在上一篇文章 AI入门-搭建一个本地聊天机器人中我们了解了 提示词与ai的聊天对话过程。这一小节我们将了解 大模型的函数调用和rag开发。
前言
既然在学习ai,那么我们能不能让ai帮助我们学ai呢?为此 决定开发一个专属的ai学习助手。作为一个初学者,我们并不知道学习ai大模型应用开发要学习一些什么,以及怎么学。为此直接通过我们搭建的聊天机器人让他给我们一份学习计划
python
ai_helper_prompt = """
你是一名高级ai开发教练,你严谨,认证细致,幽默。你的主要职责是
1. 帮助制定学习计划
2. 检验每日的学习成果,并针对学习效果进行评估。
3. 当学习效果较好时,给予鼓励,当学习效果 较差时 针对不足的内容提出针对性的学习方案,并在此检验直到完成
4. 能够根据实际情况动态调整学习计划与目标。
"""大型语言模型(LLM)如GPT-4在文本生成、问答和代码编写等任务上表现出色,但仍存在一些关键限制:
- 知识实时性不足:LLM的训练数据是静态的,无法实时获取最新信息(如新闻、股价或学术进展)。
- 事实准确性有限:模型可能生成看似合理但实际错误的回答("幻觉"问题)。
- 缺乏外部交互能力:LLM无法直接调用API、查询数据库或执行具体操作(如订机票、查天气)。
RAG(检索增强生成)和函数调用如何解决这些问题?
🔍 RAG:动态扩展知识库
-
原理:通过检索外部数据源(如数据库、文档或网页),将最新信息注入模型上下文,再生成回答。
-
优势:
- 提供实时、准确的答案(例如:"2023年世界杯冠军是谁?")。
- 减少幻觉,支持引用来源,增强可信度。
- 适用于企业知识库、客服等场景。
⚙️ 函数调用:连接现实世界的桥梁
-
原理:让LLM根据用户需求生成结构化请求(如JSON),触发外部工具或API(如计算、支付、数据查询)。
-
优势:
- 执行实际任务(如"订明天北京的酒店"或"查询我的订单状态")。
- 扩展模型能力,实现动态交互(如调用Python代码做数学计算)。
- 提升效率,避免手动操作。
函数调用
函数调用的时序如下
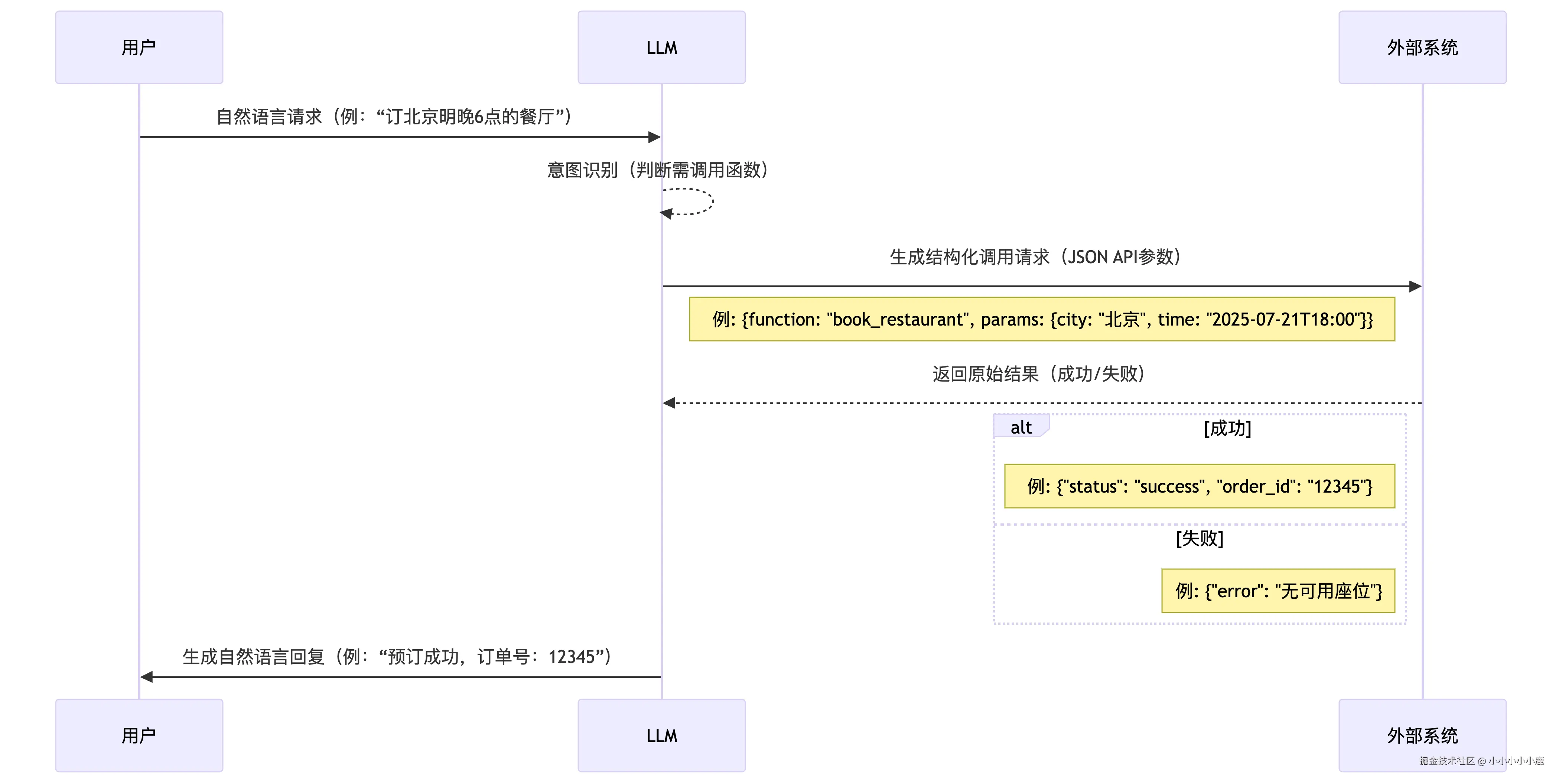 对话时大模型返回的数据结构如下
对话时大模型返回的数据结构如下
json
{
"id": "chatcmpl-ee9c3592-a825-971f-a6a2-7324a1459ab3",
"choices": [
{
"finish_reason": "tool_calls",
"index": 0,
"logprobs": null,
"message": {
