里遨游?试试这些题目吧,它们能很好地锻炼你对各种遍历方式的掌握:
- 102. 二叉树的层序遍历:BFS的经典模板题。
- 199. 二叉树的右视图:和本题类似,但要找的是每层最右边的节点。
- 103. 二叉树的锯齿形层序遍历:层序遍历的变体,需要交替改变遍历顺序。
最终,通过这番探索,我不仅解决了棘手的日志定位问题,还对树的遍历有了更深的感悟。一个小小的算法题,背后却蕴含着解决复杂工程问题的智慧,这也许就是编程的魅力所在吧!😉