"content": "",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "call_386cbbf1db3848e69c8460",
"function": {
"arguments": "{}",
"name": "get_current_time"
},
"type": "function",
"index": 0
}
]
}
}
],
"created": 1753097180,
"model": "qwen-plus",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": null,
"usage": {
"completion_tokens": 16,
"prompt_tokens": 230,
"total_tokens": 246,
"completion_tokens_details": null,
"prompt_tokens_details": {
"audio_tokens": null,
"cached_tokens": 0
}
}
}具体可以参考 其中choices 是大模型回调给我们的消息。
ai教学助手 代码设计
虽然我们才接触ai大模型应用,但考虑到 后续持续的开发迭代 我们的ai教学助手,整体代码设计如下
 关键解释: MessageManager: 维护管理 与整个大模型关联的消息,并将消息变更通知到外界 ChatContext:与大模型的交互调用,响应 MessageManager 消息变更。处理模型的消息回调, ToolsProviderMixIn:工具提供的抽象类,ChatContext 通过持有不同的 工具实现类,可以根据不同的业务场景告知大模型 有不同的工具 ChatModelMixIn:大模型抽象接口,ChatContext持有不同的实现可以切换不同的模型
关键解释: MessageManager: 维护管理 与整个大模型关联的消息,并将消息变更通知到外界 ChatContext:与大模型的交互调用,响应 MessageManager 消息变更。处理模型的消息回调, ToolsProviderMixIn:工具提供的抽象类,ChatContext 通过持有不同的 工具实现类,可以根据不同的业务场景告知大模型 有不同的工具 ChatModelMixIn:大模型抽象接口,ChatContext持有不同的实现可以切换不同的模型
函数调用的实现
大模型交互的过程中有结果 与函数调用相关的参数:
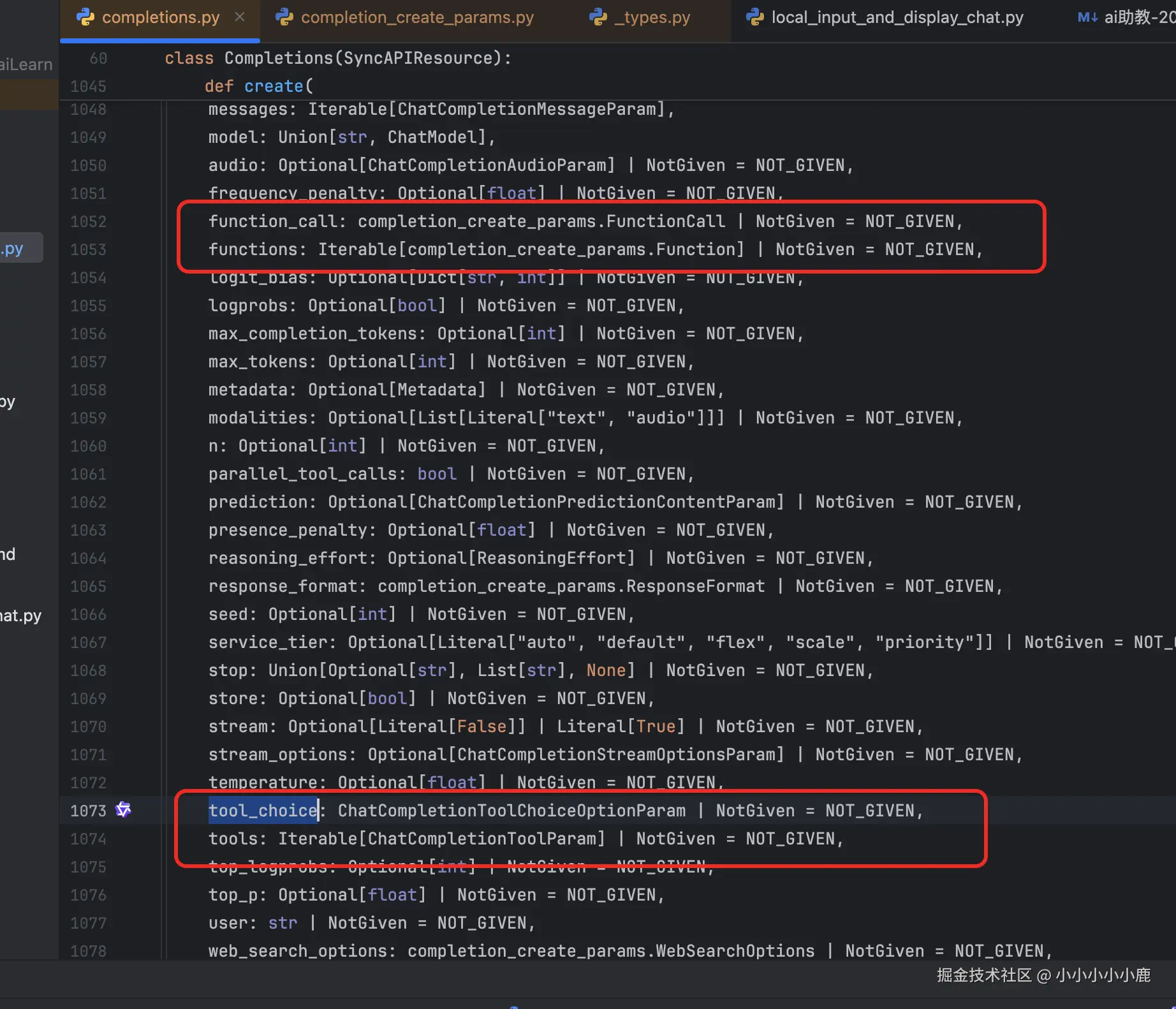 function会逐渐被废弃,因此我们直接使用tools就可以了。 函数调用主要有下面3个步骤
function会逐渐被废弃,因此我们直接使用tools就可以了。 函数调用主要有下面3个步骤
- 函数定义
- llm 决定调用函数
- 执行函数
- 将函数执行的结果在次发送给大模型
- 获取模型最终响应结果
接下来看看具体的执行代码: 前面的代码结构中ChatContext通过持有ToolsProviderMixIn,切换不同的实现类,从而使用不同的工具(这里不是说大模型一次只能回调一个函数,而是我们可能会根据不同的业务场景给大模型不同批次的工具) ToolsProviderMixIn代码设计
python
class ToolsProviderMixIn(ABC):
def __init__(self, ):
super().__init__()
@abstractmethod
def get_tools(self) -> List[ChatCompletionToolParam]:
pass
"""
返回需要将哪些工具注册到大模型中
"""
@abstractmethod
def message_match_tool(self, message: ChatCompletion|ChatCompletionChunk) -> bool:
pass
"""
判断当前工具类能否被大模型执行
"""
@abstractmethod
def tools_call(self, message: ChatCompletion) -> List[ChatCompletionToolMessageParam]:
pass
"""
响应大模型函数调用并返回结果
"""
具体的工具类实现
python
from datetime import datetime
from typing import List
from openai.types.chat import ChatCompletionToolParam, ChatCompletion, ChatCompletionToolMessageParam, \
ChatCompletionChunk
from learn02.chat_tools.chat_tool_mixin import ToolsProviderMixIn
class ChatTools(ToolsProviderMixIn):
def __init__(self, ):
super().__init__()
self.calling_tools = {}
def tools_call(self, message: ChatCompletion | ChatCompletionChunk) -> List[ChatCompletionToolMessageParam]:
if isinstance(message, ChatCompletion): # 可能是多个异步函数 当前先这样
return self.dispatch_tool_call(message)
if isinstance(message, ChatCompletionChunk):
if self.calling_tools.get(message.id):
if message.choices[0].finish_reason == "tool_calls":
self.calling_tools.pop(message.id)
return []
else:
self.calling_tools[message.id] = message
return self.dispatch_tool_call(message)
return []
return []
def dispatch_tool_call(self, message: ChatCompletion | ChatCompletionChunk):
tool_response: List[ChatCompletionToolMessageParam] = []
if isinstance(message, ChatCompletion):
for tool_call in message.choices[0].message.tool_calls:
if tool_call.function.name == "get_current_time":
current_time = self.get_current_time()
tool_response.append(
ChatCompletionToolMessageParam(role="tool", content=current_time, tool_call_id=tool_call.id))
else:
for tool_call in message.choices[0].delta.tool_calls:
if tool_call.function.name == "get_current_time":
current_time = self.get_current_time()
tool_response.append(
ChatCompletionToolMessageParam(role="tool", content=current_time, tool_call_id=tool_call.id))
return tool_response
def get_current_time(self) -> str:
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def message_match_tool(self, message: ChatCompletion | ChatCompletionChunk) -> bool:
if isinstance(message, ChatCompletion):
if message.choices[0].message.tool_calls:# 有tool_calls 存在说明是函数调用
return True
elif isinstance(message, ChatCompletionChunk):
if message.choices[0].delta.tool_calls:
return True
return False
def get_tools(self) -> List[ChatCompletionToolParam]:
return [
{
"type": "function",
"function": {
"name": "get_current_time",
"description": "获取当前时间",
"parameters": {
"type": "object",
"properties": {},
"required": [],
},
},
},
]**注意:**函数执行之后返回给大模型的消息类型是 ChatCompletionToolMessageParam,我们给大模型发送 ChatCompletionToolMessageParam 类型消息的前面一定要有 模型回调出来需要调用函数的消息,否则会报错
体验一下效果:
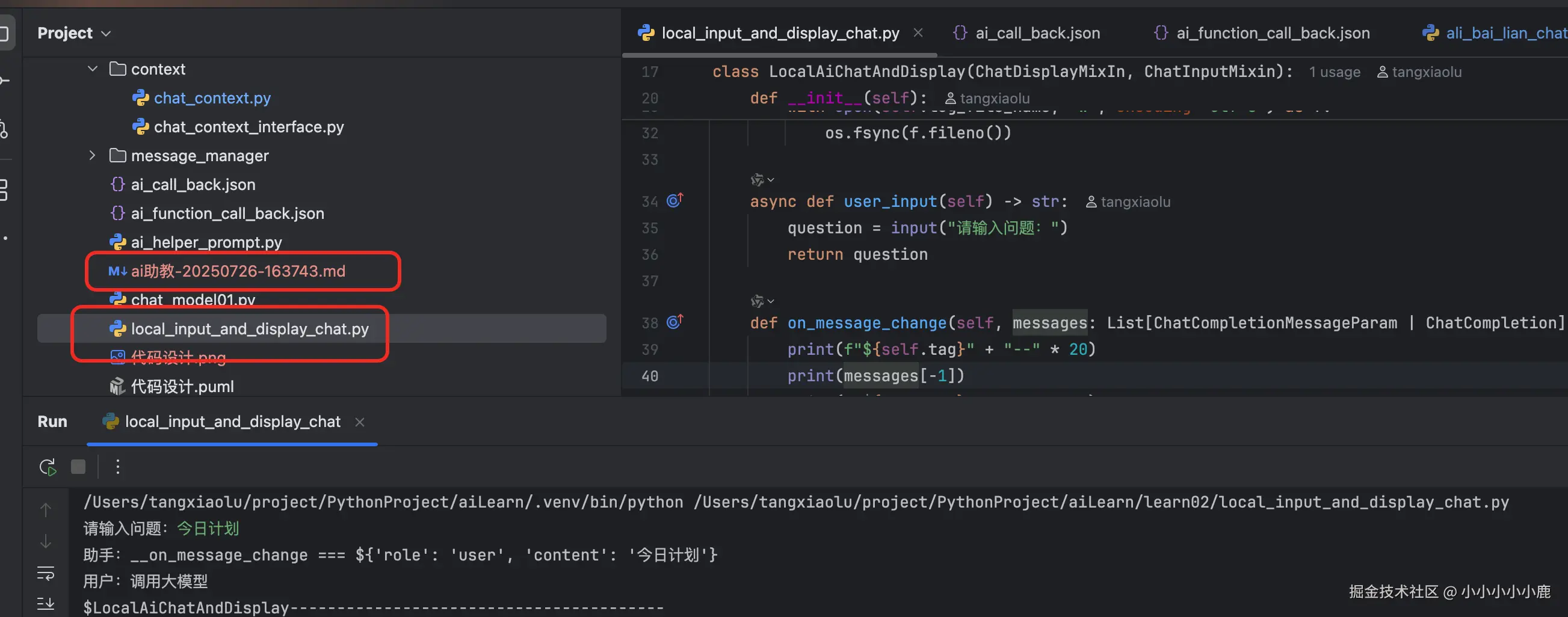 运行 local_input_and_display_chat.py ,命令行输入今日计划 会在当前文件夹下输出 一份md文件。浏览器打开
运行 local_input_and_display_chat.py ,命令行输入今日计划 会在当前文件夹下输出 一份md文件。浏览器打开
 到此函数调用的过程就结束了,后面会研究基于rag 来实现本地数据 检索,让ai 了解 我们的学习计划,学习结果,从而帮助我们 更好的验证学习情况。 参考代码:github.com/xiaolutang/...
到此函数调用的过程就结束了,后面会研究基于rag 来实现本地数据 检索,让ai 了解 我们的学习计划,学习结果,从而帮助我们 更好的验证学习情况。 参考代码:github.com/xiaolutang/...